百度西交大大数据菁英班目标检测竞赛
来源:投稿 作者:LSC
编辑:学姐
数据介绍
数据集共包括40000张训练图像和1000张测试图像,每张训练图像对应xml标注文件:


共包含3类:0:'head', 1:'helmet', 2:'person'。
提交格式要求,提交名为pred_result.txt的文件——每一行代表一个目标,每一行内容分别表示:图像名 置信度 xmin ymin xmax ymax类别

「限制只能使用paddle框架和aistudio平台运行代码」
总体思路
使用paddlex框架,模型选取ppyolov2模型。
!pip install paddleximport paddlex as pdx
from paddlex import transforms as T
## 数据增强train_transforms = T.Compose([T.MixupImage(mixup_epoch=-1), T.RandomDistort(),T.RandomExpand(im_padding_value=[123.675, 116.28, 103.53]), T.RandomCrop(),T.RandomHorizontalFlip(), T.BatchRandomResize(target_sizes=[192, 224, 256, 288, 320, 352, 384, 416, 448, 480, 512],interp='RANDOM'), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])eval_transforms = T.Compose([T.Resize(target_size=320, interp='CUBIC'), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])import osf = open("work/total.txt", "w", encoding="utf-8")
for i in os.listdir("work/helmet/train/images/"):voc = "annotations/" + i[:-3] + "xml" f.write("images/" + i + "\t" + voc + "\n")
f.close()# 最后一行是错误格式,手动删除
f = open("work/test.txt", "w", encoding="utf-8")
for i in os.listdir("work/helmet/test/images/"):voc = "annotations/" + i[:-3] + "xml" f.write("images/" + i + "\t" + voc + "\n")
f.close()from sklearn.utils import shufflef = open("work/total.txt", "r", encoding="utf-8")
total = f.readlines()ratio = 0.9
total = shuffle(total, random_state = 100)
train_len = int(len(total) * ratio)train = total[:train_len]
val = total[train_len:]f1 = open("work/train.txt", "w", encoding="utf-8")
for i in train:f1.write(i)
f1.close()f2 = open("work/val.txt", "w", encoding="utf-8")
for i in val:f2.write(i)
f2.close()f.close()
#手动创建label.txt
数据导入
train_dataset = pdx.datasets.VOCDetection(data_dir='work/helmet/train/',file_list='work/train.txt',label_list='work/label.txt',transforms=train_transforms,shuffle=True)test_dataset = pdx.datasets.VOCDetection(data_dir='work/helmet/test/',file_list='work/test.txt',label_list='work/label.txt',transforms=eval_transforms)eval_dataset = pdx.datasets.VOCDetection(data_dir='work/helmet/train/',file_list='work/val.txt',label_list='work/label.txt',transforms=eval_transforms)
# 在训练集上聚类生成9个anchor
anchors = train_dataset.cluster_yolo_anchor(num_anchors=9, image_size=608)
anchor_masks = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
#开始训练
num_classes = len(train_dataset.labels)
model = pdx.det.PPYOLOv2(num_classes=num_classes,backbone='ResNet101_vd_dcn',anchors=anchors,anchor_masks=anchor_masks,label_smooth=True)model.train(num_epochs=100,train_dataset=train_dataset,train_batch_size=8,eval_dataset=eval_dataset,pretrain_weights='COCO',learning_rate=0.005 / 12,warmup_steps=500,warmup_start_lr=0.0,save_interval_epochs=5,# lr_decay_epochs=[25, 75],save_dir='output1/',use_vdl=False,early_stop=True,
early_stop_patience=5)
# 使用之前最好的模型继续训练
model.train(num_epochs=100,train_dataset=train_dataset,train_batch_size=8,eval_dataset=eval_dataset,# pretrain_weights='COCO',learning_rate=0.005 / 12,warmup_steps=500,warmup_start_lr=0.0,save_interval_epochs=5,# lr_decay_epochs=[25, 75],save_dir='output2/',pretrain_weights='output1/best_model/model.pdparams',use_vdl=False,early_stop=True,
early_stop_patience=5)
# 导入最好的模型,评估模型效果
model = pdx.load_model("output1/best_model")
model.evaluate(eval_dataset, batch_size=8, metric=None, return_details=False)
# 模型推理,生成的两个文本文件就是最终提交的结果
image_dirs = 'work/helmet/test/images/'
f1 = open("work/pred_result1.txt", "w", encoding="utf-8") # 只写阈值大于0.5的
f2 = open("work/pred_result2.txt", "w", encoding="utf-8") # 全部写
for image_name in os.listdir(image_dirs):result = model.predict(image_dirs + image_name)for i in range(len(result)):xmin, ymin = int(result[i]['bbox'][0]), int(result[i]['bbox'][1])xmax, ymax = int(xmin + result[i]['bbox'][2]), int(ymin + result[i]['bbox'][3])if result[i]['score'] >= 0.5:f1.write(image_name[:-4] + " " + str(result[i]['score']) + " " + str(xmin) + " " + str(ymin) + " " + str(xmax) + " " + str(ymax) \+ " " + str(result[i]['category_id']) + "\n")f2.write(image_name[:-4] + " " + str(result[i]['score']) + " " + str(xmin) + " " + str(ymin) + " " + str(xmax) + " " + str(ymax) \+ " " + str(result[i]['category_id']) + "\n")
f1.close()
f2.close()
最终mAP值达到62.77648。
后续可以使用PaddleDetection框架进行优化,选取其中的ppyoloplus模型或者PaddleYOLO框架中的yolov5、yolov6、yolox、yolov7模型。ppyoloplus模型优化后的效果可以达到65%以上。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“all in”免费领取kaggle往期赛+新赛资料包
码字不易,欢迎大家点赞评论收藏!
相关文章:
百度西交大大数据菁英班目标检测竞赛
来源:投稿 作者:LSC 编辑:学姐 数据介绍 数据集共包括40000张训练图像和1000张测试图像,每张训练图像对应xml标注文件: 共包含3类:0:head, 1:helmet, 2:person。 提交格式要求,提交名为pred_r…...
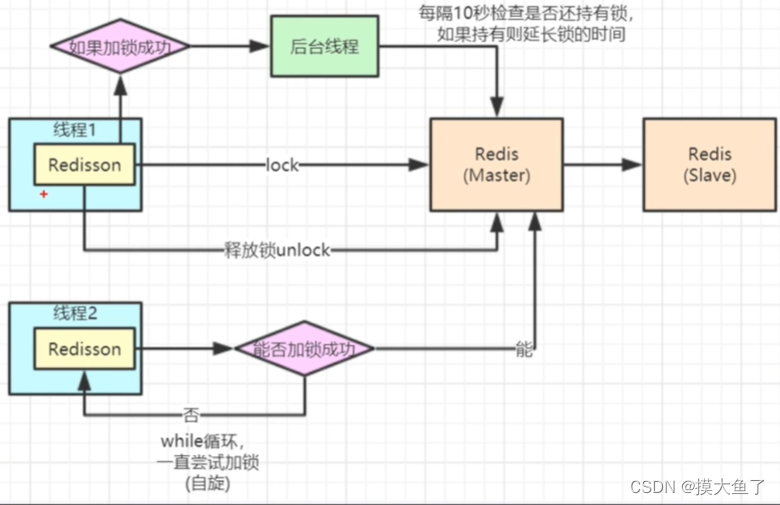
Redisson实现分布式锁
目录Redisson简介Redisson实现分布式锁步骤引入依赖application.ymlRedisson 配置类Redisson分布式锁实现Redisson简介 Redis 是最流行的 NoSQL 数据库解决方案之一,而 Java 是世界上最流行(注意,没有说“最好”)的编程语言之一。…...

【HID基础知识】
蓝牙HID基础知识 一:定义 HID是Human Interface Device的缩写,由其名称可以了解HID设备是直接与人交互的设备,例如键盘、鼠标与游戏手柄等。 蓝牙HID 是属于蓝牙协议里面的一个profile, 不管在蓝牙2.0 2.1 3.0还是4.0,5.0的蓝牙中…...

工赋开发者社区 | 工业数字孪生:西门子工业网络与设备虚拟调试案例(TIA+MCD+SINETPLAN)
PART1案例背景及基本情况新生产系统的设计和实施通常是耗时且高成本的过程,完成设计、采购、安装后,在移交生产运行之前还需要一个阶段,即调试阶段。如果在开发过程中的任何地方出现了错误而没有被发现,那么每个开发阶段的错误成本…...
将闲置的Ipad作为Windows的副屏(Twomon SE)
目录一、前言二、方法第一步 安装软件第二步 使用步骤三、注意一、前言 在看网课的时候,总有种不得劲的感觉,来来回回的切换就很糟心~~无意间看见闲置的板砖(Ipad),计上心来-- _ – 期间也尝试过免费的软件ÿ…...

浮点数在内存中的存储——“C”
各位CSDN的uu们你们好呀,今天,小雅兰的内容是浮点数在内存中的存储,昨天我们已经写过了整型在内存中的存储,那么,浮点数在内存中是怎样存储的呢?现在,就让我们进入浮点数在内存中的存储的世界吧…...

华为OD机试 C++ 实现 - 租车骑绿岛
最近更新的博客 华为OD机试 - 入栈出栈(C++) | 附带编码思路 【2023】 华为OD机试 - 箱子之形摆放(C++) | 附带编码思路 【2023】 华为OD机试 - 简易内存池 2(C++) | 附带编码思路 【2023】 华为OD机试 - 第 N 个排列(C++) | 附带编码思路 【2023】 华为OD机试 - 考古…...
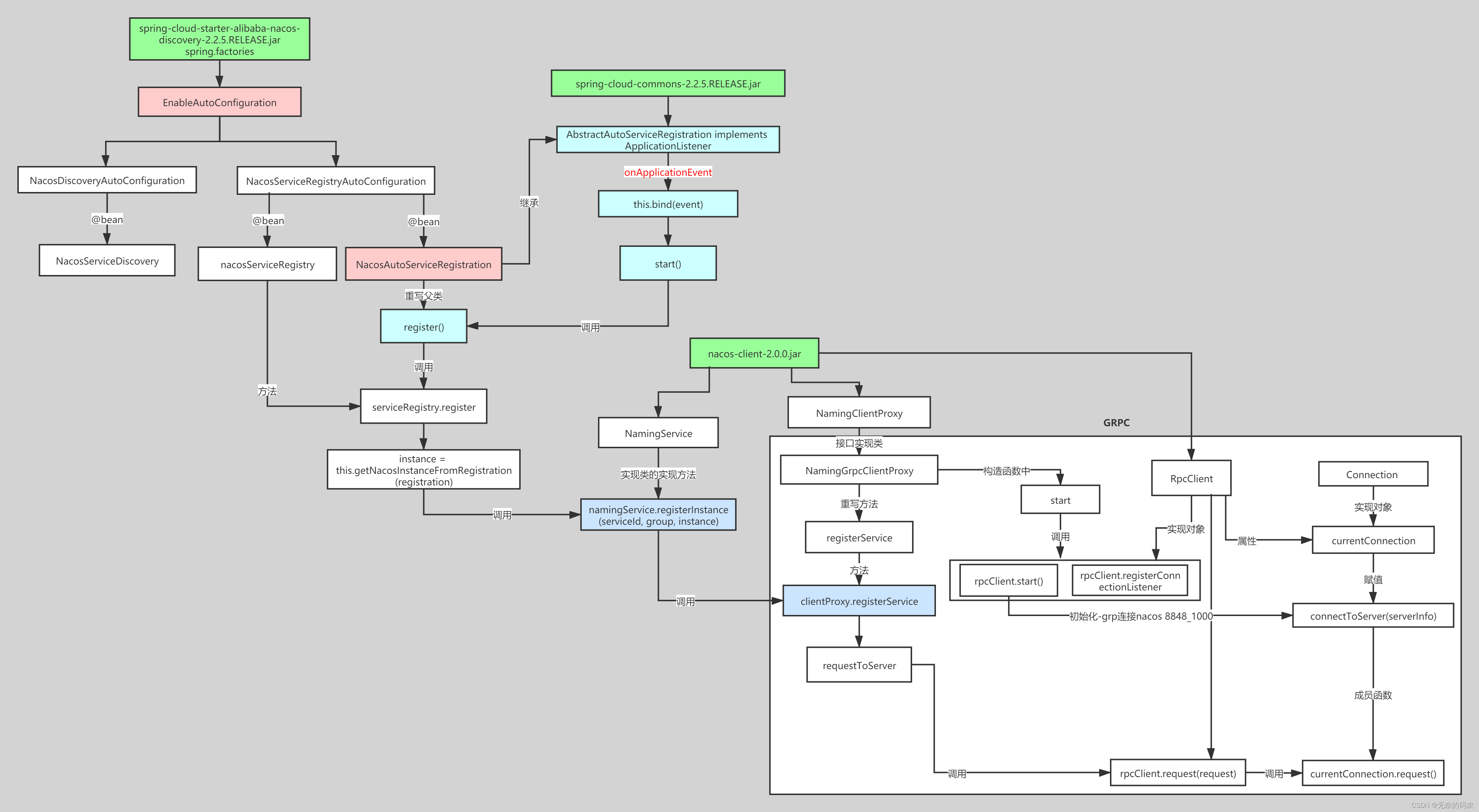
Spring Cloud Nacos源码讲解(三)- Nacos客户端实例注册源码分析
Nacos客户端实例注册源码分析 实例客户端注册入口 流程图: 实际上我们在真实的生产环境中,我们要让某一个服务注册到Nacos中,我们首先要引入一个依赖: <dependency><groupId>com.alibaba.cloud</groupId><…...

位运算(C/C++)
1. 基础知识 程序中的所有数在计算机内存中都是以二进制的形式储存的。位运算就是直接对整数在内存中的二进制位进行操作。比如,and运算本来是一个逻辑运算符,但整数与整数之间也可以进行and运算。举个例子,6的二进制是110,11的二…...

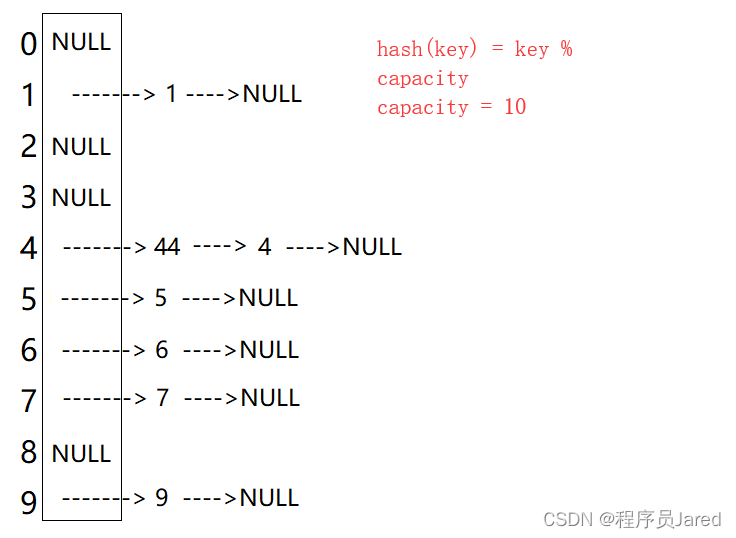
哈希表题目:设计哈希映射
文章目录题目标题和出处难度题目描述要求示例数据范围前言解法一思路和算法代码复杂度分析解法二思路和算法代码复杂度分析题目 标题和出处 标题:设计哈希映射 出处:706. 设计哈希映射 难度 3 级 题目描述 要求 不使用任何内建的哈希表库设计一个…...

力扣解法汇总1238. 循环码排列
目录链接: 力扣编程题-解法汇总_分享记录-CSDN博客 GitHub同步刷题项目: https://github.com/September26/java-algorithms 原题链接: 力扣 描述: 给你两个整数 n 和 start。你的任务是返回任意 (0,1,2,,...,2^n-1) 的排列 p&…...
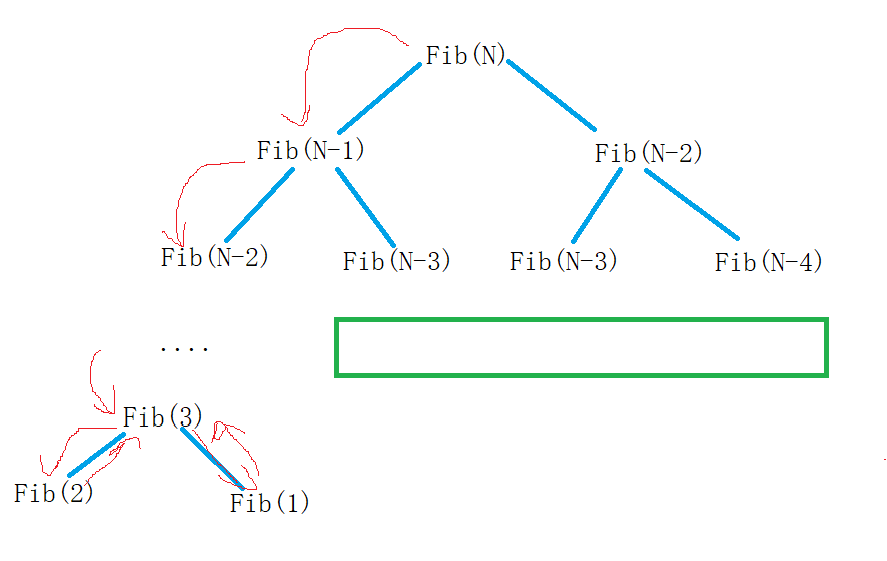
[数据结构]时间复杂度与空间复杂度
[数据结构]时间复杂度与空间复杂度 如何衡量一个算法的好坏 long long Fib(int N) {if(N < 3)return 1;return Fib(N-1) Fib(N-2); } 这是一个求斐波那契数列的函数,使用递归的方法求得,虽然代码看起来很简洁,但是简洁真的就好吗&#…...

Codeforces Round #848 (Div. 2)(A~D)
A. Flip Flop Sum给出一个只有1和-1的数组,修改一对相邻的数,将它们变为对应的相反数,修改完后数组的和最大是多少。思路:最优的情况是修改一对-1,其次是一个1一个-1,否则修改两个1。AC Code:#i…...
)
第十三届蓝桥杯Java B 组国赛 C 题——左移右移(AC)
目录1.左移右移1.题目描述2.输入格式3.输出格式4.样例输入5.样例输出6.数据范围6.原题链接2.解题思路3.Ac_code1.左移右移 1.题目描述 小蓝有一个长度为 NNN 的数组, 初始时从左到右依次是 1,2,3,…N1,2,3, \ldots N1,2,3,…N 。 之后小蓝对这个数组进行了 MMM 次操作, 每次…...

第14篇:系列二—Java抽象类/接口/枚举
目录 1、继承的定义(Inheritance) 2、继承的优点 2.1 易维护性 2.2 复用性 2.3 条理性...
深入浅出C++ ——哈希
文章目录前言一、unordered系列关联式容器1. unordered_map2. unordered_set二、哈希1. 哈希概念2. 哈希冲突3. 哈希函数4. 哈希冲突解决方法三、模拟实现unordered系列容器1. 哈希表的改造2. 模拟实现 unordered_set3. 模拟实现 unordered_map前言 在C11中,STL又提…...

Tina_Linux_系统裁剪_开发指南
文章目录Tina_Linux_系统裁剪_开发指南1 概述2 Tina系统裁剪简介2.1 boot0裁剪2.2 uboot裁剪2.3 内核裁剪2.3.1 删除不使用的功能2.3.2 删除不使用的驱动2.3.3 修改内核源代码2.3.3.1 size工具.2.3.3.2 ksize.py脚本2.3.3.3 nm命令2.3.3.4 kernel压缩方式.2.4 文件系统裁剪.2.4…...

算法刷题打卡第99天:至少在两个数组中出现的值
至少在两个数组中出现的值 难度:简单 给你三个整数数组 nums1、nums2 和 nums3 ,请你构造并返回一个 元素各不相同的 数组,且由 至少 在 两个 数组中出现的所有值组成。数组中的元素可以按 任意 顺序排列。 示例 1: 输入&…...

线程池面试题
1. 什么是线程池?为什么要使用线程池? 线程池是一种用于管理线程的技术,它可以在应用程序中重复使用一组线程来执行多个任务。线程池的优点包括提高应用程序的性能和可伸缩性、避免线程创建和销毁的开销、避免线程过多导致系统负担过重等。线…...

【学习笔记】NOIP爆零赛5
说实话是不想补题的。因为每一道题都贼难写,题解又通篇写着显然,然后自己天天搞竞赛又把注意力搞差了,调一道题又调半天,考试的题又难的要死 不会正解 ,部分分又写挂了 可能心态崩了就是从那场t1t1t1签到题考高精度数位…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

在Spring Boot中集成RabbitMQ的完整指南
前言 在现代微服务架构中,消息队列(Message Queue)是实现异步通信、解耦系统组件的重要工具。RabbitMQ 是一个流行的消息中间件,支持多种消息协议,具有高可靠性和可扩展性。 本博客将详细介绍如何在 Spring Boot 项目…...

Ray框架:分布式AI训练与调参实践
Ray框架:分布式AI训练与调参实践 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 Ray框架:分布式AI训练与调参实践摘要引言框架架构解析1. 核心组件设计2. 关键技术实现2.1 动态资源调度2.2 …...
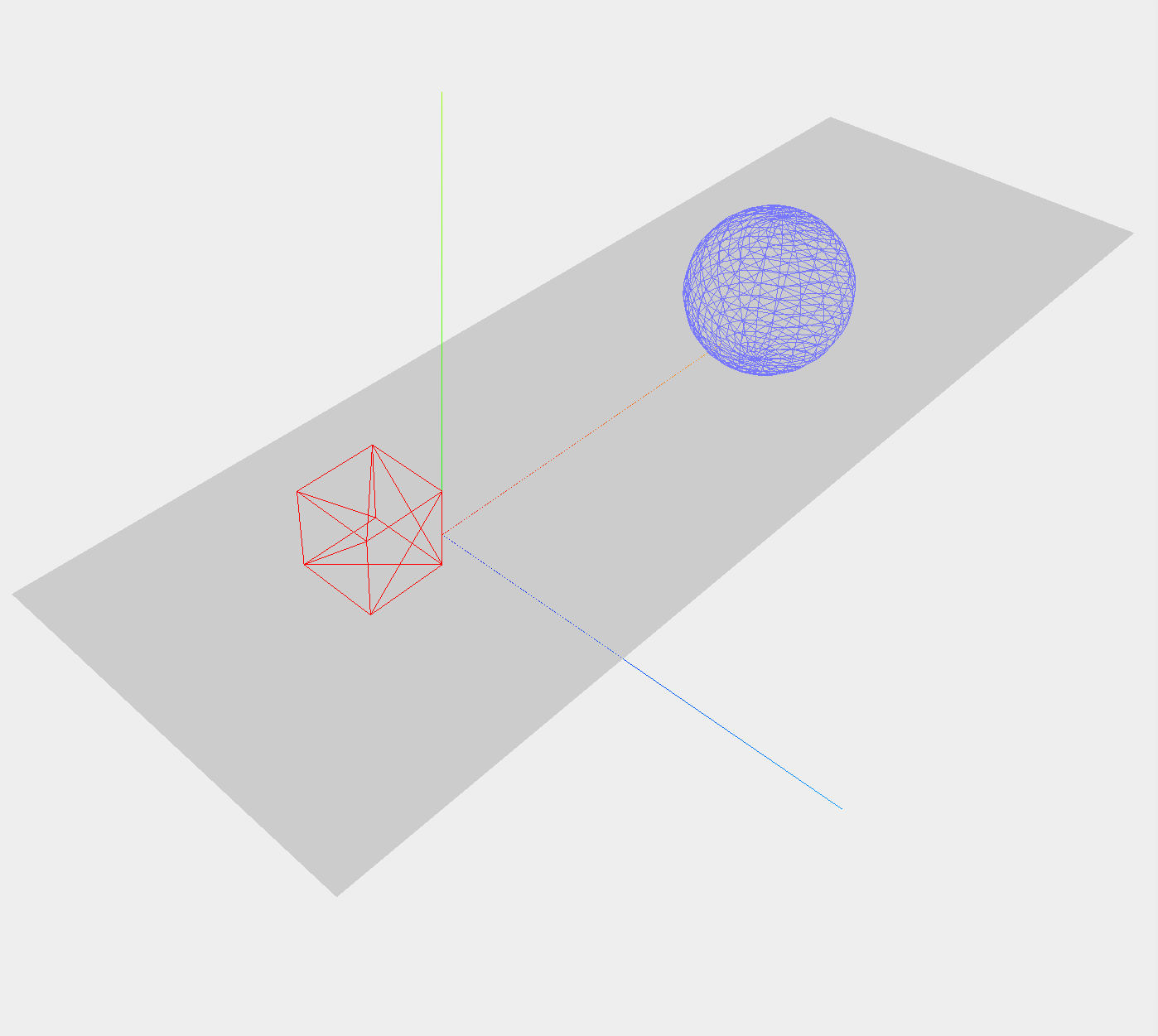
【threejs】每天一个小案例讲解:创建基本的3D场景
代码仓 GitHub - TiffanyHoo/three_practices: Learning three.js together! 可自行clone,无需安装依赖,直接liver-server运行/直接打开chapter01中的html文件 运行效果图 知识要点 核心三要素 场景(Scene) 使用 THREE.Scene(…...

以太网PHY布局布线指南
1. 简介 对于以太网布局布线遵循以下准则很重要,因为这将有助于减少信号发射,最大程度地减少噪声,确保器件作用,最大程度地减少泄漏并提高信号质量。 2. PHY设计准则 2.1 DRC错误检查 首先检查DRC规则是否设置正确,然…...
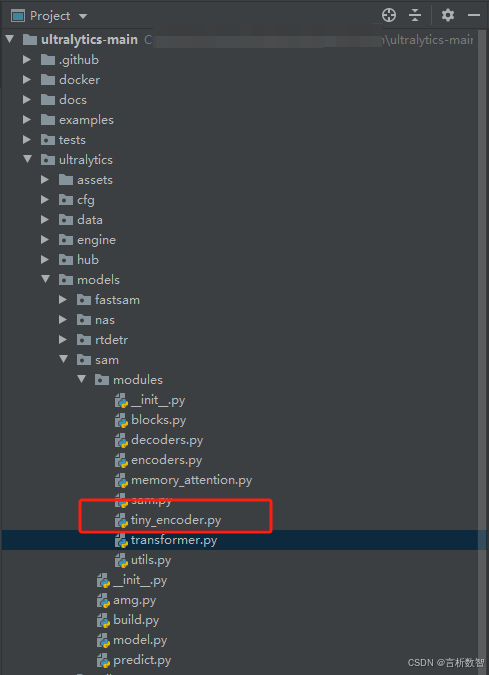
开源项目实战学习之YOLO11:12.6 ultralytics-models-tiny_encoder.py
👉 欢迎关注,了解更多精彩内容 👉 欢迎关注,了解更多精彩内容 👉 欢迎关注,了解更多精彩内容 ultralytics-models-sam 1.sam-modules-tiny_encoder.py2.数据处理流程3.代码架构图(类层次与依赖)blocks.py: 定义模型中的各种模块结构 ,如卷积块、残差块等基础构建…...