MySQL 的体系结构、引擎与索引
MySQL的引擎与体系结构
体系结构
连接层
最上层是一些客户端和链接服务,主要完成一些类似于连接处理、授权认证、及相关的安全方案。服务器也会为安全接入的每个客户端验证它所具有的操作权限
服务层
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的优化和分析,部分内置函数的操作。所有跨存储引擎的功能也是在这一层实现的,如过程、函数等
引擎层
存储引擎真正的负责MySQL中个数据的存储与提取,服务器通过API和存储引擎进行通信,不同的存储引擎具有不同的功能,这样子我们也可以根据自己的需求,来选取合适的存储引擎
存储层
主要是将数据存储在文件系统之上,并完成与存储引擎的交互
存储引擎
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式,存储引擎是基于库的,所以存储引擎也可以被称为表类型
默认引擎-InnoDB
查看所有的引擎
show engines;
可以看到所有的引擎

存储引擎的特点
InnoDB
InnoDB是一种兼顾高可靠性和高性能的通用存储引擎,在MySQL5.5版本之后,InnoDB是默认的MySQL的引擎。
特点
- DML(增删改)操作支持ACID(原子性、一致性、隔离性、持久性)模型,支持事务
- 行级锁,提高并发访问的性能
- 支持外键(Foreign Key)约束,保证数据的完整性和正确性
文件
xxx.ibd:xxx代表的是表明,innoDB引擎的每张表都会对应着这样的一个表文件,存储该表的表结构(frm、sdi)、数据和索引,参数innodb_file_per_table 默认为no,表示每张表各自占用一个表空间,如果为yes表示多张表共用一个表空间
查看指令
-- 查看是共用多个表空间
show variables like 'innodb_file_per_table';
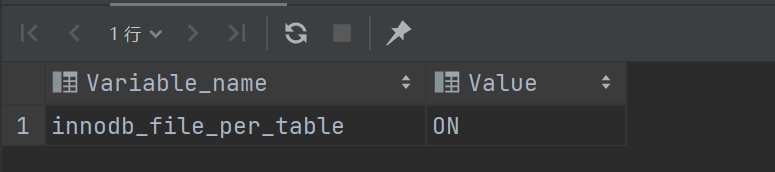
查看ibd文件:
我在本地系统中找到了自己库的文件
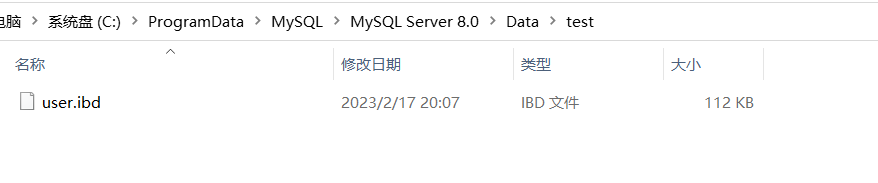
但是这个文件是一个二进制文件没法直接查看,但是可以借助指令来进行一个查看
ibd2sdi 文件命.ibd
查看结果:
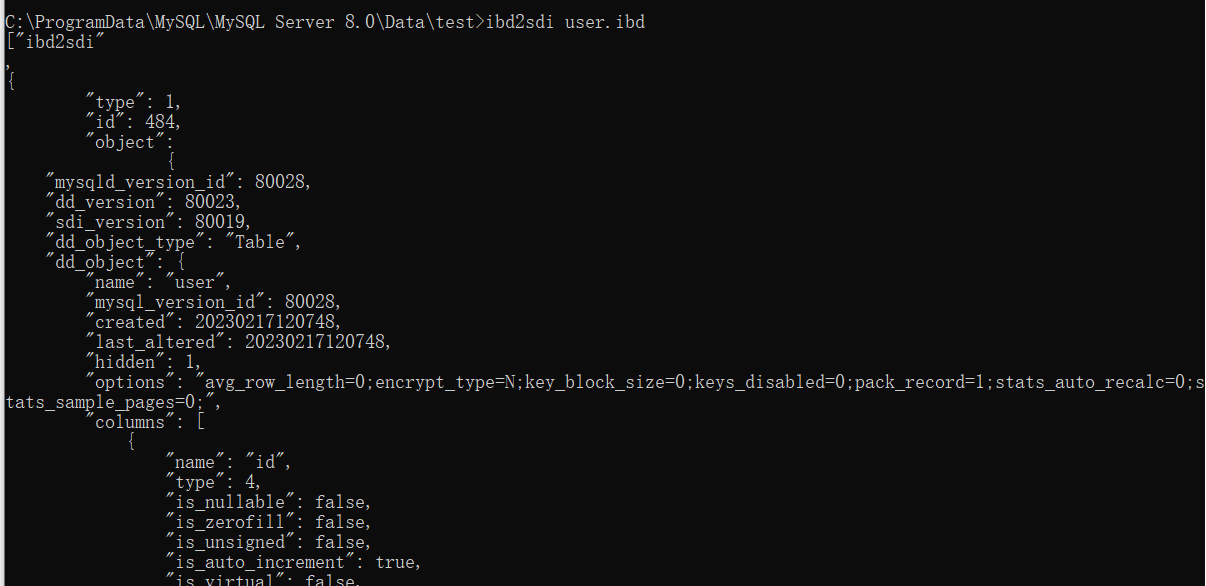
可以直接看到表的全部信息以及字段信息
逻辑空间
- TableSpace 表空间
- Segment:段
- Extent:区 区的大小是固定的,是1M, 可以包含64个页
- Page:页 页是操作的最小单元,大小页是固定的,一个页16K
- Row:行

MyISAM
MyISAM是MySQL的早期默认存储引擎
特点
不支持事务,不支持外键
支持表锁,不支持行锁
访问速度快
文件
*.sdi:存储表结构信息
.MYD:存储数据
***.MYI **:存储索引
Memory
Memory引擎的表数据是存储在内存中的,由于受到硬件问题、断电问题的影响,只能将这些表作为临时表或者缓存使用
特点
内存存放
hash索引
文件
*.sdi:存储表结构信息
各个引擎的特点
| 特点 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 存储限制 | 64TB | 有 | 有 |
| 事务安全 | 支持 | - | - |
| 锁机制 | 行锁 | 表锁 | 表锁 |
| B+tree索引 | 支持 | 支持 | 支持 |
| hash索引 | - | - | 支持 |
| 全文索引 | 5.6之后支持 | 支持 | - |
| 空间使用 | 高 | 低 | |
| 内存使用 | 高 | 低 | 中等 |
| 批量插入速度 | 低 | 高 | 高 |
| 支持外键 | 支持 | - | - |
InnoDB与MyISAM:InnoDB支持事务、外键和行级锁
执行引擎的选择
-
InnoDB:是MySQL的,默认引擎,支持事务、外键,如果应用对事物的**完整性**有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询外,还包含很多更新、删除操作,那么InnoDB存储引擎是比较合适的选择
-
MyISAM:如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事物的完整性、并发性要求不是很高,那么选择这个存储引擎比较合适
-
Memory:将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。Memory缺陷是对标的大小有限制,太大的表无法缓存在内存中,而却无法保证数据的安全性
索引
索引概述
什么是索引?
索引(index)是帮助MySQL搞笑获取数据的数据结构(有序),在数据之外,数据库系统还维护者满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引
优缺点
| 优点 | 缺点 |
|---|---|
| 提高数据检索的效率,降低数据库的IO成本 | 索引列也是要占用空间的 |
| 通过索引列堆数据进行排序,降低数据排序的成本 | 索引大大提高了查询效率,同时也降低更新表的速度,如对表进行 Insert、update、delete操作时,效率降低(但实际上查询操作更多,而增改删操作较少) |
索引数据结构
MySQL的索引是在存储引擎曾实现的,不同的存储引擎有不同的结构,主要包括以下几种:
| 索引结构 | 描述 |
|---|---|
| B+Tree索引 | 最常见的索引类型,大部分引擎都支持B+树索引 |
| Hash索引 | 底层数据结构是通过哈希表实现的,只有精确匹配索引列的查询才有效,不支持范围查询 |
| R-Tree(空间索引) | 空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,比较少用 |
| Full-text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式,类似于ES |
索引支持
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | 不支持 | 不支持 | 支持 |
| R-Tree索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本之后支持 | 支持 | 不支持 |
平时所说的索引,如果没有特别的指明,都是B+树结构组织的索引
B+Tree
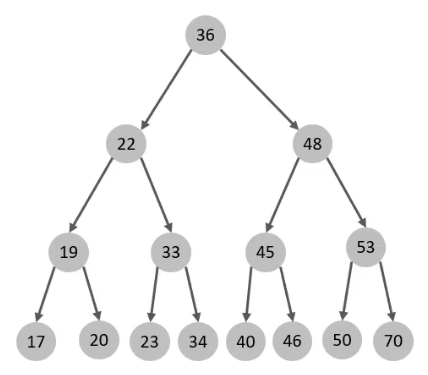

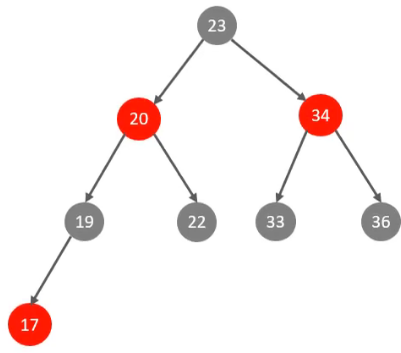
二叉树的缺点:顺序插入时,会形成链表,查询性能大大降低。大数据量的情况下,层级较深,检索速度较慢
红黑树:能够解决顺序插入形成链表的情况,但是在大数据量的情况下,层级较深,索引速度较慢
B-Tree(多路平和查找树):以一颗最大度数(max-degree)为5阶的b-tree为例(每个节点最多存储4个key,5个指针)【树的度数指的是一个结点的子结点个数】:

B+Tree与B-Tree的区别:
- 所有的数据都会出现在叶子节点
- 叶子节点形成一个单向链表

MySQL的B+树相对于经典的B+树进行了优化,在原有的B+树的基础上,增加了一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+树,提高区间访问性能

Hash
哈希索引就是采用一定的Hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中
如果两个(或多个)键值,映射到一个相同的槽位上,他们就会产生hash冲突,可以通过链表进行解决
特点:
- Hash索引只能用于对等比较(=,in),不支持范围查询
- 无法利用索引完成排序操作
- 查询效率高,通常只需要一次检索就可以了,效率通常高于B+Tree索引
存储结构支持
在MySQL中,支持hash索引的是memory引擎,而innodb中具有自适应hash功能,hash索引是存储引擎根据B+树索引在指定条件下自动构建的
InnoDB存储引擎为什么要选择B+Tree索引结构
- 相对于二叉树,层级更少,搜索效率更高
- 相对于B-Tree,无论是叶子节点还是非叶子节点都会存储数据,这样导致一页中存储的键值减少,指针跟着减少,要同时保存大量数据,只能增加树的高度,导致性能降低
- 相对于Hash索引,B+Tree支持范围匹配和排序操作
索引分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中逐渐创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中的某个数据列中的重复值 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引超找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FUNNTEXT |
在InnoDB存储索引中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引(Clustered index) | 将数据存储与索引放在一块 | 必须有,而且只能有一个 |
| 非聚集索引/二级索引/辅助索引(Secondary index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引
- 如果不存在逐渐,将使用第一个唯一(UNIQUE)索引作为聚集索引
- 如果表没有逐渐,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引
select * from user where name = "Arm"

查询条件是name,那么就先走二级索引,二级索引查找到之后就会拿到这一行的主键ID,根据主键在聚集索引中进行查询,找到这一行的数据。
回表查询指的是现在二级索引中找到主键值,然后再到主键索引中找到对应的行,这种查询被称为回表查询
索引的语法
创建索引
CREATE [UNIQUE|FULLTEXT] INDEX index_name ON table_name (index_col_name,....)
一次可以创建多个索引,如果使用UNIQUE或者FULLTEXT 则表示创建的是唯一/全文索引,反之则是普通索引
查看索引
SHOW INDEX FROM table_name;
删除索引
DROP INDEX index_name ON table_name
SQL 性能分析
SQL执行频率
MySQL客户端连接成功后,通过show [session|global] status命令可以提供服务器状态信息。通过下面指令可以看到当前数据库的insert update delete select 的访问频率:
SHOW GLOBAL STATUS LIKE 'COM_______';
-- 7个下划线

慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认为10s)的所有SQL语句的日志。
MySQL的慢查询日志默认没有开启,需要在MySQL的配置文件(/etc/my.cnf)中配置
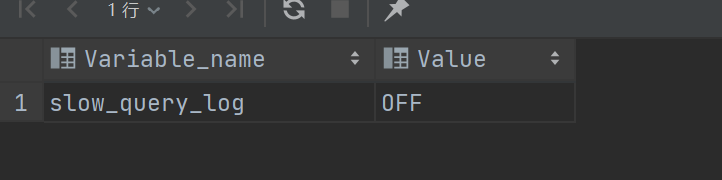
查询是否开启了慢查询日志:
show variables like 'slow_query_log';

修改配置文件
# 开启MySQL慢查询日志查询开关
slow_query_log=1
# 设置慢日志的时间为2s,如果语句执行时间超过了2s,就会被视为慢查询,记录慢查询日志
long_query_time=2

profile详情
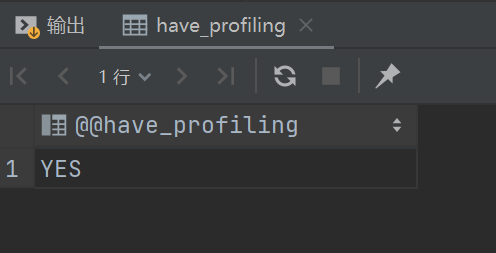
show profiles能够在做SQL优化时帮助我们了解事件都消耗到哪里去了。通过have_profiling参数,能够看到当前MySQL是否支持profile操作
查看是否支持该操作
select @@have_profiling;
默认情况下profiling是关闭的,可以通过set语句在session/global级别开启profiling;
set profiling = 1;
先查看是否已经开启:
select @@profiling;
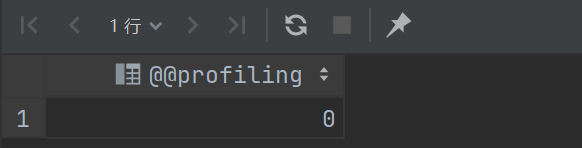
如果为1则表示已经打开,这里为0,表示没有打开,需要再进行一次设置,设置成功后再次查询:
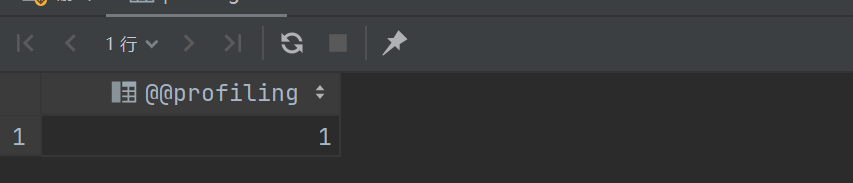
#这里我的建议是 不用看,因为MySQL8.0之后要废弃这个方法
'SHOW PROFILES' is deprecated and will be removed in a future release. Please use Performance Schema instead
explain执行计划
EXPLAIN或者DESC命令获取MySQL如何执行select语句的信息,包括在select语句执行过程中如何连接和连接顺序
-- 直接在select 语句之前加上关键字 explain 或者desc即可
explain select 字段列表 from 表名 where 条件;
查询语句:
explain select * from shop.tb_newbee_mall_admin_user where admin_user_id ='1';
查询结果:

含义介绍
-
Id
select查询的序列号,表示查询中执行select子句或者是操作表的顺序(Id相同,执行顺序从上到下,Id不同,值越大越先执行)。
-
select_type
表示select的查询类型,常见的取值有SIMPLE(见到表,及不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)
UNION(UNION中的第二个或者后面的查询语句)、SUBQUERY(Select/where之后包含了子查询)等等
-
type
表示连接类型,性能从好到差以此为:NULL system CONST eq_ref ref range index all
根据唯一主键进行查询会返回CONST,非唯一主键返回ref,null几乎达不到,除非不查询任何表
-
possible_key
显示可能应用在这张表上的索引,一个或者多个
-
key
实际使用的索引,如果为null,则表示没有使用索引
-
key_len
表示索引中使用的字节数,该职位为索引字段最大可能值,并非实际使用长度,在不损失精确性的前提下,长度越长越好
-
rows
MySQL认为必须执行的查询的行数,在innodb引擎的表中,是一个预估值,可能并不总是准确。
-
filtered
表示返回结果的行数占需读取行书的百分比,filtered越大越好
索引使用
失效原因
最小前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则,最左前缀法则指的是查询从索引最左列开始,并且不能够跳过索引中的列,如果条约某一列,索引将部分失效(后面的字段索引失效)
举个例子,现在存在一个联合索引,分别为字段A B C,顺序页是从左往右在查询过程中如果输入
select * from table where A = 1 and B = 2 and C = 3;
这样的话就会走联合索引,查出来的key_len等于ABC三个字段的和
那么如果不带C
select * from table where A=1 and B=2;
这样子仍然走联合索引,但是key_len等于AB两个字段的长度,
依此类推
那么此时不走A
select * from table where B =1 and C=3 ;
由于A是最左列,这样子就不满足最左前缀法则,所以索引为null
那么如果我们有A但是跳过B直接到C
select * from table where A = 1 and C = 3;
这样子走索引,但是key_len等于A的长度,则表示C已经被丢失,对应了后面的索引失效
那么我们走ABC但是顺序不一样
select * from table where b= 1 and c= 2 and a=1;
这样子和第一种情况相似,字段长度仍为ABC的总和
范围查询
联合索引中,出现了范围查询(>,<),范围查询右侧的索引失效,但是>= 这种可以直接规避这种情况
索引列运算操作
不要再索引列上进行运算操作,否则索引将失效
举个例子:
自己创建了一个表和一个联合索引,用nick_name和address 进行联合,用nick_name进行一个直接查询
explain select * from shop.tb_newbee_mall_user where nick_name = '十三';
结果:

那么我们进行计算,进行一个字符串切割再查看结果:
explain select *from shop.tb_newbee_mall_user where substr(nick_name,1,3) = '198';

在这里看出来索引直接失效
需要注意的是,如果是模糊查询,直接自己手动拼接 写成 字符串%不会出现任何问题,还是会走索引,如果是'%字符串%'则不会走索引,CONCAT也相同
使用CONCAT函数
explain select *from shop.tb_newbee_mall_user where nick_name like CONCAT('%','198','%');
运行结果:

单个:
explain select *from shop.tb_newbee_mall_user where nick_name like '198%';

字符串不加引号
字符串不加引号,会造成索引失效
例如:加上引号
explain select * from shop.tb_newbee_mall_user where nick_name = '1986565395';
效果:

不加引号
explain select * from shop.tb_newbee_mall_user where nick_name = 1986565395;
效果:

可能会使用tb_wxk这个索引,但是实际上并没有进行使用
发生了隐式转换
模糊查询
如果只是尾部模糊匹配,索引不会失败,如果是头部模糊匹配,索引则会失效
or连接的条件
用or分隔开的条件,如果or前的条件中的列有索引,而后面的列中没有索引,那么设计的索引都不会被用到
先查看索引:
show index from shop.tb_newbee_mall_user;

在这里使用or进行连接
连接两个都有索引的字段
explain select * from shop.tb_newbee_mall_user where nick_name='1986565395' or user_id=1;
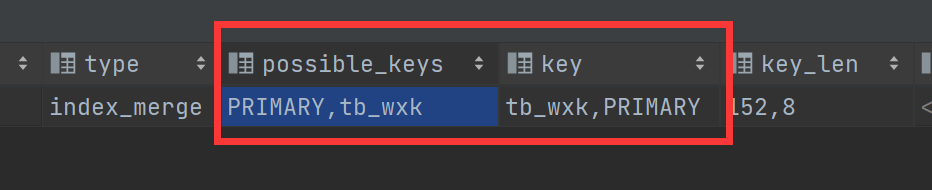
一个字段没有索引
explain select * from shop.tb_newbee_mall_user where nick_name='1986565395' or is_deleted=0;
结果:
数据分布影响
如果MySQL评估使用索引比全表更慢,则不使用索引
比如说这里的nickname是0~10,都比0大

那么我进行一个操作查询操作
explain select * from shop.tb_newbee_mall_user where nick_name >= '0';
按照正常流程,这个操作是要走索引的,此外nick_name全都比0大
运行结果如下:

到最后没有走索引,而是选择了扫描全表
那么再次进行一个更换
explain select * from shop.tb_newbee_mall_user where nick_name <= '0';

这样子又走索引了。
那么我们查询大于等于5的(大于等于五的数据小于一半)
explain select * from shop.tb_newbee_mall_user where nick_name >= '5';

这时候还是老老实实的走了全局索引
说明MySQL在选择扫描全表还是走索引会进行评估,这个评估和数据分布有关
索引使用原则
SQL提示
我们知道nick_name和address是一个联合索引,在这里我将nick_name设置成为一个单列索引
create index tb_nick on shop.tb_newbee_mall_user(nick_name);
查看所有的索引:

可以看到此时的nickname已经存在两个索引,那么执行下面SQL
explain select * from shop.tb_newbee_mall_user where nick_name = '2';

最后还是走了联合索引,说明在这时MySQL自己做出了选择,那么如何规避这个选择?这时候就是用到了SQL提示
SQL提示,是优化数据库的一个重要手段,简单来说,就是SQL语句中加入一些认为的提示来达到优化的作用
-
use index:
explain select * from shop.tb_newbee_mall_user use INDEX (tb_nick) where nick_name ='5'在这里要求使用了tb_nick这个锁:

-
ignore index:
忽略某个index
explain select * from shop.tb_newbee_mall_user ignore INDEX (tb_nick) where nick_name ='5';这里选择忽略tb_nick这个索引

直接不进行使用
-
force index:
强制使用某个索引
explain select * from shop.tb_newbee_mall_user force INDEX (tb_nick) where nick_name ='5';
覆盖索引
尽量使用覆盖索引(查询使用了索引,并需要返回的列,在该列中已经全部能找到),减少使用 select *
explain select nick_name,address from shop.tb_newbee_mall_user where nick_name >= '5';
在这里我们查询nickname和address,
查询结果

我们在查询is_deleted:
explain select is_deleted from shop.tb_newbee_mall_user where nick_name >= '5';

using index condition 查找使用了索引,但是需要回标查询
using where, using index 查找使用了索引,但是需要的数据都在索引列中能够找到,不需要进行回表查询操作
前缀索引 不建议使用,可以考虑ES
当字段为字符串(varchar text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO,影响查询效率,此时可以只讲字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率
-
语法:
create index idx_xxx on table_name(column(n))
-
前缀长度
可以根据索引的许安则醒来确定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高,唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的
select count(distinct email)/count(*) from tb_user; select count(distinct substring(email,1,5)) / count(*) from tb_user;
相关文章:
MySQL 的体系结构、引擎与索引
MySQL的引擎与体系结构 体系结构 连接层 最上层是一些客户端和链接服务,主要完成一些类似于连接处理、授权认证、及相关的安全方案。服务器也会为安全接入的每个客户端验证它所具有的操作权限 服务层 第二层架构主要完成大多数的核心服务功能,如SQL…...

数字IC设计需要学什么?
看到不少同学在网上提问数字IC设计如何入门,在学习过程中面临着各种各样的问题,比如书本知识艰涩难懂,有知识问题难解决,网络资源少,质量参差不齐。那么数字IC设计到底需要学什么呢? 首先来看看数字IC设计…...

五分钟搞懂POM设计模式
今天,我们来聊聊Web UI自动化测试中的POM设计模式。 为什么要用POM设计模式 前期,我们学会了使用PythonSelenium编写Web UI自动化测试线性脚本 线性脚本(以快递100网站登录举栗): import timefrom selenium import …...

面试 | 递归乘法【细节决定成败】
不用[ * ]如何使两数相乘❓一、题目明细二、思路罗列 & 代码解析1、野蛮A * B【不符合题意】2、sizeof【可借鉴】解析3、简易递归【推荐】① 解析(递归展开图)② 时间复杂度分析4、移位<<运算【有挑战性💪】① 思路顺理② 算法图解…...
【Linux】环境变量与进程优先级
文章目录🎪 进程优先级🚀1.孤儿进程🚀2.优先级查看🚀3.优先级修改🎪 环境变量🚀1.常见环境变量🚀2.环境变量获取🚀3.main中的命令行参数🎪 进程优先级 每个进程都有相应…...
RocketMQ5.0.0的Broker主从同步机制
目录 一、主从同步工作原理 1. 主从配置 2. 启动HA 二、主从同步实现机制 1. 从Broker发送连接事件 2. 主Broker接收连接事件 3. 从Broker反馈复制进度 4. ReadSocketService线程读取从Broker复制进度 5. WriteSocketService传输同步消息 6. GroupTransferService线程…...

深度学习论文: EdgeYOLO: An Edge-Real-Time Object Detector及其PyTorch实现
深度学习论文: EdgeYOLO: An Edge-Real-Time Object Detector及其PyTorch实现 EdgeYOLO: An Edge-Real-Time Object Detector PDF: https://arxiv.org/pdf/2302.07483.pdf PyTorch代码: https://github.com/shanglianlm0525/CvPytorch PyTorch代码: https://github.com/shangli…...

如何做好APP性能测试?
随着智能化生活的推进,我们生活中不可避免的要用到很多程序app。有的APP性能使用感很好,用户都愿意下载使用,而有的APP总是出现卡顿或网络延迟的情况,那必然就降低了用户的好感。所以APP性能测试对于软件开发方来说至关重要&#…...
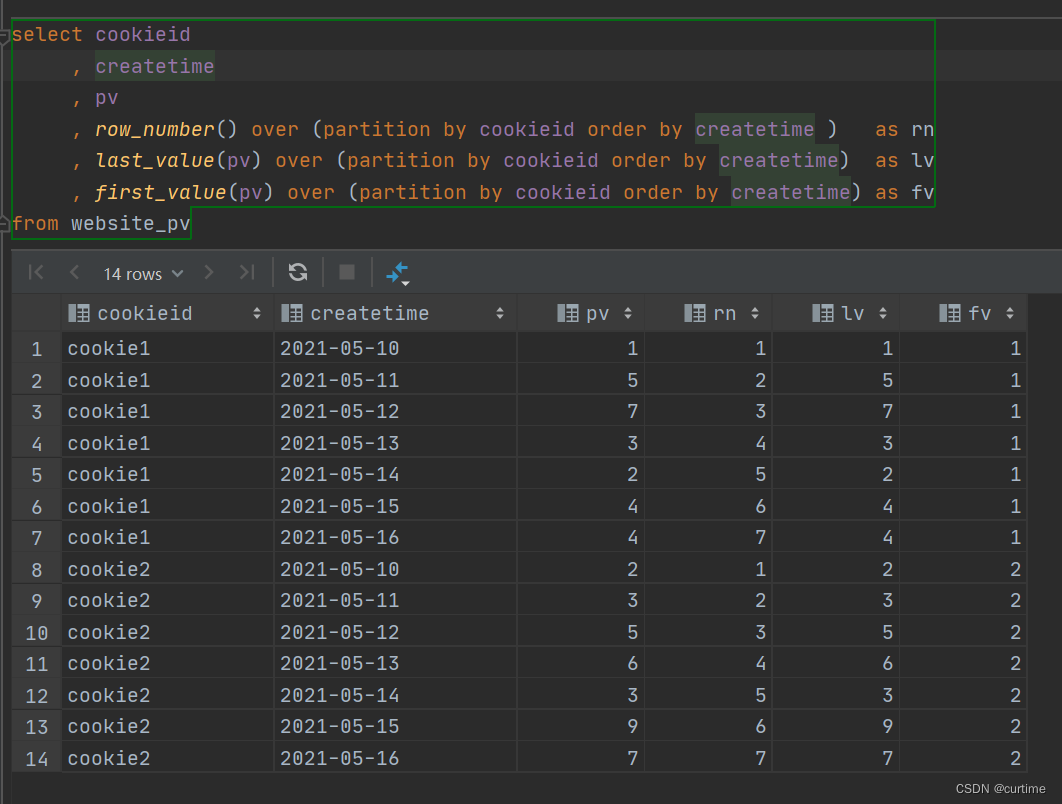
Hive窗口函数
概述 窗口函数(window functions)也叫开窗函数、OLAP函数。 如果函数具有over子句,则它是窗口函数 窗口函数可以简单地解释为类似于聚合函数的计算函数,但是通过group by 子句组合的 常规聚合会隐藏正在聚合的各个…...
:在默认构造函数内部使用带参数的构造函数)
C++学习笔记(1):在默认构造函数内部使用带参数的构造函数
题目以下代码的输出是不是0:#include <unordered_map> #include <iostream>using namespace std;struct CLS{int i;CLS(int i_) :i(i_){}CLS(){CLS(0);} };int main(){CLS obj;std::cout << obj.i << endl;return 0; }结果-858993460为什么…...
设计模式源码案例)
Android面试题_安卓面经(23/30)设计模式源码案例
系列专栏: 《150道安卓常见面试题全解析》 安卓专栏目录见帖子 : 安卓面经_anroid面经_150道安卓基础面试题全解析 安卓系统Framework面经专栏:《Android系统Framework面试题解析大全》 安卓系统Framework面经目录详情:Android系统面经_Framework开发面经_150道面试题答案解…...

Dubbo性能调优参数以及原理
Dubbo作为一个服务治理框架,功能相对来说比较完善,性能也挺不错。但很多同学在使用dubbo的时候,只是简单的参考官方说明进行配置和应用,并没有过多的去思考一些关键参数的意义,最终做出来的效果总是差强人意,接下来我们…...
)
vue3全家桶之vuex和pinia持久化存储基础(二)
一.vuex数据持久化存储 这里使用的是vuex4.1.0版本,和之前的vuex3一样,数据持久化存储方案也使用 vuex-persistedstate,版本是最新的安装版本,当前可下载依赖包版本4.1.0,接下来在vue3项中安装和使用: 安装vuex-persistedstate npm i vuex-persisteds…...
LAMP架构与搭建论坛
目录 1、LAMP架构简述 2、各组件作用 3、构建LAMP平台 1.编译安装Apache httpd服务 2.编译安装mysql 3.编译安装php 4.搭建一个论坛 1、LAMP架构简述 LAMP架构是目前成熟的企业网站应用模式之一,指的是协同工作的一整台系统和相关软件,能够提供动…...

代码随想录 || 回溯算法93 78 90
Day2493.复原IP地址力扣题目链接给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式。有效的 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 . 分隔。例如&#…...
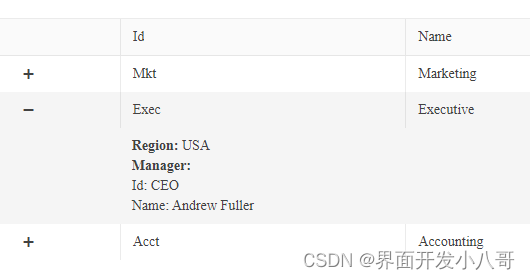
界面组件Kendo UI for Angular——让网格数据信息显示更全面
Kendo UI致力于新的开发,来满足不断变化的需求,通过React框架的Kendo UI JavaScript封装来支持React Javascript框架。Kendo UI for Angular是专用于Angular开发的专业级Angular组件,telerik致力于提供纯粹的高性能Angular UI组件,…...
【Linux】进程状态|优先级|进程切换|环境变量
文章目录1. 运行队列和运行状态2. 进程状态3. 两种特殊的进程僵尸进程孤儿进程4. 进程优先级5. 进程切换进程特性进程切换6. 环境变量的基本概念7. PATH环境变量8. 设置和获取环境变量9. 命令行参数1. 运行队列和运行状态 💕 运行队列: 进程是如何在CP…...
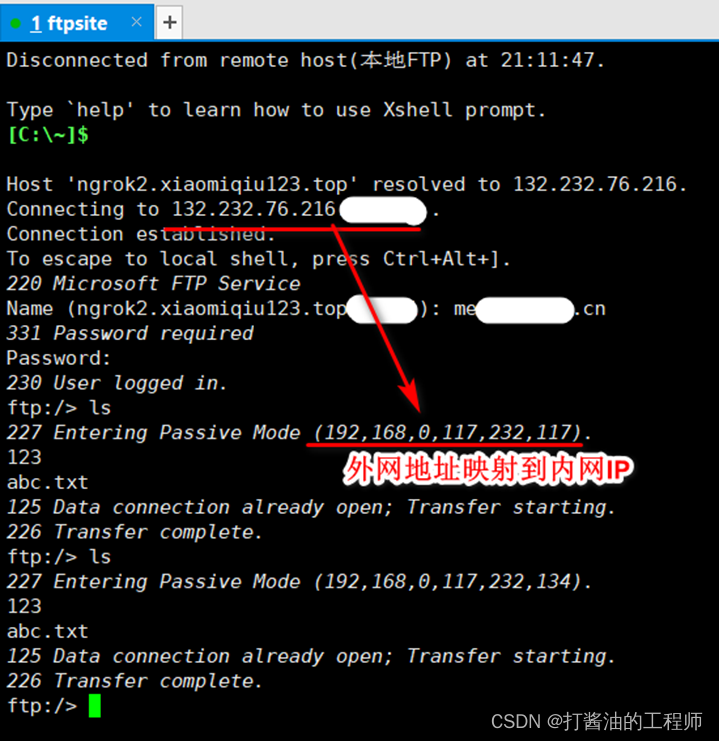
合宙Air780E|FTP|内网穿透|命令测试|LuatOS-SOC接口|官方demo|学习(18):FTP命令及应用
1、FTP服务器准备 本机为win11系统,利用IIS搭建FTP服务器。 搭建方式可参考博文:windows系统搭建FTP服务器教程 windows系统搭建FTP服务器教程_程序员路遥的博客-CSDN博客_windows服务器安装ftp 设置完成后,测试FTP(已正常访问…...
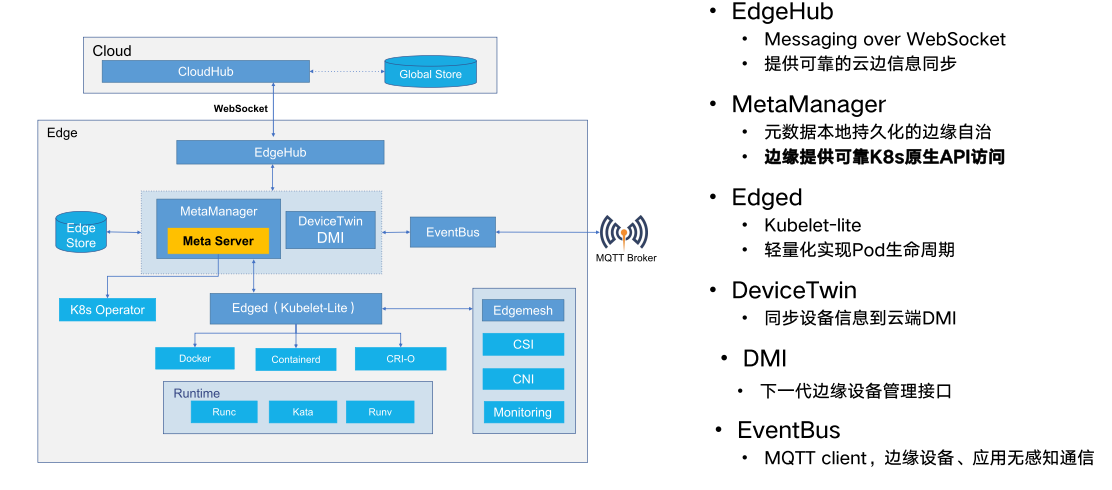
大规模 IoT 边缘容器集群管理的几种架构-4-Kubeedge
前文回顾 大规模 IoT 边缘容器集群管理的几种架构-0-边缘容器及架构简介大规模 IoT 边缘容器集群管理的几种架构-1-RancherK3s大规模 IoT 边缘容器集群管理的几种架构-2-HashiCorp 解决方案 Nomad大规模 IoT 边缘容器集群管理的几种架构-3-Portainer 📚️Reference…...

Spring底层核心原理解析
Spring简介 ClassPathXmlApplicationContext context new classPathXmlApplicationContext("spring.xml"); UserService userService (UserService) context.getBean("userService"); userService.test();上面一段代码是我们开始学习spring时看到的&…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...