【NLP的Python库(04/4)】:Flair

一、说明
Flair是一个现代的NLP库。从文本处理到文档语义,支持所有核心 NLP 任务。Flair使用现代转换器神经网络模型来完成多项任务,并结合了其他Python库,可以选择特定的模型。其清晰的API和注释文本的数据结构,以及多语言支持,使其成为NLP项目的良好候选者。
本文可帮助你开始使用 Flair。安装后,您将学习如何应用文本处理和文本语法任务,然后查看对文本和文档语义的丰富支持。
本文的技术上下文是 和 。所有示例也应该适用于较新的版本。Python v3.11Flair v0.12.2
这篇文章最初出现在我的博客 admantium.com。
二、安装
Flair库可以通过pip安装:
python3 -m pip install flair安装最多可能需要 30 分钟,因为还需要安装其他几个库。此外,在使用序列器、标记器或数据集时,需要下载其他数据。
三、自然语言处理任务
Flair 支持所有核心 NLP 任务,并提供其他功能来创建词向量和训练自定义音序器。
文本处理
- 标记化
- 词形还原
- 句法分块
文本语法
- 词性标记
文本语义
- 语义帧解析
- 命名实体识别
文档语义
- 情绪分析
- 语言毒性分析
此外,Flair 还支持以下附加功能:
- 数据
- 语料库管理
- 文本矢量
- 模型训练
四、文本处理
4.1 标记化
标记化会自动应用于 Flair 中。基本数据结构包装任何长度的文本并生成令牌。Sentence
from flair.data import Sentence# Source: Wikipedia, Artificial Intelligence, https://en.wikipedia.org/wiki/Artificial_intelligence
paragraph = '''Artificial intelligence was founded as an academic discipline in 1956, and in the years since it has experienced several waves of optimism, followed by disappointment and the loss of funding (known as an "AI winter"), followed by new approaches, success, and renewed funding. AI research has tried and discarded many different approaches, including simulating the brain, modeling human problem solving, formal logic, large databases of knowledge, and imitating animal behavior. In the first decades of the 21st century, highly mathematical and statistical machine learning has dominated the field, and this technique has proved highly successful, helping to solve many challenging problems throughout industry and academia.'''doc = Sentence(paragraph)
tokens = [token for token in doc]print(tokens)
# [Token[0]: "Artificial", Token[1]: "intelligence", Token[2]: "was", Token[3]: "founded", Token[4]: "as", Token[5]: "an", Token[6]: "academic", Token[7]: "discipline",4.2 词性标记
检测文本中额外的句法(和语义)信息涉及使用,一种特定于Flair的数据结构,它结合了预定义的转换器模型用于特定任务。Classifiers
对于POS标签,Flair提供了14种不同的型号,支持英语,德语,葡萄牙语和更多语言。
基本的英语语言分类器定义了以下类型:pos
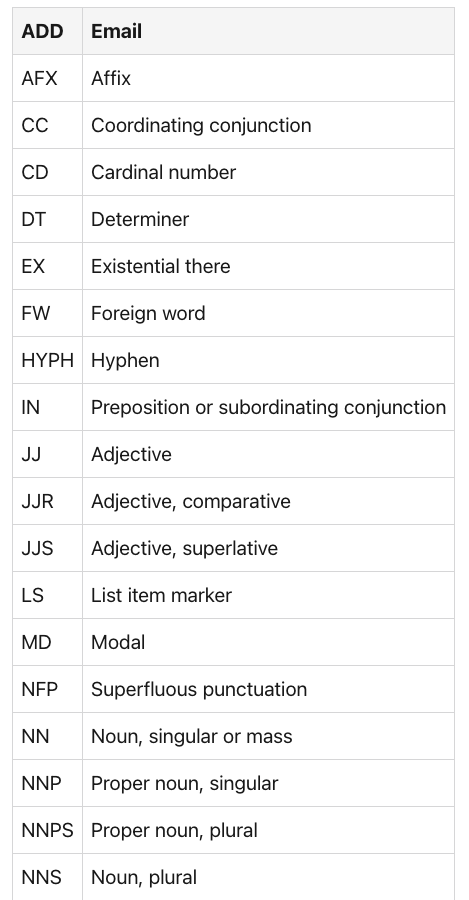
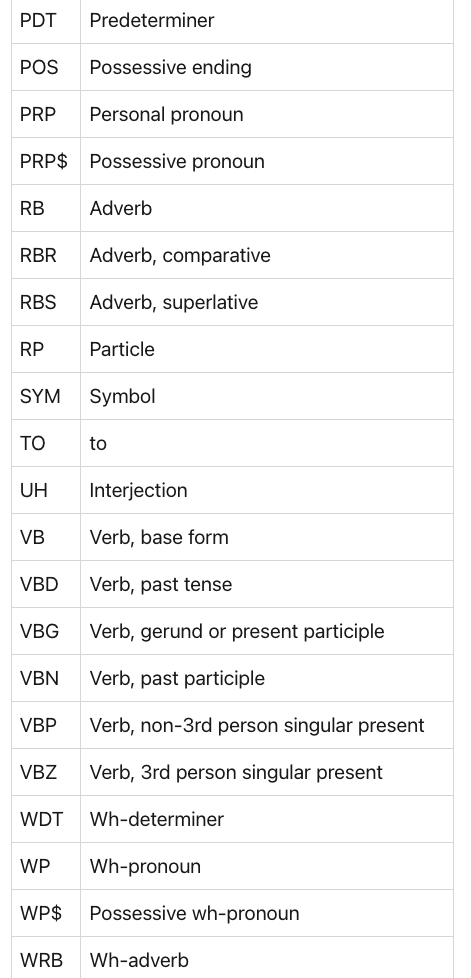
The following snippet shows how to use the POS sequencer:
from flair.data import Sentence
from flair.nn import Classifierpos = Classifier.load('pos')
# SequenceTagger predicts: Dictionary with 53 tags: <unk>, O, UH, ,, VBD, PRP, VB, PRP$, NN, RB, ., DT, JJ, VBP, VBG, IN, CD, NNS, NNP, WRB, VBZ, WDT, CC, TO, MD, VBN, WP, :, RP, EX, JJR, FW, XX, HYPH, POS, RBR, JJS, PDT, NNPS, RBS, AFX, WP$, -LRB-, -RRB-, ``, '', LS, $, SYM, ADDdoc = Sentence(paragraph)
pos.predict(doc)print(doc.to_tagged_string())
# ["Artificial"/JJ,
# "intelligence"/NN,
# "was"/VBD,
# "founded"/VBN,
# "as"/IN,
# "an"/DT,
# "academic"/JJ,4.3 句法分块
分块是提取具有不同含义的连贯标记集的过程,例如名词短语、介词短语、形容词短语等。
分类器用于此任务。下面是一个示例:chunk
from flair.data import Sentence
from flair.nn import Classifierchunk = Classifier.load('chunk')
# SequenceTagger predicts: Dictionary with 47 tags: O, S-NP, B-NP, E-NP, I-NP, S-VP, B-VP, E-VP, I-VP, S-PP, B-PP, E-PP, I-PP, S-ADVP, B-ADVP, E-ADVP, I-ADVP, S-SBAR, B-SBAR, E-SBAR, I-SBAR, S-ADJP, B-ADJP, E-ADJP, I-ADJP, S-PRT, B-PRT, E-PRT, I-PRT, S-CONJP, B-CONJP, E-CONJP, I-CONJP, S-INTJ, B-INTJ, E-INTJ, I-INTJ, S-LST, B-LST, E-LST, I-LST, S-UCP, B-UCP, E-UCP, I-UCP, <START>, <STOP>doc = Sentence(paragraph)
chunk.predict(doc)print(doc.to_tagged_string())
# ["Artificial intelligence"/NP,
# "was founded"/VP,
# "as"/PP,
# "an academic discipline"/NP,
# "in"/PP,
# "1956"/NP,
# "and"/PP,
# "in"/PP,
# "the years"/NP,五、文本语义
5.1 语义帧解析
语义框架是一种 NLP 技术,它用其语义含义标记标记序列。这有助于确定句子的情绪和主题。
和以前一样,语义框架是通过加载特定的分类器来使用的。尽管此功能被标记为实验性功能,但在撰写本文时使用 时,它运行良好。flair v0.12.2
frame = Classifier.load('frame')
# SequenceTagger predicts: Dictionary with 4852 tags: <unk>, be.01, be.03, have.01, say.01, do.01, have.03, do.02, be.02, know.01, think.01, come.01, see.01, want.01, go.02, ...doc = Sentence(paragraph)
frame.predict(doc)
print(doc.to_tagged_string())
# ["was"/be.03, "founded"/found.01, "has"/have.01, "experienced"/experience.01, "waves"/wave.04, "followed"/follow.01, "disappointment"/disappoint.01,5.2 命名实体识别
命名实体是句子中的人物、地点或日期。Flair提供不同的NER模型。
让我们将默认值与较大的.nerner-ontonotes-fast
#Source: Wikipedia, Artificial Intelligence, https://en.wikipedia.org/wiki/Artificial_intelligence
paragraph = '''
In 2011, in a Jeopardy! quiz show exhibition match, IBM's question answering system, Watson, defeated the two greatest Jeopardy! champions, Brad Rutter and Ken Jennings, by a significant margin.
'''ner = Classifier.load('ner')
# SequenceTagger predicts: Dictionary with 20 tags: <unk>, O, S-ORG, S-MISC, B-PER, E-PER, S-LOC, B-ORG, E-ORG, I-PER, S-PER, B-MISC, I-MISC, E-MISC, I-ORG, B-LOC, E-LOC, I-LOC, <START>, <STOP>doc = Sentence(paragraph)
ner.predict(doc)print(doc.get_spans('ner'))
# [Span[5:7]: "Jeopardy!" → MISC (0.5985)
# Span[12:13]: "IBM" → ORG (0.998)
# Span[18:19]: "Watson" → PER (1.0)
# Span[28:30]: "Brad Rutter" → PER (1.0)
# Span[31:33]: "Ken Jennings" → PER (0.9999)] 通过该模型,所有人员和组织都得到认可。ner
ner = Classifier.load('ner-ontonotes-fast')
# SequenceTagger predicts: Dictionary with 75 tags: O, S-PERSON, B-PERSON, E-PERSON, I-PERSON, S-GPE, B-GPE, E-GPE, I-GPE, S-ORG, B-ORG, E-ORG, I-ORG, S-DATE, B-DATE, E-DATE, I-DATE, S-CARDINAL, B-CARDINAL, E-CARDINAL, I-CARDINAL, S-NORP, B-NORP, E-NORP, I-NORP, S-MONEY, B-MONEY, E-MONEY, I-MONEY, S-PERCENT, B-PERCENT, E-PERCENT, I-PERCENT, S-ORDINAL, B-ORDINAL, E-ORDINAL, I-ORDINAL, S-LOC, B-LOC, E-LOC, I-LOC, S-TIME, B-TIME, E-TIME, I-TIME, S-WORK_OF_ART, B-WORK_OF_ART, E-WORK_OF_ART, I-WORK_OF_ART, S-FACdoc = Sentence(paragraph)
ner.predict(doc)print(list(doc.get_labels()))
# [Span[1:2]: "2011"'/'DATE' (0.9984)
# Span[12:13]: "IBM"'/'ORG' (1.0)
# Span[18:19]: "Watson"'/'PERSON' (0.9913)
# Span[22:23]: "two"'/'CARDINAL' (0.9995)
# Span[24:25]: "Jeopardy"'/'WORK_OF_ART' (0.938)
# Span[28:30]: "Brad Rutter"'/'PERSON' (0.9939)
# Span[31:33]: "Ken Jennings"'/'PERSON' (0.9914)]用、数字、日期甚至危险被识别。ner-ontonotes-fast
六、文档语义
6.1 情绪分析
Flair的情感分析通常应用于句子,但通过将整个文本包装在数据结构中,它也可以应用于整个文本。它将输出句子的正或负的二元分类。Sentence
#Source: Wikipedia, Artificial Intelligence,https://en.wikipedia.org/wiki/Artificial_intelligence
sentiment = Classifier.load('sentiment')doc = Sentence(paragraph)
sentiment.predict(doc)
print(doc)
# Sentence[124]: "Artificial intelligence was founded ..." → POSITIVE (0.9992)6.2 语言毒性分析
Flair提供了一个检测语言毒性的模型,但只有德语版本。它是在可从海德堡大学下载的特定数据集上进行训练的,
以下代码片段检测攻击性语言的用法。
paragraph = '''
Was für Bullshit.
'''toxic_language = Classifier.load('de-offensive-language')
doc = Sentence(paragraph)
toxic_language.predict(doc)print(list(doc.get_lables()))
# Sentence[16]: "Was für Bullshit." → OFFENSE (0.9772)七、附加属性
7.1 Datasets
Flair includes several datasets and corpus, see the complete list.
其中一些数据集用于训练特定于 Flair 的任务的模型,例如 NER 或关系提取。其他数据集是GLUE语言基准和文本集合。
下面是一个如何加载文本分类数据集以检测 Reddit 帖子中的情绪的示例。
import flair.datasetsdata = flair.datasets.GO_EMOTIONS()len(data.train)
# 43410data.train[42000]
# This is quite common on people on such forums. I have a feeling they are a tad sarcastic." → APPROVAL (1.0); NEUTRAL (1.0)7.1 语料库管理
在 Flair 中,对象表示为训练新的标记器或分类器而准备的文档。此对象由名为 和 的树不同集合组成,每个集合都包含 Sentence 对象。Corpustraindevtest
7.2 文本矢量
Flair 支持不同的矢量化方案:启用预训练的词向量(如手套)和来自不同转换器模型的词向量,通过转换器库加载。
让我们看看如何使用这两种方法标记段落。
from flair.embeddings import WordEmbeddingsembeddings = WordEmbeddings('glove')
doc = Sentence(paragraph)
embeddings.embed(doc)
for token in doc:print(token)print(token.embedding)# Token[0]: "Artificial"
# tensor([ 0.3455, 0.3144, -0.0313, 0.6368, 0.2727, -0.6197, -0.5177, -0.2368,
# -0.0166, 0.0344, -0.1542, 0.0435, 0.7298, 0.1112, 1.3430, ...,
# Token[1]: "intelligence"
# tensor([-0.3110, -0.4329, 0.7773, -0.3112, 0.0529, -0.8502, -0.3537, -0.7053,
# 0.0845, 0.8877, 0.8353, -0.4164, 0.3670, 0.6083, 0.0085, ...,对于转换器嵌入:
from flair.embeddings import TransformerWordEmbeddingsembedding = TransformerWordEmbeddings('bert-base-uncased')
doc = Sentence(paragraph)
embedding.embed(doc)
for token in doc:print(token)print(token.embedding)# Token[0]: "Artificial"
# tensor([ 1.0723e-01, 9.7490e-02, -6.8251e-01, -6.4322e-02, 6.3791e-01,
# 3.8582e-01, -2.0940e-01, 1.4441e-01, 2.4147e-01, ...)
# Token[1]: "intelligence"
# tensor([-9.9221e-02, -1.9465e-01, -4.9403e-01, -4.1582e-01, 1.4902e+00,
# 3.6126e-01, 3.6648e-01, 3.7578e-01, -4.8785e-01, ...)此外,可以使用文档嵌入对完整文档进行矢量化,而不是单个标记。
7.3 模型训练
Flair 包括用于训练可用作序列标记器或文本分类器的新模型的函数。它提供数据集的加载、模型定义、训练配置和执行。对于大多数这些步骤,使用转换器库。
下面是官方文档中的一个示例,用于在康奈尔语料库上训练用于词性标记的模型。
# Source: FlairNLP, How model Training works in Flair, https://flairnlp.github.io/docs/tutorial-training/how-model-training-works#example-training-a-part-of-speech-taggerfrom flair.datasets import UD_ENGLISH
from flair.embeddings import WordEmbeddings
from flair.models import SequenceTagger
from flair.trainers import ModelTrainer# 1. load the corpus
corpus = UD_ENGLISH().downsample(0.1)
print(corpus)
#Corpus: 1254 train + 200 dev + 208 test sentences# 2. what label do we want to predict?
label_type = 'upos'# 3. make the label dictionary from the corpus
label_dict = corpus.make_label_dictionary(label_type=label_type)
print(label_dict)
# Dictionary created for label 'upos' with 18 values: NOUN (seen 3642 times), VERB (seen 2375 times), PUNCT (seen 2359 times), ADP (seen 1865 times), PRON (seen 1852 times), DET (seen 1721 times), ADJ (seen 1321 times), AUX (seen 1269 times), PROPN (seen 1203 times), ADV (seen 1083 times), CCONJ (seen 700 times), PART (seen 611 times), SCONJ (seen 405 times), NUM (seen 398 times), INTJ (seen 75 times), X (seen 63 times), SYM (seen 60 times)# 4. initialize embeddings
embeddings = WordEmbeddings('glove')# 5. initialize sequence tagger
model = SequenceTagger(hidden_size=256,embeddings=embeddings,tag_dictionary=label_dict,tag_type=label_type)
print(model)
# Model: "SequenceTagger(
# (embeddings): WordEmbeddings(
# 'glove'
# (embedding): Embedding(400001, 100)
# )
# (word_dropout): WordDropout(p=0.05)
# (locked_dropout): LockedDropout(p=0.5)
# (embedding2nn): Linear(in_features=100, out_features=100, bias=True)
# (rnn): LSTM(100, 256, batch_first=True, bidirectional=True)
# (linear): Linear(in_features=512, out_features=20, bias=True)
# (loss_function): ViterbiLoss()
# (crf): CRF()
# )"# 6. initialize trainer
trainer = ModelTrainer(model, corpus)# 7. start training
trainer.train('resources/taggers/example-upos',learning_rate=0.1,mini_batch_size=32,max_epochs=10)
# Parameters:
# - learning_rate: "0.100000"
# - mini_batch_size: "32"
# - patience: "3"
# - anneal_factor: "0.5"
# - max_epochs: "10"
# - shuffle: "True"
# - train_with_dev: "False"
# epoch 1 - iter 4/40 - loss 3.12352573 - time (sec): 1.06 - samples/sec: 2397.20 - lr: 0.100000
# ...
# epoch 1 - iter 4/40 - loss 3.12352573 - time (sec): 1.06 - samples/sec: 2397.20 - lr: 0.100000
# Results:
# - F-score (micro) 0.7877
# - F-score (macro) 0.6621
# - Accuracy 0.7877
# By class:
# precision recall f1-score support
# NOUN 0.7231 0.8495 0.7812 412
# PUNCT 0.9082 0.9858 0.9454 281
# VERB 0.7048 0.7403 0.7221 258
# PRON 0.9070 0.8986 0.9028 217
# ADP 0.8377 0.8791 0.8579 182
# DET 1.0000 0.8757 0.9338 169
# ADJ 0.6087 0.6490 0.6282 151
# PROPN 0.7538 0.5568 0.6405 176
# AUX 0.8077 0.8678 0.8367 121
# ADV 0.5446 0.4661 0.5023 118
# CCONJ 0.9880 0.9425 0.9647 87
# PART 0.6825 0.8600 0.7611 50
# NUM 0.7368 0.5000 0.5957 56
# SCONJ 0.6667 0.3429 0.4528 35
# INTJ 1.0000 0.4167 0.5882 12
# SYM 0.5000 0.0833 0.1429 12
# X 0.0000 0.0000 0.0000 9
# accuracy 0.7877 2346
# macro avg 0.7276 0.6420 0.6621 2346
# weighted avg 0.7854 0.7877 0.7808 2346八、总结
Flair 是一个现代 NLP 库,支持所有核心 NLP 任务。本文介绍了如何应用文本处理、文本语法、文本语义和文档语义任务。Flair 的显著特点是它对选定任务的多语言支持,例如命名实体识别和词性标记,以及它对转换器神经网络的使用。此外,还存在用于模型训练的完整功能集,从训练数据准备、模型和训练配置到训练执行和指标计算。
相关文章:
【NLP的Python库(04/4)】:Flair
一、说明 Flair是一个现代的NLP库。从文本处理到文档语义,支持所有核心 NLP 任务。Flair使用现代转换器神经网络模型来完成多项任务,并结合了其他Python库,可以选择特定的模型。其清晰的API和注释文本的数据结构,以及多语言支持&a…...

Vue框架学习大纲
Vue.js 是一个构建用户界面的框架,尤其是单页面应用。以下是一些主要基于 Vue 2.x 的版本必须了解的 Vue.js基本知识点和特性: Vue 实例: 创建一个 Vue 实例是开始使用 Vue 的第一步。 var vm new Vue({// 选项 });数据绑定: Vue 提供了非常直观的数据绑…...
利用PPT导出一张高清图的方法,office与WPS只需要使用一个即可,我使用的是office。
利用PPT导出一张高清图的方法,office与WPS只需要使用一个即可,我使用的是office。 1,PPT的功能拓展来解决导出高清图片方法1.1,PPT功能拓展—>安装插件: 2,各种方法导出图片效果显示:2.1&…...

2023年【四川省安全员B证】最新解析及四川省安全员B证模拟考试
题库来源:安全生产模拟考试一点通公众号小程序 四川省安全员B证最新解析考前必练!安全生产模拟考试一点通每个月更新四川省安全员B证模拟考试题目及答案!多做几遍,其实通过四川省安全员B证模拟考试题很简单。 1、【多选题】5.5kW…...

某瑞集团安全技术研发岗位面试
本文由掌控安全学院 - sbhglqy 投稿 一、自我介绍 阿吧阿吧,不多说 二、就ctf比赛经历方面提些问题 面试官:ctf打了多久了 我:两三年了。 面试官:得过什么奖项没有 我:本科的时候得过一个校一等奖。 面试官&#x…...
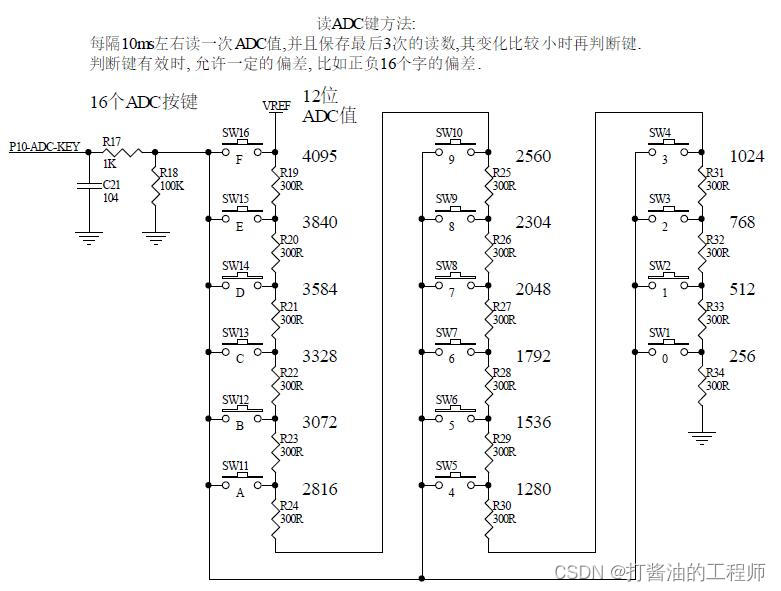
学习笔记|ADC反推电源电压|扫描按键(长按循环触发)|课设级实战练习|STC32G单片机视频开发教程(冲哥)|第十八集:ADC实战
文章目录 1.ADC反推电源电压测出Vref引脚电压的意义?手册示例代码分析复写手册代码Tips:乘除法与移位关系为什么4096后面还有L 2.ADC扫描按键(长按循环触发)长按触发的实现 3.实战小练1.初始状态显示 00 - 00 - 00,分别作为时,分,…...

2020 款凯迪拉克 XT5 车发动机加速异响
故障现象 一辆2020款凯迪拉克XT5车,搭载LSY发动机,累计行驶里程约为8万km。车主反映,加速时发动机有明显异响。 故障诊断 接车后试车,起动发动机,发动机怠速运转平稳;打开发动机室盖,能够听到轻…...

【AI视野·今日CV 计算机视觉论文速览 第255期】Wed, 27 Sep 2023
AI视野今日CS.CV 计算机视觉论文速览 Wed, 27 Sep 2023 (showing first 100 of 103 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers Generating Visual Scenes from Touch Authors Fengyu Yang, Jiacheng Zhang, Andre…...
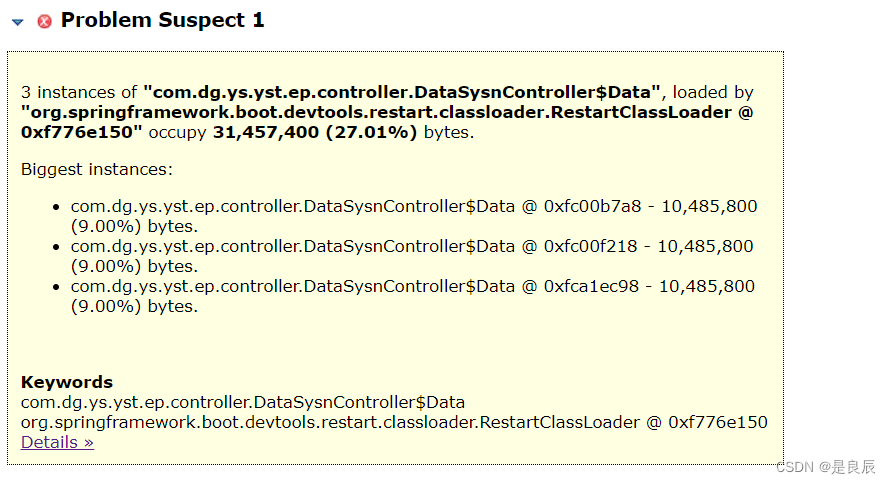
Java应用生产Full GC或者OOM问题如何定位
1 引言 生产应用服务频繁Full GC却无法释放内存,甚至可能OOM,这种情况很有可能是内存泄露或者堆内存分配不足,此时需要dump堆信息来定位问题,查看是哪些地方内存泄漏。 Dump文件也称为内存转储文件或内存快照文件,是…...

Data processing flow
1. 找出第一年的address,有lat和long,自动生成 csv_log_lat_county.ipynb import csv from geopy.geocoders import Nominatim from geopy.exc import GeocoderTimedOutgeolocator Nominatim(user_agent"my-app") data_csv r"D:/year…...

CAP理论与BASE理论
分布式领域CAP理论: Consistency(一致性), 数据一致更新,所有数据变动都是同步的Availability(可用性), 好的响应性能Partition tolerance(分区容错性) 可靠性定理:任何分布式系统只可同时满足二点,没法三者兼顾。忠告࿱…...
)
DRM全解析 —— ADD_FB2(3)
接前一篇文章:DRM全解析 —— ADD_FB2(2) 本文参考以下博文: DRM驱动(四)之ADD_FB 特此致谢! 上一回围绕libdrm与DRM在Linux内核中的接口: DRM_IOCTL_DEF(DRM_IOCTL_MODE_ADDFB2,…...

【Java】SpringMVC ResponseBodyAdvice详解
目录 1. ResponseBodyAdvice 2. supports方法 3. beforeBodyWrite方法 4. 实践 1. ResponseBodyAdvice Spring MVC的ResponseBodyAdvice是Spring 4.1版本中引入的一个接口,它允许在Controller控制器中ResponseBody修饰的方法或ResponseEntity执行之后ÿ…...

python常见面试题五
解释 Python 中的列表推导式 (list comprehension)。 答:列表推导式是一种创建新列表的简洁方式。它可以在一行代码中通过对一个可迭代对象应用表达式和条件来生成新的列表。 解释 Python 中的时间复杂度和空间复杂度。 答:时间复杂度衡量算法运行时间的…...
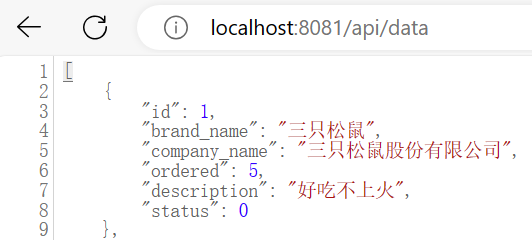
SpringBoot结合Vue.js+axios框架实现增删改查功能+网页端实时显示数据库数据(包括删除多条数据)
本文适用对象:已有基础的同学,知道基础的SpringBoot配置和Vue操作。 在此基础上本文实现基于SpringBoot和Vue.js基础上的增删改查和数据回显、刷新等。 一、实时显示数据库数据 实现步骤: 第1步:编写动态请求响应类:…...

曙光亮相工博会,发布首款国产高端工业实时仿真计算系统
9月19日-23日,中科曙光亮相第23届中国国际工业博览会,并受邀于主论坛发表主题演讲,在工业权威会议上展示曙光领先的工业数字化技术与实践成果。展会期间,曙光重磅发布首款国产工业实时仿真计算系统,并展出多项工业数字…...
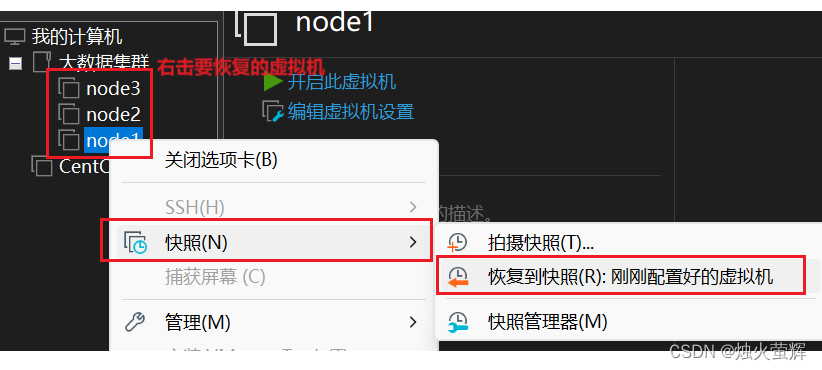
「大数据-2.0」安装Hadoop和部署HDFS集群
目录 一、下载Hadoop安装包 二、安装Hadoop 0. 安装Hadoop前的必要准备 1. 以root用户登录主节点虚拟机 2. 上传Hadoop安装包到主节点 3. 解压缩安装包到/export/server/目录中 4. 构建软链接 三、部署HDFS集群 0. 集群部署规划 1. 进入hadoop安装包内 2 进入etc目录下的hadoop…...
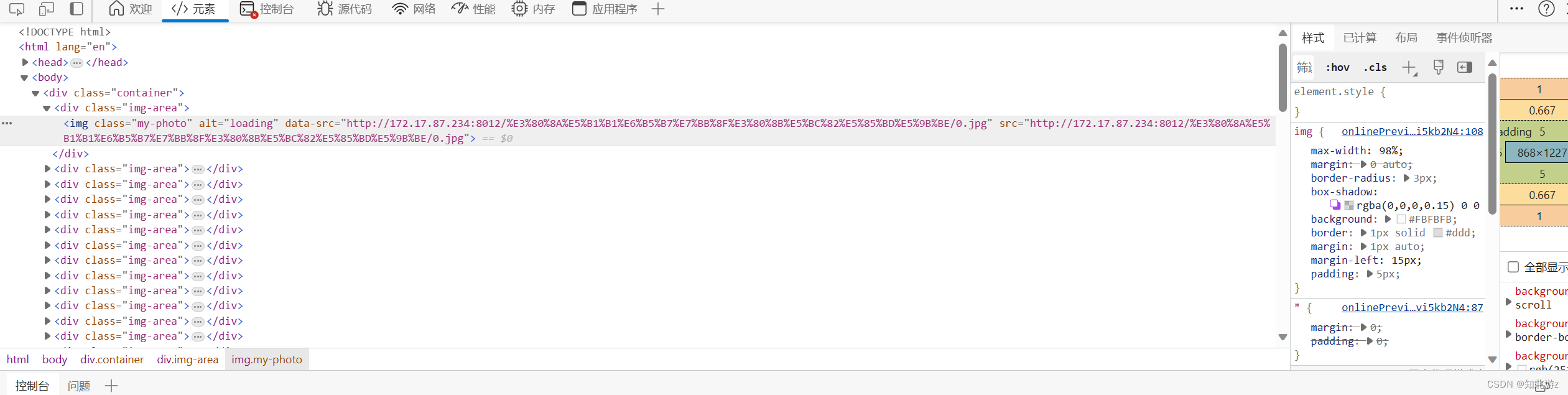
文档在线预览word、pdf、excel文件转html以实现文档在线预览
目录 一、前言 1、aspose2 、poi pdfbox3 spire二、将文件转换成html字符串 1、将word文件转成html字符串 1.1 使用aspose1.2 使用poi1.3 使用spire2、将pdf文件转成html字符串 2.1 使用aspose2.2 使用 poi pbfbox2.3 使用spire3、将excel文件转成html字符串 3.1 使用aspose…...

FFmpeg视音频分离器----向雷神学习
雷神博客地址:https://blog.csdn.net/leixiaohua1020/article/details/39767055 本程序可以将封装格式中的视频码流数据和音频码流数据分离出来。 在该例子中, 将FLV的文件分离得到H.264视频码流文件和MP3 音频码流文件。 注意: 这个是简化版…...

CentOS 8开启bbr
CentOS 8 默认内核版本为 4.18.x,内核版本高于4.9 就可以直接开启 BBR,所以CentOS 8 启用BBR非常简单不需要再去升级内核。 开启bbr echo "net.core.default_qdiscfq" >> /etc/sysctl.conf echo "net.ipv4.tcp_congestion_contro…...
)
离散数学实战:用Python解决图论问题(附完整代码示例)
离散数学实战:用Python解决图论问题(附完整代码示例) 当你在社交软件上查看"可能认识的人"推荐,或是用导航软件规划最短路线时,背后都在运行图论算法。作为离散数学中最具工程价值的领域,图论将现…...

CTF是什么?一文带你读懂网络安全大赛
CTF是什么?一文带你读懂网络安全大赛 前言 随着大数据、人工智能的发展,人们步入了新的时代,逐渐走上科技的巅峰。 科技是一把双刃剑,网络安全不容忽视,人们的隐私在大数据面前暴露无遗,账户被盗、资金损失…...

OpenClaw安全方案:nanobot本地模型的数据隐私保护实践
OpenClaw安全方案:nanobot本地模型的数据隐私保护实践 1. 为什么选择本地化部署 去年夏天,我接手了一个特殊项目——为一家小型会计师事务所设计自动化财务文档处理方案。最初考虑使用云端AI服务时,客户明确提出了数据隐私的硬性要求&#…...

基于设备树与内核中断的125KHZ RFID曼彻斯特码实时解码实践
1. 曼彻斯特码解码原理详解 125KHz RFID系统广泛用于门禁、物流追踪等场景,其数据传输采用曼彻斯特编码方式。这种编码最大的特点是每个数据位都包含电平跳变,使得时钟恢复变得简单。具体来说,EM4100卡片每传送一位数据需要64个载波周期&…...

轻量级百度搜索结果获取解决方案:让数据获取不再复杂
轻量级百度搜索结果获取解决方案:让数据获取不再复杂 【免费下载链接】python-baidusearch 自己手写的百度搜索接口的封装,pip安装,支持命令行执行。Baidu Search unofficial API for Python with no external dependencies 项目地址: http…...

RPA-Python与pytest-arangodb集成:10步实现ArangoDB测试自动化完整指南
RPA-Python与pytest-arangodb集成:10步实现ArangoDB测试自动化完整指南 【免费下载链接】RPA-Python Python package for doing RPA 项目地址: https://gitcode.com/gh_mirrors/rp/RPA-Python RPA-Python是一个强大的Python机器人流程自动化工具包࿰…...

如何用WechatFerry构建企业级微信自动化解决方案
如何用WechatFerry构建企业级微信自动化解决方案 【免费下载链接】wechatferry 基于 WechatFerry 的微信机器人底层框架 项目地址: https://gitcode.com/gh_mirrors/wec/wechatferry 一、场景化价值:从业务痛点到自动化突破 在数字化转型加速的今天…...

别再让AI芯片‘睡大觉’了:手把手教你用华为昇腾+CANN搞定异构算力调度
华为昇腾CANN实战:破解AI芯片利用率困局的5个关键策略 推开实验室玻璃门,迎面是十几台Atlas 800服务器闪烁的指示灯,而工程师小王正对着监控大屏上30%的平均利用率皱眉——这场景在采用国产AI芯片的团队中太常见了。当我们谈论异构算力调度时…...
)
保姆级教程:用Cloudreve+Obsidian打造私人云笔记(附WebDAV配置避坑指南)
零基础构建私有知识库:Cloudreve与Obsidian的完美联姻 在信息爆炸的时代,如何高效管理个人知识资产已成为现代人的刚需。想象一下:你正在咖啡馆用iPad记录灵感,回到家打开电脑时这些想法已自动同步;出差途中用手机查阅…...

3步完成Logisim-evolution开源工具安装:跨平台数字电路设计效率指南
3步完成Logisim-evolution开源工具安装:跨平台数字电路设计效率指南 【免费下载链接】logisim-evolution Digital logic design tool and simulator 项目地址: https://gitcode.com/gh_mirrors/lo/logisim-evolution 引言:开启数字电路设计的高效…...