Python爬虫教程——解析网页中的元素
前言:
嗨喽~大家好呀,这里是小曼呐 ~

在我们理解了网页中标签是如何嵌套,以及网页的构成之后,
我们就是可以开始学习使用python中的第三方库BeautifulSoup筛选出一个网页中我们想要得到的数据。
接下来我们了解一下爬取网页信息的步骤。
一、基本步骤
想要获得我们所需的数据分三步
使用BeautifulSoup解析网页
Soup = BeautifulSoup(html,‘lxml’)
描述想要爬去信息的东西在哪里。
信息 = Soup.select(‘???’)
要知道它叫什么名字,如何去定位。
从标签中获得你想要的信息
<p>Something</p> 从标签中获取我们需要的信息,去掉一些没有用的结构,
并且把我们获取的信息按照一定格式装在数据容器中,方便我们去查询。
二、两种路径获得方式详解
接下来,我们首先进行第一步,如何使用BeautifulSoup解析网页
Soup = BeautifulSoup(html,'lxml')
实际上我们构造一个解析文件需要一个网页文件和解析查询库。
就好比左边的Soup是汤,html是汤料,而lxml是食谱。
今天我们需要讲的BeautifulSoup,通过我们告诉它元素的具体的位置,就可以向他指定我们想要爬去的信息。
找到相应的元素右键检查的,看到元素的代码信息进行右击,我们有两种方式获得标签的位置的具体描述方式
1.使用copy selector
2.使用copy XPath
这两种复制的路径有什么区别,接下来就让大家看一下
右键标签copy selector复制出来的路径
body > div.body-wrapper > div.content-wrapper > div > div.main-content > div:nth-child(15) > a
右键标签copy XPath复制出来的路径
'''
完整源码、解答、教程皆+VX:Python10010验证码“M”获取
'''
/html/body/div[4]/div[2]/div/div[2]/div[14]/a
这两种不同的路径描述方式,使用copy selector复制出来的路径叫做 CSS Selector,使用copy XPath复制出来的叫做XPath。
这两种路径的描述方式在今后的学习中我们都可以用的到,但是我们今天要学习的BeautifulSoup它只认第一种,就是CSS Selector。
但是为了方便我们以后的学习,更好认识网页间不同元素的结构,我们先讲一下XPath,在学习了它之后,CSS Selector也会更好的理解,同时日后我们需要学习的一些库也需要用到XPath去描述一些元素的位置。
XPath
1.什么是XPath
Xpath使用路径表达式在XML文档中进行导航,解析到路径跟踪到的XML元素。
2.XPath路径表达式
路径表达式是xpath的传入参数,xpath使用路径表达式对XML文档中的节点(或者多个节点)进行定位。
路径表达式类似这种:/html/body/div[4]/div[2]/div/div[2]/div[14]/a 或者 /html/body/div[@class=”content”] ,其中第二个路径中的[@class=”content”] 是为了在多个相同标签中定位到一个标签。
刚才拿到的那个XPath的路径 /html/body/div[4]/div[2]/div/div[2]/div[14]/a,就针对于这一串来讲,拿到的这个元素的完整路径,叫做绝对路径,其中每个‘/’就是一个节点,
下面我们通过这个结构图我们可以简单了解一下。
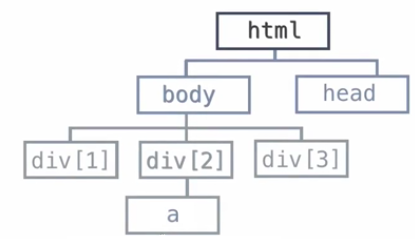
为了更清楚地了解各个节点之间的关系,通过下面的图片我们可以更直观的了解。
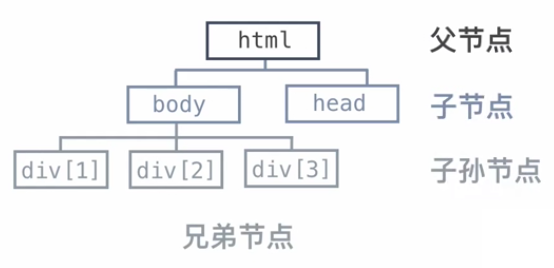
html是父节点相对于下面的节点是父节点,下面的body和head相对于html是是子节点,div标签相对于html标签是子孙节点。
其中body又相当于div标签的子节点,div标签之间是兄弟节点,基本的结构以及等级就是这样。
CSS Selector
1.什么是CSS Selector
Css Selector定位实际就是HTML的Css选择器的标签定位。
顾名思义CSS selector就是一种按照样式进行选择的一种标签选择方式。
2.CSS Selector路径表达式
在css selector路径中,最开始的路径是body,不像是XPath中最开始的是html,我们拿到刚才的那个路径看一下。
body > div.body-wrapper > div.content-wrapper > div > div.main-content > div:nth-child(15) > a
在这个路径中,在第一个div后面加了一个.body-wrapper,这个就是这个标签的样式,这种选择方式是按照样式进行选择的。
如果说XPath的路径是按照:谁,在哪,第几个的选择方式
那么CSS Selector是按照:谁,在哪,第几个,长什么样子进行选择
三、使用python代码爬取网页信息
通过刚才我们队网页中各种元素的路径认识之后,我们就可以简单的使用python的BeautifulSoup库进行代码级别实现网页信息爬取,废话不多说,直接上代码。
这里是爬去信息的网页就使用之前我进行联系的网页,网页源码的地址在:
打开本地网页的方式建议使用pycharm中新建一个html文件将源代码复制进去,如果使用自带的记事本需要把保存格式改为utf-8。
'''
完整源码、解答、教程皆+VX:Python10010验证码“M”获取
'''
import requests
from bs4 import Beautifulsoup as bs
#1.使用Beautifulsoup解析网页
with open('./ddw.html','r',encoding='utf-8') as wb data:
#我使用的是本地文件所以使用open函数打开本地路径下面的网页
Soup = bs(wb data,"1xml 这里构造的是解析文件,w data是我们要解析的网页,1xm1是解析库
# images = Soupselect( body ) diy:nth-child(2) > div.body > div.body moth > div:nth-child(6) > div:nth-child(1) > img
#这里使用Soup的方法,直接在select后面括号里添加相应的路径就可以。在这里就拿到图片的信息
#但是这行代码会有出错信息,我们只需按照出错信息中的处理方式进行修改即可
images = Soup.select(
'body > div:nth-of-type(2) > div.body > div.body moth > div > div:nth-of-type(1) > img
#通过上面那一行代码我们拿到了正确的图片信息,不过们把其倒数二个div的标签的CSs样式删除,这样就不再定位到单个图片,
#就直接把所有同类型的图片筛选出来,为什么要删倒数第
个div的css样式,因为这个div标签的兄弟标签是其他图片标签的父标签
titles = Soup.select('body ) div:nth-of-type(2) > divhead top ) div.head top ee ) ul > li > a'
#再童到这网页中的标题信息,同样的为了皇到所有的同类标题标签,根据位置信息删除1i标签的C55样式
# print(images,titles,sep=' r-.
I1131
for image,title in zip(images,titles):
data = !
"image': image.get( 'src')
'title': title.get text().
print(data)
到这里,简单的网页信息爬取就完成了,我们通过这串代码拿到了网页中商品图片的地址,以及网页中分类标签,这次仅仅进行简单信息的爬取
尾语
最后感谢你观看我的文章呐~本次航班到这里就结束啦 🛬
希望本篇文章有对你带来帮助 🎉,有学习到一点知识~
夜色难免黑凉,前行必有曙光(让我们一起努力叭)

相关文章:
Python爬虫教程——解析网页中的元素
前言: 嗨喽~大家好呀,这里是小曼呐 ~ 在我们理解了网页中标签是如何嵌套,以及网页的构成之后, 我们就是可以开始学习使用python中的第三方库BeautifulSoup筛选出一个网页中我们想要得到的数据。 接下来我们了解一下爬取网页信息…...
BiMPM实战文本匹配【上】
引言 今天来实现BiMPM模型进行文本匹配,数据集采用的是中文文本匹配数据集。内容较长,分为上下两部分。 数据准备 数据准备这里和之前的模型有些区别,主要是因为它同时有字符词表和单词词表。 from collections import defaultdict from …...
【C++】构造函数和析构函数第二部分(拷贝构造函数)--- 2023.9.28
目录 什么是拷贝构造函数?编译器默认的拷贝构造函数构造函数的分类及调用结束语 什么是拷贝构造函数? 用一句话来描述为拷贝构造即 “用一个已知的对象去初始化另一个对象” 具体怎么使用我们直接看代码,代码如下: class Maker…...

现在学RPA,还有前途吗,会不会太卷?
RPA是机器人流程自动化的缩写,是一种通过软件机器人模拟人类操作计算机的技术。随着人工智能和自动化技术的不断发展,RPA已经成为了企业数字化转型的重要工具之一。那么,现在学习RPA还有前途吗?会不会太卷? 一、RPA的…...

Vue的详细教程--用Vue-cli搭建SPA项目
Vue的详细教程--用Vue-cli搭建SPA项目 1.Vue-cli是什么2.什么是SPA项目1.vue init webpack spa2.一问一答模式2:运行完上面的命令后,我们需要将当前路径改变到SPA这个文件夹内,然后安装需要的模块此步骤可理解成:maven的web项目创…...

openldap访问控制
系统:debian12 /etc/ldap/slapd.d/cnconfig目录下 包含以下三个数据库: dn: olcDatabase{-1}frontend,cnconfig dn: olcDatabase{0}config,cnconfig dn: olcDatabase{1}mdb,cnconfigolcDatabase: [{\<index\>}]\<type\>数据库条目必须具有…...

阿里云服务器技术创新、网络技术和数据中心技术说明
阿里云服务器技术创新、网络技术创新、数据中心技术创新和智能运维:云服务器方升架构、自研硬件、自研存储硬件AliFlash和异构计算加速平台,以及全自研网络系统技术创新和数据中心巴拿马电源、液冷技术等技术创新说明,阿里云百科分享阿里云服…...

华为智能高校出口安全解决方案(2)
本文承接: https://qiuhualin.blog.csdn.net/article/details/131475315?spm1001.2014.3001.5502 重点讲解华为智能高校出口安全解决方案的基础网络安全&业务部署与优化的部署流程。 华为智能高校出口安全解决方案(2) 课程地址基础网络…...

【AI绘画】Stable Diffusion WebUI
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kuan 的首页,持续学…...

html、css学习记录【uniapp前奏】
Html 声明:该学习笔记源于菜鸟自学网站,特此记录笔记。很多示例源于此官网,若有侵权请联系删除。 文章目录 Html声明: CSS 全称 Cascading Style Sheets,层叠样式表。是一种用来为结构化文档(如 HTML 文档…...
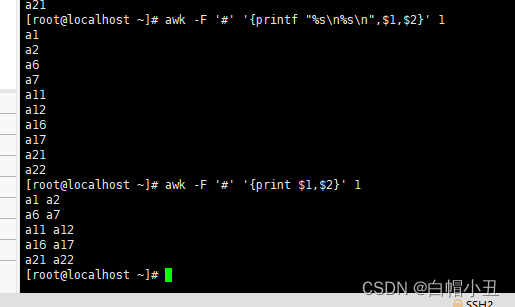
Linux-正则三剑客
目录 一、正则简介 1.正则表达式分两类: 2.正则表达式的意义 二、Linux三剑客简介 1.文本处理工具,均支持正则表达式引擎 2.正则表达式分类 3.基本正则表达式BRE集合 4.扩展正则表达式ere集合 三、grep 1.简介 2.实践 3.贪婪匹配 四、sed …...

Zilliz@阿里云:大模型时代下Milvus Cloud向量数据库处理非结构化数据的最佳实践
大模型时代下的数据存储与分析该如何处理?有没有已经落地的应用实践? 为探讨这些问题,近日,阿里云联合 Zilliz 和 Doris 举办了一场以《大模型时代下的数据存储与分析》为主题的技术沙龙,其中,阿里云对象存储 OSS 上拥有海量的非结构化数据,Milvus(Zilliz)作为全球最有…...
解决 react 项目启动端口冲突
报错信息: Emitted error event on Server instance at:at emitErrorNT (net.js:1358:8)at processTicksAndRejections (internal/process/task_queues.js:82:21) {code: EADDRINUSE,errno: -4091,syscall: listen,address: 0.0.0.0,port: 8070 }解决方法ÿ…...
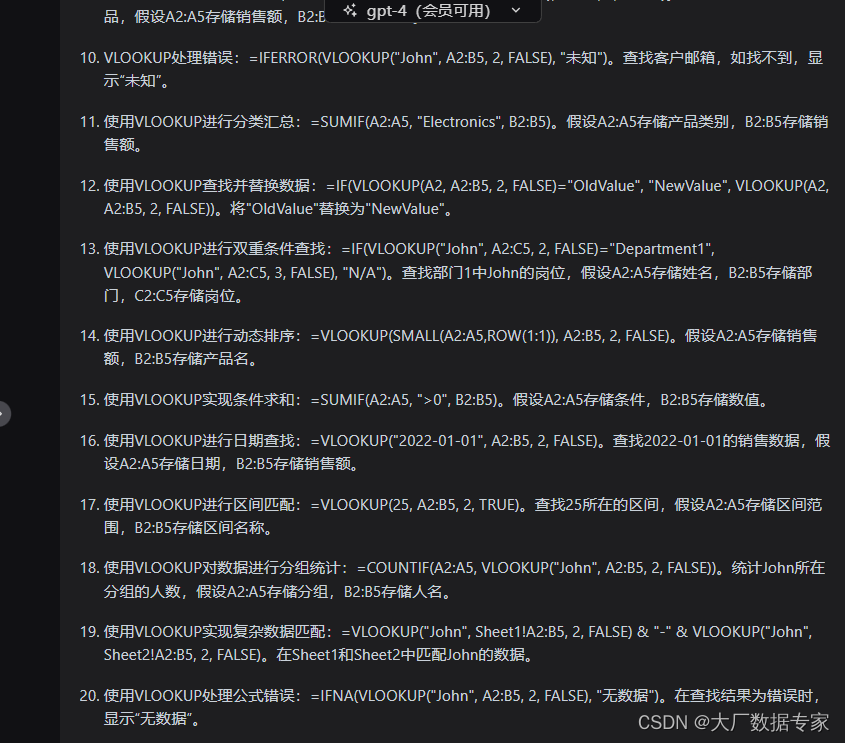
ChatGPT AIGC 总结Vlookup的20种不同用法
Vlookup是Excel中最常见的函数。接下来我们让ChatGPT,AIGC总结Vlookup函数的用法 。 1. 基本的VLOOKUP用法:=VLOOKUP("John", A2:B5, 2, FALSE)。在A2:B5范围中查找"John",返回与"John"在同一行的第2列的值。例如,查找员工姓名,返回员工ID。…...

Android Logcat 命令行工具
关于作者:CSDN内容合伙人、技术专家, 从零开始做日活千万级APP。 专注于分享各领域原创系列文章 ,擅长java后端、移动开发、商业变现、人工智能等,希望大家多多支持。 目录 一、导读二、概览三、日常用法3.1 面板介绍3.2 日志过滤…...

蓝桥等考Python组别八级004
第一部分:选择题 1、Python L8 (15分) 运行下面程序,输出的结果是( )。 i = 1 while i <= 3: print(i, end = ) i += 1 1 20 1 2 31 2 30 1 2正确答案:C 2、Python L8...

selenium-webdriver 阿里云ARMS 自动化巡检
很久没更新了,今天分享一篇关于做项目巡检的内容,这部分,前两天刚在公司做了部门分享,趁着劲还没过,发出来跟大家分享下。 一、本地巡检实现 1. Selenium Webdriver(SW) 简介 Selenium Webdriver(以下简称…...
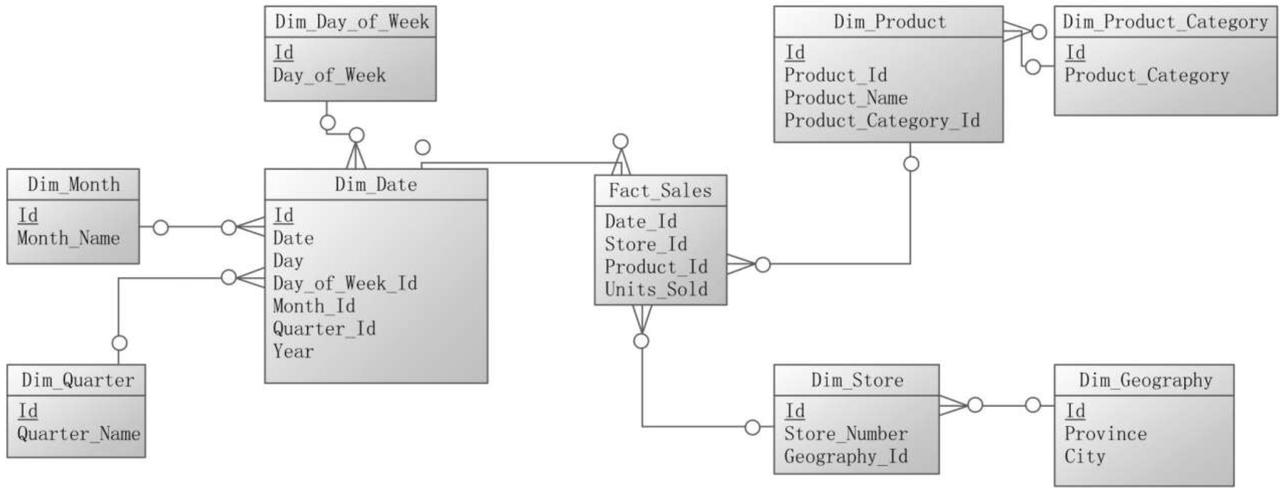
【数据仓库设计基础(二)】维度数据模型
文章目录 一. 概述二. 维度数据模型建模过程三. 维度规范化四. 维度数据模型的特点五. 维度数据模型1. 星型模式1.1.事实表1.2.维度表1.3.优点1.4.缺点1.5.示例 2. 雪花模式2.1.数据规范化与存储2.2&#x…...

【数据结构】排序算法(一)—>插入排序、希尔排序、选择排序、堆排序
👀樊梓慕:个人主页 🎥个人专栏:《C语言》《数据结构》《蓝桥杯试题》《LeetCode刷题笔记》《实训项目》 🌝每一个不曾起舞的日子,都是对生命的辜负 目录 前言 1.直接插入排序 2.希尔排序 3.直接选择排…...
基于JAVA+SpringBoot的新闻发布平台
✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景介绍: 随着科技的飞速发展和…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...