5、Docker安装mysql主从复制与redis集群
安装mysql主从复制
主从搭建步骤
1.1 新建主服务器容器实例3307
docker run -p 3307:3306 --name mysql-master #3307映射到3306,容器名为mysql-master
-v /app/mysql/mydata/mysql-master/log:/var/log/mysql #容器数据卷
-v /app/mysql/mydata/mysql-master/data:/var/lib/mysql
-v /app/mysql/mydata/mysql-master/conf:/etc/mysql
-e MYSQL_ROOT_PASSWORD=root # -e配置环境,配置了root的密码为root
-d mysql:5.7完整命令
docker run -p 3307:3306 --name mysql-master -v /app/mysql/mydata/mysql-master/log:/var/log/mysql -v /app/mysql/mydata/mysql-master/data:/var/lib/mysql -v /app/mysql/mydata/mysql-master/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root -d mysql:5.72、进入/mydata/mysql-master/conf目录下新建my.cnf
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=10623、修改完配置后重启master实例
docker restart mysql-master
4、进入mysql-master容器
[root@centos100 conf]# docker exec -it mysql-master /bin/bash
root@b58afbb1ac1a:/# mysql -uroot -p
Enter password:
...
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql | <--上面配置不需要同步的数据库名称mysql,指的就是这个库
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)5、master容器实例内创建数据同步用户
#创建一个用户
mysql> create user 'slave'@'%' identified by '123456';
Query OK, 0 rows affected (0.03 sec)#授权
mysql> grant replication slave,replication client on *.* to 'slave'@'%';
Query OK, 0 rows affected (0.00 sec)6、新建从服务器容器3308
docker run -p 3308:3306 --name mysql-slave #端口映射,3308映射到3306,修改容器名为mysql-slave
-v /app/mysql/mydata/mysql-slave/log:/var/log/mysql #添加容器卷
-v /app/mysql/mydata/mysql-slave/data:/var/lib/mysql
-v /app/mysql/mydata/mysql-slave/conf:/etc/mysql
-e MYSQL_ROOT_PASSWORD=root #创建root密码为root
-d mysql:5.7 #镜像名完整命令
docker run -p 3308:3306 --name mysql-slave -v /app/mysql/mydata/mysql-slave/log:/var/log/mysql -v /app/mysql/mydata/mysql-slave/data:/var/lib/mysql -v /app/mysql/mydata/mysql-slave/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=root -d mysql:5.77、进入/app/mysql/mydata/mysql-slave/conf目录下新建my.cnf
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=102
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能,以备Slave作为其它数据库实例的Master时使用
log-bin=mall-mysql-slave1-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
## relay_log配置中继日志
relay_log=mall-mysql-relay-bin
## log_slave_updates表示slave将复制事件写进自己的二进制日志
log_slave_updates=1
## slave设置为只读(具有super权限的用户除外)
read_only=18、修改完配置后重启slave实例
docker restart mysql-slave
9、在主数据库中查看主从同步状态
[root@centos100 conf]# docker exec -it mysql-master /bin/bash
root@b58afbb1ac1a:/# mysql -uroot -p
Enter password:
...
mysql> show master status;
+-----------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-----------------------+----------+--------------+------------------+-------------------+
| mall-mysql-bin.000001 | 617 | | mysql | |
+-----------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
10、进入mysql-slave容器
[root@centos100 conf]# docker exec -it mysql-slave /bin/bash
root@ee7d461daf7f:/# mysql -uroot -p
Enter password:
11、在从数据库中配置主从复制
change master to master_host='宿主机ip', master_user='slave', master_password='123456', master_port=3307, master_log_file='mall-mysql-bin.000001', master_log_pos=617, master_connect_retry=30;主从复制命令参数说明
master_host:主数据库的IP地址;
master_port:主数据库的运行端口;
master_user:在主数据库创建的用于同步数据的用户账号;
master_password:在主数据库创建的用于同步数据的用户密码;
master_log_file:指定从数据库要复制数据的日志文件,通过查看主数据的状态,获取File参数;
master_log_pos:指定从数据库从哪个位置开始复制数据,通过查看主数据的状态,获取Position参数;
master_connect_retry:连接失败重试的时间间隔,单位为秒。12、在从数据库中查看主从同步状态
show slave status\G;
13、在从数据库开启主从同步
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)执行这个命令之前,在12步时可以看到Slave_IO_Running: NoSlave_SQL_Running: No
当执行成功后Slave_IO_Running: Yes
14、查看从数据库状态发现已经同步
15、主从复制测试
主机创建库、表
mysql> create database db01;
Query OK, 1 row affected (0.00 sec)mysql> use db01;
Database changed
mysql> create table t1(id int,name varchar(12));
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t1 values (1,'zhangsan');
Query OK, 1 row affected (0.01 sec)mysql> select * from t1;
+------+----------+
| id | name |
+------+----------+
| 1 | zhangsan |
+------+----------+
1 row in set (0.00 sec)从机
mysql> use db01;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -ADatabase changed
mysql> select * from t1;
+------+----------+
| id | name |
+------+----------+
| 1 | zhangsan |
+------+----------+
1 row in set (0.00 sec)
1.2 安装Redis集群
cluster(集群)模式-docker版
哈希槽分区进行亿级数据存储
1.2.1 面试题:1~2亿条数据需要缓存,请问应该怎样设计
单机单台100%不可能,肯定是分布式存储,用redis如何落地?
1. 哈希取余分区1.1 2亿条记录就是2亿个k,v,我们单机不行必须要分布式多机,假设有3台机器构成一个集群,用户每次读写操作都是根据公式:
hash(key) % N个机器台数,计算出哈希值,用来决定数据映射到哪一个节点上。1.2 优点:简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。1.3 缺点:原来规划好的节点,进行扩容或者缩容就比较麻烦了额,不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,在服务器个数固定不变时没有问题,如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化:Hash(key)/3会变成Hash(key) /?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。
某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。2. 一致性哈希算法分区2.1 是什么一致性Hash算法背景:一致性哈希算法在1997年由麻省理工学院中提出的,设计目标是为了解决分布式缓存数据变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数不OK了。2.2 能干啥提出一致性Hash解决方案。目的是当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系2.3 三大步骤2.3.1 一致性哈希环一致性哈希算法必然有个hash函数并按照算法产生hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个hash空间[0,2^32-1],这个是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连(0 = 2^32),这样让它逻辑上形成了一个环形空间。2.3.2 节点映射将集群中各个IP节点映射到环上的某一个位置。将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。假如4个节点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip))2.3.3 key落到服务器的落键规则当我们需要存储一个kv键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。2.4 优点2.4.1 解决了一致性哈希算法的容错性假设Node C宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。简单说,就是C挂了,受到影响的只是B、C之间的数据,并且这些数据会转移到D进行存储。2.4.2 解决了一致性哈希算法的扩展性数据量增加了,需要增加一台节点NodeX,X的位置在A和B之间,那收到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,不会导致hash取余全部数据重新洗牌。2.5 缺点Hash环的数据倾斜问题一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题2.6 总结为了在节点数目发生改变时尽可能少的迁移数据将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会顺时针找到临近的存储节点存放。而当有节点加入或退出时仅影响该节点在Hash环上顺时针相邻的后续节点。 优点:加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。缺点 :数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果。3. 哈希槽分区3.1 为什么会出现解决一致性哈希算法的数据倾斜问题哈希槽实质就是一个数组,数组[0,2^14 -1]形成hash slot空间。3.2 能干什么解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配。3.3 有多少个hash槽一个集群只能有16384个槽,编号0-16383(0-2^14-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点。集群会记录节点和槽的对应关系。解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取余,余数是几key就落入对应的槽里。slot = CRC16(key) % 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。3.4 哈希槽计算Redis 集群中内置了 16384 个哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,也就是映射到某个节点上。如下代码,key之A 、B在Node2, key之C落在Node3上1.2.2 三主三从集群配置步骤
1、新建6个docker容器实例
docker run -d #创建并运行docker容器实例
--name redis-node-1 #容器名字
--net host #使用宿主机的ip端口,默认
--privileged=true #获取宿主机的用户权限
-v /app/redis/share/redis-node-1:/data #容器卷 宿主机地址:docker内部地址
redis #redis镜像
--cluster-enabled yes #开启redis集群
--appendonly yes #开启持久化
--port 6381 #redis端口docker run -d --name redis-node-1 --net host --privileged=true -v /app/redis/share/redis-node-1:/data redis --cluster-enabled yes --appendonly yes --port 6381docker run -d --name redis-node-2 --net host --privileged=true -v /app/redis/share/redis-node-2:/data redis --cluster-enabled yes --appendonly yes --port 6382docker run -d --name redis-node-3 --net host --privileged=true -v /app/redis/share/redis-node-3:/data redis --cluster-enabled yes --appendonly yes --port 6383docker run -d --name redis-node-4 --net host --privileged=true -v /app/redis/share/redis-node-4:/data redis --cluster-enabled yes --appendonly yes --port 6384docker run -d --name redis-node-5 --net host --privileged=true -v /app/redis/share/redis-node-5:/data redis --cluster-enabled yes --appendonly yes --port 6385docker run -d --name redis-node-6 --net host --privileged=true -v /app/redis/share/redis-node-6:/data redis --cluster-enabled yes --appendonly yes --port 63862、进入容器redis-node-1并为6台机器构建集群关系
//注意,进入docker容器后才能执行一下命令,且注意自己的真实IP地址
redis-cli --cluster create 192.168.75.100:6381 192.168.75.100:6382 192.168.75.100:6383 192.168.75.100:6384 192.168.75.100:6385 192.168.75.100:6386 --cluster-replicas 1--cluster-replicas 1 表示为每个master创建一个slave节点
[root@centos100 ~]# docker exec -it redis-node-1 /bin/bash
root@centos100:/data# redis-cli --cluster create 192.168.75.100:6381 192.168.75.100:6382 192.168.75.100:6383 192.168.75.100:6384 192.168.75.100:6385 192.168.75.100:6386 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.75.100:6385 to 192.168.75.100:6381
Adding replica 192.168.75.100:6386 to 192.168.75.100:6382
Adding replica 192.168.75.100:6384 to 192.168.75.100:6383
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 08df796c1908646c721bf261d01604cfcde0bdec 192.168.75.100:6381
slots:[0-5460] (5461 slots) master
M: c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 192.168.75.100:6382
slots:[5461-10922] (5462 slots) master
M: 1f37845789f52b4713200bbc4bc89dbad1fdfdf5 192.168.75.100:6383
slots:[10923-16383] (5461 slots) master
S: 16da45b459ba780926566fcda4407cf0798f01ca 192.168.75.100:6384
replicates c71627fc6d20b9ca61fca76d1fd7e0adab02ec48
S: 7ea18ad035fd83d1e6828022832915ffd7c1d89c 192.168.75.100:6385
replicates 1f37845789f52b4713200bbc4bc89dbad1fdfdf5
S: 1240de80a446da678036b886d11beddee60c6ba3 192.168.75.100:6386
replicates 08df796c1908646c721bf261d01604cfcde0bdec
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
....
>>> Performing Cluster Check (using node 192.168.75.100:6381)
M: 08df796c1908646c721bf261d01604cfcde0bdec 192.168.75.100:6381
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 16da45b459ba780926566fcda4407cf0798f01ca 192.168.75.100:6384
slots: (0 slots) slave
replicates c71627fc6d20b9ca61fca76d1fd7e0adab02ec48
M: c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 192.168.75.100:6382
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 1240de80a446da678036b886d11beddee60c6ba3 192.168.75.100:6386
slots: (0 slots) slave
replicates 08df796c1908646c721bf261d01604cfcde0bdec
S: 7ea18ad035fd83d1e6828022832915ffd7c1d89c 192.168.75.100:6385
slots: (0 slots) slave
replicates 1f37845789f52b4713200bbc4bc89dbad1fdfdf5
M: 1f37845789f52b4713200bbc4bc89dbad1fdfdf5 192.168.75.100:6383
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
root@centos100:/data# 3、链接进入6381作为切入点,查看集群状态
root@centos100:/data# redis-cli -p 6381
127.0.0.1:6381> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6 #6个节点
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:188
cluster_stats_messages_pong_sent:198
cluster_stats_messages_sent:386
cluster_stats_messages_ping_received:193
cluster_stats_messages_pong_received:188
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:386
127.0.0.1:6381> cluster nodes
16da45b459ba780926566fcda4407cf0798f01ca 192.168.75.100:6384@16384 slave c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 0 1653649433792 2 connected
c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 192.168.75.100:6382@16382 master - 0 1653649433000 2 connected 5461-10922
1240de80a446da678036b886d11beddee60c6ba3 192.168.75.100:6386@16386 slave 08df796c1908646c721bf261d01604cfcde0bdec 0 1653649430699 1 connected
7ea18ad035fd83d1e6828022832915ffd7c1d89c 192.168.75.100:6385@16385 slave 1f37845789f52b4713200bbc4bc89dbad1fdfdf5 0 1653649432000 3 connected
1f37845789f52b4713200bbc4bc89dbad1fdfdf5 192.168.75.100:6383@16383 master - 0 1653649432777 3 connected 10923-16383
08df796c1908646c721bf261d01604cfcde0bdec 192.168.75.100:6381@16381 myself,master - 0 1653649431000 1 connected 0-5460#根据输出结果来看 1 -> 6 2 -> 4 3 -> 5
127.0.0.1:6381> 
1.2.3 主从容错切换迁移案例
数据读写存储
1、通过exec进入一台redis[root@centos100 ~]# docker exec -it redis-node-1 /bin/bash
root@centos100:/data# redis-cli -p 6381
127.0.0.1:6381> keys *
(empty array)2、对6381新增几个key127.0.0.1:6381> set k1 v1
(error) MOVED 12706 192.168.75.100:6383
127.0.0.1:6381> set k2 v2
OK
127.0.0.1:6381> set k3 v3
OK
127.0.0.1:6381> set k4 v4
(error) MOVED 8455 192.168.75.100:6382
127.0.0.1:6381> 3、防止路由器失效,添加参数-c
root@centos100:/data# redis-cli -p 6381 -c
127.0.0.1:6381> flushall
OK
127.0.0.1:6381> set vi k1
-> Redirected to slot [8048] located at 192.168.75.100:6382
OK
192.168.75.100:6382> set k2 v2
-> Redirected to slot [449] located at 192.168.75.100:6381
OK
192.168.75.100:6381> set k3 v3
OK
192.168.75.100:6381> set k4 v4
-> Redirected to slot [8455] located at 192.168.75.100:6382
OK
4、查看集群信息
redis-cli --cluster check 192.168.75.100:6381
1.2.4 主从容错的切换迁移
1、主6381和从机切换,先停止6381
[root@centos100 ~]# docker stop redis-node-1
redis-node-1
2、再次查看集群信息
[root@centos100 ~]# docker exec -it redis-node-2 /bin/bash
root@centos100:/data# redis-cli -p 6382 -c
127.0.0.1:6382> cluster nodes
1240de80a446da678036b886d11beddee60c6ba3 192.168.75.100:6386@16386 master - 0 1653652908000 7 connected 0-5460
c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 192.168.75.100:6382@16382 myself,master - 0 1653652904000 2 connected 5461-10922
08df796c1908646c721bf261d01604cfcde0bdec 192.168.75.100:6381@16381 master,fail - 1653652828089 1653652822986 1 disconnected
1f37845789f52b4713200bbc4bc89dbad1fdfdf5 192.168.75.100:6383@16383 master - 0 1653652906922 3 connected 10923-16383
7ea18ad035fd83d1e6828022832915ffd7c1d89c 192.168.75.100:6385@16385 slave 1f37845789f52b4713200bbc4bc89dbad1fdfdf5 0 1653652908000 3 connected
16da45b459ba780926566fcda4407cf0798f01ca 192.168.75.100:6384@16384 slave c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 0 1653652908967 2 connected
3、还原之前的3主3从
[root@centos100 ~]# docker start redis-node-1
redis-node-1
[root@centos100 ~]# docker exec -it redis-node-1 /bin/bash
root@centos100:/data# redis-cli -p 6381 -c
127.0.0.1:6381> cluster nodes
16da45b459ba780926566fcda4407cf0798f01ca 192.168.75.100:6384@16384 slave c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 0 1653653200093 2 connected
7ea18ad035fd83d1e6828022832915ffd7c1d89c 192.168.75.100:6385@16385 slave 1f37845789f52b4713200bbc4bc89dbad1fdfdf5 0 1653653202126 3 connected
1f37845789f52b4713200bbc4bc89dbad1fdfdf5 192.168.75.100:6383@16383 master - 0 1653653203142 3 connected 10923-16383
c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 192.168.75.100:6382@16382 master - 0 1653653201111 2 connected 5461-10922
1240de80a446da678036b886d11beddee60c6ba3 192.168.75.100:6386@16386 master - 0 1653653200000 7 connected 0-5460
08df796c1908646c721bf261d01604cfcde0bdec 192.168.75.100:6381@16381 myself,slave 1240de80a446da678036b886d11beddee60c6ba3 0 1653653201000 7 connected停止6386
[root@centos100 ~]# docker stop redis-node-6
redis-node-6
再启动6386
[root@centos100 ~]# docker start redis-node-6
redis-node-6
查看集群状态
redis-cli --cluster check 192.168.75.100:6381
1.2.5 主从扩容案例
1、新建6387、6388两个节点,新建后启动,检查是否8个节
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis --cluster-enabled yes --appendonly yes --port 6387docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis --cluster-enabled yes --appendonly yes --port 63882、进入到6387容器内部
3、将新增的6387节点(空槽位)作为master节点加入原集群
将新增的6387作为master节点加入集群
redis-cli --cluster add-node 自己实际IP地址:6387 自己实际IP地址:6381
6387 就是将要作为master新增节点
6381 就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群
redis-cli --cluster add-node 192.168.75.100:6387 192.168.75.100:6381
4、检查集群的情况第一次
root@centos100:/data# redis-cli --cluster check 192.168.75.100:6381
192.168.75.100:6381 (08df796c...) -> 2 keys | 5461 slots | 1 slaves.
192.168.75.100:6387 (987146b1...) -> 0 keys | 0 slots | 0 slaves.
192.168.75.100:6382 (c71627fc...) -> 2 keys | 5462 slots | 1 slaves.
192.168.75.100:6383 (1f378457...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 4 keys in 4 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 192.168.75.100:6381)
M: 08df796c1908646c721bf261d01604cfcde0bdec 192.168.75.100:6381
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 987146b1eb2e78155b1885312cc5fd92e4155b79 192.168.75.100:6387
slots: (0 slots) master
S: 7ea18ad035fd83d1e6828022832915ffd7c1d89c 192.168.75.100:6385
slots: (0 slots) slave
replicates 1f37845789f52b4713200bbc4bc89dbad1fdfdf5
S: 1240de80a446da678036b886d11beddee60c6ba3 192.168.75.100:6386
slots: (0 slots) slave
replicates 08df796c1908646c721bf261d01604cfcde0bdec
M: c71627fc6d20b9ca61fca76d1fd7e0adab02ec48 192.168.75.100:6382
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: 1f37845789f52b4713200bbc4bc89dbad1fdfdf5 192.168.75.100:6383
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 16da45b459ba780926566fcda4407cf0798f01ca 192.168.75.100:6384
slots: (0 slots) slave
replicates c71627fc6d20b9ca61fca76d1fd7e0adab02ec48
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.5、重新分配槽位
重新分派槽号命令:redis-cli --cluster reshard IP地址:端口号
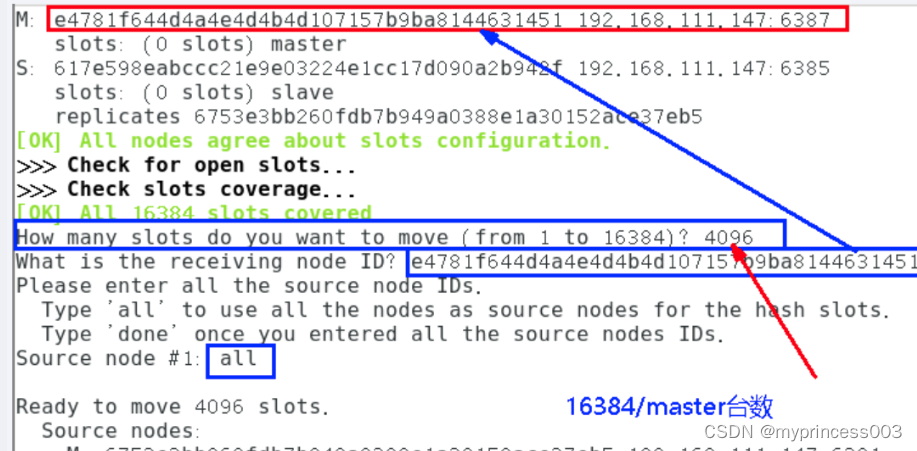
6、第二次查看集群情况
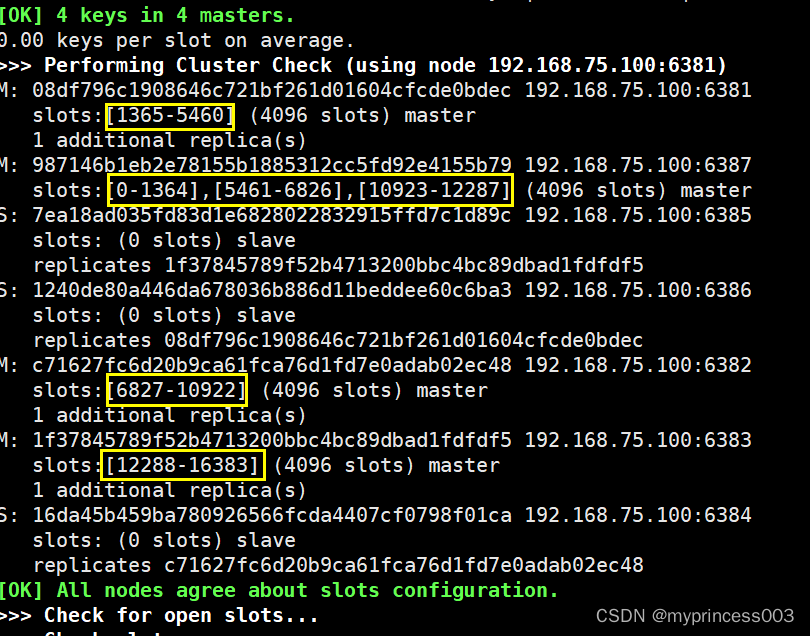
7、为主节点6387分配从节点6388
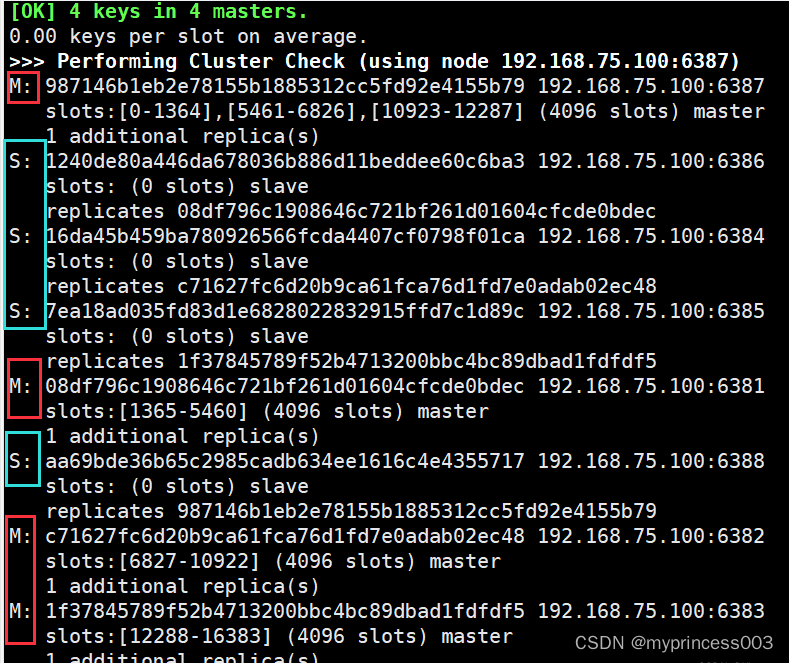
命令:redis-cli --cluster add-node ip:新slave端口 ip:新master端口 --cluster-slave --cluster-master-id 新主机节点IDredis-cli --cluster add-node 192.168.111.147:6388 192.168.111.147:6387 --cluster-slave --cluster-master-id e4781f644d4a4e4d4b4d107157b9ba8144631451-------这个是6387的编号,按照自己实际情况redis-cli --cluster add-node 192.168.75.100:6388 192.168.75.100:6387 --cluster-slave --cluster-master-id 987146b1eb2e78155b1885312cc5fd92e4155b798、第三次查看集群情况
redis-cli --cluster check 192.168.75.100:6381
1.2.6 主从缩容案例
目的:6387、6388下线
1、检查集群情况,获得6387节点ID
aa69bde36b65c2985cadb634ee1616c4e4355717
2、从集群中将4号从节点6388删除
命令:redis-cli --cluster del-node ip:从机端口 从机6388节点ID
redis-cli --cluster del-node 192.168.75.100:6388 aa69bde36b65c2985cadb634ee1616c4e4355717
检查一下,可以发现6388已经被删除
redis-cli --cluster check 192.168.75.100:6387
3、将6387槽位重新分配,本例将所有清出来的槽位都给6381
redis-cli --cluster reshard 192.168.75.100:6381
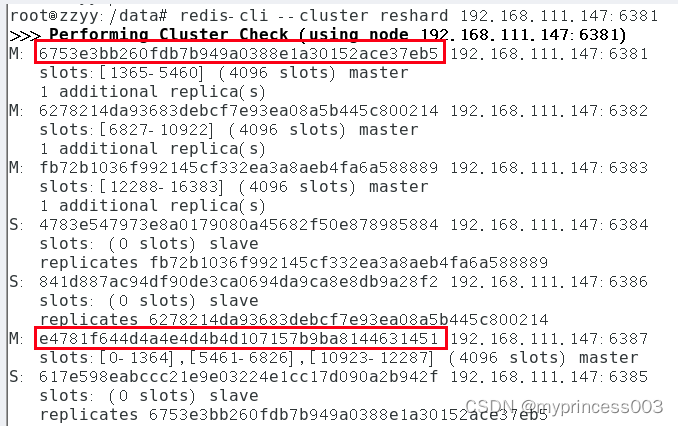
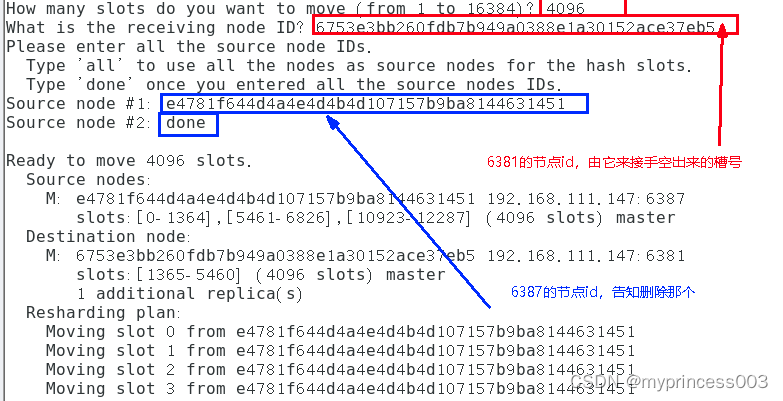
4、第二次检查集群情况
redis-cli --cluster check 192.168.75.100:6381
4096个槽位都指给6381,它变成了8192个槽位,相当于全部都给6381了,不然要输入3次
5、将6387删除
命令:redis-cli --cluster del-node ip:端口 6387节点ID
redis-cli --cluster del-node 192.168.75.100:6387 987146b1eb2e78155b1885312cc5fd92e4155b79
6、第三次检查集群情况
1.3 补充:将容器设置为开机自启
运行启动容器时指定
docker run -p 3306:3306 --restart=always -d mysql:5.7
restart具体参数值详细信息:
no 容器退出时,不重启容器;
on-failure 只有在非0状态退出时才从新启动容器;
always 无论退出状态是如何,都重启容器;
创建时未指定
docker update --restart=always xxx
相关文章:
5、Docker安装mysql主从复制与redis集群
安装mysql主从复制 主从搭建步骤 1.1 新建主服务器容器实例3307 docker run -p 3307:3306 --name mysql-master #3307映射到3306,容器名为mysql-master -v /app/mysql/mydata/mysql-master/log:/var/log/mysql #容器数据卷 -v /app/mysql/mydata/mysql-master/dat…...

【AI视野·今日NLP 自然语言处理论文速览 第四十三期】Thu, 28 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 28 Sep 2023 Totally 38 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers Cross-Modal Multi-Tasking for Speech-to-Text Translation via Hard Parameter Sharing Authors Brian Yan,…...

Unity 制作登录功能01-创建登录的UI并获取输入内容
1.创建UI面板 导入插件TextMesh Pro 2.编写脚本获取用户输入 这里用的是输入框侦听函数,所有UI都可以使用侦听函数 ,需要注意TMP_InputField 这个类是UI中导入的一个插件TextMesh Pro!在代码中需要引用using TMPro; 命名空间! …...

什么是用户画像?
(1)首先用户画像是个动词逻辑,不是名词,就是给用户绘制肖像。 (2)在互联网这个平台上,绘制肖像就相当千给用户打标签 (3)标签通常是人为规定的高度精炼的特征标识,如年龄、性别、地域、兴趣等…...

DevExpress WinForms图表组件 - 直观的数据信息呈现方式!(二)
在上文中(点击这里回顾>>),我们为大家介绍了DevExpress WinForms图表控件的互动图表、图标设计器及可定制功能等,本文将继续介绍DevExpress WinForms图表控件的数据分析、大数据功能等,欢迎持续关注我们哦~ Dev…...
基于AIOps实现智慧园区极简IT运维
随着物联网、云平台、大数据、人工智能等技术的发展,并逐步投入到智慧园区的建设,传统园区数字化转型加快。园区的形式包括产业园区、教育园区、制造业园区、科研园区、社区等等,园区形态不断演进和发展,园区网承载的对象和业务也…...
chatgpt 只会死记硬背吗
本周写两篇关于 chatgpt 的随感,我不善于写文档,所以我的文字多是输出直感和观点,而不是知识,没有关于 chatgpt 的原理和应用,甚至术语也不匹配,反正就是想到哪算哪吧。 都说 chatgpt 没有内在逻辑…...

03-Zookeeper客户端使用
上一篇:02-Zookeeper实战 1. 项目构建 zookeeper 官方的客户端没有和服务端代码分离,他们为同一个jar 文件,所以我们直接引入zookeeper的maven即可, 这里版本请保持与服务端版本一致,不然会有很多兼容性的问题 <…...

自然语言处理(NLP)学习之与HanLP的初相识
目录 前言 一、自然语言处理基本知识 1、NLP类别 2、核心任务 二、Hanlp简要介绍 三、Hanlp云服务能力 1、全新云原生2.x 2、Python api调用 3、Go api调用 4、Java api调用 四、Hanlp native服务 1、本地开发 总结 前言 在ChatGPT的滚滚浪潮下,也伴随着人工智…...

JDBC【DBUtils】
一、 DBUtils工具类🍓 (一)、DBUtils简介🥝 使用JDBC我们发现冗余的代码太多了,为了简化开发 我们选择使用 DbUtils Commons DbUtils是Apache组织提供的一个对JDBC进行简单封装的开源工具类库,使用它能够简化JDBC应用程序的开发,…...

大数据Doris(一):Doris概述篇
文章目录 Doris概述篇 一、前言 二、Doris简介...

vue 基于vue-seamless-scroll无缝滚动的用法和遇到的问题解决
vue 基于vue-seamless-scroll无缝滚动的用法和遇到的问题解决 背景 最近再做一个大屏项目,需要用到表格滚动效果,之前自己写过js实现,最近发现一个组件vue-seamless-scroll可以实现滚动,感觉挺方便的,准备用一下,但是用完之后才发现这个组件有很多坑需要解决.我把用法和一些问…...

SmartX 边缘计算解决方案:简单稳定,支持各类应用负载
在《一文了解近端边缘 IT 基础架构技术需求》文章中,我们为大家分析了边缘应用对 IT 基础架构的技术要求,以及为什么超融合架构是支持边缘场景的最佳选择。值得一提的是,IDC 近日发布的《中国软件定义存储(SDS)及超融合…...
FPGA 多路视频处理:图像缩放+视频拼接显示,HDMI采集,提供2套工程源码和技术支持
目录 1、前言版本更新说明免责声明 2、相关方案推荐FPGA图像缩放方案推荐FPGA视频拼接方案推荐 3、设计思路框架视频源选择IT6802解码芯片配置及采集动态彩条缓冲FIFO图像缩放模块详解设计框图代码框图2种插值算法的整合与选择 视频拼接算法图像缓存视频输出 4、vivado工程1&am…...
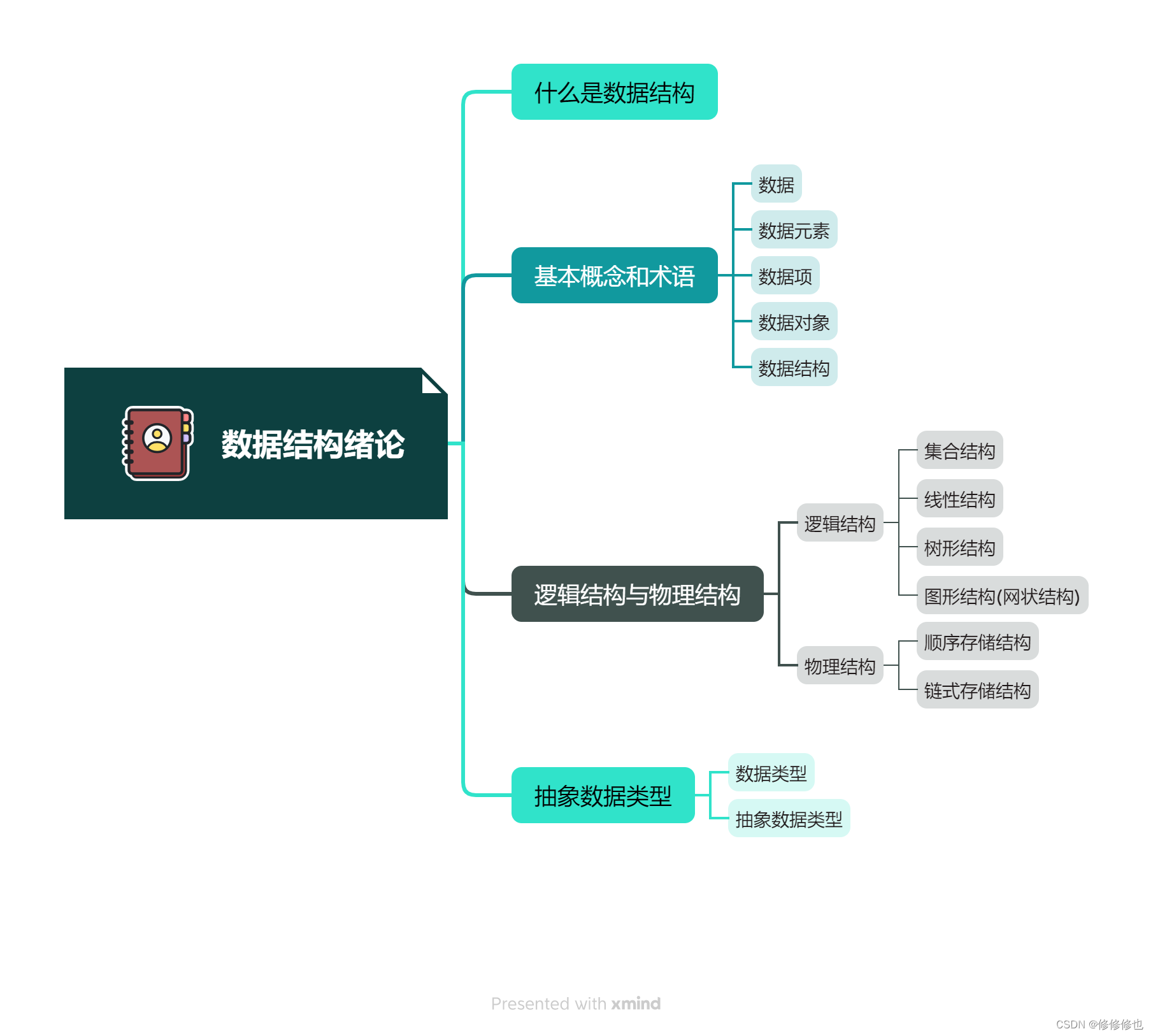
【数据结构】抽象数据类型
🦄个人主页:修修修也 🎏所属专栏:数据结构 ⚙️操作环境:Visual Studio 2022 目录 🎏数据类型 🎏抽象数据类型 结语 🎏数据类型 数据类型:是指一组性质相同的值的集合及定义在此集合上的一些操作的总称. 数据类型(d…...

Android 查看路由表
Android 查看路由表_android 路由表_念雅的博客-CSDN博客...
vulnhub靶机-DC系列-DC-3
文章目录 信息收集漏洞查找漏洞利用SQL注入John工具密码爆破反弹shell 提权 信息收集 主机扫描 arp-scan -l可以用netdiscover 它是一个主动/被动的ARP 侦查工具。使用Netdiscover工具可以在网络上扫描IP地址,检查在线主机或搜索为它们发送的ARP请求。 netdiscover -r 192.1…...
【CTFHUB】SSRF原理之简单运用(一)
一、漏洞原理 SSRF 服务端请求伪造 原理:在某些网站中提供了从其他服务器获取数据的功能,攻击者能通过构造恶意的URL参数,恶意利用后可作为代理攻击远程或本地的服务器。 二、SSRF的利用 1.对目标外网、内网进行端口扫描。 2.攻击内网或本…...
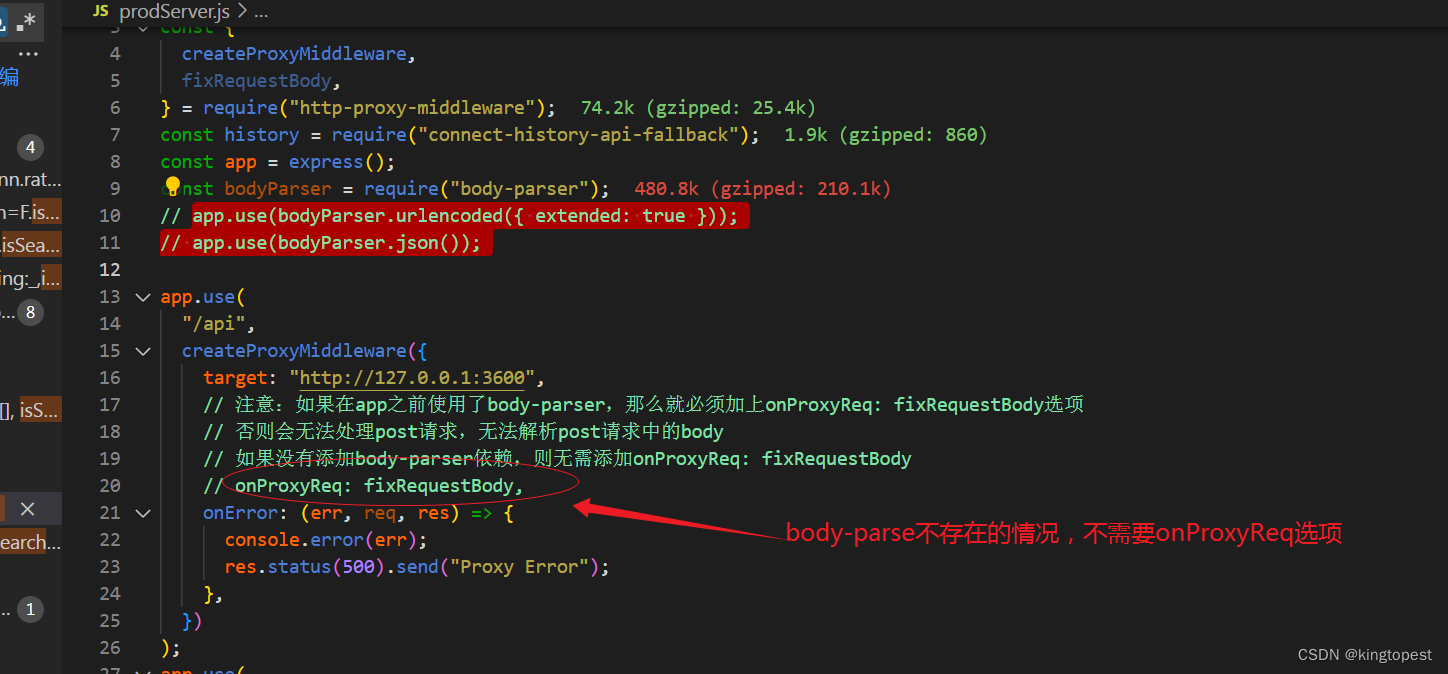
wepack打包生产环境使用http-proxy-middleware做api代理转发的方法
首先安装http-proxy-middleware依赖,这个用npm和yarn安装都可以。 然后在express服务器的代码增加如下内容: const express require("express"); const app express(); const { createProxyMiddleware, fixRequestBody, } require("h…...

一百八十六、大数据离线数仓完整流程——步骤五、在Hive的DWS层建动态分区表并动态加载数据
一、目的 经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。 二、数仓实施步骤 (五)步骤五、在Hive的…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

华为OD机试-食堂供餐-二分法
import java.util.Arrays; import java.util.Scanner;public class DemoTest3 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseint a in.nextIn…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...