一篇博客学会系列(1) —— C语言中所有字符串函数以及内存函数的使用和注意事项
目录
1、求字符串长度函数
1.1、strlen
2、字符串拷贝(cpy)、拼接(cat)、比较(cmp)函数
2.1、长度不受限制的字符串函数
2.1.1、strcpy
2.1.2、strcat
2.1.3、strcmp
2.2、长度受限制的字符串函数
2.2.1、strncpy
2.2.2、strncat
2.2.3、strncmp
3、字符串查找函数
3.1、strstr
3.2、strtok
4、错误信息报告函数
4.1、strerror
4.2、perror
5、字符函数
5.1、字符分类函数
5.2、字符转换函数
5.2.1、tolower
5.2.2、toupper
6、内存操作函数
6.1、memcpy
6.2、memmove
6.3、memset
6.4、memcmp

1、求字符串长度函数
1.1、strlen

- strlen用于求字符串长度。
- 包含头文件<string.h>。
- 字符串已经 '\0' 作为结束标志,strlen函数返回的是在字符串中 '\0' 前面出现的字符个数(不包含 '\0' )。
- 参数指向的字符串必须要以 '\0' 结束。
注意:
1、函数的返回值为size_t,是无符号的( 易错 )
2、因为strlen返回的是 '\0' 前面的字符个数,如果字符串中间本身就一个'\0',那么返回的值就会返回字符串中的'\0'之前的字符个数。
例如:"abc\0def" 这个字符串,使用strlen函数会返回3。
【使用方式】
int main()
{char arr[] = "Hello hacynn";int ret = strlen(arr);printf("%d\n", ret);return 0;
}【运行结果】
【易错提醒】
请问ret的值是多少?
int ret = strlen("abc") - strlen("abcdef");答案是3,因为函数的返回值为size_t,是无符号的整型。
【模拟实现strlen】
int my_strlen(char* arr)
{int count = 0;while (*arr != '\0'){count++;arr++;}return count;
}int main()
{char arr[] = "Hello hacynn";int ret = my_strlen(arr);printf("%d\n", ret);return 0;
}2、字符串拷贝(cpy)、拼接(cat)、比较(cmp)函数
2.1、长度不受限制的字符串函数
2.1.1、strcpy

- strcpy用于拷贝字符串,将字符串2拷贝到字符串1当中。
- 包含头文件<string.h>。
- 源字符串必须以 '\0' 结束。
- 会将源字符串中的 '\0' 拷贝到目标空间。
- 目标空间必须足够大,以确保能存放源字符串。
- 目标空间必须可变。
【使用方法】
int main()
{char arr1[] = "Hello hacynn";char arr2[20] = { 0 };strcpy(arr2,arr1);printf("%s\n", arr2);return 0;
}【运行结果】

【模拟实现strcpy】
char* my_strcpy(char* dest,const char* src)
{char* ret = dest;while (*dest = *src){dest++;src++;}return ret;
}int main()
{char arr1[] = "Hello hacynn";char arr2[20] = { 0 };my_strcpy(arr2,arr1);printf("%s\n", arr2);return 0;
}2.1.2、strcat

- strcat用于拼接两个字符串,将字符串2拼接到字符串1末尾。
- 包含头文件<string.h>。
- 源字符串必须以 '\0' 结束(保证找得到目标空间的末尾),在拷贝时会把源字符串的 '\0 '也拷贝过去。
- 目标空间必须有足够的大,能容纳下源字符串的内容,并且还可以被修改。
注意:
不能字符串自己追加自己,因为当自己追加自己的时候,追加的过程中会将目标字符串的 '\0' 覆盖掉,而有因为此时目标字符串就是源字符串,就会导致源字符没有 '\0' ,将会一直拼接下去导致死循环。
虽然有些环境中该函数可以完成自己拼接自己,但是C语言的标准中并未规定strcat可以自己拼接自己,所以这个函数最好不要使用在自己拼接自己的情况下。如果真有自己追加自己的场景,建议使用strncat函数,这个函数将在下文进行讲解。
【使用方式】
int main()
{char arr1[20] = "Hello ";char arr2[] = "hacynn" ;strcat(arr1, arr2);printf("%s\n", arr1);return 0;
}【运行结果】

【模拟实现strcat】
char* my_strcat(char* dest, const char* src)
{char* ret = dest;//找到目标空间的末尾while (*dest != '\0'){dest++;}//数据追加while (*dest = *src){dest++;src++;}return ret;
}int main()
{char arr1[20] = "Hello ";char arr2[] = "hacynn" ;my_strcat(arr1, arr2);printf("%s\n", arr1);return 0;
}2.1.3、strcmp
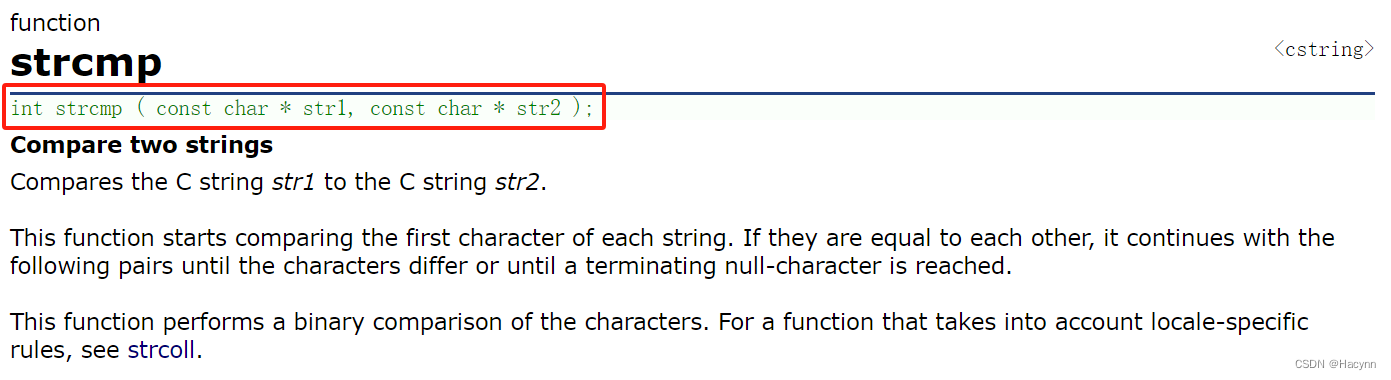
- strcmp用于比较两个字符串。
- 包含头文件<string.h>。
- 误区:该函数不是比较字符串长度的,而是比较对应位置上字符的大小(ASCII)。
- 标准规定:
第一个字符串大于第二个字符串,则返回大于0的数字
第一个字符串等于第二个字符串,则返回0
第一个字符串小于第二个字符串,则返回小于0的数字

【使用方式】
int main()
{char arr1[] = "abcdef";char arr2[] = "abz";if (strcmp(arr1, arr2) > 0)printf(">\n");else if (strcmp(arr1,arr2) < 0)printf("<\n"); elseprintf("=\n");return 0;
}【运行结果】

【模拟实现strcmp】
int my_strcmp(const char* str1, const char* str2)
{while (*str1 == *str2){if (*str1 == '\0')return 0;str1++;str2++;}if (*str1 > *str2)return 1;elsereturn -1;
}int main()
{char arr1[] = "abcdef";char arr2[] = "abz";if (my_strcmp(arr1, arr2) > 0)printf(">\n");elseprintf("<=\n"); return 0;
}2.2、长度受限制的字符串函数
- 就是可以限制操作个数的字符串函数。
- 包含头文件<string.h>。
2.2.1、strncpy

- 区别仅与strcpy差一个参数,记录要操作的个数。
- 拷贝num个字符从源字符串到目标空间。
- 如果源字符串的长度小于num,则拷贝完源字符串之后,在目标的后边追加0,直到num个。
- 因为拷贝个数由用户自己决定,因此\0没有被拷贝过来的可能性也是有的。
【使用方式】
int main()
{char arr1[] = "Hello hacynn";char arr2[20] = { 0 };strncpy(arr2, arr1, 5); //拷贝前五个字符 ,此时拷贝\0后arr2中并不会有\0printf("%s\n", arr2);return 0;
}【运行结果】

【特殊情况】
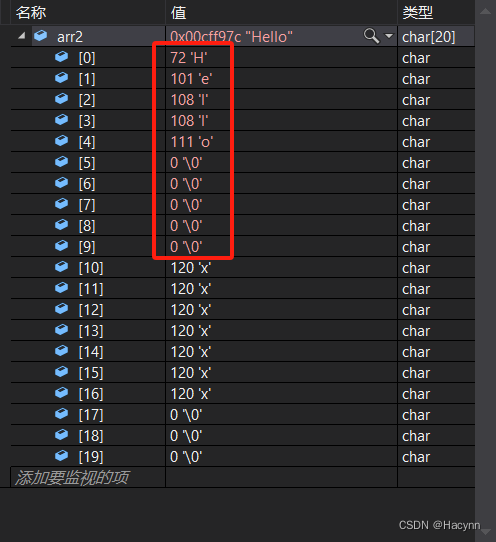
如果源字符串的长度小于num,则拷贝完源字符串之后,在目标的后边追加0,直到num个。如下:
int main()
{char arr1[] = "Hello";char arr2[20] = "xxxxxxxxxxxxxxxxx";strncpy(arr2, arr1, 10); //此时10大于arr1的元素个数,就会在后添加0直至够10个printf("%s\n", arr2);return 0;
}
2.2.2、strncat

- 区别也仅与strcat差一个参数,记录要操作的个数。
- 使用strncat追加,当结束追加时,就算没到\0,也会在末尾追加一个\0。
- 如果源字符串的长度小于num,则追加完源字符串之后,会自动停止追加。注意此处与strncpy的区别。
- 包含头文件<string.h>。
【使用方式】
int main()
{char arr1[20] = "Hello ";char arr2[] = "hacynn" ;strncat(arr1, arr2, 3);printf("%s\n", arr1);return 0;
}【运行结果】
2.2.3、strncmp

- 区别也仅与strcmp差一个参数,记录要操作的个数。
- 包含头文件<string.h>。
【使用方式】
int main()
{char arr1[] = "abcdef";char arr2[] = "abcz";if (strncmp(arr1, arr2, 3) > 0) //只比较前三个字符printf(">\n");else if (strncmp(arr1, arr2, 3) == 0)printf("=\n");elseprintf("<\n");return 0;
}【运行结果】

3、字符串查找函数
3.1、strstr

- 查找一个字符串中是否存在与另一个字符串当中,即找子串。
- 返回一个指向str1中第一个出现str2的指针,如果str2不是str1的一部分,则返回一个空指针NULL。
- 包含头文件<string.h>。
【使用方式】
可以看到,即使是有两个字串 ,也只会返回第一次出现的地址。
int main()
{char arr1[] = "abcdefghidef"; //def出现了两次char arr2[] = "def";char* ret = strstr(arr1, arr2);if (ret == NULL)printf("找不到\n");elseprintf("%s\n", ret);return 0;
}【运行结果】

【模拟实现strstr】
const char* my_strstr(const char* str1, const char* str2)
{if (*str2 == '\0')return str1;char* pc = str1; //pc用于记录开始匹配的位置while (*pc){char* s1 = pc; //遍历str1指向的字符串char* s2 = str2; //遍历str2指向的字符串while (*s1 && *s2 && (*s1 == *s2)){s1++;s2++;}if (*s2 == '\0')return pc;pc++;}return NULL;
}int main()
{char arr1[] = "abcdefghidef";char arr2[] = "def";char* ret = my_strstr(arr1, arr2);if (ret == NULL)printf("找不到\n");elseprintf("%s\n", ret);return 0;
}【图解】

3.2、strtok

比较奇葩的一个函数
char * strtok ( char * str, const char * delimiters );
- 切割字符串函数,例如hacynn@nash.com,当切割标记是@和 . 时,通过三次合理的使用可以切割出三个字符串:hacynn nash com
- 包含头文件<string.h>。
- delimiters参数是个字符串,定义了用作分隔符的字符集合。
- 第一个参数指定一个字符串,它包含了0个或者多个由delimiters字符串中一个或者多个分隔符分割的标记。
- strtok函数找到str中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针。(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。)
- strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置。
- strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标记。
- 如果字符串中不存在更多的标记,则返回 NULL 指针
【使用方式】
int main()
{char arr[] = "hacynn@nash.com";char buf[200] = { 0 }; //因为strtok会改变被操作字符串,//所以拷贝一个临时变量来操作strcpy(buf, arr);char* p = "@.";char* s = strtok(buf, p); //参数不为NULL,找到第一个标记printf("%s\n", s);s = strtok(NULL, p); //参数为NULL,找到下一个标记printf("%s\n", s);s = strtok(NULL, p); 参数为NULL,找到下一个标记printf("%s\n", s);return 0;【运行结果】

【使用方式优化 】
在实际开发中,我们不一定知道这个字符串是怎样的,这个字符串需要切割几次的,因此手动设置切割几次将代码写死的方式是不可取,而应该使用以下的方式进行自动切割。
int main()
{char arr[] = "hacynn@nash.com.hahaha@abcd";char buf[200] = { 0 };strcpy(buf, arr);char* p = "@.";char* s = NULL;for (s = strtok(buf, p); s != NULL; s = strtok(NULL, p)){printf("%s\n", s);}return 0;
}这里巧妙的运用了for函数的初始化部分只执行一次的特点,而strtok也只需要第一次传地址,其他时候都只需要传NULL就行。
【优化后的运行结果】

4、错误信息报告函数
4.1、strerror

- strerror函数是将错误码翻译成错误信息,返回错误信息的字符串起始地址。
- 包含头文件<string.h>。
- C语言中使用库函数的时候,如果发生错误,就会将错误码放在errno的变量中,errno是一个 全局变量,可以直接使用。
【错误码举例】
int main()
{int i = 0;for ( i = 0; i < 10; i++){printf("%d: %s\n", i, strerror(i));}return 0;
}每一个错误码都对应一个错误信息

【使用方式】
以打开文件为例子,fopen以读的形式打开文件,当文件存在时打开成功,文件不存在时打开失败,并返回空指针。可以利用这个来设置一个打开失败时的错误信息告知。
int main()
{FILE* pf = fopen("add.txt", "r"); //当前文件路径中并没有add.txt文件,打开失败if (pf == NULL){printf("打开文件失败,原因是:%s\n", strerror(errno));return 1;}else{printf("打开文件成功\n");}return 0;
}【运行结果】

4.2、perror

- perror也是用于翻译错误信息 ,但与strerror不同的是,perror会直接打印错误码所对应的错误信息。而perror中传递的字符串参数就是自定义显示信息的部分,打印的结果就是 自定义显示信息:错误信息
- 包含头文件<stdlib.h>
- 可以简单理解为:perror = printf + strerror 即翻译又打印
【使用方式】
int main()
{FILE* pf = fopen("add.txt", "r");if (pf == NULL){perror("打开文件失败"); //注意:此处是perror,不是printf。return 1;}else{printf("打开文件成功\n");}return 0;
}【运行结果】
5、字符函数
5.1、字符分类函数
字符分类函数使用非常简单,由于篇幅受限,在这里不就一一列举了 ,只需要把下面的图看懂就行。

5.2、字符转换函数
5.2.1、tolower

这个函数听名字就知道是用于将大写字母转换成小写字母,而这类函数唯一需要注意的就是函数有返回值,返回类型为int,因此在使用的时候最好使用一个int ret接收返回值。
int main()
{int ret = tolower('A');printf("%c\n", ret);
}5.2.2、toupper
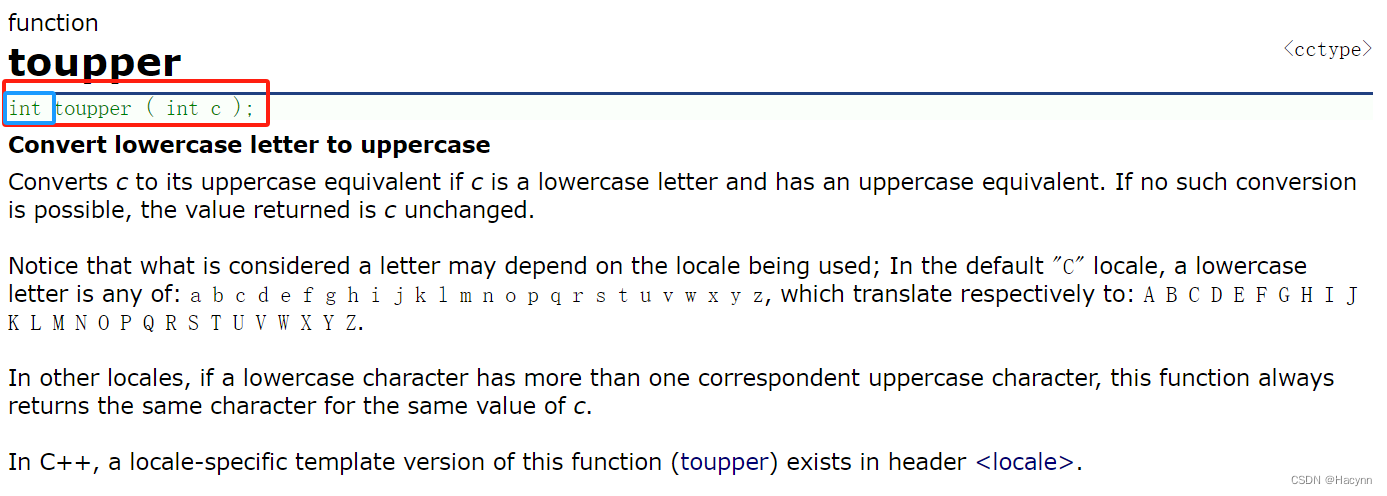
小写字母转大写字母,其他注意点与tolower一致。
6、内存操作函数
上文讲到的字符串函数只适用于字符串,但是内存中的数据不仅仅只有字符,这就导致这些函数有很大的局限性。因此需要有一个能够对所有类型的数据都适用的函数,这就是内存操作函数的出现的原因。下面我们来学习一下内存操作函数。
6.1、memcpy

- 函数memcpy从source的位置开始向后拷贝num个字节的数据到destination的内存位置。
- 包含头文件<string.h>
- 这个函数在遇到 '\0' 的时候并不会停下来。
- 如果source和destination有任何的重叠,复制的结果都是未定义的。
- 因为C语言标准中并未规定memcpy能适用于重叠内存的拷贝,因此不重叠内存的拷贝才使用memcpy,而重叠内存的拷贝使用接下来讲解的memmove函数。
【使用方式】
使用memcpy拷贝整型数据。
int main()
{int arr1[10] = { 0 };int arr2[] = { 1,2,3,4,5 };memcpy(arr1, arr2, sizeof(int) * 5);int i = 0;for ( i = 0; i < 5; i++){printf("%d ", arr1[i]);}return 0;
}【运行结果】

【模拟实现memcpy】
void* my_memcpy(void* dest, const void* src, size_t sz)
{void* ret = dest;while (sz){*(char*)dest = *(char*)src;dest = (char*)dest + 1;src = (char*)src + 1;sz--;}return ret;
}int main()
{int arr1[10] = { 0 };int arr2[] = { 1,2,3,4,5 };my_memcpy(arr1, arr2, sizeof(int) * 5);int i = 0;for ( i = 0; i < 5; i++){printf("%d ", arr1[i]);}return 0;
}6.2、memmove

- memmove的参数和功能与memcpy完全一致。
- 包含头文件<string.h>
- 唯一有区别的就是memmove函数处理的源内存块和目标内存块是可以重叠的。
- 因此当出现重叠内存的拷贝时,就使用memmove函数处理。
【模拟实现memmove】
void* my_memmove(void* dest, const void* src, size_t sz)
{void* ret = dest;if (dest < src){while (sz){*(char*)dest = *(char*)src;dest = (char*)dest + 1;src = (char*)src + 1;sz--;}}else{while (sz--){*((char*)dest + sz) = *((char*)dest + sz);}}return ret;
}int main()
{int arr1[] = { 1,2,3,4,5 ,6,7,8,9,10 };my_memmove(arr1, arr1+2, sizeof(int) * 5);int i = 0;for (i = 0; i < 10; i++){printf("%d ", arr1[i]);}return 0;
}6.3、memset

- 将ptr所指向空间的前num个字节设置为指定值value。
- 包含头文件<string.h>
【使用方式】
int main()
{char arr[] = "hello world";memset(arr + 6, 'x', 3);printf("%s\n", arr);return 0;
}【运行结果】

6.4、memcmp
- 比较ptr1和ptr2前num个字节的内容。
- 包含头文件<string.h>
- 标准规定:
ptr1大于ptr2,则返回大于0的数字。
ptr1等于ptr2,则返回0。
ptr1小于ptr2,则返回小于0的数字。
 【使用方式】
【使用方式】
int main()
{int arr1[] = { 1,2,3,4,5,6,7 };int arr2[] = { 1,2,3,7 };int ret = memcmp(arr1, arr2, sizeof(int) * 3);printf("%d\n", ret);
}【运行结果】
如果觉得作者写的不错,求给博主一个大大的点赞支持一下,你们的支持是我更新的最大动力!
如果觉得作者写的不错,求给博主一个大大的点赞支持一下,你们的支持是我更新的最大动力!
如果觉得作者写的不错,求给博主一个大大的点赞支持一下,你们的支持是我更新的最大动力!
相关文章:
一篇博客学会系列(1) —— C语言中所有字符串函数以及内存函数的使用和注意事项
目录 1、求字符串长度函数 1.1、strlen 2、字符串拷贝(cpy)、拼接(cat)、比较(cmp)函数 2.1、长度不受限制的字符串函数 2.1.1、strcpy 2.1.2、strcat 2.1.3、strcmp 2.2、长度受限制的字符串函数 2.2.1、strncpy 2.2.2、strncat 2.2.3、strncmp 3、字符串查找函数…...
计算机视觉与深度学习-循环神经网络与注意力机制-RNN(Recurrent Neural Network)、LSTM-【北邮鲁鹏】
目录 举例应用槽填充(Slot Filling)解决思路方案使用前馈神经网络输入1-of-N encoding(One-hot)(独热编码) 输出 问题 循环神经网络(Recurrent Neural Network,RNN)定义如何工作学习目标深度Elm…...
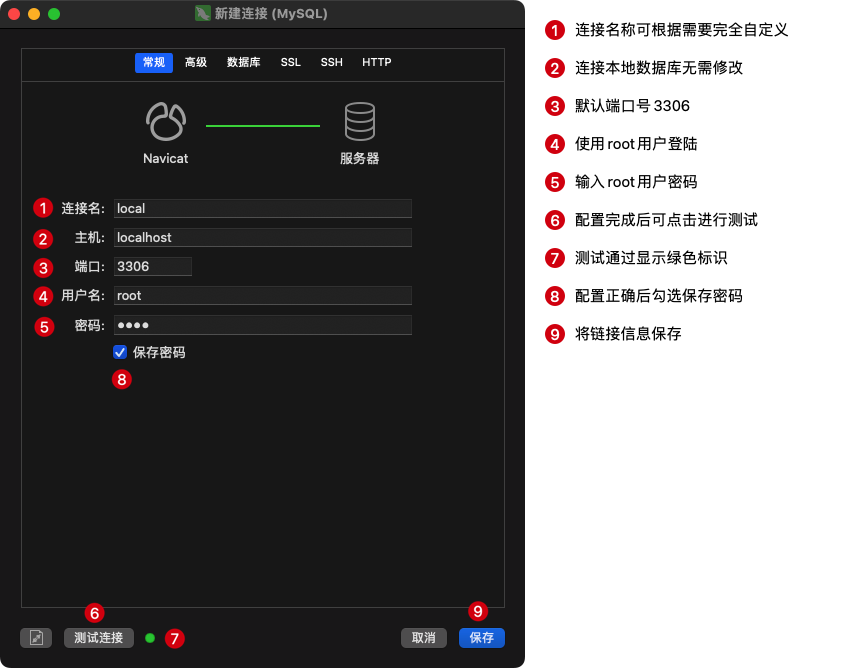
brew 安装MySQL 5.7
写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成…...

【中国知名企业高管团队】系列22:滴滴
大家好! 今天华研荟的走进中国知名企业高管团队系列带大家认识滴滴。 滴滴公司是出行领域的先行者,也是一个典型样本。通过滴滴公司的名字变迁我们可以感受到滴滴公司的业务发展,这也是整个出行行业公司的发展路径: 第一阶段&a…...

Unity之Hololens如何实现3D物体交互
一.前言 什么是Hololens? Hololens是由微软开发的一款混合现实头戴式设备,它将虚拟内容与现实世界相结合,为用户提供了沉浸式的AR体验。Hololens通过内置的传感器和摄像头,能够感知用户的环境,并在用户的视野中显示虚拟对象。这使得用户可以与虚拟内容进行互动,将数字信…...
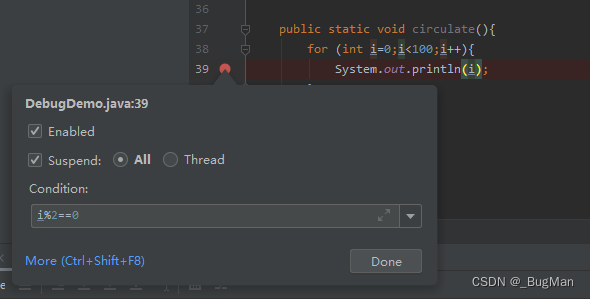
IDEA Debug技巧大全,看完就能提升工作效率
作者简介 目录 1.行断点 2.方法断点 3.异常断点 4.字段断点 5.条件表达式 1.行断点 行断点就是平时我们在代码行旁边单击鼠标打上的断点,这个没有什么好说的。关键点在于很多人不知道的,行断点其实是可以右击选择是对改行的全部调用都生效…...

蓝桥等考Python组别六级003
第一部分:选择题 1、PythonL6(15分) 运行下面的程序,输出的值最大可能是()。 importrandom print(random.randint(2,4)*5) 10152030正确答案:C 2、PythonL6(15分) 甲、乙、丙三个人赛跑,已知甲不是第一名,乙不是第二名,名次没有并列的。...
机器学习小白理解之一元线性回归
关于机器学习,百度上一搜一大摞,总之各有各的优劣,有的非常专业,有的看的似懂非懂。我作为一名机器学习的门外汉,为了看懂这些公式和名词真的花了不少时间,还因此去着重学了高数。 不过如果不去看公式&…...

目标检测:FROD: Robust Object Detection for Free
论文作者:Muhammad,Awais,Weiming,Zhuang,Lingjuan,Lyu,Sung-Ho,Bae 作者单位:Sony AI; Kyung-Hee University 论文链接:http://arxiv.org/abs/2308.01888v1 内容简介: 1)方向:目标检测 2)…...
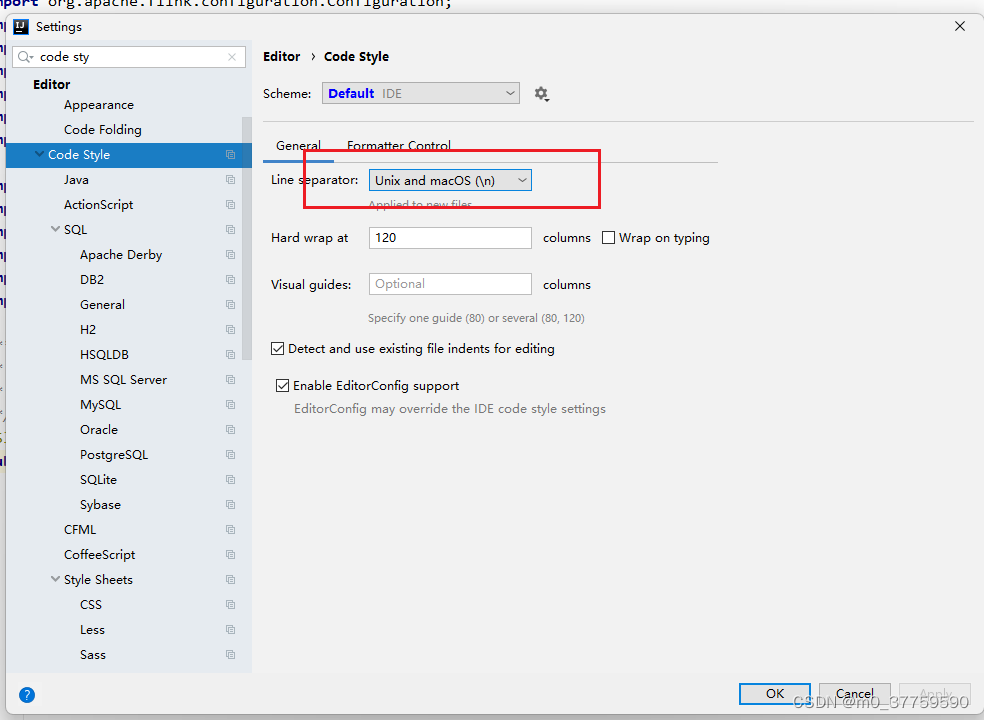
linux 和 windows的換行符不兼容問題
linux 和 windows的換行符: 1.vim 模式下,執行命令: :set ffunix idea中設置code style...
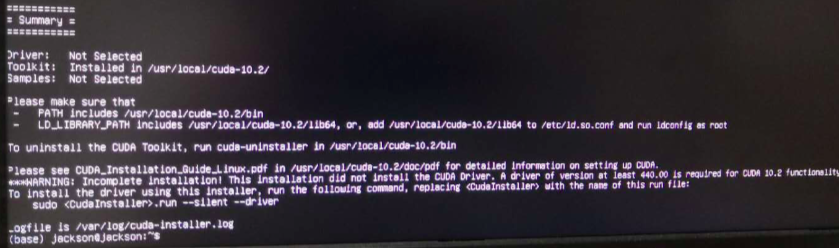
ubuntu 20 安装 CUDA
1. 查看需要安装的cuda版本 nvidia-smi cuda的版本信息如下图所示 2. 去官网下载对应版本的CUDA 官网:CUDA Toolkit Archive | NVIDIA Developer 弹出以下界面,依次点击以下按钮 得到以下内容: 复制下载链接,下载cuda11到本…...

C++友元函数和友元类
友元介绍 类的友元函数是定义在类外部,但有权访问类的所有私有(private)成员和保护(protected)成员。尽管友元函数的原型有在类的定义中出现过,但是友元函数并不是成员函数。 友元可以是一个函数…...
特斯拉——使用人工智能制造智能汽车
特斯拉(Tesla)是电动汽车开发和推广的先驱。特斯拉对自动驾驶汽车的未来寄予厚望--实际上,每一辆特斯拉汽车都有可能通过软件升级成为自动驾驶汽车。该公司还生产和销售高级电池和太阳能电池板。 汽车的自动驾驶是按从1~5的等级划分的。自适应巡航控制和自动停车系…...

如何删除gitlab上多余的文件夹
无意间在提交代码时,包含了多余的 .idea 或者 __pychche__ 缓存文件夹等等,如何一次性删除呢? 实际上没有更好的办法,如果还没有合并,close 掉 MR就行了,重新提交。 如果已经合并了,就会留下记…...

computed和methods有什么区别
面试题:computed和methods有什么区别 标准而浅显的回答 在使用时,computed当做属性使用,而methods则当做方法调用computed可以具有getter和setter,因此可以赋值,而methods不行computed无法接收多个参数,而m…...
、聚集索引、二级索引(索引篇 二))
MySQL索引分类和操作(增删查)、聚集索引、二级索引(索引篇 二)
具体类型索引分类 分类主要作用特点主键索引(primary)针对于表中主键创建的索引默认自动创建, 只能有一个唯一索引(unique)避免同一个表中某数据列中的值重可以有多个常规索引最基本类型,可以加快查询速度可以有多个全文索引(fulltext)查找的是文本中的关键词&…...
(三)Python变量类型和运算符
所有的编程语言都支持变量,Python 也不例外。变量是编程的起点,程序需要将数据存储到变量中。 变量在 Python 内部是有类型的,比如 int、float 等,但是我们在编程时无需关注变量类型,所有的变量都无需提前声明&#x…...

vue三种import导入方式详解?
在Vue.js中,你可以使用三种不同的方式来导入模块或组件: 默认导入 (Default Import): 这种方式用于导入一个模块的默认导出(通常是一个组件或一个对象)。例如: import MyComponent from ./MyComponent.vue;…...

深入理解数据库视图
在数据库管理中,视图(View)是一种强大但常常被忽视的功能。它不仅可以简化复杂的查询操作,还可以提供更高层次的数据抽象和保护。 本文将详细解析视图的各个方面,并以《三国志》游戏的数据为例,给出实际应用场景。 文章目录 什么是视图?基本结构创建视图查看视图的定义…...
方法的作用~)
Java中@before和setup()方法的作用~
在Java中,setup()和Before同时使用的作用是在测试方法之前执行一些准备工作, setup()是JUnit中的一个方法,它通常被用来初始化测试对象和设置测试环境,它会在每个测试方法执行之前被调用,并且可以在多个测试方法中共享…...

抖音视频批量下载:从零掌握双版本工具的完整实战指南
抖音视频批量下载:从零掌握双版本工具的完整实战指南 【免费下载链接】douyin-downloader 项目地址: https://gitcode.com/GitHub_Trending/do/douyin-downloader 在短视频内容日益丰富的今天,如何高效批量下载抖音视频成为许多内容创作者和研究…...

Onekey:Steam游戏清单管理的自动化解决方案 | 玩家与开发者必备工具
Onekey:Steam游戏清单管理的自动化解决方案 | 玩家与开发者必备工具 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 当独立游戏开发者小林第三次因为手动复制Steam App ID出错而导致…...

5款部署方案的开源UML工具:开发者与设计师的高效协作绘图平台
5款部署方案的开源UML工具:开发者与设计师的高效协作绘图平台 【免费下载链接】umlet Free UML Tool for Fast UML Diagrams 项目地址: https://gitcode.com/gh_mirrors/um/umlet 开源UML工具UMLet是一款专为高效绘图设计的跨平台解决方案,它通过…...

Fillinger终极指南:Illustrator智能填充脚本如何10倍提升你的设计效率
Fillinger终极指南:Illustrator智能填充脚本如何10倍提升你的设计效率 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 你是否曾在Illustrator中为了填充图案而花费数小时…...

哔哩哔哩第三方开放平台软件bilipai7.0.2
bilipai是一款面向B站内容爱好者的第三方安卓客户端,它有着清新灵动的界面风格和流畅自然的操作体验,能完整同步B站的各类视频资源,包括番剧、动画、知识科普、生活分享等内容类别,用户登录账号后,还可以实时同步自己的…...

桌面歌词工具:LyricsX让Mac音乐体验全面升级
桌面歌词工具:LyricsX让Mac音乐体验全面升级 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics 在Mac上享受音乐时,你是否曾因无法显示桌面歌词而感到…...

brpc代码重构原则:保持兼容性与提升性能并重的终极指南
brpc代码重构原则:保持兼容性与提升性能并重的终极指南 【免费下载链接】brpc brpc is an Industrial-grade RPC framework using C Language, which is often used in high performance system such as Search, Storage, Machine learning, Advertisement, Recomme…...

自动驾驶避障实战:人工势场法的核心原理与MATLAB仿真
1. 人工势场法基础概念 第一次接触人工势场法是在研究生阶段的机器人学课程上,当时教授用了一个非常形象的比喻:想象你手里拿着一块磁铁,目标点是一块异性磁极的磁铁,障碍物则是同性磁极的磁铁。这个简单的物理现象,就…...

概率神经网络的分类预测:基于PNN网络的变压器故障诊断应用研究及对比实验(附Matlab源代码...
概率神经网络的分类预测 基于pnn网络变压器故障诊断 应用研究及对比实验 matlab源代码 代码有详细注释,完美运行变压器故障诊断这事儿听起来挺玄乎,但用概率神经网络(Probabilistic Neural Network)来处理就跟开挂似的。我最近在M…...

TargetMol明星分子—— Eragidomide Mezigdomide
Eragidomide ,别名 CC-90009、 Cereblon modulator 1,是一种 GSPT1 选择性 cereblon (CRBN) E3 泛素连接酶调节剂,以分子胶的方式作用。它通过 CRL4CRBN 选择性靶向 GSPT1 进行泛素化和蛋白酶体降解。 Mezigdomide 货号 T10703,别…...