分布式文件存储系统minio、大文件分片传输
上传大文件
1、Promise对象
Promise 对象代表一个异步操作,有三种状态:
- pending: 初始状态,不是成功或失败状态。
- fulfilled: 意味着操作成功完成。
- rejected: 意味着操作失败。
只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态
有了 Promise 对象,就可以将异步操作以同步操作的流程表达出来,避免了层层嵌套的回调函数
//定义异步操作
var promise = new Promise (function (resolve,reject)) {// ... some code if(/* 异步操作成功 */){resolve(value)} else {reject(error)}
}//异步操作的回调(写法一)
promise.then( function( result ) {// result ==上面的valueconsole.log("fulfilled:",val)
}).catch(function (error){// error==上面的errorconsole.log('rejected',err)
});//异步操作的回调(写法二)
promise.then((result) => console.log("fulfilled:",result)).catch((error) =>console.log('rejected',error));Promise.all()
除了串行执行若干异步任务外,Promise还可以并行执行异步任务。
Promise.all() 可以将多个Promise实例包装成一个新的Promise实例;
const p = Promise.all([p1, p2, p3]);
p的状态由p1、p2、p3决定,分成两种情况。(1)只有
p1、p2、p3的状态都变成fulfilled,p的状态才会变成fulfilled,此时p1、p2、p3的返回值组成一个数组,传递给p的回调函数。(2)只要
p1、p2、p3之中有一个被rejected,p的状态就变成rejected,此时第一个被reject的实例的返回值,会传递给p的回调函数。
曾经困扰我的一个问题
<button @click="bbb">异步调用</button>异步的写法
//异步的bbb() {let arr = [];for (let index = 0; index < 15; index++) {arr.push(this.aaa(index));}//使用之前不希望调用console.log(arr);},aaa(i) {return new Promise((resolve, reject) => {setTimeout(() => {console.log("i", i);resolve(i);this.a++;}, 200 - 5 * i);});},同步的写法
bbb() {let arr = [];let p = undefined;for (let index = 0; index < 15; index++) {if (index == 0) {p = this.aaa(index);} else {//获取上一个p = this.aaa(index, p);}}//使用之前不希望调用console.log(p);},aaa(i, promise) {if (i == 0) {return new Promise((resolve, reject) => {setTimeout(() => {console.log("i", i);resolve(i);this.a++;}, 200 - 5 * i);});} else {return promise.then((value) => {return new Promise((resolve, reject) => {setTimeout(() => {console.log("i", i);resolve(i);this.a++;}, 200 - 5 * i);});});}},2、Blob对象和File 对象
Blob对象
Blob对象有一个slice方法,返回一个新的
Blob对象,包含了源Blob对象中制定范围内的数据。var blob = instanceOfBlob.slice([start [, end [, contentType]]]};参数说明:
start: 可选,代表 Blob 里的下标,表示第一个会被会被拷贝进新的 Blob 的字节的起始位置。如果传入的是一个负数,那么这个偏移量将会从数据的末尾从后到前开始计算。
end: 可选,代表的是 Blob 的一个下标,这个下标-1的对应的字节将会是被拷贝进新的Blob 的最后一个字节。如果你传入了一个负数,那么这个偏移量将会从数据的末尾从后到前开始计算。
contentType可选给新的 Blob 赋予一个新的文档类型。这将会把它的 type 属性设为被传入的值。它的默认值是一个空的字符串。
通过slice方法,从blob1中创建出一个新的blob对象,size等于3。
var data = "abcdef";
var blob1 = new Blob([data]);
var blob2 = blob1.slice(0,3);console.log(blob1); //输出:Blob {size: 6, type: ""}
console.log(blob2); //输出:Blob {size: 3, type: ""}File继承字Blob,因此我们可以调用slice方法对大文件进行分片上传。
3、FileReader函数
FileReader的使用方式非常简单分为三个步骤:
1.创建FileReader对象 2.读取文件 3.处理文件读取事件(完成,中断,错误等...)
创建FileReader对象
let reader = new FileReader();
读取文件
FileReader 的实例拥有 4 个方法,其中 3 个用以读取文件,另一个用来中断读取。
上面的表格列出了这些方法以及他们的参数和功能,需要注意的是 ,无论读取成功或失败,方法并不会返回读取结果, 这一结果存储在 result属性中。
方法名 参数 描述 abort 无 中断读取 readAsBinaryString file 将文件读取为二进制码 readAsDataURL file 将文件读取为 DataURL readAsText file, [文件编码] 将文件读取为文本 //1.将文件读取为二进制数据 reader.readAsBinaryString(file); //2.将文件读取为文本数据 reader.readAsText(file,"UTF-8")
读取事件
FileReader包含了一套完整的事件模型,用于捕获读取文件时的状态,下面这个表格归纳了这些事件。
事件 描述 onabort 中断时触发 onerror 出错时触发 onload 文件读取成功完成时触发 onloadend 读取完成触发,无论成功或失败 onloadstart 读取开始时触发 onprogress 读取中
完整读取示例
//1.获取文件对象let file = data.file;//2.创建FileReader对象,用于读取文件let reader = new FileReader();//3.将文件读取为二进制码reader.readAsBinaryString(file);//4.处理读取事件//4.1读取完成事件,获取数据reader.onload = (e) => {//获取数据const data = e.currentTarget.result;};//4.2 //读取中断事件reader.onabort = () => {console.log('读取中断了');};4、前端文件转MD5
MD5计算将整个文件或者字符串,通过其不可逆的字符串变换计算,产生文件或字符串的MD5散列值。
因此MD5常用于校验文件,以防止文件被“篡改”。因为如果文件、字符串的MD5散列值不一样,说明文件内容也是不一样的
安装依赖
npm install spark-md5 --save导包
import SparkMD5 from 'spark-md5'要配合js的 FileReader 函数来使用 SparkMD5
const getFileMD5 = (file:File) => {return new Promise((resolve, reject) => {const spark = new SparkMD5.ArrayBuffer()const fileReader = new FileReader()fileReader.onload = (e:any) => {spark.append(e.target.result)resolve(spark.end())}fileReader.onerror = () => {reject('')}fileReader.readAsArrayBuffer(file)})
}6、
Minio基本知识
minio下载启动
minio:对象存储服务。一个对象文件可以是任意大小,从几kb到最大5T不等
中文网站: MinIO | 高性能分布式存储,私有云存储
下载后:新建一个minioData文件夹用来存储上传的文件

在minio.exe文件夹的路径处输入cmd进入命令行界面(该exe文件不能双击运行)
输入命令:minio.exe server E:\server\minio\install\minioData

接着访问:http://localhost:9000/
用户名和密码都是minioadmin

基础概念
Object:存储到minio中的基本对象,如文件、字节流
Bucket:存放文件的顶层目录,起到一个隔离的作用
Drive:存储数据的磁盘
mc客户端使用
MinIO 提供客户端工具访问和操作服务端。MinIO 客户端工具 mc(minio client)
提供了类似 unix 的命令去操作服务端。mc 相关命令列表如下所示(请查看英文官网):
ls 列出文件和文件夹。
mb 创建一个存储桶或一个文件夹。
cat 显示文件和对象内容。
pipe 将一个STDIN重定向到一个对象或者文件或者STDOUT。
share 生成用于共享的URL。
cp 拷贝文件和对象。
mirror 给存储桶和文件夹做镜像。
find 基于参数查找文件。
diff 对两个文件夹或者存储桶比较差异。
rm 删除文件和对象。
events 管理对象通知。
watch 监听文件和对象的事件。
policy 管理访问策略。
session 为cp命令管理保存的会话。
config 管理mc配置文件。
update 检查软件更新。
version 输出版本信息。
![]()
查看 minio服务端
mc config host ls添加服务端
mc config host add xiayumao_minio http://127.0.0.1:9000 minioadmin minioadmin再次查看
删除服务端
mc config host remove xiayumao_miniomc config host add minio-server http://127.0.0.1:9000 minioadmin minioadmin

查看
ls命令列出文件、对象和存储桶。
-----------------
创建桶
mc mb minio-server/sringcloud
递归创建桶,对吗?
mc mb minio-server/nacos/2023/9/23



springboot整合minio
依赖和配置
<dependency><groupId>io.minio</groupId><artifactId>minio</artifactId><version>8.2.1</version>
</dependency>application.yml 配置信息
minio:endpoint: http://127.0.0.1:9000 #Minio服务所在地址accessKey: minioadmin #账号secretKey: minioadmin #密码注入MinioClient
关于 MinIO 的一切操作都得通过 MinioClient 对象来进行
@Data
@Configuration
@ConfigurationProperties(prefix = "minio")
public class MinioConfig {private String endpoint;private String accessKey;private String secretKey;@Beanpublic MinioClient minioClient() {return MinioClient.builder().endpoint(endpoint)//服务地址.credentials(accessKey, secretKey)//账号 密码.build();}
}MinioUtil封装桶操作
@Component
@Slf4j
public class MinioUtil {@Resourceprivate MinioClient minioClient;/*** 查看存储bucket是否存在** @return boolean*/public Boolean bucketExists(String bucketName) {Boolean found;try {found = minioClient.bucketExists(BucketExistsArgs.builder().bucket(bucketName).build());} catch (Exception e) {e.printStackTrace();return false;}return found;}/*** 创建存储bucket** @return Boolean*/public Boolean makeBucket(String bucketName) {try {minioClient.makeBucket(MakeBucketArgs.builder().bucket(bucketName).build());} catch (Exception e) {e.printStackTrace();return false;}return true;}/*** 删除存储bucket** @return Boolean*/public Boolean removeBucket(String bucketName) {try {//删除一个空桶minioClient.removeBucket(RemoveBucketArgs.builder().bucket(bucketName).build());} catch (Exception e) {e.printStackTrace();return false;}return true;}/*** 获取全部bucket*/public List<Bucket> getAllBuckets() {try {return minioClient.listBuckets();} catch (Exception e) {e.printStackTrace();}return null;}/*** 列出存储桶中的所有对象** @param bucketName 存储桶名称* @return* @throws Exception*/public Iterable<Result<Item>> listObjects(String bucketName) {boolean flag = bucketExists(bucketName);if (flag) {return minioClient.listObjects(ListObjectsArgs.builder().bucket(bucketName).build());}return null;}/*** 递归查询桶下对象** @param bucketName 存储桶名称* @return* @throws Exception*/public Iterable<Result<Item>> recursiveListObjects(String bucketName) {boolean flag = bucketExists(bucketName);if (flag) {return minioClient.listObjects(ListObjectsArgs.builder().bucket(bucketName).recursive(true).build());}return null;}/*** 列出某个桶中的所有文件名* 文件夹名为空时,则直接查询桶下面的数据,否则就查询当前桶下对于文件夹里面的数据** @param bucketName 桶名称* @param folderName 文件夹名* @param isDeep 是否递归查询*/public Iterable<Result<Item>> getBucketAllFile(String bucketName, String folderName, Boolean isDeep) {if (!StringUtils.hasLength(folderName)) {folderName = "";}System.out.println(folderName);Iterable<Result<Item>> listObjects = minioClient.listObjects(ListObjectsArgs.builder().bucket(bucketName).prefix(folderName + "/").recursive(isDeep).build());return listObjects;}/*** 创建文件夹** @param bucketName 桶名* @param folderName 文件夹名称* @return* @throws Exception*/public ObjectWriteResponse createBucketFolder(String bucketName, String folderName) throws Exception {if (!bucketExists(bucketName)) {throw new RuntimeException("必须在桶存在的情况下才能创建文件夹");}if (!StringUtils.hasLength(folderName)) {throw new RuntimeException("创建的文件夹名不能为空");}PutObjectArgs putObjectArgs = PutObjectArgs.builder().bucket(bucketName).object(folderName + "/").stream(new ByteArrayInputStream(new byte[0]), 0, 0).build();ObjectWriteResponse objectWriteResponse = minioClient.putObject(putObjectArgs);return objectWriteResponse;}
}创建桶和文件夹
通过MinioClient 对象,指定 Bucket 即可进行相应的操作。
桶操作接口测试
@Slf4j
@RestController
@RequestMapping(value = "product/file")
public class FileController {@Autowiredprivate MinioUtil minioUtil;@Autowiredprivate MinioConfig prop;//查看存储bucket是否存在@GetMapping("/bucketExists")public Boolean bucketExists(@RequestParam("bucketName") String bucketName) {return minioUtil.bucketExists(bucketName);}//创建存储bucket@GetMapping("/makeBucket")public Boolean makeBucket(String bucketName) {return minioUtil.makeBucket(bucketName);}//删除存储bucket@GetMapping("/removeBucket")public Boolean removeBucket(String bucketName) {return minioUtil.removeBucket(bucketName);}
}新创建桶ipadmini6下,创建文件夹
//创建文件夹 @GetMapping("/createBucketFolder") public void createBucketFolder(String bucketName) throws Exception {String folderName = "aa/bb";ObjectWriteResponse response = minioUtil.createBucketFolder(bucketName, folderName); }递归查询桶ipadmini6下所有对象
桶中对象信息查询
查询所有的桶
//获取全部bucket @GetMapping("/getAllBuckets") public List getAllBuckets() {List<Bucket> allBuckets = minioUtil.getAllBuckets();allBuckets.forEach(bucket -> {System.out.printf("存储桶名:%s,创建时间:%s \n", bucket.name(), bucket.creationDate());});return allBuckets; }

查询桶下所有对象
//查询桶下所有对象 @GetMapping("/listObjects") public void listObjects(@RequestParam("bucketName") String bucketName) throws Exception {Iterable<Result<Item>> listObjects = minioUtil.listObjects(bucketName);for (Result<Item> result : listObjects) {Item item = result.get();System.out.println(item.objectName() + "\t" + item.size());} }
控制台打印:


递归查询桶下所有对象
//递归查询桶下所有对象@GetMapping("/recursiveListObjects")public void recursiveListObjects(@RequestParam("bucketName") String bucketName) throws Exception {Iterable<Result<Item>> listObjects = minioUtil.recursiveListObjects(bucketName);for (Result<Item> result : listObjects) {Item item = result.get();System.out.println(item.objectName() + "\t" + item.size());}}控制台打印:

指定前缀查询桶下所有对象
//指定前缀查询 @GetMapping("/getBucketAllFile") public void getBucketAllFile(@RequestParam("bucketName") String bucketName) throws Exception {Iterable<Result<Item>> listObjects = minioUtil.getBucketAllFile(bucketName,"兰兰/img",true);for (Result<Item> result : listObjects) {Item item = result.get();System.out.println(item.objectName() + "\t" + item.size());} }

文件上传下载
上传本地文件(path)
OSS没有文件夹的概念,所有资源都是以文件来存储,但您可以通过创建一个以正斜线(/)结尾,大小为0的Object来创建模拟文件夹。
MinioUtil中继续新增
/*** 上传本地文件,根据路径上传* minio 采用文件内容上传,可以换成上面的流上传** @param filePath 上传本地文件路径* @Param bucketName 上传至服务器的桶名称*/
public boolean uploadPath(String filePath, String bucketName) throws Exception {File file = new File(filePath);if (!file.isFile()) {throw new RuntimeException("上传文件为空,请重新上传");}if (!StringUtils.hasLength(bucketName)) {throw new RuntimeException("传入桶名为空,请重新上传");}if (!this.bucketExists(bucketName)) {throw new RuntimeException("当前操作的桶不存在!");}String minioFilename = UUID.randomUUID().toString() + "_" + file.getName();//获取文件名称String fileType = minioFilename.substring(minioFilename.lastIndexOf(".") + 1);minioClient.uploadObject(UploadObjectArgs.builder().bucket(bucketName).object(minioFilename)//文件存储在minio中的名字.filename(filePath)//上传本地文件存储的路径.contentType(fileType)//文件类型.build());return this.getBucketFileExist(minioFilename, bucketName);
}上传后,结果只能在桶下吗

- objectName,是指文件的路径,即存储桶下文件的相对路径
略微修改一下objectName

再上传,就能看到

上传文件(MultipartFile)
MinioUtil中继续新增
使用的是建造者模式,创建PutObjectArgs参数对象
/*** 根据MultipartFile file上传文件* minio 采用文件流上传,可以换成下面的文件上传** @param file 上传的文件* @param bucketName 上传至服务器的桶名称*/public boolean uploadFile(MultipartFile file, String bucketName) throws Exception {if (file == null || file.getSize() == 0 || file.isEmpty()) {throw new RuntimeException("上传文件为空,请重新上传");}if (!this.bucketExists(bucketName)) {throw new RuntimeException("当前操作的桶不存在!");}// 获取上传的文件名String filename = file.getOriginalFilename();assert filename != null;//可以选择生成一个minio中存储的文件名称String minioFilename = UUID.randomUUID().toString() + "_" + filename;InputStream inputStream = file.getInputStream();long size = file.getSize();String contentType = file.getContentType();// Upload known sized input stream.minioClient.putObject(PutObjectArgs.builder().bucket(bucketName) //上传到指定桶里面.object(minioFilename)//文件在minio中存储的名字//p1:上传的文件流;p2:上传文件总大小;p3:上传的分片大小.stream(inputStream, size, -1) //上传分片文件流大小,如果分文件上传可以采用这种形式.contentType(contentType) //文件的类型.build());return this.getBucketFileExist(minioFilename, bucketName);}再去尝试上传一个很大的(433MB)文件,报错
报错的原因是: springBoot项目自带的tomcat对上传的文件大小有默认的限制,SpringBoot官方文档中展示:每个文件的配置最大为1Mb,单次请求的文件的总数不能大于10Mb。

文件大小限制配置
重新指定最大限制
spring:servlet:multipart:enabled: truemax-file-size: 500MBmax-request-size: 500MB- spring.servlet.multipart.enabled:表示是否开启文件上传支持,默认为 true
- spring.servlet.multipart.file-size-threshold:表示文件写入磁盘的阀值,默认为 0
- spring.servlet.multipart.location:表示上传文件的临时保存位置
- spring.servlet.multipart.max-file-size:表示上传的单个文件的最大大小,默认为 1MB
- spring.servlet.multipart.max-request-size:表示多文件上传时文件的总大小,默认为 10MB
- spring.servlet.multipart.resolve-lazily:表示文件是否延迟解析,默认为 false
重新调用 上传文件(MultipartFile)

文件下载(path)
MinioUtil中继续新增
/*** 文件下载到指定路径** @param downloadPath 下载到本地路径* @param bucketName 下载指定服务器的桶名称* @param objectName 下载的文件名称*/
public void downloadPath(String downloadPath, String bucketName, String objectName) throws Exception {if (downloadPath.isEmpty() || !StringUtils.hasLength(bucketName) || !StringUtils.hasLength(objectName)) {throw new RuntimeException("下载文件参数不全!");}if (!new File(downloadPath).isDirectory()) {throw new RuntimeException("本地下载路径必须是一个文件夹或者文件路径!");}if (!this.bucketExists(bucketName)) {throw new RuntimeException("当前操作的桶不存在!");}downloadPath += objectName;minioClient.downloadObject(DownloadObjectArgs.builder().bucket(bucketName) //指定是在哪一个桶下载.object(objectName)//是minio中文件存储的名字;本地上传的文件是user.xlsx到minio中存储的是user-minio,那么这里就是user-minio.filename(downloadPath)//需要下载到本地的路径,一定是带上保存的文件名;如 d:\\minio\\user.xlsx.build());
}文件预览
在分片上传的时候如果没有设置分片类型,会默认设置分片类型为application/octet-stream。这样的话不能在线观看,只能够进行下载再查看资源,从而不利于前端直接引用地址。
大文件分片(前端传)
CustomMinioClient
思路:
- 前端对文件进行切片,并且记录切片总数
- 访问后端预上传接口,该接口仅仅处理目标文件上传url并且返回给前端,没有太多的资源占用。
- 前端获取到返回的预上传url后,循环分片进行上传。
- 在前端上传完分片后,请求后端文件合并接口对目标分片进行合并。
这样可以最大限度的利用前端的性能,而不是只发请求到后端,并且实现了前端直接对接minio服务器的功能。
public class CustomMinioClient extends MinioClient {public CustomMinioClient(MinioClient client) {super(client);}/*** 创建分片上传请求** @param bucket 存储桶* @param region 区域* @param object 对象名* @param headers 消息头* @param extraQueryParams 额外查询参数*/public String initMultiPartUpload(String bucket, String region, String object, Multimap<String, String> headers, Multimap<String, String> extraQueryParams) throws Exception {CreateMultipartUploadResponse response = this.createMultipartUpload(bucket, region, object, headers, extraQueryParams);return response.result().uploadId();}/*** 完成分片上传,执行合并文件** @param bucketName 存储桶* @param region 区域* @param objectName 对象名* @param uploadId 上传ID* @param parts 分片* @param extraHeaders 额外消息头* @param extraQueryParams 额外查询参数*/public ObjectWriteResponse mergeMultipartUpload(String bucketName, String region, String objectName, String uploadId, Part[] parts, Multimap<String, String> extraHeaders, Multimap<String, String> extraQueryParams) throws Exception {return this.completeMultipartUpload(bucketName, region, objectName, uploadId, parts, extraHeaders, extraQueryParams);}/*** 查询分片数据** @param bucketName 存储桶* @param region 区域* @param objectName 对象名* @param uploadId 上传ID* @param extraHeaders 额外消息头* @param extraQueryParams 额外查询参数*/public ListPartsResponse listMultipart(String bucketName, String region, String objectName, Integer maxParts, Integer partNumberMarker, String uploadId, Multimap<String, String> extraHeaders, Multimap<String, String> extraQueryParams) throws Exception {return this.listParts(bucketName, region, objectName, maxParts, partNumberMarker, uploadId, extraHeaders, extraQueryParams);}
}分片规则

在构建InputStream时,会进行分片操作,我们可以了解到上传文件大小的一些限制:
- 分片大小不能小于5MB,大于5GB
- 对象大小不能超过5TiB
- partSize传入-1,默认按照5MB进行分割
- 分片数量不能超过10000
分片规则如下:
// 参数为 文件大小objectSize、分片大小partSize,分片数我们传入的是-1,表示使用默认配置protected long[] getPartInfo(long objectSize, long partSize) {// 1. 校验大小,如果设置的分片大小 小于5M或者大于5GB,报错不支持// 对象大小超过5TiB,报错不支持this.validateSizes(objectSize, partSize);if (objectSize < 0L) {return new long[]{partSize, -1L};} else {// 2. 没有设置分片数据大小,怎按照默认的5M进行分割if (partSize <= 0L) {double dPartSize = Math.ceil((double)objectSize / 10000.0D);dPartSize = Math.ceil(dPartSize / 5242880.0D) * 5242880.0D;partSize = (long)dPartSize;}if (partSize > objectSize) {partSize = objectSize;}long partCount = partSize > 0L ? (long)Math.ceil((double)objectSize / (double)partSize) : 1L;// 3. 分片数量不能超过10000if (partCount > 10000L) {throw new IllegalArgumentException("object size " + objectSize + " and part size " + partSize + " make more than " + 10000 + "parts for upload");} else {// 4. 返回一个数组,第一个值为分片数据大小,第二个为分片数量return new long[]{partSize, partCount};}}}
创建分片请求(获取uploadId)
createMultipartUpload方法会创建分块请求,根据对象名和存储桶名去Minio获取上传当前对象的uploadId。
uploadId在循环中使用的都是同一个,说明分片上传的时候都会使用同一个uploadId,最后合并同一个uploadId的文件。
用户调用初始化接口,后端调用minio初始化,得到uploadId,生成每个分片的minio上传url
/*** 初始化分片上传** @param bucket 桶* @param objectName 文件全路径名称* @param partCount 分片数量* @param contentType 类型,如果类型使用默认流会导致无法预览* @return /*/public Map<String, Object> initMultiPartUpload(String bucket, String objectName, int partCount, String contentType) {Map<String, Object> result = new HashMap<>();try {if (StrUtil.isBlank(contentType)) {contentType = "application/octet-stream";}HashMultimap<String, String> headers = HashMultimap.create();headers.put("Content-Type", contentType);String uploadId = customMinioClient.initMultiPartUpload(bucket, null, objectName, headers, null);result.put("uploadId", uploadId);List<String> partList = new ArrayList<>();Map<String, String> reqParams = new HashMap<>();//reqParams.put("response-content-type", "application/json");reqParams.put("uploadId", uploadId);for (int i = 1; i <= partCount; i++) {reqParams.put("partNumber", String.valueOf(i));String uploadUrl = customMinioClient.getPresignedObjectUrl(GetPresignedObjectUrlArgs.builder().method(Method.PUT).bucket(bucket).object(objectName).expiry(1, TimeUnit.DAYS).extraQueryParams(reqParams).build());partList.add(uploadUrl);}result.put("uploadUrls", partList);} catch (Exception e) {e.printStackTrace();return null;}return result;}测试,我们把partCount给成4
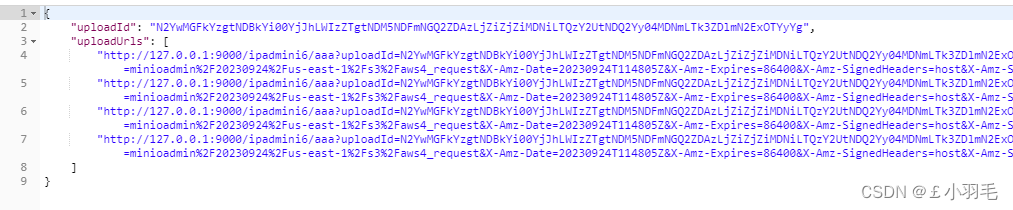
上传分片
获取到了uploadId以后,就会执行上传操作,调用uploadPart方法,uploadPart最终也是调用execute,可以看到该方法,是调用的OkHttpClient 去执行的。
合并文件
MinioUtil中继续新增
/*** 分片上传完后合并** @param objectName 文件全路径名称* @param uploadId 返回的uploadId* @return /*/
public boolean mergeMultipartUpload(String bucket, String objectName, String uploadId) {try {//TODO::目前仅做了最大1000分片Part[] parts = new Part[1000];ListPartsResponse partResult = customMinioClient.listMultipart(bucket, null, objectName, 1000, 0, uploadId, null, null);int partNumber = 1;for (Part part : partResult.result().partList()) {parts[partNumber - 1] = new Part(partNumber, part.etag());partNumber++;}customMinioClient.mergeMultipartUpload(bucket, null, objectName, uploadId, parts, null, null);} catch (Exception e) {e.printStackTrace();return false;}return true;
}大文件分片(后端传)
思路:
- 前端上传文件到web后台。
- 后端对文件进行切割,并且记录切割段数。
- 后端调用minio上传api。
- 等待分片全部上传后再调用合并文件
分片上传和断点续传的实现过程中,需要在Minio内部记录已上传的分片文件。
这些分片文件将以文件md5作为父目录,分片文件的名字按照01,02,...的顺序进行命名。同时,还必须知道当前文件的分片总数,这样就能够根据总数来判断文件是否上传完毕了。
比如,一个文件被分成了10片,所以总数是10。当前端发起上传请求时,把一个个文件分片依次上传,Minio 服务器中存储的临时文件依次是01、02、03 等等。
假设前端把05分片上传完毕了之后断开了连接,由于 Minio 服务器仍然存储着01~05的分片文件,因此前端再次上传文件时,只需从06序号开始上传分片,而不用从头开始传输。这就是所谓的断点续传。
相关文章:
分布式文件存储系统minio、大文件分片传输
上传大文件 1、Promise对象 Promise 对象代表一个异步操作,有三种状态: pending: 初始状态,不是成功或失败状态。fulfilled: 意味着操作成功完成。rejected: 意味着操作失败。 只有异步操作的结果,可以决定当前是哪一种状态&a…...

在 msys2/mingw 下安装及编译 opencv
最简单就是直接安装 pacman -S mingw-w64-x86_64-opencv 以下记录一下编译的过程 1. 安装编译工具及第三方库 pacman -S --needed base-devel mingw-w64-x86_64-toolchain unzip gccpacman -S python mingw-w64-x86_64-python2 mingw-w64-x86_64-gtk3 mingw-w64-x86_64-…...

java 根据身份证号码判断性别
在Java中,您可以根据身份证号码的规则来判断性别。中国的身份证号码通常采用的是以下规则: 第17位数字代表性别,奇数表示男性,偶数表示女性。 通常,男性的出生日期的第15、16位数字是01,女性是02。 请注意&…...
)
信息服务上线渗透检测网络安全检查报告和解决方案4(XSS漏洞修复)
系列文章目录 信息服务上线渗透检测网络安全检查报告和解决方案2(安装文件信息泄漏、管理路径泄漏、XSS漏洞、弱口令、逻辑漏洞、终极上传漏洞升级)信息服务上线渗透检测网络安全检查报告和解决方案信息服务上线渗透检测网络安全检查报告和解决方案3(系统漏洞扫描、相对路径覆…...
【SQL】mysql创建定时任务执行存储过程--20230928
1.先设定时区 https://blog.csdn.net/m0_46629123/article/details/133382375 输入命令show variables like “%time_zone%”;(注意分号结尾)设置时区,输入 set global time_zone “8:00”; 回车,然后退出重启(一定记得重启&am…...
安全基础 --- MySQL数据库解析
MySQL的ACID (1)ACID是衡量事务的四个特性 原子性(Atomicity,或称不可分割性)一致性(Consistency)隔离性(Isolation)持久性(Durability) &…...

软件设计师考试学习3
开发模型 瀑布模型 现在基本被淘汰了 是一种结构化方法中的模型,一般用于结构化开发 问题在于需求阶段需求不可能一次搞清楚,很可能做完推翻重做 适用于需求明确或二次开发 原型模型、演化模型、增量模型 原型是为了解决需求不明确的问题 原型在项目…...
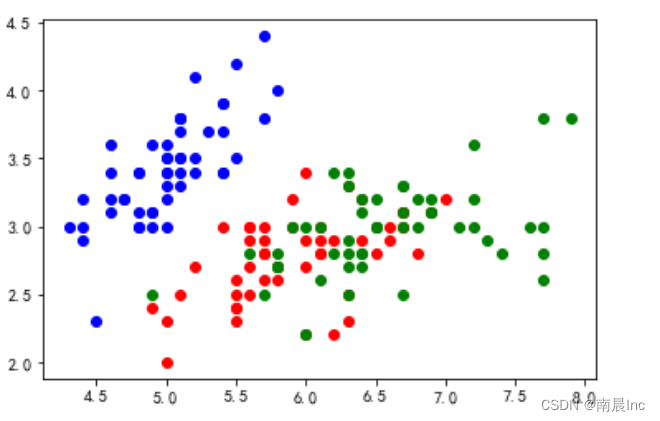
使用LDA(线性判别公式)进行iris鸢尾花的分类
线性判别分析((Linear Discriminant Analysis ,简称 LDA)是一种经典的线性学习方法,在二分类问题上因为最早由 [Fisher,1936] 提出,亦称 ”Fisher 判别分析“。并且LDA也是一种监督学习的降维技术,也就是说它的数据集的每个样本都…...

王学岗生成泛型的简易Builder
github大佬地址 使用 //class 可以传参DataBean.classpublic static <T> T handlerJson(String json, Class<T> tClass) {T resultData null;if (CommonUtils.StringNotNull(json) && !nullString.equals(json)) {if (isArray(json)) {resultData BaseN…...

kafka消息队列简单使用
下面是使用Spring Boot和Kafka实现消息队列的简单例子: 引入依赖 在pom.xml中添加以下依赖: <dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>2.7.5&l…...

性能优化实战使用CountDownLatch
1.分析问题 原程序是分页查询EventAffinityScoreDO表的数据,每次获取2000条在一个个遍历去更新EventAffinityScoreDO表的数据。但是这样耗时比较慢,测试过30万的数据需要2小时 private void eventSubjectHandle(String tenantId, String eventSubject) …...
基于视频技术与AI检测算法的体育场馆远程视频智能化监控方案
一、方案背景 近年来,随着居民体育运动意识的增强,体育场馆成为居民体育锻炼的重要场所。但使用场馆内的器材时,可能发生受伤意外,甚至牵扯责任赔偿纠纷问题。同时,物品丢失、人力巡逻成本问题突出,体育场…...
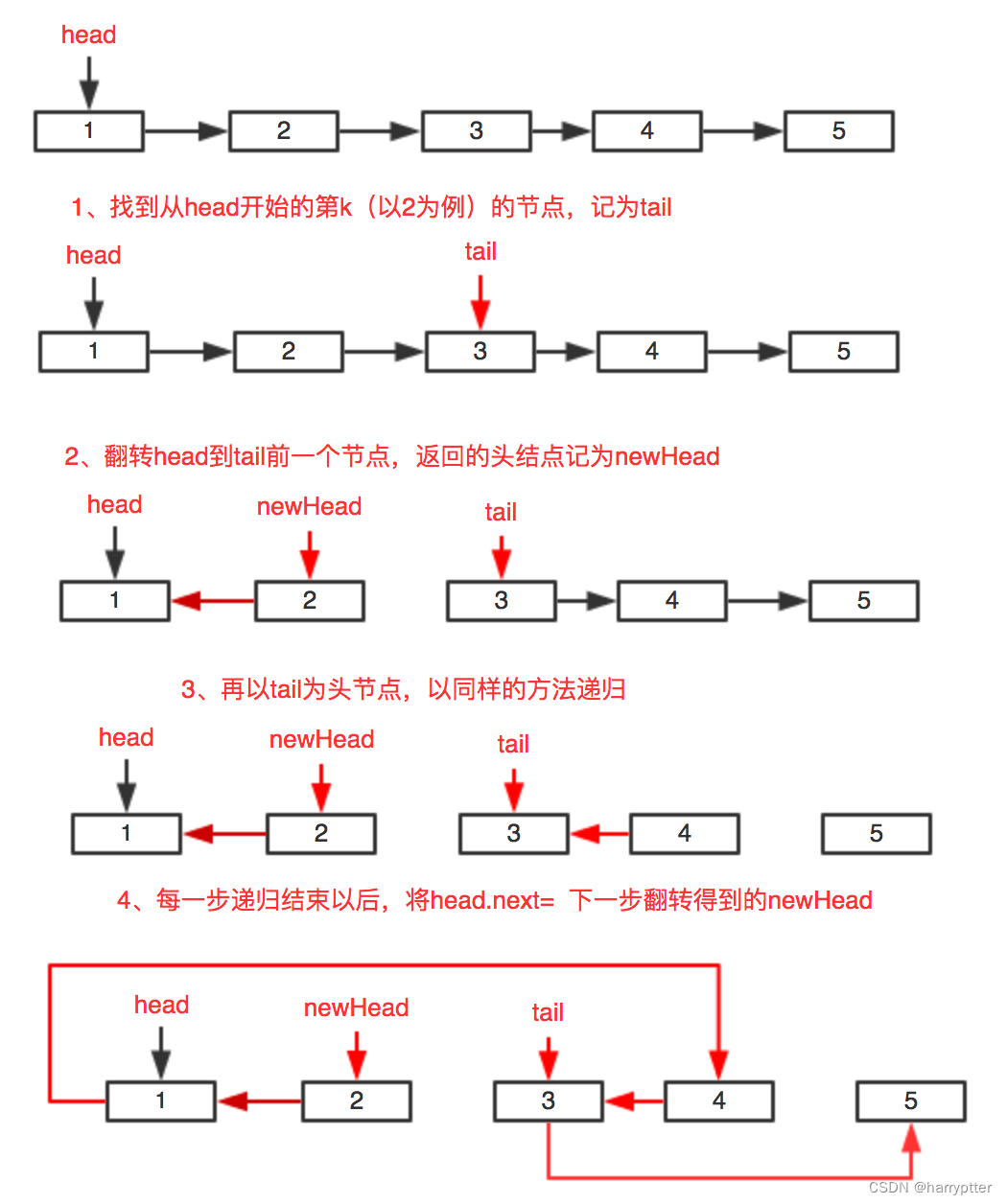
leetcodetop100(29) K 个一组翻转链表
K 个一组翻转链表 给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。 k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。 你不能只是单纯的改…...
最新影视视频微信小程序源码-带支付和采集功能/微信小程序影视源码PHP(更新)
源码简介: 这个影视视频微信小程序源码,新更新的,它还带支付和采集功能,作为微信小程序影视源码,它可以为用户 提供丰富的影视资源,包括电影、电视剧、综艺节目等。 这个小程序影视源码,还带有…...

C++:vector 定义,用法,作用,注意点
C 中的 vector 是标准模板库(STL)提供的一种动态数组容器,它提供了一组强大的方法来管理和操作可变大小的数组。以下是关于 vector 的定义、用法、作用以及一些注意点: 定义: 要使用 vector,首先需要包含 …...
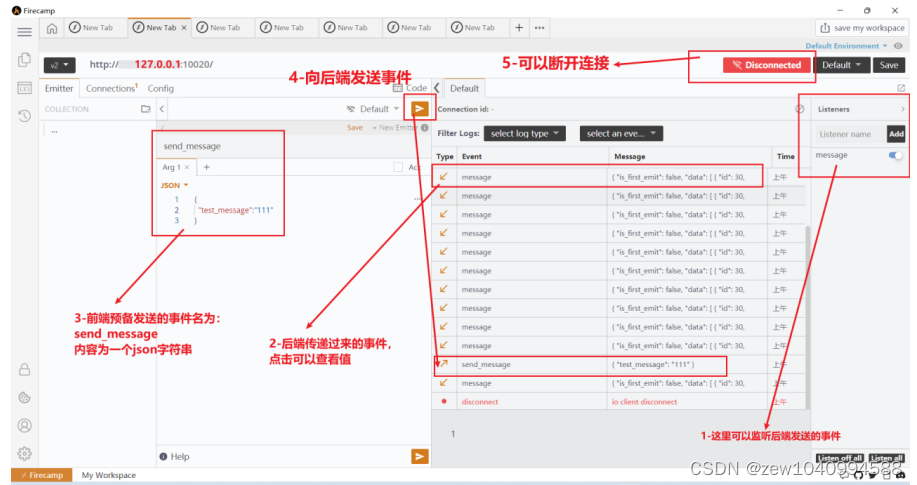
Firecamp2.7.1exe安装与工具调试向后端发送SocketIO请求
背景: 笔者在python使用socket-io包时需要一个测试工具,选择了firecamp这个测试工具来发送请求。 参考视频与exe资源包: Firecamp2.7.1exe安装包以及基本使用说明文档(以SocketIO为例).zip资源-CSDN文库 15_send方法…...
MySQL到TiDB:Hive Metastore横向扩展之路
作者:vivo 互联网大数据团队 - Wang Zhiwen 本文介绍了vivo在大数据元数据服务横向扩展道路上的探索历程,由实际面临的问题出发,对当前主流的横向扩展方案进行了调研及对比测试,通过多方面对比数据择优选择TiDB方案。其次分享了整…...

算法通关村-----寻找祖先问题
最近公共祖先 问题描述 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一…...
Sentinel结合Nacos实现配置持久化(全面)
1、前言 我们在进行分布式系统的开发中,无论是在开发环境还是发布环境,配置一定不能是内存形式的,因为系统可能会在中途宕机或者重启,所以如果放在内存中,那么配置在服务停到就是就会消失,那么此时就需要重…...

Verilog中什么是断言?
断言就是在我们的程序中插入一句代码,这句代码只有仿真的时候才会生效,这段代码的作用是帮助我们判断某个条件是否满足(例如某个数据是否超出了范围),如果条件不满足(数据超出了范围)࿰…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...