使用YOLOv5的backbone网络识别图像天气 - P9
目录
- 环境
- 步骤
- 环境设置
- 包引用
- 声明一个全局的设备
- 数据准备
- 收集数据集信息
- 构建数据集
- 在数据集中读取分类名称
- 划分训练、测试数据集
- 数据集划分批次
- 模型设计
- 编写维持卷积前后图像大小不变的padding计算函数
- 编写YOLOv5中使用的卷积模块
- 编写YOLOv5中使用的Bottleneck模块
- 编写YOLOv5中使用的C3模块
- 编写YOLOv5中使用SPPF模块
- 基于以上模块编写本任务需要的网络结构
- 模型训练
- 编写训练函数
- 开始模型的训练
- 训练过程图表展示
- 模型效果展示
- 载入最佳模型
- 编写预测函数
- 执行预测并展示
- 总结与心得体会
环境
- 系统: Linux
- 语言: Python3.8.10
- 深度学习框架: Pytorch2.0.0+cu118
步骤
环境设置
包引用
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transformsimport pathlib, random, copy
from PIL import Imageimport numpy as np
import matplotlib.pyplot as plt
from torchinfo import summary
声明一个全局的设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
数据准备
收集数据集信息
# 图像数据的路径
image_path = 'weather_photos'# 所有图像的列表
image_list = list(pathlib.Path(image_path).glob('*/*'))# 随机打印几张图像的信息
for _ in range(5):image = random.choice(image_list)print(f"{str(image)}, shape is: {np.array(Image.open(str(image))).shape}")# 查看随机的20张图像
plt.figure(figsize=(20, 4))
for i in range(20):plt.subplot(2, 10, i+1)plt.axis('off')image = random.choice(image_list)plt.title(image.parts[-2])plt.imshow(Image.open(str(image)))

通过图像信息的获取可以发现图像的尺寸并不一致,因此需要在构建数据集的时候对图像做一些伸缩处理。
构建数据集
img_transform = transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
dataset = datasets.ImageFolder(image_path, transform=img_transform)
在数据集中读取分类名称
class_names = [k for k in dataset.class_to_idx]
print(class_names)
划分训练、测试数据集
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_size
train_dataset, test_dataset = random_split(dataset, [train_size, test_size])
数据集划分批次
batch_size = 32
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
模型设计
编写维持卷积前后图像大小不变的padding计算函数
def pad(kernel_size, padding=None):if padding is None:return kernel_size // 2 if isinstance(kernel_size, int) else [item //2 for item in kernel_size]return padding
编写YOLOv5中使用的卷积模块
class Conv(nn.Module):def __init__(self, ch_in, ch_out, kernel_size, stride=1, padding=None, groups=1, activation=True):super().__init__()self.conv = nn.Conv2d(ch_in, ch_out, kernel_size, stride, pad(kernel_size, padding), groups=groups, bias=False)self.bn = nn.BatchNorm2d(ch_out)self.act = nn.SiLU() if activation is True else (activation if isinstance(activation, nn.Module) else nn.Identity())def forward(self, x):x = self.act(self.bn(self.conv(x)))return x
编写YOLOv5中使用的Bottleneck模块
class Bottleneck(nn.Module):def __init__(self, ch_in, ch_out, shortcut=True, groups=1, factor=0.5):super().__init__()hidden_size = int(ch_out*factor)self.conv1 = Conv(ch_in, hidden_size, 1)self.conv2 = Conv(hidden_size, ch_out, 3)self.add = shortcut and ch_in == ch_outdef forward(self, x):return x + self.conv2(self.conv1(x)) if self.add else self.conv2(self.conv1(x))
编写YOLOv5中使用的C3模块
class C3(nn.Module):def __init__(self, ch_in, ch_out, n=1, shortcut=True, groups=1, factor=0.5):super().__init__()hidden_size = int(ch_out*factor)self.conv1 = Conv(ch_in, hidden_size, 1)self.conv2 = Conv(ch_in, hidden_size, 1)self.conv3 = Conv(2*hidden_size, ch_out, 1)self.m = nn.Sequential(*(Bottleneck(hidden_size, hidden_size) for _ in range(n)))def forward(self, x):return self.conv3(torch.cat((self.conv1(x), self.m(self.conv2(x))), dim=1))
编写YOLOv5中使用SPPF模块
class SPPF(nn.Module):def __init__(self, ch_in, ch_out, kernel_size=5):super().__init__()hidden_size = ch_in // 2self.conv1 = Conv(ch_in, hidden_size, 1)self.conv2 = Conv(4*hidden_size, ch_out, 1)self.m = nn.MaxPool2d(kernel_size=kernel_size, stride=1, padding=kernel_size//2)def forward(self, x):x = self.conv1(x)y1 = self.m(x)y2 = self.m(y1)y3 = self.m(y2)return self.conv2(torch.cat([x, y1, y2, y3], dim=1))
基于以上模块编写本任务需要的网络结构
class Network(nn.Module):def __init__(self, num_classes):super().__init__()self.conv1 = Conv(3, 64, 3, 2, 2)self.conv2 = Conv(64, 128, 3, 2)self.c3_1 = C3(128, 128)self.conv3 = Conv(128, 256, 3, 2)self.c3_2 = C3(256, 256)self.conv4 = Conv(256, 512, 3, 2)self.c3_3 = C3(512, 512)self.conv5 = Conv(512, 1024, 3, 2)self.c3_4 = C3(1024, 1024)self.sppf = SPPF(1024, 1024, 5)self.classifier = nn.Sequential(nn.Linear(65536, 100),nn.ReLU(),nn.Linear(100, num_classes))def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.c3_1(x)x = self.conv3(x)x = self.c3_2(x)x = self.conv4(x)x = self.c3_3(x)x = self.conv5(x)x = self.c3_4(x)x = self.sppf(x)x = x.view(x.size(0), -1)x = self.classifier(x)return x
model = Network(len(class_names)).to(device)
print(model)
summary(model, input_size=(32, 3, 224, 224))
直接打印出的模型结构如下:
Network((conv1): Conv((conv): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(2, 2), bias=False)(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(conv2): Conv((conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(c3_1): C3((conv1): Conv((conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(conv2): Conv((conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(conv3): Conv((conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(m): Sequential((0): Bottleneck((conv1): Conv((conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(conv2): Conv((conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU()))))(conv3): Conv((conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(c3_2): C3((conv1): Conv((conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(conv2): Conv((conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(conv3): Conv((conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(m): Sequential((0): Bottleneck((conv1): Conv((conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(conv2): Conv((conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU()))))(conv4): Conv((conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(c3_3): C3((conv1): Conv((conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(conv2): Conv((conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(conv3): Conv((conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(m): Sequential((0): Bottleneck((conv1): Conv((conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(conv2): Conv((conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU()))))(conv5): Conv((conv): Conv2d(512, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(c3_4): C3((conv1): Conv((conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(conv2): Conv((conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(conv3): Conv((conv): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(m): Sequential((0): Bottleneck((conv1): Conv((conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(conv2): Conv((conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU()))))(sppf): SPPF((conv1): Conv((conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(conv2): Conv((conv): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(m): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False))(classifier): Sequential((0): Linear(in_features=65536, out_features=100, bias=True)(1): ReLU()(2): Linear(in_features=100, out_features=4, bias=True))
)
torchinfo库中的summary函数打印的结果如下:
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Network [32, 4] --
├─Conv: 1-1 [32, 64, 113, 113] --
│ └─Conv2d: 2-1 [32, 64, 113, 113] 1,728
│ └─BatchNorm2d: 2-2 [32, 64, 113, 113] 128
│ └─SiLU: 2-3 [32, 64, 113, 113] --
├─Conv: 1-2 [32, 128, 57, 57] --
│ └─Conv2d: 2-4 [32, 128, 57, 57] 73,728
│ └─BatchNorm2d: 2-5 [32, 128, 57, 57] 256
│ └─SiLU: 2-6 [32, 128, 57, 57] --
├─C3: 1-3 [32, 128, 57, 57] --
│ └─Conv: 2-7 [32, 64, 57, 57] --
│ │ └─Conv2d: 3-1 [32, 64, 57, 57] 8,192
│ │ └─BatchNorm2d: 3-2 [32, 64, 57, 57] 128
│ │ └─SiLU: 3-3 [32, 64, 57, 57] --
│ └─Conv: 2-8 [32, 64, 57, 57] --
│ │ └─Conv2d: 3-4 [32, 64, 57, 57] 8,192
│ │ └─BatchNorm2d: 3-5 [32, 64, 57, 57] 128
│ │ └─SiLU: 3-6 [32, 64, 57, 57] --
│ └─Sequential: 2-9 [32, 64, 57, 57] --
│ │ └─Bottleneck: 3-7 [32, 64, 57, 57] 20,672
│ └─Conv: 2-10 [32, 128, 57, 57] --
│ │ └─Conv2d: 3-8 [32, 128, 57, 57] 16,384
│ │ └─BatchNorm2d: 3-9 [32, 128, 57, 57] 256
│ │ └─SiLU: 3-10 [32, 128, 57, 57] --
├─Conv: 1-4 [32, 256, 29, 29] --
│ └─Conv2d: 2-11 [32, 256, 29, 29] 294,912
│ └─BatchNorm2d: 2-12 [32, 256, 29, 29] 512
│ └─SiLU: 2-13 [32, 256, 29, 29] --
├─C3: 1-5 [32, 256, 29, 29] --
│ └─Conv: 2-14 [32, 128, 29, 29] --
│ │ └─Conv2d: 3-11 [32, 128, 29, 29] 32,768
│ │ └─BatchNorm2d: 3-12 [32, 128, 29, 29] 256
│ │ └─SiLU: 3-13 [32, 128, 29, 29] --
│ └─Conv: 2-15 [32, 128, 29, 29] --
│ │ └─Conv2d: 3-14 [32, 128, 29, 29] 32,768
│ │ └─BatchNorm2d: 3-15 [32, 128, 29, 29] 256
│ │ └─SiLU: 3-16 [32, 128, 29, 29] --
│ └─Sequential: 2-16 [32, 128, 29, 29] --
│ │ └─Bottleneck: 3-17 [32, 128, 29, 29] 82,304
│ └─Conv: 2-17 [32, 256, 29, 29] --
│ │ └─Conv2d: 3-18 [32, 256, 29, 29] 65,536
│ │ └─BatchNorm2d: 3-19 [32, 256, 29, 29] 512
│ │ └─SiLU: 3-20 [32, 256, 29, 29] --
├─Conv: 1-6 [32, 512, 15, 15] --
│ └─Conv2d: 2-18 [32, 512, 15, 15] 1,179,648
│ └─BatchNorm2d: 2-19 [32, 512, 15, 15] 1,024
│ └─SiLU: 2-20 [32, 512, 15, 15] --
├─C3: 1-7 [32, 512, 15, 15] --
│ └─Conv: 2-21 [32, 256, 15, 15] --
│ │ └─Conv2d: 3-21 [32, 256, 15, 15] 131,072
│ │ └─BatchNorm2d: 3-22 [32, 256, 15, 15] 512
│ │ └─SiLU: 3-23 [32, 256, 15, 15] --
│ └─Conv: 2-22 [32, 256, 15, 15] --
│ │ └─Conv2d: 3-24 [32, 256, 15, 15] 131,072
│ │ └─BatchNorm2d: 3-25 [32, 256, 15, 15] 512
│ │ └─SiLU: 3-26 [32, 256, 15, 15] --
│ └─Sequential: 2-23 [32, 256, 15, 15] --
│ │ └─Bottleneck: 3-27 [32, 256, 15, 15] 328,448
│ └─Conv: 2-24 [32, 512, 15, 15] --
│ │ └─Conv2d: 3-28 [32, 512, 15, 15] 262,144
│ │ └─BatchNorm2d: 3-29 [32, 512, 15, 15] 1,024
│ │ └─SiLU: 3-30 [32, 512, 15, 15] --
├─Conv: 1-8 [32, 1024, 8, 8] --
│ └─Conv2d: 2-25 [32, 1024, 8, 8] 4,718,592
│ └─BatchNorm2d: 2-26 [32, 1024, 8, 8] 2,048
│ └─SiLU: 2-27 [32, 1024, 8, 8] --
├─C3: 1-9 [32, 1024, 8, 8] --
│ └─Conv: 2-28 [32, 512, 8, 8] --
│ │ └─Conv2d: 3-31 [32, 512, 8, 8] 524,288
│ │ └─BatchNorm2d: 3-32 [32, 512, 8, 8] 1,024
│ │ └─SiLU: 3-33 [32, 512, 8, 8] --
│ └─Conv: 2-29 [32, 512, 8, 8] --
│ │ └─Conv2d: 3-34 [32, 512, 8, 8] 524,288
│ │ └─BatchNorm2d: 3-35 [32, 512, 8, 8] 1,024
│ │ └─SiLU: 3-36 [32, 512, 8, 8] --
│ └─Sequential: 2-30 [32, 512, 8, 8] --
│ │ └─Bottleneck: 3-37 [32, 512, 8, 8] 1,312,256
│ └─Conv: 2-31 [32, 1024, 8, 8] --
│ │ └─Conv2d: 3-38 [32, 1024, 8, 8] 1,048,576
│ │ └─BatchNorm2d: 3-39 [32, 1024, 8, 8] 2,048
│ │ └─SiLU: 3-40 [32, 1024, 8, 8] --
├─SPPF: 1-10 [32, 1024, 8, 8] --
│ └─Conv: 2-32 [32, 512, 8, 8] --
│ │ └─Conv2d: 3-41 [32, 512, 8, 8] 524,288
│ │ └─BatchNorm2d: 3-42 [32, 512, 8, 8] 1,024
│ │ └─SiLU: 3-43 [32, 512, 8, 8] --
│ └─MaxPool2d: 2-33 [32, 512, 8, 8] --
│ └─MaxPool2d: 2-34 [32, 512, 8, 8] --
│ └─MaxPool2d: 2-35 [32, 512, 8, 8] --
│ └─Conv: 2-36 [32, 1024, 8, 8] --
│ │ └─Conv2d: 3-44 [32, 1024, 8, 8] 2,097,152
│ │ └─BatchNorm2d: 3-45 [32, 1024, 8, 8] 2,048
│ │ └─SiLU: 3-46 [32, 1024, 8, 8] --
├─Sequential: 1-11 [32, 4] --
│ └─Linear: 2-37 [32, 100] 6,553,700
│ └─ReLU: 2-38 [32, 100] --
│ └─Linear: 2-39 [32, 4] 404
===============================================================================================
Total params: 19,987,832
Trainable params: 19,987,832
Non-trainable params: 0
Total mult-adds (G): 64.43
===============================================================================================
Input size (MB): 19.27
Forward/backward pass size (MB): 2027.63
Params size (MB): 79.95
Estimated Total Size (MB): 2126.85
===============================================================================================
模型训练
编写训练函数
def train(train_loader, model, loss_fn, optimizer):model.train()train_loss, train_acc = 0, 0num_batches = len(train_loader)size = len(train_loader.dataset)for x, y in train_loader:x, y = x.to(device), y.to(device)pred = model(x)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss /= num_batchestrain_acc /= sizereturn train_loss, train_accdef test(test_loader, model, loss_fn):model.eval()test_loss, test_acc = 0, 0num_batches = len(test_loader)size = len(test_loader.dataset)with torch.no_grad():for x, y in test_loader:x, y = x.to(device), y.to(device)pred = model(x)loss = loss_fn(pred, y)test_loss += loss.item()test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchestest_acc /= sizereturn test_loss, test_acc
开始模型的训练
epochs = 60
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
best_acc = 0
best_model_path = 'best_p9_model.pth'train_loss, train_acc = [], []
test_loss, test_acc = [], []for epoch in range(epochs):epoch_train_loss, epoch_train_acc = train(train_loader, model, loss_fn, optimizer)epoch_test_loss, epoch_test_acc = test(test_loader, model, loss_fn)if best_acc < epoch_test_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_loss.append(epoch_train_loss)train_acc.append(epoch_train_acc)test_loss.append(epoch_test_loss)test_acc.append(epoch_test_acc)lr = optimizer.state_dict()['param_groups'][0]['lr']print(f"Epoch: {epoch+1}, TrainLoss: {epoch_train_loss:.3f}, TrainAcc: {epoch_train_acc*100:.1f},TestLoss: {epoch_test_loss:.3f}, TestAcc: {epoch_test_acc*100:.1f}, learning_rate: {lr}")
print(f"training finished, save best model to : {best_model_path})")
torch.save(best_model.state_dict(), best_model_path)
print("done")
训练过程打印日志如下
Epoch: 1, TrainLoss: 0.986, TrainAcc: 57.2,TestLoss: 2.137, TestAcc: 25.3, learning_rate: 0.0001
Epoch: 2, TrainLoss: 0.725, TrainAcc: 76.2,TestLoss: 0.486, TestAcc: 87.6, learning_rate: 0.0001
Epoch: 3, TrainLoss: 0.368, TrainAcc: 84.7,TestLoss: 0.310, TestAcc: 87.6, learning_rate: 0.0001
Epoch: 4, TrainLoss: 0.295, TrainAcc: 89.9,TestLoss: 0.329, TestAcc: 90.7, learning_rate: 0.0001
Epoch: 5, TrainLoss: 0.407, TrainAcc: 87.2,TestLoss: 0.288, TestAcc: 88.9, learning_rate: 0.0001
Epoch: 6, TrainLoss: 0.316, TrainAcc: 89.4,TestLoss: 0.354, TestAcc: 89.8, learning_rate: 0.0001
Epoch: 7, TrainLoss: 0.347, TrainAcc: 92.1,TestLoss: 0.244, TestAcc: 92.9, learning_rate: 0.0001
Epoch: 8, TrainLoss: 0.206, TrainAcc: 93.1,TestLoss: 0.313, TestAcc: 94.2, learning_rate: 0.0001
Epoch: 9, TrainLoss: 0.204, TrainAcc: 92.4,TestLoss: 0.227, TestAcc: 90.2, learning_rate: 0.0001
Epoch: 10, TrainLoss: 0.151, TrainAcc: 95.4,TestLoss: 0.242, TestAcc: 92.9, learning_rate: 0.0001
Epoch: 11, TrainLoss: 0.146, TrainAcc: 95.6,TestLoss: 0.314, TestAcc: 88.9, learning_rate: 0.0001
Epoch: 12, TrainLoss: 0.223, TrainAcc: 91.7,TestLoss: 0.769, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 13, TrainLoss: 0.155, TrainAcc: 95.2,TestLoss: 0.223, TestAcc: 92.4, learning_rate: 0.0001
Epoch: 14, TrainLoss: 0.267, TrainAcc: 93.9,TestLoss: 0.280, TestAcc: 93.3, learning_rate: 0.0001
Epoch: 15, TrainLoss: 0.194, TrainAcc: 93.3,TestLoss: 0.345, TestAcc: 89.3, learning_rate: 0.0001
Epoch: 16, TrainLoss: 0.283, TrainAcc: 91.3,TestLoss: 0.267, TestAcc: 92.4, learning_rate: 0.0001
Epoch: 17, TrainLoss: 0.183, TrainAcc: 94.3,TestLoss: 1.779, TestAcc: 84.4, learning_rate: 0.0001
Epoch: 18, TrainLoss: 0.161, TrainAcc: 95.7,TestLoss: 0.279, TestAcc: 90.7, learning_rate: 0.0001
Epoch: 19, TrainLoss: 0.100, TrainAcc: 95.7,TestLoss: 0.249, TestAcc: 93.8, learning_rate: 0.0001
Epoch: 20, TrainLoss: 0.134, TrainAcc: 97.0,TestLoss: 0.252, TestAcc: 91.1, learning_rate: 0.0001
Epoch: 21, TrainLoss: 0.236, TrainAcc: 94.0,TestLoss: 0.264, TestAcc: 88.0, learning_rate: 0.0001
Epoch: 22, TrainLoss: 0.199, TrainAcc: 93.1,TestLoss: 0.251, TestAcc: 94.7, learning_rate: 0.0001
Epoch: 23, TrainLoss: 0.243, TrainAcc: 95.2,TestLoss: 0.425, TestAcc: 88.0, learning_rate: 0.0001
Epoch: 24, TrainLoss: 0.181, TrainAcc: 94.8,TestLoss: 0.390, TestAcc: 86.7, learning_rate: 0.0001
Epoch: 25, TrainLoss: 0.138, TrainAcc: 97.4,TestLoss: 0.337, TestAcc: 91.1, learning_rate: 0.0001
Epoch: 26, TrainLoss: 0.212, TrainAcc: 96.6,TestLoss: 0.358, TestAcc: 90.2, learning_rate: 0.0001
Epoch: 27, TrainLoss: 0.289, TrainAcc: 92.4,TestLoss: 0.239, TestAcc: 94.2, learning_rate: 0.0001
Epoch: 28, TrainLoss: 0.220, TrainAcc: 95.6,TestLoss: 0.280, TestAcc: 88.4, learning_rate: 0.0001
Epoch: 29, TrainLoss: 0.177, TrainAcc: 95.6,TestLoss: 0.216, TestAcc: 92.9, learning_rate: 0.0001
Epoch: 30, TrainLoss: 0.116, TrainAcc: 96.3,TestLoss: 0.240, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 31, TrainLoss: 0.065, TrainAcc: 98.0,TestLoss: 0.230, TestAcc: 92.4, learning_rate: 0.0001
Epoch: 32, TrainLoss: 0.097, TrainAcc: 98.0,TestLoss: 0.261, TestAcc: 92.9, learning_rate: 0.0001
Epoch: 33, TrainLoss: 0.084, TrainAcc: 97.9,TestLoss: 0.262, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 34, TrainLoss: 0.113, TrainAcc: 96.2,TestLoss: 0.257, TestAcc: 95.1, learning_rate: 0.0001
Epoch: 35, TrainLoss: 0.071, TrainAcc: 97.8,TestLoss: 0.284, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 36, TrainLoss: 0.238, TrainAcc: 95.2,TestLoss: 0.210, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 37, TrainLoss: 0.175, TrainAcc: 96.9,TestLoss: 0.259, TestAcc: 92.9, learning_rate: 0.0001
Epoch: 38, TrainLoss: 0.129, TrainAcc: 95.8,TestLoss: 0.315, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 39, TrainLoss: 0.077, TrainAcc: 98.0,TestLoss: 0.233, TestAcc: 91.6, learning_rate: 0.0001
Epoch: 40, TrainLoss: 0.092, TrainAcc: 97.3,TestLoss: 0.266, TestAcc: 89.3, learning_rate: 0.0001
Epoch: 41, TrainLoss: 0.064, TrainAcc: 98.0,TestLoss: 0.248, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 42, TrainLoss: 0.062, TrainAcc: 99.2,TestLoss: 0.211, TestAcc: 93.3, learning_rate: 0.0001
Epoch: 43, TrainLoss: 0.098, TrainAcc: 97.2,TestLoss: 0.359, TestAcc: 90.7, learning_rate: 0.0001
Epoch: 44, TrainLoss: 0.153, TrainAcc: 97.0,TestLoss: 0.411, TestAcc: 89.3, learning_rate: 0.0001
Epoch: 45, TrainLoss: 0.234, TrainAcc: 96.9,TestLoss: 0.198, TestAcc: 92.0, learning_rate: 0.0001
Epoch: 46, TrainLoss: 0.042, TrainAcc: 98.6,TestLoss: 0.191, TestAcc: 93.3, learning_rate: 0.0001
Epoch: 47, TrainLoss: 0.033, TrainAcc: 98.9,TestLoss: 0.141, TestAcc: 96.9, learning_rate: 0.0001
Epoch: 48, TrainLoss: 0.012, TrainAcc: 99.7,TestLoss: 0.202, TestAcc: 94.7, learning_rate: 0.0001
Epoch: 49, TrainLoss: 0.016, TrainAcc: 99.1,TestLoss: 0.171, TestAcc: 93.8, learning_rate: 0.0001
Epoch: 50, TrainLoss: 0.011, TrainAcc: 99.6,TestLoss: 0.274, TestAcc: 93.8, learning_rate: 0.0001
Epoch: 51, TrainLoss: 0.014, TrainAcc: 99.8,TestLoss: 0.233, TestAcc: 94.2, learning_rate: 0.0001
Epoch: 52, TrainLoss: 0.263, TrainAcc: 98.7,TestLoss: 0.233, TestAcc: 91.6, learning_rate: 0.0001
Epoch: 53, TrainLoss: 0.284, TrainAcc: 92.7,TestLoss: 0.680, TestAcc: 92.9, learning_rate: 0.0001
Epoch: 54, TrainLoss: 0.334, TrainAcc: 90.9,TestLoss: 0.332, TestAcc: 91.1, learning_rate: 0.0001
Epoch: 55, TrainLoss: 0.261, TrainAcc: 94.4,TestLoss: 0.498, TestAcc: 90.7, learning_rate: 0.0001
Epoch: 56, TrainLoss: 0.144, TrainAcc: 95.9,TestLoss: 0.376, TestAcc: 88.4, learning_rate: 0.0001
Epoch: 57, TrainLoss: 0.080, TrainAcc: 97.3,TestLoss: 0.296, TestAcc: 92.4, learning_rate: 0.0001
Epoch: 58, TrainLoss: 0.033, TrainAcc: 99.2,TestLoss: 0.226, TestAcc: 93.3, learning_rate: 0.0001
Epoch: 59, TrainLoss: 0.023, TrainAcc: 99.0,TestLoss: 0.327, TestAcc: 93.8, learning_rate: 0.0001
Epoch: 60, TrainLoss: 0.073, TrainAcc: 98.0,TestLoss: 0.347, TestAcc: 90.7, learning_rate: 0.0001
training finished, save best model to : best_p9_model.pth)
done
训练过程图表展示
epoch_ranges = range(epochs)plt.figure(figsize=(20, 4))
plt.subplot(121)
plt.plot(epoch_ranges, train_loss, label='train loss')
plt.plot(epoch_ranges, test_loss, label='validation loss')
plt.legend(loc='upper right')
plt.title('Loss')plt.subplot(122)
plt.plot(epoch_ranges, train_acc, label='train accuracy')
plt.plot(epoch_ranges, test_acc, label='validation accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')
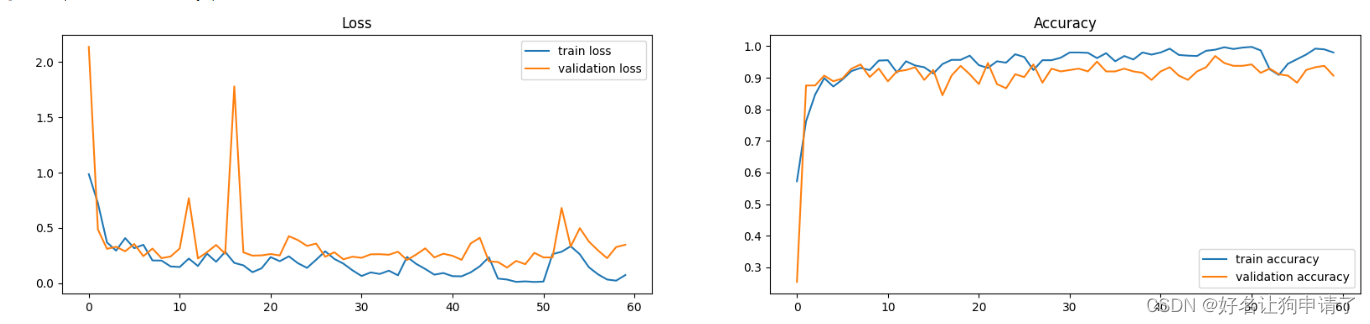
模型效果展示
载入最佳模型
model.load_state_dict(torch.load(best_model_path))
model.to(device)
编写预测函数
def predict(model, image_path):image = Image.open(image_path)image = img_transform(image)image = image.unsqueeze(0).to(device)model.eval()with torch.no_grad():pred = model(image)return class_names[pred.argmax(1).item()]
执行预测并展示
评估应当只用测试集中的数据,这里没有再使用数据集进行反归一化,会有一部分训练集中的数据参与其中,导致预测的结果非常好(可能是假象)
plt.figure(figsize=(20, 4))
for i in range(20):plt.subplot(2, 10, i+1)image = random.choice(image_list)real_label = image.parts[-2]pred_label = predict(model, str(image))plt.title(f"R:{real_label}, P:{pred_label}")plt.axis('off')plt.imshow(Image.open(str(image)))

总结与心得体会
- YOLOv5的骨干网络中大量使用了1x1卷积,只用来将特征图重新映射到不同通道的特征图中,执行效率比执行大核卷积快
- 骨干网络中特征图大小的缩减并没用像普通的卷积网络一样使用池化层,而是使用卷积通过调整stride和padding属性来实现,这样做会比直接使用池化层多一些可训练参数,可能会增加一些模型的拟合能力
- 通过本次任务学习到了跳跃连接应该怎样编写代码,还有SPPF模块的实现
- 模型的评估应该不包含训练集中的数据,不然展示的结果并不真实
相关文章:
使用YOLOv5的backbone网络识别图像天气 - P9
目录 环境步骤环境设置包引用声明一个全局的设备 数据准备收集数据集信息构建数据集在数据集中读取分类名称划分训练、测试数据集数据集划分批次 模型设计编写维持卷积前后图像大小不变的padding计算函数编写YOLOv5中使用的卷积模块编写YOLOv5中使用的Bottleneck模块编写YOLOv5…...

TikTok海外扩张:亚马逊的新对手崛起
随着社交媒体和电子商务的融合,TikTok正迅速崭露头角,成为亚马逊等传统电商巨头的潜在竞争对手。这一新兴平台的快速发展引发了广泛的关注,特别是在全球范围内。 在这篇文章中,我们将探讨TikTok海外扩张的战略,以及它…...
CSS详细基础(五)选择器的优先级
本节介绍选择器优先级,优先级决定了元素最终展示的样式~ 浏览器是通过判断CSS优先级,来决定到底哪些属性值是与元素最为相关的,从而作用到该元素上。CSS选择器的合理组成规则决定了优先级,我们也常常用选择器优先级来合理控制元素…...

LLM-TAP随笔——有监督微调【深度学习】【PyTorch】【LLM】
文章目录 5、 有监督微调5.1、提示学习&语境学习5.2、高效微调5.3、模型上下文窗口扩展5.4、指令数据构建5.5、开源指令数据集 5、 有监督微调 5.1、提示学习&语境学习 提示学习 完成预测的三个阶段:提示添加、答案搜索、答案映射 提示添加 “[X] 我感到…...
kafka伪集群部署,使用docker环境拷贝模式
线上启动容器的方式是复制容器的运行环境出来,然后进行运行脚本的形式 1:在home/kafka目录下创建如下目录 2:复制kafka1容器内的数据/bitnami/kafka/data,直接放在1992_data里面,同理,复制kafka2容器内的数据/bitnami/…...

工业交换机一般的价格是多少呢?
工业交换机是一种应用于工业领域的网络设备。它的性能和所有安全指标都比一般商业交换机更加稳定。所以,工业级交换机的价格相对于普通的交换机要稍稍昂贵一些。工业交换机一般的价格是多少呢?每个厂家的交换机价格是不是都一样呢? 首先&…...

QT使用前的知识
QT使用前的知识 常用的快捷键 源文件的内容解释 .pro文件的解释 头文件的解释 构建新的对象—组成对象树 槽函数 自定的信号和槽 槽函数的信号是一个重载函数时 电机按钮触发信号 调用无参数的信号 断开信号...

Unity制作旋转光束
Unity制作旋转光束 大家好,我是阿赵。 这是一个在很多游戏里面可能都看到过的效果,在传送门、魔法阵、角色等脚底下往上散发出一束拉丝形状的光,然后在不停的旋转。 这次来在Unity引擎里面做一下这种效果。 一、准备材料 需要准备的素材很简…...

考研王道强化阶段(二轮复习)“算法题”备考打卡表 记录
问题:做408真题_2010_42题,即王道书 2.2.3_大题_10 思路: 回头补 代码: int moveL(SqlList &L,SqlList &S,int p) {// 健壮性表达if( L.len 0 ){return 0;}// 调用另外一个顺序表存储pos前面的元素for( int i0;i<p;…...

UE4/5数字人MetaHuman通过已有动画进行修改
目录 通过已有动画修改动画 开始制作 创建一个关卡序列 将动画序列烘焙到控制绑定 打开我们自己创建的动画序列 之后便是烘焙出来 通过已有动画修改动画 首先架设我们已经有相关的MetaHuman的动画,但是这个动画因为是外部导入进来的,所以可能会出…...

在Mac M2本地注册GitLab runner
最近在搞公司的CI/CD,简单记录下部分过程 安装runner sudo curl --output /usr/local/bin/gitlab-runner "https://gitlab-runner-downloads.s3.amazonaws.com/latest/binaries/gitlab-runner-darwin-arm64" 创建runner 这个步骤需要在gitlab中进行&am…...

「大数据-2.2」使用命令操作HDFS文件系统
目录 一、HDFS文件系统基本信息 1. HDFS的路径表达形式 2.HDFS和Linux的根目录的区分 二、 使用命令操作HDFS文件系统 0. Hadoop的两套命令体系 1. 创建文件夹 2. 查看指定目录下内容 3. 上传文件到HDFS指定目录下 4. 查看HDFS文件内容 5. 下载HDFS文件 6. 拷贝HDFS文件 7.…...

面试买书复习就能进大厂?
大家好,我是苍何。 现在进大仓是越来越难了,想通过简单的刷题面试背书,比几年前难的不少, 但也并非毫无希望,那究竟该如何准备才能有希望进大厂呢? 我总结了 4 点: 1、不差的学历背景 2、丰富…...

使用Http Interface客户端解析text/html类型参数
前言 Spring6和Spring Boot3的正式发布也有一段时间了,最低支持的java版本也是直接跳到了17。而且最近java21也出来了,作为一个javaer,你不会还在坚守java8吧? Http Interface是Spring6新推出的一个声明式http客户端,…...

Linux - linux命令进阶
打包压缩解压 基本概述 打包 将多数文件或目录汇总成一个整体 打包默认没有压缩功能,不节省磁盘空间 压缩 将大文件压缩成小文件 可以节省磁盘空间 打包压缩 将一堆零散的文件打包到一起,然后再压缩,可以节省磁盘空间 打包命令 命令格式 ta…...

排序篇(一)----插入排序
1.直接插入排序 插入排序的思想: 把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列 。 你可以想像成打牌一样,比如说斗地主,一张一张的摸牌,然后把手上的这些牌变成手续的排列.…...
通俗讲解深度学习轻量网络MobileNet-v1/v2/v3
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)。MobileNet网络…...

mmpretrain学习笔记
深度学习模型的训练涉及几个方面 1、模型结构:模型有几层、每层多少通道数等 2、数据:数据集划分、数据文件路径、批大小、数据增强策略等 3、训练优化 :梯度下降算法、学习率参数、训练总轮次、学习率变化策略等 4、运行时:GPU、…...

rhel8 网络操作学习
一、查询dns服务器地址汇总 1.查询dns服务器地址: (1)方法一:执行命令 cat /etc/resolv.conf 执行结果如下: nameserver后面就是dns服务器的ip地址。 (2)方法2:查看/etc/syscon…...
,车厂(CarFactory),经销商(Distributor)三个表)
有车型(CarModel),车厂(CarFactory),经销商(Distributor)三个表
用drf编写 1 有车型(CarModel),车厂(CarFactory),经销商(Distributor)三个表, 一个车厂可以生产多种车型,一个经销商可以出售多种车型,一个车型可以有多个经销商出售车型:车型名,车型…...

如何快速掌握CoolProp:热物理性质计算的完整指南
如何快速掌握CoolProp:热物理性质计算的完整指南 【免费下载链接】CoolProp Thermophysical properties for the masses 项目地址: https://gitcode.com/gh_mirrors/co/CoolProp 在工程设计和科学研究中,热物理性质计算是每个工程师和研究人员都必…...

Real-ESRGAN-GUI完全指南:让模糊图片秒变高清的免费AI神器
Real-ESRGAN-GUI完全指南:让模糊图片秒变高清的免费AI神器 【免费下载链接】Real-ESRGAN-GUI Lovely Real-ESRGAN / Real-CUGAN GUI Wrapper 项目地址: https://gitcode.com/gh_mirrors/re/Real-ESRGAN-GUI 还在为模糊的老照片、低分辨率的网络图片而烦恼吗&…...
Attention Is All You Need作者再出手:Transformer 99%稀疏,还能更快?
本文约2000字,建议阅读5分钟稀释不止省 FLOPs2017 年,《Attention Is All You Need》将 Transformer 推上深度学习主舞台。如今,几乎所有主流大模型都站在这套架构之上,推理、训练、显存和能耗成本也随模型规模一路上涨。大模型运…...

树张量网络FPGA部署:亚微秒级AI推理的硬件架构与量化实践
1. 项目概述:当量子启发算法遇上硬件加速在机器学习模型日益庞大、推理延迟要求愈发严苛的今天,我们常常面临一个核心矛盾:模型的强大性能与部署时的资源消耗、计算延迟难以兼得。尤其是在高能物理实验的触发系统、工业实时检测或自动驾驶感知…...

HAR模型调优实战:为何精心调优的线性模型能击败复杂机器学习?
1. 项目概述:当HAR模型遇上机器学习,一场关于“调优”的较量在金融计量和量化交易领域,预测明天的市场波动率,就像试图预测一场风暴的强度,充满了挑战但也至关重要。无论是为了给衍生品定价、管理投资组合风险…...

基于XAI与增量删除的地球观测数据特征精炼实战
1. 项目概述与核心思路在机器学习项目中,我们常常陷入一个思维定式:数据越多,模型性能就越好。尤其是在处理地球观测这类多模态、高维度的时序数据时,从哨兵卫星的光谱波段、气象站的小时级观测到静态地形数据,我们习惯…...

基于Hugging Face与Gradio的智能问答系统构建实战
1. 项目概述:从零构建一个可交互的智能问答系统 如果你对自然语言处理(NLP)感兴趣,并且一直想亲手搭建一个能“读懂”文章并回答问题的智能系统,那么这篇文章就是为你准备的。过去几年,基于Transformer架构…...

CSS Animations实战指南:打造流畅的用户体验
CSS Animations实战指南:打造流畅的用户体验 引言 CSS Animations是创建流畅动画效果的强大工具,无需JavaScript即可实现丰富的视觉效果。本文将深入探讨CSS动画的核心概念、实用技巧和最佳实践。 一、CSS动画基础 1.1 keyframes定义动画 keyframes slid…...

Linux Hook技术演进史:从函数指针到eBPF,安全与监控的十年变迁
Linux Hook技术演进史:从函数指针到eBPF的十年变革在系统级编程领域,Hook技术始终扮演着关键角色。想象一下这样的场景:当某个关键系统调用被触发时,你需要在不修改原始代码的情况下注入自定义逻辑——可能是记录日志、实施安全检…...

【AI Agent招聘效能跃迁计划】:为什么92%的HR团队在第3周就放弃?——附可立即上线的MVP验证模板
更多请点击: https://intelliparadigm.com 第一章:AI Agent招聘效能跃迁计划的战略定位与行业悖论 在人才竞争白热化的当下,AI Agent并非招聘流程的“自动化补丁”,而是重构人岗匹配底层逻辑的战略支点。其核心价值不在于替代HR执…...