DETR中的问题汇总(代码)
一、讲述一下torch.tensor()和torch.as_tensor()的区别
torch.tensor() 和 torch.as_tensor() 都是 PyTorch 中用于创建张量(Tensor)的函数,但它们有一些区别,主要涉及到张量的内存管理方式和数据拷贝。以下是它们的主要区别:
-
内存管理:
-
torch.tensor(): 这个函数会创建一个新的张量,它的数据通常是从原始数据拷贝而来的,即使原始数据是一个 NumPy 数组或其他类型的数据。这意味着它会分配新的内存来存储数据,因此它的内存管理是独立的,不与原始数据共享内存。这可以确保修改张量的值不会影响原始数据。 -
torch.as_tensor(): 这个函数通常不会创建新的张量,而是使用现有的数据创建一个张量视图。这意味着它会与原始数据共享内存,如果原始数据发生更改,张量的值也会随之改变。这种方式可以节省内存,但需要注意确保原始数据在张量使用期间保持有效。
-
-
数据类型推断:
-
torch.tensor():这个函数可以根据输入数据的类型来推断出张量的数据类型,如果不指定数据类型,它会选择默认的数据类型。 -
torch.as_tensor():这个函数通常会保持输入数据的数据类型,不会自动进行数据类型转换。
-
-
性能和效率:
-
torch.tensor():由于创建新的张量并分配内存,它可能会更慢一些,尤其是对于大型数据。 -
torch.as_tensor():由于共享内存,它通常更高效,特别是在处理大型数据时。
-
综上所述,选择使用哪个函数取决于你的需求和使用场景。如果你需要确保张量的值不会影响原始数据,或者需要数据类型转换,那么使用 torch.tensor() 可能更合适。如果你需要在效率上进行优化,而且可以确保原始数据在张量使用期间不会改变,那么 torch.as_tensor() 可能更合适。
二、讲述一下为什么训练用的是batch_sampler_train,测试的时候用batch_size?
batch_sampler_train = torch.utils.data.BatchSampler(sampler_train, args.batch_size, drop_last=True)
data_loader_train = DataLoader(dataset_train, batch_sampler=batch_sampler_train,collate_fn=utils.collate_fn, num_workers=args.num_workers) data_loader_val = DataLoader(dataset_val, args.batch_size, sampler=sampler_val,drop_last=False, collate_fn=utils.collate_fn,num_workers=args.num_workers) -
训练时的批量大小(batch size):
-
训练通常使用批量梯度下降(Batch Gradient Descent)或者小批量梯度下降(Mini-Batch Gradient Descent)来更新模型参数。这意味着在每个训练迭代中,模型会根据一个批次(batch)的训练数据来计算梯度并更新参数。批量大小决定了每个迭代中使用多少样本来计算梯度。
-
大批量大小通常可以加速训练过程,但会占用更多内存。因此,通常会将训练数据分成多个小批次来训练,每个小批次的大小由
args.batch_size参数控制。 -
torch.utils.data.BatchSampler用于创建训练数据的批量采样器,它从原始数据中创建大小为args.batch_size的小批次。 -
num_workers参数用于并行加载数据,以提高数据加载速度。
-
-
测试时的批量大小(batch size):
-
在测试或评估模型性能时,通常不需要计算梯度或进行参数更新。因此,可以选择更大的批量大小来处理测试数据,以便更快地进行推理(inference)。
-
在测试时,
args.batch_size参数指定了测试数据的批量大小,而不需要使用批量采样器。这是因为在测试时,不需要计算梯度,所以不需要分批加载数据,可以直接将整个测试数据集加载到内存中。 -
drop_last=False表示在测试时,如果测试数据集大小不能被args.batch_size整除,最后一个小批次不会被丢弃,而是保留下来。这是为了确保在测试时使用了所有的测试样本。
-
总之,训练和测试时使用不同的批量大小是因为它们的任务和需求不同。训练需要进行梯度下降来更新模型参数,而测试只需进行推理并计算性能指标,因此可以使用不同的数据加载策略来满足各自的需求。
三、ann_folder和ann_file的区别
ann_folder 和 ann_file 是在计算机视觉和深度学习任务中常见的两个概念,通常用于数据集的注释(标签)存储。它们的区别如下:
-
ann_folder:
-
文件夹结构:
ann_folder通常指的是一个包含多个注释文件的文件夹或目录。每个注释文件通常对应于数据集中的一个数据样本(例如图像),并包含与该样本相关的标签信息。这些注释文件可以采用不同的格式,如XML、JSON、YAML等,具体取决于数据集的设计。 -
多样性:使用
ann_folder可以支持多种注释文件格式,因此允许数据集创建者选择最适合其数据的格式。 -
适用场景:
ann_folder适用于数据集中的每个数据样本具有不同的注释格式或需要不同的标签信息,或者对于数据集的每个样本都有一个单独的注释文件的情况。
-
-
ann_file:
-
单一文件:
ann_file通常指的是一个包含所有数据样本的标签信息的单一注释文件。这个文件可以采用特定的数据标注格式,如COCO JSON格式、PASCAL VOC XML格式等。所有样本的标签信息都以一种结构化的方式存储在此文件中。 -
一致性:使用
ann_file可以确保所有样本的注释信息都以相同的格式和结构存储,从而更容易进行数据加载和处理。 -
适用场景:
ann_file适用于数据集中的每个数据样本具有相同的注释格式和结构的情况,或者对于大多数数据集而言,以一种统一的格式提供注释信息更为方便。
-
在选择使用 ann_folder 还是 ann_file 时,需要根据数据集的特点和实际需求来决定。通常,对于小型数据集或具有不同注释格式的数据集,ann_folder 可能更灵活。而对于大型数据集或注释结构相对一致的数据集,ann_file 可能更为方便。
四、DETR中,coco数据集的类别设置为什么是91?
DETR模型中COCO数据集的类别数量被设置为91而不是90,是因为在COCO数据集中,有80个物体类别(如人、车、狗等),但DETR模型在类别上额外添加了一个"背景"类别,因此总共有81个类别。另外,DETR还考虑了一些特殊的类别嵌入,因此总共的类别数目为91。
1、加入背景类别的原因
当模型无法确定图像中是否包含目标时。这个额外的类别通常被称为"无目标"或"背景"类别,它表示模型在某个位置上没有检测到任何目标。这个类别的引入有几个重要的原因:
(1)对目标检测任务的建模
在实际场景中,图像中的某些区域可能不包含任何目标,而模型需要能够识别这种情况。如果不引入"无目标"类别,模型可能会错误地将图像中的空白区域解释为某个特定的目标类别,导致误检测。
(2)模型的稳定性
引入"无目标"类别有助于提高模型的稳定性。当图像中没有目标时,模型可以更容易地预测"无目标"类别,而不是强行预测其他类别。这有助于降低误检测率。
(3)数据平衡
在训练数据中,"无目标"类别可以帮助平衡数据集,因为在实际图像中无目标的区域通常比有目标的区域多得多。这有助于防止模型对某些类别过度拟合。
因此,为了更好地处理图像中的"无目标"情况并提高模型的性能和稳定性,DETR模型将COCO数据集的类别数量设置为91,其中包括80个目标类别和1个"无目标"类别,共计91个类别。这种设置有助于DETR模型更好地适应实际目标检测任务。
2、DETR中,coco数据集的类别本来是 80,加了背景信息也是81,设置为什么是91而不是81呢?
在DETR中,将COCO数据集的类别数设置为91而不是81是因为DETR模型使用了一种称为"类别嵌入"(class embeddings)的方法,该方法将目标类别嵌入到模型中,以便直接在模型内部预测目标的类别。
COCO数据集中原本有80个目标类别,加上一个用于表示背景的类别,总共是81个类别。然而,DETR引入了一些额外的类别嵌入,用于表示不同的类别信息。这些额外的嵌入不是来自COCO数据集本身,而是为了模型的目标检测任务而引入的。这些嵌入可以用于预测模型可能遇到的不同类别,而不仅仅是COCO数据集中的类别。
因此,DETR将类别数设置为91,其中80个类别来自COCO数据集,1个类别用于表示背景,其余的10个类别用于表示其他信息或嵌入。这使得模型具有更多的类别表示能力,能够处理更广泛的目标类别,而不仅仅局限于COCO数据集中的类别。
总之,DETR中将类别数设置为91是为了增加模型的泛化能力,使其能够处理更多种类别的目标。这些额外的类别嵌入是DETR模型设计中的一部分,用于支持其目标检测任务。
五、stack操作和cat操作的区别
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
#拼接位置嵌入的x分量和y分量,并将通道维度移动到正确的位置
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)在上面的代码中,stack 和 cat 都用于将张量组合在一起,但它们有一些关键的区别:
-
stack函数:stack函数用于沿着指定的维度创建新的维度。- 在这个代码片段中,
torch.stack用于将两个张量沿维度 4 堆叠在一起,即创建了一个新的维度。这意味着在结果张量中,原始的pos_x和pos_y张量将变成新的维度。 - 结果张量的维度会增加一个,因此最终张量的形状将比原始张量的形状多一个维度。
-
cat函数:cat函数用于在指定的维度上将多个张量连接在一起,而不会创建新的维度。- 在这个代码片段中,
torch.cat用于将pos_x和pos_y张量在维度 3 上连接在一起,即在原始维度上进行拼接。 - 结果张量的形状将与原始张量的形状在拼接的维度上相加,而不会创建新的维度。
所以,关键区别是 stack 创建了一个新的维度,而 cat 在指定的维度上进行连接。进一步理解 pos_x 和 pos 的形状。
-
pos_x的形状:- 在这段代码中,首先使用
pos_x[:, :, :, 0::2].sin()和pos_x[:, :, :, 1::2].cos()分别计算了正弦和余弦变换后的 x 分量。这两个部分具有相同的形状,即(batch_size, num_rows, num_columns, num_pos_feats // 2)。 - 接着,
torch.stack函数用于将这两个部分在维度 4 上堆叠,即dim=4。这将创建一个新的维度,所以结果张量的形状变为(batch_size, num_rows, num_columns, num_pos_feats // 2, 2)。 - 最后,使用
flatten(3)将维度 3 展平,将正弦和余弦部分合并为一个维度。所以,最终的pos_x形状为(batch_size, num_rows, num_columns, num_pos_feats),其中num_pos_feats是位置编码的特征维度数。
- 在这段代码中,首先使用
-
pos的形状:pos是通过将pos_x和pos_y沿维度 3 连接在一起,然后重新排列维度得到的。- 在连接部分,
pos_x和pos_y具有相同的形状(batch_size, num_rows, num_columns, num_pos_feats),因为它们都是经过正弦和余弦变换后的位置嵌入。 - 使用
torch.cat函数在维度 3 上连接这两个部分,结果张量的形状仍然是(batch_size, num_rows, num_columns, num_pos_feats * 2),因为连接维度上的元素总数会加倍。 - 接着,使用
.permute(0, 3, 1, 2)将维度重新排列,将通道维度移动到正确的位置。最终,pos的形状变为(batch_size, num_pos_feats * 2, num_rows, num_columns)。
总结:
pos_x的形状为(batch_size, num_rows, num_columns, num_pos_feats)。pos的形状为(batch_size, num_pos_feats * 2, num_rows, num_columns)。
六、// 和 / 的区别
// 和 / 是两种不同的除法运算符,它们执行不同类型的除法操作:
1、/ 运算符
执行浮点数除法,即使两个操作数都是整数,结果也将是浮点数。例如:
result = 7 / 3 # 结果是浮点数:2.3333333333333335 2、// 运算符
执行整数除法,它将结果截断为整数,省略小数部分。例如:
result = 7 // 3 # 结果是整数:2所以,关键区别在于 / 产生浮点数结果,而 // 产生整数结果。选择使用哪个取决于你的需求和期望的结果类型。如果你需要一个浮点数结果,可以使用 /。如果你需要一个整数结果,可以使用 //。
七、FrozenBatchNorm2d模块的作用
冻结批归一化(Frozen Batch Normalization)的主要作用是在训练深度神经网络时提供稳定性和一定的正则化效果。下面是冻结批归一化的主要作用和优势:
-
稳定性增强: 冻结批归一化将批归一化的统计信息(均值和方差)固定在训练过程中计算的值上。这可以防止在训练期间批归一化统计信息的波动,有助于提高模型的稳定性和收敛速度。特别是在小批量大小或训练数据分布不均匀的情况下,冻结批归一化可以防止模型的性能下降。
-
减少内存和计算开销: 在推理(inference)阶段,不需要计算均值和方差,因为它们在训练期间已经固定。这减少了模型的内存需求和计算开销,使推理速度更快。
-
提高泛化性能: 冻结批归一化可以被视为一种正则化技巧。由于统计信息固定,模型在训练数据上的拟合更强制,因此有助于减轻过拟合的风险,提高泛化性能。这对于小样本数据集或复杂模型特别有益。
-
迁移学习: 冻结批归一化在迁移学习中特别有用。当将一个在大型数据集上训练的模型(如预训练的模型)用于较小的目标数据集时,冻结批归一化可以防止在目标数据上过度拟合,并且通常能够更快地收敛。
-
保持模型一致性: 在某些情况下,模型的一致性对于可重复性和解释性很重要。冻结批归一化确保每次运行模型时都得到相同的输出,因为统计信息不会随着数据批次的变化而变化。
需要注意的是,冻结批归一化不适用于所有情况。它通常在训练初期使用,随着模型的收敛,可以考虑逐渐解冻批归一化层以允许统计信息逐渐适应新数据分布。决定是否使用冻结批归一化取决于具体问题和实验结果,需要谨慎权衡。
八、为什么要返回骨干网络中的中间层特征?
返回骨干网络(backbone network)中的中间层特征在深度学习中有许多重要的用途和好处,这些用途包括:
-
特征金字塔(Feature Pyramid): 返回骨干网络中的中间层特征可以用于构建特征金字塔,这对于处理不同尺度的目标或特征非常有用。特征金字塔包括来自不同网络层的特征图,每个特征图代表不同尺度的信息。这有助于改善目标检测、语义分割和实例分割等任务的性能,使模型能够识别不同大小的对象。
-
语义信息丰富: 骨干网络的低层特征包含有关边缘和纹理等低级图像信息,而高层特征包含更多的语义信息。通过返回中间层特征,可以同时获取低级和高级信息,使模型更具表征能力,有助于改善任务的性能。
-
降低计算成本: 骨干网络通常比完整的神经网络模型要深,因此返回中间层特征可以减少计算成本。在一些应用中,只需利用骨干网络的中间层特征就足够完成任务,而无需执行更深层次的计算,从而提高了效率。
-
可视化和分析: 返回中间层特征还使得模型的可视化和解释更容易。研究人员和从业者可以通过可视化中间层特征来理解模型的工作原理,分析其决策过程,并进行模型调试和改进。
-
迁移学习: 中间层特征可以用于迁移学习。在预训练模型上提取中间层特征,然后将这些特征用于不同的任务,通常会带来良好的性能,因为这些特征具有一定的泛化能力。
-
自定义任务: 返回中间层特征允许研究人员和工程师自定义网络结构,以满足特定任务的需求。他们可以根据任务的复杂性和要求选择不同层次的特征来构建自己的网络结构。
总之,返回骨干网络中的中间层特征是深度学习中的一种重要策略,它提供了更多的灵活性和性能优势,可以用于改善模型在各种计算机视觉任务中的表现。
九、设置空洞卷积的作用是什么?
replace_stride_with_dilation=[False, False, dilation]1、定义
replace_stride_with_dilation 是一个用于配置骨干网络中卷积层步幅(stride)和膨胀率(dilation)的参数列表。通常,这个参数列表用于修改卷积神经网络的行为,特别是在一些计算机视觉任务中,如语义分割或目标检测。
这个参数列表通常是一个长度为3的列表,其中包含三个元素,分别对应于骨干网络中的三个不同的阶段(通常是三个卷积层块)。每个元素可以取布尔值或整数。
解释这个参数列表的含义如下:
-
replace_stride_with_dilation[0]:这个参数控制网络的第一个卷积层是否应该使用膨胀率。如果设置为False,则表示该层不使用膨胀率,步幅仍然生效。如果设置为True,则表示该层的步幅将被替换为指定的膨胀率。 -
replace_stride_with_dilation[1]:这个参数控制网络的第二个卷积层是否应该使用膨胀率。与第一个卷积层一样,如果设置为False,则表示该层不使用膨胀率,步幅仍然生效。如果设置为True,则表示该层的步幅将被替换为指定的膨胀率。 -
replace_stride_with_dilation[2]:这个参数控制网络的第三个卷积层(如果有的话)是否应该使用膨胀率。同样,如果设置为False,则表示该层不使用膨胀率,步幅仍然生效。如果设置为True,则表示该层的步幅将被替换为指定的膨胀率。
这个参数列表的目的通常是为了调整卷积神经网络的感受野(receptive field)和特征图的分辨率。通过将步幅替换为膨胀率,可以增加卷积层的感受野,同时保持较高的特征图分辨率。这在一些计算机视觉任务中很有用,例如语义分割,其中需要捕获更广泛的上下文信息。
2、例子
例如,如果 replace_stride_with_dilation=[False, False, 2],则表示前两个卷积层的步幅将保持不变,而第三个卷积层的步幅将被替换为2,从而增加了感受野。这通常与深度学习框架中的相应参数一起使用,以控制网络中特定卷积层的行为。
3、作用
将卷积操作中的步幅(stride)替换为膨胀率(dilation)是使用空洞卷积(Dilated Convolution)的一种常见技巧。空洞卷积的作用主要包括以下几点:
-
扩大感受野(Receptive Field): 膨胀率决定了卷积核在输入特征图上采样的间隔。较大的膨胀率使得卷积核能够跳过更多的像素进行计算,从而扩大了感受野。这有助于捕获更广阔范围内的特征信息,特别是对于大尺寸的目标或对象上的特征。
-
减少特征图尺寸损失: 在传统的卷积中,通过减小步幅来增加感受野通常会导致特征图尺寸的显著减小。但在空洞卷积中,可以保持常规步幅,同时通过增加膨胀率来实现感受野的扩大,从而减少了特征图尺寸的损失,有助于保持更高分辨率的特征图。
-
多尺度特征提取: 空洞卷积允许同时在不同膨胀率下进行特征提取。这意味着可以从输入特征图中获取多个尺度的信息,有助于提高模型对多尺度对象或细节的识别能力。
-
参数效率: 空洞卷积在扩大感受野的同时,不引入额外的参数,因此相对于增加卷积核大小的传统方法,它更加参数高效。
-
语义分割和密集预测任务: 空洞卷积常用于语义分割和其他密集预测任务中,因为它可以捕获更广阔范围的上下文信息,有助于提高像素级别的预测精度。
九、normalize_before
normalize_before 是一个用于控制正则化(Normalization)层位置的参数,在Transformer等模型中经常用于调整正则化层的位置。这个参数的值可以是布尔类型(True或False),决定了正则化层是在某个操作之前还是之后应用。下面分别解释 normalize_before 参数的两种取值:
-
normalize_before=True:- 当设置为True时,正则化层位于操作之前。也就是说,输入数据首先会经过正则化,然后再进入操作(如自注意力操作或前馈神经网络操作)。
- 这种设置有助于稳定输入数据的分布,可以减少输入数据的变化范围,有助于提高模型的收敛性和训练稳定性。
- 在某些情况下,将正则化层放在操作之前可以防止梯度消失或爆炸等问题。
-
normalize_before=False:- 当设置为False时,正则化层位于操作之后。也就是说,操作的输出会先经过正则化,然后再传递给下一层。
- 这是标准的Transformer模型中的设置。它有助于稳定操作的输出,防止输出的变化范围过大,有助于模型的收敛性和泛化性能。
- 在实际应用中,这是较常见的设置。
总之,normalize_before 参数的选择通常取决于具体的任务和模型结构,以及对输入和输出数据分布的需求。不同的设置可能会影响模型的性能和训练过程,因此在实验中可以尝试不同的设置以找到最佳配置。
十、深拷贝和浅拷贝的区别
深拷贝(Deep Copy)和浅拷贝(Shallow Copy)是两种不同的拷贝(复制)对象的方式,它们在复制对象时的行为和效果不同。下面是它们的区别以及示例说明
1、浅拷贝(Shallow Copy)
浅拷贝创建一个新对象,然后将原始对象中的元素复制到新对象中,但是元素本身仍然是原始对象元素的引用。
浅拷贝只复制了对象的一层结构,不会递归复制对象内部包含的子对象。
import copyoriginal_list = [1, 2, [3, 4]]
shallow_copy_list = copy.copy(original_list)# 修改原始列表的子列表
original_list[2][0] = 999print(original_list) # 输出: [1, 2, [999, 4]]
print(shallow_copy_list) # 输出: [1, 2, [999, 4]]在上面的示例中,尽管我们修改了原始列表的子列表,但浅拷贝的列表也受到了影响,因为子列表仍然是相同的引用。
2、深拷贝(Deep Copy)
深拷贝创建一个新对象,并递归复制原始对象中的所有元素及其内部包含的所有子对象。
深拷贝确保复制了整个对象层次结构,包括嵌套对象。
import copyoriginal_list = [1, 2, [3, 4]]
deep_copy_list = copy.deepcopy(original_list)# 修改原始列表的子列表
original_list[2][0] = 999print(original_list) # 输出: [1, 2, [999, 4]]
print(deep_copy_list) # 输出: [1, 2, [3, 4]]在这个示例中,深拷贝创建了一个完全独立的对象,因此对原始列表的修改不会影响深拷贝的列表。
3、总结
浅拷贝复制对象的一层结构,子对象仍然是原始对象的引用,因此对子对象的修改会影响复制后的对象。
深拷贝递归复制整个对象层次结构,包括所有子对象,确保复制后的对象与原始对象完全独立,对原始对象或其子对象的修改不会影响复制后的对象。深拷贝一般需要更多的计算资源,因为它需要复制整个对象图。
十一、三种激活函数的对比(relu、gelu、glu)
在深度学习中,激活函数用于引入非线性性质,以便神经网络能够学习复杂的模式和特征。在这里,我们比较三种常见的激活函数:ReLU(Rectified Linear Unit)、GELU(Gaussian Error Linear Unit)和GLU(Gated Linear Unit),并讨论它们的特点和用途。
1、ReLU(Rectified Linear Unit)
ReLU 是一种简单且广泛使用的激活函数,其公式为 f(x) = max(0, x)。
- 特点:
- 非常易于计算,因为它只是简单地将负数变为零,保持正数不变。
- 在许多情况下,ReLU 能够快速收敛,使神经网络训练更加高效。
- 但存在一个问题,称为 "死亡 ReLU",在训练中,某些神经元可能会停止更新,导致输出恒定为零。
2、GELU(Gaussian Error Linear Unit)
GELU 是一种激活函数,其公式为 f(x) = 0.5 * x * (1 + tanh(sqrt(2/pi) * (x + 0.044715 * x^3)))。
- 特点:
- GELU 是一个平滑且连续的函数,与ReLU相比,它在某些情况下可以提供更好的性能。
- GELU 在自然语言处理等任务中表现良好,因为它更平滑,有助于减少梯度爆炸的问题。
- 与ReLU相比,GELU的计算成本略高。
3、GLU(Gated Linear Unit)
GLU(Gated Linear Unit)是一种激活函数,通常用于序列建模和自然语言处理任务中,它的公式包括两个部分:门控部分和线性部分。
(1)门控部分(Gate Part)
gate(x) = sigmoid(x[:d/2])- 首先,将输入向量 x 分成两个子向量,通常是将 x 的一半作为门控部分,另一半作为线性部分。假设输入向量 x 的长度为 d,那么门控部分的长度为 d/2。
- 门控部分一般用 sigmoid 激活函数进行变换,将每个元素的值压缩到 [0, 1] 的范围内。
(2)线性部分(Linear Part)
linear(x) = x[d/2:](3)GLU输出(Output)
y = gate(x) * linear(x)- 最后,将门控部分和线性部分相乘,得到GLU的输出。
GLU的关键特点是它引入了门控机制,通过门控部分来选择性地控制线性部分的信息。这使得GLU能够学习输入数据之间的复杂关系,并在一些序列建模任务中表现出色。
十二、在transformerdecoder中,为什么重复的确定是否输出return_intermediate以及 self.norm is not None:
for layer in self.layers:output = layer(output, memory, tgt_mask=tgt_mask,memory_mask=memory_mask,tgt_key_padding_mask=tgt_key_padding_mask,memory_key_padding_mask=memory_key_padding_mask,pos=pos, query_pos=query_pos)if self.return_intermediate: #if self.return_intermediate and self.norm is not None: intermediate.append(self.norm(output))if self.norm is not None:output = self.norm(output)if self.return_intermediate:intermediate.pop()intermediate.append(output) #如果return_intermediate为True,那最后一层已经被normif self.return_intermediate: #将多个decoder的输出拼接return torch.stack(intermediate)return output.unsqueeze(0)在这段代码中,看起来多次检查 self.return_intermediate 和 self.norm is not None 的值可能有些冗余。让我们一步步解释为什么要这样做:
-
self.return_intermediate:self.return_intermediate是一个布尔值,用于确定是否要返回中间层的输出。如果为True,模型将会在每个层次的处理之后记录中间层的输出,并将它们存储在列表intermediate中。- 在代码中有多个检查
self.return_intermediate的地方,这是因为它影响着中间层输出的记录和返回。第一个检查是在循环中,用于确定是否将当前层的输出添加到intermediate列表中。第二个检查是在最后,用于确定是否将最后一层的输出作为模型的最终输出。 - 这样设计的好处是,它允许根据
self.return_intermediate的值在不同的阶段采取不同的行为,以适应不同的需求。
-
self.norm is not None:self.norm是一个正规化(Normalization)层,通常用于将模型的输出归一化。- 第一个检查
self.norm is not None是在循环中,用于确定是否在每个层的输出上应用正规化操作。这是因为正规化通常是在每个层的输出后进行的。 - 第二个检查
self.norm is not None是在最后,用于确定是否在最终输出上应用正规化。这是因为如果self.return_intermediate为True,最后一层的输出通常已经在循环中被正规化过了,所以不需要再次正规化。
虽然有多个检查,但这种设计是为了确保在不同的情况下能够灵活地处理中间层输出和正规化。如果 self.return_intermediate 或 self.norm 的值在模型的不同部分需要不同的行为,这些检查是合理的。这种方式使得代码更具可配置性和通用性,能够适应多种使用情况。
相关文章:
)
DETR中的问题汇总(代码)
一、讲述一下torch.tensor()和torch.as_tensor()的区别 torch.tensor() 和 torch.as_tensor() 都是 PyTorch 中用于创建张量(Tensor)的函数,但它们有一些区别,主要涉及到张量的内存管理方式和数据拷贝。以下是它们的主要区别&…...

华为云云耀云服务器L实例评测|使用华为云耀云服务器L实例的CentOS部署Docker并运行Tomcat应用
目录 前言 步骤1:登录到华为云耀云服务器L实例 步骤2:安装Docker 并验证Docker安装 步骤3:拉取Tomcat镜像并运行Tomcat容器 步骤4:放行8080端口 步骤5:访问tomcat 步骤6:管理Tomcat容器 小结 前言 …...

Java基础---第八篇
系列文章目录 文章目录 系列文章目录一、a=a+b与a+=b有什么区别吗?二、try catch finally,try里有return,finally还执行么?三、Excption与Error包结构一、a=a+b与a+=b有什么区别吗? += 操作符会进行隐式自动类型转换,此处a+=b隐式的将加操作的结果类型强制转换为持有结果…...
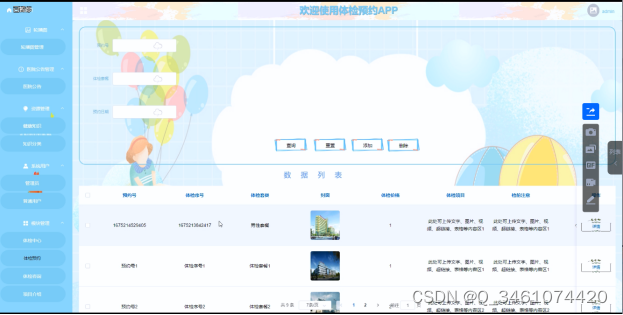
(附源码)springboot体检预约APP 计算机毕设16370
目 录 摘要 1 绪论 1.1开发背景 1.2研究现状 1.3springboot框架介绍 1.4论文结构与章节安排 2 Springboot体检预约APP系统分析 2.1 可行性分析 2.1.1 技术可行性分析 2.1.2 经济可行性分析 2.1.3 操作可行性分析 2.2 系统流程分析 2.2.1 数据添加流程 2.2.2 数据…...

Spring的注解开发-@Component的三个衍生注解
由于JavaEE开发是分层的(三层架构体系,控制层、服务层、持久层),为了每层Bean标识的注解语义化更加明确,Component又衍生出以下三个注解 注解用途Repository(仓库)标识持久层(DAO&am…...

无线WIFI工业路由器可用于楼宇自动化
钡铼4G工业路由器支持BACnet MS/TP协议。BACnet MS/TP协议是一种用于工业自动化的开放式通信协议,被广泛应用于楼宇自动化、照明控制、能源管理等领域。通过钡铼4G工业路由器的支持,可以使设备间实现高速、可靠的数据传输,提高自动化水平。 钡…...

基于长短期神经网络铜期货价格预测,基于LSTM的铜期货价格预测,LSTM的详细原理
目录 背影 摘要 代码和数据下载:基于长短期神经网络的铜期货开盘价格预测,基于长短期神经网络的铝价格期货开盘价预测(代码完整,数据齐全)资源-CSDN文库 https://download.csdn.net/download/abc991835105/88230626 LSTM的基本定义 LSTM实现的步骤 基于长短期神经网络LSTM…...

300元开放式耳机推荐哪个、最值得入手的开放式耳机推荐
开放式耳机成为今年耳机界的主流了,如果你还不曾体验过开放式耳机,那真的是太OUT了!相对于传统的入耳式耳机对听力的损伤,开放式耳机有着很长远的益处,能够很好的保护听力。随着技术的成熟,开放式耳机也在音…...

嵌入式学习笔记(37) S5PV210的PWM定时器
7.3.1为什么叫PWM定时器 (1)叫定时器说明它本质上的原理是定时器。 (2)叫PWM定时器,是因为这个定时器天然是用来产生PWM波形的。 7.3.2 PWM定时器介绍 (1)S5PV210有5个PWM定时器。其中0、1、2、3各自对应一个外部GPIO,可以通过这些对应的GPIO产生PWM…...

python工具-base64-zip-json
python工具-base64-zip-json # 先 base64 解码,再 zip 解码,再打印 json 内容,支持多个字符串解码import sys import base64 import zlib import jsondef enc_json_zip_base64(input_data):json_object json.loads(input_data)zip_data zl…...

Centos 7安装pm2 , 操作等常用命令
Centos 7安装pm2 1、首先需要安装node,node安装教程前一篇已经说了,是安装pm2 [rootlocalhost ~]# npm install -g pm2 2、pm2 命令参考 复制代码 2.1 启动进程/应用 pm2 start bin/www 或 pm2 start app.js 2.2 重命名进程/应用 pm2 start app.js -…...

vue 实现弹出菜单,解决鼠标点击其他区域的检测问题
弹出菜单应该具有的功能,当鼠标点击其他区域时,则关闭该菜单。 问题来了,怎么检测鼠标点击了其他区域而不是当前菜单? 百度“JS检测区域外的点击事件”,会发现有很多方法,有递归检测父元素,有遍…...
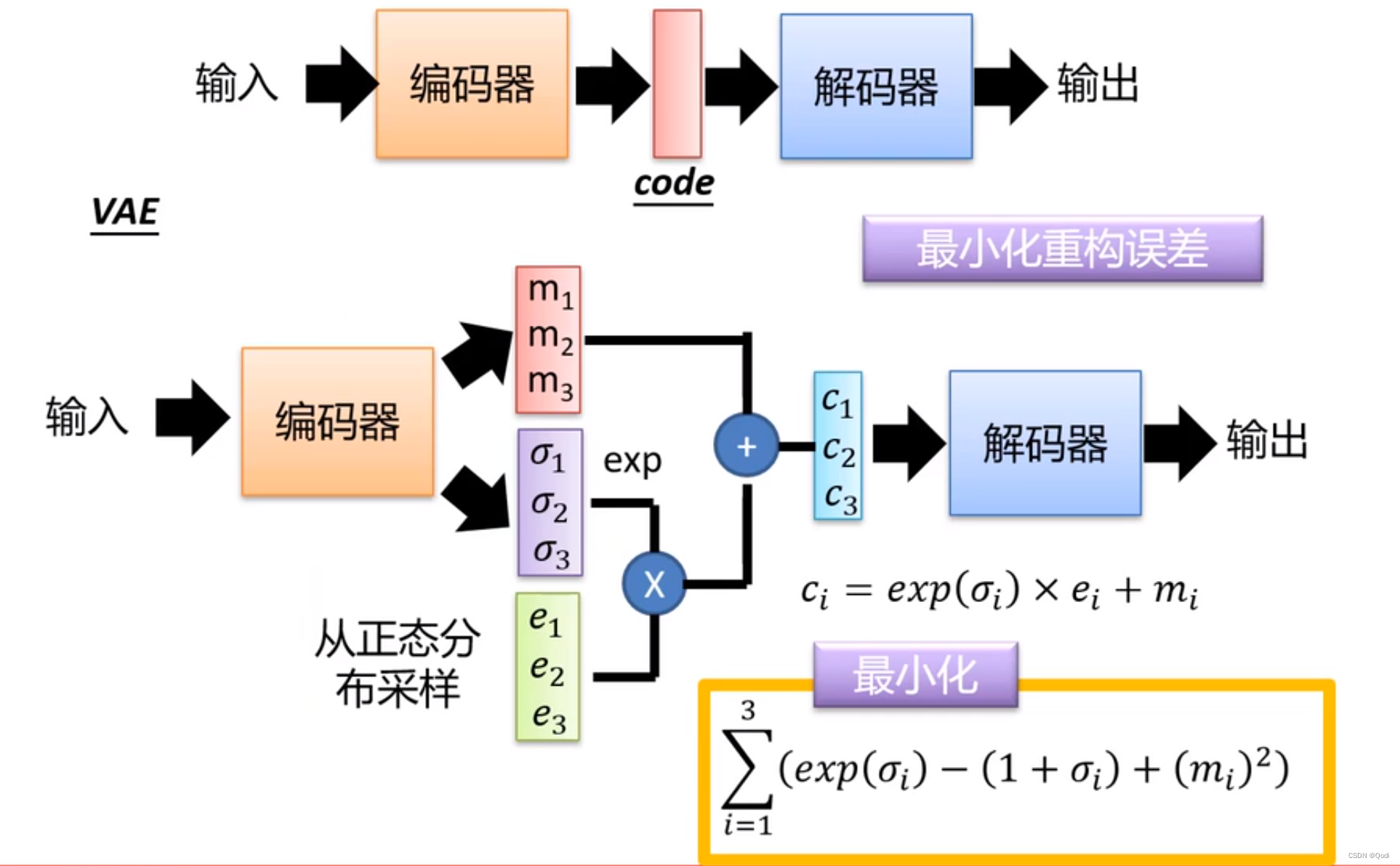
经典网络解(三) 生成模型VAE | 自编码器、变分自编码器|有监督,无监督
文章目录 1 有监督与无监督2 生成模型2.1 重要思路 3 VAE编码器怎么单独用?解码器怎么单独用?为什么要用变分变分自编码器推导高斯混合模型 4 代码实现 之前我们的很多网络都是有监督的 生成网络都是无监督的(本质就是密度估计)&a…...
gif怎么转换成视频MP4?
gif怎么转换成视频MP4?GIF动图已成为一种风靡网络的流行的特殊图片文件,其循环播放和逐帧呈现的特点使其在社交媒体、聊天应用等场合广泛应用,平时我们进行群聊是,大家总会一些gif动态表情的出现而感觉非常的开行,gif动…...

标准化、逻辑回归、随机梯度参数估计
机器学习入门 数据预处理: 将?替换为缺失值 data data.replace(to_replace"?",valuenp.nan)丢掉缺失值 data.dropna(how"any) #howall删除全是缺失值的行和列 #haowany删除有缺失值的行和列将数据集划分成测试集和训练集 data[colu…...

【数据结构】【C++】封装哈希表模拟实现unordered_map和unordered_set容器
【数据结构】&&【C】封装哈希表模拟实现unordered_map和unordered_set容器 一.哈希表的完成二.改造哈希表(泛型适配)三.封装unordered_map和unordered_set的接口四.实现哈希表迭代器(泛型适配)五.封装unordered_map和unordered_set的迭代器六.解决key不能修改问题七.实…...

26967-2011 一般用喷油单螺杆空气压缩机
声明 本文是学习GB-T 26967-2011 一般用喷油单螺杆空气压缩机. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了一般用喷油单螺杆空气压缩机(以下简称"单螺杆空压机")的术语和定义、型号、基本 参数、要求、试验方法、…...
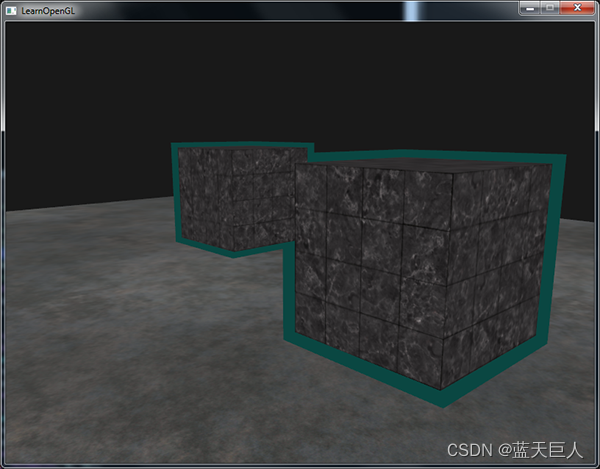
Opengl之模板测试
当片段着色器处理完一个片段之后,模板测试(Stencil Test)会开始执行,和深度测试一样,它也可能会丢弃片段。接下来,被保留的片段会进入深度测试,它可能会丢弃更多的片段。模板测试是根据又一个缓冲来进行的,…...
iPhone苹果手机复制粘贴内容提示弹窗如何取消关闭提醒?
经常使用草柴APP查询淘宝、天猫、京东商品优惠券拿购物返利的iPhone苹果手机用户,复制商品链接后打开草柴APP粘贴商品链接查券时总是弹窗提示粘贴内容,为此很多苹果iPhone手机用户联系客服询问如何关闭iPhone苹果手机复制粘贴内容弹窗提醒功能的方法如下…...

释放潜力:人工智能对个性化学习的影响
人工智能有潜力通过使个性化学习成为一种实用且可扩展的方法来彻底改变教育。它使教育工作者能够满足每个学生的独特需求,促进参与并提高整体学习成果。然而,必须解决道德问题,并确保技术仍然是教育工作者手中的工具,为学生创造更…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现企业微信功能
1. 开发环境准备 安装DevEco Studio 3.1: 从华为开发者官网下载最新版DevEco Studio安装HarmonyOS 5.0 SDK 项目配置: // module.json5 {"module": {"requestPermissions": [{"name": "ohos.permis…...
协议转换利器,profinet转ethercat网关的两大派系,各有千秋
随着工业以太网的发展,其高效、便捷、协议开放、易于冗余等诸多优点,被越来越多的工业现场所采用。西门子SIMATIC S7-1200/1500系列PLC集成有Profinet接口,具有实时性、开放性,使用TCP/IP和IT标准,符合基于工业以太网的…...

API网关Kong的鉴权与限流:高并发场景下的核心实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 引言 在微服务架构中,API网关承担着流量调度、安全防护和协议转换的核心职责。作为云原生时代的代表性网关,Kong凭借其插件化架构…...
基础)
6个月Python学习计划 Day 16 - 面向对象编程(OOP)基础
第三周 Day 3 🎯 今日目标 理解类(class)和对象(object)的关系学会定义类的属性、方法和构造函数(init)掌握对象的创建与使用初识封装、继承和多态的基本概念(预告) &a…...

Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...
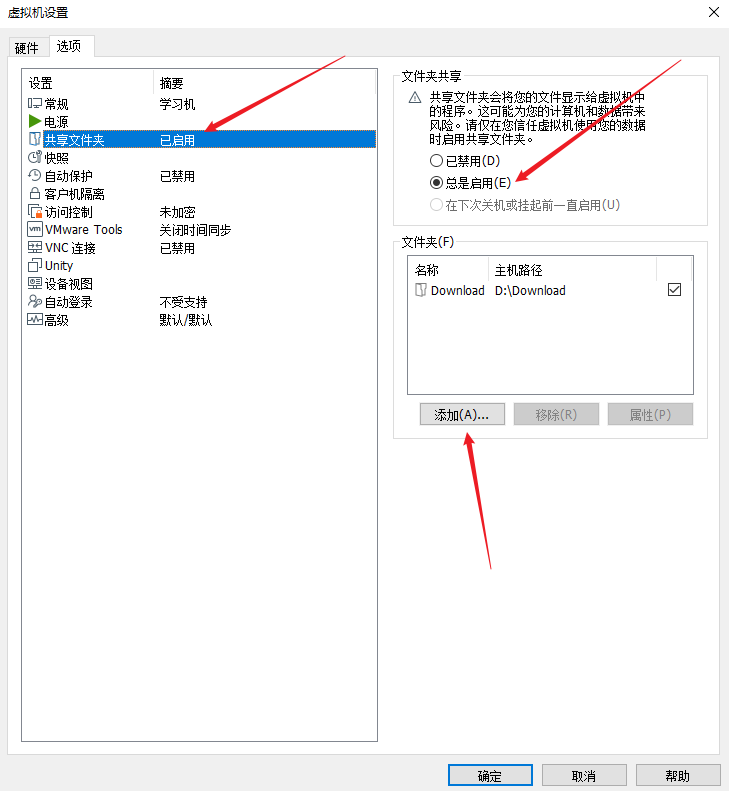
Linux操作系统共享Windows操作系统的文件
目录 一、共享文件 二、挂载 一、共享文件 点击虚拟机选项-设置 点击选项,设置文件夹共享为总是启用,点击添加,可添加需要共享的文件夹 查询是否共享成功 ls /mnt/hgfs 如果显示Download(这是我共享的文件夹)&…...