Hive SQL初级练习(30题)
前言
Hive 的重要性不必多说,离线批处理的王者,Hive 用来做数据分析,SQL 基础必须十分牢固。
环境准备
建表语句
这里建4张表,下面的练习题都用这些数据。
-- 创建学生表
create table if not exists student_info(stu_id string COMMENT '学生id',stu_name string COMMENT '学生姓名',birthday string COMMENT '出生日期',sex string COMMENT '性别'
)
row format delimited fields terminated by ','
stored as textfile;-- 创建课程表
create table if not exists course_info(course_id string COMMENT '课程id',course_name string COMMENT '课程名',tea_id string COMMENT '任课老师id'
)
row format delimited fields terminated by ','
stored as textfile;-- 创建老师表
create table if not exists teacher_info(tea_id string COMMENT '老师id',tea_name string COMMENT '学生姓名'
)
row format delimited fields terminated by ','
stored as textfile;-- 创建分数表
create table if not exists score_info(stu_id string COMMENT '学生id',course_id string COMMENT '课程id',score int COMMENT '成绩'
)
row format delimited fields terminated by ','
stored as textfile;
数据
student_info.txt
001,彭于晏,1995-05-16,男
002,胡歌,1994-03-20,男
003,周杰伦,1995-04-30,男
004,刘德华,1998-08-28,男
005,唐国强,1993-09-10,男
006,陈道明,1992-11-12,男
007,陈坤,1999-04-09,男
008,吴京,1994-02-06,男
009,郭德纲,1992-12-05,男
010,于谦,1998-08-23,男
011,潘长江,1995-05-27,男
012,杨紫,1996-12-21,女
013,蒋欣,1997-11-08,女
014,赵丽颖,1990-01-09,女
015,刘亦菲,1993-01-14,女
016,周冬雨,1990-06-18,女
017,范冰冰,1992-07-04,女
018,李冰冰,1993-09-24,女
019,邓紫棋,1994-08-31,女
020,宋丹丹,1991-03-01,女teacher_info.txt
1001,张高数
1002,李体音
1003,王子文
1004,刘丽英course_info.txt
01,语文,1003
02,数学,1001
03,英语,1004
04,体育,1002
05,音乐,1002score_info.txt
001,01,94
002,01,74
004,01,85
005,01,64
006,01,71
007,01,48
008,01,56
009,01,75
010,01,84
011,01,61
012,01,44
013,01,47
014,01,81
015,01,90
016,01,71
017,01,58
018,01,38
019,01,46
020,01,89
001,02,63
002,02,84
004,02,93
005,02,44
006,02,90
007,02,55
008,02,34
009,02,78
010,02,68
011,02,49
012,02,74
013,02,35
014,02,39
015,02,48
016,02,89
017,02,34
018,02,58
019,02,39
020,02,59
001,03,79
002,03,87
004,03,89
005,03,99
006,03,59
007,03,70
008,03,39
009,03,60
010,03,47
011,03,70
012,03,62
013,03,93
014,03,32
015,03,84
016,03,71
017,03,55
018,03,49
019,03,93
020,03,81
001,04,54
002,04,100
004,04,59
005,04,85
007,04,63
009,04,79
010,04,34
013,04,69
014,04,40
016,04,94
017,04,34
020,04,50
005,05,85
007,05,63
009,05,79
015,05,59
018,05,87加载数据
加载数据到 Hive 的数据源目录
load data local inpath '/opt/module/hive-3.1.2/datas/student_info.txt' into table student_info;
load data local inpath '/opt/module/hive-3.1.2/datas/teacher_info.txt' into table teacher_info;
load data local inpath '/opt/module/hive-3.1.2/datas/course_info.txt' into table course_info;
load data local inpath '/opt/module/hive-3.1.2/datas/score_info.txt' into table score_info;
第一章 简单查询
1.1、查找特定条件
重点就是一个 where ,可能涉及到一点多表联结。
1.1.1 查询姓名中带“冰”的学生名单
简单的可以用 like 配合 % 和 _ ,复杂的可以使用 Hive 扩展的 rlike 配合正则表达式。
-- 查询姓名中带“冰”的学生名单
select * from student_info where stu_name like '%冰%';1.1.2 查询姓“王”老师的个数
-- 查询姓“王”老师的个数
select count(*) from teacher_info where tea_name like '王%';
-- 或者
select count(*) from teacher_info where tea_name rlike '^王';1.1.3 检索课程编号为“04”且分数小于60的学生的课程信息,结果按分数降序排列
通过 course_id 联结两张表,找到不及格的成绩所对应的课程信息。
select c.* from course_info c
join score_info s on c.course_id = s.course_id
where c.course_id = 4 and s.score < 60
order by s.score desc;1.1.4 查询数学成绩不及格的学生和其对应的成绩,按照学号升序排序
- 查询数学课对应的 course_id
- 通过该 course_id 在 score_info 表中查出不及格的成绩的学生信息
- 通过学生信息中的 stu_id 字段将 score_info 表和 student_info 表联结起来,输出需要的字段(学生信息,成绩)。
select stu.*,s.score from student_info stu
join (select * from score_infowhere course_id =(select course_id from course_info where course_name = '数学')
)son s.stu_id = stu.stu_id
where s.score < 60
order by stu.stu_id;第二章 汇总分析
2.1 汇总分析
这里需要注意的是,聚合函数通常和 group by 配合使用!表示分组再做聚合处理。
2.1.1 查询编号为“02”的课程的总成绩
--查询编号为“02”的课程的总成绩
select course_id,sum(score) from score_info where course_id = 02
group by course_id;2.1.2 查询参加考试的学生个数
select count(distinct stu_id) from score_info;2.2 分组
重点就是一个 group by。
2.2.1 查询各科成绩最高和最低的分,显示格式:课程号,最高分,最低分
不同的科目对应不同的 course_id ,所以我们用 group by course_id。
-- 同样这里有聚合函数配合 group by 来使用
select course_id,max(score) max,min(score) min from score_info
group by course_id;2.2.2 查询每门课程有多少学生参加了考试
select course_id, count(stu_id) from score_info
group by course_id;2.2.3 查询男生、女生人数
-- 查询男生、女生人数
select sex,count(stu_id) from student_info
group by sex;2.3 分组结果的条件
重点就是 group by 之后的条件判断语句用 having。
2.3.1 查询平均成绩大于60分的学生的学号和平均成绩
这里需要先分组后判断,所以不能用 where,因为 group by 后面的条件语句只能是 having。
-- 这里需要分组后再判断条件
select stu_id,avg(score) avg_score from score_info
group by stu_id
having avg_score>60;2.3.2 查询至少选修四门课程的学生学号
-- 查询至少选修四门课程的学生学号
select stu_id,count(course_id) cnt from score_info
group by stu_id
having cnt>=4;2.3.3 查询同姓的学生名单并统计同姓人数大于2的姓
这里用到一个没用过的函数 substr() ,需要记忆一下。
select t1.first_name,count(stu_id) cnt from (select *,substr(stu_name,0,1) first_name from student_info)t1
group by t1.first_name
having cnt>=2;2.3.4 查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列
多重排序判断直接逗号隔开即可。
-- 查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列
select course_id,avg(score) avg_score from score_info
group by course_id
order by avg_score,course_id desc ;
2.3.5 统计参加考试人数大于等于15的学科
-- 统计参加考试人数大于等于15的学科
select course_id,count(*) cnt from score_info
group by course_id
having cnt>=15;2.4 查询结果排序&分组指定条件
2.4.1 查询学生的总成绩并按照总成绩降序排序
-- 查询学生的总成绩并按照总成绩降序排序
select stu_id,sum(score) sum_score from score_info
group by stu_id
order by sum_score desc;2.4.2 按照 学生id 语文 数学 英语 有效课程数 平均成绩 的格式输出成绩,没有成绩的记为 0
这里用到了 Hive 中的 if 语句,它的语法是:
IF(condition, true_value, false_value)其中,condition是要评估的条件,true_value是当条件为真时要返回的值,false_value是当条件为假时要返回的值。
比如;
SELECT name, age, IF(age >= 18, 'Adult', 'Minor') AS age_group
FROM users;此外,还可以使用多重 if 嵌套语句:
SELECT name, age, IF(age >= 18 AND gender = 'Male', 'Adult Male', IF(age >= 18 AND gender = 'Female', 'Adult Female', IF(age < 18 AND gender = 'Male', 'Minor Male', 'Minor Female'))) AS age_group
FROM users;本题:这里的反引号是引用的作用,这里代表的是 列名。
select s.stu_id,sum(if(c.course_name='语文',score,0)) `语文`,sum(if(c.course_name='数学',score,0)) `数学`,sum(if(c.course_name='英语',score,0)) `英语`,count(*) `有效课程数`,avg(s.score) `平均成绩`
from score_info sjoin course_info c on s.course_id = c.course_id
group by s.stu_id
order by `平均成绩` desc ;2.4.3 查询一共参加三门课程且其中一门为语文课程的学生的id和姓名
有点复杂,需要好好理解掌握。
-- 查询一共参加三门课程且其中一门为语文课程的学生的id和姓名
select t2.stu_id,s.stu_name from (
select t1.stu_id from (select stu_id,course_id from score_info where stu_id in (select stu_id from score_infowhere course_id = '01') -- 筛选出有语文成绩的学生的id) t1 group by t1.stu_idhaving count(t1.course_id)=3) t2
join student_info s on t2.stu_id = s.stu_id;第三章 复杂查询
3.1 子查询
3.1.1 查询所有课程成绩均小于60分的学生的学号、姓名
我们根据 stu_id 把每个学生的成绩信息聚合在一起。然后巧妙的使用了 if 语句来判断是否有不及格的科目,如果>=60分,结果+1,最后用 sum 函数统计出结果,如果 sum 等于0,则说明全部不及格。
-- 查询所有课程成绩均小于60分的学生的学号、姓名
select t1.stu_id,s.stu_name from(select stu_id,sum(if(score>=60,1,0)) flag from score_infogroup by stu_idhaving flag=0) t1
join student_info s on s.stu_id = t1.stu_id;3.1.2 查询没有学全所有课的学生的学号、姓名
这里需要注意:
- 在Hive SQL中,子查询的结果可能返回多行数据,因此需要使用IN关键字而不是=关键字。IN关键字用于匹配子查询结果中的任何一个值,而=关键字只能匹配单个值。
- group by 不一定必须和聚合函数搭配使用,比如下面的查询 course_info 表的行数。
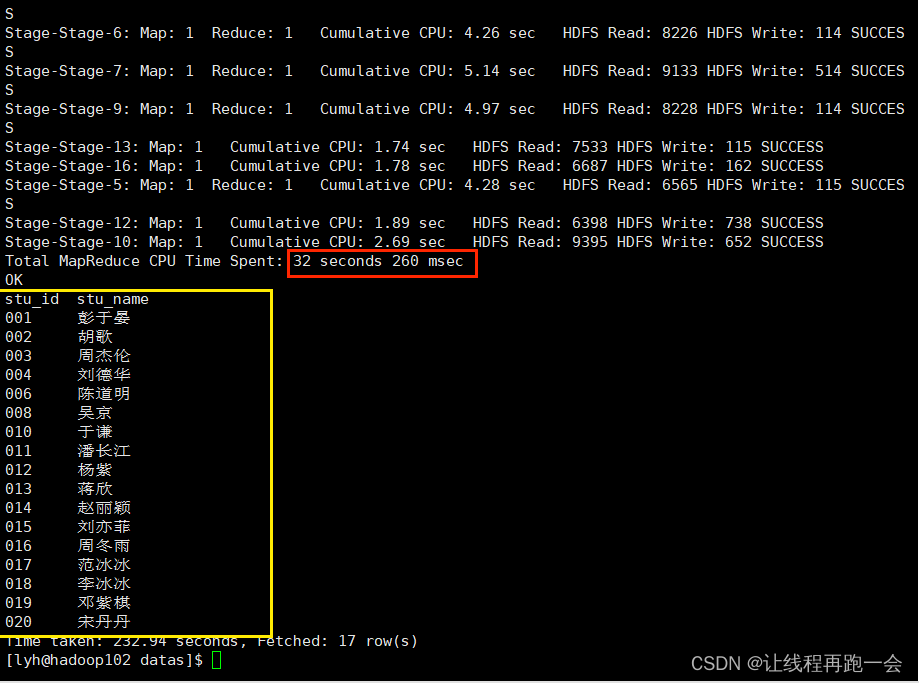
-- 查询没有学全所有课的学生的学号、姓名
select stu_id, stu_name
from student_info
where stu_id not in (select stu_idfrom score_infogroup by stu_idhaving count(distinct course_id) = (select count(distinct course_id) from course_info)
);
3.1.3 查询出只选修了三门课程的全部学生的学号和姓名
这里同样需要注意:当子查询的结果是多行值时,用 in 而不是 = !
-- 查询出只选修了三门课程的全部学生的学号和姓名
select stu_id,stu_name from student_info where stu_id in (select stu_id from score_infogroup by stu_idhaving count(course_id)=3);第四章 多表查询
4.1 表联结
4.1.1 查询有两门以上的课程不及格的同学的姓名及其平均成绩
-- 查询有两门以上的课程不及格的同学的姓名及其平均成绩
select stu_name,avg_score from student_info st join (select stu_id,avg(score) avg_score from score_infogroup by stu_idhaving sum(if(score<60,1,0))>=2) t1
on st.stu_id=t1.stu_id;4.1.2 查询所有学生的学号、姓名、选课数、总成绩
-- 查询所有学生的学号、姓名、选课数、总成绩
select t1.stu_id,s.stu_name,cnt,sum_score from (select stu_id,count(course_id) cnt,sum(score) sum_score from score_infogroup by stu_id)t1 join student_info s
on t1.stu_id=s.stu_id;4.1.3 查询平均成绩大于85的所有学生的学号、姓名和平均成绩
-- 查询平均成绩大于85的所有学生的学号、姓名和平均成绩
select t1.stu_id,s.stu_name,avg from (select stu_id,avg(score) avg from score_infogroup by stu_idhaving avg>85)t1 join student_info s
on t1.stu_id=s.stu_id;4.1.4 查询学生的选课情况:学号,姓名,课程号,课程名称
-- 查询学生的选课情况:学号,姓名,课程号,课程名称
select t1.stu_id,s.stu_name,t1.course_id,c.course_name from(select stu_id,course_id from score_info)t1
join student_info s
on t1.stu_id=s.stu_id
join course_info c
on c.course_id=t1.course_id;输出结果明显按照科目分开, 前几行都是选语文的学生信息。
或者
-- 查询学生的选课情况:学号,姓名,课程号,课程名称
select t1.stu_id,s.stu_name,t1.course_id,c.course_name from(select stu_id,course_id from score_infogroup by stu_id, course_id)t1
join student_info s
on t1.stu_id=s.stu_id
join course_info c
on c.course_id=t1.course_id;这里的输出结果明显按照姓名分开,前几行都是同一个学生的选课信息(这里的 group by要么指定两个字段(即我们要查询的 stu_id 和 course_id),要么就不需要 group by)。
4.1.5 查询出每门课程的及格人数和不及格人数
-- 查询出每门课程的及格人数和不及格人数
select c.course_name,`及格人数`,`不及格人数` from (select course_id,sum(if(score>=60,1,0)) `及格人数`,sum(if(score<60,1,0)) `不及格人数` from score_infogroup by course_id)t1
join course_info c
on t1.course_id=c.course_id;4.1.6 查询课程编号为03且课程成绩在80分以上的学生的学号和姓名及课程信息
这里需要注意如果查询结果中没有用到聚合函数就少用 group by,因为group by会触发生成 mapreduce 程序;能用 where 最好,因为 where 不会触发产生 mapreduce 程序;where 可以秒出结果,而 group by需要好多秒。
-- 查询课程编号为03且课程成绩在80分以上的学生的学号和姓名及课程信息
select t1.stu_id,s.stu_name,c.course_name from (select stu_id,course_id from score_infowhere course_id=03 and score>80)t1
join course_info c
on t1.course_id=c.course_id
join student_info s
on t1.stu_id=s.stu_id;4.2 多表连接
4.2.1 课程编号为"01"且课程分数小于60,按分数降序排列的学生信息
-- 课程编号为"01"且课程分数小于60,按分数降序排列的学生信息
select s.*,t1.score from student_info s join (select stu_id,score from score_infowhere course_id=01 and score<60)t1
on s.stu_id=t1.stu_id
order by t1.score desc;4.2.2 查询所有课程成绩在70分以上的学生的姓名、课程名称和分数,按分数升序排列
-- 查询所有课程成绩在70分以上的学生的姓名、课程名称和分数,按分数升序排列
select s.stu_id,s.stu_name,c.course_name,s2.score from student_info s
join (select stu_id,sum(if(score>=70,0,1)) flag from score_infogroup by stu_idhaving flag=0) t1
on s.stu_id=t1.stu_id
left join score_info s2
on s.stu_id=s2.stu_id
left join course_info c
on s2.course_id=c.course_id;4.2.3 查询该学生不同课程的成绩相同的学生编号、课程编号、学生成绩
-- 查询该学生不同课程的成绩相同的学生编号、课程编号、学生成绩
select sc1.stu_id,sc1.course_id,sc1.score from score_info sc1
join score_info sc2
on sc1.stu_id=sc2.stu_id
and sc1.course_id <> sc2.course_id
and sc1.score=sc2.score;4.2.4 查询课程编号为“01”的课程比“02”的课程成绩高的所有学生的学号
-- 查询课程编号为“01”的课程比“02”的课程成绩高的所有学生的学号
select s1.stu_id from (select stu_id,course_id,score from score_info sc1where sc1.course_id=01) s1
join (select sc2.stu_id,sc2.course_id,sc2.score from score_info sc2where sc2.course_id=02) s2
on s1.stu_id=s2.stu_id
where s1.score>s2.score;4.2.5 查询学过编号为“01”的课程并且也学过编号为“02”的课程的学生的学号、姓名
-- 查询学过编号为“01”的课程并且也学过编号为“02”的课程的学生的学号、姓名
select s.stu_id,s.stu_name from(select stu_id,sum(if(course_id=01,1,0)+if(course_id=02,1,0)) sumOfCourse from score_infogroup by stu_id)t1
join student_info s
on t1.stu_id=s.stu_id
where sumOfCourse=2;4.2.6 查询学过“李体音”老师所教的所有课的同学的学号、姓名
-- 查询学过“李体音”老师所教的所有课的同学的学号、姓名
select t1.stu_id,si.stu_name
from(select stu_id from score_info siwhere course_id in(select course_id from course_info cjoin teacher_info ton c.tea_id = t.tea_idwhere tea_name='李体音' --李体音教的所有课程)group by stu_idhaving count(*)=2 --学习所有课程的学生
)t1
left join student_info si
on t1.stu_id=si.stu_id;4.2.7 查询学过“李体音”老师所讲授的任意一门课程的学生的学号、姓名
selectt1.stu_id,si.stu_name
from
(selectstu_idfrom score_info siwhere course_id in(selectcourse_idfrom course_info cjoin teacher_info ton c.tea_id = t.tea_idwhere tea_name='李体音')group by stu_id
)t1
left join student_info si
on t1.stu_id=si.stu_id;4.2.8 查询没学过"李体音"老师讲授的任一门课程的学生姓名
selectstu_id,stu_name
from student_info
where stu_id not in
(selectstu_idfrom score_info siwhere course_id in(selectcourse_idfrom course_info cjoin teacher_info ton c.tea_id = t.tea_idwhere tea_name='李体音')group by stu_id
);4.2.9 查询至少有一门课与学号为“001”的学生所学课程相同的学生的学号和姓名
selectsi.stu_id,si.stu_name
from score_info sc
join student_info si
on sc.stu_id = si.stu_id
where sc.course_id in
(selectcourse_idfrom score_infowhere stu_id='001' --001的课程
) and sc.stu_id <> '001' --排除001学生
group by si.stu_id,si.stu_name;4.2.10 按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
-- 按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
select stu_name,course_name,sc.score,t1.avg_score from score_info sc
join student_info si
on sc.stu_id=si.stu_id
join course_info ci
on sc.course_id=ci.course_id
join(
select stu_id,avg(score) avg_score from score_info
group by stu_id,course_id)t1
on sc.stu_id=t1.stu_id
order by t1.avg_score desc;总结
本想着跳过这些题目的,但是最后还是刷了一遍,期间确实发现了很多基础的不足,总之这次刷题收获满满。
相关文章:
Hive SQL初级练习(30题)
前言 Hive 的重要性不必多说,离线批处理的王者,Hive 用来做数据分析,SQL 基础必须十分牢固。 环境准备 建表语句 这里建4张表,下面的练习题都用这些数据。 -- 创建学生表 create table if not exists student_info(stu_id st…...

NSSCTF做题(6)
[HCTF 2018]Warmup 查看源代码得到 开始代码审计 <?php highlight_file(__FILE__); class emmm { public static function checkFile(&$page) { $whitelist ["source">"source.php","hint"…...
公众号商城小程序的作用是什么
公众号是微信平台重要的生态体系之一,它可以与其它体系连接实现多种效果,同时公众号内容创作者非常多,个人或企业商家等,会通过公众号分享信息或获得收益等,而当商家需要在微信做私域经营或想要转化粉丝、售卖产品时就…...

关于 FOCA
目录 注意团队成员成品官网项目社区 版本信息致谢 注意 此文章会随时更新,最好收藏起来,总对你有好处。我们不定时发布一些 IT 内容,所以请关注我们。 此账号为 FOCA 唯一的官方账号,请勿轻易相信其他账号所发布内容。 团队 全…...
TVP专家谈腾讯云 Cloud Studio:开启云端开发新篇章
导语 | 近日,由腾讯云 TVP 团队倾力打造的 TVP 吐槽大会第六期「腾讯云 Cloud Studio」专场圆满落幕,6 位资深的 TVP 专家深度体验腾讯云 Cloud Studio 产品,提出了直击痛点的意见与建议,同时也充分肯定了腾讯云 Cloud Studio 的实…...

2023-09-27 Cmake 编译 OpenCV+Contrib 源码通用设置
Cmake 编译 OpenCV 通用设置 特点: 包括 Contrib 模块关闭了 Example、Test、OpenCV_AppLinux、Windows 均只生成 OpenCV_World 需要注意: 每次把 Cmake 缓存清空,否则,Install 路径可能被设置为默认路径Windows 需要注意编译…...
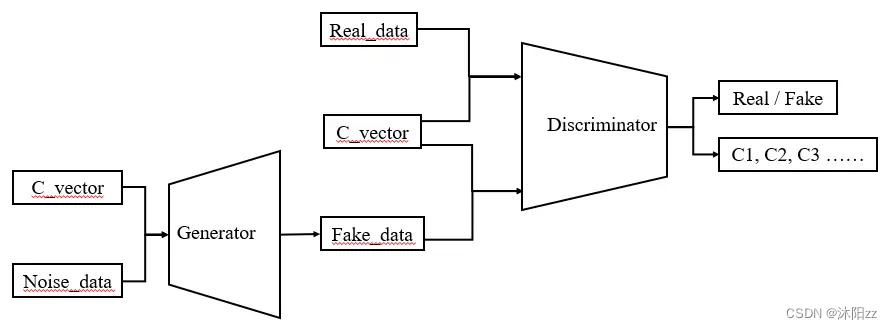
ACGAN
CGAN通过在生成器和判别器中均使用标签信息进行训练,不仅能产生特定标签的数据,还能够提高生成数据的质量;SGAN(Semi-Supervised GAN)通过使判别器/分类器重建标签信息来提高生成数据的质量。既然这两种思路都可以提高生成数据的质…...

模块化CSS
1、什么是模块化CSS 模块化CSS是一种将CSS样式表的规则和样式定义封装到模块或组件级别的方法,以便于更好地管理、维护和组织样式代码。这种方法通过将样式与特定的HTML元素或组件相关联,提供了一种更具可维护性、可复用性和隔离性的方式来处理样式。简单…...

意大利储能公司【Energy Dome】完成1500万欧元融资
来源:猛兽财经 作者:猛兽财经 猛兽财经获悉,总部位于意大利米兰的储能公司Energy Dome今日宣布已完成1500万欧元B轮融资。 本轮融资完成后,Energy Dome的融资总额已经达到了5500万欧元,本轮融资的参与者包括阿曼创新发…...

【Java 进阶篇】JDBC Connection详解:连接到数据库的关键
在Java中,要与数据库进行交互,需要使用Java数据库连接(JDBC)。JDBC允许您连接到不同类型的数据库,并执行SQL查询、插入、更新和删除操作。在JDBC中,连接数据库是一个重要的步骤,而Connection对象…...
vue-cli项目打包体积太大,服务器网速也拉胯(100kb/s),客户打开网站需要等十几秒!!! 尝试cdn优化方案
一、首先用插件webpack-bundle-analyzer查看自己各个包的体积 插件用法参考之前博客 vue-cli项目中,使用webpack-bundle-analyzer进行模块分析,查看各个模块的体积,方便后期代码优化 二、发现有几个插件体积较大,有改成CDN引用的…...

【优秀学员统计】python实现-附ChatGPT解析
1.题目 优秀学员统计 知识点排序统计编程基础 时间限制: 1s 空间限制: 256MB 限定语言:不限 题目描述: 公司某部门软件教导团正在组织新员工每日打卡学习活动,他们开展这项学习活动已经一个月了,所以想统计下这个月优秀的打卡员工。每个员工会对应一个id,每天的打卡记录记录…...
餐饮外卖配送小程序商城的作用是什么?
餐饮是支撑市场的主要行业之一,其市场规模很大,从业商家从大到小不计其数,对众商家来说,无论门店大小都希望不断生意增长,但在实际发展中却会面对不少痛点; 餐饮很适合线上经营,无论第三方外卖…...
【QT】使用toBase64方法将.txt文件的明文变为非明文(类似加密)
目录 0.环境 1.背景 2.详细代码 2.1 .h主要代码 2.2 .cpp主要代码,主要实现上述的四个方法 0.环境 windows 11 64位 Qt Creator 4.13.1 1.背景 项目需求:我们项目中有配置文件(类似.txt,但不是这个格式,本文以…...

《QDebug 2023年9月》
一、Qt Widgets 问题交流 1.Qt 程序在 Windows 上以管理员权限运行时无法响应拖放(Drop) 无论是 Widget 还是 QML 程序,以管理员权限运行时,都无法响应拖放操作。可以右键管理员权限打开 Qt Creator,然后丢个文本文件…...

C++使用高斯模糊处理图像
C使用高斯模糊处理图像 cv::GaussianBlur 是 OpenCV 中用于对图像进行高斯模糊处理的函数。高斯模糊是一种常用的图像滤波方法,它可以减少图像中的噪声,并平滑图像以降低细节级别。 void cv::GaussianBlur(const cv::Mat& src, cv::Mat& dst, …...

多维时序 | MATLAB实现PSO-BP多变量时间序列预测(粒子群优化BP神经网络)
多维时序 | MATLAB实现PSO-BP多变量时间序列预测(粒子群优化BP神经网络) 目录 多维时序 | MATLAB实现PSO-BP多变量时间序列预测(粒子群优化BP神经网络)效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现PSO-BP粒子群优化BP神经网络多变量时间序列预测ÿ…...

LeetCode 283. 移动零
移动零 问题描述 LeetCode 283. 移动零 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意,必须在不复制数组的情况下原地对数组进行操作。 解决思路 为了将所有 0 移动到数组的末尾&#…...

【数据结构】选择排序 堆排序(二)
目录 一,选择排序 1,基本思想 2, 基本思路 3,思路实现 二,堆排序 1,直接选择排序的特性总结: 2,思路实现 3,源代码 最后祝大家国庆快乐! 一…...

opencv实现目标跟踪及视频转存
创建跟踪器 def createTypeTracker(trackerType): 读取视频第一帧,选择跟踪的目标 读第一帧。 ok, frame video.read() 选择边界框 bbox cv2.selectROI(frame, False) 初始化跟踪器 tracker_type ‘MIL’ tracker createTypeTracker(tracker_type) 用第一…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...

系统掌握PyTorch:图解张量、Autograd、DataLoader、nn.Module与实战模型
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文通过代码驱动的方式,系统讲解PyTorch核心概念和实战技巧,涵盖张量操作、自动微分、数据加载、模型构建和训练全流程&#…...

人工智能 - 在Dify、Coze、n8n、FastGPT和RAGFlow之间做出技术选型
在Dify、Coze、n8n、FastGPT和RAGFlow之间做出技术选型。这些平台各有侧重,适用场景差异显著。下面我将从核心功能定位、典型应用场景、真实体验痛点、选型决策关键点进行拆解,并提供具体场景下的推荐方案。 一、核心功能定位速览 平台核心定位技术栈亮…...

比特币:固若金汤的数字堡垒与它的四道防线
第一道防线:机密信函——无法破解的哈希加密 将每一笔比特币交易比作一封在堡垒内部传递的机密信函。 解释“哈希”(Hashing)就是一种军事级的加密术(SHA-256),能将信函内容(交易细节…...