大数据核心技术是什么
大数据的核心层:数据采集层、数据存储与分析层、数据共享层、数据应用层,可能叫法有所不同本质上的角色都大同小异。
大数据的核心技术都包括什么?
1、数据采集
数据采集的任务就是把数据从各种数据源中采集和存储到数据存储上,期间有可能会做一些简单的清洗。数据源的种类比较多:
网站日志:作为互联网行业,网站日志占的份额最大,网站日志存储在多台网站日志服务器上,一般是在每台网站日志服务器上部署flume agent,实时的收集网站日志并存储到HDFS上;
业务数据库:业务数据库的种类也是多种多样,有Mysql、Oracle、SqlServer等,这时候,我们迫切的需要一种能从各种数据库中将数据同步到HDFS上的工具,Sqoop是一种,但是Sqoop太过繁重,而且不管数据量大小,都需要启动MapReduce来执行,而且需要Hadoop集群的每台机器都能访问业务数据库;应对此场景,淘宝开源的DataX,是一个很好的解决方案,有资源的话,可以基于DataX之上做二次开发,就能非常好的解决。当然,Flume通过配置与开发,也可以实时的从数据库中同步数据到HDFS。
来自于Ftp/Http的数据源:有可能一些合作伙伴提供的数据,需要通过Ftp/Http等定时获取,DataX也可以满足该需求;
其他数据源:比如一些手工录入的数据,只需要提供一个接口或小程序即可完成。
2、数据存储与分析
毋庸置疑HDFS是大数据环境下数据仓库/数据平台最完美的数据存储解决方案。
离线数据分析与计算,也就是对实时性要求不高的部分,在笔者看来,Hive还是首当其冲的选择,丰富的数据类型、内置函数;压缩比非常高的ORC文件存储格式;非常方便的SQL支持,使得Hive在基于结构化数据上的统计分析远远比MapReduce要高效的多,一句SQL可以完成的需求,开发MR可能需要上百行代码。
当然,使用Hadoop框架自然而然也提供了MapReduce接口,如果真的很乐意开发Java,或者对SQL不熟,那么也可以使用MapReduce来做分析与计算。Spark是这两年非常火的,经过实践,它的性能的确比MapReduce要好很多,而且和Hive、Yarn结合的越来越好,因此,必须支持使用Spark和SparkSQL来做分析和计算。因为已经有Hadoop Yarn,使用Spark其实是非常容易的,不用单独部署Spark集群。
3、数据共享
这里的数据共享,其实指的是前面数据分析与计算后的结果存放的地方,其实就是关系型数据库和NOSQL数据库;前面使用Hive、MR、Spark、SparkSQL分析和计算的结果,还是在HDFS上,但大多业务和应用不可能直接从HDFS上获取数据,那么就需要一个数据共享的地方,使得各业务和产品能方便的获取数据;和数据采集层到HDFS刚好相反,这里需要一个从HDFS将数据同步至其他目标数据源的工具,同样,DataX也可以满足。
另外一些实时计算的结果数据可能由实时计算模块直接写入数据共享。
4、数据应用
业务产品业务产品所使用的数据,已经存在于数据共享层,直接从数据共享层访问即可;报表(FineReport、业务报表)同业务产品,报表所使用的数据,一般也是已经统计汇总好的,存放于数据共享层;即席查询即席查询的用户有很多,有可能是数据开发人员、网站和产品运营人员、数据分析人员、甚至是部门老大,他们都有即席查询数据的需求;这种即席查询通常是现有的报表和数据共享层的数据并不能满足他们的需求,需要从数据存储层直接查询。即席查询一般是通过SQL完成,最大的难度在于响应速度上,使用Hive有点慢,可以用SparkSQL,它的响应速度较Hive快很多,而且能很好的与Hive兼容。当然,你也可以使用Impala,如果不在乎平台中再多一个框架的话。
OLAP目前,很多的OLAP工具不能很好的支持从HDFS上直接获取数据,都是通过将需要的数据同步到关系型数据库中做OLAP,但如果数据量巨大的话,关系型数据库显然不行;这时候,需要做相应的开发,从HDFS或者HBase中获取数据,完成OLAP的功能;比如:根据用户在界面上选择的不定的维度和指标,通过开发接口,从HBase中获取数据来展示。
其它数据接口这种接口有通用的,有定制的。比如:一个从Redis中获取用户属性的接口是通用的,所有的业务都可以调用这个接口来获取用户属性。
5、实时计算
现在业务对数据仓库实时性的需求越来越多,比如:实时的了解网站的整体流量;实时的获取一个广告的曝光和点击;在海量数据下,依靠传统数据库和传统实现方法基本完成不了,需要的是一种分布式的、高吞吐量的、延时低的、高可靠的实时计算框架;Storm在这块是比较成熟了,但我选择Spark Streaming,原因很简单,不想多引入一个框架到平台中,另外,Spark Streaming比Storm延时性高那么一点点,那对于我们的需要可以忽略。
我们目前使用Spark Streaming实现了实时的网站流量统计、实时的广告效果统计两块功能。做法也很简单,由Flume在前端日志服务器上收集网站日志和广告日志,实时的发送给Spark Streaming,由Spark Streaming完成统计,将数据存储至Redis,业务通过访问Redis实时获取。
6、任务调度与监控
在数据仓库/数据平台中,有各种各样非常多的程序和任务,比如:数据采集任务、数据同步任务、数据分析任务等;这些任务除了定时调度,还存在非常复杂的任务依赖关系,比如:数据分析任务必须等相应的数据采集任务完成后才能开始;数据同步任务需要等数据分析任务完成后才能开始;
这就需要一个非常完善的任务调度与监控系统,它作为数据仓库/数据平台的中枢,负责调度和监控所有任务的分配与运行。
猎聘大数据研究院发布了《2022未来人才就业趋势报告》
从排名来看,2022年1-4月各行业中高端人才平均年薪来看,人工智能行业中高端人才平均年薪最高,为31.04万元;金融行业中高端人才以27.69万元的平均年薪位居第二;通信、大数据行业中高端人才平均年薪分别为27.51万元、25.23万元,位列第三、第四;IT/互联网行业中高端人才平均年薪23.02万元,位列第七。
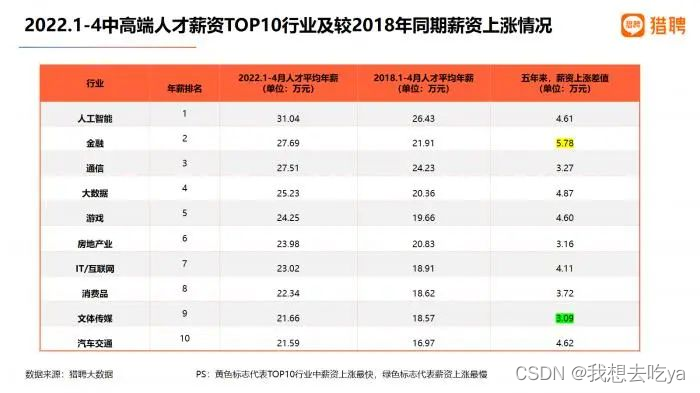
图表来源:《2022未来人才就业趋势报告》
如果你觉得很高,被平均了这样?那么打开Boss直聘,搜大数据工程师:
我们来做下数据分析:
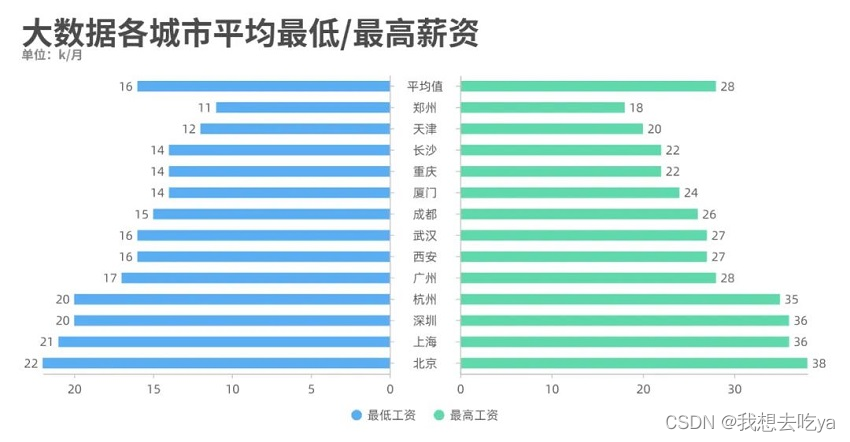
薪资那一列都有一个最低薪资和最高薪资,我们通过不同城市来对比分析一下,发现北京的工资水平最高,最低为22k,最高为38k。
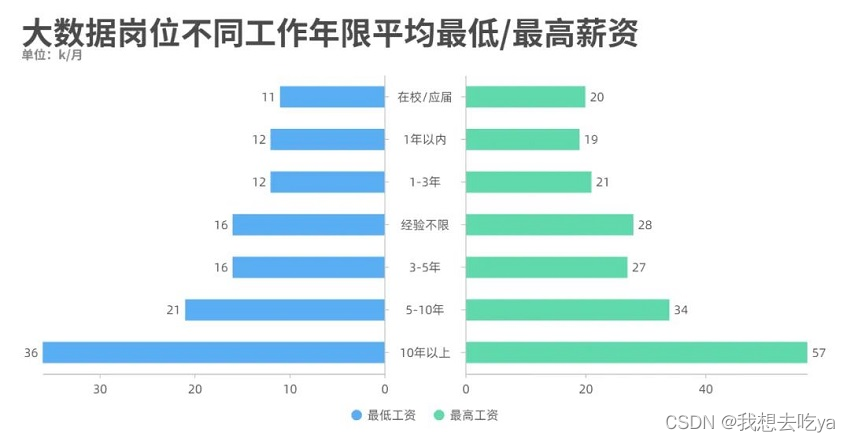
工作年限也是一个制约工资水平的很大因素,从图中可以看出,即使是刚毕业,也能达到一个11-20k的薪资范围。
而学历要求来说,大部分为本科,其次为大专和硕士,其他比较少,以至于在图中并没有显示出来。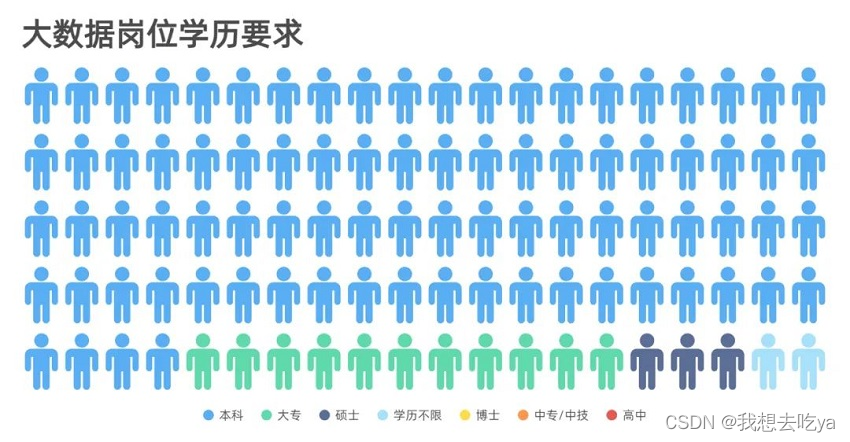
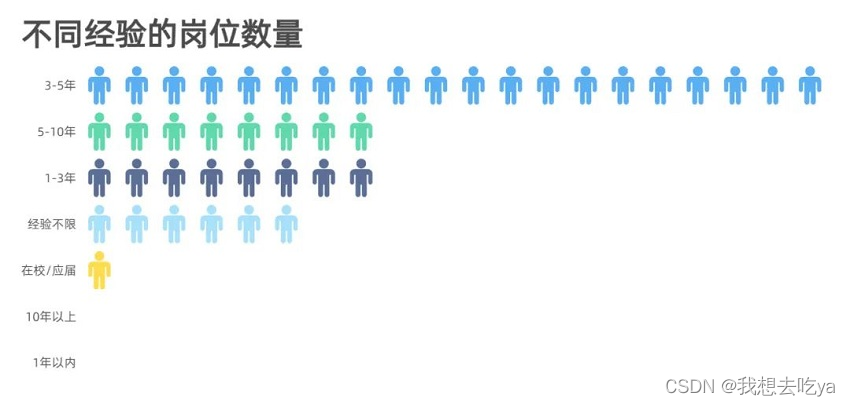
企业对不同岗位的要求以3-5年的居多,企业当然是需要有一定工作经验的员工,但是在实际招聘中,如果你有项目经验,且理论知识没问题,企业也会放宽条件。
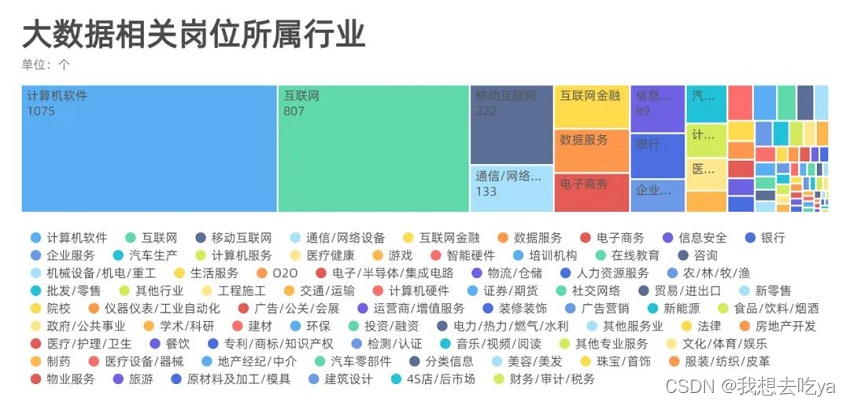
分析不同行业, 我们发现,大数据岗位需求分布在各行各业,主要还是在计算机软件和互联网最多,也有可能是这个招聘软件决定的,毕竟Boss直聘还是以互联网行业为主。
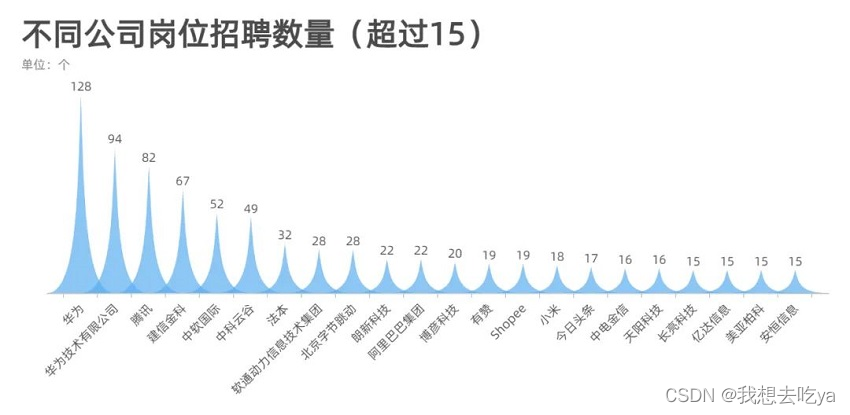
来看看哪些公司在招聘大数据相关岗位,从这个超过15的数量来看,华为,腾讯,阿里,字节,这些大厂对这个岗位的需求量还是很大的。
那么这些岗位都需要什么技能呢?Spark,Hadoop,数据仓库,Python,SQL,Mapreduce,Hbase等等

根据国内的发展形势,大数据未来的发展前景会非常好。自 2018 年企业纷纷开始数字化转型,一二线城市对大数据领域的人才需求非常强烈,未来几年,三四线城市的人才需求也会大增。
在大数据领域,国内发展的比较晚,从 2016 年开始,仅有 200 多所大学开设了大数据相关的专业,也就是说 2020 年第一批毕业生才刚刚步入社会,我国市场环境处于急需大数据人才但人才不足的阶段,所以未来大数据领域会有很多的就业机遇。
薪资高、缺口大,自然成为职场人的“薪”选择!
任何学习过程都需要一个科学合理的学习路线,才能够有条不紊的完成我们的学习目标。Python+大数据所需学习的内容纷繁复杂,难度较大,为大家整理了一个全面的Python+大数据学习路线图,帮大家理清思路,攻破难关!
Python+大数据学习路线图详细介绍
第一阶段 大数据开发入门
学前导读:从传统关系型数据库入手,掌握数据迁移工具、BI数据可视化工具、SQL,对后续学习打下坚实基础。
1.大数据数据开发基础MySQL8.0从入门到精通
MySQL是整个IT基础课程,SQL贯穿整个IT人生,俗话说,SQL写的好,工作随便找。本课程从零到高阶全面讲解MySQL8.0,学习本课程之后可以具备基本开发所需的SQL水平。
2022最新MySQL知识精讲+mysql实战案例_零基础mysql数据库入门到高级全套教程
第二阶段 大数据核心基础
学前导读:学习Linux、Hadoop、Hive,掌握大数据基础技术。
2022版大数据Hadoop入门教程
Hadoop离线是大数据生态圈的核心与基石,是整个大数据开发的入门,是为后期的Spark、Flink打下坚实基础的课程。掌握课程三部分内容:Linux、Hadoop、Hive,就可以独立的基于数据仓库实现离线数据分析的可视化报表开发。
2022最新大数据Hadoop入门视频教程,最适合零基础自学的大数据Hadoop教程
第三阶段 千亿级数仓技术
学前导读:本阶段课程以真实项目为驱动,学习离线数仓技术。
数据离线数据仓库,企业级在线教育项目实战(Hive数仓项目完整流程)
本课程会、建立集团数据仓库,统一集团数据中心,把分散的业务数据集中存储和处理 ;目从需求调研、设计、版本控制、研发、测试到落地上线,涵盖了项目的完整工序 ;掘分析海量用户行为数据,定制多维数据集合,形成数据集市,供各个场景主题使用。
大数据项目实战教程_大数据企业级离线数据仓库,在线教育项目实战(Hive数仓项目完整流程)
第四阶段 PB内存计算
学前导读:Spark官方已经在自己首页中将Python作为第一语言,在3.2版本的更新中,高亮提示内置捆绑Pandas;课程完全顺应技术社区和招聘岗位需求的趋势,全网首家加入Python on Spark的内容。
1.python入门到精通(19天全)
python基础学习课程,从搭建环境。判断语句,再到基础的数据类型,之后对函数进行学习掌握,熟悉文件操作,初步构建面向对象的编程思想,最后以一个案例带领同学进入python的编程殿堂。
全套Python教程_Python基础入门视频教程,零基础小白自学Python必备教程
2.python编程进阶从零到搭建网站
学完本课程会掌握Python高级语法、多任务编程以及网络编程。
Python高级语法进阶教程_python多任务及网络编程,从零搭建网站全套教程
3.spark3.2从基础到精通
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。本课程基于Python语言学习Spark3.2开发,课程的讲解注重理论联系实际,高效快捷,深入浅出,让初学者也能快速掌握。让有经验的工程师也能有所收获。
Spark全套视频教程,大数据spark3.2从基础到精通,全网首套基于Python语言的spark教程
4.大数据Hive+Spark离线数仓工业项目实战
通过大数据技术架构,解决工业物联网制造行业的数据存储和分析、可视化、个性化推荐问题。一站制造项目主要基于Hive数仓分层来存储各个业务指标数据,基于sparkSQL做数据分析。核心业务涉及运营商、呼叫中心、工单、油站、仓储物料。
全网首次披露大数据Spark离线数仓工业项目实战,Hive+Spark构建企业级大数据平台
相关文章:
大数据核心技术是什么
大数据的核心层:数据采集层、数据存储与分析层、数据共享层、数据应用层,可能叫法有所不同本质上的角色都大同小异。 大数据的核心技术都包括什么? 1、数据采集 数据采集的任务就是把数据从各种数据源中采集和存储到数据存储上,…...

「TCG 规范解读」初识 TPM 2.0 库续一
可信计算组织(Ttrusted Computing Group,TCG)是一个非盈利的工业标准组织,它的宗旨是加强在相异计算机平台上的计算环境的安全性。TCG于2003年春成立,并采纳了由可信计算平台联盟(the Trusted Computing Platform Alli…...

task与function
task和function主要是有助于代码的可重用性,都可以在module-endmodule之外声明。 1.function 1.1.function逻辑的综合 function:一个只有1个wire型输出值、全是组合逻辑的函数,且函数名即输出信号名,小括号中按顺序例化输入信号。…...
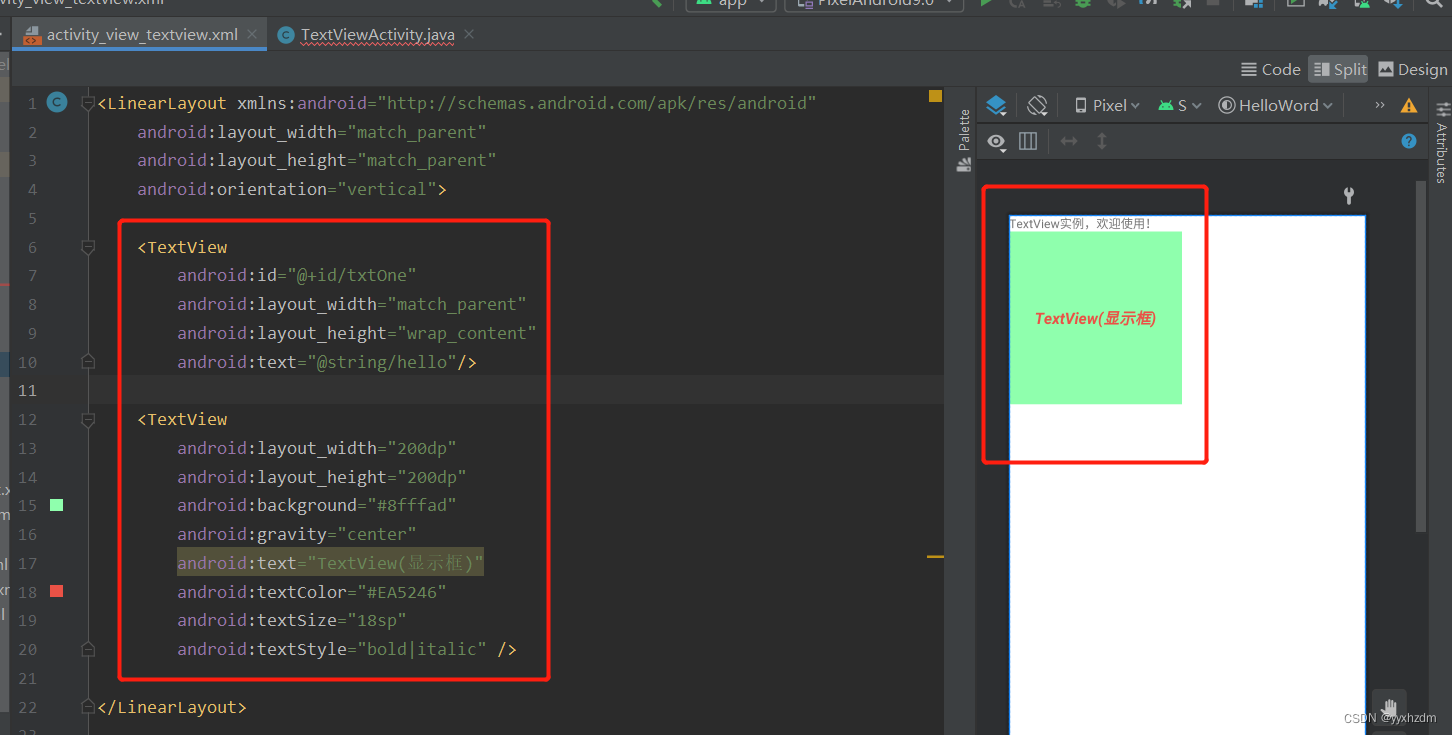
Android 基础知识4-3.1 TextView(文本框)详解
一、前言 TextView就是一个显示文本标签的控件,就是用来显示文本。可以在代码或者 XML中设置字体,字体大小,字体颜色 ,字体样式 (加粗级斜体),文字截断(比如:只显示10个字…...
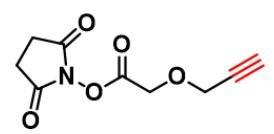
点击化学 PEG 试剂1858242-47-3,Propargyl丙炔基-PEG1-乙酸活性酯
Propargyl-PEG1-Acetic acid-NHS ester,丙炔基-聚乙二醇-乙酸琥珀酰亚胺酯,丙炔基-PEG1-乙酸活性酯,丙炔基-PEG1-乙酸-NHS 酯产品规格:1.CAS号:1858242-47-32.分子式:C9H9NO53.分子量:211.174.包…...

正则表达式是如何运作的?
在日常的开发工作当中,我们必不可免的会碰到需要使用正则的情况。 正则在很多时候通过不同的组合方式最后都可以达到既定的目标结果。比如我们有一个需要匹配的字符串: hello,我们可以通过 / .</p>/ 以及 / .?</p>/ 来匹配&…...

JVM参数GC线程数ParallelGCThreads设置
1. ParallelGCThreads参数含义JVM垃圾回收(GC)算法的两个优化标的:吞吐量和停顿时长。JVM会使用特定的GC收集线程,当GC开始的时候,GC线程会和业务线程抢占CPU时间,吞吐量定义为CPU用于业务线程的时间与CPU总消耗时间的比值。为了承…...

java 线程的那些事
什么是进程: 你把它理解成一个软件 什么是线程: 你把它理解成软件里面的一个功能,做的事情 什么是多线程: 你把它理解成 软件里面的某一个功能,原先是一个人累死累活的在那里完成,现在好了,多…...
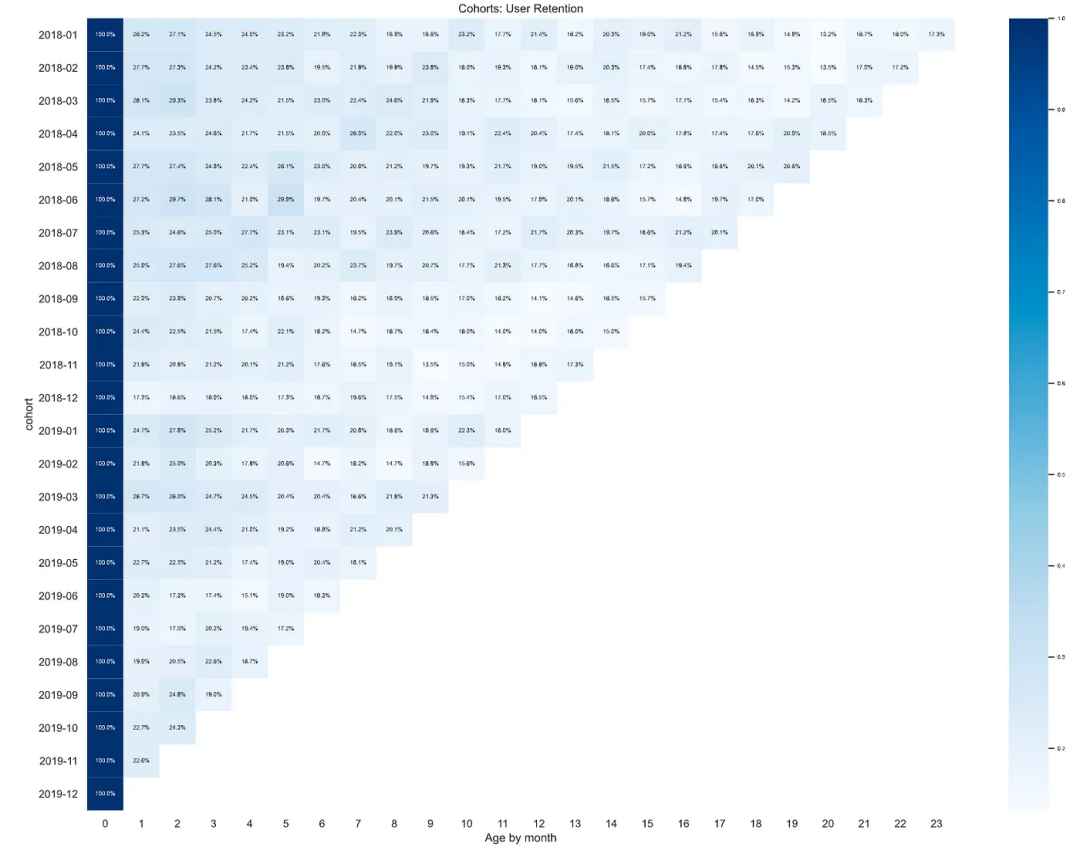
如何利用 Python 进行客户分群分析(附源码)
每个电子商务数据分析师必须掌握的一项数据聚类技能 如果你是一名在电子商务公司工作的数据分析师,从客户数据中挖掘潜在价值,来提高客户留存率很可能就是你的工作任务之一。 然而,客户数据是巨大的,每个客户的行为都不一样。20…...

D1s RDC2022纪念版开发板开箱评测及点屏教程
作者new_bee 本文转自:https://bbs.aw-ol.com/topic/3005/ 目录 芯片介绍开发板介绍RT-Smart用户态系统编译使用感想引用 1. 芯片介绍 RISC-V架构由于其精简和开源的特性,得到业界的认可,近几年可谓相当热门。操作系统方面有RT-Thread&am…...

了解一下TCP/IP协议族
在《简单说说OSI网络七层模型》中讲到,目前实际使用的网络模型是 TCP/IP 模型,它对 OSI 模型进行了简化,只包含了四层,从上到下分别是应用层、传输层、网络层和链路层(网络接口层),每一层都包含…...

【第十九部分】存储过程与存储函数
【第十九部分】存储过程与存储函数 文章目录【第十九部分】存储过程与存储函数19. 存储过程与存储函数19.1 存储过程19.2 创建、调用存储过程19.2.1 不带参数19.2.2 IN 类型19.2.3 OUT类型19.2.4 IN和OUT类型同时使用19.2.5 INOUT类型19.3 存储函数19.4 创建、调用存储函数19.5…...

字节序
字节序 字节序:字节在内存中存储的顺序。 小端字节序:数据的高位字节存储在内存的高位地址,低位字节存储在内存的低位地址 大端字节序:数据的低位字节存储在内存的高位地址,高位字节存储在内存的低位地址 bit ( 比特…...
PDF文件怎么转图片格式?转换有技巧
PDF文件有时为了更美观或者更直观的展现出效果,我们会把它转成图片格式,这样不论是归档总结还是存储起来都会更为高效。有没有合适的转换方法呢?这就来给你们罗列几种我个人用过体验还算不错的方式,大家可以拿来参考一下哈。1.用电…...
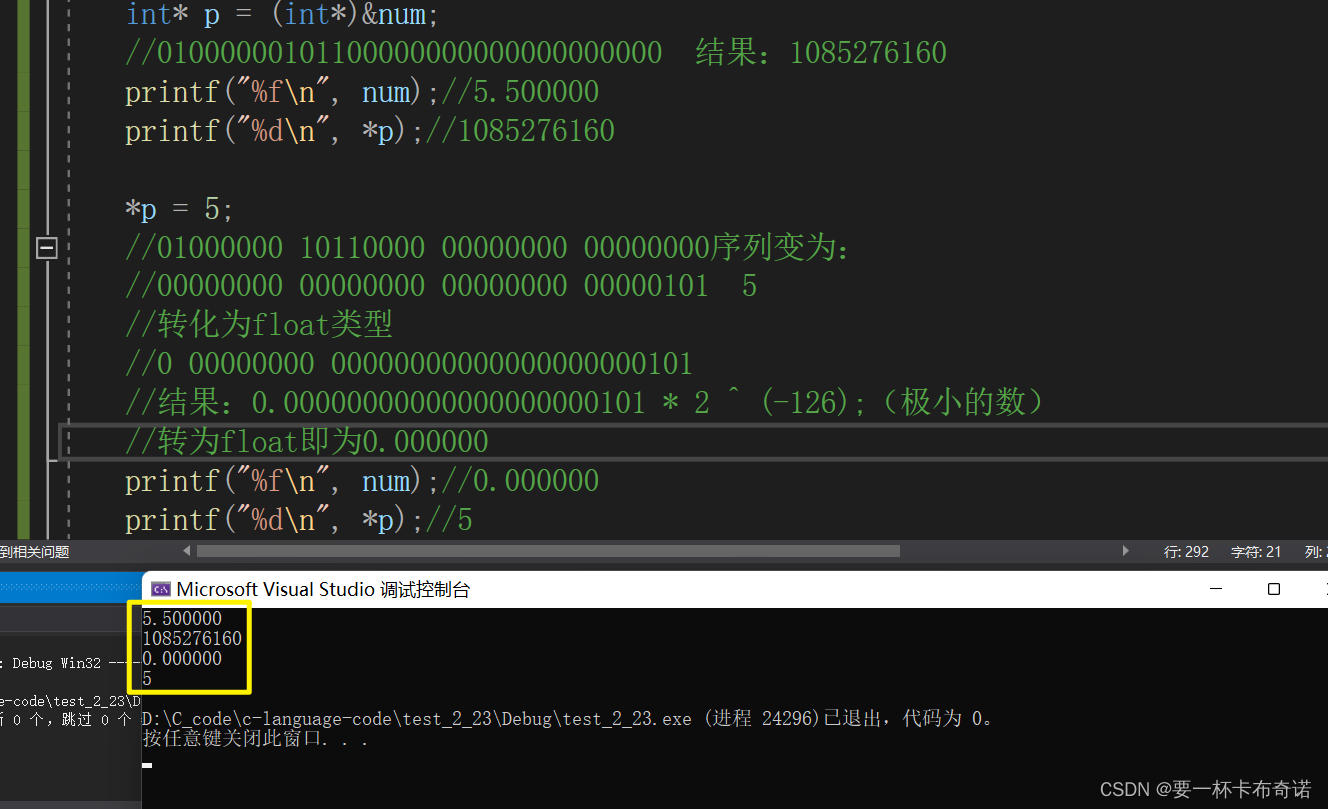
筑基七层 —— 数据在内存中的存储?拿来吧你
目录 零:移步 一.修炼必备 二.问题思考 三.整型在内存中的存储 三.大端字节序和小端字节序 四.浮点数在内存中的存储 零:移步 CSDN由于我的排版不怎么好看,我的有道云笔记相当的美观,请移步至有道云笔记 一.修炼必备 1.入门…...
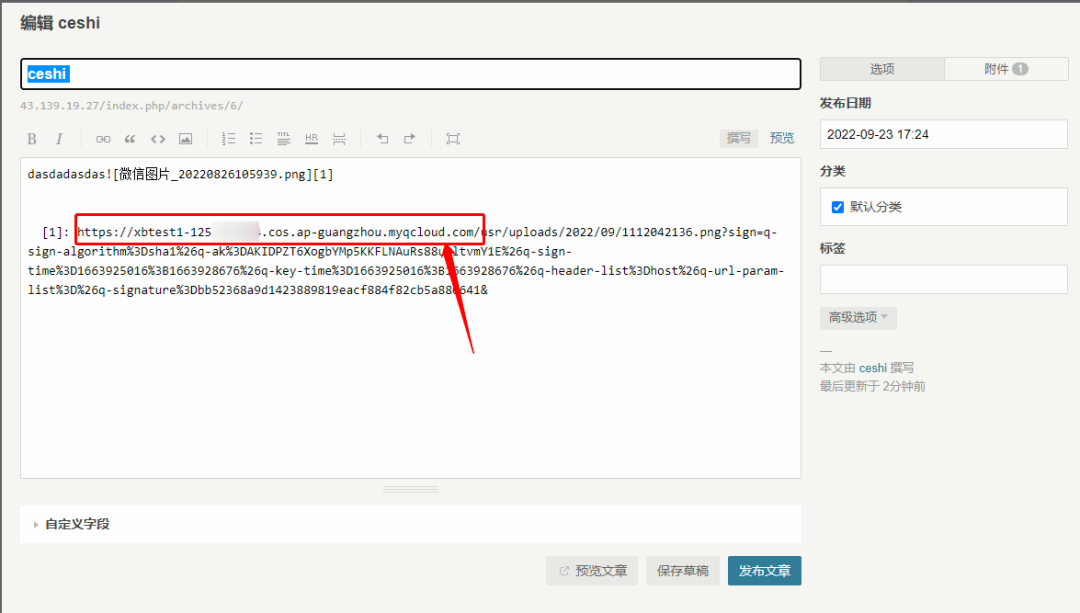
Typecho COS插件实现网站静态资源存储到COS,降低本地存储负载
Typecho 简介Typecho 是一个简单、强大的轻量级开源博客平台,用于建立个人独立博客。它具有高效的性能,支持多种文件格式,并具有对设备的响应式适配功能。Typecho 相对于其他 CMS 还有一些特殊优势:包括可扩展性、不同数据库之间的…...
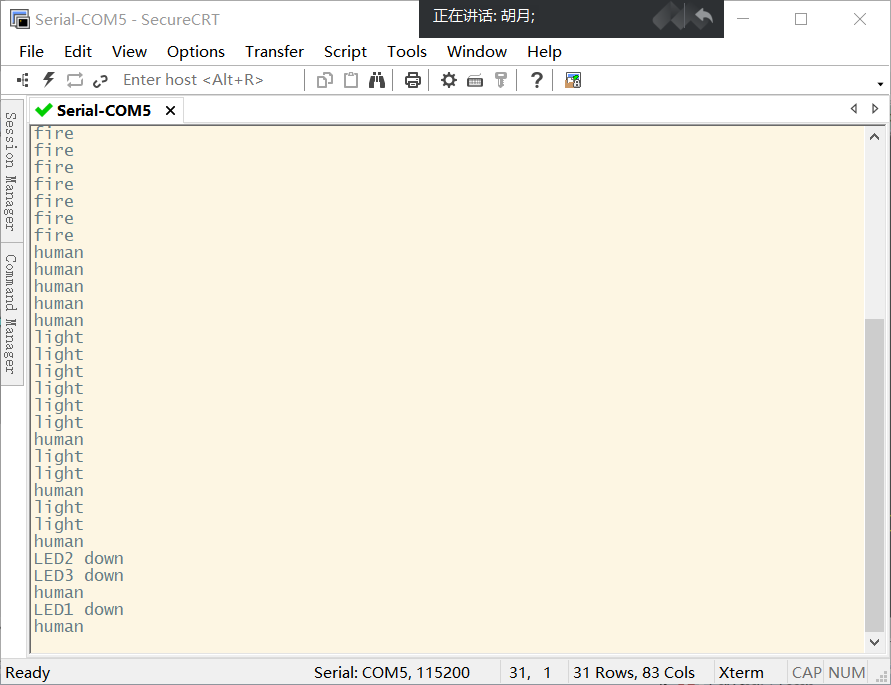
2月23号作业
题目:题目一:通过操作Cortex-A7核,串口输入相应的命令,控制LED灯进行工作--->上传CSDN 1.例如在串口输入led1on,开饭led1灯点亮 2.例如在串口输入led1off,开饭led1灯熄灭 3.例如在串口输入led2on,开饭led2灯点亮 4.例如在串口输…...
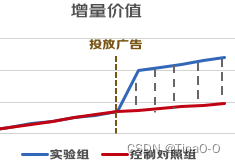
因果推断方法(一)合成控制
知道的跳过下面的简单介绍: 就是比如广告主投放了10w元,那么他的收益怎么算?哪些订单就是广告带来的,哪些是不放广告也会购买? 合成控制法是目前我实际应用发现最好用的。置信度高,且容易理解。 简单讲下思…...
)
数据结构第12周 :( 有向无环图的拓扑排序 + 拓扑排序和关键路径 + 确定比赛名次 + 割点 )
目录有向无环图的拓扑排序拓扑排序和关键路径确定比赛名次割点有向无环图的拓扑排序 【问题描述】 由某个集合上的一个偏序得到该集合上的一个全序,这个操作被称为拓扑排序。偏序和全序的定义分别如下:若集合X上的关系R是自反的、反对称的和传递的&…...
)
Linux安装docker(无网)
1. 下载Docker安装包 下载地址:https://download.docker.com/linux/static/stable/x86_64/ 如果服务器可以联网可以通过wget下载安装包 wget https://download.docker.com/linux/static/stable/x86_64/docker-18.06.3-ce.tgz2. 解压安装 tar -zxvf docker-18.06…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...

深入浅出Diffusion模型:从原理到实践的全方位教程
I. 引言:生成式AI的黎明 – Diffusion模型是什么? 近年来,生成式人工智能(Generative AI)领域取得了爆炸性的进展,模型能够根据简单的文本提示创作出逼真的图像、连贯的文本,乃至更多令人惊叹的…...

Sklearn 机器学习 缺失值处理 获取填充失值的统计值
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 使用 Scikit-learn 处理缺失值并提取填充统计信息的完整指南 在机器学习项目中,数据清…...