如何利用 Python 进行客户分群分析(附源码)
每个电子商务数据分析师必须掌握的一项数据聚类技能
如果你是一名在电子商务公司工作的数据分析师,从客户数据中挖掘潜在价值,来提高客户留存率很可能就是你的工作任务之一。
然而,客户数据是巨大的,每个客户的行为都不一样。2020年3月收购的客户A与2020年5月收购的客户B表现出不同的行为。因此,有必要将客户分为不同的群组,然后调查每个群组在一段时间内的行为。这就是所谓的同期群分析。
同期群分析是了解一个特殊客户群体在一段时间内的行为的数据分析技术。
在这篇文章中,不会详细介绍同期群分析的理论。这篇文章更多的是告诉你如何将客户分成不同的群组,并在一段时间内观察每个群组的留存率。
导入数据和python库
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('sales_2018-01-01_2019-12-31.csv')
df
技术交流
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
本文来自技术群粉丝分享整理,文章源码、数据、技术交流,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:pythoner666,备注:来自CSDN +备注来意
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
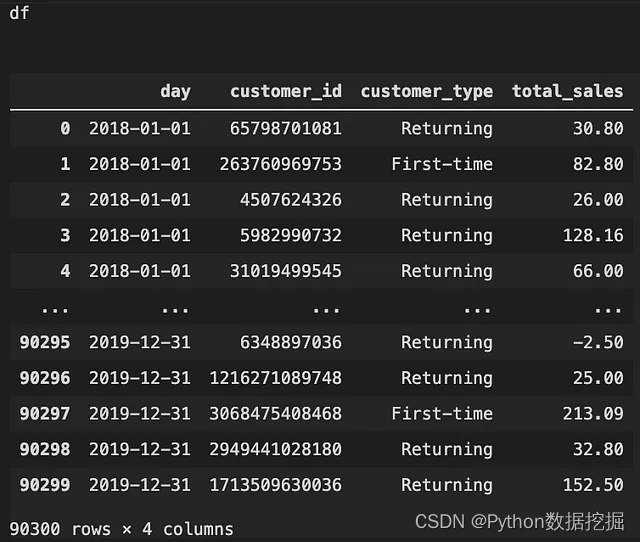
分离新老客户
first_time = df.loc[df['customer_type'] == 'First-time',]
final = df.loc[df['customer_id'].isin(first_time['customer_id'].values)]
在这里,不能简单地选择df.loc[df['customer_type']],因为在这个数据中,在customer_type列下,First_time指的是新客户,而Returning指的是老客户。因此,如果我在2019年12月31日第一次购买,数据会显示我在2019年12月31日是新客户,但在我第二次、第三次…时是返回客户。同期群分析着眼于新客户和他们的后续购买行为。因此,如果我们简单地使用df.loc[df['customer_type']=='First-time',],我们就会忽略新客户的后续购买,这不是分析同期群行为的正确方法。
因此,这里所需要做的是,首先创建一个所有第一次的客户列表,并将其存储为first_time。然后从原始客户数据框df中只选择那些ID在first_time客户组内的客户。通过这样做,我们可以确保我们获得的数据只有第一次的客户和他们后来的购买行为。
现在,我们删除customer_type列,因为它已经没有必要了。同时,将日期列转换成正确的日期时间格式
final = final.drop(columns = ['customer_type'])
final['day']= pd.to_datetime(final['day'], dayfirst=True)
按客户ID排序,然后是日期
final = final.drop(columns = ['customer_type'])
final['day']= pd.to_datetime(final['day'], dayfirst=True)

定义一些函数
def purchase_rate(customer_id): purchase_rate = [1] counter = 1 for i in range(1,len(customer_id)): if customer_id[i] != customer_id[i-1]: purchase_rate.append(1) counter = 1 else: counter += 1 purchase_rate.append(counter) return purchase_rate
def join_date(date, purchase_rate): join_date = list(range(len(date))) for i in range(len(purchase_rate)): if purchase_rate[i] == 1: join_date[i] = date[i] else: join_date[i] = join_date[i-1] return join_date
def age_by_month(purchase_rate, month, year, join_month, join_year): age_by_month = list(range(len(year))) for i in range(len(purchase_rate)): if purchase_rate[i] == 1: age_by_month[i] = 0 else: if year[i] == join_year[i]: age_by_month[i] = month[i] - join_month[i] else: age_by_month[i] = month[i] - join_month[i] + 12*(year[i]-join_year[i]) return age_by_month
-
purchase_rate函数将决定这是否是每个客户的第二次、第三次、第四次购买。 -
join_date函数允许确定客户加入的日期。 -
age_by_month函数提供了从客户当前购买到第一次购买的多少个月。
现在输入已经准备好了,接下来创建群组。
创建群组
final['month'] =pd.to_datetime(final['day']).dt.month
final['Purchase Rate'] = purchase_rate(final['customer_id'])
final['Join Date'] = join_date(final['day'], final['Purchase Rate'])
final['Join Date'] = pd.to_datetime(final['Join Date'], dayfirst=True)
final['cohort'] = pd.to_datetime(final['Join Date']).dt.strftime('%Y-%m')
final['year'] = pd.to_datetime(final['day']).dt.year
final['Join Date Month'] = pd.to_datetime(final['Join Date']).dt.month
final['Join Date Year'] = pd.to_datetime(final['Join Date']).dt.year

final['Age by month'] = age_by_month(final['Purchase Rate'], final['month'], final['year'], final['Join Date Month'], final['Join Date Year'])

cohorts = final.groupby(['cohort','Age by month']).nunique()
cohorts = cohorts.customer_id.to_frame().reset_index() # convert series to frame
cohorts = pd.pivot_table(cohorts, values = 'customer_id',index = 'cohort', columns= 'Age by month')
cohorts.replace(np.nan, '',regex=True)

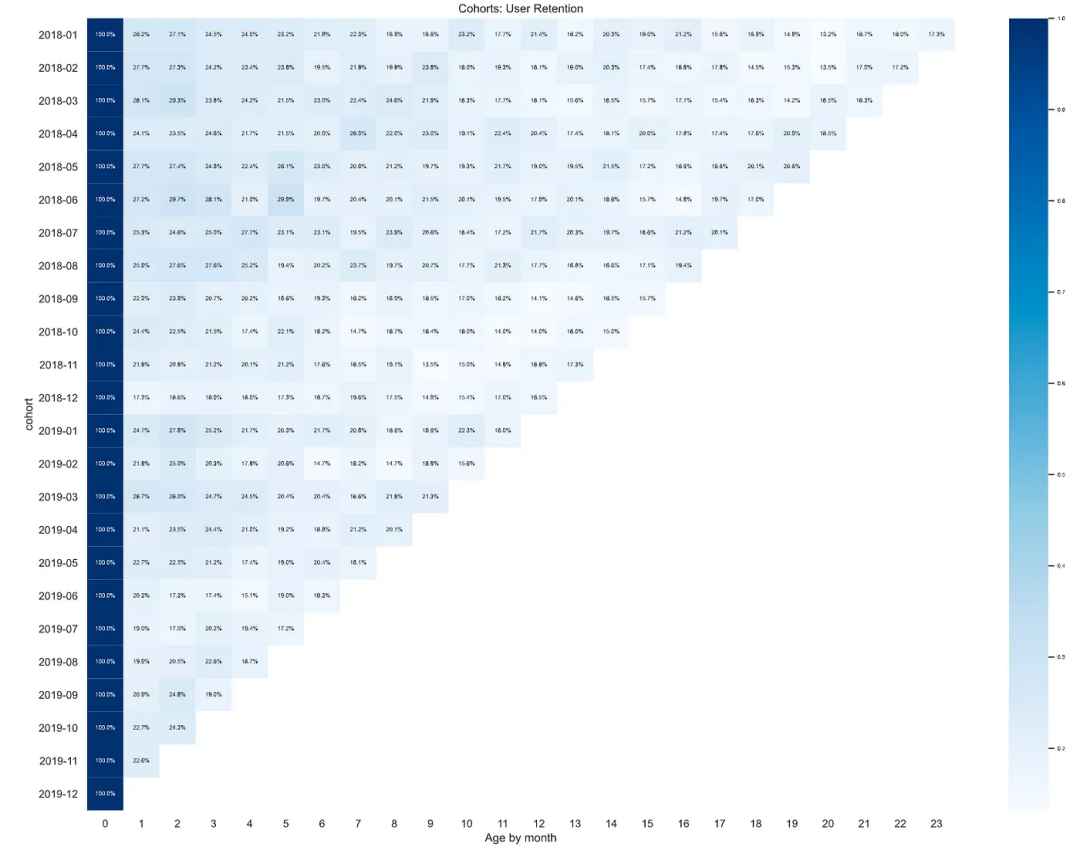
**如何解释这个表格:**以群组2018-01为例。在2018年1月,有462名新客户。在这462人中,121名客户在2018年2月回来购买,125名在2018年3月购买,以此类推。
转换为群组百分比
for i in range(len(cohorts)-1): cohorts[i+1] = cohorts[i+1]/cohorts[0]
cohorts[0] = cohorts[0]/cohorts[0]

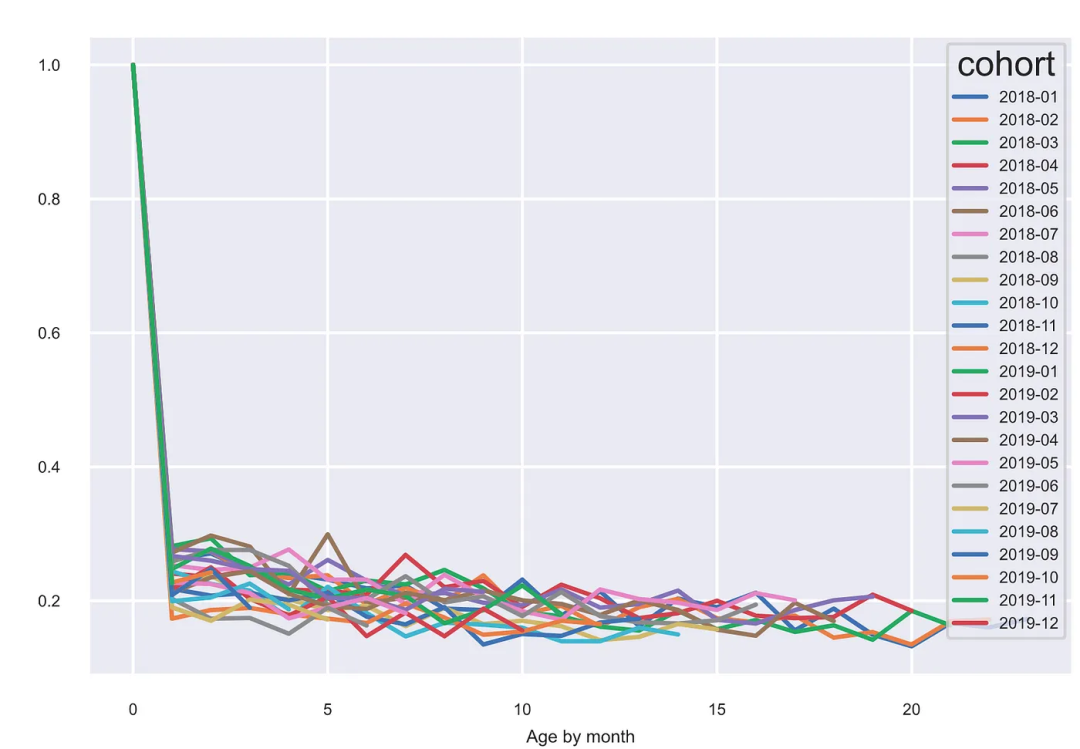
可视化
cohorts_t = cohorts.transpose()
cohorts_t[cohorts_t.columns].plot(figsize=(10,5))
sns.set(style='whitegrid')
plt.figure(figsize=(20, 15))
plt.title('Cohorts: User Retention')
sns.set(font_scale = 0.5) # font size
sns.heatmap(cohorts, mask=cohorts.isnull(),
cmap="Blues",
annot=True, fmt='.01%')
plt.show()
就这样吧。希望你们喜欢并从这篇文章中获得一些对你有用的东西。
相关文章:
如何利用 Python 进行客户分群分析(附源码)
每个电子商务数据分析师必须掌握的一项数据聚类技能 如果你是一名在电子商务公司工作的数据分析师,从客户数据中挖掘潜在价值,来提高客户留存率很可能就是你的工作任务之一。 然而,客户数据是巨大的,每个客户的行为都不一样。20…...

D1s RDC2022纪念版开发板开箱评测及点屏教程
作者new_bee 本文转自:https://bbs.aw-ol.com/topic/3005/ 目录 芯片介绍开发板介绍RT-Smart用户态系统编译使用感想引用 1. 芯片介绍 RISC-V架构由于其精简和开源的特性,得到业界的认可,近几年可谓相当热门。操作系统方面有RT-Thread&am…...

了解一下TCP/IP协议族
在《简单说说OSI网络七层模型》中讲到,目前实际使用的网络模型是 TCP/IP 模型,它对 OSI 模型进行了简化,只包含了四层,从上到下分别是应用层、传输层、网络层和链路层(网络接口层),每一层都包含…...

【第十九部分】存储过程与存储函数
【第十九部分】存储过程与存储函数 文章目录【第十九部分】存储过程与存储函数19. 存储过程与存储函数19.1 存储过程19.2 创建、调用存储过程19.2.1 不带参数19.2.2 IN 类型19.2.3 OUT类型19.2.4 IN和OUT类型同时使用19.2.5 INOUT类型19.3 存储函数19.4 创建、调用存储函数19.5…...

字节序
字节序 字节序:字节在内存中存储的顺序。 小端字节序:数据的高位字节存储在内存的高位地址,低位字节存储在内存的低位地址 大端字节序:数据的低位字节存储在内存的高位地址,高位字节存储在内存的低位地址 bit ( 比特…...
PDF文件怎么转图片格式?转换有技巧
PDF文件有时为了更美观或者更直观的展现出效果,我们会把它转成图片格式,这样不论是归档总结还是存储起来都会更为高效。有没有合适的转换方法呢?这就来给你们罗列几种我个人用过体验还算不错的方式,大家可以拿来参考一下哈。1.用电…...
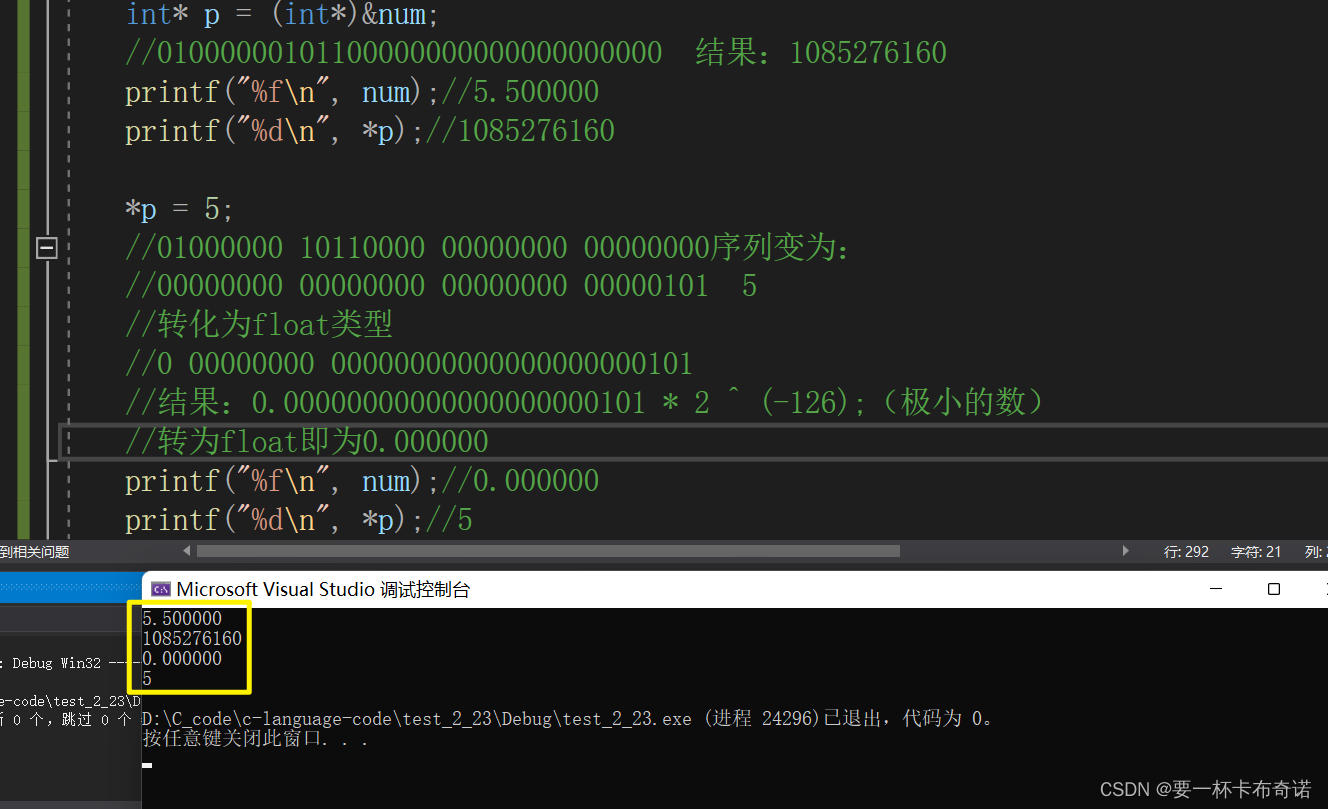
筑基七层 —— 数据在内存中的存储?拿来吧你
目录 零:移步 一.修炼必备 二.问题思考 三.整型在内存中的存储 三.大端字节序和小端字节序 四.浮点数在内存中的存储 零:移步 CSDN由于我的排版不怎么好看,我的有道云笔记相当的美观,请移步至有道云笔记 一.修炼必备 1.入门…...
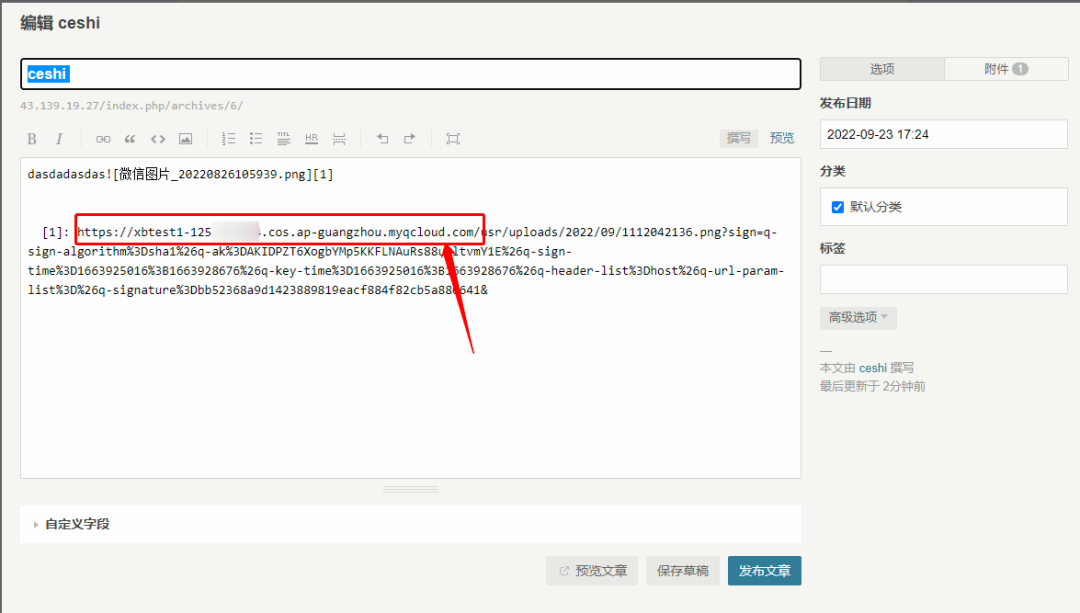
Typecho COS插件实现网站静态资源存储到COS,降低本地存储负载
Typecho 简介Typecho 是一个简单、强大的轻量级开源博客平台,用于建立个人独立博客。它具有高效的性能,支持多种文件格式,并具有对设备的响应式适配功能。Typecho 相对于其他 CMS 还有一些特殊优势:包括可扩展性、不同数据库之间的…...
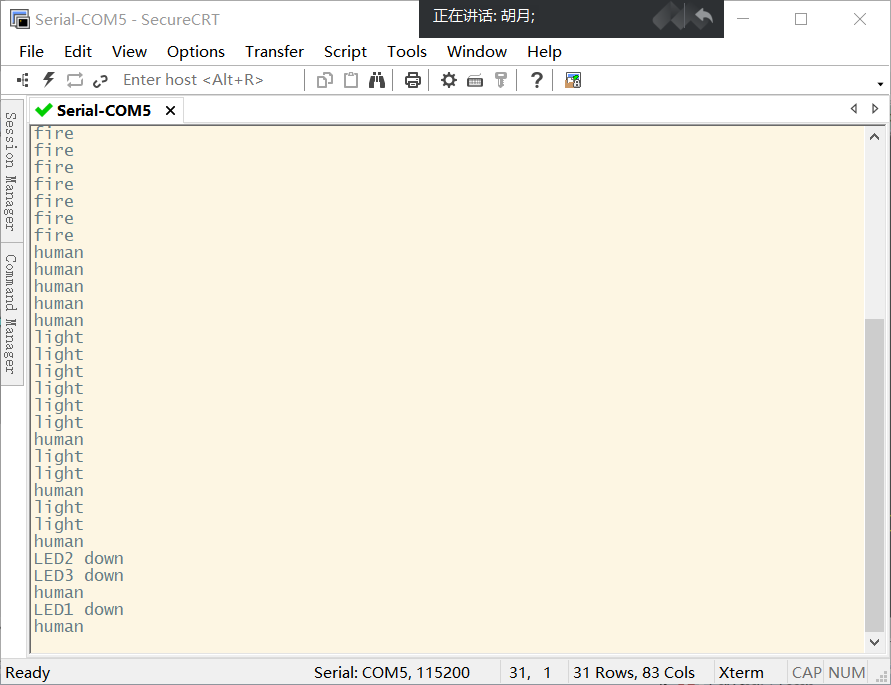
2月23号作业
题目:题目一:通过操作Cortex-A7核,串口输入相应的命令,控制LED灯进行工作--->上传CSDN 1.例如在串口输入led1on,开饭led1灯点亮 2.例如在串口输入led1off,开饭led1灯熄灭 3.例如在串口输入led2on,开饭led2灯点亮 4.例如在串口输…...
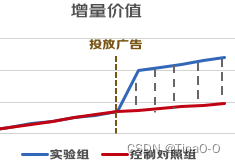
因果推断方法(一)合成控制
知道的跳过下面的简单介绍: 就是比如广告主投放了10w元,那么他的收益怎么算?哪些订单就是广告带来的,哪些是不放广告也会购买? 合成控制法是目前我实际应用发现最好用的。置信度高,且容易理解。 简单讲下思…...
)
数据结构第12周 :( 有向无环图的拓扑排序 + 拓扑排序和关键路径 + 确定比赛名次 + 割点 )
目录有向无环图的拓扑排序拓扑排序和关键路径确定比赛名次割点有向无环图的拓扑排序 【问题描述】 由某个集合上的一个偏序得到该集合上的一个全序,这个操作被称为拓扑排序。偏序和全序的定义分别如下:若集合X上的关系R是自反的、反对称的和传递的&…...
)
Linux安装docker(无网)
1. 下载Docker安装包 下载地址:https://download.docker.com/linux/static/stable/x86_64/ 如果服务器可以联网可以通过wget下载安装包 wget https://download.docker.com/linux/static/stable/x86_64/docker-18.06.3-ce.tgz2. 解压安装 tar -zxvf docker-18.06…...

解决JNI操作内核节点出现写操作失败的问题
Android 9.0下,因为采取了SEAndroid/SElinux的安全机制,即使拥有root权限,或者对某内核节点设置为777的权限,仍然无法在JNI层访问。 本文将以用户自定义的内核节点/dev/wf_bt为例,手把手教会读者如何在JNI层获得对该节…...

纵然是在产业互联网的时代业已来临的大背景下,人们对于它的认识依然是短浅的
纵然是在产业互联网的时代业已来临的大背景下,人们对于它的认识依然是短浅的。这样一种认识的最为直接的结果,便是我们看到了各式各样的产业互联网平台的出现。如果一定要找到这些互联网平台的特点的话,以产业端为出发点,无疑是它…...

干翻 nio ,王炸 io_uring 来了 !!(图解+史上最全)
大趋势:全链路异步化,性能提升10倍 随着业务的发展,微服务应用的流量越来越大,使用到的资源也越来越多。 在微服务架构下,大量的应用都是 SpringCloud 分布式架构,这种架构总体上是全链路同步模式。 全链…...
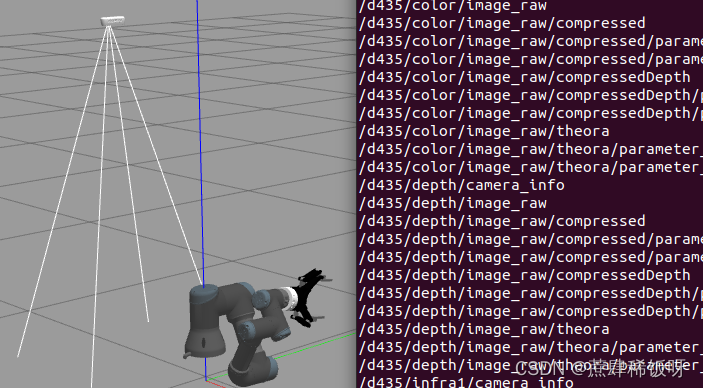
ur3+robotiq ft sensor+robotiq 2f 140+realsense d435i配置rviz,gazebo仿真环境
ur3robotiq ft sensorrobotiq 2f 140realsense d435i配置rviz,gazebo仿真环境 搭建环境: ubuntu: 20.04 ros: Nonetic sensor: robotiq_ft300 gripper: robotiq_2f_140_gripper UR: UR3 reasense: D435i 通过下面几篇博客配置好了ur3、力传…...

ASP.NET Core MVC 项目 AOP之Authorization
目录 一:说明 二:传统鉴权授权的基本配置 三 :角色配置说明 四:策略鉴权授权 五:策略鉴权授权Requirement扩展 总结 一:说明 鉴权:是指验证你是否登录,你登录后的身份是什么。…...
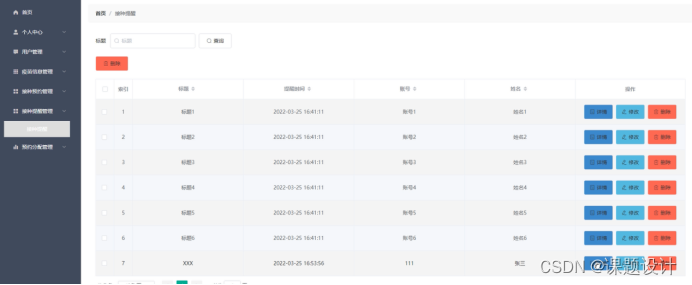
智能新冠疫苗接种助手管理系统
项目背景介绍 近几年来,网络事业,特别是Internet发展速度之快是任何人都始料不及的。目前,由于Internet表现出来的便捷,快速等诸多优势,已经使它成为社会各行各业,甚至是平民大众工作,生活不可缺少的一个重…...

Python+Selenium4元素交互1_web自动化(5)
目录 0. 上节回顾 1. 内置的等待条件 2. 元素属性 1. Python对象属性 2. HTML元素属性 3. 元素的交互 1. 输入框 2. 按钮 3. 单选框和复选框 0. 上节回顾 DEBUG的方式:JS断点 Python断点编程语言提供的等待方式:sleepselenium提供的等待方式&…...

2023双非计算机硕士应战秋招算法岗之深度学习基础知识
word版资料自取链接: 链接:https://pan.baidu.com/s/1H5ZMcUq-V7fxFxb5ObiktQ 提取码:kadm 卷积层 全连接神经网络需要非常多的计算资源才能支撑它来做反向传播和前向传播,所以说全连接神经网络可以存储非常多的参数,…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...
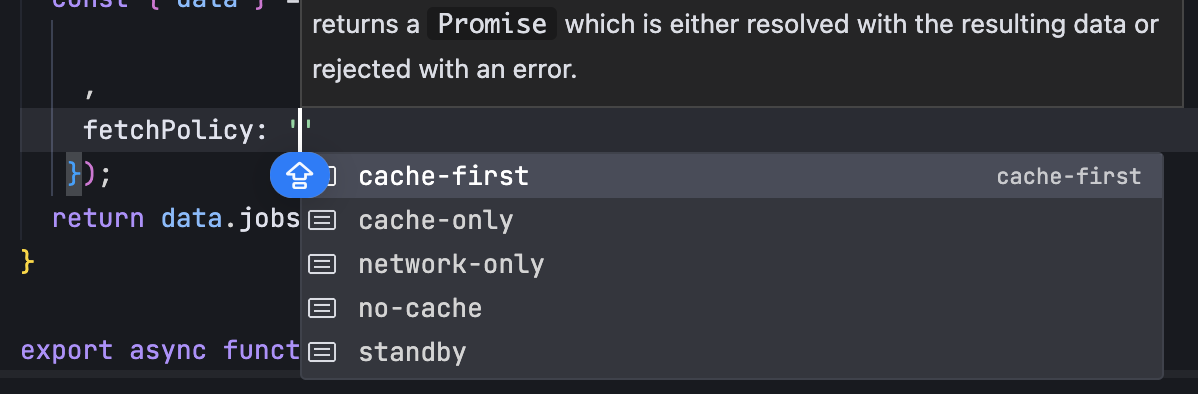
GraphQL 实战篇:Apollo Client 配置与缓存
GraphQL 实战篇:Apollo Client 配置与缓存 上一篇:GraphQL 入门篇:基础查询语法 依旧和上一篇的笔记一样,主实操,没啥过多的细节讲解,代码具体在: https://github.com/GoldenaArcher/graphql…...

基于江科大stm32屏幕驱动,实现OLED多级菜单(动画效果),结构体链表实现(独创源码)
引言 在嵌入式系统中,用户界面的设计往往直接影响到用户体验。本文将以STM32微控制器和OLED显示屏为例,介绍如何实现一个多级菜单系统。该系统支持用户通过按键导航菜单,执行相应操作,并提供平滑的滚动动画效果。 本文设计了一个…...