MySQL 通过存储过程高效插入100w条数据
目录
- 一、前言
- 二、创建表
- 三、编写存储过程插入数据
- 四、高效插入数据方案
- 4.1、插入数据时删除表中全部索引
- 4.2、存储过程中使用统一事务插入(性能显著提升)
- 4.3、调整MySQL系统配置(性能显著提升,适合存储过程没有使用统一事务)
- 查看MySQL这两个配置默认值(一般默认都是1)
- 修改MySQL配置文件
- 插入10w数据测试
- 五、总结
一、前言
最近在做SQL索引优化的时候经常需要批量插入一些数据,采用存储过程来进行批量插入是一个很好的选择,但是在插入100w数据时我本地耗时需要24分钟有点顶不住,本文会讲解如何通过存储过程批量插入数据,并且提供两个提升插入速度的方法。
二、创建表
DROP TABLE IF EXISTS `order_info`;
CREATE TABLE `order_info` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '订单ID',`order_no` varchar(100) NOT NULL COMMENT '订单编号',`customer_id` bigint(20) NOT NULL COMMENT '客户编号',`goods_id` bigint(20) NOT NULL COMMENT '商品ID',`goods_title` varchar(100) COLLATE utf8mb4_0900_as_cs DEFAULT NULL COMMENT '商品标题',`order_status` tinyint(4) NOT NULL DEFAULT '1' COMMENT '订单状态 1:待支付 2:已支付 3:已发货 4、已收货',`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_as_cs COMMENT='订单信息表';
三、编写存储过程插入数据
在测试的时候插入数据量可以调小一点,一次别插入太多,如果存储过程不加事务插入10w条数据我本地耗时143秒,插入100w数据我本地耗时24分钟太慢了,可以先看下面高效插入数据方案。
## 创建一个插入数据的存储过程
DROP PROCEDURE IF EXISTS insert_procedure;
delimiter;;
CREATE PROCEDURE insert_procedure ()
BEGIN# 定义循环值DECLARE i INT DEFAULT 1;# 开启事务START TRANSACTION;# 开始循环插入WHILE ( i <= 1000000 ) DOINSERT INTO `order_info`(`order_no`,`customer_id`, `goods_id`, `goods_title`, `order_status`, `create_time`) VALUES (CONCAT('ON00000',i), CEIL(RAND() * 100), CEIL(RAND() * 100), CONCAT('笔记本电脑',i), MOD(i, 4)+1, NOW());SET i = i + 1;END WHILE;
END;;
delimiter;# 调用存储过程插入数据
CALL insert_procedure ();
四、高效插入数据方案
MySQL版本:8.0.18
如果MySQL不做任何配置,我本地固态盘使用MySQL8.0插入10w条数据耗时142s,插入数据量越大可能等比耗时更长,一般表中都会创建一些索引,在插入数据的时候也会变更索引,尤其是唯一索引会增长插入数据的时间,要想加快插入速度有多种方法,硬件上的优化就不说了,这里只说三个方法够我们做SQL索引优化测试即可。
4.1、插入数据时删除表中全部索引
将表中索引全部删除,包括主键索引,尤其是自增主键索引还有唯一索引,自己生成ID保证自增不重复即可,这里以10w条数据做测试对比,插入100w数据耗时太长。
我本地10w条数据插入有自增主键索引插入耗时142s,删除主键索引改用自己生成ID值插入耗时139s,这个数据量还比较小,有兴趣可以加大数据量测试,数据量越大差值越明显。
只需要把把存储过程中的SQL改一下把让 ID 使用 i 的值即可
INSERT INTO `order_info`(id,`order_no`,`customer_id`, `goods_id`, `goods_title`, `order_status`, `create_time`) VALUES (i, CONCAT('ON00000',i), CEIL(RAND() * 100), CEIL(RAND() * 100), CONCAT('笔记本电脑',i), MOD(i, 4)+1, NOW());
4.2、存储过程中使用统一事务插入(性能显著提升)
在存储过程中添加事务,存储过程中的每次新增语句都会开启一个自己的事务,控制所有新增都在一个事务中,10w条数据插入耗时从142s提升到20s,速度大大提升,但是有个问题这20s其它插入操作需要等待,线上业务需要考量一下,本地SQL索引优化测试倒是一个很不错的选择。
- 给存储过程添加上统一事务
## 创建一个插入数据的存储过程
DROP PROCEDURE IF EXISTS insert_procedure;
delimiter;;
CREATE PROCEDURE insert_procedure ()
BEGIN# 定义循环值DECLARE i INT DEFAULT 1;#定义一个错误的变量,类型是整形,默认是0DECLARE t_error INTEGER DEFAULT 0;#捕获到sql的错误,就设置t_error为1DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SET t_error=1;# 开启事务START TRANSACTION;# 开始循环插入WHILE ( i <= 1000000 ) DOINSERT INTO `order_info`(`order_no`,`customer_id`, `goods_id`, `goods_title`, `order_status`, `create_time`) VALUES (CONCAT('ON00000',i), CEIL(RAND() * 100), CEIL(RAND() * 100), CONCAT('笔记本电脑',i), MOD(i, 4)+1, NOW());SET i = i + 1;END WHILE;#如果捕获到错误IF t_error=1 THEN#回滚ROLLBACK;ELSE#提交COMMIT;END IF;
END;;
delimiter;# 调用存储过程插入数据
CALL insert_procedure ();
4.3、调整MySQL系统配置(性能显著提升,适合存储过程没有使用统一事务)
这种方案是适合存储过程没有使用统一事务插入,每一次插入都需要开启事务然后提交,对存储过程中使用了统一事务插入提升不大。
MySQL有两个配置是控制日志文件写入的,在计算器中最耗时的操作就是IO,MySQL默认是会同步写入redo日志和binlog日志的,我们插入100w数据就需要同步写入100w次redo日志和100w次binlog日志,这是非常耗时的,如果能改成异步批量写入则可以大大加快新增数据的速度,但是可能会导致数据库宕机时数据丢失问题,这里不做详细说明。
- innodb_flush_log_at_trx_commit (控制redo日志写入模式)
- 等于0: log buffer每秒就会被刷写日志文件到磁盘,提交事务的时候不做任何操作(执行是由mysql的master thread线程来执行的。
- 等于1: 每次提交事务的时候,都会将log buffer刷写到日志 (默认)
- 等于2: 表示在每次事务提交的时候会把log buffer刷到文件系统中去,但并不会立即刷写到磁盘。如果只是MySQL数据库挂掉了,由于文件系统没有问题,那么对应的事务数据并没有丢失。只有在数据库所在的主机操作系统损坏或者突然掉电的情况下,数据库的事务数据可能丢失1秒之类的事务数据。这样的好处,减少了事务数据丢失的概率,而对底层硬件的IO要求也没有那么高(log buffer写到文件系统中,一般只是从log buffer的内存转移的文件系统的内存缓存中,对底层IO没有压力)。
- sync_binlog (控制binlog日志写入模式)
- 在提交n次事务后,进行binlog的落盘,0为不进行强行的刷新操作,而是由文件系统控制刷新日志文件,如果是在线交易和账有关的数据建议设置成1,如果是其他数据可以保持为0即可
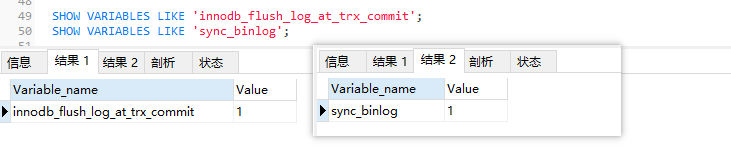
查看MySQL这两个配置默认值(一般默认都是1)
SHOW VARIABLES LIKE 'innodb_flush_log_at_trx_commit';
SHOW VARIABLES LIKE 'sync_binlog';
修改MySQL配置文件
我的MySQL是Linux版的配置文件在/etc/mysql/my.cnf,window 上的 MySQL 配置文件默认是在 C:\Program Files\MySQL\MySQL Server 8.0\my-default.ini。
# 打开/etc/mysql/my.cnf
vi /etc/mysql/my.cnf
- 在配置文件中的
[mysqld]下添加如下配置
## 2表示在每次事务提交的时候会把log buffer刷到文件系统中去,但并不会立即刷写到磁盘。
innodb_flush_log_at_trx_commit = 2
## 0为不进行强行的刷新操作,而是由文件系统控制刷新日志文件
sync_binlog = 0
- 重启MySQL
service mysqld restart
# 或
service mysql restart
插入10w数据测试
-
修改前
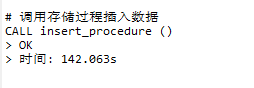
-
修改后

插入速度还是比使用统一事务插入差很多。
五、总结
我的需求是为了做SQL索引优化测试需要批量插入一些数据,这里最适合我的是4.2中添加统一事务来插入方案。
- 4.2方案存储过程中使用统一事务,插入100w数据耗时217秒差不多3.6分钟,没有调整前耗时24分钟插入速度提升6.6倍多。
- 4.3方案调整MySQL配置,插入100w数据耗时415秒差不多7分钟,没有调整前耗时24分钟插入速度提升3.4倍多。
要想高效插入数据还有很多种方法,我这里只是为了做SQL索引优化测试使用,这个插入耗时我还可以接受,有其它好的方法可以一起交流。
相关文章:
MySQL 通过存储过程高效插入100w条数据
目录 一、前言二、创建表三、编写存储过程插入数据四、高效插入数据方案4.1、插入数据时删除表中全部索引4.2、存储过程中使用统一事务插入(性能显著提升)4.3、调整MySQL系统配置(性能显著提升,适合存储过程没有使用统一事务&…...

国庆10.1
用select实现服务器并发 ser #include <myhead.h> #define ERR_MSG(msg) do{\fprintf(stderr, "__%d__", __LINE__);\perror(msg);\ }while(0)#define PORT 8888 //端口号,范围1024~49151 #define IP "192.168.1.205" //本机…...

[C++_containers]10分钟让你掌握vector
前言 在一个容器的创建或是使用之前,我们应该先明白这个容器的一些特征。 我们可以通过文档来来了解,当然我也会将重要的部分写在下面。 1. vector 是表示可变大小数组的序列容器。 2. 就像数组一样, vector 也采用的连续存储空间来存储元…...

前端与后端:程序中两个不同的领域
前端和后端是构成一个完整的计算机应用系统的两个主要部分。它们分别负责不同的功能和任务,有以下几个方面的区别: 功能:前端主要负责用户界面的呈现和交互,包括网页的设计、布局、样式、动画效果和用户输入等。后端则处理网站或应…...

vue3 +elementplus | vue2+elementui 动态地通过验证规则子新增或删除单个表单字段
效果图 点击 ‘’ 新增一行,点击‘-’ 删除一行 vue3elementplus写法 template <el-dialog v-model"dialogFormVisible" :title"title"><el-form ref"ruleFormRef" :model"form" :inline"true" lab…...

STM32之DMA
简介 • DMA ( Direct Memory Access )直接存储器存取 (可以直接访问STM32内部存储器,如SRAM、程序存储器Flash和寄存器等) •DMA可以提供外设和存储器或者存储器和存储器之间的高速数据传输,无须CPU干预&a…...
解决前端二进制流下载的文件(例如:excel)打不开的问题
1. 现在后端请求数据后,返回了一个二进制的数据,我们要把它下载下来。 这是响应的数据: 2. 这是调用接口的地方: uploadOk(){if(this.files.length 0){return this.$Message.warning("请选择上传文件!ÿ…...
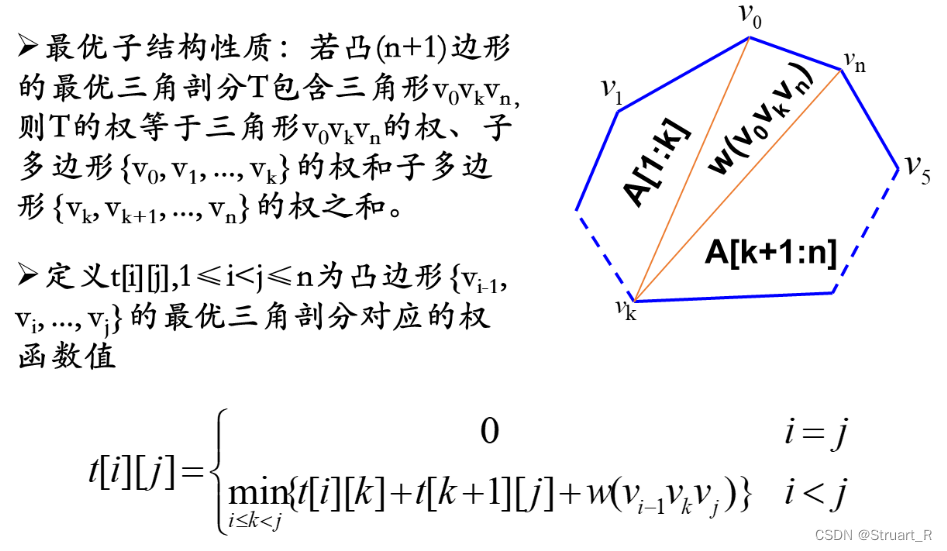
动态规划算法(1)--矩阵连乘和凸多边形剖分
目录 一、动态数组 1、创建动态数组 2、添加元素 3、删除修改元素 4、访问元素 5、返回数组长度 6、for each遍历数组 二、输入多个数字 1、正则表达式 2、has.next()方法 三、矩阵连乘 1、什么是矩阵连乘? 2、动态规划思路 3、手推m和s矩阵 4、完…...

通过Nginx重新认识HTTP错误码
文章目录 概要一、HTTP错误码1.1、1xx1.2、2xx1.3、3xx1.4、4xx1.5、5xx 二、Nginx对常见错误处理三、参考资料 概要 在web开发过程中,通过HTTP错误码快速定位问题是一个非常重要的技能,同时Nginx是非常常用的一个实现HTTP协议的服务,因此本…...

某房产网站登录RSA加密分析
文章目录 1. 写在前面2. 抓包分析3. 扣加密代码4. 还原加密 1. 写在前面 今天是国庆节,首先祝福看到这篇文章的每一个人节日快乐!假期会老的这些天一直在忙事情跟日常带娃,抽不出一点时间来写东西。夜深了、娃也睡了。最近湖南开始降温了&…...
深度学习:基于长短时记忆网络LSTM实现情感分析
目录 1 LSTM网络介绍 1.1 LSTM概述 1.2 LSTM网络结构 1.3 LSTM门机制 1.4 双向LSTM 2 Pytorch LSTM输入输出 2.1 LSTM参数 2.2 LSTM输入 2.3 LSTM输出 2.4 隐藏层状态初始化 3 基于LSTM实现情感分析 3.1 情感分析介绍 3.2 数据集介绍 3.3 基于pytorch的代码实现 3…...
selenium使用已经获取的cookies登录网站报错unable to set cookie的处理方式
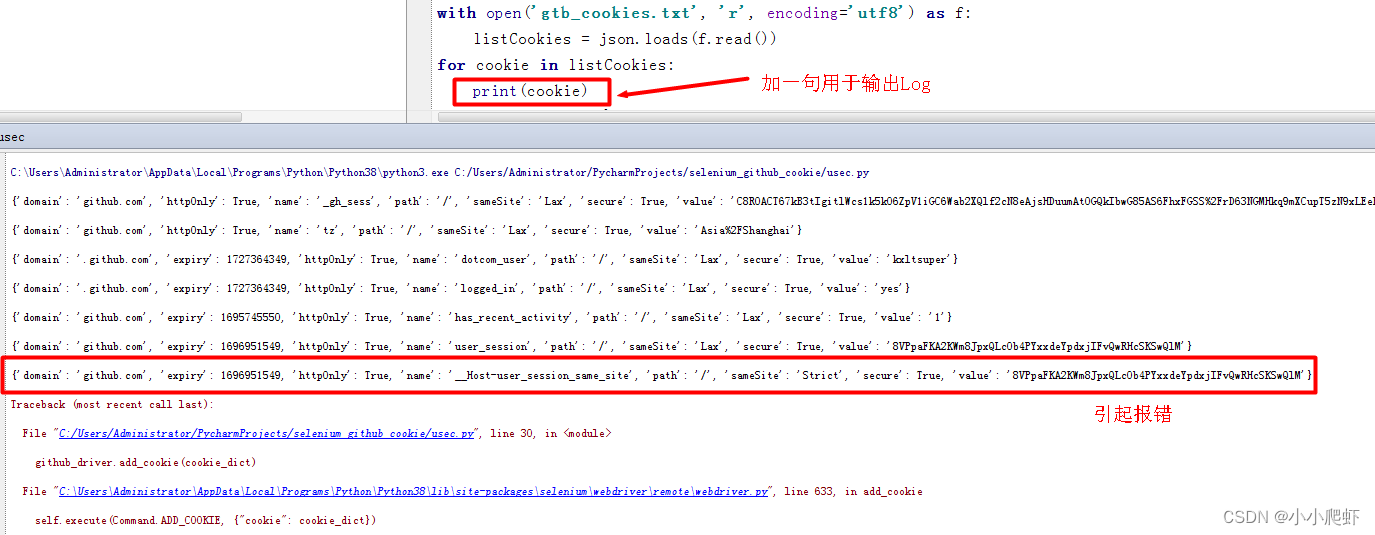
用selenium半手动登录github获取其登录cookies后,保存到一个文件gtb_cookies.txt中。 然后用selenium使用这个cookies文件,免登录上github。但是报错如下:selenium.common.exceptions.UnableToSetCookieException: Message: unable to set co…...
初阶数据结构(四)带头双向链表
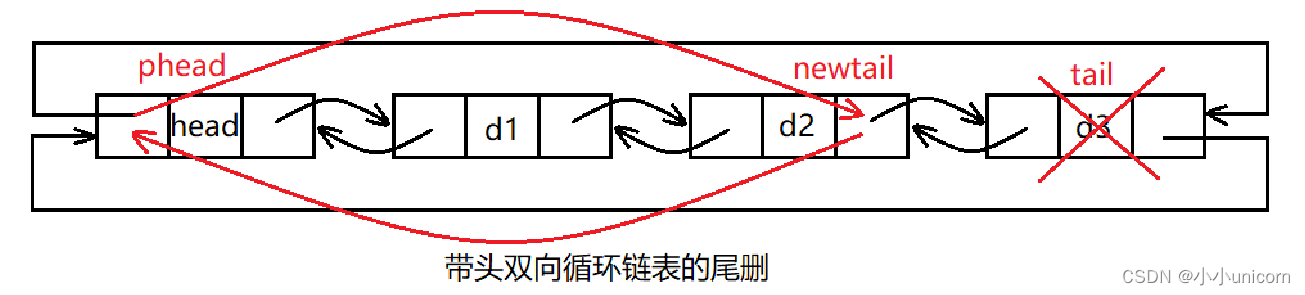
💓博主csdn个人主页:小小unicorn ⏩专栏分类:数据结构 🚚代码仓库:小小unicorn的代码仓库🚚 🌹🌹🌹关注我带你学习编程知识 带头双向链表 链表的相关介绍初始化链表销毁链…...
2022年9月及10月
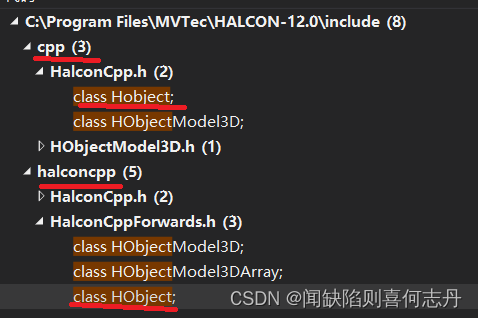
9月 1.Halcon12的HObject和Hobject halcon12 可以用HObject,也可以用Hobject,用法都一样 包括HalconCpp.h 如果附加目录中: C:\Program Files\MVTec\HALCON-12.0\include\halconcpp\ 在前面,则用 HalconCpp::HObject 如果附加目录…...

Vmware安装
title: “Vmware安装” createTime: 2021-11-22T09:53:2908:00 updateTime: 2021-11-22T09:53:2908:00 draft: false author: “name” tags: [“VMware”,“安装”,“linux”] categories: [“install”] description: “测试的” linux安装VMware Workstation16 1.安装包 …...

RSA算法
算法简介 RSA是一种非对称加密方式。发送者把明文通过公钥加密后发送出去,接受者把密文通过私钥解密得到明文。 算法过程 生成公钥和私钥 选取两个质数p和q,np*q。n的长度就是密钥长度。φ(n)(p-1)*(q-1)φ(n)为n的欧拉函数。找到1-φ(n)间与φ(n)互质的…...

计算机竞赛 深度学习手势识别 - yolo python opencv cnn 机器视觉
文章目录 0 前言1 课题背景2 卷积神经网络2.1卷积层2.2 池化层2.3 激活函数2.4 全连接层2.5 使用tensorflow中keras模块实现卷积神经网络 3 YOLOV53.1 网络架构图3.2 输入端3.3 基准网络3.4 Neck网络3.5 Head输出层 4 数据集准备4.1 数据标注简介4.2 数据保存 5 模型训练5.1 修…...

Spring的Ordered
Ordered Java中的Ordered接口是Spring框架中的一个接口,用于表示对象的顺序。它定义了一个方法getOrder(),用于获取对象的顺序值,值越小的对象越先被处理。 Ordered接口是Spring框架中的一个接口,用于定义组件的加载顺序。当一个…...

前端两年半,CSDN创作一周年
文章目录 一、机缘巧合1.1、起因1.2、万事开头难1.3、 何以坚持? 二、收获三、日常四、憧憬 五、总结 一、机缘巧合 1.1、起因 最开始接触CSDN,还是因为同专业的同学,将计算机实验课的实验题,记录总结并发在了专业群里。后来正式…...

定时任务管理平台青龙 QingLong
一、关于 QingLong 1.1 QingLong 介绍 青龙面板是支持 Python3、JavaScript、Shell、Typescript 多语言的定时任务管理平台,支持在线管理脚本和日志等。其功能丰富,能够满足大部分需求场景,值得一试。 主要功能 支持多种脚本语言…...

5分钟搞定串口设备联网:用USR-K5模块搭建TCP通讯的保姆级教程
5分钟搞定串口设备联网:用USR-K5模块搭建TCP通讯的保姆级教程 当你需要将老旧的串口设备接入现代网络时,USR-K5模块就像一位精通双语的翻译官,能在RS-232和TCP/IP协议之间架起无缝桥梁。作为一款即插即用的串口转以太网模块,它特别…...

Pi0 VLA模型实战落地:某新能源车企电池模组装配线VLA质检系统上线
Pi0 VLA模型实战落地:某新能源车企电池模组装配线VLA质检系统上线 1. 引言:当机器人“看懂”指令,质检效率迎来质变 在新能源电池的生产线上,有一个环节至关重要却又异常繁琐——电池模组的装配质检。成百上千个电芯、连接片、绝…...

PCB设计全流程检查清单:从输入验证到文件归档
1. PCB设计全流程检查清单:从输入验证到文件归档在嵌入式硬件开发实践中,PCB设计质量直接决定产品可靠性、可制造性与电磁兼容性。一个成熟的设计流程绝非仅依赖EDA工具自动布线,而是一套覆盖全生命周期的系统性工程管控体系。本文基于工业级…...

ARM寄存器体系深度解析:从Cortex-M到AArch64的演进与实践
1. ARM架构寄存器体系深度解析ARM处理器的寄存器设计是其指令集架构(ISA)的核心组成部分,直接决定了程序执行效率、异常处理机制、系统安全模型以及软件可移植性。不同于x86等复杂指令集架构中寄存器数量有限且功能高度专用的特点,…...

2024移动端UI设计趋势:除了深色模式,这些新规范你必须知道
2024移动端UI设计趋势:超越深色模式的五大革新方向 当设计师们还在为深色模式的适配问题焦头烂额时,移动界面设计的前沿已经悄然进化。Material Design 3和iOS 17带来的不仅是视觉语言的更新,更是一场关于人机交互本质的重新思考。从折叠屏的…...

从实验室到真实场景:基于eNSP的IPv6-over-IPv4隧道在企业网络过渡中的实战模拟
企业级IPv6-over-IPv4隧道实战:基于eNSP的跨地域网络互联方案 当企业开始内部部署IPv6时,往往会遇到一个典型困境:分支机构之间的互联网服务提供商(ISP)仍仅支持IPv4。这种"内IPv6、外IPv4"的混合环境,使得跨地域的IPv…...

Neo4j Desktop版实战:从下载加速到登录认证,一站式攻克三大典型障碍
1. 下载加速:突破Neo4j Desktop龟速下载难题 第一次打开Neo4j官网准备下载Desktop版时,那个进度条简直让人怀疑人生。我清楚地记得当时盯着浏览器右下角显示的"剩余时间:2小时42分钟"时,差点把咖啡喷在键盘上。对于国内…...

深入解析UVM寄存器模型:mirror、desired与actual value的协同工作机制
1. UVM寄存器模型的三重镜像机制 在芯片验证领域,UVM寄存器模型就像一位尽职的仓库管理员,时刻记录着DUT中寄存器的状态。但这个管理员有点特殊——它同时维护着三本不同的账本:mirror value(镜像值)、desired value&a…...

Ubuntu 22.04自动登录设置指南:告别每次开机输密码的烦恼
Ubuntu 22.04自动登录完全指南:安全与便捷的平衡艺术 每次开机都要输入密码,对于个人开发者或家庭用户来说,确实是个不小的麻烦。特别是在家里使用的电脑,安全性要求相对较低的情况下,自动登录功能可以大幅提升使用体验…...

DAMO-YOLO模型量化部署:TensorRT加速实战
DAMO-YOLO模型量化部署:TensorRT加速实战 探索如何通过TensorRT量化加速技术,让DAMO-YOLO目标检测模型在保持精度的同时获得显著的速度提升。 1. 开篇:为什么需要量化加速? 在实际的目标检测应用场景中,我们经常遇到这…...