Python实用技术二:数据分析和可视化(2)
目录
一,多维数组库numpy
1,操作函数:
2,numpy数组元素增删
1)添加数组元素
2)numpy删除数组元素
3)在numpy数组中查找元素
4)numpy数组的数学运算
3,numpy数组的切片
二,数据分析库pandas
1,DataFrame的构造和访问
Series是一维表格,每个元素带标签且有下标,兼具列表和字典的访问形式
DataFrame是带行列标签的二维表格,每一列都是一个Series
2,DataFrame的切片和统计
3,DataFrame的分析统计
4,DataFrame的修改增删
5,读写excel和csv文档
1)用pandas读excel文档
2)用pandas读写csv文件
三,用matplotlib进行数据展示
1,绘制直方图
2,绘制堆叠直方图
3,绘制对比直方图(有多组数据)
4,绘制散点,折线图
5,绘制饼图
6,绘制热力图
7,绘制雷达图
8,绘制多层雷达图
9,多子图绘制
一,多维数组库numpy
➢多维数组库,创建多维数组很方便,可以替代多维列表
➢速度比多维列表快
➢支持向量和矩阵的各种数学运算
➢所有元素类型必须相同
1,操作函数:

import numpy as np #以后numpy简写为np
print (np.array([1,2,3]) ) #>>[1 2 3]
print (np. arange(1,9,2) ) #>>[13 5 7]
print (np. linspace(1,10,4)) #>>[ 1. 4. 7. 10. ]
print (np . random. randint (10,20, [2,3]) )
#>>[[12 19 12]
#>> [19 13 10 ]]print (np . random. randint (10,20,5) ) #>> [12 19 19 10 13]
a = np. zeros (3)
print (a)
#>>[ 0. 0. 0.]print(list(a) )
#>>[0.0,0.0,0.0]a = np. zeros((2 ,3) ,dtype=int) #创建- t个2行3列的元素都是整数0的数组
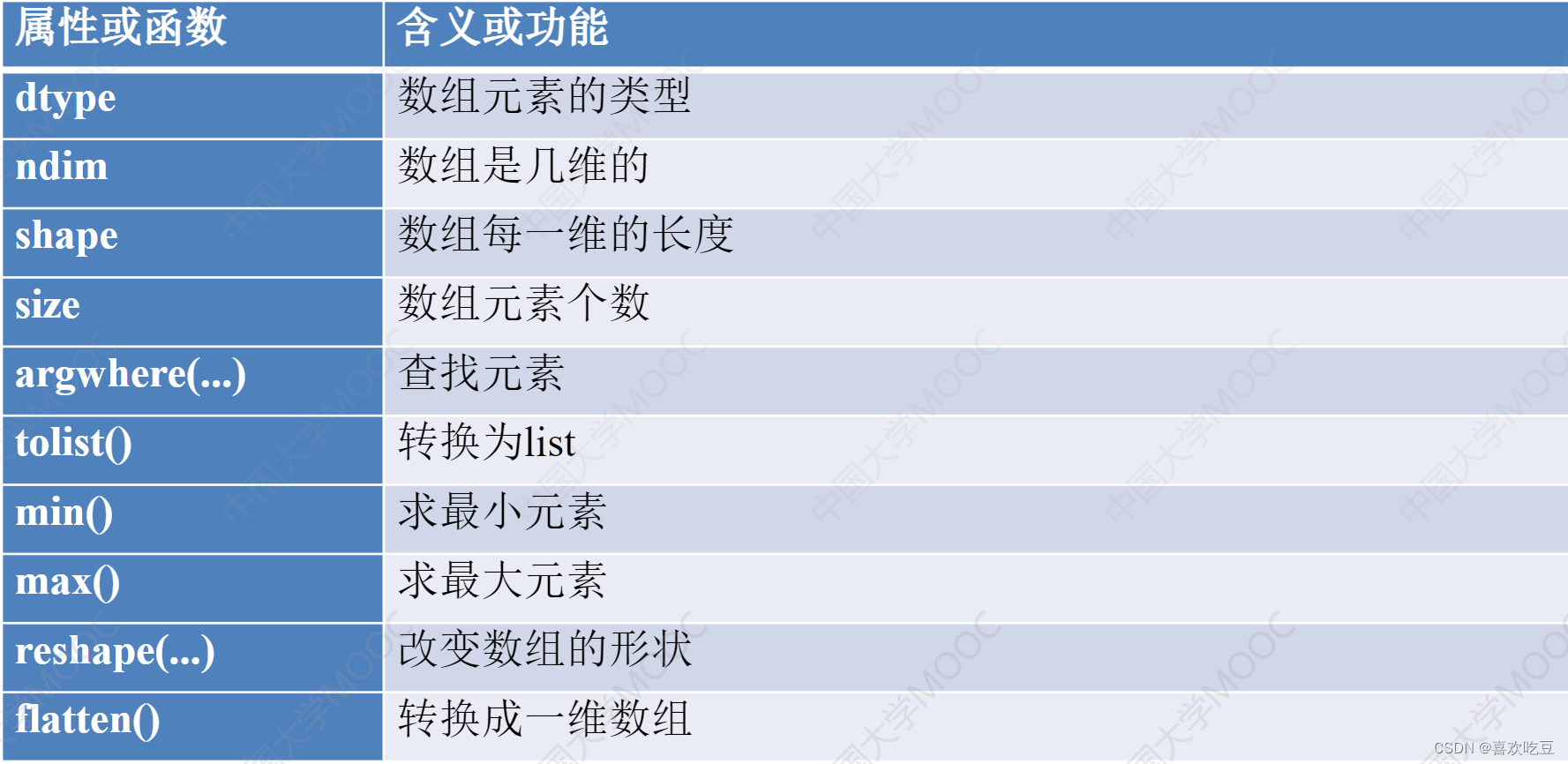
import numpy as np
b = np.array([i for i in range (12) ])
#b是[ 0 1 5 6 7 8 9 10 11]
a = b.reshape( (3,4) )
#转换成3行4列的数组,b不变print (len(a) )
#>>3 a有3行print(a. size )
#>>12 a的元素个数是12
print (a. ndim)
#>>2 a是2维的print (a. shape)
#>>(3, 4) a是3行4列print (a. dtype)
#>>int32 a的元素类型 是32位的整数
L = a.tolist ()
#转换成列表,a不变print (L)
#>>[[0,1,2,3],[4,5,6,7],[8,9,10,11]]
b = a. flatten ()
#转换成一维数组print (b)
#>>[0 1 2 3 5 6 7 8 9 10 11]
2,numpy数组元素增删
numpy数组一旦生成,元素就不能增删。上面 函数返回一个新的数组。
1)添加数组元素
import numpy as np
a = np.array((1,2,3) )
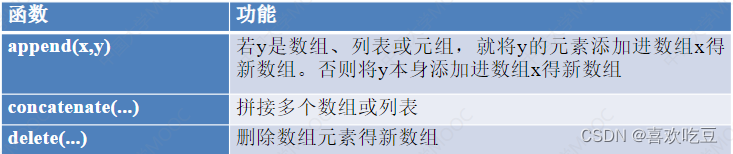
#a是[123]b = np. append(a,10)<
#a不会发生变化
print (b)
#>>[1 2 3 10]print (np. append(a, [10,20] ) )
#>>[1 2 3 10 20]C=np. zeros ( (2,3) , dtype=int)
#c是2行3列的全0数组print (np. append(a,c) )
#>>[1 2 3 0 0 0 0 0 0]print (np. concatenate( (a, [10,20] ,a)) )
#>>[1 2 3 10 20 1 2 3]print (np. concatenate( (C, np. array([[10 ,20,30]] ) ) ) )
#c拼接一行[10, 20 ,30]得新数组print (np. concatenate( (C, np.array([[1,2], [10,20]])) ,axis=1) )
#c的第0行拼接了1,2两个元素、第1行拼接了10 , 20两个新元素后得到新数组
2)numpy删除数组元素
import numpy as np
a = np.array((1,2,3,4) )
b = np.delete(a,1) #删除a中下标为1的元素, a不会改变
print (b)
#>>[1_ 3 4]b = np.array([[1,2,3,4] ,[5,6, 7,8], [9,10,11,121])
print (np. delete (b,1 ,axis=0) )
#删除b的第1行得新数组
#>>[[1 2 3 4]
#>>[9 10 11 12]]print (np. delete (b,1 ,axis=1) )
#删除b的第1列得新数组print (np. delete (b,[1,2] ,axis=0) )
#删除b的第1行和第2行得新数组print (np. delete (b,[1,3] ,axis=1) )
#删除b的第1列和第3列得新数组
3)在numpy数组中查找元素
import numpy as np
a = np.array( (1,2,3,5,3,4) )
pos = np. argwhere(a==3)
#pos是[[2] [4] ]a = np.array([[1,2,3] , [4,5,2]])
print(2 in a)
#>>Truepos = np. argwhere(a==2)
#pos是[[0 1] [1 2]]b = a[a>2]
#抽取a中大于2的元素形成一个一维数组print (b)
#>>[3 4 5]a[a>2]=-1
#a变成[[12-1][-1-12]]
4)numpy数组的数学运算
import numpy as np
a = np.array( (1,2,3,4) )
b=a+1
print (b)
#>>[2 3 4 5]print (a*b)
#>>[2 6 12 20] a,b对应元素相乘
print (a+b)
#>>[3579]a,b对应元素相加c = np.sqrt(a*10) #a*10是[10 20 30 40]print(c)
#>>[ 3. 16227766 4. 47213595 5. 47722558 6.32455532]
3,numpy数组的切片
numpy数组的切片是“视图”,是原数组的一部分,而非一部分的拷贝
import numpy as np
a=np.arange(8)
#a是[0 1 2 3 4 5 6 7]b = a[3:6]
#注意,b是a的一部分print (b)
#>>[3 4 5]c = np.copy(a[3:6])
#c是a的一部分的拷贝b[0] = 100
#会修改aprint(a)
#>>[ 0 1 2 100 4 6 7]print(c)
#>>[3 4 5] c不受b影响a = np.array([[1,2,3,4] ,[5,6,7,8] , [9,10,11,12] , [13,14,15,16]])
b = a[1:3,1:4]
#b是>>[[678][101112]]
二,数据分析库pandas
1,DataFrame的构造和访问
➢核心功能是在二维表格上做各种操作,如增删、修改、求- -列数据的和、方差、中位数、平均数等
➢需要numpy支持
➢如果有openpyxI或xIrd或xIwt支持,还可以读写excel文档。
➢最关键的类: DataFrame,表示二维表格
pandas的重要类:Series
Series是一维表格,每个元素带标签且有下标,兼具列表和字典的访问形式
import pandas as pd
s = pd. Series (data=[80, 90,100] , index=['语文', '数学', '英语'])
for x in s:
#>>80 90 100 print(x,end=" ")
print ("")
print(s['语文'] ,s[1])
#>>80 90 标签和序号都可以作为下标来访问元
print(s[0:2] [ '数学'])
#>>90 s[0:2]是切片
print(s['数学': '英语'] [1])
#>>100for i in range (len (s. index) ) :
#>>语文 数学 英语print(s. index[i] ,end = " ")
s['体育'] = 110
#在尾部添加元素,标签为'体育',值为110s. pop('数学')
#删除标签为'数学’的元素s2 = s. append (pd . Series (120, index = [' 政治'])) #不改变s
print(s2['语文'] ,s2['政治'])
#>>80 120print (1ist(s2) )
#>>[80,100, 110, 120]print(s.sum() ,s.min() ,s .mean() ,s . median() )
#>>290 80 96. 66666666667 100.0输出和、 最小值、平均值、中位数>print (s . idxmax() ,s. argmax () )
#>>体育 2 输出最大元素的标签和下标DataFrame是带行列标签的二维表格,每一列都是一个Series
import pandas as pd
pd.set_ option( 'display . unicode.east asian width' , True)
#输出对齐方面的设置scores = [['男' ,108 ,115,97] ,['女' ,115,87,105] , ['女' ,100, 60 ,130]
['男' ,112,80,50]]
names = ['刘一哥,'王二姐’,'张三妹',李四弟'] .
courses = ['性别', '语文', '数学', '英语']
df = . pd.DataFrame (data=scores ,index = names , columns = courses)
print (df)
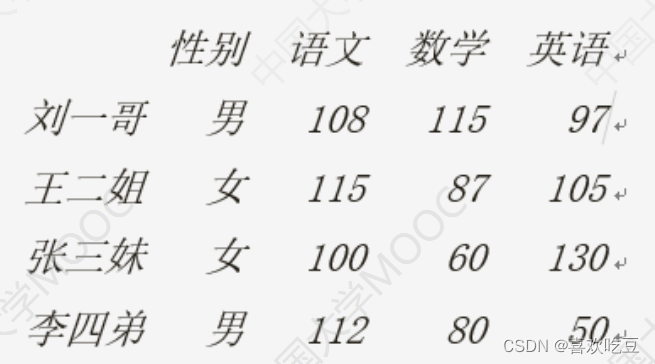
print (df. values[0] [1] , type (df. values) ) #>>108. <class numpy . ndarray '>
print (list (df. index) )
#>>['刘一哥','王二姐','张三妹','李四弟']print (list (df. columns) )
#>>['性别','语文','数学','英语']print (df . index[2] ,df . columns[2]) #>>张三妹 数学
s1 = df['语文']
#s1是个Series,代表'语文'那一列print(s1['刘一哥'] ,s1[0])
#>>108 108 刘一哥语文成绩
print(df['语文']['刘一哥'])
#>>108 列索引先写
s2 = df.1oc['王二姐']
#s2也是个Series,代表“王二姐”那一行print(s2['性别'] ,s2['语文'] ,s2[2])
#>>女 115 87 二姐的性别、语文和数学分数
2,DataFrame的切片和统计
#DataFrame的切片:
#1loc[行选择器,.列选择器] 用下标做切片
#Ioc[行选择器,列选择器] 用标签做切片
#DataFrame的切片是视图df2 = df. iloc[1:3] #行切片,是视图,选1 ,2两行
dt2 = df.1c['王二姐':张三妹'] #和上一行等价
print (df2)

df2 = df. i1oc[: ,0:3] #列切片(是视图),选0、1. 2三列
df2 = df.1oc[:, '性别': '数学'] #和上一行等价
print (df2)

df2 = df.i1oc[:2,[1,3]] #行列切片
df2 = df.1oc[:'王二姐',['语文', '英语']] #和上一行等价
print (df2)

df2 = df.i1oc[[1,3] ,2:4] #取第1、3行,第2、3列<
df2 = df.1oc[['王二姐' , '李四弟'],'数学': '英语'] #和上一行等价
print (df2)

3,DataFrame的分析统计
print ("---下面是DataFrame的分析和统计---")
print (df. T)
#df . T是df的转置矩阵,即行列互换的矩阵print (df . sort_ values ( '语文' , ascending=False)) #按语文成绩降序排列
print (df.sum() [ '语文'] ,df .mean() ['数学'],df .median() ['英语'])
#>>435 85.5 101.0语文分数之和、 数学平均分、英语中位数print(df .min() ['语文'] ,df .max() ['数学'])
#>>100 115 语文最低分,数学最高分
print (df .max(axis = 1)['王二姐'1) #>>115 二姐的最高分科目的分数
print (df['语文' ] . idxmax() )
#>>王二姐 语文最高分所在行的标签
print(df['数学] . argmin())
#>>2 数学最低分所在行的行号
print (df.1oc[ (df['语文'] > 100) & (df['数学'] >= 85)])


4,DataFrame的修改增删
print ("---下面是DataFrame的增删和修改---")
df.1oc['王二姐', '英语'] = df. iloc[0,1] = 150 #修改王二姐英语和刘一哥语文成绩
df['物理'] = [80, 70,90,100]
#为所有人添加物理成绩这-列df. insert(1, "体育", [89,77, 76,45])
#为所有人插入体育成绩到第1列df.1oc['李四弟'] = ['男' ,100 ,100 ,100 ,100,100] #修改李四弟全部信息
df.1oc[: , '语文'] = [20,20,20,20]
#修改所有人语文成绩df.1oc[ '钱五叔'] = [ '男' , 100 , 100 ,100, 100 , 100]
#加一行df.1oc[: , '英语'] += 10
#>>所有人英语加10分df. columns = ['性别', '体育', '语文', '数学', 'English', '物理'] #改列标签
print (df)


df.drop( ['体育', '物理'] ,axis=1, inplace=True) #删除体育和物理成绩
df.drop( '王二姐' ,axis = 0,inplace=True)
#删除王二姐那一行print (df)

df.drop ( [df. index[i] for i in range(1,3) ] ,axis=0 , inplace = True)
#删除第1,2行
df .drop( [df . columns[i] for i in range(3) ] ,axis = y 1 , inplace=
True) #删除第0到2列
5,读写excel和csv文档
➢需要openpyxI(对 .xIsx文件)或xIrd或xIwt支持(老的.xls文件)
➢读取的每张工作表都是一个DataFrame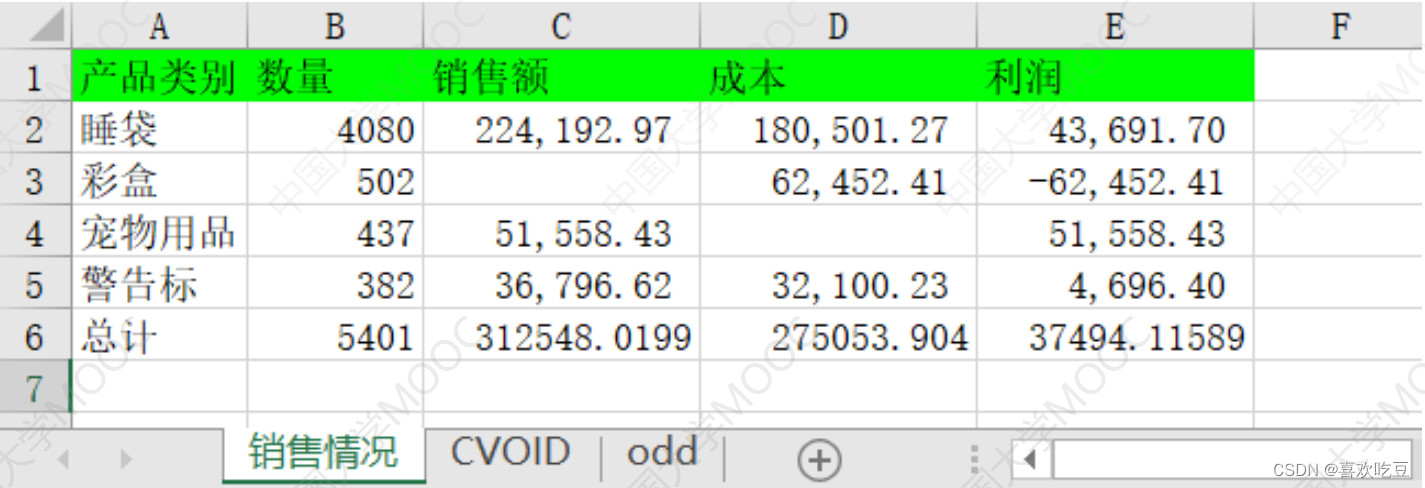
1)用pandas读excel文档
import pandas as pd
pd.set option ( ' display . unicode.east asian width' , True)
dt = pd. read excel ("'excel sample.xlsx" , sheet name= [ '销售情况' ,1] ,
index col=0) #读取第0和第1张二工作表
df =
dt [ '销售情况']
#dt是字典,df是DataFrameprint (df. iloc[0,0] ,df.loc[ 'I睡袋' , '数量'])
#>>4080 4080print (df)
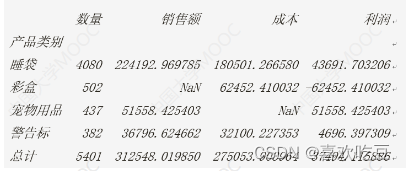
print (pd. isnu1l (df.1oc['彩盒', '销售额']))
#>> True
df . fillna (0 , inplace= =True)
#将所有NaNa用0替换
print(df.loc[ '彩盒' , '销售额'] ,df. iloc[2,2] )
#>>0.0 0.0
df.to excel (filename , sheet_ name="Sheet1" ,na_ rep='',.. ......)
➢将DataFrame对象df中的数据写入exce1文档filename中的"Sheet1"工作表, NaN用' '代替。
➢会覆盖原有的filename文件
➢如果要在一个excel文档中写入多个工作表,需要用ExcelWrite
# (接.上面程序)writer = pd. Exce 1Writer ("new.x1sx")
#创建ExcelWri ter对象df. to exce1 (writer , sheet_ name="S1")
df.T. to exce1 (writer, sheet_ name="S2")
#转置矩阵写入df.sort_ values( '销售额' , ascending= False) . to exce1 (writer ,
sheet_ name="S3")
#按销售额排序的新DataFrame写入工作表s3df[ '销售额'] . to excel (writer ,sheet_ name="S4")
#只写入一列
writer . save ()
2)用pandas读写csv文件
df. to_ csv (" result. csv" ,sep=" ," ,na rep= 'NA' ,
float_ format="号 .2f" , encoding="gbk")df = pd. read csv (" result. csv")
三,用matplotlib进行数据展示
1,绘制直方图
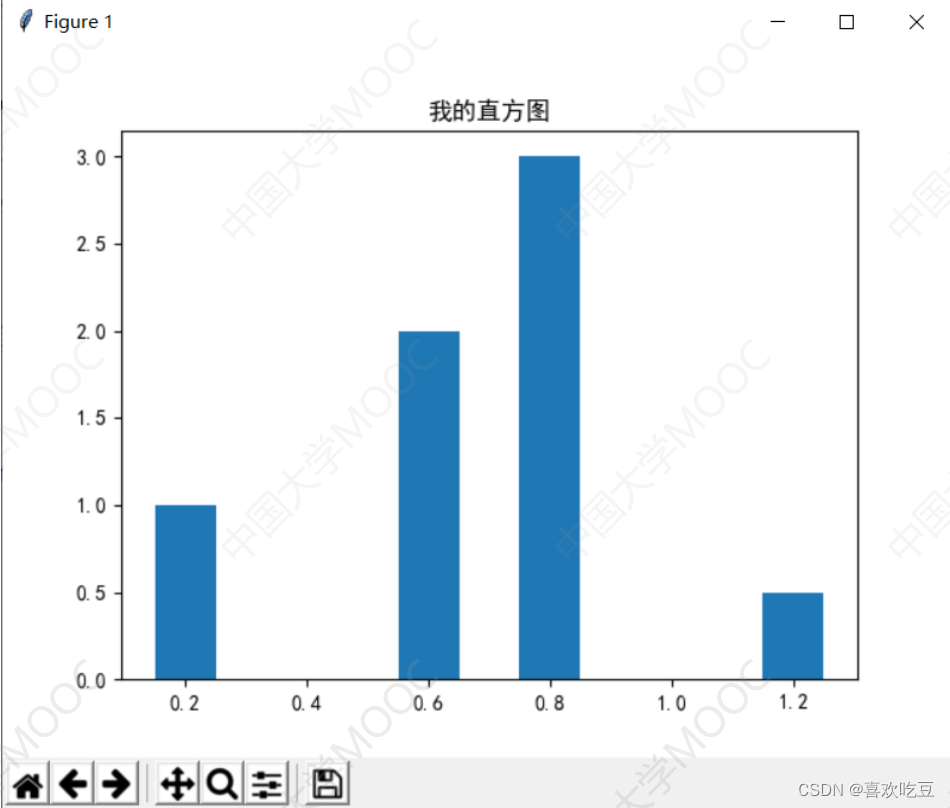
import matp1otlib. pYp1ot as plt #以后plt等价于ma tplotlib . pyplot
from ma tp1ot1ib import rcParams
rcParams[ ' font. family'] = rcParams[ ' font. sans-serif'] = ' SimHei '
#设置中文支持,中文字体为简体黑体ax = p1t. figure() .add subp1ot ()
#建图,获取子图对象axax.bar(x = (0.2,0.6,0.8,1.2) ,height = (1,2,3,0.5) ,width = 0.1)
#x表示4个柱子中心横坐标分别是0.2,0.6,0.8,1
#height表示4个柱子高度分别是1,2,3,0.5
#width表示柱子宽度0.1ax.set_ title ('我的直方图)
#设置标题p1t. show ()
#显示绘图结果
纵向
ax.bar(x = (0.2,0.6,0.8,1.2) ,height = (1,2,3,0.5) ,width = 0.1)
横向
ax.barh(y = (0.2,0.6,0.8,1.2) ,width = (1,2,3,0.5) ,height = 0.1)
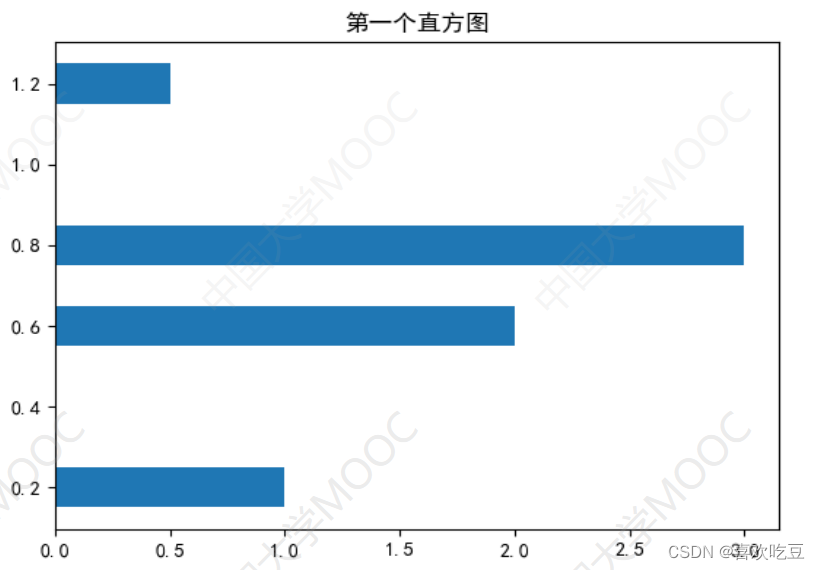
2,绘制堆叠直方图

import ma tplotlib. pyp1ot as p1t
ax = plt. figure() . add subp1ot()
labels = ['Jan' ,'Feb' ,'Mar' ,lApr']
num1 = [20, 30, 15, 35]
#Dept1的数据num2 = [15, 30,40, 20]
#Dept2的数据cordx = range (len (num1) )
#x轴刻度位置rects1 = ax.bar(x = cordx,height=num1, width=0.5, color=' red' ,
label="Dept1")
rects2 = ax.bar(x = cordx, height=num2, width=0 .5,color='green' ,
label="Dept2",bottom= =num1 )ax.set_ y1im(0, 100)
#y轴坐标范围
ax. set_ ylabel ("Profit")
#y轴含义(标签)
ax. set xticks (cordx )
#设置x轴刻度位置
ax. set_ xlabel ("In year 2020")
#x轴含义(标签)ax.set_ title ("My Company")
ax. legend()
#在右上角显示图例说明p1t. show ()
3,绘制对比直方图(有多组数据)
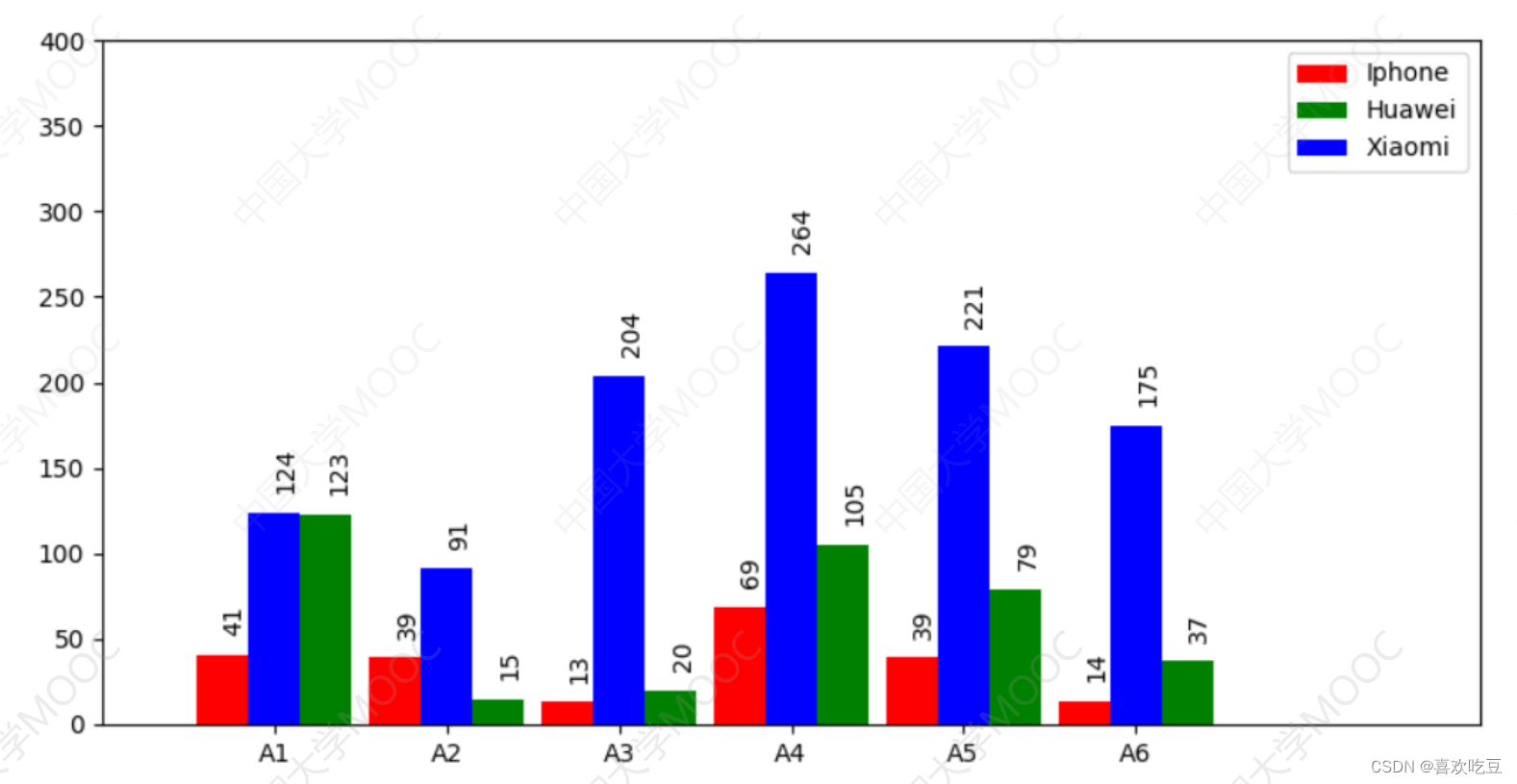
import matplotlib. pyp1ot as plt
ax =. plt. figure (figsize= (10,5)) . add_ subplot () #建图,获取子图对象ax
ax.set ylim(0, 400)
#指定y轴坐标范围ax.set xlim(0, 80)
#指定x轴坐标范围
#以下是3组直方图的数据x1=[7,17,27,37,47,57]
#第一-组直方图每个柱子中心点的横坐标
x2 = [13, 23,33,43, 53,63] #第二组直方图每个柱子中心点的横坐标
x3 = [10, 20,30,40, 50, 60]y1 = [41, 39,13,69,39, 14]
#第一组直方图每个柱子的高度
y2 = [123,15, 20,105,79,37] #第二组直方图每个柱子的高度
y3 = [124,91, 204, 264,221, 175]rects1 = ax.bar(x1, y1,facecolor='red' ,width=3, label =_ ' Iphone' )
rects2 = ax.bar (x2,y2,facecolor='green' ,width=3, label = ' Huawei ' )
rects3 = ax.bar(x3, y3,facecolor= ='blue',width=3,label = ' Xiaomi )ax.set_ xticks (x3)
#x轴在x3中的各坐标点下面加刻度ax. set_ xticklabels( ('A1', 'A2', 'A3', 'A4' , 'A5', 'A6') )
#指定x轴上每- -刻度下方的文字ax. legend ()
#显示右.上角三组图的说明def 1abe1 (ax , rects) : #在rects的每个柱子顶端标注数值
for rect in rects :
height = rect.get_ height()
ax. text (rect.get_ x() + rect.get_ width() /2,
height+14, str (height) , rotation=90) #文字旋转90度
1abe1 (ax, rects1)
label (ax , rects2)
labe1 (ax, rects3)
p1t. show ()
4,绘制散点,折线图
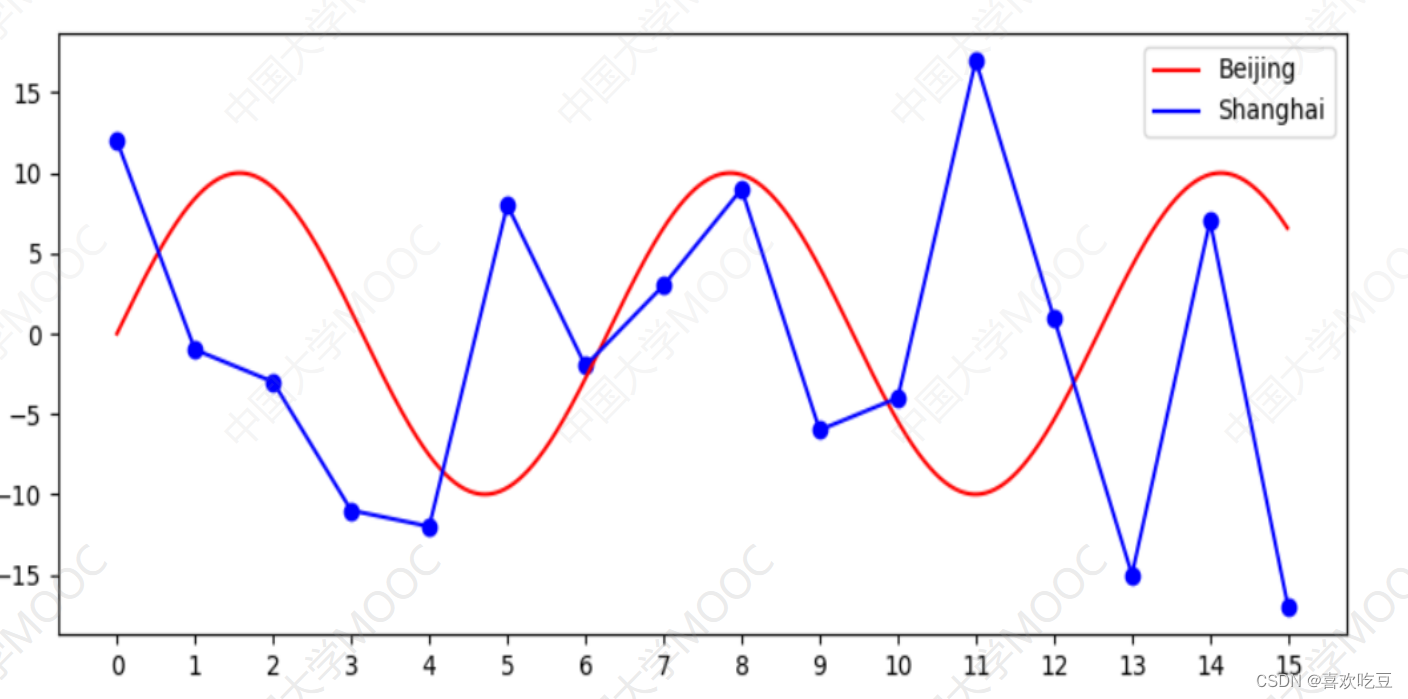
import math , random
import matplotlib.pyplot as plt
def drawPlot(ax) :
xs = [i / 100 for i in range (1500)] #1500个 点的横坐标,间隔0 .01
ys = [10*math.sin(x) for X in xs]
#对应曲线y=10*sin (x).上的1 500个点的y坐标ax.plot (xs,ys, "red" ,label = "Beijing") #画曲线y= =10*sin (x)
ys = list (range(-18,18) )
random. shuffle (ys)ax. scatter (range(16),ys[:16] ,c = "blue") #画散点
ax.plot (range(16),ys[:16] ,"blue", label=" Shanghai") #画折线ax . legend ()
#显示右.上角的各条折线说明ax.set xticks (range (16) )
#x轴在坐标0,1.. .15处加刻度
ax. set_ xticklabels (range (16)) #指定x轴每个刻度 下方显示的文字ax = plt. figure (figsize=(10,4) ,dpi=100) .add_ subp1ot() #图像长宽和清晰度
drawP1ot (ax)
p1t. show ()
5,绘制饼图
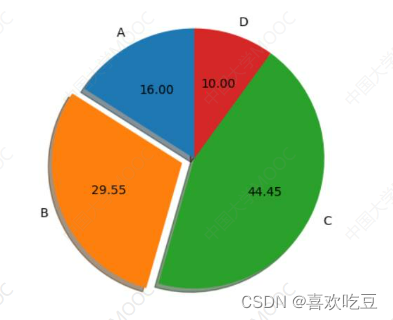
import matplotlib.pyplot as p1t .
def drawPie (ax) :
1bs = ( 'A','B', 'C',
'D' )
#四个扇区的标签
sectors = [16, 29.55, 44.45, 10]
#四个扇区的份额(百分比)
exp1 = [0, 0.1, 0,0]
#四个扇区的突出程度
ax.pie (x=sectors,labels=lbs, exp1ode=exp1,
autopct=18.2f' , shadow=True, labeldistance=1 .1,
pctdistance = 0 .6, startangle = 90)ax.set_ title ("pie sample")
#饼图标题ax = p1t. figure() .add subp1ot()
drawPie (ax)
p1t. show()
6,绘制热力图

import numpy as np
from matplotlib import pyp1ot as plt
data = np. random. randint(0,100, 30) .reshape (5,6)
#生成一一个5行六列,元素[0, 100]内的随机矩阵
xlabels = [ 'Beijing', ' Shanghai','Chengdu' ,
' Guangzhou',' Hangzhou',
' Wuhan' ]
ylabels=['2016','2017','2018','2019','20201]
ax = plt. figure (figsize=(10,8)) .add_ subp1ot()
ax.set yticks (range (len (ylabels))) #y轴在坐标 [0 , len (ylabels))处加刻度
ax.set_ yticklabels (ylabels) #设置y轴刻度文字ax. set_ xticks (range (len (xlabels) ) )
ax.set xticklabels (xlabels)
heatMp = ax. imshow (data,cmap=plt. cm.hot, aspect=' auto' ,
vmin =0,vmax=100)for i in range (1en (x1abe1s) ) :
for j in range (1en (y1abe1s) ) :
ax. text(i,j ,data[j] [i] ,ha = "center" ,va = "center"
color =
"blue" ,size=26)
p1t. colorbar (heatMp)
#绘制右边的颜色-数值对照柱
plt . xticks (rotation=45 , ha=" right") #将x轴刻度文字进行旋转, 且水平方向右对齐
p1t. title ("Sales Volume (ton) ")
p1t. show ()
7,绘制雷达图
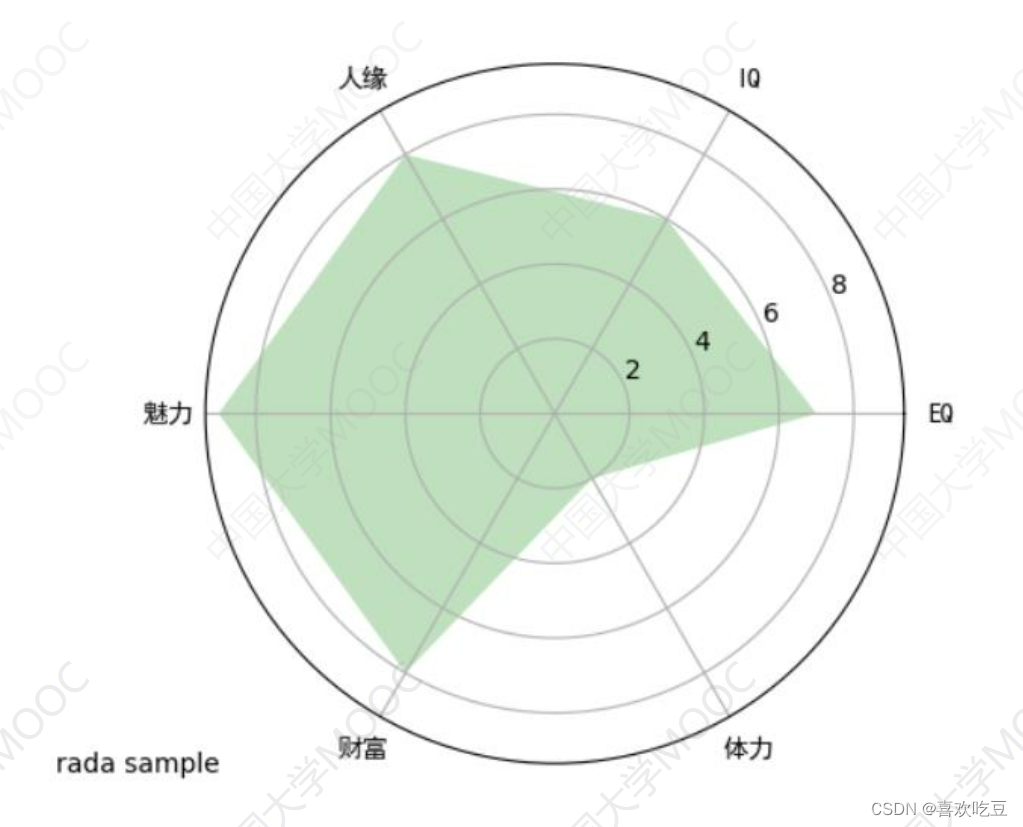
import matplotlib. pyplot as plt
from matplotlib import rcParams
#处理汉字用def drawRadar (ax) :
pi = 3.1415926
labels = ['EQ', 'IQ','人缘' , '魅力', '财富' , '体力'] #6个属性的名称
attrNum = len (labels)
#attrNum是属性种类数,处等于6
data = [7 ,6,8,9,8,2]
#六个属性的值
angles = [2*pi *i/ attrNum for i in range (attrNum) ]
#angles是以弧度为单位的6个属性对应的6条半径线的角度
angles2 = [x * 180/pi for x in angles]
#angles2是以角度为单位的6个属性对应的半径线的角度
ax.set ylim(0,10)
#限定半径线上的坐标范围ax. set_ thetagrids (angles2,labels , fontproperties="SimHei" )
#绘制6个属性对应的6条半径ax. fi1l (angles,data, facecolor= ; : 6 'g' ,alpha= =0.25)
#填充,alpha :透明度rcParams[' font. family'] = rcParams[' font. sans-serif'] = ' SimHei '
#处理汉字
ax = p1t. figure() . add_ subplot (projection = "polar")
#生成极坐标形式子图
drawRadar (ax)
p1t. show ()
8,绘制多层雷达图
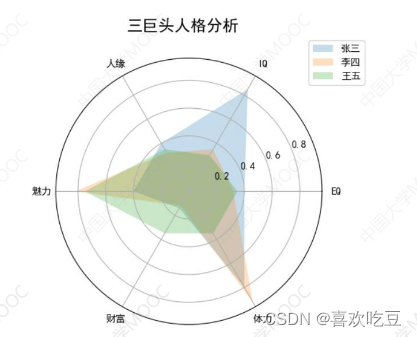
import matplotlib.pyplot as p1t
from ma tplot1ib import rcPar ams
rcParams[ ' font. family'] = rcParams[ ' font. sans-serif'] = ' SimHei !
pi = 3.1415926
labels = ['EQ', 'IQ','人缘', '魅力',财富', '体力] #6个属性的名称
attrNum = len (labels)
names = (张三',李四'王五
data = [[0.40,0.32,0.35] ,
[0.85,0.35,0.30] ,
[0.40,0.32,0.35],[0.40,0.82,0.75] ,
[0.14,0.12,0.35] ,
[0.80,0.92,0.35]]
#三个人的数据angles = [2*pi*i/attrNum for i in range (attrNum) ]
angles2 = [x * 180/pi for x in ang1es]
ax = p1t. figure() .add_ subp1ot (projection = "polar")ax. set_ the tagrids (angles2 , labels)
ax.set_ title('三巨头人格分析',y = 1.05) #y指明标题垂直位置
ax. legend (names , 1oc=(0.95,0.9)) #画出右上角不同人的颜色说明
plt. show ()
9,多子图绘制
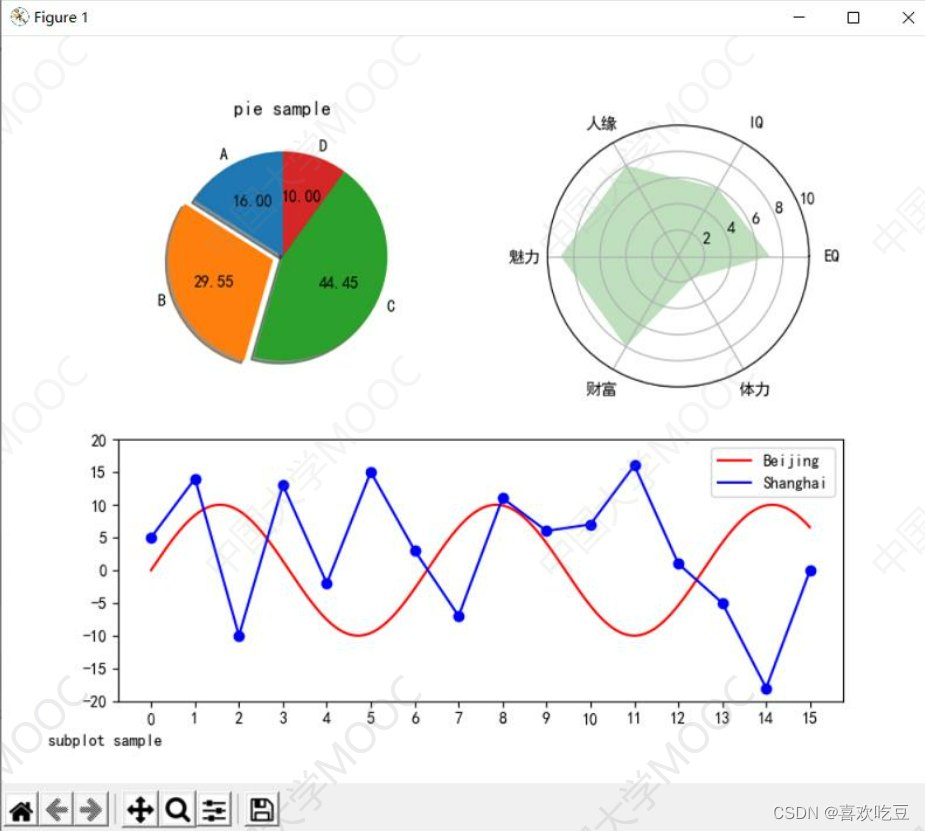
#程序中的import、汉字处理及drawRadar、 drawPie、 drawPlot函数略, 见前面程序
fig = plt. figure (figsize=(8,8) )
ax = fig.add subplot(2,2,1) #窗口分割成2*2,取位于第1个方格的子图
drawPie (ax)
ax = fig.add subplot(2 ,2 ,2 ,projection = "polar" )
drawRadar (ax)
ax = p1t. subp1ot2grid( (2, 2),(1, 0),colspan=2)
#或写成: ax = fig.add subplot(2,1,2)drawPlot (ax)
plt. figtext(0.05,0.05, ' subplot sample' )
#显示左下角的图像标题plt. show ()
相关文章:
Python实用技术二:数据分析和可视化(2)
目录 一,多维数组库numpy 1,操作函数: 2,numpy数组元素增删 1)添加数组元素 2)numpy删除数组元素 3)在numpy数组中查找元素 4)numpy数组的数学运算 3,numpy数…...
24Hibench
1. Hibench 官网 HiBench is a big data benchmark suite that helps evaluate different big data frameworks in terms of speed, throughput and system resource utilizations. It contains a set of Hadoop, Spark and streaming workloads, including Sort, WordCou…...

VC++父进程交互式操作子进程标准输入输出
父进程接管子进程的标准输入输出和错误,实现对子进程的交互操作。比如子进程是一个类似mysql这种可以交互的命令,执行操作后输出结果,父进程根据结果分析决定执行下一步的命令,从而替代人工的输入。 通过父进程创建子进程,使用管道重定向子进程的输入输出错误可以实现 在 …...
一步一招,教你如何制作出成功的优惠促销微传单
在当今的数字化时代,几乎所有的事情都可以在互联网上完成,包括制作宣传单。有很多在线工具可以帮助我们轻松制作出精美的商场促销宣传单。下面就以乔拓云为例,详细介绍如何简单几步制作出让人眼前一亮的商场促销宣传单。 1. 注册并登录乔拓云…...
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...
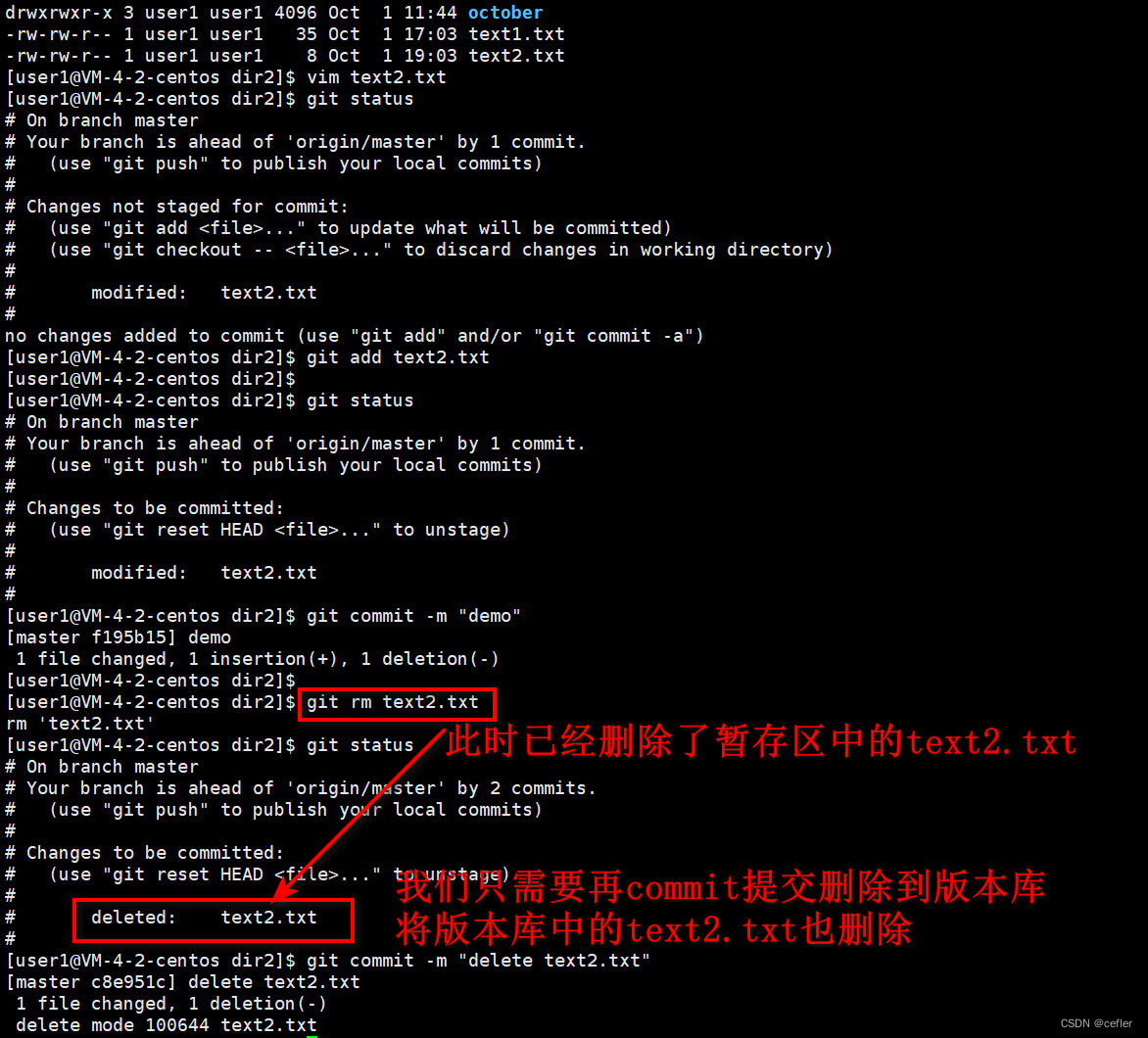
Git使用【上】
欢迎来到Cefler的博客😁 🕌博客主页:那个传说中的man的主页 🏠个人专栏:题目解析 🌎推荐文章:题目大解析3 前言 先前有些git命令我在我的其它文章里面已经写过,若要查看可参考【Linu…...
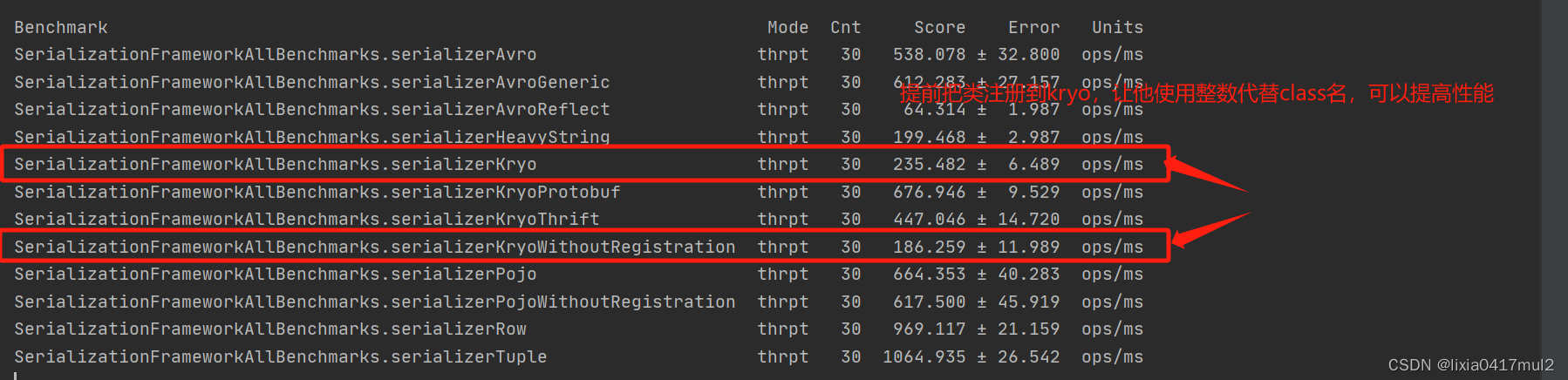
flink的序列化基准测试
背景: flink提供了在本地环境使用jmh测试不同序列化方法的性能差异,本文就是基于这个https://github.com/apache/flink-benchmarks这个性能测试,总结几个结论,以便后面使用时避免掉坑 基准测试 我们本次运行的是SerializationF…...

Error: node: unknown or unsupported macOS version: :dunno 错误解决
一、原因 今天安装 brew install node报错了,错误信息如下: 二、解决方案 1)查找homebrew-cask安装位置 echo $(brew --repo homebrew/homebrew-cask) // 输出 /opt/homebrew/Library/Taps/homebrew/homebrew-cask2)使用 gi…...

嵌入式Linux应用开发-基础知识-第十八章系统对中断的处理②
嵌入式Linux应用开发-基础知识-第十八章系统对中断的处理② 第十八章 Linux系统对中断的处理 ②18.3 Linux中断系统中的重要数据结构18.3.1 irq_desc数组18.3.2 irqaction结构体18.3.3 irq_data结构体18.3.4 irq_domain结构体18.3.5 irq_chip结构体 18.4 在设备树中指定中断_在…...

Kolmogorov-Smirnov正态性检验
Kolmogorov-Smirnov正态性检验是一种统计方法,用于检验数据集是否服从正态分布。其基本原理和用途如下: 基本原理: 假设检验:Kolmogorov-Smirnov检验基于一个假设,即待检验的数据集服从特定的理论正态分布。计算累积…...

BI神器Power Query(25)-- 使用PQ实现表格多列转换(1/3)
实例需求:原始表格包含多列属性数据,现在需要将不同属性分列展示在不同的行中,att1、att3、att5为一组,att2、att3、att6为另一组,数据如下所示。 更新表格数据 原始数据表: Col1Col2Att1Att2Att3Att4Att5Att6AAADD…...
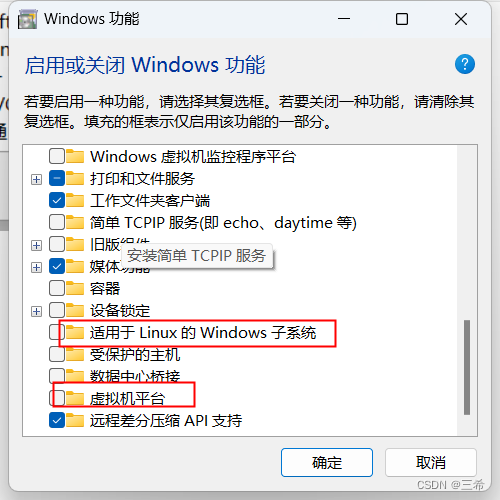
windows系统一键开启和关闭虚拟化
说明 跟虚拟化相关的三个程序 一键开启脚本 REM 开启 Hyper-V 服务 pushd "%~dp0"dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hyper-v.txtfor /f %%i in (findstr /i . hyper-v.txt 2^>nul) do dism /online /norestart /add-package:"%Sy…...

NSSCTF做题(5)
[NSSCTF 2022 Spring Recruit]babyphp 代码审计 if(isset($_POST[a])&&!preg_match(/[0-9]/,$_POST[a])&&intval($_POST[a])){ if(isset($_POST[b1])&&$_POST[b2]){ if($_POST[b1]!$_POST[b2]&&md5($_POST[b1])md5($_POST[b2])){…...

java基础题——二维数组的基本应用
1.设计程序按照各个学生的 Java 成绩进行排序 ( 降序 ) 2.设计程序,根据学生总成绩进行排序(降序排列),并输出学生姓名、每门课程的名称和该学生的成绩、该学生的总成绩 public static void main(String[] args) {String[] names {"安琪拉",…...

Leetcode 2119.反转两次的数字
反转 一个整数意味着倒置它的所有位。 例如,反转 2021 得到 1202 。反转 12300 得到 321 ,不保留前导零 。 给你一个整数 num ,反转 num 得到 reversed1 ,接着反转 reversed1 得到 reversed2 。如果 reversed2 等于 num &#x…...
BI神器Power Query(27)-- 使用PQ实现表格多列转换(3/3)
实例需求:原始表格包含多列属性数据,现在需要将不同属性分列展示在不同的行中,att1、att3、att5为一组,att2、att3、att6为另一组,数据如下所示。 更新表格数据 原始数据表: Col1Col2Att1Att2Att3Att4Att5Att6AAADD…...
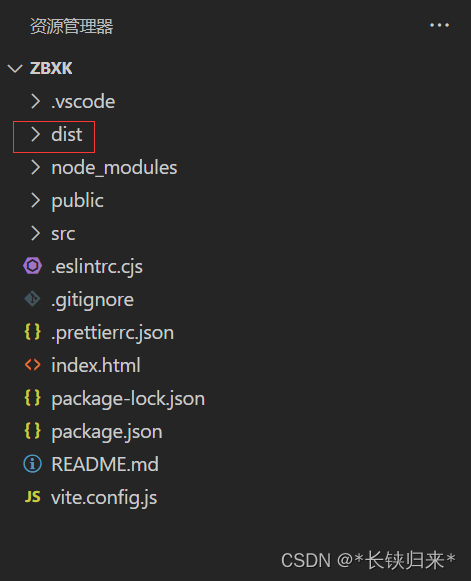
VUE3照本宣科——认识VUE3
VUE3照本宣科——认识VUE3 前言一、命令创建项目1.中文官网2.菜鸟教程 二、VUE3项目目录结构1.public2.src(1)assets(2)components 3. .eslintrc.cjs4. .gitignore5. .prettierrc.json6.index.html7.package.json8.README.md9.vit…...

《计算机视觉中的多视图几何》笔记(12)
12 Structure Computation 本章讲述如何在已知基本矩阵 F F F和两幅图像中若干对对应点 x ↔ x ′ x \leftrightarrow x x↔x′的情况下计算三维空间点 X X X的位置。 文章目录 12 Structure Computation12.1 Problem statement12.2 Linear triangulation methods12.3 Geomet…...

TFT LCD刷新原理及LCD时序参数总结(LCD时序,写的挺好)
cd工作原理目前不了解,日后会在博客中添加这一部分的内容。 1.LCD工作原理[1] 我对LCD的工作原理也仅仅处在了解的地步,下面基于NXP公司对LCD工作原理介绍的ppt来学习一下。 LCD(liquid crystal display,液晶显示屏) 是由液晶段阵列组成,当…...

基于Java的电影院购票系统设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作…...

从UHS-II到DDR4:2014年存储技术演进与工程实践启示
1. 项目概述:一次2014年秋的存储技术快照九月的风刚带起一丝凉意,存储半导体领域却热闹非凡。作为一名长期跟踪硬件发展的从业者,我习惯定期梳理行业动态,而2014年9月这份来自EE Times的“Memory Product Round Up”产品汇总&…...

3分钟掌握跨平台鼠标连点器:免费开源自动化工具快速上手指南
3分钟掌握跨平台鼠标连点器:免费开源自动化工具快速上手指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 &#…...

Linux小白避坑指南:Resilio Sync安装后权限配置与Web界面访问失败的常见问题解决
Linux权限迷宫:Resilio Sync安装后的深度避坑实战 当8888端口沉默时:一次真实的故障排查记录 上周五晚上11点,我正准备将团队的设计素材库同步到本地开发环境。按照官方文档,我在Ubuntu 22.04上顺利安装了Resilio Sync,…...

用STM32+NRF24L01模拟蓝牙广播,手机能搜到设备了!附完整代码
用STM32NRF24L01模拟蓝牙低功耗广播的实战指南 当我在实验室里第一次看到手机蓝牙搜索列表中出现自己用NRF24L01模块模拟的设备名称时,那种成就感至今难忘。这个看似简单的实验背后,其实隐藏着无线通信协议栈的巧妙设计。本文将带你从零开始,…...

3步搞定无损音乐自由:网易云音乐歌单批量下载终极指南
3步搞定无损音乐自由:网易云音乐歌单批量下载终极指南 【免费下载链接】NeteaseCloudMusicFlac 根据网易云音乐的歌单, 下载flac无损音乐到本地.。 项目地址: https://gitcode.com/gh_mirrors/nete/NeteaseCloudMusicFlac 你是否曾经想过,只需一个…...

从Concur到特斯拉:为什么伟大产品始于“丑陋”的1.0版本
1. 从一笔74亿美元的收购案说起:为什么别急着给1.0产品判死刑 前几天翻看一些旧资料,看到一篇2014年的行业评论,讲的是德国软件巨头SAP以74亿美元的天价,收购了一家名叫Concur的西雅图公司。当时很多人觉得不可思议,Co…...

从“能用”到“可靠”:基于SonarQube与Jenkins的Java代码质量防线构建实战
当测试覆盖率不再只是一串数字,而是合并代码前的“一票否决权” 1. 为什么你的“质量门禁”只是个摆设? 在很多团队的CI/CD流水线中,SonarQube的集成往往停留在“能跑就行”的阶段。流水线里确实有代码扫描这一步,日志里也打印出…...

量子机器学习框架互操作性挑战与解决方案
1. 量子机器学习框架互操作性挑战与解决方案量子机器学习(QML)作为量子计算与经典机器学习的交叉领域,近年来在理论和实践层面都取得了显著进展。变分量子算法(VQAs)和参数化量子电路(PQCs)已成…...

)
CC2530项目实战:用OLED屏做个简易温湿度显示器(基于DHT11传感器)
CC2530实战:基于DHT11的OLED温湿度监测系统开发指南 在嵌入式开发领域,将传感器数据可视化是物联网项目的核心技能之一。CC2530作为一款经典的51内核单片机,搭配0.96寸OLED屏幕和DHT11温湿度传感器,可以构建一个低成本但功能完整的…...