kubernetes-v1.23.3 部署 kafka_2.12-2.3.0
文章目录
- @[toc]
- 构建 debian 基础镜像
- 部署 zookeeper
- 配置 namespace
- 配置 gfs 的 endpoints
- 配置 pv 和 pvc
- 配置 configmap
- 配置 service
- 配置 statefulset
- 部署 kafka
- 配置 configmap
- 配置 service
- 配置 statefulset
文章目录
- @[toc]
- 构建 debian 基础镜像
- 部署 zookeeper
- 配置 namespace
- 配置 gfs 的 endpoints
- 配置 pv 和 pvc
- 配置 configmap
- 配置 service
- 配置 statefulset
- 部署 kafka
- 配置 configmap
- 配置 service
- 配置 statefulset
- 这里采用的部署方式如下:
- 使用自定义的 debian 镜像作为基础镜像
- 目的1:可以塞很多排查工具进去
- 目的2:一个统一的基础镜像,方便维护
- 目的3:centos 后期不维护了,避免尴尬场景
- 通过 gfs 做数据持久化,通过 pv 和 pvc 的形式将二进制文件挂载到 pod 内
- kafka 的二进制文件里面带有了 zookeeper,这里就只使用 kafka 的二进制文件
- kafka 二进制文件下载地址
构建 debian 基础镜像
FROM debian:11ENV TZ=Asia/Shanghai
ENV LANG=en_US.UTF-8RUN echo "" > /etc/apt/sources.list && \for i in stable stable-proposed-updates stable-updates;\do \echo "deb http://mirrors.cloud.aliyuncs.com/debian ${i} main contrib non-free" >> /etc/apt/sources.list;\echo "deb-src http://mirrors.cloud.aliyuncs.com/debian ${i} main contrib non-free" >> /etc/apt/sources.list;\echo "deb http://mirrors.aliyun.com/debian ${i} main contrib non-free" >> /etc/apt/sources.list;\echo "deb-src http://mirrors.aliyun.com/debian ${i} main contrib non-free" >> /etc/apt/sources.list;\done && \apt-get update && \DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends vim \curl wget bind9-utils telnet unzip net-tools tree nmap ncat && \apt-get clean && apt-get autoclean
DEBIAN_FRONTEND=noninteractive
- 非交互模式
--no-install-recommends
- 此选项告诉
apt-get不要安装与请求的软件包一起推荐的软件包。- Debian 软件包的依赖关系可以分为两种类型:“Depends” 和 “Recommends”。
- 通过使用此选项,您表示只想安装 “Depends” 部分中列出的软件包,并跳过 “Recommends” 部分。
- 如果您不需要所有推荐的软件包,这可以帮助保持安装的系统更加精简
- 构建镜像
docker build -t debian11_amd64_base:v1.0 .
部署 zookeeper
配置 namespace
我的环境做了软连接,下面的命令中出现的 k 表示 kubectl 命令
k create ns bigdata
配置 gfs 的 endpoints
正如开头提到的,我这边使用的是 gfs 来做的持久化,需要通过 endpoints 来暴露给 k8s 集群内部使用,相关的资料可以看我其他的文章
- CentOS 7.6 部署 GlusterFS 分布式存储系统
- Kubernetes 集群使用 GlusterFS 作为数据持久化存储
---
apiVersion: v1
kind: Endpoints
metadata:annotations:name: glusterfs-bigdatanamespace: bigdata
subsets:
- addresses:- ip: 172.72.0.130- ip: 172.72.0.131ports:- port: 49152protocol: TCP
---
apiVersion: v1
kind: Service
metadata:annotations:name: glusterfs-bigdatanamespace: bigdata
spec:ports:- port: 49152protocol: TCPtargetPort: 49152sessionAffinity: Nonetype: ClusterIP
配置 pv 和 pvc
---
apiVersion: v1
kind: PersistentVolume
metadata:annotations:labels:software: bigdataname: bigdata-software-pv
spec:accessModes:- ReadOnlyManycapacity:storage: 10Giglusterfs:endpoints: glusterfs-bigdatapath: online-share/kubernetes/software/readOnly: falsepersistentVolumeReclaimPolicy: Retain
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:annotations:labels:software: bigdataname: bigdata-software-pvcnamespace: bigdata
spec:accessModes:- ReadOnlyManyresources:requests:storage: 10Giselector:matchLabels:software: bigdata
检查 pvc 是否处于 bound 状态
k get pvc -n bigdata
正确创建的情况下,STATUS 的状态是 bound
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
bigdata-software-pvc Bound bigdata-software-pv 10Gi ROX 87s
配置 configmap
---
apiVersion: v1
data:startZk.sh: |-#!/bin/bashset -xecho "${POD_NAME##*-}" > ${ZK_DATA}/myidsed "s|{{ ZK_DATA }}|${ZK_DATA}|g" ${CM_DIR}/zookeeper.properties > ${ZK_CONF}/zookeeper.propertiesecho "" >> ${ZK_CONF}/zookeeper.propertiesn=0while (( n++ < ${REPLICAS} ))doecho "server.$((n-1))=${APP_NAME}-$((n-1)).${APP_NAME}-svc.${NAMESPACE}.svc.cluster.local:2888:3888" >> ${ZK_CONF}/zookeeper.propertiesdonecat ${ZK_CONF}/zookeeper.propertiesKAFKA_HEAP_OPTS="-Xmx${JAVA_OPT_XMX} -Xms${JAVA_OPT_XMS} -Xss512k -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:MaxGCPauseMillis=200 -XX:InitiatingHeapOccupancyPercent=45 -Djava.io.tmpdir=/tmp -Xloggc:${LOG_DIR}/gc.log -Dsun.net.inetaddr.ttl=10"${ZK_HOME}/bin/zookeeper-server-start.sh ${ZK_CONF}/zookeeper.propertieszookeeper.properties: |-dataDir={{ ZK_DATA }}clientPort=2181maxClientCnxns=0initLimit=1syncLimit=1
kind: ConfigMap
metadata:annotations:labels:app: zkname: zk-cmnamespace: bigdata
配置 service
---
apiVersion: v1
kind: Service
metadata:annotations:labels:app: zkname: zk-svcnamespace: bigdata
spec:ports:- name: tcpport: 2181- name: serverport: 2888- name: electport: 3888selector:app: zk
配置 statefulset
启动 statefulset 之前,需要先给节点打上标签,因为针对 pod 做了节点和 pod 的亲和性,因为 zookeeper 的数据是通过 hostpath 的方式来持久化的,所以需要固定节点,同时需要 pod 亲和性来控制一个节点只能出现一个 zookeeper 的 pod,避免 hostpath 出现问题
k label node 172.72.0.129 zk=
k label node 172.72.0.130 zk=
k label node 172.72.0.131 zk=
创建 statefulset
---
apiVersion: apps/v1
kind: StatefulSet
metadata:annotations:labels:app: zkname: zknamespace: bigdata
spec:replicas: 3selector:matchLabels:app: zkserviceName: zk-svctemplate:metadata:annotations:labels:app: zkspec:affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: zkoperator: ExistspodAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- zktopologyKey: kubernetes.io/hostnamecontainers:- command:- bash- /app/zk/cm/startZk.shenv:- name: APP_NAMEvalue: zk- name: NODE_NAMEvalueFrom:fieldRef:fieldPath: spec.nodeName- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespace- name: POD_IPvalueFrom:fieldRef:fieldPath: status.podIP- name: ZK_HOMEvalue: /app/software/kafka_2.12-2.3.0- name: REPLICASvalue: "3"- name: ZK_DATAvalue: /app/zk/data# LOG_DIR 是 kafka-run-class.sh 启动 zk 的时候使用的环境变量- name: LOG_DIRvalue: /app/zk/log- name: ZK_CONFvalue: /app/zk/conf- name: CM_DIRvalue: /app/zk/cm- name: JAVA_HOMEvalue: /app/software/jdk1.8.0_231- name: JAVA_OPT_XMSvalue: 512m- name: JAVA_OPT_XMXvalue: 512mimage: debian11_amd64_base:v1.0imagePullPolicy: IfNotPresentlivenessProbe:tcpSocket:port: 2181failureThreshold: 3initialDelaySeconds: 10periodSeconds: 30successThreshold: 1timeoutSeconds: 5readinessProbe:tcpSocket:port: 2181failureThreshold: 3initialDelaySeconds: 20periodSeconds: 30successThreshold: 1timeoutSeconds: 5name: zkports:- containerPort: 2181name: tcp- containerPort: 2888name: server- containerPort: 3888name: electvolumeMounts:- mountPath: /app/zk/dataname: data- mountPath: /app/zk/logname: log- mountPath: /app/zk/cmname: cm- mountPath: /app/zk/confname: conf- mountPath: /app/softwarename: softwarereadOnly: truerestartPolicy: AlwayssecurityContext: {}terminationGracePeriodSeconds: 0volumes:- emptyDir: {}name: log- emptyDir: {}name: conf- configMap:name: zk-cmname: cm- name: softwarepersistentVolumeClaim:claimName: bigdata-software-pvc- hostPath:path: /data/k8s_data/zookeepertype: DirectoryOrCreatename: data
部署 kafka
配置 configmap
---
apiVersion: v1
data:server.properties: |-broker.id={{ broker.id }}broker.rack={{ broker.rack }}log.dirs={{ DATA_DIR }}listeners=INTERNAL://0.0.0.0:9092, EXTERNAL://0.0.0.0:9093advertised.listeners=INTERNAL://{{ broker.name }}:9092,EXTERNAL://{{ broker.host }}:9093listener.security.protocol.map=INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXTinter.broker.listener.name=INTERNALzookeeper.connect={{ ZOOKEEPER_CONNECT }}auto.create.topics.enable=falsedefault.replication.factor=2num.partitions: 3num.network.threads: 3num.io.threads: 6socket.send.buffer.bytes: 102400socket.receive.buffer.bytes: 102400socket.request.max.bytes: 104857600num.recovery.threads.per.data.dir: 1offsets.topic.replication.factor: 2transaction.state.log.replication.factor: 2transaction.state.log.min.isr: 2log.retention.hours: 168log.segment.bytes: 1073741824log.retention.check.interval.ms: 300000zookeeper.connection.timeout.ms: 6000group.initial.rebalance.delay.ms: 0delete.topic.enable: truestartKafka.sh: |-#!/bin/bashset -xif [ -f ${DATA_DIR}/meta.properties ];thenKAFKA_BROKER_ID=$(awk -F '=' '/broker.id/ {print $NF}' app/kafka/data/meta.properties)elseKAFKA_BROKER_ID=${POD_NAME##*-}fiZOOKEEPER_CONNECT='zk-0.zk-svc.bigdata.svc.cluster.local:2181,zk-1.zk-svc.bigdata.svc.cluster.local:2181,zk-2.zk-svc.bigdata.svc.cluster.local:2181'sed "s|{{ broker.id }}|${KAFKA_BROKER_ID}|g" ${CM_DIR}/server.properties > ${CONF_DIR}/server.propertiessed -i "s|{{ broker.rack }}|${NODE_NAME}|g" ${CONF_DIR}/server.propertiessed -i "s|{{ broker.host }}|${NODE_NAME}|g" ${CONF_DIR}/server.propertiessed -i "s|{{ broker.name }}|${POD_NAME}.${APP_NAME}-svc.${NAMESPACE}.svc.cluster.local|g" ${CONF_DIR}/server.propertiessed -i "s|{{ ZOOKEEPER_CONNECT }}|${ZOOKEEPER_CONNECT}|g" ${CONF_DIR}/server.propertiessed -i "s|{{ DATA_DIR }}|${DATA_DIR}|g" ${CONF_DIR}/server.propertiescat ${CONF_DIR}/server.propertiesexport KAFKA_HEAP_OPTS="-Xmx${JAVA_OPT_XMX} -Xms${JAVA_OPT_XMS} -Xss512k -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:MaxGCPauseMillis=200 -XX:InitiatingHeapOccupancyPercent=45 -Djava.io.tmpdir=/tmp -Xloggc:${LOG_DIR}/gc.log -Dsun.net.inetaddr.ttl=10"${KAFKA_HOME}/bin/kafka-server-start.sh ${CONF_DIR}/server.propertiessleep 3
kind: ConfigMap
metadata:annotations:labels:app: kafkaname: kafka-cmnamespace: bigdata
配置 service
---
apiVersion: v1
kind: Service
metadata:annotations:labels:app: kafkaname: kafka-svcnamespace: bigdata
spec:clusterIP: Noneports:- name: tcpport: 9092targetPort: 9092selector:app: kafka
配置 statefulset
---
apiVersion: apps/v1
kind: StatefulSet
metadata:annotations:labels:app: kafkaname: kafkanamespace: bigdata
spec:replicas: 3selector:matchLabels:app: kafkaserviceName: kafka-svctemplate:metadata:labels:app: kafkaspec:affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- kafkatopologyKey: kubernetes.io/hostnamecontainers:- command:- /bin/bash- -c- . ${CM_DIR}/startKafka.shenv:- name: APP_NAMEvalue: kafka- name: NODE_NAMEvalueFrom:fieldRef:fieldPath: spec.nodeName- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespace- name: POD_IPvalueFrom:fieldRef:fieldPath: status.podIP- name: KAFKA_HOMEvalue: /app/software/kafka_2.12-2.3.0- name: DATA_DIRvalue: /app/kafka/data- name: LOG_DIRvalue: /app/kafka/log- name: CONF_DIRvalue: /app/kafka/conf- name: CM_DIRvalue: /app/kafka/configmap- name: JAVA_HOMEvalue: /app/software/jdk1.8.0_231- name: JAVA_OPT_XMSvalue: 512m- name: JAVA_OPT_XMXvalue: 512mname: kafkaimage: debian11_amd64_base:v1.0imagePullPolicy: IfNotPresentlivenessProbe:failureThreshold: 3initialDelaySeconds: 60periodSeconds: 20successThreshold: 1tcpSocket:port: kafkatimeoutSeconds: 1readinessProbe:failureThreshold: 3initialDelaySeconds: 20periodSeconds: 20successThreshold: 1tcpSocket:port: kafkatimeoutSeconds: 1ports:- containerPort: 9092hostPort: 9092name: kafka- containerPort: 9093hostPort: 9093name: kafkaoutvolumeMounts:- mountPath: /app/kafka/dataname: data- mountPath: /app/kafka/logname: log- mountPath: /app/kafka/configmapname: configmap- mountPath: /app/kafka/confname: conf- mountPath: /app/softwarename: softwarereadOnly: truerestartPolicy: AlwayssecurityContext: {}terminationGracePeriodSeconds: 10volumes:- emptyDir: {}name: log- emptyDir: {}name: conf- configMap:name: kafka-cmname: configmap- name: softwarepersistentVolumeClaim:claimName: bigdata-software-pvc- name: datahostPath:path: /data/k8s_data/kafkatype: DirectoryOrCreate
相关文章:

kubernetes-v1.23.3 部署 kafka_2.12-2.3.0
文章目录 [toc]构建 debian 基础镜像部署 zookeeper配置 namespace配置 gfs 的 endpoints配置 pv 和 pvc配置 configmap配置 service配置 statefulset 部署 kafka配置 configmap配置 service配置 statefulset 这里采用的部署方式如下: 使用自定义的 debian 镜像作为…...

位置编码器
目录 1、位置编码器的作用 2、代码演示 (1)、使用unsqueeze扩展维度 (2)、使用squeeze降维 (3)、显示张量维度 (4)、随机失活张量中的数值 3、定义位置编码器类,我…...
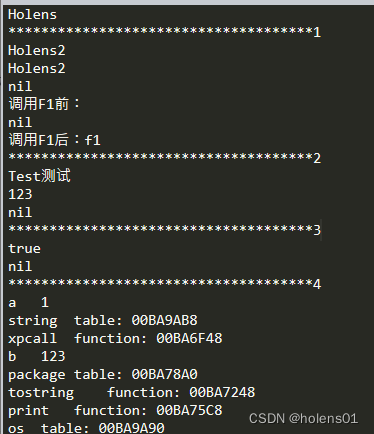
Lua多脚本执行
--全局变量 a 1 b "123"for i 1,2 doc "Holens" endprint(c) print("*************************************1")--本地变量(局部变量) for i 1,2 dolocal d "Holens2"print(d) end print(d)function F1( ..…...
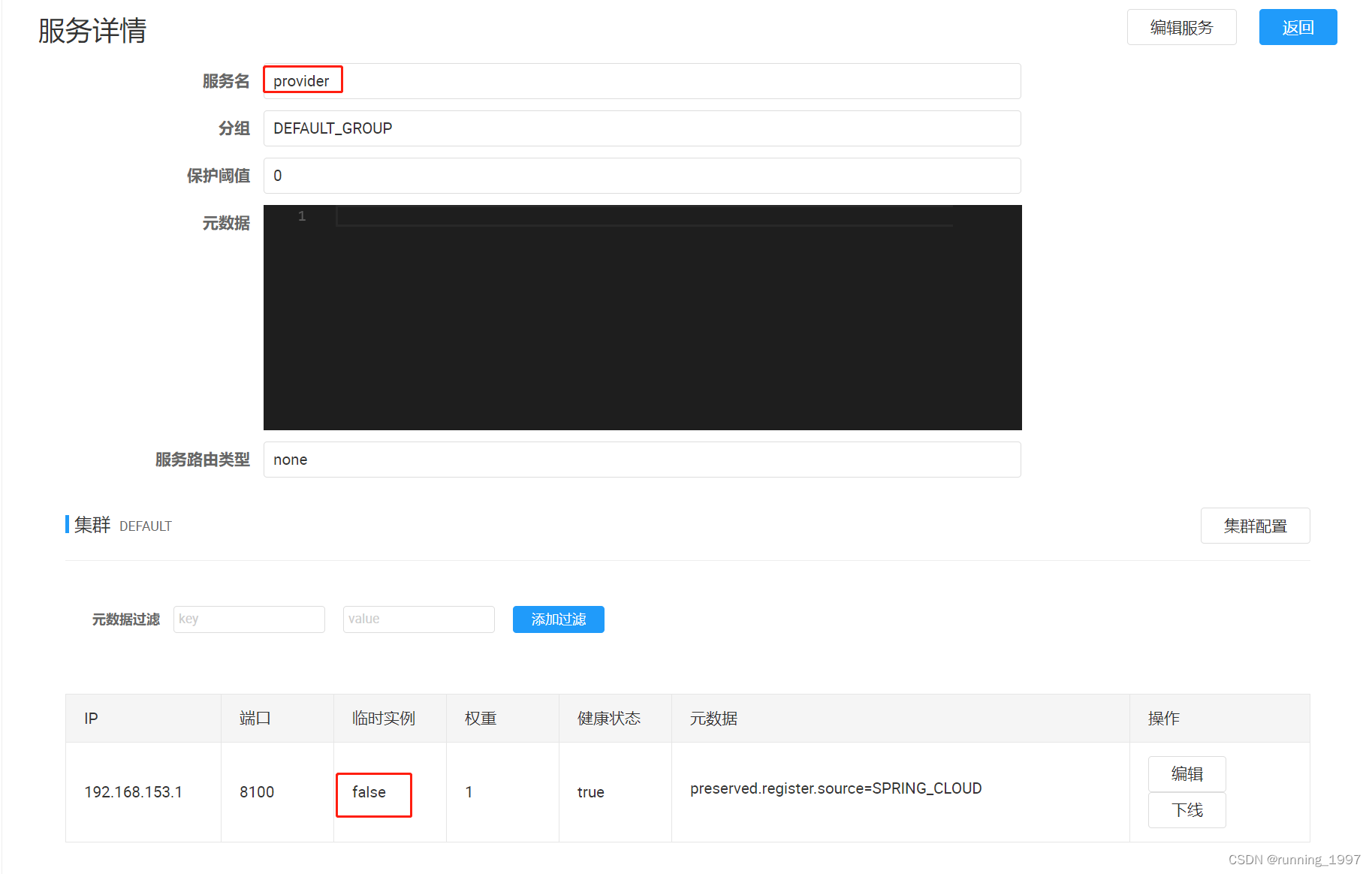
Spirng Cloud Alibaba Nacos注册中心的使用 (环境隔离、服务分级存储模型、权重配置、临时实例与持久实例)
文章目录 一、环境隔离1. Namespace(命名空间):2. Group(分组):3. Services(服务):4. DataId(数据ID):5. 实战演示:5.1 默…...

26663-2011 大型液压安全联轴器 课堂随笔
声明 本文是学习GB-T 26663-2011 大型液压安全联轴器. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了大型液压安全联轴器的分类、技术要求、试验方法及检验规则等。 本标准适用于联接两同轴线的传动轴系,可起到限制…...
ChatGPT架构师:语言大模型的多模态能力、幻觉与研究经验
来源 | The Robot Brains Podcast OneFlow编译 翻译|宛子琳、杨婷 9月26日,OpenAI宣布ChatGPT新增了图片识别和语音能力,使得ChatGPT不仅可以进行文字交流,还可以给它展示图片并进行互动,这是一次ChatGPT向多模态进化的…...

二、VXLAN BGP EVPN基本原理
VXLAN BGP EVPN基本原理 1、BGP EVPN2、BGP EVPN路由2.1、Type2路由——MAC/IP路由2.2、Type3路由——Inclusive Multicast路由2.3、Type5路由——Inclusive Multicast路由 ————————————————————————————————————————————————…...

Evil.js
Evil.js install npm i lodash-utils什么?黑心996公司要让你体统跑路了? 想在离开前给你们的项目留点小礼物? 偷偷地把本项目引入你们的项目吧,你们的项目会有但不仅限于如下的神奇效果: 仅在周日时: 当…...
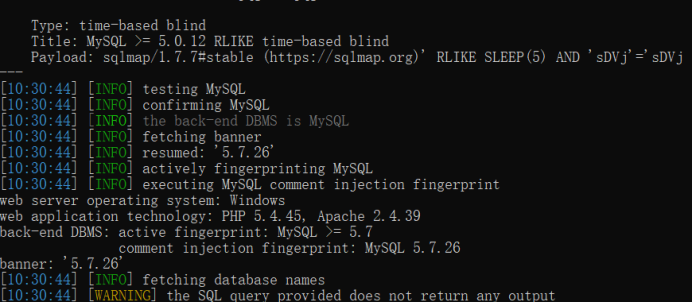
使用sqlmap的 ua注入
文章目录 1.使用sqlmap自带UA头的检测2.使用sqlmap随机提供的UA头3.使用自己写的UA头4.调整level检测 测试环境:bWAPP SQL Injection - Stored (User-Agent) 1.使用sqlmap自带UA头的检测 python sqlmap.py -u http://127.0.0.1:9004/sqli_17.php --cookie“BEEFHOO…...
华为云云耀云服务器L实例评测 | 实例评测使用之体验评测:华为云云耀云服务器管理、控制、访问评测
华为云云耀云服务器L实例评测 | 实例评测使用之体验评测:华为云云耀云服务器管理、控制、访问评测 介绍华为云云耀云服务器 华为云云耀云服务器 (目前已经全新升级为 华为云云耀云服务器L实例) 华为云云耀云服务器是什么华为云云耀…...

resultmap
自定义映射resultMap resultMap处理字段和属性的映射关系 若字段名和实体类中的属性名称不一致,则可以通过resultMap设置自定义映射 建moudel项目【实现多对一、一对多的表操作demo】 temp员工表、dept部门表 导入依赖【mysql驱动、junit、mybatis、日志依赖log4…...
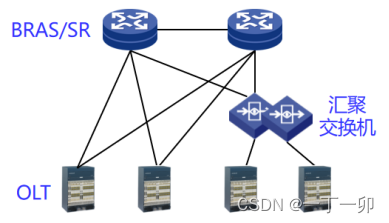
宽带光纤接入网中影响家宽业务质量的常见原因有哪些
1 引言 虽然家宽业务质量问题约60%发生在家庭网(见《家宽用户家庭网的主要质量问题是什么?原因有哪些》一文),但在用户的眼里,所有家宽业务质量问题都是由运营商的网络质量导致的,用户也因此对不同运营商家…...
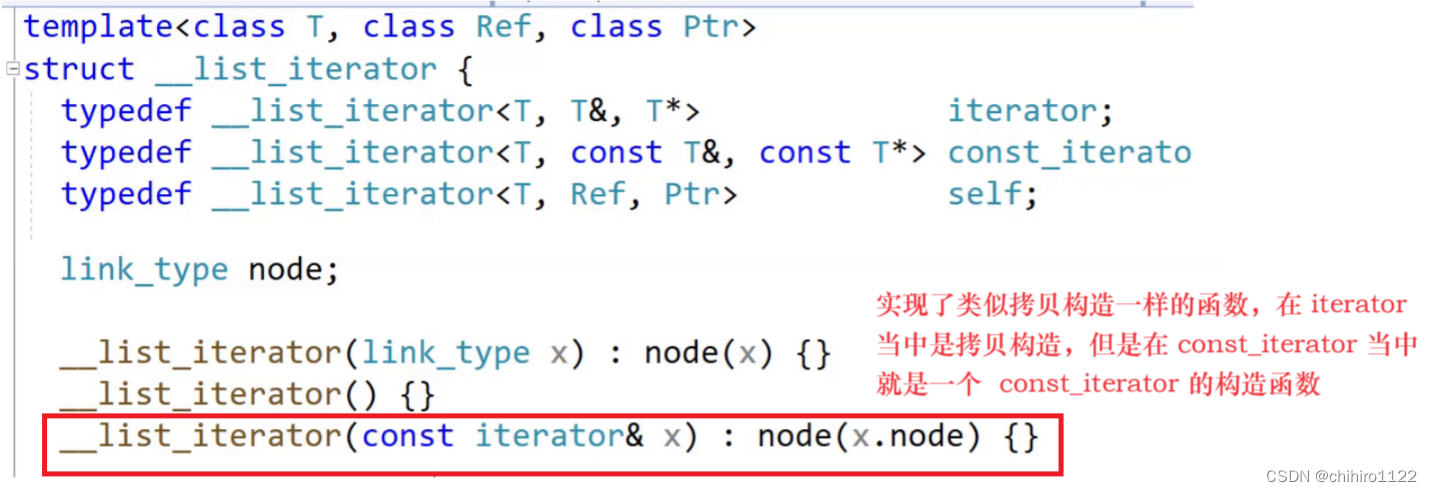
C++ - 封装 unordered_set 和 unordered_map - 哈希桶的迭代器实现
前言 unordered_set 和 unordered_map 两个容器的底层是哈希表实现的,此处的封装使用的 上篇博客当中的哈希桶来进行封装,相当于是在 哈希桶之上在套上了 unordered_set 和 unordered_map 。 哈希桶的逻辑实现: C - 开散列的拉链法&…...
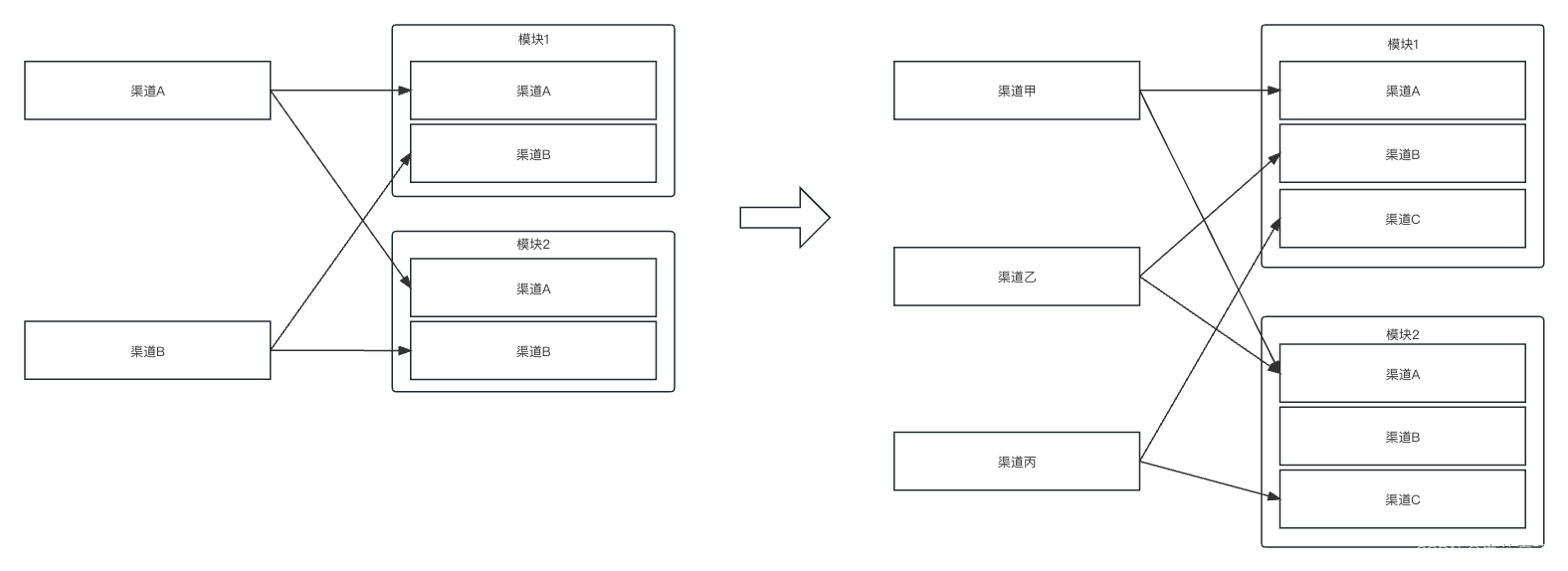
gradle中主模块/子模块渠道对应关系通过配置实现
前言: 我们开发过程中,经常会面对针对不同的渠道,要产生差异性代码和资源的场景。目前谷歌其实为我们提供了一套渠道包的方案,这里简单描述一下。 比如我主模块依赖module1和module2。如果主模块中声明了2个渠道A和B,…...

28383-2012 卷筒料凹版印刷机 学习笔记
声明 本文是学习GB-T 28383-2012 卷筒料凹版印刷机. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了卷筒料凹版印刷机的型式、基本参数、要求、试验方法、检验规则、标志、包装、运输与 贮存。 本标准适用于机组式的卷筒料凹版…...
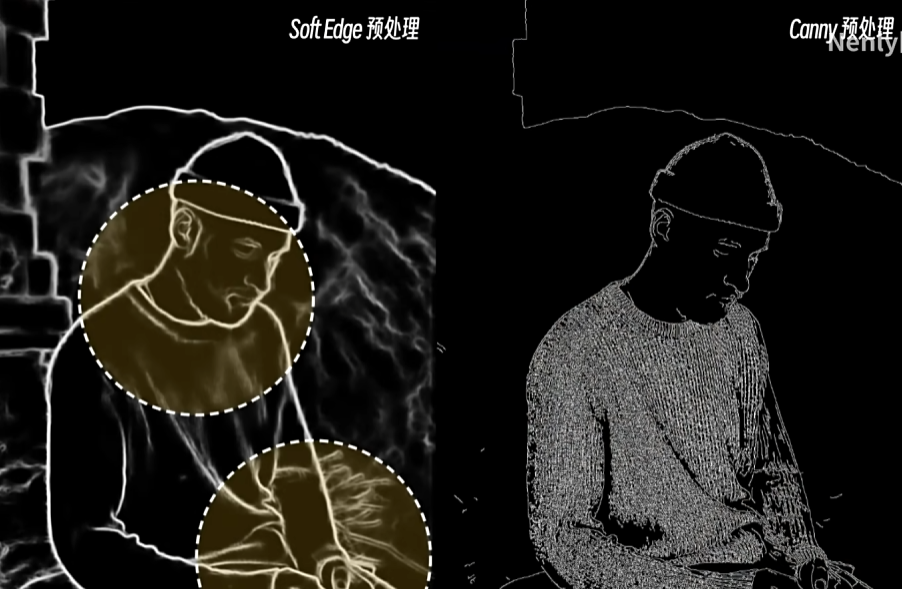
stable diffusion学习笔记【2023-10-2】
L1:界面 CFG Scale:提示词相关性 denoising:重绘幅度 L2:文生图 女性常用的负面词 nsfw,NSFW,(NSFW:2),legs apart, paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, (…...
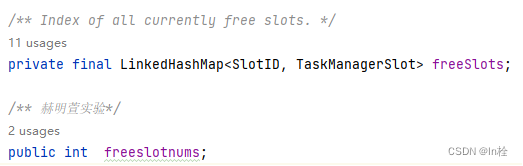
flink选择slot
flink选择slot 在这个类里修改 package org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerImpl; findMatchingSlot(resourceProfile):找到满足要求的slot(负责从哪个taskmanager中获取slot)对应上图第8,9&…...

世界前沿技术发展报告2023《世界信息技术发展报告》(六)网络与通信技术
(六)网络与通信技术 1. 概述2. 5G与光通讯2.1 美国研究人员利用电磁拓扑绝缘体使5G频谱带宽翻倍2.2 日本东京工业大学推出可接入5G网络的高频收发器2.3 美国得克萨斯农工大学通过波束管理改进5G毫米波通信2.4 联发科完成全球首次5G NTN卫星手机连线测试2…...
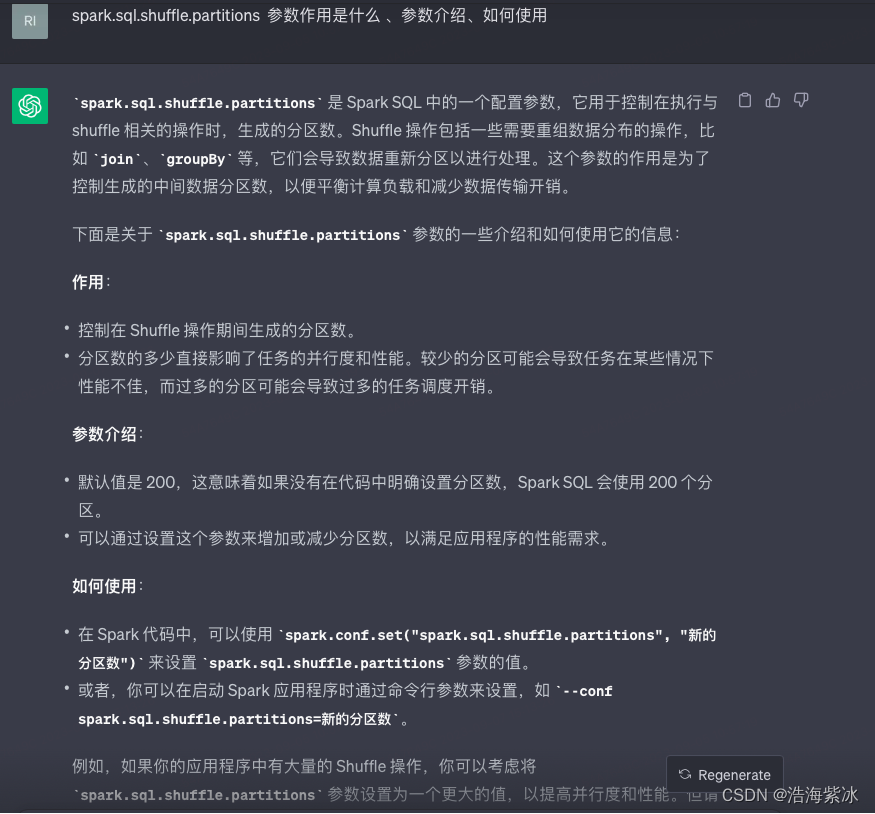
spark SQL 任务参数调优1
1.背景 要了解spark参数调优,首先需要清楚一部分背景资料Spark SQL的执行原理,方便理解各种参数对任务的具体影响。 一条SQL语句生成执行引擎可识别的程序,解析(Parser)、优化(Optimizer)、执行…...

算法练习2——移除元素
LeetCode 27 移除元素 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。 元素的顺序可以改变。你不需要考虑…...

Rspack
根据你提供的 package.json 中的 scripts 信息,这是一个使用 Rspack(字节跳动推出的基于 Rust 的高性能构建工具)而非传统的 Webpack/Vite 的 Vue 3 项目。要在 VS Code 中运行这个项目,请按照以下步骤操作:1. 准备工作…...

5分钟实战:用ArchivePasswordTestTool找回遗忘的压缩包密码
5分钟实战:用ArchivePasswordTestTool找回遗忘的压缩包密码 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经面对着一…...

文档站点生成器 - Sphinx
简介 Sphinx 是一个高度可扩展、功能丰富的文档生成工具,最初为 Python 官方文档开发,现已成为技术文档领域的事实标准。它支持从 reStructuredText 或 Markdown 源文件生成多种输出格式(HTML、PDF、ePub、LaTeX 等)。 核心特点 …...

Ultimate ASI Loader:Windows游戏模组安装的终极解决方案
Ultimate ASI Loader:Windows游戏模组安装的终极解决方案 【免费下载链接】Ultimate-ASI-Loader The Ultimate ASI Loader is a proxy DLL that loads custom .asi libraries into any game process. 项目地址: https://gitcode.com/gh_mirrors/ul/Ultimate-ASI-L…...

避坑指南:用ATGM336H模块做定位,为什么你的STM32总收不到有效数据?
ATGM336H模块实战:STM32开发者必知的GPS数据解析避坑指南 当你第一次将ATGM336H模块连接到STM32开发板时,满心期待能获取精准的经纬度坐标,却发现串口终端里只有一堆乱码或固定不变的字符串——这种挫败感我深有体会。作为一款支持北斗/GPS双…...

基于大语言模型的游戏AI助手:ChatGPT-On-CS项目实战解析
1. 项目概述:当ChatGPT遇上反恐精英如果你是一名《反恐精英》(Counter-Strike, 简称CS)的玩家,同时又对AI助手ChatGPT的强大能力有所耳闻,那么“ChatGPT-On-CS”这个项目可能会让你眼前一亮。简单来说&…...
)
告别手动查ID!用CAPL的GetMessageID/GetMessageName函数快速定位DBC报文(附实战代码)
告别手动查ID!用CAPL的GetMessageID/GetMessageName函数快速定位DBC报文(附实战代码) 在CANoe自动化测试开发中,处理DBC数据库报文是工程师们每天都要面对的常规操作。无论是编写测试脚本还是分析总线数据,快速准确地通…...

网易云QQ音乐歌词提取工具:零基础快速获取专业歌词的完整指南
网易云QQ音乐歌词提取工具:零基础快速获取专业歌词的完整指南 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 你是否曾为找不到心爱歌曲的歌词而烦恼…...

3个高效技巧:零门槛将VR视频转为普通设备可观看的2D格式
3个高效技巧:零门槛将VR视频转为普通设备可观看的2D格式 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址: https://gitcode.com/gh_…...

WzComparerR2完整指南:解密冒险岛WZ文件的终极工具
WzComparerR2完整指南:解密冒险岛WZ文件的终极工具 【免费下载链接】WzComparerR2 Maplestory online Extractor 项目地址: https://gitcode.com/gh_mirrors/wz/WzComparerR2 WzComparerR2是一款专门用于解析和提取《冒险岛》(MapleStory…...