ElasticSearch - 基于 拼音分词器 和 IK分词器 模拟实现“百度”搜索框自动补全功能
目录
一、自动补全
1.1、效果说明
1.2、安装拼音分词器
1.3、自定义分词器
1.3.1、为什么要自定义分词器
1.3.2、分词器的构成
1.3.3、自定义分词器
1.3.4、面临的问题和解决办法
问题
解决方案
1.4、completion suggester 查询
1.4.1、基本概念和语法
1.4.2、示例
1.4.3、示例(黑马旅游)
a)修改 hotel 索引库结构,设置自定义拼音分词器.
b)给 HotelDoc 类添加 suggestion 字段
c)将数据重新导入到 hotel 索引库中
d)基于 JavaRestClient 编写 DSL
1.5、黑马旅游案例
1.5.1、需求
1.5.2、前端对接
1.5.3、实现 controller
1.5.4、创建接口并实现.
1.5.5、效果展示
一、自动补全
1.1、效果说明
当用户在搜索框中输入字符时,我们应该提示出与该字符有关的搜索项.
例如百度中,输入关键词 "byby",他的效果如下:

1.2、安装拼音分词器
要实现根据字母补全,就需要对文档按照拼英分词. 在GitHub 上有一个 es 的拼英分词插件.
地址:GitHub - medcl/elasticsearch-analysis-pinyin: This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
这里的安装方式和 IK 分词器一样,分四步:
1. 安装解压.
![]()
2. 上传到云服务器中,es 的 plugin 目录.
3. 重启 es.

4. 测试.

这里可以看到,拼音分词器不光对每个字用拼音进行分词,还对每个字的首字母进行分词.
1.3、自定义分词器
1.3.1、为什么要自定义分词器
根据上述测试,可以看出.
1. 拼音分词器是将一句话中的每一个字都分成了拼音,这没什么实际的用处.
2. 这里并没有分出汉字,只有拼英. 实际的使用中,用户更多的是使用汉字去搜,有拼音只是锦上添花,但是也不能只用拼音分词器,把汉字丢了.
因此这里我们需要对拼音分词器进行一些自定义的配置.
1.3.2、分词器的构成
想要自定义分词器,首先要先了解 es 中分词器的构成.
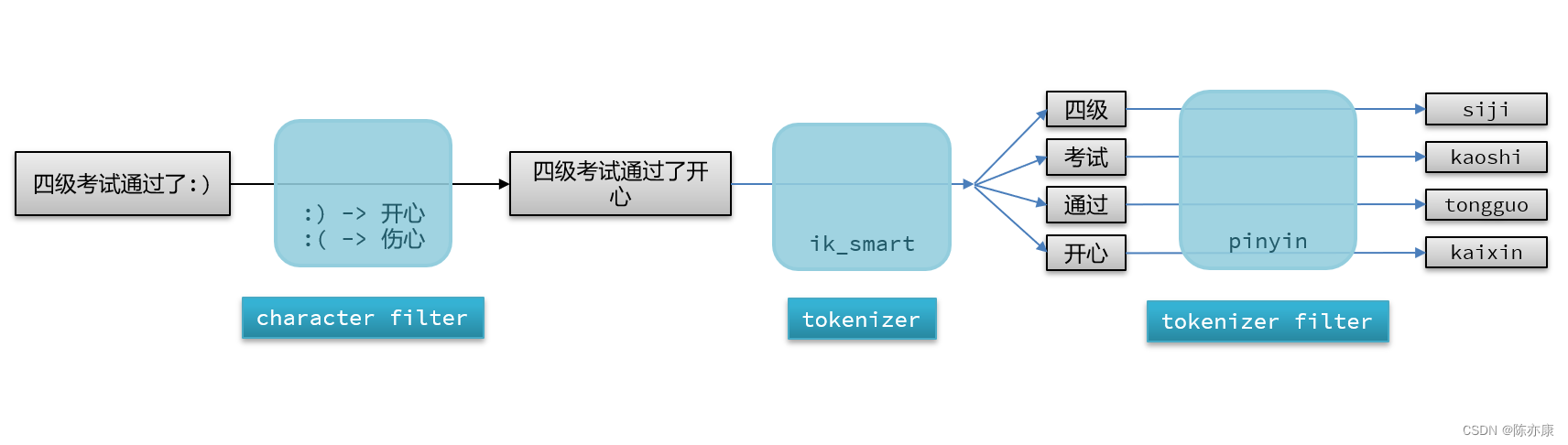
分词器主要由以下三个部分组成:
- character filters:在 tokenizer 之前,对文本的特殊字符进行处理. 比如他会把文本中出现的一些特殊字符转化成汉字,例如 :) => 开心.
- tokenizer:将文本按照一定的规则切割成词条(term). 例如 “我很开心” 会切割成 "我"、"很"、"开心".
- tokenizer filter:对 tokenizer 进一步处理. 例如将汉字转化成拼音.
1.3.3、自定义分词器
PUT /test
{"settings": {"analysis": {"analyzer": { //自定义分词器"my_analyzer": { //自定义分词器名称"tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": { "type": "pinyin","keep_full_pinyin": false, "keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}}
}- “type”: “pinyin”:指定使用拼音过滤器进行拼音转换。
- “keep_full_pinyin”: false:表示不保留完整的拼音。如果设置为true,则会将完整的拼音保留下来。
- “keep_joined_full_pinyin”: true:表示保留连接的完整拼音。当设置为true时,如果某个词的拼音有多个音节,那么它们将被连接在一起作为一个完整的拼音。
- “keep_original”: true:表示保留原始词汇。当设置为true时,原始的中文词汇也会保留在分词结果中。
- “limit_first_letter_length”: 16:限制拼音首字母的长度。默认为16,即只保留拼音首字母的前16个字符。
- “remove_duplicated_term”: true:表示移除重复的拼音词汇。如果设置为true,则会移除拼音结果中的重复词汇。
- “none_chinese_pinyin_tokenize”: false:表示是否对非中文文本进行拼音分词处理。当设置为false时,非中文文本将保留原样,不进行拼音分词处理
例如,创建一个 test 索引库,来测试自定义分词器.
PUT /test
{"settings": {"analysis": {"analyzer": { "my_analyzer": { "tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": { "type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer"}}}
}使用此索引库的分词器进行测试

从上图中可以看出:
1.不光有拼音,还有中文分词.
2.还有中文分词后的英文全拼,以及分词首字母.
1.3.4、面临的问题和解决办法
问题
上面实现的拼音分词器还不能应用到实际的生产环境中~
可以想象这样一个场景:
如果词库中有这两个词:“狮子” 和 “虱子”,那么也就意味着,创建倒排索引时,通过上述自定义的 拼音分词器 ,就会把这两个词归为一个文档,因为他们在分词的时候,会分出共同的拼音 "shizi" 和 "sz",这就导致他两的文档编号对应同一个词条,导致将来用户在搜索框里输入 “狮子” ,点击搜索之后,会同时搜索出 "狮子" 和 “虱子” ,这并不是我们想看到的.

解决方案
因此字段在创建倒排索引时因该使用 my_analyzer 分词器,但是字段在搜索时应该使用 ik_smart 分词器.
也就是说,用户输入中文的时候,就按中文去搜,用户输入拼音的时候,才按拼音去搜,即使出现上述情况,同时搜出这两个词,那你是按拼音搜,两个都是符合的,不存在歧义.
如下:
PUT /test
{"settings": {"analysis": {"analyzer": { "my_analyzer": { "tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": { "type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer" //创建倒排索引使用 my_analyzer 分词器."search_analyzer": "ik_smart" //搜索时使用 ik_smart 分词器.}}}
}1.4、completion suggester 查询
1.4.1、基本概念和语法
es 中提供了 completion suggester 查询来实现自动补全功能. 这个查询会匹配用户输入内容开头的词条并返回.
为了提高补全查询的效率,对于文档中的字段类型有一些约束,如下:
- 参与补全查询的字段必须是 completion 类型.
- 参与 自动补全字段 的内容一般是多个词条形成的数组.
POST /test2/_search
{"suggest": {"title_suggest": { //自定义补全名"text": "s", //用户在搜索框中输入的关键字"completion": { // completion 是自动补全中的一种类型(最常用的)"field": "补全时需要查询的字段名", //这里的字段名指向的是一个数组(字段必须是 completion 类型),就是要根据数组中的字段进行查询,然后自动补全"skip_duplicates": true, //如果查询时有重复的词条,是否自动跳过(true 为跳过)"size": 10 // 获取前 10 条结果.}}}
}
1.4.2、示例
这里我用一个示例来演示 completion suggester 的用法.
首先创建索引库(参与自动补全的字段类型必须是 completion).
PUT /test2
{"mappings": {"properties": {"title": {"type": "completion"}}}
}插入示例数据(字段内容一般是用来补全的多个词条形成的数组.)
POST test2/_doc
{"title": ["Sony", "WH-1000XM3"]
}
POST test2/_doc
{"title": ["SK-II", "PITERA"]
}
POST test2/_doc
{"title": ["Nintendo", "switch"]
}这里我们设置关键字为 "s",来自动补全查询,如下:
POST /test2/_search
{"suggest": {"title_suggest": {"text": "s", "completion": {"field": "title", "skip_duplicates": true, "size": 10}}}
}


1.4.3、示例(黑马旅游)
这里我们基于之前实现的黑马旅游案例来做栗子,实现步骤如下:
a)修改 hotel 索引库结构,设置自定义拼音分词器.
1.设置自定义分词器.
2. 修改索引库的 name、all 字段(建立倒排索引使用 拼音分词器,搜索时使用 ik 分词器).
3. 给索引库添加一个新字段 suggestion,类型为 completion 类型,使用自定义分词器.
PUT /hotel
{"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}}
}b)给 HotelDoc 类添加 suggestion 字段
suggestion 字段(包含多个字段的数组,这里可以使用 List 表示),内容包含 brand、business.
Ps:name、all 是可以分词的,自动补全的 brand、business 是不可分词的,要使用不同的分词器组合.
@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;private Object distance;private Boolean isAD;private List<String> suggestion;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();this.suggestion = new ArrayList<>();suggestion.add(brand);suggestion.add(business);}
}
c)将数据重新导入到 hotel 索引库中
将 hotel 索引库删了,然后重建(a 中的 DSL). 通过单元测试将所有信息从数据库同步到 es 上.
@Testpublic void testBulkDocument() throws IOException {//1.获取酒店所有数据List<Hotel> hotelList = hotelService.list();//2.构造请求BulkRequest request = new BulkRequest();//3.准备参数for(Hotel hotel : hotelList) {//转化为文档(主要是地理位置)HotelDoc hotelDoc = new HotelDoc(hotel);String json = objectMapper.writeValueAsString(hotelDoc);request.add(new IndexRequest("hotel").id(hotel.getId().toString()).source(json, XContentType.JSON));}//4.发送请求client.bulk(request, RequestOptions.DEFAULT);}
d)基于 JavaRestClient 编写 DSL
例如自动补全关键为 "h" 的内容.
@Testpublic void testSuggestion() throws IOException {//1.创建请求SearchRequest request = new SearchRequest("hotel");//2.准备参数request.source().suggest(new SuggestBuilder().addSuggestion("testSuggestion",SuggestBuilders.completionSuggestion("suggestion").prefix("h").skipDuplicates(true).size(10)));//3.发送请求,接收响应SearchResponse search = client.search(request, RequestOptions.DEFAULT);//4.解析响应handlerResponse(search);}
这里可以对应着 DSL 语句来写.

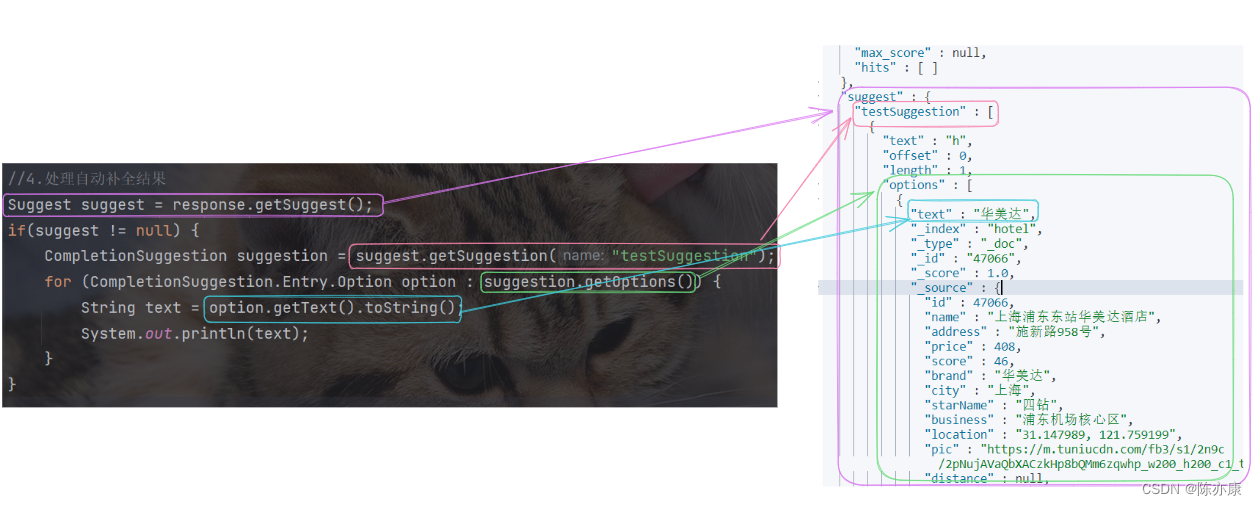
对查询结果的处理如下:
//4.处理自动补全结果Suggest suggest = response.getSuggest();if(suggest != null) {CompletionSuggestion suggestion = suggest.getSuggestion("testSuggestion");for (CompletionSuggestion.Entry.Option option : suggestion.getOptions()) {String text = option.getText().toString();System.out.println(text);}}
这里可以对应着 DSL 语句来写.
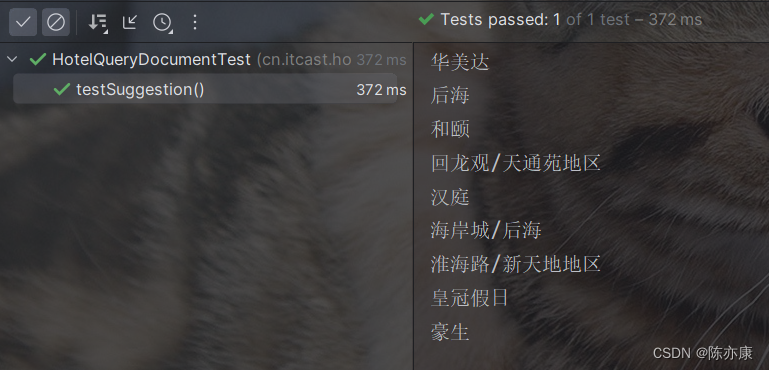
运行结果如下:
1.5、黑马旅游案例
1.5.1、需求
首先搜索框的自动补全功能.
最终实现效果就类似于 百度的搜索框,比如当我们输入 "byby",他就会立马自动补全出有关 byby 关键字的信息,如下图:

1.5.2、前端对接
在搜索框中输入,会触发以下请求. 这里前端就传入一个参数 key.
这里约定,返回的是一个 List,内容就是自动补全的所有信息.
1.5.3、实现 controller
这里使用 @RequestParam 接收前端传入的参数,然后调用 IhotelService 接口处理即可.
@RequestMapping("/suggestion")public List<String> suggestion(@RequestParam("key") String prefix) {return hotelService.suggestion(prefix);}
1.5.4、创建接口并实现.
在 IhotelService 接口中创建 suggestion 方法.
public interface IHotelService extends IService<Hotel> {PageResult search(RequestParams params);Map<String, List<String>> filters(RequestParams params);List<String> suggestion(String prefix);
}
接着在 IhotelService 的实现类 HotelService 中实现该方法.
具体的实现,就和前面写的测试案例基本一致了~ 要注意的点就是补全的关键字不是写死的,而是前端传入的 prefix.
@Overridepublic List<String> suggestion(String prefix) {try {//1.创建请求SearchRequest request = new SearchRequest("hotel");//2.准备参数request.source().suggest(new SuggestBuilder().addSuggestion("mySuggestion",SuggestBuilders.completionSuggestion("suggestion").prefix(prefix).skipDuplicates(true).size(10)));//3.发送请求,接收响应SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析响应(处理自动补全结果)Suggest suggest = response.getSuggest();List<String> suggestionList = new ArrayList<>();if(suggest != null) {CompletionSuggestion suggestion = suggest.getSuggestion("mySuggestion");for (CompletionSuggestion.Entry.Option option : suggestion.getOptions()) {String text = option.getText().toString();suggestionList.add(text);}}return suggestionList;} catch (IOException e) {System.out.println("[HotelService] 自动补全失败!prefix=" + prefix);e.printStackTrace();return null;}}
}
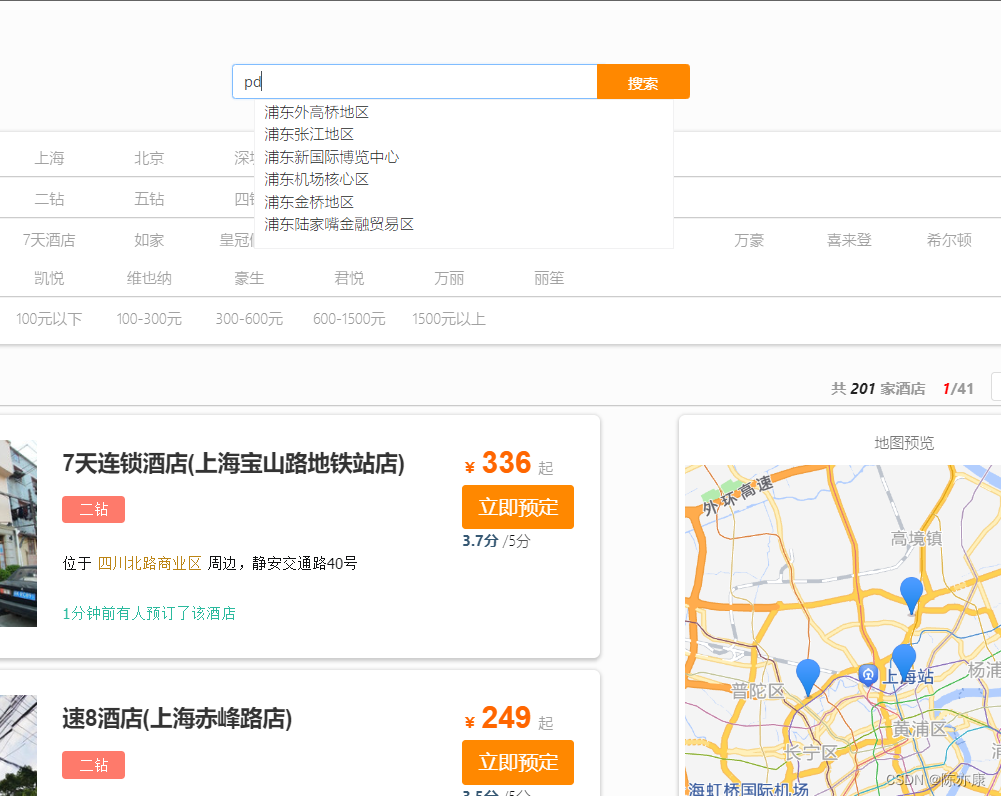
1.5.5、效果展示
输入关键词,即可出现自动补全.


相关文章:
ElasticSearch - 基于 拼音分词器 和 IK分词器 模拟实现“百度”搜索框自动补全功能
目录 一、自动补全 1.1、效果说明 1.2、安装拼音分词器 1.3、自定义分词器 1.3.1、为什么要自定义分词器 1.3.2、分词器的构成 1.3.3、自定义分词器 1.3.4、面临的问题和解决办法 问题 解决方案 1.4、completion suggester 查询 1.4.1、基本概念和语法 1.4.2、示例…...

【kubernetes】kubernetes中的调度
1 调度过程 调度的本来含义是指决定某个任务交给某人来做的过程,kubernetes中的调度是指决定Pod在哪个Node上运行。 k8s的调度分为2个过程: 预选:去掉不满足条件的节点优选:对剩下符合条件的节点按照一些策略进行排序ÿ…...

java读取csv文件或者java读取字符串,找出引号内容,采用正则表达式书写
将一个csv文件复制出来将后缀改变为txt,我们就得到了一个文件文件打开这个txt文件,可以看到每一个字段之间都是用英文逗号隔开 正常的内容形似 20,C4,Pm,tem,tion,21,A4,E,H,"1,2,3,NA,aaa,bbbb,cccc,ddd,N/A,aaa,bbbb,cccc,ddd,tttttt对于这种我们只需要进行…...

【寻找关键钥匙】python实现-附ChatGPT解析
1.题目 寻找关键钥匙 知识点字符串、编程基础、正则表达式、排序 时间限制:1s 空间限制: 256MB 限定语言:不限 题目描述: 小强正在参加《密室逃生》游戏,当前关卡要求找到符合给定 密码K(升序的不重复小写字母组成)的箱子,并给出箱子编号,箱子编号为1~N。 每个箱子中都有一个…...

基于 QT 实现一个 Ikun 专属桌面宠物
Step0、实现思路 想到的思路有两种: 1、使用 QT 的状态机模式,参考官网文档,这个模式的解耦最佳 2、使用原生 Wigets,将窗口设置为透明无框,循环播放桌面宠物的状态 本文采用第二种思路,实现一个极简版…...

新闻报道的未来:自动化新闻生成与爬虫技术
概述 自动化新闻生成是一种利用自然语言处理和机器学习技术,从结构化数据中提取信息并生成新闻文章的方法。它可以实现大规模、高效、多样的新闻内容生产。然而,要实现自动化新闻生成,首先需要获取可靠的数据源。这就需要使用爬虫技术&#…...
C++ 并发编程实战 第八章 设计并发代码 二
目录 8.3 设计数据结构以提升多线程程序的性能 8.3.1 针对复杂操作的数据划分 8.3.2 其他数据结构的访问模式 8.4 设计并发代码时要额外考虑的因素 8.4.1 并行算法代码中的异常安全 8.4.2 可扩展性和Amdahl定律 8.4.3 利用多线程隐藏等待行为 8.4.4 借并发特性改进响应…...

list(链表)
文章目录 功能迭代器的分类sort函数(排序)merage(归并)unique(去重)removesplice(转移) 功能 这里没有“[]"的实现;原因:实现较麻烦;这里使用迭代器来实…...

使用代理IP进行安全高效的竞争情报收集,为企业赢得竞争优势
在激烈的市场竞争中,知己知彼方能百战百胜。竞争对手的信息对于企业来说至关重要,它提供了洞察竞争环境和市场的窗口。在这个信息时代,代理IP是一种实用的工具,可以帮助企业收集竞争对手的产品信息和营销活动数据,为企…...

【数学知识】一些数学知识,以供学习
矩阵的特征值和特征向量 https://zhuanlan.zhihu.com/p/104980382 矩阵的逆 https://zhuanlan.zhihu.com/p/163748569 对数似然方程(log-likelihood equation),简称“似然方程”: https://baike.baidu.com/item/%E5%AF%B9%E6%95%B0%E4%BC%BC%E7%84%B6%E6%96%B9%E7…...

JKChangeCapture swift 版本的捕捉属性变化的工具
在OC的时代里,大家捕捉属性的变化通常是通过KVO机制来实现的,KVO把所有的属性变化都放在了一个方法进行相应处理,并不友好,之前基于KVO的机制实现了一套属性变化工具JKKVOHelper,这里不就在过多介绍这个了,在swift的时…...

RISC-V 指令
RISC-V指令都是32位长。 文章目录 R-Type指令格式:I-Type指令格式:S-Type指令格式:B-Type指令格式:U-Type指令格式:UJ-Type指令格式:J-Type指令格式:R4-Type指令格式:F-Type指令格式:vC-Type指令格式:CB-Type指令格式:CIW-Type指令格式:CL-Type指令格式:R-Type指…...
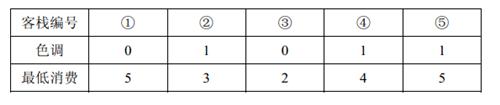
[NOIP2011 提高组] 选择客栈
[NOIP2011 提高组] 选择客栈 题目描述 丽江河边有 n n n 家很有特色的客栈,客栈按照其位置顺序从 1 1 1 到 n n n 编号。每家客栈都按照某一种色调进行装饰(总共 k k k 种,用整数 0 ∼ k − 1 0 \sim k-1 0∼k−1 表示)&am…...
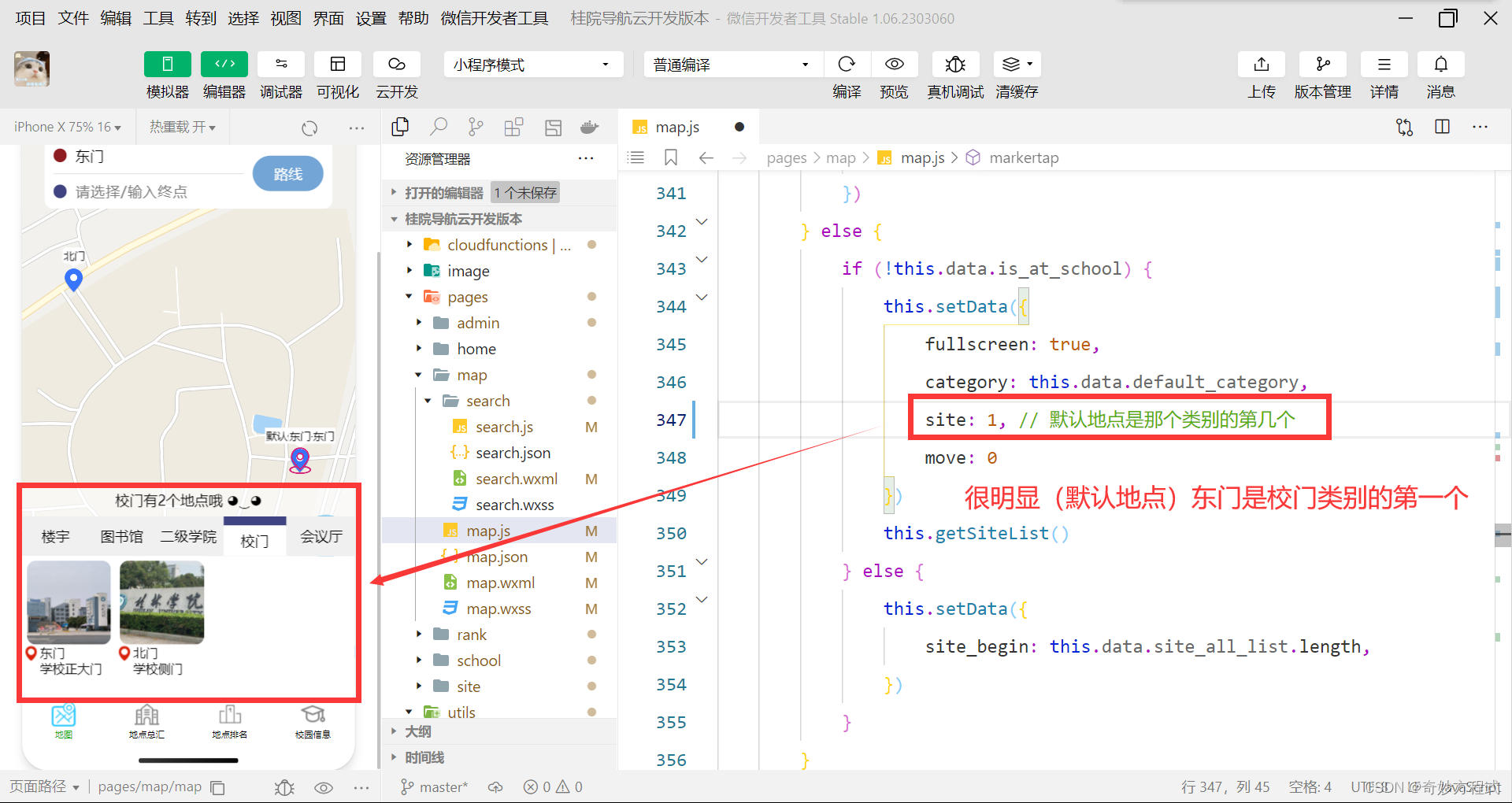
桂院校园导航 静态项目 二次开发教程 1.2
Gitee代码仓库:桂院校园导航小程序 GitHub代码仓库:GLU-Campus-Guide 先 假装 大伙都成功安装了静态项目,并能在 微信开发者工具 和 手机 上正确运行。 接着就是 将项目 改成自己的学校。 代码里的注释我就不说明了,有提到 我…...

private static final long serialVersionUID = 1L的作用是什么?
1.作用是什么? 当一个类被序列化后,存储在文件或通过网络传输时,这些序列化数据会包含该类的结构信息。当反序列化操作发生时,Java虚拟机会根据序列化数据中的结构信息来还原对象。 但是,如果在序列化之后,…...

leetCode 122.买卖股票的最佳时机 II 贪心算法
122. 买卖股票的最佳时机 II - 力扣(LeetCode) 给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。 在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买&…...

阿里云ACP知识点(三)
1、弹性伸缩不仅提供了在业务需求高峰或低谷时自动调节ECS实例数量的能力,而且提供了ECS实例上自动部署应用的能力。弹性伸缩的伸缩配置支持多种特性,例如______,帮助您高效、灵活地自定义ECS实例配置,满足业务需求。 标签、密钥对、 实例RAM…...

nmap 扫描内网IP, 系统, 端口
nmap 扫描内网IP, 系统, 端口 扫描内网ip 对内网进行ARP扫描 .\nmap.exe -sn 192.168.110.0/24 # 全网段 .\nmap.exe -sn 192.168.110.100-200 # 100-200范围 扫描端口 .\nmap.exe -sT 192.168.110.130 # 三次握手连接 较慢, 但更有效 .\nmap.exe -sS 192.168.110.130 # 发…...

Llama2-Chinese项目:4-量化模型
一.量化模型调用方式 下面是一个调用FlagAlpha/Llama2-Chinese-13b-Chat[1]的4bit压缩版本FlagAlpha/Llama2-Chinese-13b-Chat-4bit[2]的例子: from transformers import AutoTokenizer from auto_gptq import AutoGPTQForCausalLM model AutoGPTQForCausalLM…...
【深度学习实验】卷积神经网络(六):自定义卷积神经网络模型(VGG)实现图片多分类任务
目录 一、实验介绍 二、实验环境 1. 配置虚拟环境 2. 库版本介绍 三、实验内容 0. 导入必要的工具包 1. 构建数据集(CIFAR10Dataset) a. read_csv_labels() b. CIFAR10Dataset 2. 构建模型(FeedForward&…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...