如何使用nuScenes数据集格式的单帧数据推理(以DETR3D为例)
【请尊重原创!转载和引用文章内容务必注明出处!未经许可上传到某文库或其他收费阅读/下载网站赚钱的必追究责任!】
无论是mmdetection3D还是OpenPCDet都只有使用数据集(使用哪个数据集由配置文件里指定)训练和测试的代码,没有使用某种数据集格式的单帧数据进行推理的代码(也就是一些2D目标检测框里里提供的推理demo代码),而OpenPCDet尤其是mmdetection里面为了支持多种不同的数据集和多种不同模型的训练和测试,把很多实现步骤高度配置化,这是好事也是坏事,如果你只是使用这些框架(尤其是使用它们已支持的公开数据集)进行训练和测试,那么相对简单,如果是要使用这些框架对单帧数据(可以是他们支持的公开数据集里的数据或者遵循这些数据集的格式自己制作的数据集的数据)进行推理,就比较复杂了,框架没有提供工具代码只能自己去写,写之前当然得把框架的相关代码翻看几遍把支持某个数据集和模型的配置文件和分散在多处的代码的逻辑理顺连贯起来,不然没法下手,因为框架高度配置化的话相关的代码就会非常分散在连贯性可读性方面很差,需要花时间先理清楚,然后把那些配置化的相关零散代码都整理并修改和串联起来,完成数据的多步预处理、调用模型推理、对推理结果的解析和后处理的全部流程的实现。
用nuScense格式数据调用detr3d模型的一个最烦的地方就是,你在调用模型推理时非得提供对应的img_metas数据,模型的这个设计我觉得不是很合理,起码不算友好,对于硬件和相关标定参数定了后,这种参数完全可以通过配置隐式提供给模型,为何每次调用都得提供这些meta参数呢!反正我写下面的推理代码之前是浪费了不少时间在厘清img_metas这个参数的数据该怎么准备上!
此处已DETR3D最初的官方实现代码GitHub - WangYueFt/detr3d基础给出了相关数据预处理和模型调用及推理结果后处理等代码,另外,这些代码是用于在ROS2节点中运行,解析出的推理结果还按项目实际要求转换成autoware的ObjectDetection数据格式后发布,所以还包含了ROS2和autoware相关的代码,这些代码不是重点仅供做代码逻辑完整性展示。当然,如果你项目中有类似需要的话,可以直接拷贝使用这些代码。
import rclpy
from rclpy.node import Node
from rclpy.executors import MultiThreadedExecutor
from rclpy.callback_groups import MutuallyExclusiveCallbackGroup, ReentrantCallbackGroupfrom cv_bridge import CvBridge
from sensor_msgs.msg import CompressedImage, Image
from std_msgs.msg import String
from autoware_auto_perception_msgs.msg import DetectedObjects
from autoware_auto_perception_msgs.msg import DetectedObject
from autoware_auto_perception_msgs.msg import ObjectClassification
from autoware_auto_perception_msgs.msg import DetectedObjectKinematics
from autoware_auto_perception_msgs.msg import Shapeimport numpy as np
import mmcv
import sys, os
import torch
import warnings
from mmcv import Config, DictAction
from mmcv.cnn import fuse_conv_bn
from mmcv.parallel import MMDataParallel, MMDistributedDataParallel
from mmcv.runner import (get_dist_info, init_dist, load_checkpoint,wrap_fp16_model)from mmdet3d.models import build_model
from mmdet.apis import multi_gpu_test, set_random_seed
from mmdet.datasets import replace_ImageToTensor
from mmdet3d.core.bbox.structures.box_3d_mode import (Box3DMode, CameraInstance3DBoxes,DepthInstance3DBoxes, LiDARInstance3DBoxes)from nuscenes import NuScenes
from pyquaternion import Quaternion
from geometry_msgs.msg import Point
from geometry_msgs.msg import Vector3
from trimesh.transformations import quaternion_from_euler
from geometry_msgs.msg import Quaternion as GeoQuaternion
from geometry_msgs.msg import Twist
import math
import timeclass DetectionPublisher(Node):def __init__(self):super().__init__('DetectionPublisher_python')self.publisher_ = self.create_publisher(String, 'example_topic', 10)timer_period = 0.5 # secondsself.timer = self.create_timer(timer_period, self.timer_callback)self.i = 0def timer_callback(self):msg = String()msg.data = 'Hello World: %d' % self.iself.publisher_.publish(msg)self.get_logger().info('Publishing: "%s"' % msg.data)self.i += 1class PadMultiViewImage(object):"""Pad the multi-view image.There are two padding modes: (1) pad to a fixed size and (2) pad to theminimum size that is divisible by some number.Added keys are "pad_shape", "pad_fixed_size", "pad_size_divisor",Args:size (tuple, optional): Fixed padding size.size_divisor (int, optional): The divisor of padded size.pad_val (float, optional): Padding value, 0 by default."""def __init__(self, size=None, size_divisor=32, pad_val=0):self.size = sizeself.size_divisor = size_divisorself.pad_val = pad_val# only one of size and size_divisor should be validassert size is not None or size_divisor is not Noneassert size is None or size_divisor is Nonedef _pad_img(self, results):"""Pad images according to ``self.size``."""if self.size is not None:padded_img = [mmcv.impad(img, shape=self.size, pad_val=self.pad_val) for img in results['img']]elif self.size_divisor is not None:padded_img = [mmcv.impad_to_multiple(img, self.size_divisor, pad_val=self.pad_val) for img in results['img']]results['img'] = padded_imgresults['img_shape'] = [img.shape for img in padded_img]results['pad_shape'] = [img.shape for img in padded_img]results['pad_fixed_size'] = self.sizeresults['pad_size_divisor'] = self.size_divisordef __call__(self, results):"""Call function to pad images, masks, semantic segmentation maps.Args:results (dict): Result dict from loading pipeline.Returns:dict: Updated result dict."""self._pad_img(results)return resultsdef __repr__(self):repr_str = self.__class__.__name__repr_str += f'(size={self.size}, 'repr_str += f'size_divisor={self.size_divisor}, 'repr_str += f'pad_val={self.pad_val})'return repr_strclass NormalizeMultiviewImage(object):"""Normalize the image.Added key is "img_norm_cfg".Args:mean (sequence): Mean values of 3 channels.std (sequence): Std values of 3 channels.to_rgb (bool): Whether to convert the image from BGR to RGB,default is true."""def __init__(self, mean=[103.530, 116.280, 123.675], std=[1.0, 1.0, 1.0], to_rgb=True):self.mean = np.array(mean, dtype=np.float32)self.std = np.array(std, dtype=np.float32)self.to_rgb = to_rgbdef __call__(self, results):"""Call function to normalize images.Args:results (dict): Result dict from loading pipeline.Returns:dict: Normalized results, 'img_norm_cfg' key is added intoresult dict."""results['img'] = [mmcv.imnormalize(img, self.mean, self.std, self.to_rgb) for img in results['img']]results['img_norm_cfg'] = dict(mean=self.mean, std=self.std, to_rgb=self.to_rgb)return resultsdef __repr__(self):repr_str = self.__class__.__name__repr_str += f'(mean={self.mean}, std={self.std}, to_rgb={self.to_rgb})'return repr_strclass LoadSingleViewImageFromFiles(object):"""Load multi channel images from a list of separate channel files.Expects results['img_filename'] to be a list of filenames.Args:to_float32 (bool): Whether to convert the img to float32.Defaults to False.color_type (str): Color type of the file. Defaults to 'unchanged'."""def __init__(self, to_float32=True, color_type='unchanged'):self.to_float32 = to_float32self.color_type = color_typedef __call__(self, results):"""Call function to load multi-view image from files.Args:results (dict): Result dict containing multi-view image filenames.Returns:dict: The result dict containing the multi-view image data. \Added keys and values are described below.- filename (str): Multi-view image filenames.- img (np.ndarray): Multi-view image arrays.- img_shape (tuple[int]): Shape of multi-view image arrays.- ori_shape (tuple[int]): Shape of original image arrays.- pad_shape (tuple[int]): Shape of padded image arrays.- scale_factor (float): Scale factor.- img_norm_cfg (dict): Normalization configuration of images."""results['filename'] = 'sample.jpg'# h,w,c => h, w, c, nv img = np.stack([results['img']], axis=-1)if self.to_float32:img = img.astype(np.float32)results['img'] = [img[..., i] for i in range(img.shape[-1])]results['img_shape'] = img.shaperesults['ori_shape'] = img.shape# Set initial values for default meta_keysresults['pad_shape'] = img.shaperesults['scale_factor'] = 1.0num_channels = 1 if len(img.shape) < 3 else img.shape[2]results['img_norm_cfg'] = dict(mean=np.zeros(num_channels, dtype=np.float32),std=np.ones(num_channels, dtype=np.float32),to_rgb=False)return resultsdef __repr__(self):"""str: Return a string that describes the module."""repr_str = self.__class__.__name__repr_str += f'(to_float32={self.to_float32}, 'repr_str += f"color_type='{self.color_type}')"return repr_strdef obtain_sensor2top(nusc,sensor_token,l2e_t,l2e_r_mat,e2g_t,e2g_r_mat,sensor_type='lidar'):"""Obtain the info with RT matric from general sensor to Top LiDAR.Args:nusc (class): Dataset class in the nuScenes dataset.sensor_token (str): Sample data token corresponding to thespecific sensor type.l2e_t (np.ndarray): Translation from lidar to ego in shape (1, 3).l2e_r_mat (np.ndarray): Rotation matrix from lidar to egoin shape (3, 3).e2g_t (np.ndarray): Translation from ego to global in shape (1, 3).e2g_r_mat (np.ndarray): Rotation matrix from ego to globalin shape (3, 3).sensor_type (str, optional): Sensor to calibrate. Default: 'lidar'.Returns:sweep (dict): Sweep information after transformation."""sd_rec = nusc.get('sample_data', sensor_token)cs_record = nusc.get('calibrated_sensor',sd_rec['calibrated_sensor_token'])pose_record = nusc.get('ego_pose', sd_rec['ego_pose_token'])data_path = str(nusc.get_sample_data_path(sd_rec['token']))if os.getcwd() in data_path: # path from lyftdataset is absolute pathdata_path = data_path.split(f'{os.getcwd()}/')[-1] # relative pathsweep = {'data_path': data_path,'type': sensor_type,'sample_data_token': sd_rec['token'],'sensor2ego_translation': cs_record['translation'],'sensor2ego_rotation': cs_record['rotation'],'ego2global_translation': pose_record['translation'],'ego2global_rotation': pose_record['rotation'],'timestamp': sd_rec['timestamp']}l2e_r_s = sweep['sensor2ego_rotation']l2e_t_s = sweep['sensor2ego_translation']e2g_r_s = sweep['ego2global_rotation']e2g_t_s = sweep['ego2global_translation']# obtain the RT from sensor to Top LiDAR# sweep->ego->global->ego'->lidarl2e_r_s_mat = Quaternion(l2e_r_s).rotation_matrixe2g_r_s_mat = Quaternion(e2g_r_s).rotation_matrixR = (l2e_r_s_mat.T @ e2g_r_s_mat.T) @ (np.linalg.inv(e2g_r_mat).T @ np.linalg.inv(l2e_r_mat).T)T = (l2e_t_s @ e2g_r_s_mat.T + e2g_t_s) @ (np.linalg.inv(e2g_r_mat).T @ np.linalg.inv(l2e_r_mat).T)T -= e2g_t @ (np.linalg.inv(e2g_r_mat).T @ np.linalg.inv(l2e_r_mat).T) + l2e_t @ np.linalg.inv(l2e_r_mat).Tsweep['sensor2lidar_rotation'] = R.T # points @ R.T + Tsweep['sensor2lidar_translation'] = Treturn sweepdef getSemanticType(class_name):if (class_name == "CAR" or class_name == "Car"):return ObjectClassification.CARelif (class_name == "TRUCK" or class_name == "Medium_Truck" or class_name =="Big_Truck"):return ObjectClassification.TRUCKelif (class_name == "BUS"):return ObjectClassification.BUSelif (class_name == "TRAILER"):return ObjectClassification.TRAILERelif (class_name == "BICYCLE"):return ObjectClassification.BICYCLEelif (class_name == "MOTORBIKE"):return ObjectClassification.MOTORCYCLEelif (class_name == "PEDESTRIAN" or class_name == "Pedestrian"):return ObjectClassification.PEDESTRIANelse: return ObjectClassification.UNKNOWNclass CustomBox3D(object):def __init__(self,nid,score,x,y,z,w,l,h,rt,vel_x,vel_y):self.id = nidself.score = scoreself.x = xself.y = yself.z = zself.w = wself.l = lself.h = hself.rt = rtself.vel_x = vel_xself.vel_y = vel_ydef isCarLikeVehicle(label):return label == ObjectClassification.BICYCLE or label == ObjectClassification.BUS or \label == ObjectClassification.CAR or label == ObjectClassification.MOTORCYCLE or \label == ObjectClassification.TRAILER or label == ObjectClassification.TRUCK def createPoint(x, y, z):p = Point()p.x = float(x)p.y = float(y)p.z = float(z)return pdef createQuaternionFromYaw(yaw):# tf2.Quaternion# q.setRPY(0, 0, yaw)q = quaternion_from_euler(0, 0, yaw)# geometry_msgs.msg.Quaternion#return tf2.toMsg(q)#return GeoQuaternion(*q)return GeoQuaternion(x=q[0],y=q[1],z=q[2],w=q[3])def createTranslation(x, y, z):v = Vector3()v.x = float(x)v.y = float(y)v.z = float(z)return vdef box3DToDetectedObject(box3d, class_names, has_twist, is_sign):obj = DetectedObject()obj.existence_probability = float(box3d.score)classification = ObjectClassification()classification.probability = 1.0if (box3d.id >= 0 and box3d.id < len(class_names)):classification.label = getSemanticType(class_names[box3d.id])else: if is_sign:sign_label = 255classification.label = sign_labelelse:classification.label = ObjectClassification.UNKNOWNprint("Unexpected label: UNKNOWN is set.")if (isCarLikeVehicle(classification.label)):obj.kinematics.orientation_availability = DetectedObjectKinematics.SIGN_UNKNOWNobj.classification.append(classification)# pose and shape# mmdet3d yaw format to ros yaw formatyaw = -box3d.rt - np.pi / 2obj.kinematics.pose_with_covariance.pose.position = createPoint(box3d.x, box3d.y, box3d.z)obj.kinematics.pose_with_covariance.pose.orientation = createQuaternionFromYaw(yaw)obj.shape.type = Shape.BOUNDING_BOXobj.shape.dimensions = createTranslation(box3d.l, box3d.w, box3d.h)# twistif (has_twist):vel_x = float(box3d.vel_x)vel_y = float(box3d.vel_y)twist = Twist()twist.linear.x = math.sqrt(pow(vel_x, 2) + pow(vel_y, 2))twist.angular.z = 2 * (math.atan2(vel_y, vel_x) - yaw)obj.kinematics.twist_with_covariance.twist = twistobj.kinematics.has_twist = has_twistreturn obj class ImageSubscriber(Node):def __init__(self):super().__init__('ImageSubscriber_python')cb_group = MutuallyExclusiveCallbackGroup()self.img_sub = self.create_subscription(CompressedImage,'pub_image/compressed',self.image_callback,10,callback_group=cb_group)self.img_subself.od_pub = self.create_publisher(DetectedObjects, 'pub_detection', 10)self.cvBridge = CvBridge()self.pad = PadMultiViewImage()self.norm = NormalizeMultiviewImage()self.file_loader = LoadSingleViewImageFromFiles() config_path = "./detr3d_res101_gridmask_wst.py"self.cfg = Config.fromfile(config_path)if self.cfg.get('custom_imports', None):from mmcv.utils import import_modules_from_stringsimport_modules_from_strings(**self.cfg['custom_imports'])if hasattr(self.cfg, 'plugin'):if self.cfg.plugin:import importlibif hasattr(self.cfg, 'plugin_dir'):plugin_dir = self.cfg.plugin_dir_module_dir = os.path.dirname(plugin_dir)_module_dir = _module_dir.split('/')_module_path = _module_dir[0]for m in _module_dir[1:]:_module_path = _module_path + '.' + mprint(_module_path)print(sys.path)plg_lib = importlib.import_module(_module_path)if self.cfg.get('cudnn_benchmark', False):torch.backends.cudnn.benchmark = Trueself.cfg.model.pretrained = Noneself.cfg.model.train_cfg = Noneself.model = build_model(self.cfg.model, test_cfg=self.cfg.get('test_cfg'))fp16_cfg = self.cfg.get('fp16', None)if fp16_cfg is not None:wrap_fp16_model(self.model)checkpoint = load_checkpoint(self.model, "epoch_200.pth", map_location='cpu')if 'CLASSES' in checkpoint.get('meta', {}):self.model.CLASSES = checkpoint['meta']['CLASSES']else:self.model.CLASSS = ('car', 'truck', 'trailer', 'bus', 'construction_vehicle','bicycle', 'motorcycle', 'pedestrian', 'traffic_cone','barrier')# palette for visualization in segmentation tasksif 'PALETTE' in checkpoint.get('meta', {}):self.model.PALETTE = checkpoint['meta']['PALETTE']self.model.cfg = self.cfg self.model.cuda()self.model.eval()#if torch.cuda.device_count() > 1: # for server side# self.model = nn.DataParallel(self.model)print("model is created!")nusc = NuScenes(version='v1.0-mini', dataroot='nuscenes_mini', verbose=True)scene0 = nusc.scene[0]first_sample_token = scene0['first_sample_token']first_sample = nusc.get('sample', first_sample_token)sd_rec = nusc.get('sample_data', first_sample['data']['LIDAR_TOP'])cs_record = nusc.get('calibrated_sensor',sd_rec['calibrated_sensor_token'])pose_record = nusc.get('ego_pose', sd_rec['ego_pose_token'])lidar_token = first_sample['data']['LIDAR_TOP']lidar_path, boxes, _ = nusc.get_sample_data(lidar_token)info = {'lidar_path': lidar_path,'token': first_sample['token'],'sweeps': [],'cams': dict(),'lidar2ego_translation': cs_record['translation'],'lidar2ego_rotation': cs_record['rotation'],'ego2global_translation': pose_record['translation'],'ego2global_rotation': pose_record['rotation'],'timestamp': first_sample['timestamp'],}l2e_r = info['lidar2ego_rotation']l2e_t = info['lidar2ego_translation']e2g_r = info['ego2global_rotation']e2g_t = info['ego2global_translation']l2e_r_mat = Quaternion(l2e_r).rotation_matrixe2g_r_mat = Quaternion(e2g_r).rotation_matrixcamera_types = ['CAM_FRONT','CAM_FRONT_RIGHT','CAM_FRONT_LEFT','CAM_BACK','CAM_BACK_LEFT','CAM_BACK_RIGHT',]for cam in camera_types:cam_token = first_sample['data'][cam]cam_path, _, cam_intrinsic = nusc.get_sample_data(cam_token)cam_info = obtain_sensor2top(nusc, cam_token, l2e_t, l2e_r_mat,e2g_t, e2g_r_mat, cam)cam_info.update(cam_intrinsic=cam_intrinsic)info['cams'].update({cam: cam_info})'''cam_front_sample_data = nusc.get('sample_data', first_sample['data']['CAM_FRONT'])cam_front_sample_path = os.path.join(nusc.dataroot, cam_front_sample_data['filename'])print("sample image file:", cam_front_sample_path)cam_front_calibrate = nusc.get('calibrated_sensor', cam_front_sample_data['calibrated_sensor_token'])sensor2lidar = translation = np.expand_dims(np.array(cam_front_calibrate['translation']), axis=-1)sensor2lidar_rotation = np.expand_dims(np.array(cam_front_calibrate['rotation']), axis=-1)camera_intrinsic = np.array(cam_front_calibrate['camera_intrinsic'])'''image_paths = []lidar2img_rts = []lidar2cam_rts = []cam_intrinsics = []for cam_type, cam_info in info['cams'].items():image_paths.append(cam_info['data_path'])# obtain lidar to image transformation matrixlidar2cam_r = np.linalg.inv(cam_info['sensor2lidar_rotation'])lidar2cam_t = cam_info['sensor2lidar_translation'] @ lidar2cam_r.Tlidar2cam_rt = np.eye(4)lidar2cam_rt[:3, :3] = lidar2cam_r.Tlidar2cam_rt[3, :3] = -lidar2cam_tintrinsic = cam_info['cam_intrinsic']viewpad = np.eye(4)viewpad[:intrinsic.shape[0], :intrinsic.shape[1]] = intrinsiclidar2img_rt = (viewpad @ lidar2cam_rt.T)lidar2img_rts.append(lidar2img_rt)cam_intrinsics.append(viewpad)lidar2cam_rts.append(lidar2cam_rt.T)self.img_metas = {}self.img_metas.update(dict(img_filename=image_paths,lidar2img=lidar2img_rts,cam_intrinsic=cam_intrinsics,lidar2cam=lidar2cam_rts,))self.class_names_ = self.cfg.class_namesprint("ImageSubscriber init done")def image_callback(self, msg):#image = self.cvBridge.imgmsg_to_cv2(msg, "bgr8")image = self.cvBridge.compressed_imgmsg_to_cv2(msg, "bgr8")#print("image received, shape:", image.shape)results = {'img': image}self.file_loader(results)self.norm(results)self.pad(results)image = results['img'][0]meta = {'filename': results['filename'], 'img_shape': results['img_shape'],'ori_shape': results['ori_shape'],'pad_shape': results['pad_shape'],'scale_factor': results['scale_factor'],'box_type_3d': LiDARInstance3DBoxes, #CameraInstance3DBoxes/LiDARInstance3DBoxes'box_mode_3d': Box3DMode.LIDAR}meta.update(self.img_metas)#print("meta:", meta)img_metas = [[meta]]inputs = torch.tensor(image).to('cuda')# h,w,c => bs,nv,c,h,winputs = inputs.permute(2,0,1)inputs = torch.unsqueeze(inputs, 0)inputs = torch.unsqueeze(inputs, 0)#print("input tensor shape:", inputs.shape)with torch.no_grad():outputs = self.model(return_loss=False, rescale=True, img=inputs, img_metas=img_metas) torch.cuda.synchronize()pts_bbox = outputs[0]['pts_bbox']boxes_3d_enc = pts_bbox['boxes_3d']scores_3d = pts_bbox['scores_3d']labels_3d = pts_bbox['labels_3d']filter = scores_3d >= 0.5boxes_3d_enc.tensor = boxes_3d_enc.tensor[filter]boxes_3d = boxes_3d_enc.tensor.numpy() # [[cx, cy, cz, w, l, h, rot, vx, vy]]scores_3d = scores_3d[filter].numpy()labels_3d = labels_3d[filter].numpy()custom_boxes_3d = []for i, box_3d in enumerate(boxes_3d):box3d = CustomBox3D(labels_3d[i], scores_3d[i],box_3d[0],box_3d[1],box_3d[2],box_3d[3],box_3d[4],box_3d[5],box_3d[6],box_3d[7],box_3d[8])custom_boxes_3d.append(box3d)#print("boxes_3d", boxes_3d)#print("scores_3d", scores_3d)#print("labels_3d", labels_3d)output_msg = DetectedObjects()obj_num = len(boxes_3d)for i, box3d in enumerate(custom_boxes_3d):obj = box3DToDetectedObject(box3d, self.class_names_, True, False);output_msg.objects.append(obj)output_msg.header.stamp = self.get_clock().now().to_msg() #rclpy.time.Time()output_msg.header.frame_id = "base_link"self.od_pub.publish(output_msg)print(obj_num, "Objects published")def main(args=None):rclpy.init(args=args)sys.path.append(os.getcwd())image_subscriber = ImageSubscriber()executor = MultiThreadedExecutor()executor.add_node(image_subscriber)executor.spin()image_subscriber.destroy_node()detection_publisher.destroy_node()rclpy.shutdown()if __name__ == '__main__':main()这里说的单帧数据可以是单张图片或者nuScenes格式的6张环视图片,之所以说一帧,是对应点云的概念,实际做3D目标检测尤其是雷视融合推理时一般都是以点云帧的频率为时间单位进行推理(在获取一帧点云的同时获取一张或多张图片(取决于有几个摄像头),前融合的话是将点云和图像的数据做数据融合后输入模型或直接输入模型由模型内部抽取特征做特征融合,后融合的话是将点云和图像分别输入不同的模型推理,再对模型各自的结果进行融合处理)。
上面的代码由于是以DETR3D官方代码为基础的,所以和mmdetection3D后来集成DETR3D的实现代码不同,对比两者代码可以发现,mmdetection3D将DETR3D官方代码里的一些数据预处理环节的实现代码都移走了,在模型内部单独提供了一个Det3DDataPreprocessor类来进行一些公共处理,总体的配置文件和实现思路还是比较类似,毕竟DETR3D官方是在mmdetection3D的早期版本基础上开发的,例如两者的detr3d_r101_gridmask.py配置文件里面有些配置不同,但是思路是相似的:
mmdetection3d/projects/DETR3D/configs/detr3d_r101_gridmask.py
model = dict(type='DETR3D',use_grid_mask=True,data_preprocessor=dict(type='Det3DDataPreprocessor', **img_norm_cfg, pad_size_divisor=32),img_backbone=dict(type='mmdet.ResNet',depth=101,num_stages=4,out_indices=(0, 1, 2, 3),frozen_stages=1,norm_cfg=dict(type='BN2d', requires_grad=False),norm_eval=True,style='caffe',dcn=dict(type='DCNv2', deform_groups=1, fallback_on_stride=False),stage_with_dcn=(False, False, True, True)),img_neck=dict(type='mmdet.FPN',in_channels=[256, 512, 1024, 2048],out_channels=256,start_level=1,add_extra_convs='on_output',num_outs=4,relu_before_extra_convs=True),pts_bbox_head=dict(type='DETR3DHead',num_query=900,num_classes=10,in_channels=256,sync_cls_avg_factor=True,with_box_refine=True,as_two_stage=False,transformer=dict(type='Detr3DTransformer',decoder=dict(type='Detr3DTransformerDecoder',num_layers=6,return_intermediate=True,transformerlayers=dict(type='mmdet.DetrTransformerDecoderLayer',attn_cfgs=[dict(type='MultiheadAttention', # mmcv.embed_dims=256,num_heads=8,dropout=0.1),dict(type='Detr3DCrossAtten',pc_range=point_cloud_range,num_points=1,embed_dims=256)],feedforward_channels=512,ffn_dropout=0.1,operation_order=('self_attn', 'norm', 'cross_attn', 'norm','ffn', 'norm')))),bbox_coder=dict(type='NMSFreeCoder',post_center_range=[-61.2, -61.2, -10.0, 61.2, 61.2, 10.0],pc_range=point_cloud_range,max_num=300,voxel_size=voxel_size,num_classes=10),positional_encoding=dict(type='mmdet.SinePositionalEncoding',num_feats=128,normalize=True,offset=-0.5),loss_cls=dict(type='mmdet.FocalLoss',use_sigmoid=True,gamma=2.0,alpha=0.25,loss_weight=2.0),loss_bbox=dict(type='mmdet.L1Loss', loss_weight=0.25),loss_iou=dict(type='mmdet.GIoULoss', loss_weight=0.0)),# model training and testing settingstrain_cfg=dict(pts=dict(grid_size=[512, 512, 1],voxel_size=voxel_size,point_cloud_range=point_cloud_range,out_size_factor=4,assigner=dict(type='HungarianAssigner3D',cls_cost=dict(type='mmdet.FocalLossCost', weight=2.0),reg_cost=dict(type='BBox3DL1Cost', weight=0.25),# ↓ Fake cost. This is just to get compatible with DETR headiou_cost=dict(type='mmdet.IoUCost', weight=0.0),pc_range=point_cloud_range))))dataset_type = 'NuScenesDataset'
data_root = 'data/nuscenes/'test_transforms = [dict(type='RandomResize3D',scale=(1600, 900),ratio_range=(1., 1.),keep_ratio=True)
]
train_transforms = [dict(type='PhotoMetricDistortion3D')] + test_transformsbackend_args = None
train_pipeline = [dict(type='LoadMultiViewImageFromFiles',to_float32=True,num_views=6,backend_args=backend_args),dict(type='LoadAnnotations3D',with_bbox_3d=True,with_label_3d=True,with_attr_label=False),dict(type='MultiViewWrapper', transforms=train_transforms),dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),dict(type='ObjectNameFilter', classes=class_names),dict(type='Pack3DDetInputs', keys=['img', 'gt_bboxes_3d', 'gt_labels_3d'])
]test_pipeline = [dict(type='LoadMultiViewImageFromFiles',to_float32=True,num_views=6,backend_args=backend_args),dict(type='MultiViewWrapper', transforms=test_transforms),dict(type='Pack3DDetInputs', keys=['img'])
]detr3d/projects/configs/detr3d/detr3d_res101_gridmask.py
model = dict(type='Detr3D',use_grid_mask=True,img_backbone=dict(type='ResNet',depth=101,num_stages=4,out_indices=(0, 1, 2, 3),frozen_stages=1,norm_cfg=dict(type='BN2d', requires_grad=False),norm_eval=True,style='caffe',dcn=dict(type='DCNv2', deform_groups=1, fallback_on_stride=False),stage_with_dcn=(False, False, True, True)),img_neck=dict(type='FPN',in_channels=[256, 512, 1024, 2048],out_channels=256,start_level=1,add_extra_convs='on_output',num_outs=4,relu_before_extra_convs=True),pts_bbox_head=dict(type='Detr3DHead',num_query=900,num_classes=10,in_channels=256,sync_cls_avg_factor=True,with_box_refine=True,as_two_stage=False,transformer=dict(type='Detr3DTransformer',decoder=dict(type='Detr3DTransformerDecoder',num_layers=6,return_intermediate=True,transformerlayers=dict(type='DetrTransformerDecoderLayer',attn_cfgs=[dict(type='MultiheadAttention',embed_dims=256,num_heads=8,dropout=0.1),dict(type='Detr3DCrossAtten',pc_range=point_cloud_range,num_points=1,embed_dims=256)],feedforward_channels=512,ffn_dropout=0.1,operation_order=('self_attn', 'norm', 'cross_attn', 'norm','ffn', 'norm')))),bbox_coder=dict(type='NMSFreeCoder',post_center_range=[-61.2, -61.2, -10.0, 61.2, 61.2, 10.0],pc_range=point_cloud_range,max_num=300,voxel_size=voxel_size,num_classes=10), positional_encoding=dict(type='SinePositionalEncoding',num_feats=128,normalize=True,offset=-0.5),loss_cls=dict(type='FocalLoss',use_sigmoid=True,gamma=2.0,alpha=0.25,loss_weight=2.0),loss_bbox=dict(type='L1Loss', loss_weight=0.25),loss_iou=dict(type='GIoULoss', loss_weight=0.0)),# model training and testing settingstrain_cfg=dict(pts=dict(grid_size=[512, 512, 1],voxel_size=voxel_size,point_cloud_range=point_cloud_range,out_size_factor=4,assigner=dict(type='HungarianAssigner3D',cls_cost=dict(type='FocalLossCost', weight=2.0),reg_cost=dict(type='BBox3DL1Cost', weight=0.25),iou_cost=dict(type='IoUCost', weight=0.0), # Fake cost. This is just to make it compatible with DETR head. pc_range=point_cloud_range))))dataset_type = 'NuScenesDataset'
data_root = 'data/nuscenes/'...train_pipeline = [dict(type='LoadMultiViewImageFromFiles', to_float32=True),dict(type='PhotoMetricDistortionMultiViewImage'),dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True, with_attr_label=False),dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),dict(type='ObjectNameFilter', classes=class_names),dict(type='NormalizeMultiviewImage', **img_norm_cfg),dict(type='PadMultiViewImage', size_divisor=32),dict(type='DefaultFormatBundle3D', class_names=class_names),dict(type='Collect3D', keys=['gt_bboxes_3d', 'gt_labels_3d', 'img'])
]
test_pipeline = [dict(type='LoadMultiViewImageFromFiles', to_float32=True),dict(type='NormalizeMultiviewImage', **img_norm_cfg),dict(type='PadMultiViewImage', size_divisor=32),dict(type='MultiScaleFlipAug3D',img_scale=(1333, 800),pts_scale_ratio=1,flip=False,transforms=[dict(type='DefaultFormatBundle3D',class_names=class_names,with_label=False),dict(type='Collect3D', keys=['img'])])
]相关文章:
)
如何使用nuScenes数据集格式的单帧数据推理(以DETR3D为例)
【请尊重原创!转载和引用文章内容务必注明出处!未经许可上传到某文库或其他收费阅读/下载网站赚钱的必追究责任!】 无论是mmdetection3D还是OpenPCDet都只有使用数据集(使用哪个数据集由配置文件里指定)训练和测试的代码,没有使用…...
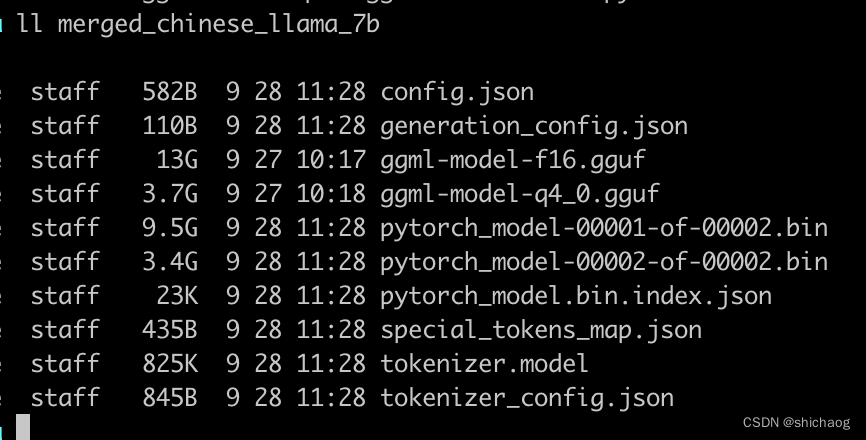
大语言模型之十三 LLama2中文推理
在《大语言模型之十二 SentencePiece扩充LLama2中文词汇》一文中已经扩充好了中文词汇表,接下来就是使用整理的中文语料对模型进行预训练了。这里先跳过预训练环节。先试用已经训练好的模型,看看如何推理。 合并模型 这一步骤会合并LoRA权重࿰…...

iOS AVAudioSession 详解
iOS AVAudioSession 详解 - 简书 默认没有options,category 7种即可满足条件 - (BOOL)setCategory:(AVAudioSessionCategory)category error:(NSError **)outError API_AVAILABLE(ios(3.0), watchos(2.0), tvos(9.0)) API_UNAVAILABLE(macos); 有optionsÿ…...
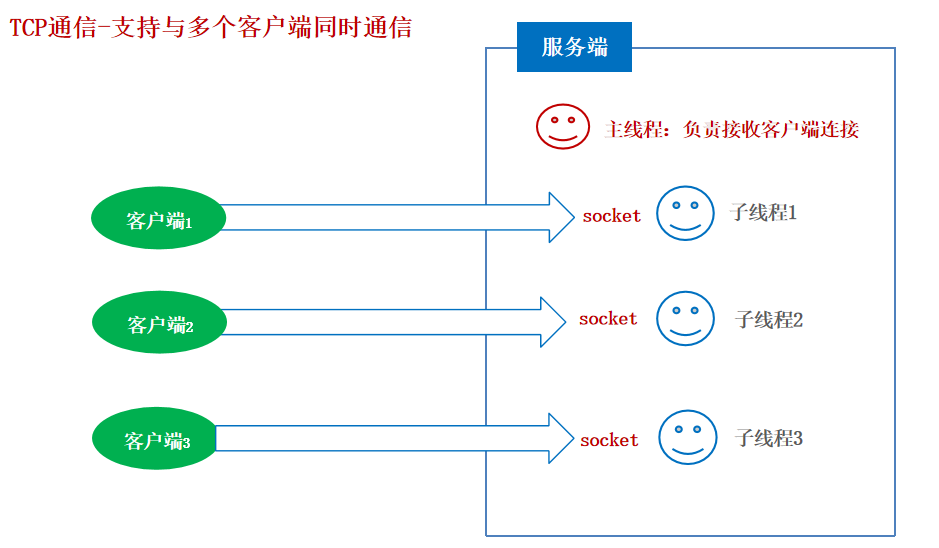
26-网络通信
网络通信 什么是网络编程? 可以让设备中的程序与网络上其他设备中的程序进行数据交互(实现网络通信的)。 java.net.包下提供了网络编程的解决方案! 基本的通信架构有2种形式:CS架构( Client客户端/Server服…...

嵌入式Linux应用开发-基础知识-第十九章驱动程序基石③
嵌入式Linux应用开发-基础知识-第十九章驱动程序基石③ 第十九章 驱动程序基石③19.5 定时器19.5.1 内核函数19.5.2 定时器时间单位19.5.3 使用定时器处理按键抖动19.5.4 现场编程、上机19.5.5 深入研究:定时器的内部机制19.5.6 深入研究:找到系统滴答 1…...
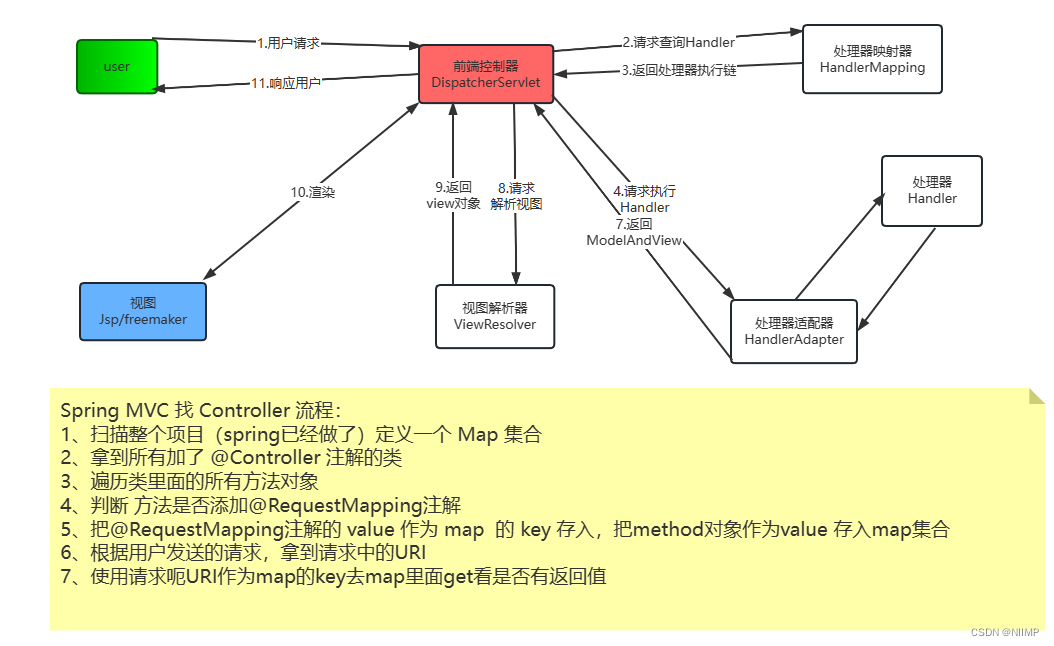
一文拿捏SpringMVC的调用流程
SpringMVC的调用流程 1.核心元素: DispatcherServlet(前端控制器)HandlerMapping(处理器映射器)HandlerAdapter(处理器适配器) ---> Handler(处理器)ViewResolver(视图解析器 )---> view(视图) 2.调用流程 用户发送请求到前端控制器前端控制器接收用户请求…...

一文详解 JDK1.8 的 Lambda、Stream、LocalDateTime
Lambda Lambda介绍 Lambda 表达式(lambda expression)是一个匿名函数,Lambda表达式基于数学中的λ演算得名,直接对应于其中的lambda抽象(lambda abstraction),是一个匿名函数,即没有函数名的函数。 Lambda表达式的结构 一个 Lamb…...

WebSocket实战之二协议分析
一、前言 上一篇 WebSocket实战之一 讲了WebSocket一个极简例子和基础的API的介绍,这一篇来分析一下WebSocket的协议,学习网络协议最好的方式就是抓包分析一下什么就都明白了。 二、WebSocket协议 本想盗一张网络图,后来想想不太好&#x…...
)
LeetCode //C - 208. Implement Trie (Prefix Tree)
208. Implement Trie (Prefix Tree) A trie (pronounced as “try”) or prefix tree is a tree data structure used to efficiently store and retrieve keys in a dataset of strings. There are various applications of this data structure, such as autocomplete and s…...
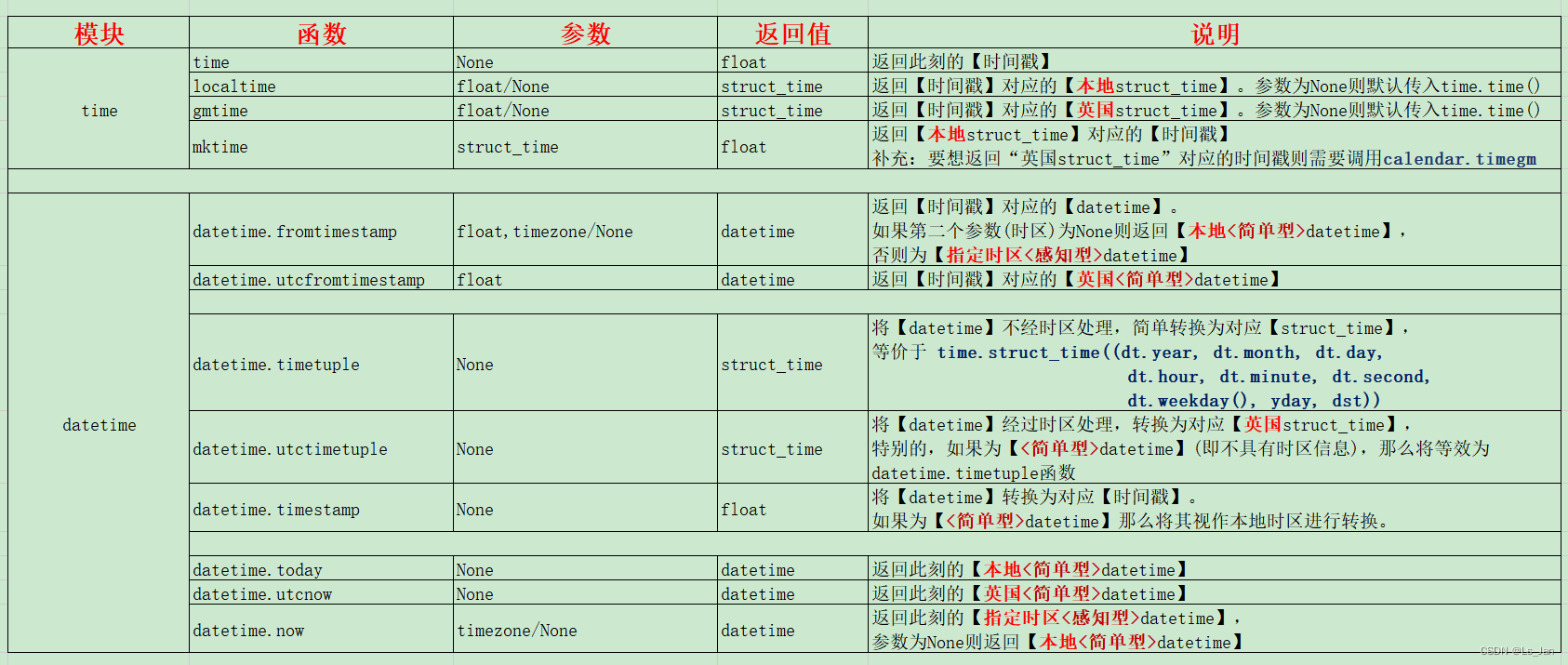
【Python】time模块和datetime模块的部分函数说明
时间戳与日期 在说到这俩模块之前,首先先明确几个概念: 时间戳是个很单纯的东西,没有“时区”一说,因为时间戳本质上是经过的时间。日常生活中接触到的“日期”、“某点某时某分”准确的说是时间点,都是有时区概念的…...

Python 无废话-基础知识元组Tuple详讲
“元组 Tuple”是一个有序、不可变的序列集合,元组的元素可以包含任意类型的数据,如整数、浮点数、字符串等,用()表示,如下示例: 元组特征 1) 元组中的各个元素,可以具有不相同的数据类型,如 T…...

【Win】Microsoft Spy++学习笔记
参考资料 《用VisualStudio\Spy查窗口句柄,监控窗口消息》 1. 安装 Spy是VS中的工具,所以直接安装VS就可以了; 2. 检查应用程序架构 ChatGPT-Bing: 对于窗口应用程序分析,确定应用程序是32位还是64位是很重要的,因…...
如何解决版本不兼容Jar包冲突问题
如何解决版本不兼容Jar包冲突问题 引言 “老婆”和“妈妈”同时掉进水里,先救谁? 常言道:编码五分钟,解冲突两小时。作为Java开发来说,第一眼见到ClassNotFoundException、 NoSuchMethodException这些异常来说&…...
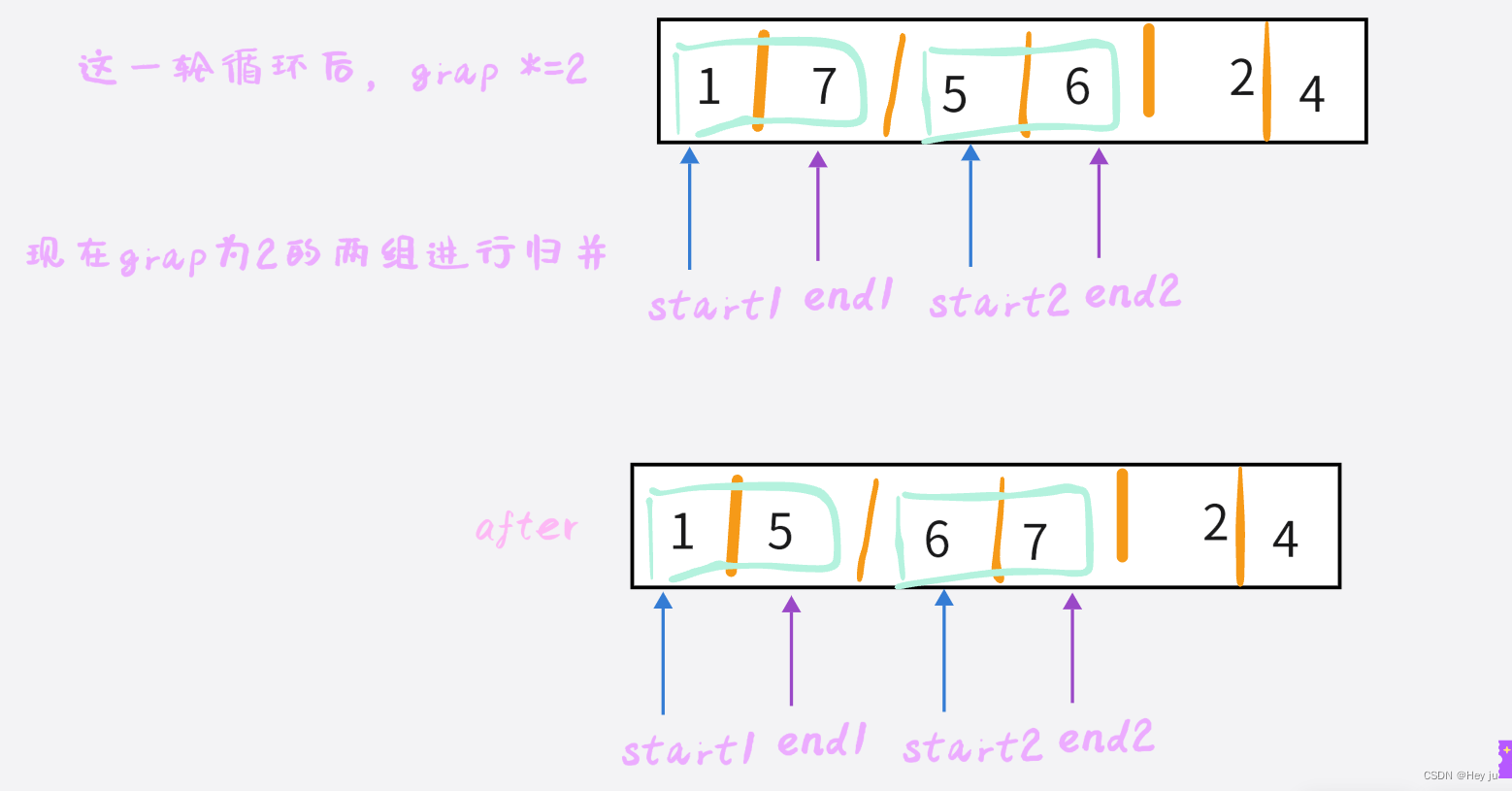
数据结构—归并排序-C语言实现
引言:归并排序跟快速排序一样,都运用到了分治的算法,但是归并排序是一种稳定的算法,同时也具备高效,其时间复杂度为O(N*logN) 算法图解: 然后开始归并: 就是这个思想,拆成最小子问题…...
Multiple CORS header ‘Access-Control-Allow-Origin‘ not allowed
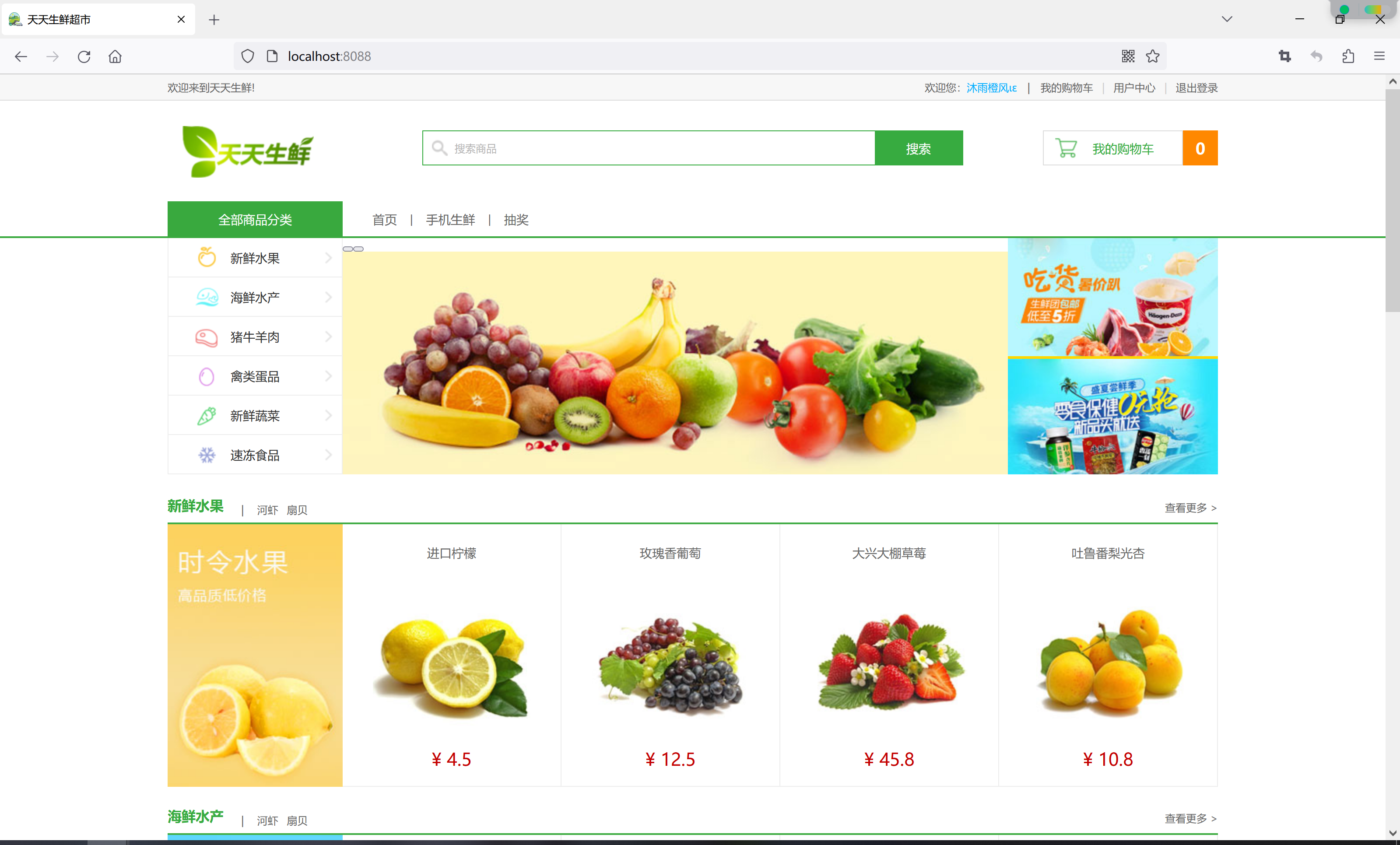
今天在修改天天生鲜超市项目的时候,因为使用了前后端分离模式,前端通过网关统一转发请求到后端服务,但是第一次使用就遇到了问题,比如跨域问题: 但是,其实网关里是有配置跨域的,只是忘了把前端项…...
msvcp100.dll丢失怎样修复,msvcp100.dll丢失问题全面解析
msvcp100.dll是一个动态链接库文件,属于 Microsoft Visual C Redistributable 的一个组件。它包含了 C 运行时库,这些库在运行程序时会被加载到内存中。msvcp100.dll文件的主要作用是为基于 Visual C 编写的程序提供必要的运行时支持。 当您运行一个基于…...
最新AI智能问答系统源码/AI绘画系统源码/支持GPT联网提问/Prompt应用+支持国内AI提问模型
一、AI创作系统 SparkAi创作系统是基于国外很火的ChatGPT进行开发的AI智能问答系统和AI绘画系统。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图…...
全连接网络实现回归【房价预测的数据】
也是分为data,model,train,test import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optimclass FCNet(nn.Module):def __init__(self):super(FCNet,self).__init__()self.fc1 nn.Linear(331,200)s…...
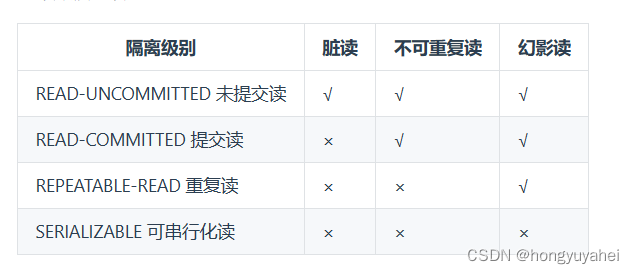
mysql八股
1、请你说说mysql索引,以及它们的好处和坏处 检索效率、存储资源、索引 索引就像指向表行的指针,是一个允许查询操作快速确定哪些行符合WHERE子句中的条件,并检索到这些行的其他列值的数据结构索引主要有普通索引、唯一索引、主键索引、外键…...
(附MATLAB代码实现))
MATLAB算法实战应用案例精讲-【优化算法】狐猴优化器(LO)(附MATLAB代码实现)
代码实现 MATLAB LO.m %======================================================================= % Lemurs Optimizer: A New Metaheuristic Algorithm % for Global Optimization (LO)% This work is published in Journal of "Applied …...

CHORD-X深度研究报告生成终端ComfyUI可视化工作流集成教程
CHORD-X深度研究报告生成终端ComfyUI可视化工作流集成教程 你是不是也遇到过这样的场景:需要生成一份深度行业分析报告,手头有CHORD-X这样强大的研究工具,但每次都要写代码调用API,流程繁琐,调试起来也不直观。或者&a…...
)
QGIS地图下载避坑指南:如何用XYZ Tiles精准导出0.3米分辨率地图(附CRS设置技巧)
QGIS高精度地图下载实战:从XYZ Tiles配置到0.3米级分辨率输出的完整方案 当城市规划师需要在老旧城区改造项目中获取0.3米精度的底图时,或者测绘工程师要为基础设施项目准备高分辨率参考影像时,QGIS配合XYZ Tiles的解决方案往往能提供专业级的…...

ESP32开发板快速上手:Arduino IDE环境搭建避坑指南
ESP32开发板快速上手:Arduino IDE环境搭建避坑指南 第一次接触ESP32开发板时,那种既兴奋又忐忑的心情至今记忆犹新。作为一款功能强大且价格亲民的物联网开发平台,ESP32确实为创客和开发者打开了无限可能。但在Arduino IDE中配置ESP32开发环…...

Qt与QCustomPlot实战:打造高效实时波形可视化工具
1. Qt与QCustomPlot基础入门 第一次接触Qt和QCustomPlot时,我也被它们强大的功能震撼到了。记得当时在做一个工业传感器项目,需要实时显示十几个通道的采集数据。试过用Python的Matplotlib,刷新率跟不上;改用Qt自带的QChart&#…...

YOLOv12优化升级:官方镜像训练更稳定,内存占用显著降低
YOLOv12优化升级:官方镜像训练更稳定,内存占用显著降低 1. YOLOv12核心架构革新 YOLOv12标志着目标检测领域的一次重大技术跃迁。与以往版本最大的不同在于,它彻底摒弃了传统CNN架构,转而采用以注意力机制为核心的创新设计。这种…...

Ubuntu20.04下ROS1-Noetic的快速安装与配置指南
1. 环境准备:Ubuntu20.04基础配置 在开始安装ROS1-Noetic之前,我们需要确保Ubuntu20.04系统的基础环境已经正确配置。很多新手容易忽略这一步,结果在后续安装过程中遇到各种奇怪的问题。我自己第一次安装时就踩过这个坑,浪费了半天…...

别只把XSA当黑盒:拆解它的ZIP结构,手动提取你需要的驱动和初始化代码
别只把XSA当黑盒:拆解它的ZIP结构,手动提取你需要的驱动和初始化代码 在FPGA开发的世界里,XSA文件常被视为一个神秘的黑盒——Vitis或PetaLinux工具链自动处理它,生成我们需要的BSP和驱动代码。但当你需要定制化硬件描述、优化启动…...

从晶振到外设:用STM32CubeMX图解F103时钟信号完整路径
从晶振到外设:用STM32CubeMX图解F103时钟信号完整路径 在嵌入式开发中,时钟系统如同芯片的"心跳",决定了整个系统的运行节奏。对于STM32开发者而言,理解时钟信号的完整路径不仅有助于优化系统性能,还能在调试…...

CHORD-X部署排错指南:常见问题如403 Forbidden的解决方法
CHORD-X部署排错指南:常见问题如403 Forbidden的解决方法 部署一个新的AI模型,就像组装一台精密仪器,过程中难免会遇到几个“螺丝”拧不上的情况。特别是当你兴致勃勃地按照教程部署好CHORD-X,准备大展身手时,一个冷冰…...

SUNFLOWER MATCH LAB 入门必看:Java开发者集成指南与八股文精讲
SUNFLOWER MATCH LAB 入门必看:Java开发者集成指南与八股文精讲 最近和几个做Java开发的朋友聊天,发现大家都有类似的烦恼:项目里想加点AI能力,比如智能问答或者文档分析,但一看那些大模型的API文档就头大,…...