用pyinstaller打包LGBM模型为ELF/EXE可执行文件
1. 引入
写好的python代码和模型,如果需要做到离线部署、运行,就必须要将代码和模型打包为可独立运行的可执行文件。
使用pyinstaller就能做到这个,相同的代码,在windows上运行就能打包为exe,在linux上运行就能打包为elf。
打包的过程是怎么样?有哪些不同的打包方式?各有什么优缺点呢?
2. 打包过程:生成多个文件
假设我们的项目有3个文件组成:
main.py: 主入口程序utils.py: 各种工具函数model_rf.jl: 模型文件
打包过程分为如下步骤,在windows和linux都一样:
- 安装pyinstaller
pip install pyinstaller
- 生成.spec文件
pyi-makespec -w main.py
- 修改.spec文件
注意几点:
(1)主入口程序写在: Analysis第一个参数
(2)其他依赖程序写在:Analysis第一个参数的列表中
(3)模型文件写在: binaries中,注意要写为tuple
修改后好的.spec文件如下所示:
# -*- mode: python ; coding: utf-8 -*-block_cipher = Nonea = Analysis(['main.py','utils.py'],pathex=[],binaries=[('model_rf.jl','.')],datas=[],hiddenimports=['scipy.special.cython_special'],hookspath=[],hooksconfig={},runtime_hooks=[],excludes=[],win_no_prefer_redirects=False,win_private_assemblies=False,cipher=block_cipher,noarchive=False,
)
pyz = PYZ(a.pure, a.zipped_data, cipher=block_cipher)exe = EXE(pyz,a.scripts,[],exclude_binaries=True,name='main',debug=False,bootloader_ignore_signals=False,strip=False,upx=True,console=False,disable_windowed_traceback=False,argv_emulation=False,target_arch=None,codesign_identity=None,entitlements_file=None,
)
coll = COLLECT(exe,a.binaries,a.zipfiles,a.datas,strip=False,upx=True,upx_exclude=[],name='main',
)至于为什么要加入hiddenimports=['scipy.special.cython_special'],,是因为笔者在python3.8下运行,打包正常后,运行可执行文件依然报错如下:
(xxx) [aaa@bbb main]$ ./main
Traceback (most recent call last):File "main.py", line 1, in <module>File "PyInstaller/loader/pyimod02_importers.py", line 385, in exec_moduleFile "sklearn/ensemble/__init__.py", line 5, in <module>File "PyInstaller/loader/pyimod02_importers.py", line 385, in exec_moduleFile "sklearn/ensemble/_base.py", line 18, in <module>File "PyInstaller/loader/pyimod02_importers.py", line 385, in exec_moduleFile "sklearn/tree/__init__.py", line 6, in <module>File "PyInstaller/loader/pyimod02_importers.py", line 385, in exec_moduleFile "sklearn/tree/_classes.py", line 41, in <module>File "sklearn/tree/_criterion.pyx", line 1, in init sklearn.tree._criterion
ModuleNotFoundError: No module named 'scipy.special.cython_special'
[45300] Failed to execute script 'main' due to unhandled exception!
根据参考4,加入后就能修正该错误,因为pyinstaller没有加入这个必须的依赖。
- 运行命令进行打包
pyinstaller main.spec
这种打包方式,会生成一个可执行文件(位于dist文件夹中),也会生成很多个运行该可执行文件所需的依赖库(dll, so),所以部署时,需要将整个文件夹拷贝到目标机。
那么,能不能只生成一个可执行文件,不生成额外的依赖文件呢?
3. 打包过程:生成单个文件
如果只有一个py文件,那么,使用一条命令就能实现生成独立的可执行文件:
pyinstaller -F main.py
但是我们这个例子中,是有多个文件的,这就必须用下面的命令来打包:
pyinstaller -F -w main.py -p utils.py -p model_rf.jl --hidden-import scipy.special.cython_special
这样就能在dist文件夹中生成一个较大的可执行文件,部署时只需要部署这一个文件就可以。
4. 两种打包方式的区别
上面讲解了生成多个文件和生成单个文件两种pyinstaller的打包方式。看上去生成单个文件方式更方便。
但是,实际运行打包后的可执行文件,就能发现:
(1)生成单个文件,最终只生成一个可执行文件,比较简单,但是运行很慢
(2)生成多个文件,最终生成一堆文件,但是其中的可执行文件运行会快很多;笔者实测这种方式比单个文件快5倍
为什么生成单个文件会更慢呢?从参考3可知
“one file” mode – this mode means that it has to unpack all of the libraries to a temporary directory before the app can start
因为这个很大的单个文件,在运行主函数前,会将所有依赖都释放到临时文件中,再加载运行。这个释放文件的操作,需要占用I/O,而且每次启动程序都释放文件,自然就拖慢了运行速度。
5. 总结
pyinstaller能实现将多个.py文件,和其他模型文件,打包为可离线运行,不安装配置环境就能运行的可执行文件EXE或者ELF。
打包时,建议按照生成多个文件的方式来打包,这样程序运行起来会更快。 本文用到的所有代码和相关文件,都放到这个repo了,在linux下是正确运行的:https://github.com/ybdesire/machinelearning/tree/master/pyinstaller_model_package。
参考
- https://blog.csdn.net/weixin_42112050/article/details/129555170
- https://blog.csdn.net/LIUWENCAIJIAYOU/article/details/121470028
- 为什么打包后的程序运行慢: https://stackoverflow.com/questions/9469932/app-created-with-pyinstaller-has-a-slow-startup
- https://stackoverflow.com/questions/62581504/why-do-i-have-modulenotfounderror-no-module-named-scipy-special-cython-specia
- 本文所用代码。https://github.com/ybdesire/machinelearning/tree/master/pyinstaller_model_package
相关文章:

用pyinstaller打包LGBM模型为ELF/EXE可执行文件
1. 引入 写好的python代码和模型,如果需要做到离线部署、运行,就必须要将代码和模型打包为可独立运行的可执行文件。 使用pyinstaller就能做到这个,相同的代码,在windows上运行就能打包为exe,在linux上运行就能打包为…...
软考中级—— 操作系统知识
进程管理 操作系统概述 操作系统的作用:通过资源管理提高计算机系统的效率;改善人机界面向用户提供友好的工作环境。 操作系统的特征:并发性、共享性、虚拟性、不确定性。 操作系统的功能:进程管理、存储管理、文件管理、设备…...

我们是否真的需要k8s?
文章目录 背景k8s相关的讨论为什么要用k8sk8s带来了什么当前业务使用到k8s的核心优势了吗直接自己买服务器会不会更便宜?其他QA没有人可以说出来为什么一定要用k8s而不是其他的没有人可以解释为什么成本核算困难以及成本这么高的原因没有人给出面向C端,面…...
基于蜉蝣优化的BP神经网络(分类应用) - 附代码
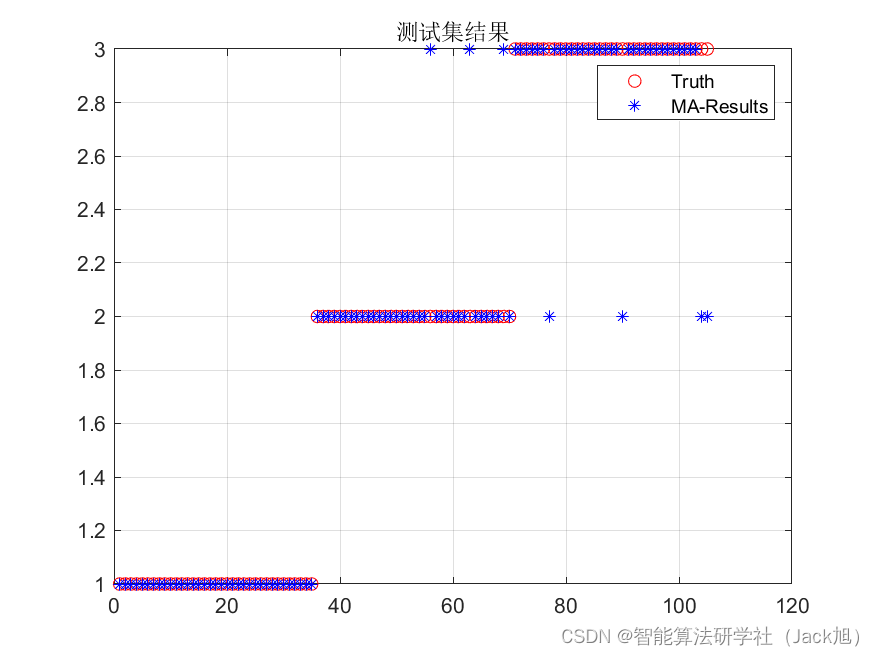
基于蜉蝣优化的BP神经网络(分类应用) - 附代码 文章目录 基于蜉蝣优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.蜉蝣优化BP神经网络3.1 BP神经网络参数设置3.2 蜉蝣算法应用 4.测试结果:5.M…...

前端系列-1 HTML+JS+CSS基础
背景: 前端系列会收集碎片化的前端知识点,作为自己工作和学习时的字典,欢迎读者收藏和使用。 笔者是后端开发😶前端涉猎不深,因此文章重在广度和实用,对原理和性能不会过多深究。 1.html 1.1 html5网页结…...

Learning Invariant Representation for Unsupervised Image Restoration
Learning Invariant Representation for Unsupervised Image Restoration (Paper reading) Wenchao Du, Sichuan University, CVPR20, Cited:63, Code, Paper 1. 前言 近年来,跨域传输被应用于无监督图像恢复任务中。但是,直接应用已有的框架…...

1.4.C++项目:仿muduo库实现并发服务器之buffer模块的设计
项目完整版在: 一、buffer模块: 缓冲区模块 Buffer模块是一个缓冲区模块,用于实现通信中用户态的接收缓冲区和发送缓冲区功能。 二、提供的功能 存储数据,取出数据 三、实现思想 1.实现换出去得有一块内存空间,采…...

AndroidStudio精品插件集
官网 项目地址:Github博客地址:Studio 精品插件推荐 使用需知 所有插件在 Android Studio 2022.3.1.18(长颈鹿)上测试均没有问题,推荐使用此版本Android Studio 2022.3.1.18(长颈鹿)正式版下…...
java图书管理系统
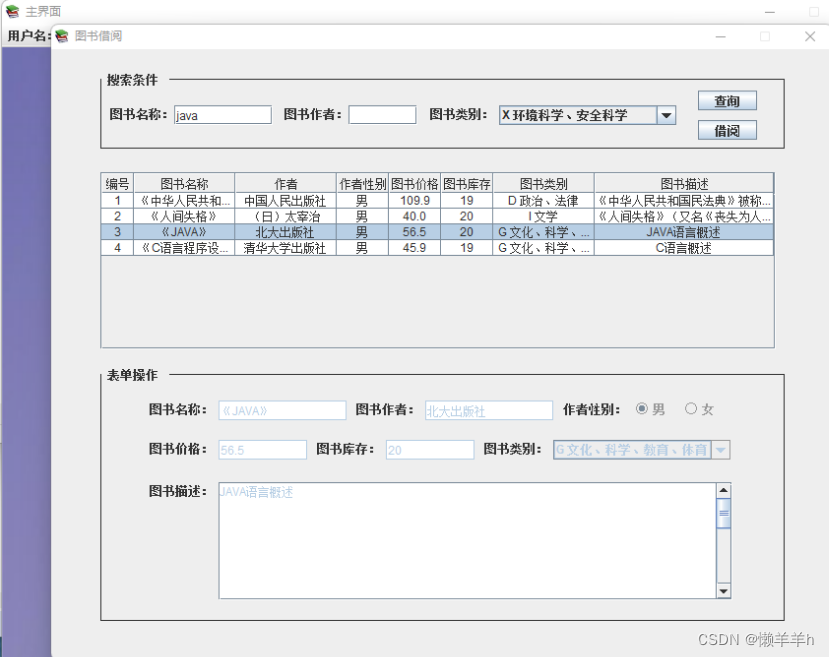
一、 引言 图书管理系统是一个用于图书馆或书店管理图书信息、借阅记录和读者信息的应用程序。本系统使用Java Swing框架进行开发,提供直观的用户界面,方便图书馆管理员或书店工作人员对图书信息进行管理。以下是系统的设计、功能和实现的详细报告。 二…...
大屏自适应容器组件-Vue3+TS
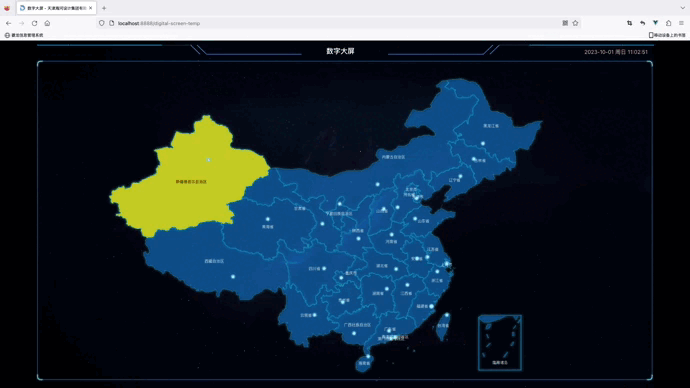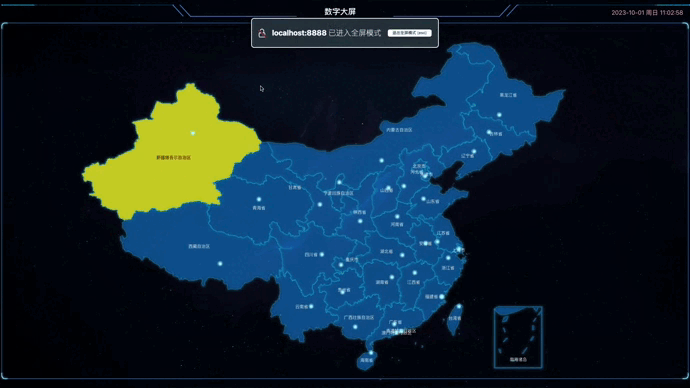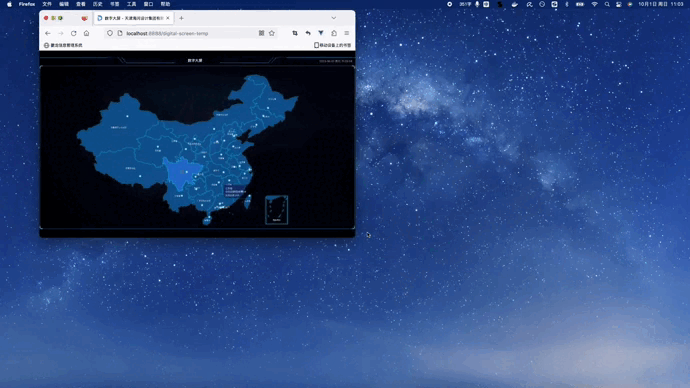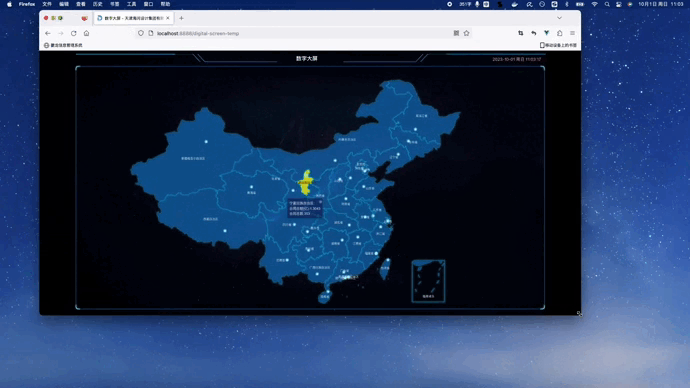
1.引言 在做数字大屏时,图表能跟着浏览器的尺寸自动变化,本文采用Vue3前端框架,采用TypeScript语言,封装了一个大屏自适应组件,将需要显示的图表放入组件的插槽中,就能实现自适应屏幕大小的效果。 2.实际…...
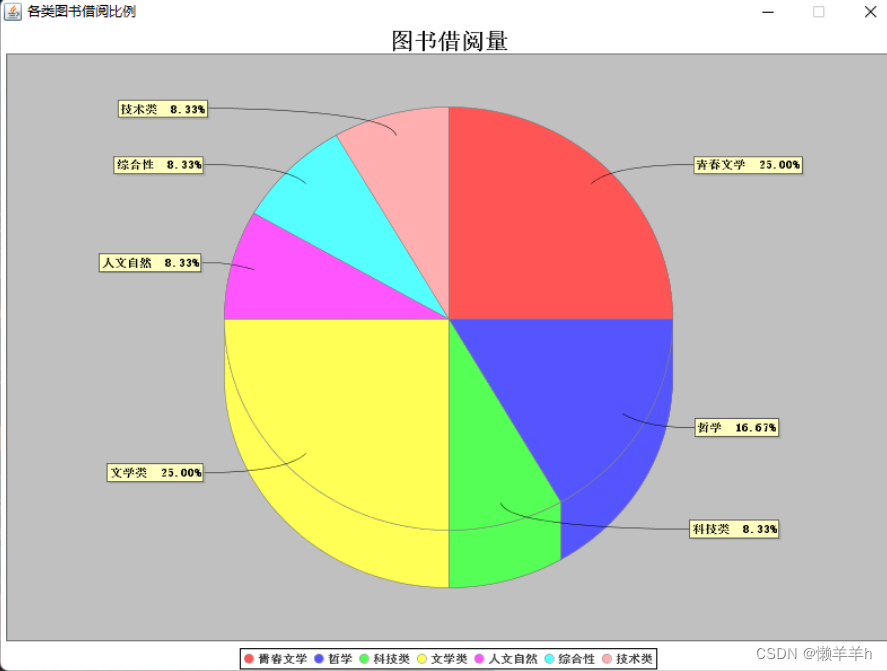
java图书信息管理
一、项目概述 本图书信息管理系统旨在提供一个直观的用户界面,用于管理图书馆或书店的图书信息。系统包括图书添加、查询、借阅和归还等功能。 二、系统架构 系统采用JavaSwing作为前端UI框架,后端使用Java Servlet处理业务逻辑,数据存储在…...

apache服务器出现No input file specified.解决方案
APACHE服务器出现No input file specified.解决方案 thinkcmf程序默认的.htaccess里面的规则: <IfModule mod_rewrite.c> RewriteEngine on RewriteCond %{REQUEST_FILENAME} !-d RewriteCond %{REQUEST_FILENAME} !-f RewriteRule ^(.*)$ index.php/$1 [QSA…...

你写过的最蠢的代码是?——全栈开发篇
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
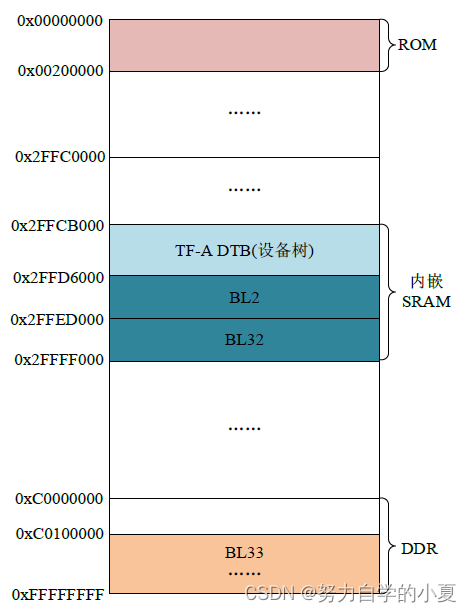
正点原子嵌入式linux驱动开发——TF-A初探
上一篇笔记中,正点原子的文档简单讲解了一下什么是TF-A,并且也学习了如何编译TF-A。但是TF-A是如何运行的,它的一个运行流程并未涉及。TF-A的详细运行过程是很复杂的,涉及到很多ARM处理器底层知识,所以这一篇笔记的内容…...

【网安别学成开发】之——python篇
经典入门编程题 1.猜数字 经典的猜数字游戏,几乎所有人学编程时都会做。 功能描述: 随机选择一个三位以内的数字作为答案。用户输入一个数字,程序会提示大了或是小了,直到用户猜中。 #!/usr/bin/env python3import randomresu…...

vue图片显示
一、Vue图片显示方法: 1.直接使用<img>标签: 最简单的方法是使用<img>标签,并将图片的URL作为src属性的值。例如: <img src"path/to/your/image.jpg" alt"Image"> 如果是绝对路径&#x…...
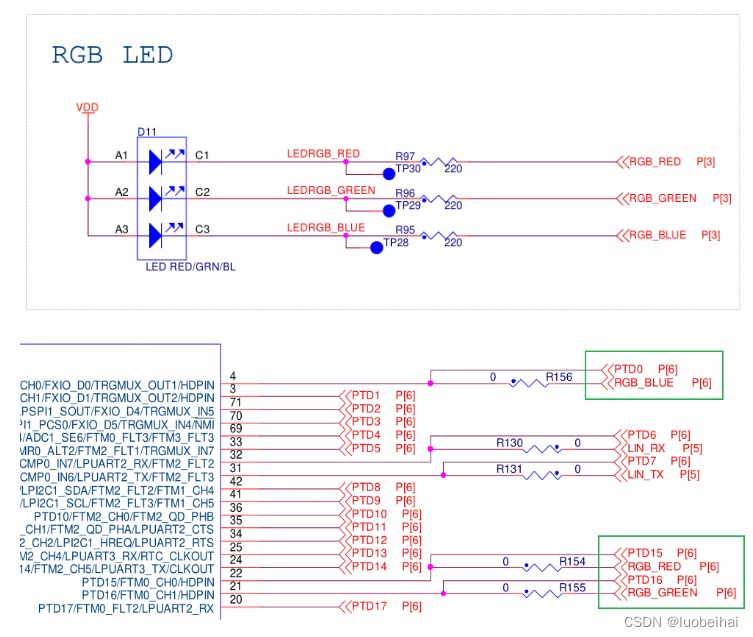
S32K144 GPIO编程
前面的文章介绍了如何在MDK-Keil下面进行S32K144的开发,下面就使用该工程模板进行GPIO LED的编程试验。 1. 开发环境 S32K144EVB-Q100开发板MDK-Keil Jlink 2. 硬件连接 S32K144EVB-Q100开发板关于LED的原理图如下: 也就是具体连接关系如下…...
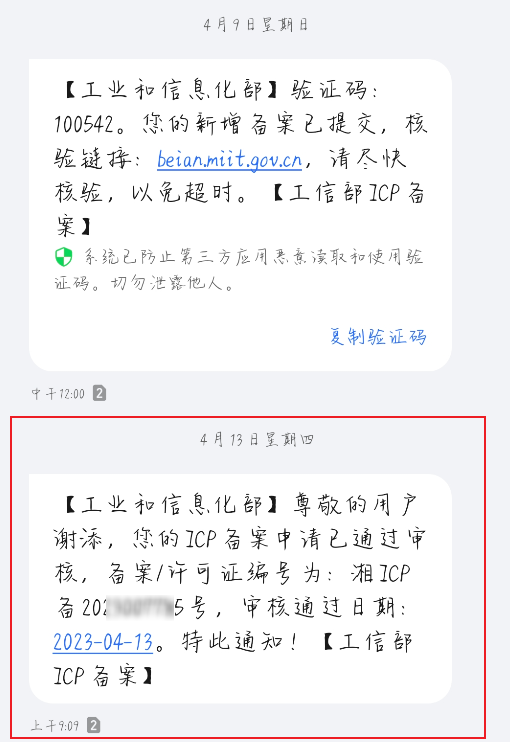
域名备案流程(个人备案,腾讯云 / 阿里云)
文章目录 1.网站备案的目的2.备案准备的材料2.1 网站域名2.2 云资源或备案授权码2.3 电子材料 3.首次个人备案准备的材料3.1 主体相关3.2 域名相关3.3 网站相关3.4 网站服务相关3.5 变更相关 4.个人备案流程4.1 登录系统4.2 填写备案信息🍀 填写备案省份ἴ…...

子网ip和子网掩码的关系
子网ip和子网掩码的关系 一个IP地址被分为两部分:网络地址和主机地址。这是通过子网掩码来实现的。 子网掩码(Subnet Mask)是一个32位的二进制数,它用来区分一个IP地址中的网络地址和主机地址。在子网掩码中,网络地址…...

openGauss学习笔记-88 openGauss 数据库管理-内存优化表MOT管理-内存表特性-使用MOT-MOT使用将磁盘表转换为MOT
文章目录 openGauss学习笔记-88 openGauss 数据库管理-内存优化表MOT管理-内存表特性-使用MOT-MOT使用将磁盘表转换为MOT88.1 前置条件检查88.2 转换88.3 转换示例 openGauss学习笔记-88 openGauss 数据库管理-内存优化表MOT管理-内存表特性-使用MOT-MOT使用将磁盘表转换为MOT …...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...