TinyWebServer学习笔记-log
为什么服务器要有一个日志系统?
故障排查和调试: 在服务器运行期间,可能会发生各种问题和故障,例如程序崩溃、性能下降、异常请求等。日志记录了服务器的运行状态、错误信息和各种操作,这些日志可以用来快速定位和排查问题,帮助开发人员更容易地找到问题的根本原因,从而更快地修复bug和提高服务器稳定性。
性能监测: 通过日志系统可以记录服务器的性能数据,包括请求处理时间、吞吐量、内存使用情况、CPU利用率等等。这些数据有助于监控服务器的性能,发现潜在的性能瓶颈,以便进行性能优化。
安全性: 日志可以记录系统的安全事件,如登录失败尝试、异常访问等。通过分析这些日志,可以检测和防止潜在的安全威胁,提高服务器的安全性。
法律合规性: 某些行业和法规要求服务器必须记录和保留特定类型的操作日志,以便进行审计和合规性检查。缺乏合规性的日志记录可能会导致法律责任。
运营和分析: 运营团队可以通过分析日志数据来了解用户行为、产品使用情况和趋势。这有助于改进产品、优化用户体验和制定业务策略。
历史记录: 日志还可以用作历史记录,以跟踪系统的状态和操作历史。这对于了解系统的演化和历史情况非常有用。
实现过程
为了实现异步写入,利用循环数组实现阻塞队列。
template <class T>
class block_queue
{
public:block_queue(int max_size = 1000){if (max_size <= 0){exit(-1);}m_max_size = max_size;m_array = new T[max_size];m_size = 0;m_front = -1;m_back = -1;}void clear(){m_mutex.lock();m_size = 0;m_front = -1;m_back = -1;m_mutex.unlock();}~block_queue(){m_mutex.lock();if (m_array != NULL)delete [] m_array;m_mutex.unlock();}//判断队列是否满了bool full() {m_mutex.lock();if (m_size >= m_max_size){m_mutex.unlock();return true;}m_mutex.unlock();return false;}//判断队列是否为空bool empty() {m_mutex.lock();if (0 == m_size){m_mutex.unlock();return true;}m_mutex.unlock();return false;}//返回队首元素bool front(T &value) {m_mutex.lock();if (0 == m_size){m_mutex.unlock();return false;}value = m_array[m_front];m_mutex.unlock();return true;}//返回队尾元素bool back(T &value) {m_mutex.lock();if (0 == m_size){m_mutex.unlock();return false;}value = m_array[m_back];m_mutex.unlock();return true;}int size() {int tmp = 0;m_mutex.lock();tmp = m_size;m_mutex.unlock();return tmp;}int max_size(){int tmp = 0;m_mutex.lock();tmp = m_max_size;m_mutex.unlock();return tmp;}//往队列添加元素,需要将所有使用队列的线程先唤醒//当有元素push进队列,相当于生产者生产了一个元素//若当前没有线程等待条件变量,则唤醒无意义bool push(const T &item){m_mutex.lock();if (m_size >= m_max_size){m_cond.broadcast();m_mutex.unlock();return false;}m_back = (m_back + 1) % m_max_size;m_array[m_back] = item;m_size++;m_cond.broadcast();m_mutex.unlock();return true;}//pop时,如果当前队列没有元素,将会等待条件变量bool pop(T &item){m_mutex.lock();while (m_size <= 0){if (!m_cond.wait(m_mutex.get())){m_mutex.unlock();return false;}}/*m_front = (m_front + 1) % m_max_size;item = m_array[m_front];*///这里我认为应该先得到值,然后更新m_front下标item=m_array[m_front];m_front=(m_frong+1)% m_max_size;m_size--;m_mutex.unlock();return true;}//增加了超时处理bool pop(T &item, int ms_timeout){struct timespec t = {0, 0};struct timeval now = {0, 0};gettimeofday(&now, NULL);m_mutex.lock();if (m_size <= 0){t.tv_sec = now.tv_sec + ms_timeout / 1000;t.tv_nsec = (ms_timeout % 1000) * 1000;if (!m_cond.timewait(m_mutex.get(), t)){m_mutex.unlock();return false;}}if (m_size <= 0){m_mutex.unlock();return false;}m_front = (m_front + 1) % m_max_size;item = m_array[m_front];m_size--;m_mutex.unlock();return true;}private:locker m_mutex; //互斥锁cond m_cond; //条件变量T *m_array; //存放日志的数组int m_size; //已经用的空间int m_max_size; //最大容量int m_front; //数组头的下标int m_back; //数组尾的下标
};解释下timespec结构体和timeval结构体,timespec结构体,分为秒和微秒两个部分,timeval结构体now,分为秒和纳秒两个部分。在这个自定义队列中,当队列为空时,从队列中获取元素的线程将会被挂起;当队列是满时,往队列里添加元素的线程将会挂起。
class Log
{
public://C++11以后,使用局部变量懒汉不用加锁static Log *get_instance(){static Log instance;return &instance;}static void *flush_log_thread(void *args){Log::get_instance()->async_write_log();}//可选择的参数有日志文件、日志缓冲区大小、最大行数以及最长日志条队列bool init(const char *file_name, int close_log, int log_buf_size = 8192, int split_lines = 5000000, int max_queue_size = 0);void write_log(int level, const char *format, ...);void flush(void);private:Log();virtual ~Log();void *async_write_log(){string single_log;//从阻塞队列中取出一个日志string,写入文件while (m_log_queue->pop(single_log)){m_mutex.lock();fputs(single_log.c_str(), m_fp);m_mutex.unlock();}}private:char dir_name[128]; //路径名char log_name[128]; //log文件名int m_split_lines; //日志最大行数int m_log_buf_size; //日志缓冲区大小long long m_count; //日志行数记录int m_today; //因为按天分类,记录当前时间是那一天FILE *m_fp; //打开log的文件指针char *m_buf; //缓冲区block_queue<string> *m_log_queue; //阻塞队列bool m_is_async; //是否同步标志位locker m_mutex; //互斥锁int m_close_log; //关闭日志
};#define LOG_DEBUG(format, ...) if(0 == m_close_log) {Log::get_instance()->write_log(0, format, ##__VA_ARGS__); Log::get_instance()->flush();}
#define LOG_INFO(format, ...) if(0 == m_close_log) {Log::get_instance()->write_log(1, format, ##__VA_ARGS__); Log::get_instance()->flush();}
#define LOG_WARN(format, ...) if(0 == m_close_log) {Log::get_instance()->write_log(2, format, ##__VA_ARGS__); Log::get_instance()->flush();}
#define LOG_ERROR(format, ...) if(0 == m_close_log) {Log::get_instance()->write_log(3, format, ##__VA_ARGS__); Log::get_instance()->flush();}本项目中,使用单例模式创建日志系统,记录服务器的运行状态、错误信息和访问数据。能够按天分类,超行分类。可以选择同步和异步写入两种方式。
同步打开对应的文件写入日志;异步则采取生产者-消费者模型封装为阻塞队列,创建一个写线程,工作线程将要写的日志push进队列,写线程从队列中读取内容,写入日志。
在这个项目的日志系统中,如果设置了阻塞队列的长度,则代表选择了异步写入日志;如果没有设置,则代表同步写入日志。
为什么要日志分级?
信息过滤: 在大型应用程序中,产生的日志可能非常庞大。通过分级,可以根据需要选择性地查看日志。例如,开发人员可能只对错误和警告感兴趣,而不关心调试信息。
故障排查: 当应用程序出现故障或错误时,日志分级可以帮助开发人员快速定位问题。错误日志可以提供关于发生了什么错误的详细信息,而调试日志则可以提供更多上下文,帮助解决问题。
性能监测: 分级日志还可以用于监测应用程序的性能。通过记录某些操作的耗时信息,开发人员可以识别性能瓶颈,并进行优化。
审核和合规性: 在某些情况下,应用程序需要记录特定事件或行为,以满足合规性要求或进行审核。通过使用不同级别的日志,可以轻松地识别和检索这些信息。
容易维护: 通过使用分级日志,开发人员可以更容易地维护应用程序的日志记录。不同级别的日志通常被写入不同的文件或存储位置,这使得查找和清理日志变得更加简单。
常见的日志级别包括:
DEBUG(调试): 用于记录详细的调试信息,通常只在开发和测试阶段启用。
INFO(信息): 用于记录应用程序的重要事件和状态信息,例如启动、关闭、用户登录等。
WARNING(警告): 用于记录可能需要关注但不一定是错误的事件,例如配置警告或不寻常的操作。
ERROR(错误): 用于记录应用程序的错误事件,例如异常、未处理的异常、无法连接到数据库等。
CRITICAL(关键): 用于记录严重错误,可能导致应用程序无法正常运行的情况,例如关键服务崩溃。
本项目中,包括DEBUG,INFO,WARN,ERROR四个级别。
#define LOG_DEBUG(format, ...) Log::get_instance()->write_log(0, format, __VA_ARGS__)
#define LOG_INFO(format, ...) Log::get_instance()->write_log(1, format, __VA_ARGS__)
#define LOG_WARN(format, ...) Log::get_instance()->write_log(2, format, __VA_ARGS__)
#define LOG_ERROR(format, ...) Log::get_instance()->write_log(3, format, __VA_ARGS__)在init函数中完成路径名,文件名等私有数据成员的设置。
if (p == NULL)
{snprintf(log_full_name, 255, "%d_%02d_%02d_%s", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, file_name);
}
else
{strcpy(log_name, p + 1);strncpy(dir_name, file_name, p - file_name + 1);snprintf(log_full_name, 255, "%s%d_%02d_%02d_%s", dir_name, my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, log_name);
}这段代码判断file_name是是否包含'\',如果不包含,也就是没有包含路径信息,那么就用当前日期和file_name来构建日志文件名。p为空则代表file_name不包含路径信息,只包含文件名,那么生成最终文件名:年_月_日_文件名。如果p不为空,那么找到最后一个路径分隔符,计算出文件名所在文件夹的长度,并将路径复制到dir_name中,文件名复制到log_name中,最终构建的路径是文件路径+时间+文件名。也就是根据是否包含路径信息,生成不同格式的日志文件名。
接下来是分级和分片函数:
void Log::write_log(int level, const char *format, ...)
{struct timeval now = {0, 0};gettimeofday(&now, NULL);time_t t = now.tv_sec;struct tm *sys_tm = localtime(&t);struct tm my_tm = *sys_tm;char s[16] = {0};switch (level){case 0:strcpy(s, "[debug]:");break;case 1:strcpy(s, "[info]:");break;case 2:strcpy(s, "[warn]:");break;case 3:strcpy(s, "[erro]:");break;default:strcpy(s, "[info]:");break;}//写入一个log,对m_count++, m_split_lines最大行数m_mutex.lock();m_count++;if (m_today != my_tm.tm_mday || m_count % m_split_lines == 0) //everyday log{char new_log[256] = {0};fflush(m_fp);fclose(m_fp);char tail[16] = {0};snprintf(tail, 16, "%d_%02d_%02d_", my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday);if (m_today != my_tm.tm_mday){snprintf(new_log, 255, "%s%s%s", dir_name, tail, log_name);m_today = my_tm.tm_mday;m_count = 0;}else{snprintf(new_log, 255, "%s%s%s.%lld", dir_name, tail, log_name, m_count / m_split_lines);}m_fp = fopen(new_log, "a");}m_mutex.unlock();va_list valst;va_start(valst, format);string log_str;m_mutex.lock();//写入的具体时间内容格式int n = snprintf(m_buf, 48, "%d-%02d-%02d %02d:%02d:%02d.%06ld %s ",my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday,my_tm.tm_hour, my_tm.tm_min, my_tm.tm_sec, now.tv_usec, s);int m = vsnprintf(m_buf + n, m_log_buf_size - n - 1, format, valst);m_buf[n + m] = '\n';m_buf[n + m + 1] = '\0';log_str = m_buf;m_mutex.unlock();if (m_is_async && !m_log_queue->full()){m_log_queue->push(log_str);}else{m_mutex.lock();fputs(log_str.c_str(), m_fp);m_mutex.unlock();}va_end(valst);
}思路如下:
1、获得今天的日期时间,如果日志的日期不是今天则创建新的日志文件,然后向新的文件写入。
2、如果是今天的日期时间,但是超过了文件的最大行,那么就进行分片,在文件结尾加入分片的ID,比如***_log_file1,***_log_file2这样。然后写入文件。
3、如果是今天的日期,并且没有超过最大文件行,就写入对应的文件。
准备好要写入的文件后,格式化时间和内容,放到缓冲数组中,然后判断日志系统是异步写入还是同步写入,如果是异步则将需要写的日志内容加入到阻塞队列中,否则直接调用fputs函数将输入文件指针对应的文件中。
相关文章:

TinyWebServer学习笔记-log
为什么服务器要有一个日志系统? 故障排查和调试: 在服务器运行期间,可能会发生各种问题和故障,例如程序崩溃、性能下降、异常请求等。日志记录了服务器的运行状态、错误信息和各种操作,这些日志可以用来快速定位和排查…...

【kubernetes】CRI OCI
1 OCI OCI(Open Container Initiative):由Linux基金会主导,主要包含容器镜像规范和容器运行时规范: Image Specification(image-spec)Runtime Specification(runtime-spec)runC image-spec定义了镜像的格式,镜像的格式有以下几…...

竞赛 机器视觉opencv答题卡识别系统
0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 答题卡识别系统 - opencv python 图像识别 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🥇学长这里给一个题目综合评分(每项满分5分…...
Youtube视频下载工具分享-油管视频,音乐,字幕下载方法汇总
YouTube视频下载方法简介 互联网上存在很多 YouTube 下载工具,但我们经常会发现自己收藏的工具没过多久就会失效,我们为大家整理的这几种方法,是存在时间较久并且亲测可用的。后续如果这些工具失效或者有更好的工具,我们也会分享…...

【算法练习Day11】滑动窗口最大值前 K 个高频元素
📝个人主页:Sherry的成长之路 🏠学习社区:Sherry的成长之路(个人社区) 📖专栏链接:练题 🎯长路漫漫浩浩,万事皆有期待 文章目录 滑动窗口最大值前 K 个高频…...
华为云HECS云服务器docker环境下安装nginx
前提:有一台华为云服务器。 华为云HECS云服务器,安装docker环境,查看如下文章。 华为云HECS安装docker-CSDN博客 一、拉取镜像 下载最新版Nginx镜像 (其实此命令就等同于 : docker pull nginx:latest ) docker pull nginx查看镜像 dock…...

GET 和 POST的区别
GET 和 POST 是 HTTP 请求的两种基本方法,要说它们的区别,接触过 WEB 开发的人都能说出一二。 最直观的区别就是 GET 把参数包含在 URL 中,POST 通过 request body 传递参数。 你可能自己写过无数个 GET 和 POST 请求,或者已经看…...
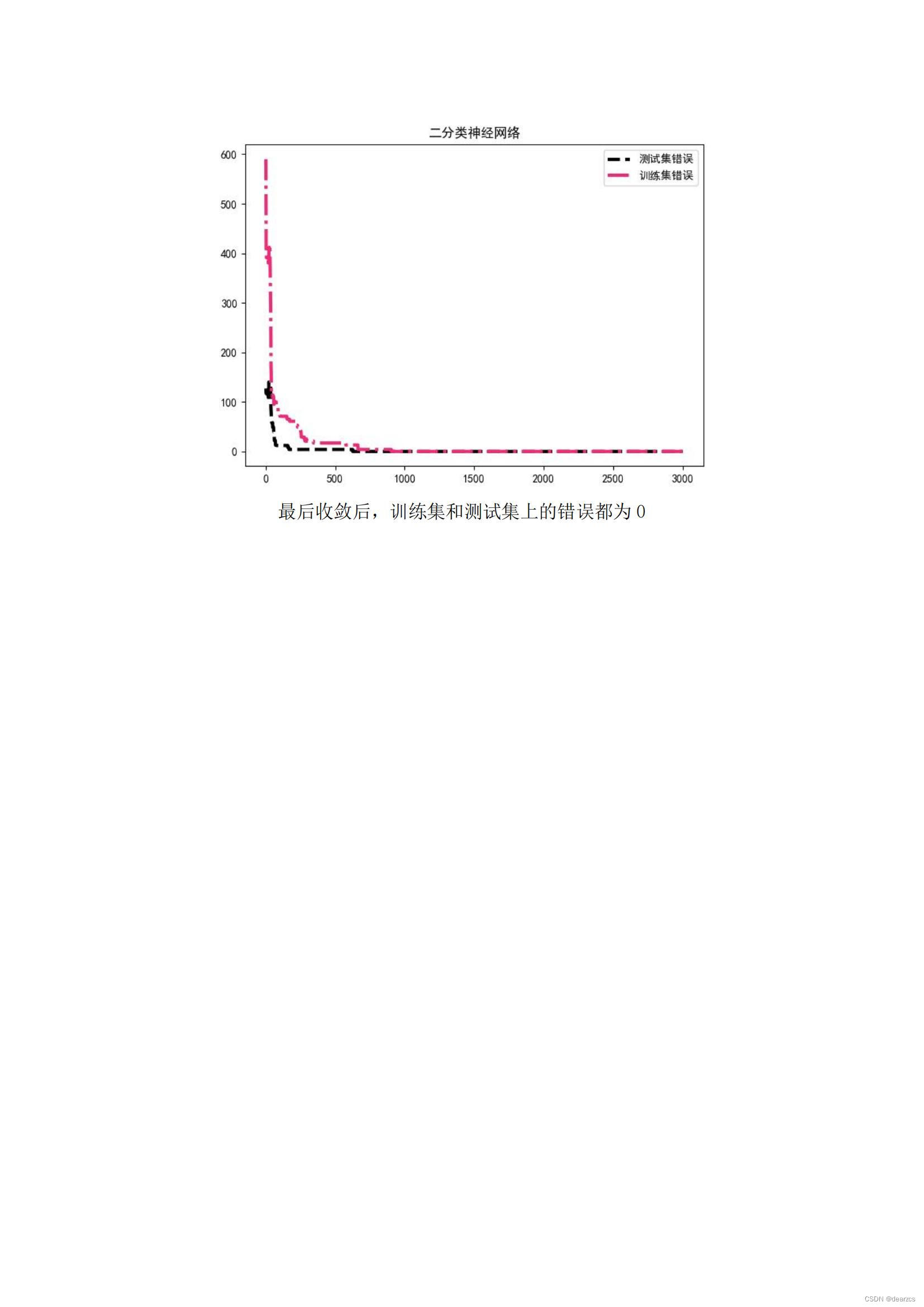
机器学习(监督学习)笔记
目录 总览笔记内容线性回归梯度下降特征缩放多输出线性回归 逻辑回归二分类与逻辑回归分类任务的性能指标(召回率,精度,F1分数等)支持向量机SVMK近邻朴素贝叶斯分类器朴素贝叶斯分类器进阶多分类逻辑回归二分类神经网络多分类神经…...
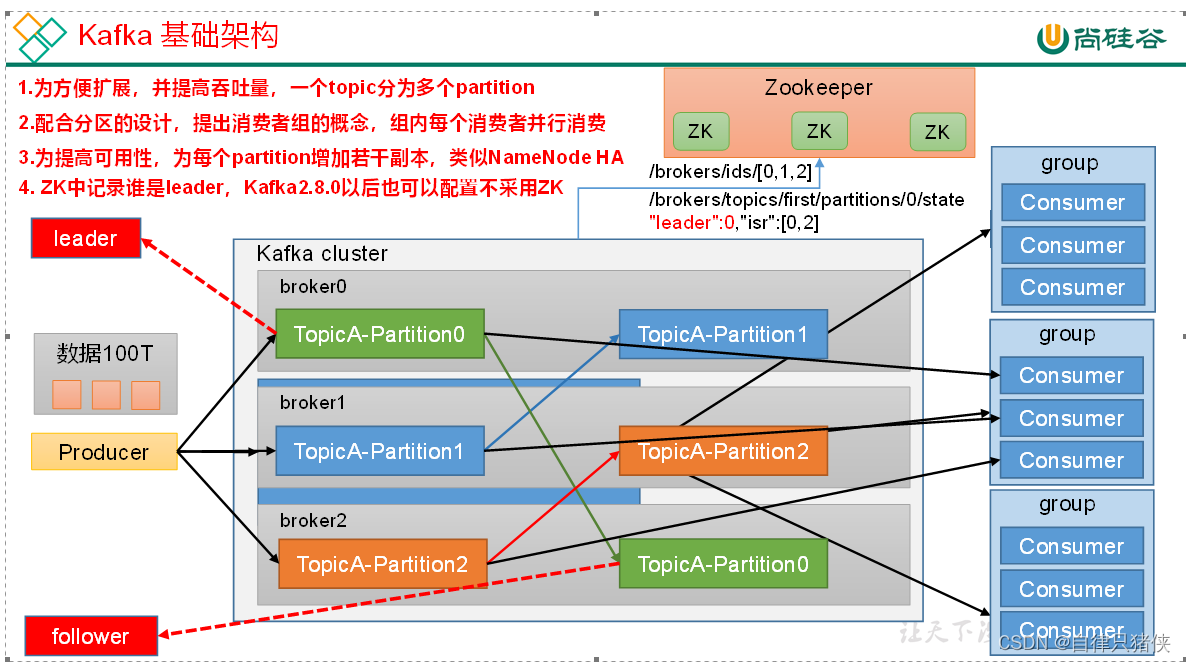
科普rabbitmq,rocketmq,kafka三者的架构比较
对比 架构对比 从架构可以看出三者有些类似,但是在细节上有很多不同。下面我们就从它们的各个组件,介绍它们: RabbitMQ,是一种开源的消息队列中间件。下面是RabbitMQ中与其相关的几个概念: 1.生产者(P…...
)
加密货币交易技巧——地利(二)
EMA指标 针对资金体量大的代币,做现货交易或低倍合约,可参考以下指标: 1.指标介绍:EMA,移动平均线指标,这里只分享中长线用法,非常实用且准确率超高 2.适用群体:适用于现货或低倍…...

服务网关Gateway_微服务中的应用
没有服务网关 问题: 地址太多安全性管理问题 为什么要使用服务网关 网关是微服务架构中不可或缺的部分。使用网关后,客户端和微服务之间的网络结构如下。 注意: 网关统一向外部系统(如访问者、服务)提供REST API。在Sp…...

2G大小的GPU对深度学习的加速效果如何?
训练数据情况 总共42776张224*224*3张图片 Found 42776 files belonging to 9 classes. Using 12833 files for training. 模型参数情况 Total params: 10,917,385 Trainable params: 10,860,745 Non-trainable params: 56,640 batch-size:12 GPU信息 NVIDIA GeForce GT 7…...

intel 一些偏门汇编指令总结
intel 汇编手册下载链接:https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html LDS指令: 手册中可以找到 位于 3-588 根据手册内容猜测:lds r16 m16:16 的作用,是把位于 [m16:16] 内存地址的数…...

python 多个proto文件import引用时出现ModuleNotFoundError错误
问题描述 my_proto文件夹里有两个proto文件,book.proto想要引用person.proto文件中的Person,如下 book.proto syntax "proto2";import "person.proto"; // 导入person.proto文件message Book {optional string name 1;optional …...
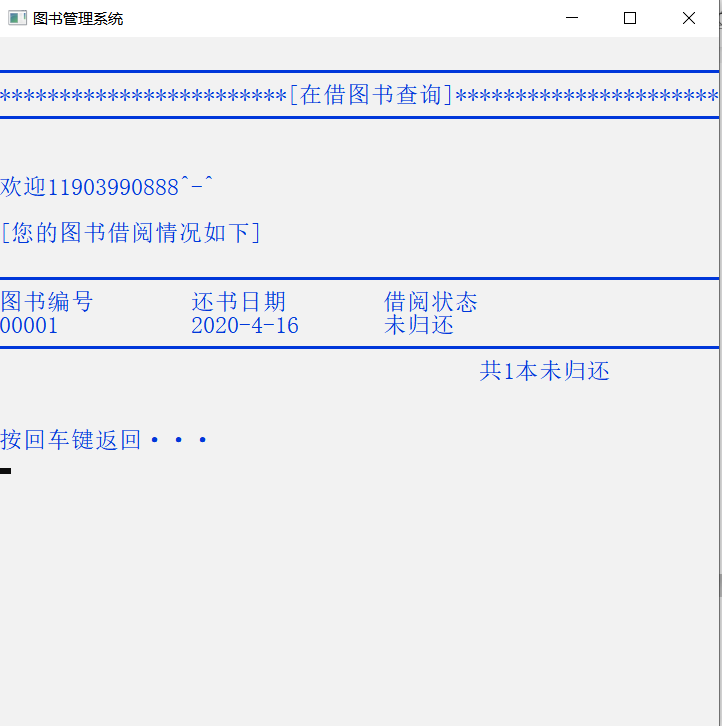
C语言图书管理系统
一、 系统概述 图书管理系统是一个用C语言编写的软件系统,旨在帮助图书馆或图书机构管理其图书馆藏书和读者信息。该系统提供了一套完整的功能,包括图书录入、借阅管理、归还管理、读者管理、图书查询、统计报表等。 二、 系统功能 2.1 图书录入 管理…...

归并排序及其非递归实现
个人主页:Lei宝啊 愿所有美好如期而遇 目录 归并排序递归实现 归并排序非递归实现 归并排序递归实现 图示: 代码: 先分再归并,像是后序一般。 //归并排序 void MergeSort(int* arr, int left, int right) {int* temp (int…...
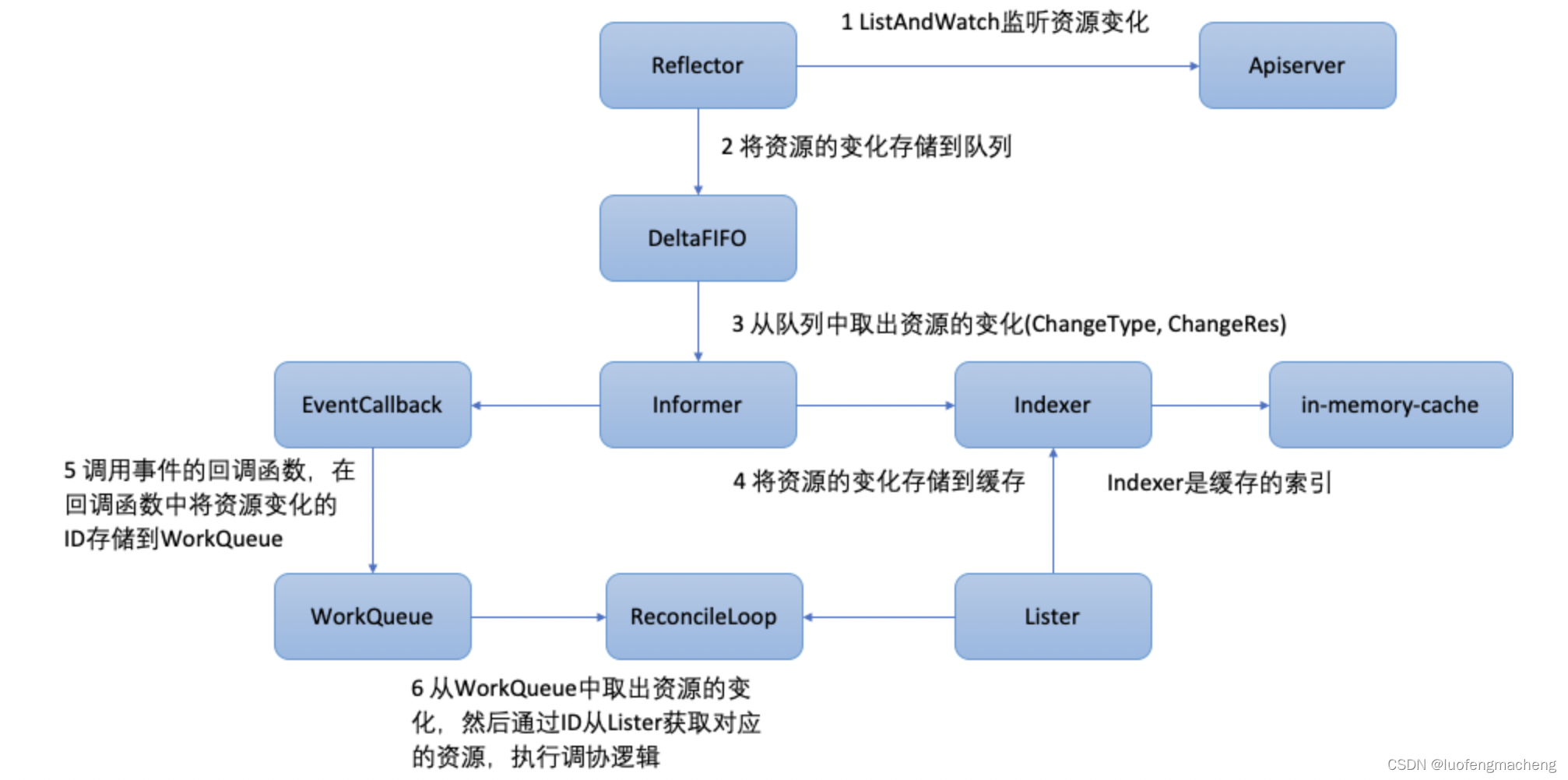
【kubernetes】kubernetes中的Controller
1 什么是Controller? kubernetes采用了声明式API,与声明式API相对应的是命令式API: 声明式API:用户只需要告诉期望达到的结果,系统自动去完成用户的期望命令式API:用户需要关注过程,通过命令一…...

RabbitMQ-死信队列
接上文 RabbitMQ-java使用消息队列 1 死信队列简介 死信队列模式实际上本质是一个死信交换机绑定的死信队列,当正常队列的消息被判定为死信时,会被发送到对应的死信交换机,然后再通过交换机发送到死信队列中,死信队列也有对应的消…...

ElasticSearch - 基于 DSL 、JavaRestClient 实现数据聚合
目录 一、数据聚合 1.1、基本概念 1.1.1、聚合分类 1.1.2、特点 1.2、DSL 实现 Bucket 聚合 1.2.1、Bucket 聚合基础语法 1.2.2、Bucket 聚合结果排序 1.2.3、Bucket 聚合限定范围 1.3、DSL 实现 Metrics 聚合 1.4、基于 JavaRestClient 实现聚合 1.4.1、组装请求 …...
什么是数学建模(mooc笔记)
什么是数学建模 前提:我们数学建模国赛计划选择C题,故希望老师的教学中侧重与C题相关性大的模型及其思想进行培训。之后的学习内容中希望涉及以下知识点: logistic回归相关知识点。如:用法、适用、限制范围等。精学数学建模中常…...

智驾的“眼睛”之争:再议激光雷达的价值——从小鹏袁婷婷两篇文章引发的思考
引言:一场关于“安全感”的行业大讨论 2025年的初夏,中国智能驾驶领域再次掀起了一场关于技术路线的深刻讨论。5月8日和5月16日,小鹏汽车自动驾驶产品高级总监袁婷婷老师先后发表了《小鹏的物理世界基座大模型,和行业现有的自动驾驶模型有什么区别?》及《关于模型参数、蒸…...

三菱FX3U PLC 与昆仑通泰触摸屏控制松下伺服电机使用例程分享
三菱fx3uPLC和昆仑通泰触摸屏控制松下伺服电机使用例程3,带CAD接线图,带伺服电机使用手册最近在项目中捣鼓三菱FX3U PLC和昆仑通泰触摸屏来控制松下伺服电机,过程挺有趣,踩了不少坑,也学到了不少东西,今天就…...

XHS-Downloader数据解析异常全解析:从500错误到多策略兼容的完整解决方案
XHS-Downloader数据解析异常全解析:从500错误到多策略兼容的完整解决方案 【免费下载链接】XHS-Downloader 免费;轻量;开源,基于 AIOHTTP 模块实现的小红书图文/视频作品采集工具 项目地址: https://gitcode.com/gh_mirrors/xh/…...

FireRedASR-AED-L部署案例:高校图书馆讲座录音归档+知识图谱构建
FireRedASR-AED-L部署案例:高校图书馆讲座录音归档知识图谱构建 1. 项目背景与需求 高校图书馆每年举办大量学术讲座和培训活动,这些珍贵的音频资料传统上需要人工整理归档,耗时耗力且容易出错。某高校图书馆面临以下痛点: 音频…...

Linux 的 base32 命令
Linux 的 base32 命令 概述 base32 是 Linux 系统中用于 Base32 编码和解码的命令行工具。Base32 是一种用 32 个可打印字符(A-Z 和 2-7)表示二进制数据的编码方式,常用于在不支持二进制数据的传输环境中安全地传递数据。 基本语法 base3…...

直流调速系统Simulink仿真:包含参数设置代码、Simulink仿真模型及撰写文档
直流调速系统simulink仿真, 用matlab2016a做的。包含三部分 1.参数设置代码 2.simulink仿真模型 3.撰写的直流调速系统docx打开Matlab2016a的瞬间,电机控制老司机的手就开始痒了。今天咱们要搞的是直流电机双闭环调速系统的仿真,这玩意儿在工…...

3大维度释放暗黑破坏神2潜力:PlugY插件从入门到精通的实战指南
3大维度释放暗黑破坏神2潜力:PlugY插件从入门到精通的实战指南 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 价值定位:为什么PlugY是单机玩…...

模拟IC避坑指南:二级运放电流镜负载的PSRR提升方案
模拟IC设计实战:二级运放电流镜负载的PSRR优化策略 在模拟集成电路设计中,电源抑制比(PSRR)是衡量电路对电源噪声抑制能力的关键指标。对于采用电流镜负载的二级运放结构,PSRR性能往往成为制约整体电路精度的瓶颈。本文将深入探讨如何在Virtu…...

Langchain + 通义千问:打造你的第一个多工具智能体
1. 为什么需要Langchain与通义千问的结合 在AI技术快速发展的今天,单一模型已经很难满足复杂场景的需求。想象一下,你有一个非常聪明的助手,但它只会回答问题,却不会帮你查天气、查航班或者处理其他具体事务。这就是为什么我们需要…...

Qwen3-14b_int4_awq部署效果展示:vLLM吞吐提升与Chainlit交互流畅性实测
Qwen3-14b_int4_awq部署效果展示:vLLM吞吐提升与Chainlit交互流畅性实测 1. 模型效果概览 Qwen3-14b_int4_awq是基于Qwen3-14b模型的int4量化版本,采用AngelSlim技术进行压缩优化。在实际部署测试中,该模型展现出两大核心优势: …...