【Java-LangChain:使用 ChatGPT API 搭建系统-2】语言模型,提问范式与 Token
第二章 语言模型,提问范式与 Token
在本章中,我们将和您分享大型语言模型(LLM)的工作原理、训练方式以及分词器(tokenizer)等细节对 LLM 输出的影响。我们还将介绍 LLM 的提问范式(chat format),这是一种指定系统消息(system message)和用户消息(user message)的方式,让您了解如何利用这种能力。
一,环境配置
Helper function 辅助函数。
如果之前曾参加过《ChatGPT Prompt Engineering for Developers》课程,那么对此就相对较为熟悉。 调用该函数输入 Prompt 其将会给出对应的 Completion 。
public String getCompletion(String prompt) {ChatCompletionRequest chatCompletionRequest = new ChatCompletionRequest();chatCompletionRequest.setModel("gpt-3.5-turbo");chatCompletionRequest.setTemperature(0d);ChatMessage chatMessage = new ChatMessage();chatMessage.setRole("user");chatMessage.setContent(prompt);chatCompletionRequest.setMessages(Arrays.asList(chatMessage));ChatCompletionResult result = openAiService.createChatCompletion(chatCompletionRequest);ChatMessage chatMessage1 = result.getChoices().get(0).getMessage();return chatMessage1.getContent();}
二,尝试向模型提问并得到结果
LLM 可以通过使用监督学习来构建,通过不断预测下一个词来学习。 并且,给定一个大的训练集,有数百亿甚至更多的词,你可以创建一个大规模的训练集,你可以从一 句话或一段文本的一部分开始,反复要求语言模型学习预测下一个词是什么
LLM 主要分为两种类型:基础语言模型(Base LLM)和越来越受欢迎的指令微调语言模型(Instruction Tuned LLM)。基础语言模型通过反复预测下一个词来训练,因此如果我们给它一个 Prompt,比如“从前有一只独角兽”,它可能通过逐词预测来完成一个关于独角兽在魔法森林中与其他独角兽朋友们生活的故事。
然而,这种方法的缺点是,如果您给它一个 Prompt,比如“中国的首都是哪里?”,很可能它数据中有一段互联网上关于中国的测验问题列表。这时,它可能会用“中国最大的城市是什么?中国的人口是多少?”等等来回答这个问题。但实际上,您只是想知道中国的首都是什么,而不是列举所有这些问题。然而,指令微调语言模型会尝试遵循 Prompt,并给出“中国的首都是北京”的回答。
那么,如何将基础语言模型转变为指令微调语言模型呢?这就是训练一个指令微调语言模型(例如ChatGPT)的过程。首先,您需要在大量数据上训练基础语言模型,因此需要数千亿个单词,甚至更多。这个过程在大型超级计算系统上可能需要数月时间。训练完基础语言模型后,您会通过在一小部分示例上进行进一步的训练,使模型的输出符合输入的指令。例如,您可以请承包商帮助您编写许多指令示例,并对这些指令的正确回答进行训练。这样就创建了一个用于微调的训练集,让模型学会在遵循指令的情况下预测下一个词是什么。
之后,为了提高语言模型输出的质量,常见的方法是让人类对许多不同输出进行评级,例如是否有用、是否真实、是否无害等。然后,您可以进一步调整语言模型,增加生成高评级输出的概率。这通常使用强化学习中的人类反馈(RLHF)技术来实现。相较于训练基础语言模型可能需要数月的时间,从基础语言模型到指令微调语言模型的转变过程可能只需要数天时间,使用较小规模的数据集和计算资源。
String prompt = "中国的首都是哪里?";String message = this.getCompletion(prompt);log.info("iterative1:\n{}", message);中国的首都是北京。
三,Tokens
到目前为止对 LLM 的描述中,我们将其描述为一次预测一个单词,但实际上还有一个更重要的技术细节。即 LLM 实际上并不是重复预测下一个单词,而是重复预测下一个 token 。当 LLM 接收到输入时,它将将其转换为一系列 token,其中每个 token 都代表常见的字符序列。
例如,对于 “Learning new things is fun!” 这句话,每个单词都被转换为一个 token ,而对于较少使用的单词,如 “Prompting as powerful developer tool”,单词 “prompting” 会被拆分为三个 token,即"prom"、“pt"和"ing”。
当您要求 ChatGPT 颠倒 “lollipop” 的字母时,由于分词器(tokenizer) 将 “lollipop” 分解为三个 token,即 “l”、“oll”、“ipop”,因此 ChatGPT 难以正确输出字母的顺序。您可以通过在字母之间添加连字符或空格的方式,使分词器将每个字母分解为单独的 token,从而帮助 ChatGPT 更好地认识单词中的每个字母并正确输出它们。
String prompt = "Take the letters in lollipop \n" +"and reverse them";String message = this.getCompletion(prompt);//The reversed letters of "lollipop" are "pillipol".//实际上 lollipop 的 翻转是 popillollog.info("test2:\n{}", message);String prompt1 = "Take the letters in\n" +"l-o-l-l-i-p-o-p and reverse them";String message1 = this.getCompletion(prompt1);//p-o-p-i-l-l-o-l//这次正确了log.info("test2:\n{}", message1);对于英文输入,一个 token 一般对应 4 个字符或者四分之三个单词;对于中文输入,一个 token 一般对应一个或半个词。
不同模型有不同的 token 限制,需要注意的是,这里的 token 限制是输入的 Prompt 和输出的 completion 的 token 数之和,因此输入的 Prompt 越长,能输出的 completion 的上限就越低。
ChatGPT3.5-turbo 的 token 上限是 4096。
四,Helper function 辅助函数 (提问范式)
下图是 OpenAI 提供的一种提问范式,接下来吴恩达老师就是在演示如何利用这种范式进行更好的提问

System 信息用于指定模型的规则,例如设定、回答准则等,而 assistant 信息就是让模型完成的具体指令
ChatCompletionRequest chatCompletionRequest = new ChatCompletionRequest();//调用的模型,默认为 gpt-3.5-turbo(ChatGPT),有内测资格的用户可以选择 gpt-4\chatCompletionRequest.setModel("gpt-3.5-turbo");//决定模型输出的随机程度,默认为0,表示输出将非常确定。增加温度会使输出更随机。chatCompletionRequest.setTemperature(temperature);//这决定模型输出的最大的 token 数。chatCompletionRequest.setMaxTokens(500);//是一个消息列表,每个消息都是一个字典,包含 role(角色)和 content(内容)。角色可以是'system'、'user' 或 'assistant’,内容是角色的消息。chatCompletionRequest.setMessages(chatMessages);ChatCompletionResult result = openAiService.createChatCompletion(chatCompletionRequest);ChatMessage chatMessage1 = result.getChoices().get(0).getMessage();return chatMessage1.getContent();List<ChatMessage> chatMessages = new ArrayList<>();ChatMessage chatMessage = new ChatMessage();chatMessage.setRole("system");chatMessage.setContent("你是一个助理, 并以 Seuss 苏斯博士的风格作出回答。");chatMessages.add(chatMessage);ChatMessage chatMessage2 = new ChatMessage();chatMessage2.setRole("user");chatMessage2.setContent("就快乐的小鲸鱼为主题给我写一首短诗");chatMessages.add(chatMessage2);String message1 = this.getCompletionFromMessage(chatMessages, 1);log.info("test3:\n{}", message1);test3:
在大海深处有一只小鲸鱼,
游来游去像个顽皮的小露珠。
它喜欢跳跃在波浪中,
展现出它的自由和活力。它的背上有绚丽的颜色,
像艳阳般明亮,充满温暖的力量。
在阳光下闪烁的小鱼鳍,
给人们带来无尽的欢乐和惊喜。它和鱼群一起游弋在大海里,
快乐洋溢在每一刻,
它们跳跃、转圈、翻滚,
把欢乐传递给每个人。小鲸鱼是快乐的使者,
散发着温暖和爱的气息。
让我们跟随它的脚步,
一起享受快乐的时光的魔力。快乐的小鲸鱼如此独特,
带给我们世界的色彩和美丽。
让我们永远怀抱快乐和希望,
像小鲸鱼一样,自由地飞扬起舞。
List<ChatMessage> chatMessages = new ArrayList<>();ChatMessage chatMessage = new ChatMessage();chatMessage.setRole("system");//长度控制chatMessage.setContent("你的所有答复只能是一句话");chatMessages.add(chatMessage);ChatMessage chatMessage2 = new ChatMessage();chatMessage2.setRole("user");chatMessage2.setContent("写一个关于快乐的小鲸鱼的故事");chatMessages.add(chatMessage2);String message1 = this.getCompletionFromMessage(chatMessages, 1);log.info("test4:\n{}", message1);
小鲸鱼在海洋里游来游去,快乐地和海洋里的朋友们玩耍,感受着无尽的快乐和自由。
把以上的要求用一句话结合起来
List<ChatMessage> chatMessages = new ArrayList<>();ChatMessage chatMessage = new ChatMessage();chatMessage.setRole("system");//结合chatMessage.setContent("你是一个助理, 并以 Seuss 苏斯博士的风格作出回答,只回答一句话");chatMessages.add(chatMessage);ChatMessage chatMessage2 = new ChatMessage();chatMessage2.setRole("user");chatMessage2.setContent("写一个关于快乐的小鲸鱼的故事");chatMessages.add(chatMessage2);String message1 = this.getCompletionFromMessage(chatMessages, 1);log.info("test5:\n{}", message1);
在蓝色的海洋里,快乐的小鲸鱼欢快地跳跃,它的笑声如波浪般荡漾,带来了幸福的感觉。
最后,我们认为 Prompt 对 AI 应用开发的革命性影响仍未得到充分重视低。在传统的监督机器学习工作流中,如果想要构建一个可以将餐厅评论分类为正面或负面的分类器,首先需要获取一大批带有标签的数据,可能需要几百个,这个过程可能需要几周,甚至一个月的时间。接着,您需要在这些数据上训练一个模型,找到一个合适的开源模型,并进行模型的调整和评估,这个阶段可能需要几天、几周,甚至几个月的时间。最后,您可能需要使用云服务来部署模型,将模型上传到云端,并让它运行起来,才能最终调用您的模型。整个过程通常需要一个团队数月时间才能完成。
相比之下,使用基于 Prompt 的机器学习方法,当您有一个文本应用时,只需提供一个简单的 Prompt 就可以了。这个过程可能只需要几分钟,如果需要多次迭代来得到有效的 Prompt 的话,最多几个小时即可完成。在几天内(尽管实际情况通常是几个小时),您就可以通过 API 调用来运行模型,并开始使用。一旦您达到了这个步骤,只需几分钟或几个小时,就可以开始调用模型进行推理。
因此,以前可能需要花费六个月甚至一年时间才能构建的应用,现在只需要几分钟或几个小时,最多是几天的时间,就可以使用 Prompt 构建起来。这种方法正在极大地改变 AI 应用的快速构建方式。
需要注意的是,这种方法适用于许多非结构化数据应用,特别是文本应用,以及越来越多的视觉应用,尽管目前的视觉技术仍在发展中。但它并不适用于结构化数据应用,也就是那些处理 Excel 电子表格中大量数值的机器学习应用。然而,对于适用于这种方法的应用,AI 组件可以被快速构建,并且正在改变整个系统的构建工作流。构建整个系统可能仍然需要几天、几周或更长时间,但至少这部分可以更快地完成。
Java快速转换到大模型开发:
配套课程的所有代码已经发布在:https://github.com/Starcloud-Cloud/java-langchain
课程合作请留言
相关文章:
【Java-LangChain:使用 ChatGPT API 搭建系统-2】语言模型,提问范式与 Token
第二章 语言模型,提问范式与 Token 在本章中,我们将和您分享大型语言模型(LLM)的工作原理、训练方式以及分词器(tokenizer)等细节对 LLM 输出的影响。我们还将介绍 LLM 的提问范式(chat format…...

想要精通算法和SQL的成长之路 - 最长连续序列
想要精通算法和SQL的成长之路 - 最长连续序列 前言一. 最长连续序列1.1 并查集数据结构创建1.2 find 查找1.3 union 合并操作1.4 最终代码 前言 想要精通算法和SQL的成长之路 - 系列导航 并查集的运用 一. 最长连续序列 原题链接 这个题目,如何使用并查集是一个小难…...
- 制图(Draft)-工程图框选制图曲线并输出制图曲线的信息)
UG NX二次开发(C#)- 制图(Draft)-工程图框选制图曲线并输出制图曲线的信息
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1、前言2、在UG NX中打开一个装配体模型3、进入工程制图模块,创建工程制图4、在VS中创建一个工程项目5、在Main()中添加选择的代码(UFun)6、在Main()中添加选择的代码(NXOpen)7、框选解决方案…...

1.7.C++项目:仿muduo库实现并发服务器之Poller模块的设计
项目完整在: 文章目录 一、Poller模块:描述符IO事件监控模块二、提供的功能三、实现思想(一)功能(二)意义(三)功能设计 四、封装思想五、代码(一)框架&#…...

Flutter笔记:build方法、构建上下文BuildContext解析
Flutter笔记 build 方法解析 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/qq_28550263/article/details/133556333 本文主要介绍Flu…...

composer 安装和基本使用
php的包管理软件 如果没有安装php,参考这篇:添加链接描述 1.composer安装 composer官网 需要先安装好php,同时php -v输出有信息 cd /usr/localphp -r "copy(https://install.phpcomposer.com/installer, composer-setup.php);"…...

Ubuntu配置深度学习环境(TensorFlow和PyTorch)
文章目录 一、CUDA安装1.1 安装显卡驱动1.2 CUDA安装1.3 安装cuDNN 二、Anaconda安装三、安装TensorFlow和pyTorch3.1 安装pyTorch3.2 安装TensorFlow2 四、安装pyCharm4.1 pyCharm的安装4.2 关联anaconda的Python解释器 五、VScode配置anaconda的Python虚拟环境 前言ÿ…...

【产品经理】国内企业服务SAAS平台的生存与发展
SaaS在国外发展的比较成熟,甚至已经成为了主流,但在国内这几年才掀起热潮;企业服务SaaS平台在少部分行业发展较快,大部分行业在国内还处于起步、探索阶段;SaaS将如何再国内生存和发展? 在企业服务行业做了五…...

【vue 首屏加载优化】
Vue 首屏加载优化指的是通过一系列的技术手段,尽可能地缩短首屏(即页面中可见的部分)的加载时间,提高用户体验。 以下是一些常见的 Vue 首屏加载优化技巧: 使用 Vue SSR(服务端渲染)࿱…...

docker--redis容器部署及与SpringBoot整合-I
文章目录 1. 容器化部署docker2. 如何与SpringBoot集成2.1. 引入依赖2.2. 添加配置信息2.3. 测试类2.4. 内置的Spring Beansredis 主流客户端比较redissonlettucejedis参考1. 容器化部署docker 拉取镜像创建数据目录data 及 配置目录conf创建配置文件redis.conf启动redis容器进…...

力扣 -- 518. 零钱兑换 II(完全背包问题)
解题步骤: 参考代码: 未优化代码: class Solution { public:int change(int amount, vector<int>& coins) {int ncoins.size();//多开一行,多开一列vector<vector<int>> dp(n1,vector<int>(amount1…...
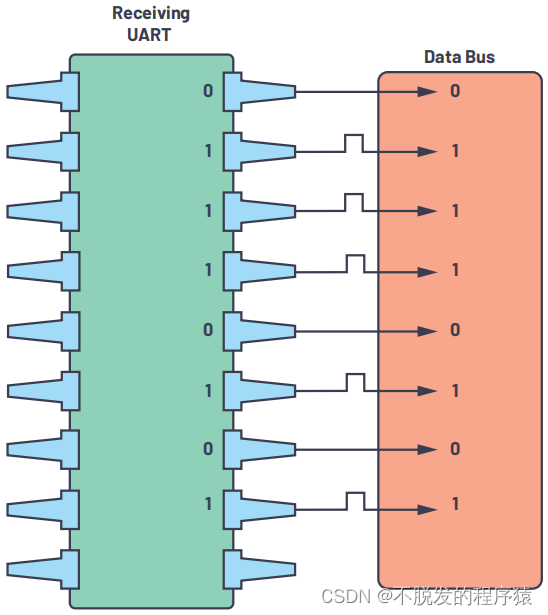
一文搞懂UART通信协议
目录 1、UART简介 2、UART特性 3、UART协议帧 3.1、起始位 3.2、数据位 3.3、奇偶校验位 3.4、停止位 4、UART通信步骤 1、UART简介 UART(Universal Asynchronous Receiver/Transmitter,通用异步收发器)是一种双向、串行、异步的通信…...
【算法|动态规划No.7】leetcode300. 最长递增子序列
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【手撕算法系列专栏】【LeetCode】 🍔本专栏旨在提高自己算法能力的同时,记录一下自己的学习过程,希望…...

LeetCode 54 螺旋矩阵
先贴代码 class Solution {public int[][] generateMatrix(int n) {int left 0;int right n-1;int up 0;int down n-1;int[][] result new int[n][n];int number 0;while(left < right && up < down) {for(int ileft;i<right;i) {number;result[up]…...

OpenCV 概念、整体架构、各模块主要功能
文章目录 1. OpenCV 概念2 OpenCV主要模块3 各模块 详细介绍3.1 calib3d 标定3.2 core 核心功能模块3.4 features2d 二维特征3.5 flann 快速近似近邻算法库3.7 highgui 高级图形用户界面3.9 imgproc 图像处理模块3.10 ml 机器学习模块3.11 objdetect 目标检测模块3.12 photo 数…...

组合数与莫队——组合数前缀和
用莫队求组合数是一种常见套路 莫队求 S ( n , m ) ∑ i 0 m ( n i ) S(n,m)\sum_{i0}^m\binom n i S(n,m)∑i0m(in) S ( n , m 1 ) S(n,m1) S(n,m1) 直接做个差,然后就相当于加上 ( n i 1 ) \binom n {i1} (i1n) 求 S ( n 1 , m ) S(n1,m) S(n1,m)…...
stm32之雨滴传感器使用记录
一、简介 雨滴传感器、烟雾传感器(MQ2)、轨迹传感器、干黄管等的原理都类似,都是将检测到的信号通过LM393进行处理之后再输出,可以输出数字信号DO(0和1)和模拟信号A0。 雨滴传感器在正常情况下是AO输出的是…...
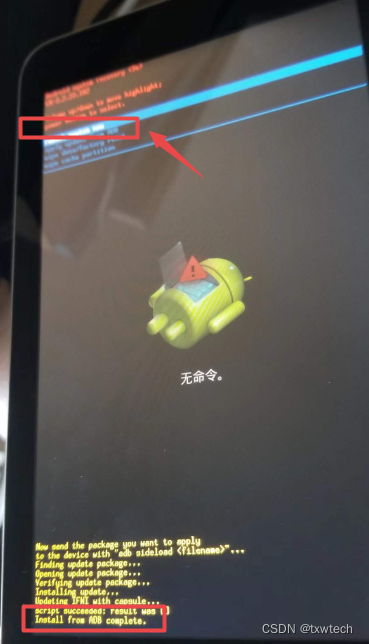
华硕平板k013me176cx线刷方法
1.下载adb刷机工具, 或者刷机精灵 2.下载刷机rom包 华硕asus k013 me176cx rom固件刷机包-CSDN博客 3.平板进入刷机界面 进入方法参考: ASUS (k013) ME176CX不进入系统恢复出厂设置的方法-CSDN博客 4.解压ME176C-CN-3_2_23_182.zip,把UL-K013-CN-3.2.…...
C#停车场管理系统
目录 一、绪论1.1内容简介及意义1.2开发工具及技术介绍 二、总体设计2.1系统总体架构2.2登录模块总体设计2.3主界面模块总体设计2.4停车证管理模块总体设计2.5停车位管理模块总体设计2.6员工管理模块总体设计2.7其他模块总体设计 三、详细设计3.1登录模块设计3.2主界面模块设计…...
C++:stl:stack、queue、priority_queue介绍及模拟实现和容量适配器deque介绍
本文主要介绍c中stl的栈、队列和优先级队列并对其模拟实现,对deque进行一定介绍并在栈和队列的模拟实现中使用。 目录 一、stack的介绍和使用 1.stack的介绍 2.stack的使用 3.stack的模拟实现 二、queue的介绍和使用 1.queue的介绍 2.queue的使用 3.queue的…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

pycharm 设置环境出错
pycharm 设置环境出错 pycharm 新建项目,设置虚拟环境,出错 pycharm 出错 Cannot open Local Failed to start [powershell.exe, -NoExit, -ExecutionPolicy, Bypass, -File, C:\Program Files\JetBrains\PyCharm 2024.1.3\plugins\terminal\shell-int…...

Neko虚拟浏览器远程协作方案:Docker+内网穿透技术部署实践
前言:本文将向开发者介绍一款创新性协作工具——Neko虚拟浏览器。在数字化协作场景中,跨地域的团队常需面对实时共享屏幕、协同编辑文档等需求。通过本指南,你将掌握在Ubuntu系统中使用容器化技术部署该工具的具体方案,并结合内网…...
uni-app学习笔记三十五--扩展组件的安装和使用
由于内置组件不能满足日常开发需要,uniapp官方也提供了众多的扩展组件供我们使用。由于不是内置组件,需要安装才能使用。 一、安装扩展插件 安装方法: 1.访问uniapp官方文档组件部分:组件使用的入门教程 | uni-app官网 点击左侧…...

Java 与 MySQL 性能优化:MySQL 慢 SQL 诊断与分析方法详解
文章目录 一、开启慢查询日志,定位耗时SQL1.1 查看慢查询日志是否开启1.2 临时开启慢查询日志1.3 永久开启慢查询日志1.4 分析慢查询日志 二、使用EXPLAIN分析SQL执行计划2.1 EXPLAIN的基本使用2.2 EXPLAIN分析案例2.3 根据EXPLAIN结果优化SQL 三、使用SHOW PROFILE…...
:电商转化率优化与网站性能的底层逻辑)
精益数据分析(98/126):电商转化率优化与网站性能的底层逻辑
精益数据分析(98/126):电商转化率优化与网站性能的底层逻辑 在电子商务领域,转化率与网站性能是决定商业成败的核心指标。今天,我们将深入解析不同类型电商平台的转化率基准,探讨页面加载速度对用户行为的…...

简约商务通用宣传年终总结12套PPT模版分享
IOS风格企业宣传PPT模版,年终工作总结PPT模版,简约精致扁平化商务通用动画PPT模版,素雅商务PPT模版 简约商务通用宣传年终总结12套PPT模版分享:商务通用年终总结类PPT模版https://pan.quark.cn/s/ece1e252d7df...