《机器学习实战》学习记录-ch2
PS: 个人笔记,建议不看
原书资料:https://github.com/ageron/handson-ml2
2.1数据获取
import pandas as pd
data = pd.read_csv(r"C:\Users\cyan\Desktop\AI\ML\handson-ml2\datasets\housing\housing.csv")
data.head()
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 10 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 longitude 20640 non-null float641 latitude 20640 non-null float642 housing_median_age 20640 non-null float643 total_rooms 20640 non-null float644 total_bedrooms 20433 non-null float645 population 20640 non-null float646 households 20640 non-null float647 median_income 20640 non-null float648 median_house_value 20640 non-null float649 ocean_proximity 20640 non-null object
dtypes: float64(9), object(1)
memory usage: 1.6+ MB
data.columns
Index(['longitude', 'latitude', 'housing_median_age', 'total_rooms','total_bedrooms', 'population', 'households', 'median_income','median_house_value', 'ocean_proximity'],dtype='object')
data['ocean_proximity'].value_counts().plot()

data.describe()
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | |
|---|---|---|---|---|---|---|---|---|---|
| count | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20433.000000 | 20640.000000 | 20640.000000 | 20640.000000 | 20640.000000 |
| mean | -119.569704 | 35.631861 | 28.639486 | 2635.763081 | 537.870553 | 1425.476744 | 499.539680 | 3.870671 | 206855.816909 |
| std | 2.003532 | 2.135952 | 12.585558 | 2181.615252 | 421.385070 | 1132.462122 | 382.329753 | 1.899822 | 115395.615874 |
| min | -124.350000 | 32.540000 | 1.000000 | 2.000000 | 1.000000 | 3.000000 | 1.000000 | 0.499900 | 14999.000000 |
| 25% | -121.800000 | 33.930000 | 18.000000 | 1447.750000 | 296.000000 | 787.000000 | 280.000000 | 2.563400 | 119600.000000 |
| 50% | -118.490000 | 34.260000 | 29.000000 | 2127.000000 | 435.000000 | 1166.000000 | 409.000000 | 3.534800 | 179700.000000 |
| 75% | -118.010000 | 37.710000 | 37.000000 | 3148.000000 | 647.000000 | 1725.000000 | 605.000000 | 4.743250 | 264725.000000 |
| max | -114.310000 | 41.950000 | 52.000000 | 39320.000000 | 6445.000000 | 35682.000000 | 6082.000000 | 15.000100 | 500001.000000 |
import matplotlib.pyplot as plt
%matplotlib inline # 这是IPython的内置绘图命令,PyCharm用不了,可以省略plt.show()
#data.hist(bins=100,figsize=(20,15),column = 'longitude') # 选一列
# 绘制直方图
data.hist(bins=50,figsize=(20,15)) # bins 代表柱子的数目,高度为覆盖宽度内取值数目之和# plt.show()

# 划分数据集与测试集
import numpy as np
# 自定义划分函数
def split_train_test(data, test_ratio):shuffled_indices = np.random.permutation(len(data)) # 将 0 ~ len(data) 随机打乱test_set_size = int(len(data) * test_ratio)test_indices = shuffled_indices[:test_set_size]train_indices = shuffled_indices[test_set_size:]return data.iloc[train_indices], data.iloc[test_indices]
train_data,test_data = my_split_train_test(data,.2)
len(train_data),len(test_data)
(16512, 4128)
from sklearn.model_selection import train_test_split
# 利用 sklean的包 切分数据集,random_state 类似 np.random.seed(42), 保证了每次运行切分出的测试集相同
train_set, test_set = train_test_split(data, test_size=0.2, random_state=42)
len(train_set),len(test_set)
(16512, 4128)
# 但是仅仅随机抽取作为测试集是不合理的,要保证测试集的数据分布跟样本一致
# 创建收入类别属性,为了服从房价中位数的分布对数据进行划分
data["income_cat"] = pd.cut(data["median_income"],bins=[0., 1.5, 3.0, 4.5, 6., np.inf],labels=[1, 2, 3, 4, 5])
# 分层抽样
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42) #
for train_index, test_index in split.split(data, data["income_cat"]):strat_train_set = data.loc[train_index]strat_test_set = data.loc[test_index]
# 查看测试集数据分布比例
strat_test_set["income_cat"].value_counts() / len(strat_test_set),data["income_cat"].value_counts() / len(data)
(3 0.3505332 0.3187984 0.1763575 0.1143411 0.039971Name: income_cat, dtype: float64,3 0.3505812 0.3188474 0.1763085 0.1144381 0.039826Name: income_cat, dtype: float64)
# 删除添加的 income_cat 属性
strat_test_set.drop("income_cat",axis=1,inplace=True)
strat_train_set.drop("income_cat",axis=1,inplace=True)
# 或者如此删除,可能效率更高,或者更美观吧
for set_ in (strat_train_set, strat_test_set):set_.drop("income_cat", axis=1, inplace=True)
相关文章:
《机器学习实战》学习记录-ch2
PS: 个人笔记,建议不看 原书资料:https://github.com/ageron/handson-ml2 2.1数据获取 import pandas as pd data pd.read_csv(r"C:\Users\cyan\Desktop\AI\ML\handson-ml2\datasets\housing\housing.csv")data.head() data.info()<clas…...
lv7 嵌入式开发-网络编程开发 07 TCP服务器实现
目录 1 函数介绍 1.1 socket函数 与 通信域 1.2 bind函数 与 通信结构体 1.3 listen函数 与 accept函数 2 TCP服务端代码实现 3 TCP客户端代码实现 4 代码优化 5 练习 1 函数介绍 其中read、write、close在IO中已经介绍过,只需了解socket、bind、listen、acc…...
mysql技术文档--阿里巴巴java准则《Mysql数据库建表规约》--结合阿丹理解尝试解读--国庆开卷
阿丹: 国庆快乐呀大家! 在项目开始前一个好的设计、一个健康的表关系,不仅会让开发变的有趣舒服,也会在后期的维护和升级迭代中让系统不断的成长。那么今天就认识和解读一下阿里的准则!! 建表规约 表达是…...
Qt+openCV学习笔记(十六)Qt6.6.0rc+openCV4.8.1+emsdk3.1.37编译静态库
前言: 有段时间没来写文章了,趁编译库的空闲,再写一篇记录文档 WebAssembly的发展逐渐成熟,即便不了解相关技术,web前端也在不经意中使用了相关技术的库,本篇文档记录下如何编译WebAssembly版本的openCV&…...

JUC第十四讲:JUC锁: ReentrantReadWriteLock详解
JUC第十四讲:JUC锁: ReentrantReadWriteLock详解 本文是JUC第十四讲:JUC锁 - ReentrantReadWriteLock详解。ReentrantReadWriteLock表示可重入读写锁,ReentrantReadWriteLock中包含了两种锁,读锁ReadLock和写锁WriteLockÿ…...

在vue3中使用vite-svg-loader插件
vite-svg-loader插件可以让我们像使用vue组件那样使用svg图,使用起来超级方便。 安装 npm install vite-svg-loader --save-dev使用 import svgLoader from vite-svg-loaderexport default defineConfig({plugins: [vue(), svgLoader()] })组件里使用 在路径后加…...
国庆10.4
QT实现TCP服务器客户端 服务器 头文件 #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QTcpServer> //服务器头文件 #include <QTcpSocket> //客户端头文件 #include <QList> //链表容器 #include <QMe…...

2023/8/12 下午8:41:46 树状控件guilite
2023/8/12 下午8:41:46 树状控件guilite 2023/8/12 下午8:42:08 树状控件(Tree View)是一种常见的图形用户界面(GUI)元素,它通常用于显示层次结构数据或文件系统的目录结构。Guilite 是一个轻量级的跨平台 GUI 库,支持多种控件,包括树状控件。 在 Guilite 中使用树状…...
BL808学习日志-2-LVGL for M0 and D0
一、lvgl测试环境 对拿到的M1S_DOCK开发板进行开发板测试,博流的官方SDK是支持M0和D0两个内核都进行测试的;但是目前只实现了M0的LVGLBenchmark,测试D0内核中发现很多莫名其妙的问题。一会详细记录。 使用的是开发板自带的SPI显示屏ÿ…...

treectrl类封装 2023/8/13 下午4:07:35
2023/8/13 下午4:07:35 treectrl类封装 2023/8/13 下午4:07:53 TreeCtrl 类是一个常用的图形用户界面控件,用于实现树形结构的展示和交互。以下是一个简单的 TreeCtrl 类的封装示例: python import wxclass MyTreeCtrl(wx.TreeCtrl):def __init__(self, parent):super()…...
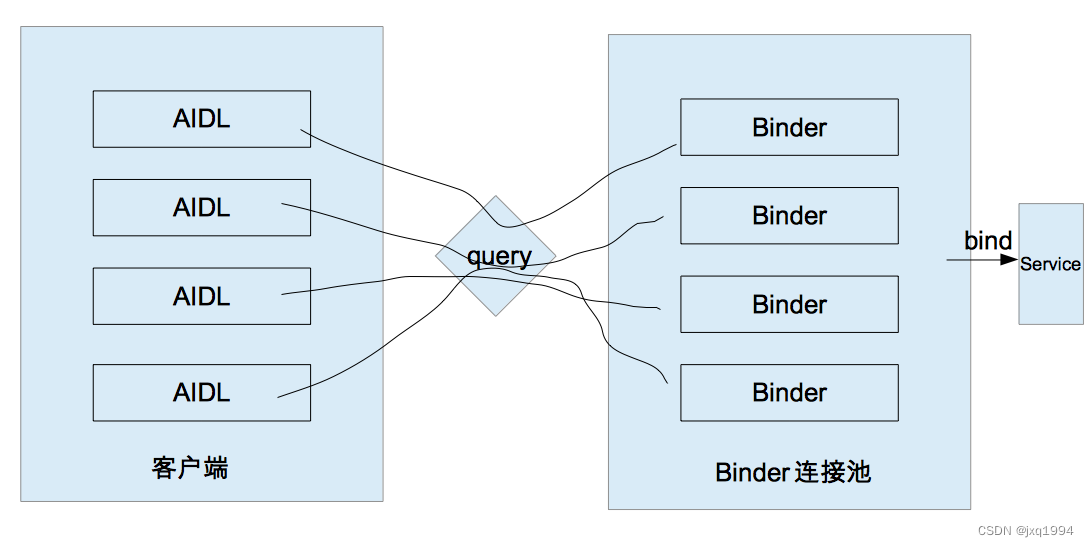
Android学习之路(20) 进程间通信
IPC IPC为 (Inter-Process Communication) 缩写,称为进程间通信或跨进程通信,指两个进程间进行数据交换的过程。安卓中主要采用 Binder 进行进程间通信,当然也支持其他 IPC 方式,如:管道,Socket࿰…...
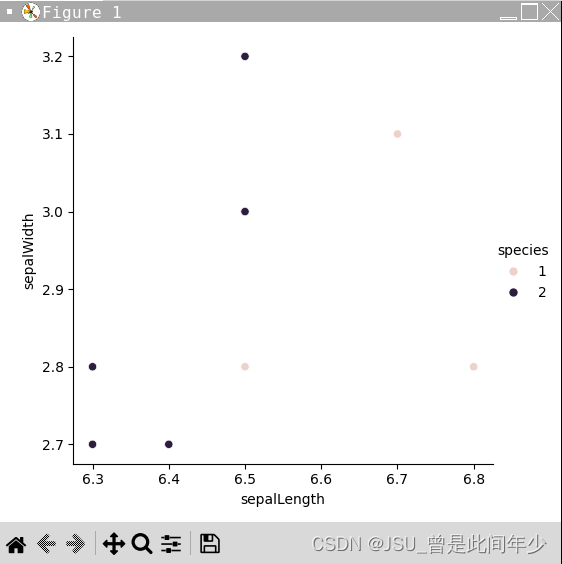
机器学习——KNN算法流程详解(以iris为例)
、 目 录 前情说明 问题陈述 数据说明 KNN算法流程概述 代码实现 运行结果 基于可视化的改进 可视化代码 全部数据可视化总览 分类投票结果 改进后最终代码 前情说明 本书基于《特征工程入门与入门与实践》庄家盛 译版P53页K最近邻(KNN)算…...
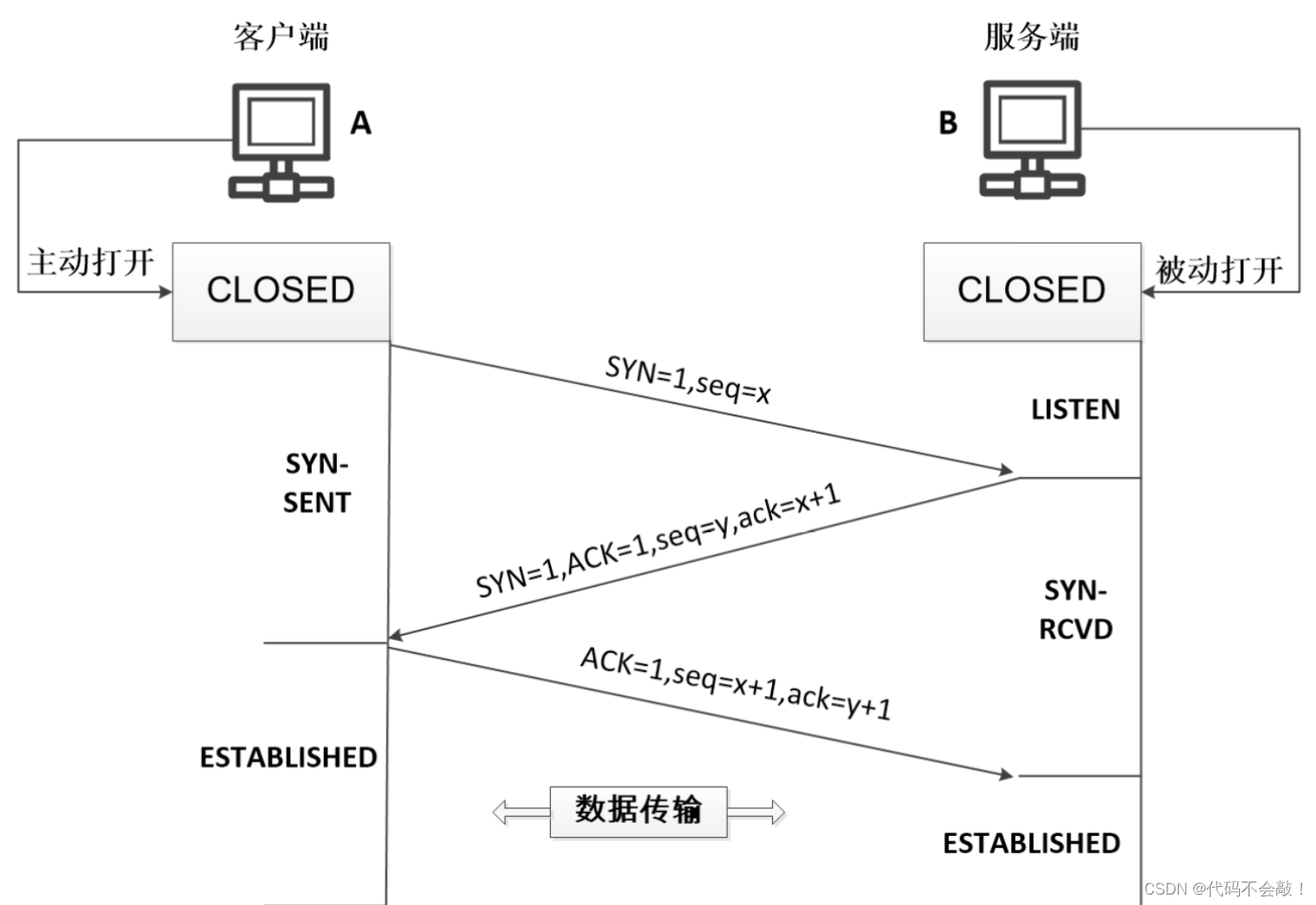
国庆假期day5
作业:请写出七层模型及每一层的功能,请绘制三次握手四次挥手的流程图 1.OSI七层模型: 应用层--------提供函 表示层--------表密缩 会话层--------会话 传输层--------进程的接收和发送 网络层--------寻主机 数据链路层----相邻节点的可靠传…...

ES6中的let、const
let ES6中新增了let命令,用来声明变量,和var类似但是也有一定的区别 1. 块级作用域 只能在当前作用域内使用,各个作用域不能互相使用,否则会报错。 {let a 1;var b 1; } console.log(a); // 会报错 console.log(b); // 1为什…...

Python 列表操作指南3
示例,将新列表中的所有值设置为 ‘hello’: newlist [hello for x in fruits]表达式还可以包含条件,不像筛选器那样,而是作为操纵结果的一种方式: 示例,返回 “orange” 而不是 “banana”: …...
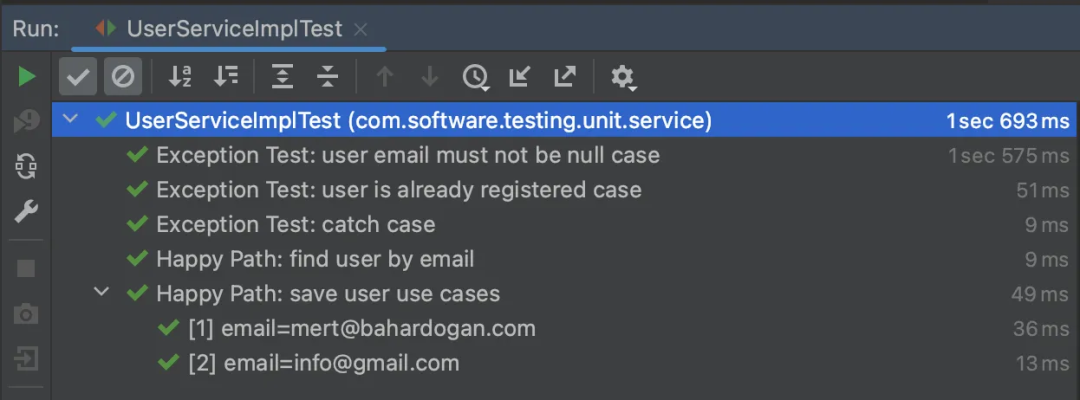
三个要点,掌握Spring Boot单元测试
单元测试是软件开发中不可或缺的重要环节,它用于验证软件中最小可测试单元的准确性。结合运用Spring Boot、JUnit、Mockito和分层架构,开发人员可以更便捷地编写可靠、可测试且高质量的单元测试代码,确保软件的正确性和质量。 一、介绍 本文…...
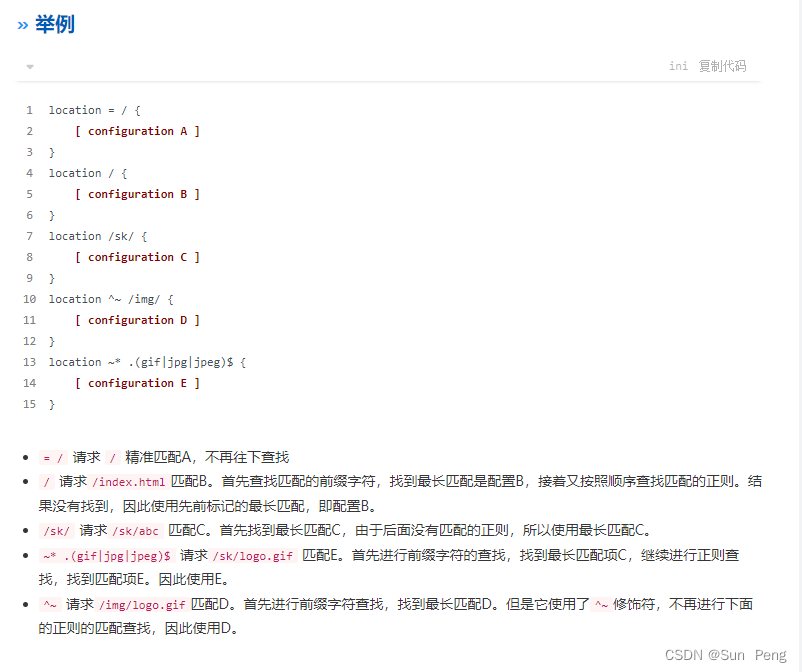
【nginx】Nginx配置:
文章目录 一、什么是Nginx:二、为什么使用Nginx:三、如何处理请求:四、什么是正向代理和反向代理:五、nginx 启动和关闭:六、目录结构:七、配置文件nginx.conf:八、location:九、单页…...

CSS3与HTML5
box-sizing content-box:默认,宽高包不含边框和内边距 border-box:也叫怪异盒子,宽高包含边框和内边距 动画:移动translate,旋转、transform等等 走马灯:利用动画实现animation:from…...
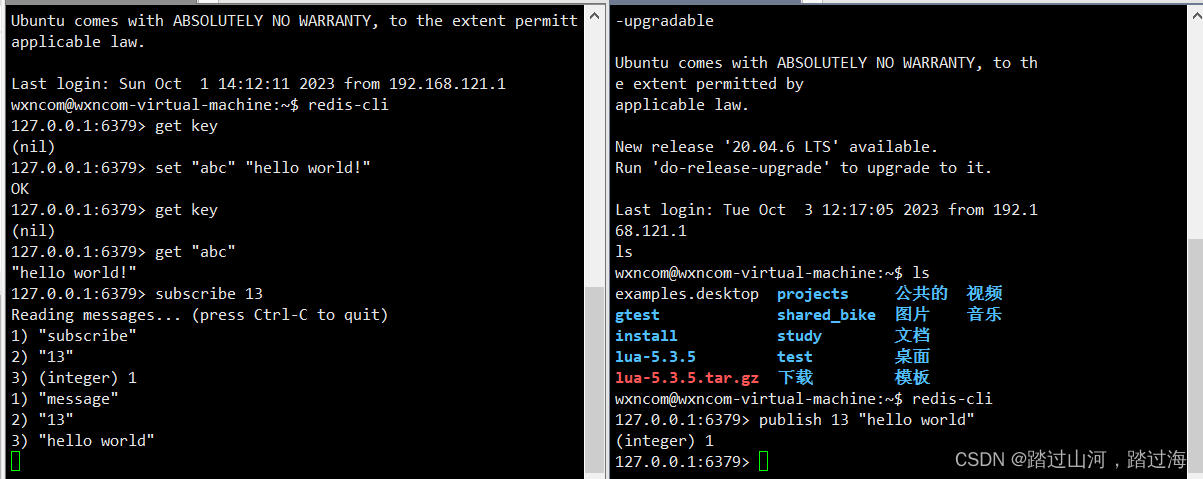
redis的简单使用
文章目录 环境安装与配置redis发布-订阅相关命令redis发布-订阅的客户端编程redis的订阅发布的例子 环境安装与配置 sudo apt-get install redis-server # ubuntu命令安装redis服务ubuntu通过上面命令安装完redis,会自动启动redis服务,通过ps命令确认&a…...
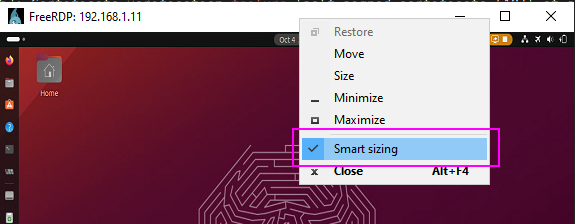
Windows下启动freeRDP并自适应远端桌面大小
几个二进制文件 xfreerdp # Linux下的,an X11 Remote Desktop Protocol (RDP) client which is part of the FreeRDP project wfreerdp.exe # Windows下的,freerdp2.0 主程序,freerdp3.0将废弃 sdl-freerdp.exe # Windows下的&…...

【C++27协程调试终极指南】:20年专家亲授5大不可外泄的断点追踪黑科技
第一章:C27协程调试的底层模型与认知重构 C27将首次将协程(coroutine)纳入核心语言调试规范,其调试模型不再依赖于传统栈帧回溯,而是围绕可恢复执行上下文(resumable execution context)、挂起点…...

别再只搜字符串了!x64dbg逆向破解卡密软件的另一种思路:从API断点MessageBoxW开始
逆向工程实战:突破字符串搜索局限的API断点追踪法 在逆向分析领域,字符串搜索常被视为破解卡密验证的"第一板斧"。但当你面对一个精心设计的商业软件时,这招往往会失灵——字符串被混淆、关键提示信息被加密、甚至整个代码段都被加…...

STM32CubeMX配置RT-Thread Nano:从零构建到任务与内存管理实战
1. 环境准备与基础工程搭建 第一次接触STM32CubeMX和RT-Thread Nano时,我完全按照官方文档操作却踩了不少坑。这里分享一个经过实战验证的配置流程,适用于STM32H7系列(其他型号也类似)。你需要准备: STM32CubeMX 6.12.…...

MCP与Skill:AI Agent的连接与方法能力详解,小白程序员必备收藏
本文详细解释了AI Agent中的两个核心概念:MCP和Skill。MCP主要解决连接问题,让Agent能够接入外部工具和数据;Skill则专注于方法能力,指导Agent如何正确、稳定地执行任务。两者并非替代关系,而是协作关系。文章通过实例…...

GraalVM原生镜像与MongoDB Java驱动:构建极致性能的微服务应用
GraalVM原生镜像与MongoDB Java驱动:构建极致性能的微服务应用 【免费下载链接】mongo-java-driver The official MongoDB drivers for Java, Kotlin, and Scala 项目地址: https://gitcode.com/gh_mirrors/mo/mongo-java-driver 在当今云原生和微服务架构盛…...

Omni-Vision Sanctuary低代码实践:在Dify平台上快速构建AI应用
Omni-Vision Sanctuary低代码实践:在Dify平台上快速构建AI应用 1. 为什么选择低代码平台构建AI应用 在AI技术快速发展的今天,很多企业都希望将AI能力集成到自己的业务系统中。但传统AI应用开发面临几个主要挑战:开发周期长、技术门槛高、维…...

3大核心功能解放窗口控制:Simple Runtime Window Editor全场景应用指南
3大核心功能解放窗口控制:Simple Runtime Window Editor全场景应用指南 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 在数字创作的世界里,窗口分辨率的限制常常成为创意落地的隐形障碍…...

告别性能焦虑:5个被忽略的华硕设备优化神器隐藏功能
告别性能焦虑:5个被忽略的华硕设备优化神器隐藏功能 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar…...

SRWE:突破Windows窗口限制的运行时分辨率编辑解决方案
SRWE:突破Windows窗口限制的运行时分辨率编辑解决方案 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 在Windows操作系统生态中,应用程序窗口的尺寸和位置控制一直受到系统预设框架的限制…...

Wan2.2-I2V-A14B模型生成复古像素艺术与游戏角色Sprite
Wan2.2-I2V-A14B模型生成复古像素艺术与游戏角色Sprite 1. 复古像素艺术的魅力重现 还记得小时候玩红白机时,那些由简单像素点构成的游戏世界吗?虽然画面简单,但那些8-bit和16-bit风格的图像却承载着我们最美好的游戏记忆。如今,…...