【网络安全-信息收集】网络安全之信息收集和信息收集工具讲解
一,域名信息收集
1-1 域名信息查询
可以用一些在线网站进行收集,比如站长之家
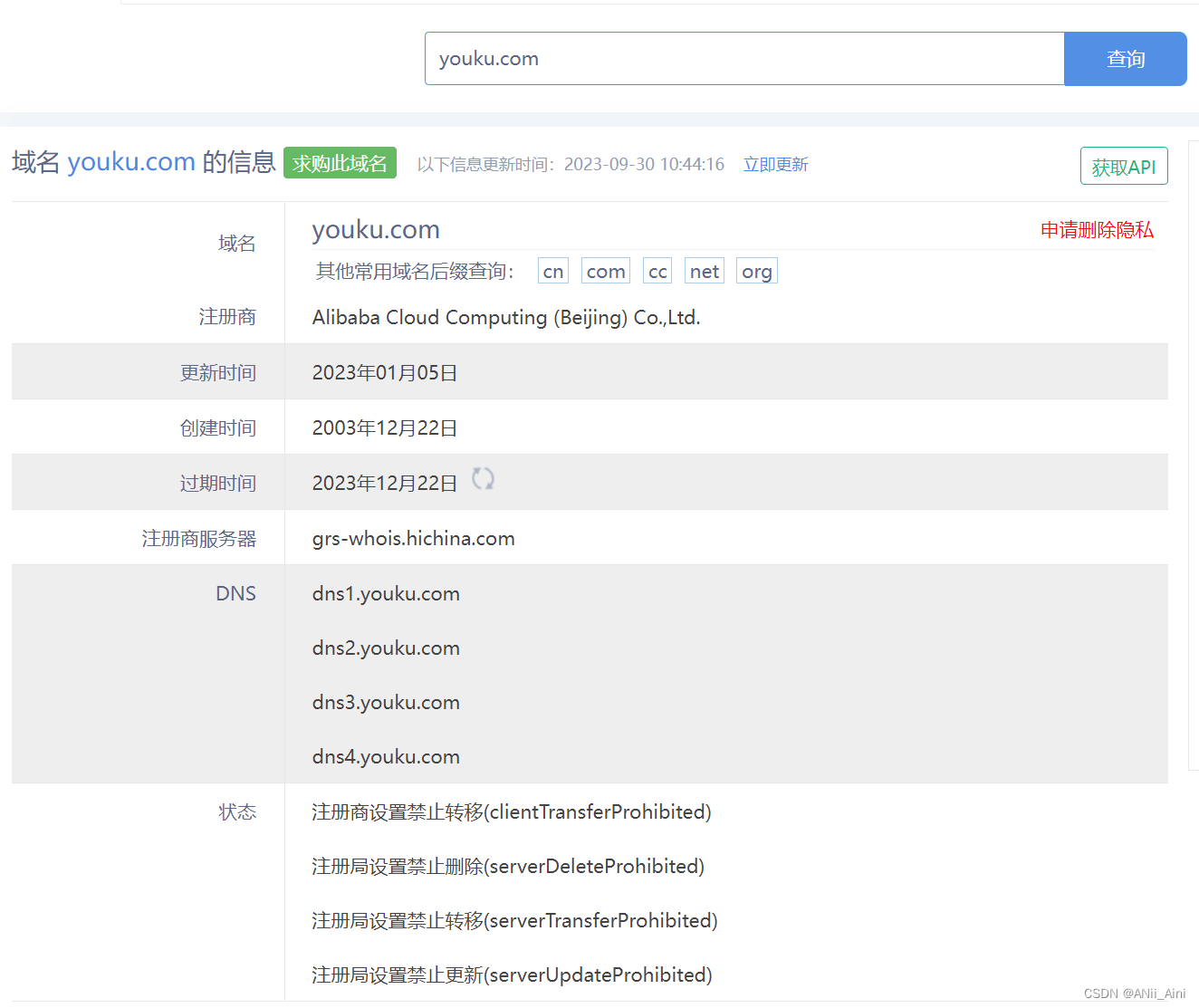
域名Whois查询 - 站长之家站长之家-站长工具提供whois查询工具,汉化版的域名whois查询工具。
https://whois.chinaz.com/
可以查看一下有没有有用的信息,不过一些大网站优化的很好,一般没有什么可用信息的。
其他查询网站
中国万网域名WHOIS信息查询地址:
https://whois.aliyun.com/
西部数码域名WHOIS信息查询地址:
https://whois.west.cn/
新网域名WHOIS信息查询地址:
http://whois.xinnet.com/domain/whois/index.jsp
纳网域名WHOIS信息查询地址:
http://whois.nawang.cn/
中资源域名WHOIS信息查询地址:
https://www.zzy.cn/domain/whois.html
三五互联域名WHOIS信息查询地址:
https://cp.35.com/chinese/whois.php
新网互联域名WHOIS信息查询地址:
http://www.dns.com.cn/show/domain/whois/index.do
美橙互联域名WHOIS信息查询地址:
https://whois.cndns.com/
爱名网域名WHOIS信息查询地址:
https://www.22.cn/domain/
易名网域名WHOIS信息查询地址:
https://whois.ename.net/
1-2 SEO信息查询
站长之家可以查
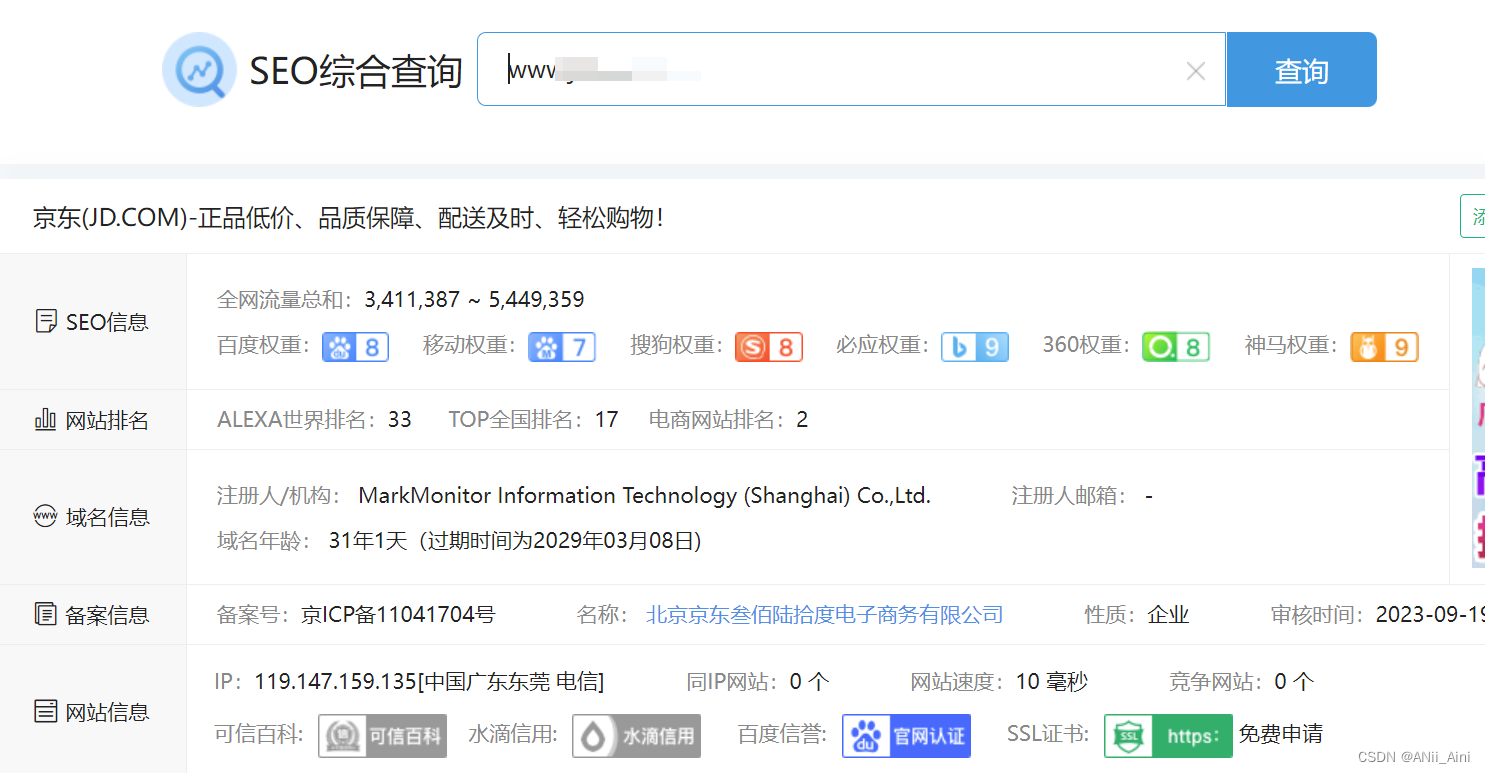
可以看到一些备案信息,真实IP地址等一些信息
1-3 子域名收集
首先为什么要进行子域名收集呢?因为往往网站首页或者一些主要网页安全做的很好,很难找到突破口,但是一些子网站安全不一定做的很好,所以有时候从子域名入手也是个思路,所以需要手机子域名信息
1-3-1 在线收集子域名
子域名查询 - 站长工具子域名查询![]() https://tool.chinaz.com/subdomain/
https://tool.chinaz.com/subdomain/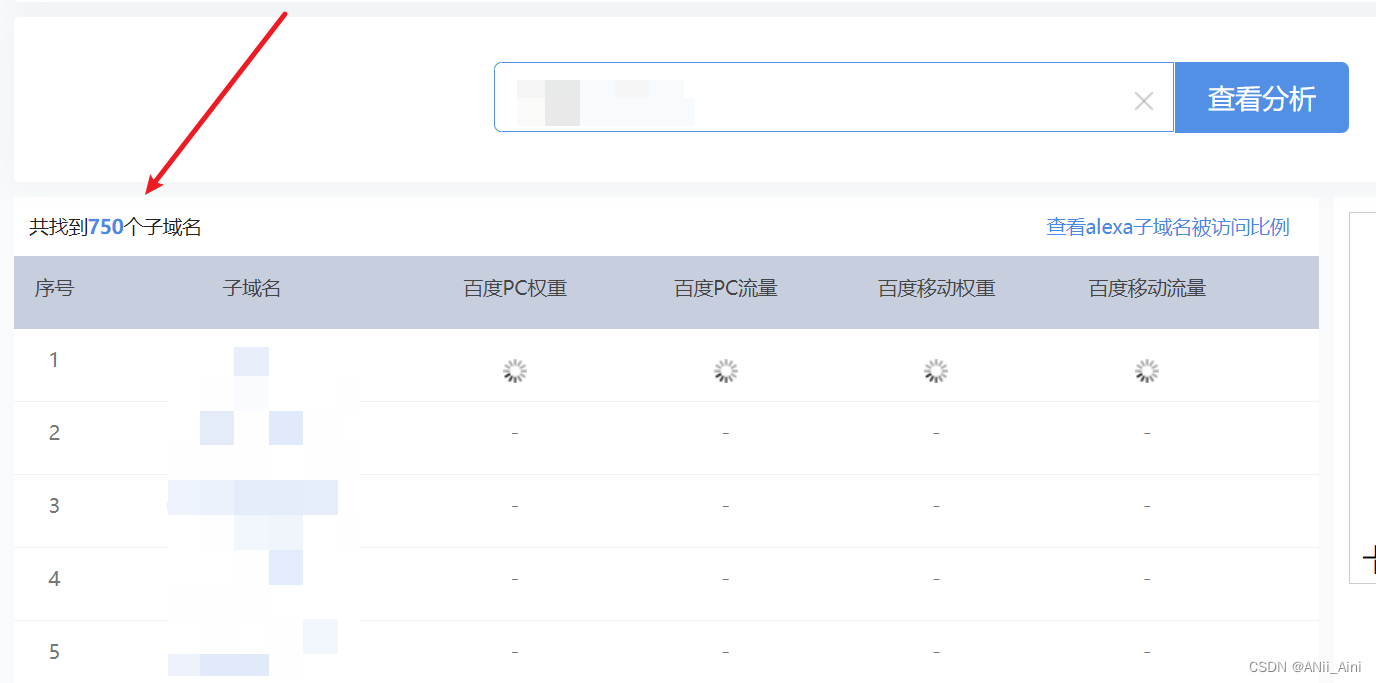
查到的子域名你一个个去访问一下,看看是否能访问,是否开放文本服务等
1-3-2 子域名收集工具
2-1 JSFinder
工具下载地址:(Python写的工具,需要有Python环境)
GitHub - Threezh1/JSFinder: JSFinder is a tool for quickly extracting URLs and subdomains from JS files on a website.JSFinder is a tool for quickly extracting URLs and subdomains from JS files on a website. - GitHub - Threezh1/JSFinder: JSFinder is a tool for quickly extracting URLs and subdomains from JS files on a website.![]() https://github.com/Threezh1/JSFinder
https://github.com/Threezh1/JSFinder
需要安装模块
pip install requestspip install bs4用法:(在JSFinder.py路径下打开终端,按住shift,鼠标右击可以看到打开终端选项)
python JSFinder.py -u https://www.mi.com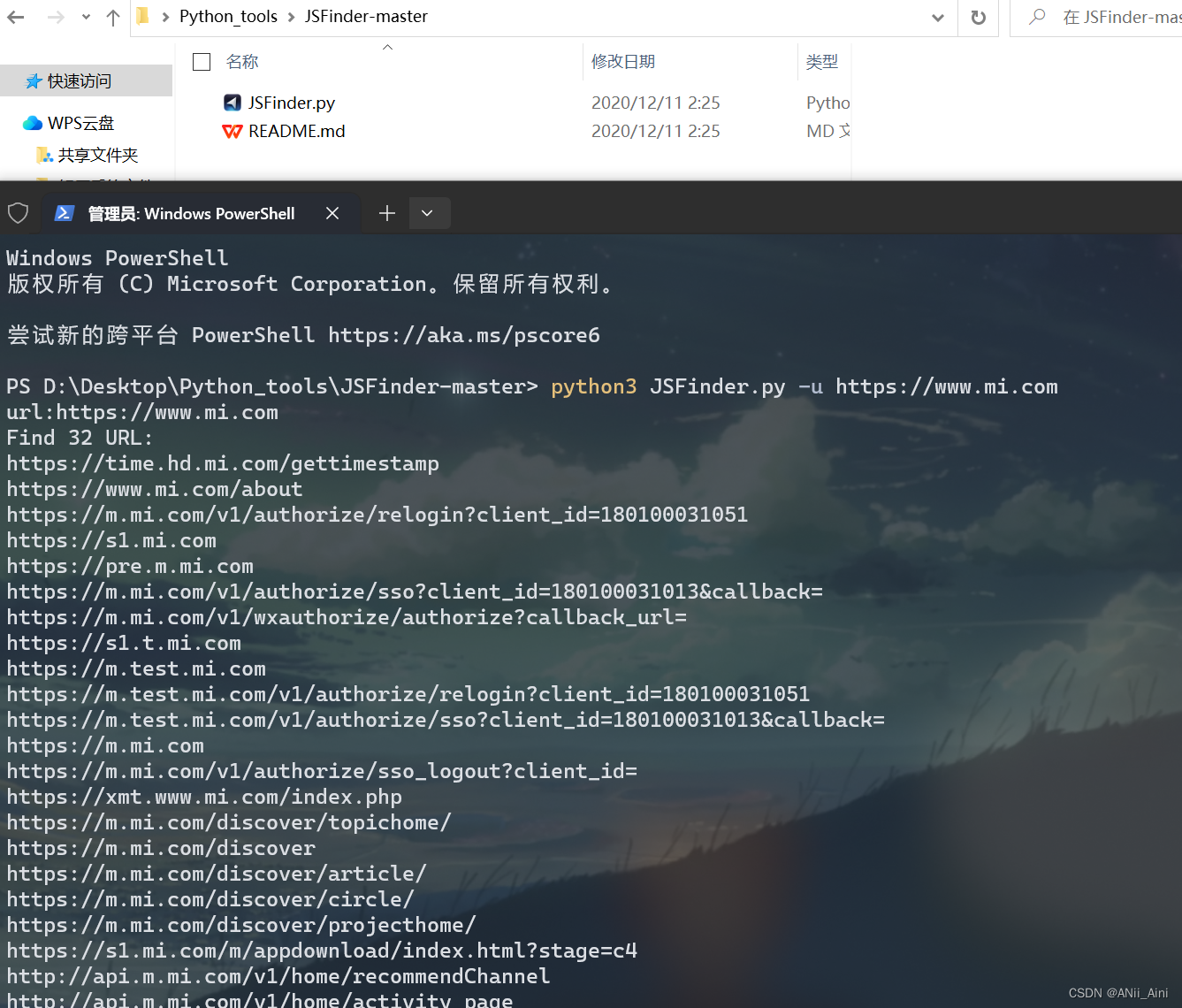
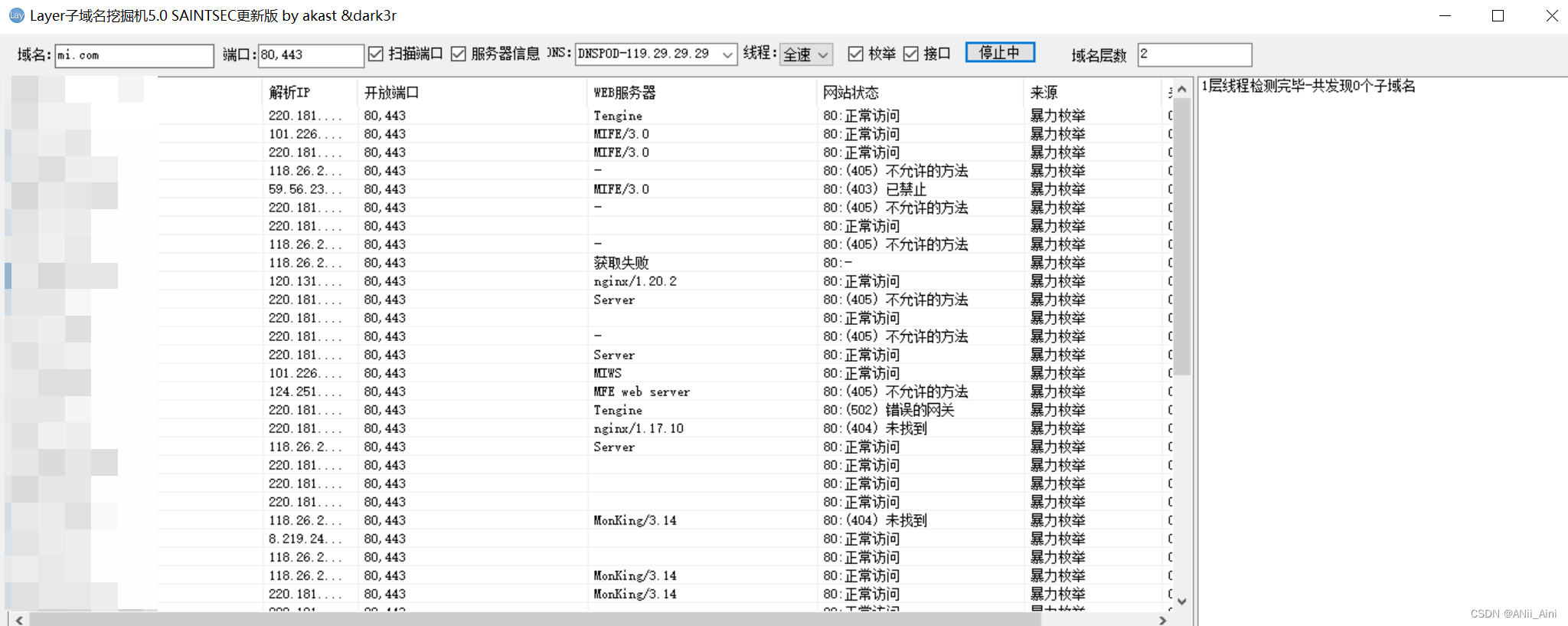
2-2 Layer子域名挖掘机
(需要工具可以留言)
2-3 subDomainsBrute.py
需要工具可以留言,或者自行找一下,去github上搜
python .\subDomainsBrute.py www.baigui.cloud2-4 oneforall.py
python .\oneforall.py --target mi.com run 2-5 用Python自己写个脚本
5-1 ping命令+ 域名字典进行收集
## 基于ping 进行子域名扫描
import os
def ping_domain(P_domain):## xxx是二级域名字典with open('xxx') as f:domain_list = f.readlines()for domain in domain_list:full_domain = f'{domain.strip()}.{P_domain}'result = os.popen(f'ping -n 1 -w 1000 {full_domain}').read()if '请求超时' in result or "TTL=" in result:print(f'{full_domain} 存在')if "找不到主机" not in result:print(f'{full_domain} 存在')5-2 基于socket库
import socket
## 基于socket库DNS解析记录实现扫描
def socket_domain(P_domain):## 读取域名字典文件with open('xxx') as f:domain_list = f.readlines()for domain in domain_list:try:full_domain = f'{domain.strip()}.{P_domain}'ip = socket.gethostbyname(full_domain) ## 如果这个域名存在则会返回IP地址,不存在报 socket.gaierrorprint(f"{ip} ------ {full_domain}")except socket.gaierror:passexcept:pass1-4 备案号和ssl证书查询子域名
1-4-1 域名备案信息查询
ICP备案查询 APP备案 小程序备案 - 站长工具通过域名可查询该域名是否有备案及相关的ICP备案许可信息。通过名称查询APP备案信息和小程序备案,快应用备案信息。![]() https://icp.chinaz.com/
https://icp.chinaz.com/
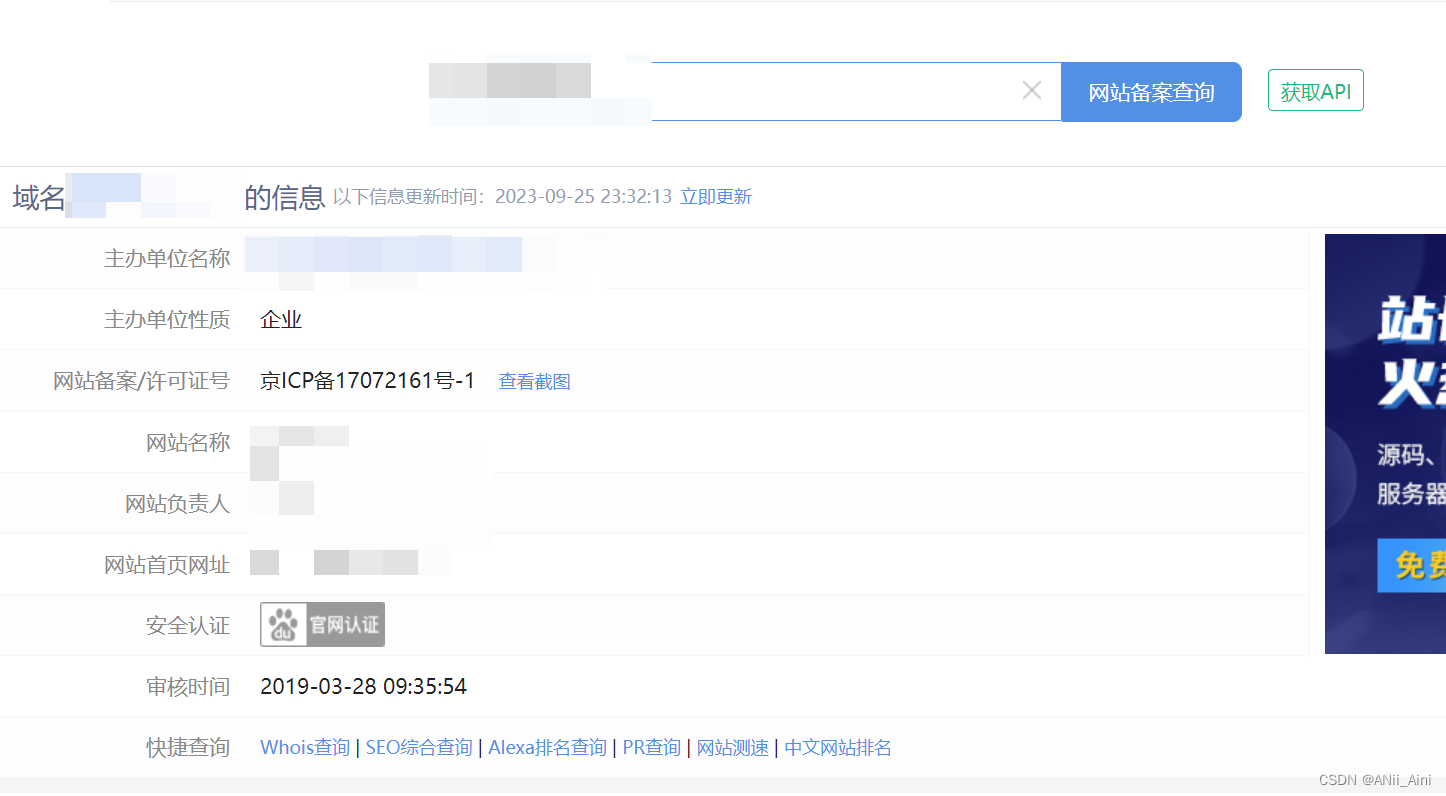
1-4-2 ICP备案号查询
https://beian.miit.gov.cn/![]() https://beian.miit.gov.cn/
https://beian.miit.gov.cn/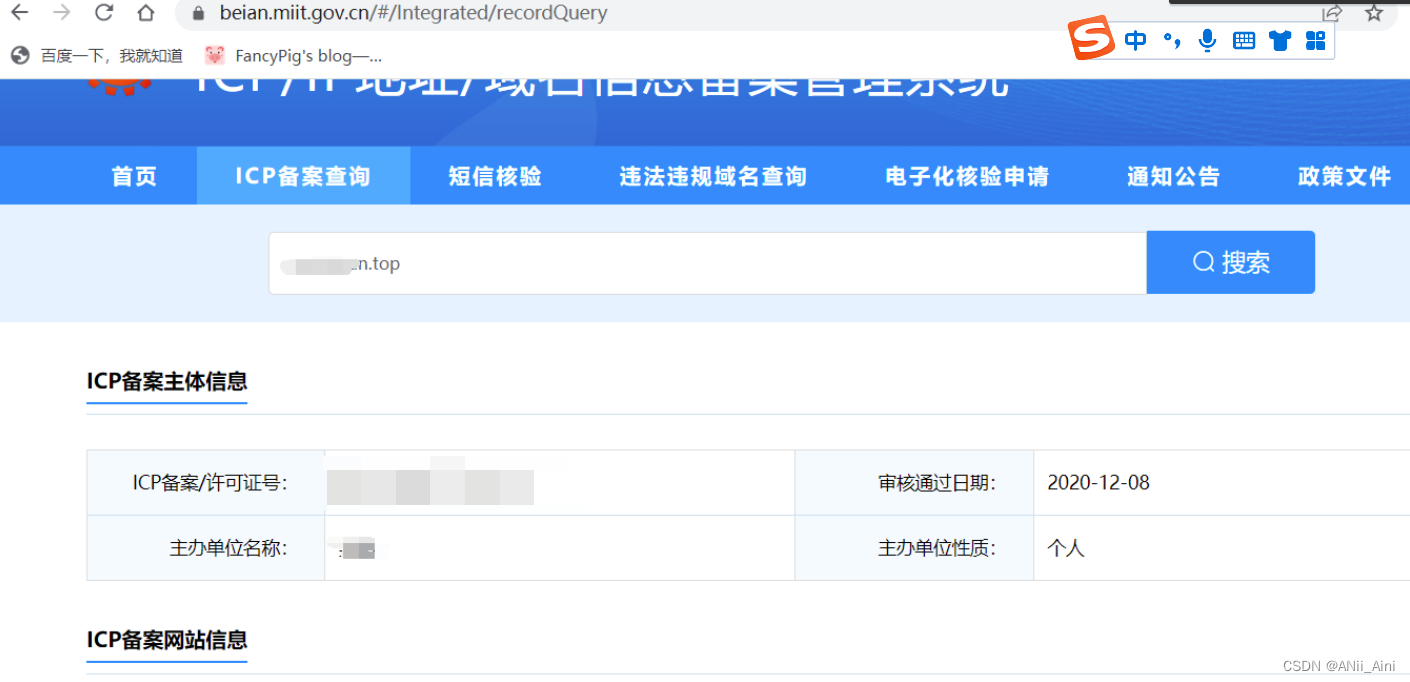
有了备案号,可以通过备案号查询这个公司的其他备案的子域名
1-4-3 ssl证书查询
SSL状态检测本站提供的SSL状态检测工具,可以检测出证书详细信息、证书链详细信息、当前支持协议、加密套件详细信息,可以为您的服务器证书部署状态提供最详细说明,如果你的证书部署状态存在缺陷,我们还提供了详细的建议信息,协助你配置出最安全的SSL站点。![]() https://myssl.com/ssl.html
https://myssl.com/ssl.html
SSL证书在线检测工具-中国数字证书CHINASSLSSL证书在线检测工具-中国数字证书CHINASSL![]() https://www.chinassl.net/ssltools/ssl-checker.html
https://www.chinassl.net/ssltools/ssl-checker.html
二,真实IP信息收集
为什么要找网站真实IP呢,因为网站有可能使用CDN服务器来进行加速,相当于说CDN服务器也缓存了一份服务器的数据,网站数据是从CDN服务器获取的,这样的话我们需要找出网站的真实IP来找出网站自己的真实服务器,所以我们需要找到网站的真实IP。要不然不找到真实IP,直接进行攻击,很有可能我们攻击的是CSDN服务器,

有了CDN服务器加速以后,客户端只要到离自己最近的一个CDN服务器拿数据即可,这样网站访问速度会提高,但是我们要攻击的是网站的真实服务器,不是CDN服务器,那么就需要找出真实IP
如何判断有没有CDN加速呢? 下面有几种方法?
2-1 超级ping
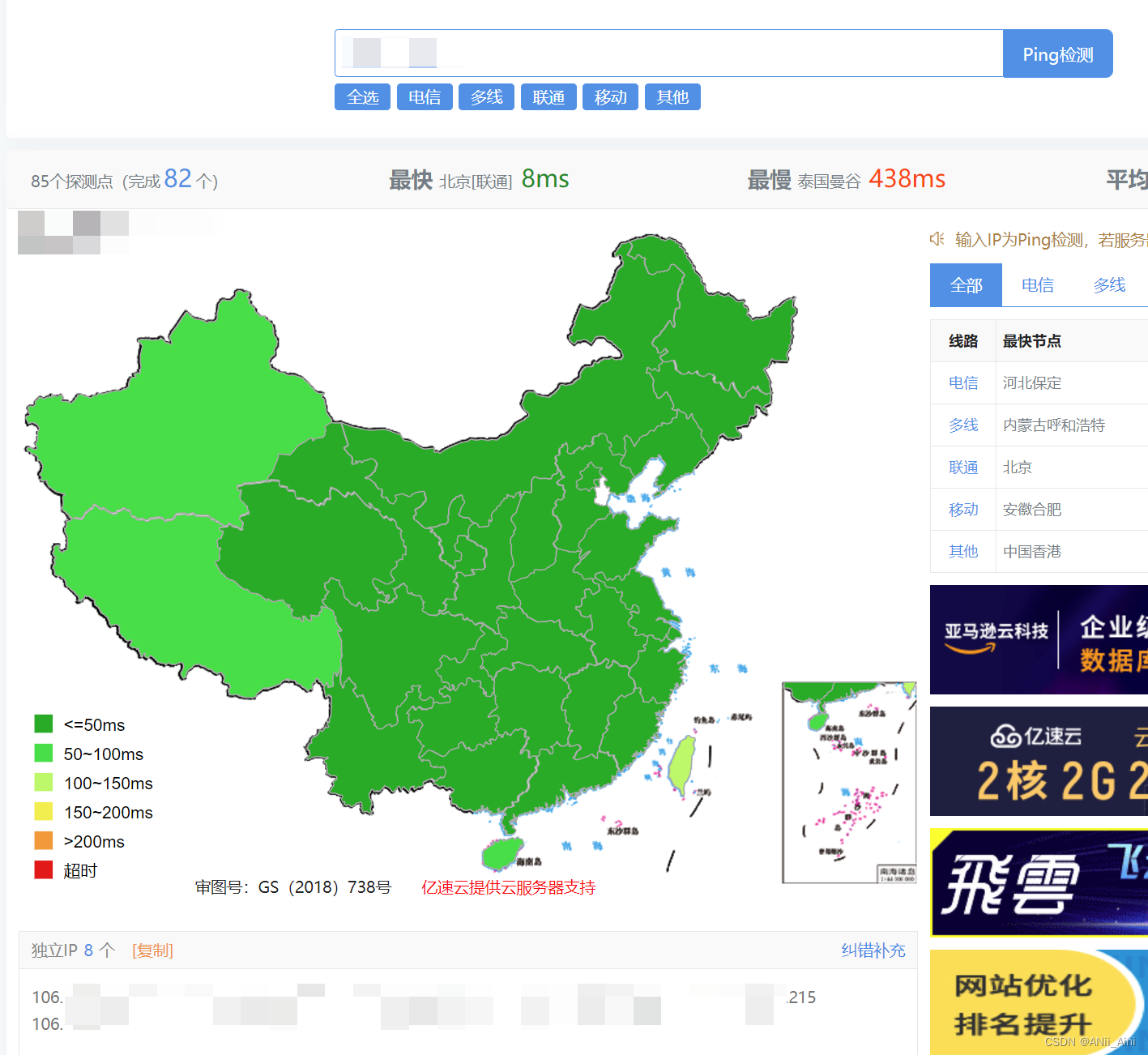
原理:如果有了CDN加速的话,不同地方的客户端都会去离子最近的CND服务器去拿资源,所以你在新疆,海南,北京.....不同地方Ping对方服务器,拿到的IP不一样。如果没有CDN加速的话,你ping 对方服务器,无论你在哪里,都会去找真实服务器拿资源,ping出来的IP都一样
多个地点Ping服务器,网站测速 - 站长工具通过该工具可以多个地点Ping服务器以检测服务器响应速度。![]() https://ping.chinaz.com/
https://ping.chinaz.com/
全国各地对域名进行ping 最后ping出来的只有一个IP,说明没有用CDN加速

模拟全国各地进行ping 得到8个IP地址,说明很有可能使用了DNS加速
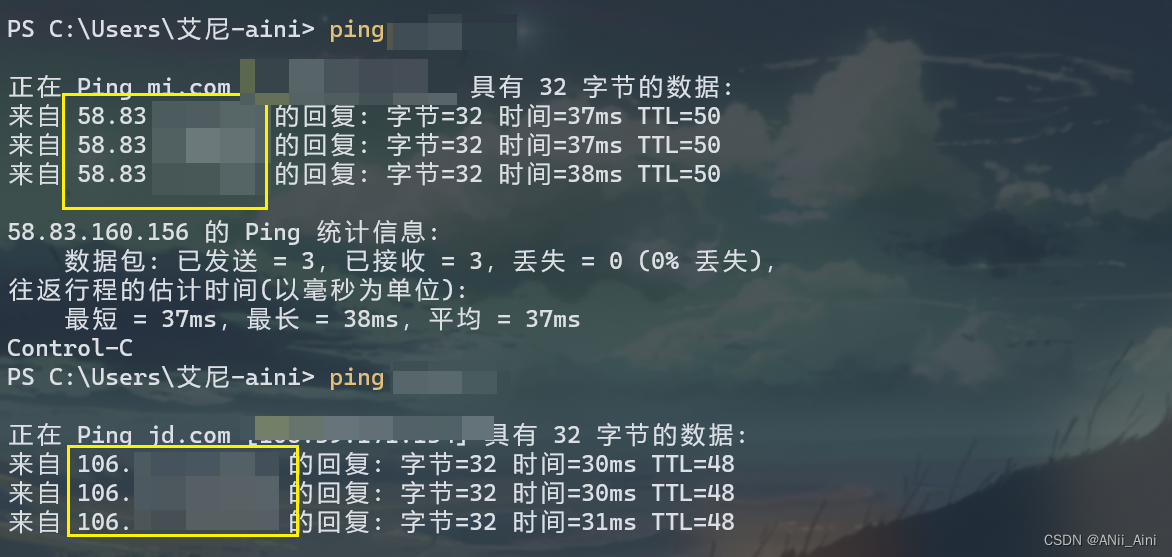
2-2 终端ping
上面看到的IP很有可能是真实IP,不过需要确认。
2-3 nslookup(windows)
是查询DNS的记录,查看域名解析是否正常,在网络故障的时候用来诊断网络问题的工具,通过它也可以尝试获取一个域名对应的ip地址
命令格式:nslookup domain[dns-server]
示例:nslookup ainiai.top
还可以指定查询的DNS记录类型
命令格式:nslookup -qt=type domain[dns-server]
示例:nslookup -qt=CNAME ainiai.top 2-4 dig(Linux)
2-4 dig(Linux)
Dig是一个在linux命令行模式下查询DNS包括NS记录,A记录,MX记录等相关信息的工具。也能探测到某个域名对应的ip地址。dig 最基本的功能就是查询域名信息
dig ainiai.top2-5 CDN绕过工具
2-5-1 使用工具绕过,效果不佳
## 工具1:fuckcdn
https://github.com/Tai7sy/fuckcdn## 工具2:w8fuckcdn
https://github.com/boy-hack/w8fuckcdn2-5-2 DNS历史解析
这种历史记录查询,有可能能够找到它没有使用cdn之前的真实ip地址
可以用如下网站试一试。我就不试了
https://x.threatbook.com/v5/domain/wulaoban.top
https://dnsdb.io/zh-cn/ ###DNS查询
https://x.threatbook.cn/ ###微步在线
http://toolbar.netcraft.com/site_report?url=www.wulaoban.top ###在线域名信息查询
http://viewdns.info/ ###DNS、IP等查询
https://tools.ipip.net/cdn.php ###CDN查询IP
https://securitytrails.com/domain/wulaoban.top/dns三,旁站和C段
3-1 什么是旁站?
旁站:一般是指的是同ip,也就是同服务器下的不同站点,比如我们前面使用IIS部署了多个网站在同一个ip下。
比如一个服务192.168.31.20 分别用三个端口部署了三个网站
192.168.31.20:80
192.168.31.20:81
192.168.31.20:82
3-2 什么是C段 ?
比如在:127.127.127.4 这个IP上面有一个网站 127.4 这个服务器上面有网站我们可以想想..他是一个非常大的站几乎没什么漏洞!但是在他同C段 127.127.127.1~127.127.127.255 这 1~255 上面也有服务器而且也有网站并且存在漏洞,那么我们就可以来渗透 1~255任何一个站 之后提权来嗅探得到127.4 这台服务器的密码 甚至3389连接的密码后台登录的密码 如果运气好会得到很多的密码…
简单来讲就是一个大的公司可能在一个IP段买了很多连号服务器 ,这些服务器就是C段
3-3 IISPutScanner
用来收集旁站和C段(需要工具请留言)
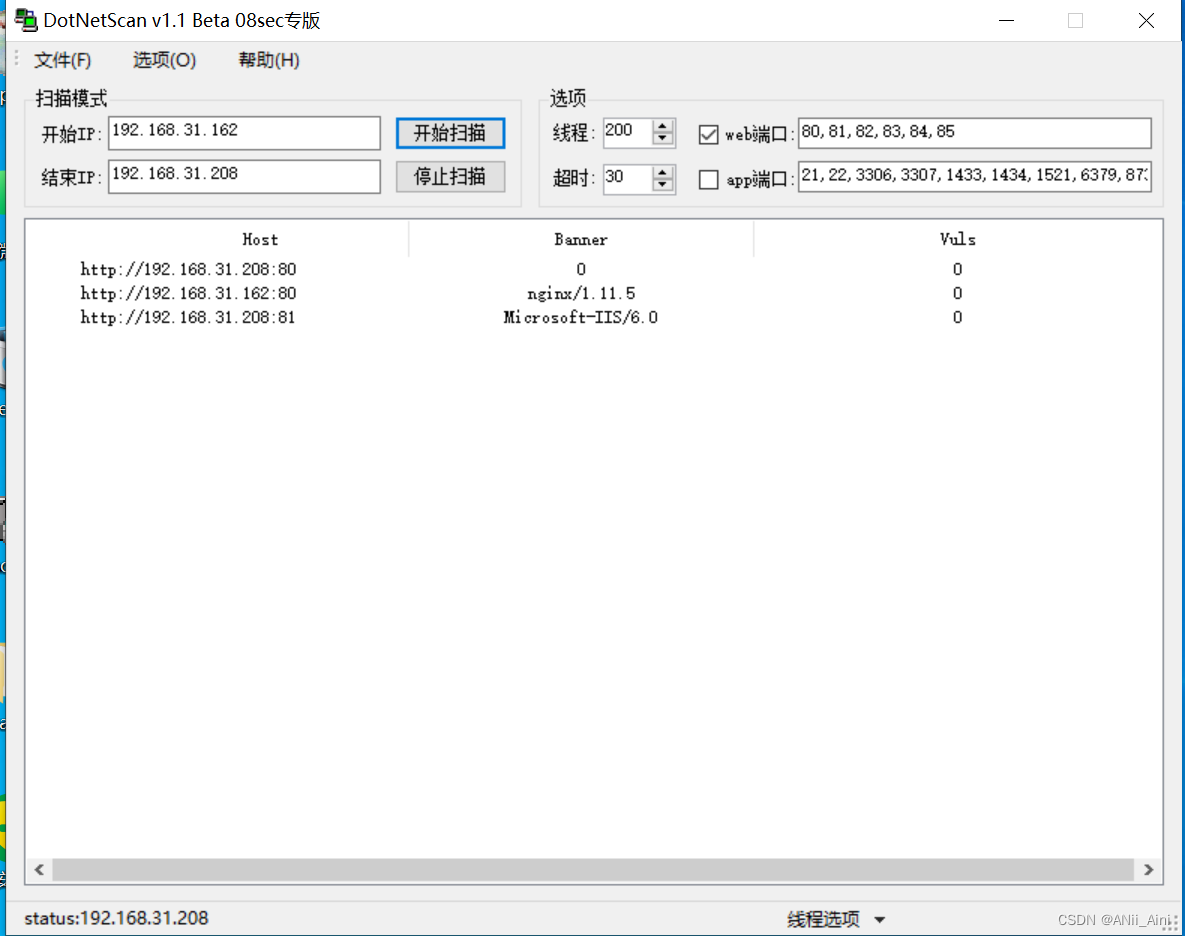
四,收集端口和服务
4-1 常用端口
这些端口需要记住,很多都是很常用的
ftp 21
ssh\sftp 22
telnet 23 # 很多交换机、路由器会用到telnet来进行管理,主要是用来做远程主机管理的
smtp 25 # 发邮件
pop3 110 # 收邮件
dns 53
smb 445 # 微软的文件共享,netstat -an -p tcp|findstr "LISTENING" windows必开,139端口也是windows做共享的
https 443
http 80
apache 80 443
nginx 80 443
tomcat 8080
weblogic 7001
mysql 3306
mssql 1433
oracle 1521
postgresql 5432
redis 6379
mongdb 27017
vnc 5900 # 远程控制工具
IIS 80
jboss 8080
rdp == remote desktop protocol 3389
4-2 nmap工具扫描
这个工具kali上自带,可以直接在命令行使用
Windows的话需要下载,我已经下载并配置好了环境变量
nmap工具的详细使用步骤我写了一篇博客详细讲了,请看下面这篇博客
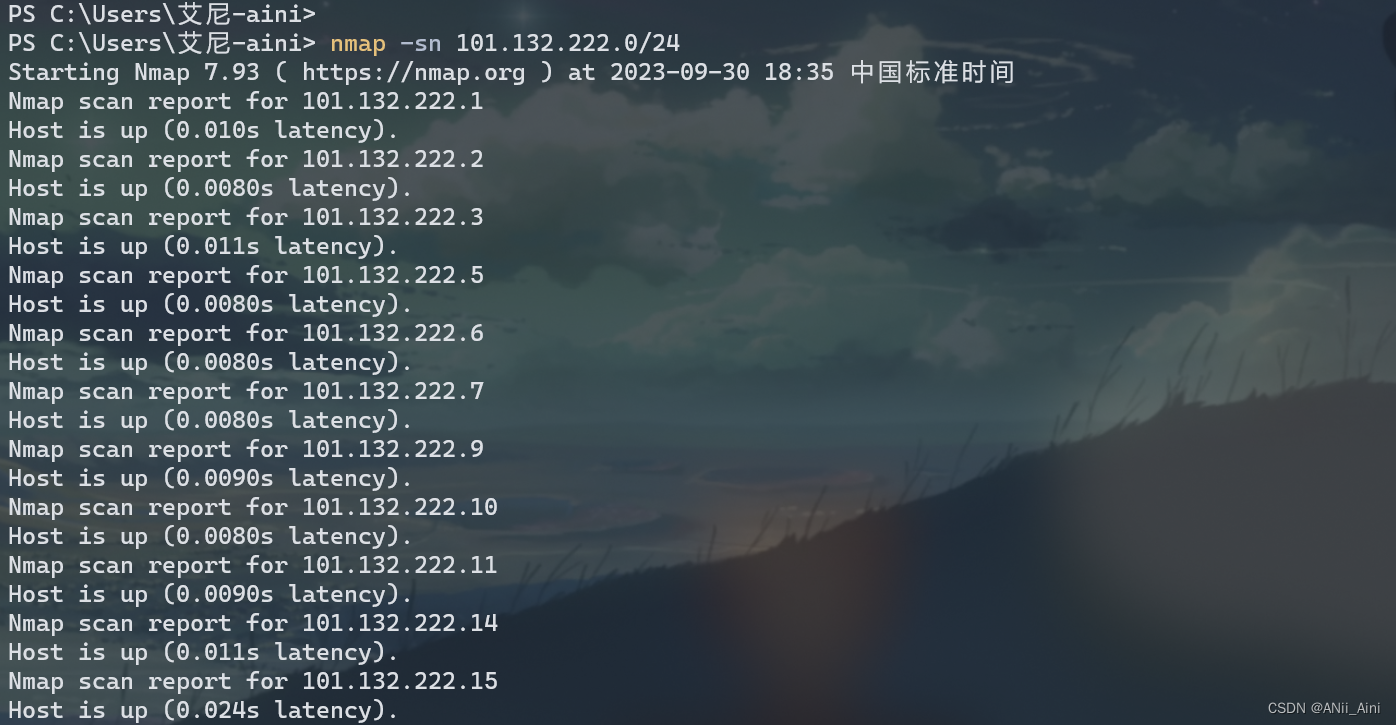
nmap工具的使用_ANii_Aini的博客-CSDN博客扫描网段判断存活主机;扫描端口;扫描操作系统;基于三次握手去扫描;基于ACK包进行探测https://blog.csdn.net/m0_67844671/article/details/132805990?spm=1001.2014.3001.5502可以简单用以下,比如判断一个IP段的存活主机
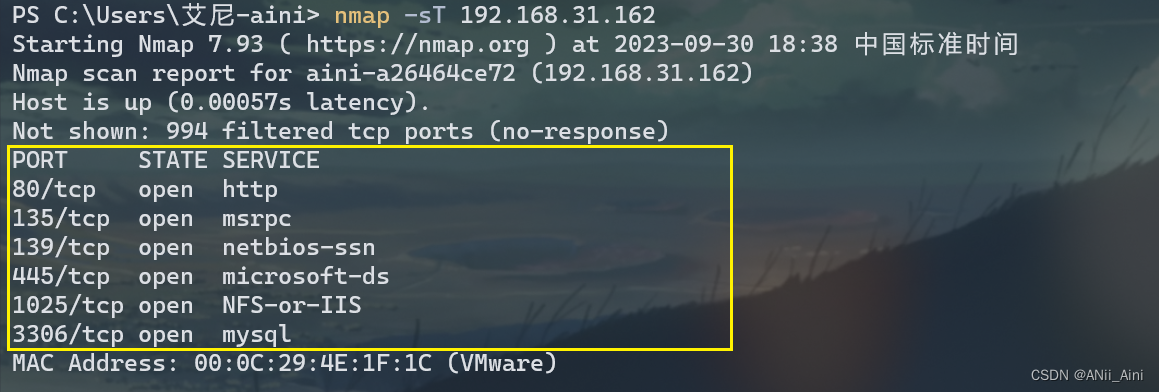
收集一个主机开放的端口和服务
4-3 自己编写的Python脚本
4-3-1 基于单线程找开放端口
## 端口扫描
## 对目标IP进行进行端口扫描,尝试连接IP和端口
# 单线程
import socket
def socket_port(ip):for port in range(1,100):try:s = socket.socket()s.settimeout(0.1)s.connect((ip,port))print(f'端口:-----{port}可用 ----------- yes')except socket.timeout:passexcept:pass4-3-2 基于多线程找开放端口
# 基于多线程进行端口扫描
import socket
def socket_port_thread(ip,start):for port in range(start,start+50):try:s = socket.socket()s.settimeout(0.01)s.connect((ip,port))print(f'端口:-----{port}可用 ----------- yes')except:passfrom threading import Thread
port_list = [22,25,80,443,3306,1521]
if __name__ == "__main__":# socket_port('192.168.31.162')for i in range(1,10000,50):Thread(target=socket_port_thread,args=('192.168.31.160',i)).start()4-3-3 优化
## 优化思路:对常用端口进行优先扫描
import socket
import timedef socket_port_noramal(ip):list = [7,21,22,23,25,53,67,68,69,79,80,81,88,109,110,113,135,137,138,139,143,161,162,179,194,220,389,443,445,465,513,520,546,547,554,563,631,636,991,993,995,1080,1194,1433,1434,1494,1521,1701,1723,1755,1812,1813,1863,3269,3306,3307,3389,3544,4369,5060,5061,5355,5432,5671,5672,6379,7001,8080,8081,8088,8443,8883,8888,9443,9988,15672,50389,61613,61614]for port in list:try:s = socket.socket()s.settimeout(0.01)s.connect((ip,port))print(f'端口:-----{port}可用 ----------- yes')except:passif __name__ == "__main__":socket_port_noramal('192.168.31.162')4-3-4 用Python进行IP扫描
4-1 Ping扫描
## 如果要内网渗透,则必须要知道哪些IP地址是存活的,可访问的
## IP地址工作在IP层,ICMP,ARP协议也存在IP信息
## 先使用ping 命令进行IP探测,不过一旦防火墙禁止ICMP协议,那么也会扫不出来
import socket,threading,os
def ping_ip():for i in range(1,255):ip = f'192.168.31.{i}'res = os.popen(f'ping -n 1 -w 100 {ip}').read()if 'TTL=' in res:print(f'ip {ip} online')## 第二种过滤,直接在命令里过滤# res = os.popen(f'ping -n 1 -w 100 {ip} | findstr TTL=').read()# if len(res) > 0:# print(f'ip {ip} online')
ping_ip()4-2 基于ARP协议
2-1 单线程
import scapy
from scapy.layers.l2 import ARP
from scapy.sendrecv import sr1## 设置日志级别,不让错误信息打印出来
import logging
logging.getLogger('scary.runtime').setLevel(logging.ERROR)def scapy_ip():for i in range(1,255):ip = f'192.168.31.{i}'try:pkg = ARP(psrc='192.168.31.17', pdst=ip)reply = sr1(pkg, timeout=3, verbose=False)print(f'IP {ip} online ----- {reply[ARP].hwsrc} ')except:passif __name__ == '__main__':scapy_ip()2-2 多线程
import threading
from scapy.layers.l2 import ARP
from scapy.sendrecv import sr1
import scapy## 设置日志级别,不让错误信息打印出来
import logging
logging.getLogger('scapy.runtime').setLevel(logging.ERROR)def scapy_ip(start):for i in range(start,start+20):ip = f'192.168.31.{i}'try:pkg = ARP(psrc='192.168.31.17', pdst=ip)reply = sr1(pkg, timeout=3, verbose=False)print(f'IP {ip} online ----- {reply[ARP].hwsrc} ')except:passif __name__ == '__main__':for i in range(1,255,20):threading.Thread(target=scapy_ip,args=(i,)).start()2-3 扫描端口
## 基于半链接,SYN / SYN,ACK / RA等标志位来对端口进行判断
## 如果目标端口开放,则 SYN -> SYN,ACK; 如果目标端口未开放,则SYN -> RAimport threadingfrom scapy.layers.inet import IP, TCP
from scapy.layers.l2 import ARP
from scapy.sendrecv import sr1
import scapy## 设置日志级别,不让错误信息打印出来
import logging
logging.getLogger('scapy.runtime').setLevel(logging.ERROR)def scapy_port(ip):# 通过指定源IP地址,可以进行IP欺骗,进而导致半链接,此列操作也可以用于flags参数定义上for port in range(20,100):try:pkg = IP(src = '192.168.31.17', dst = ip)/TCP(dport=port,flags='S')reply = sr1(pkg,timeout=1,verbose=False)res = reply[TCP].flagsif res == 0x12:print(f"{port} 开放")except:passscapy_port('192.168.31.162')五,收集敏感信息
5-1 目录信息收集
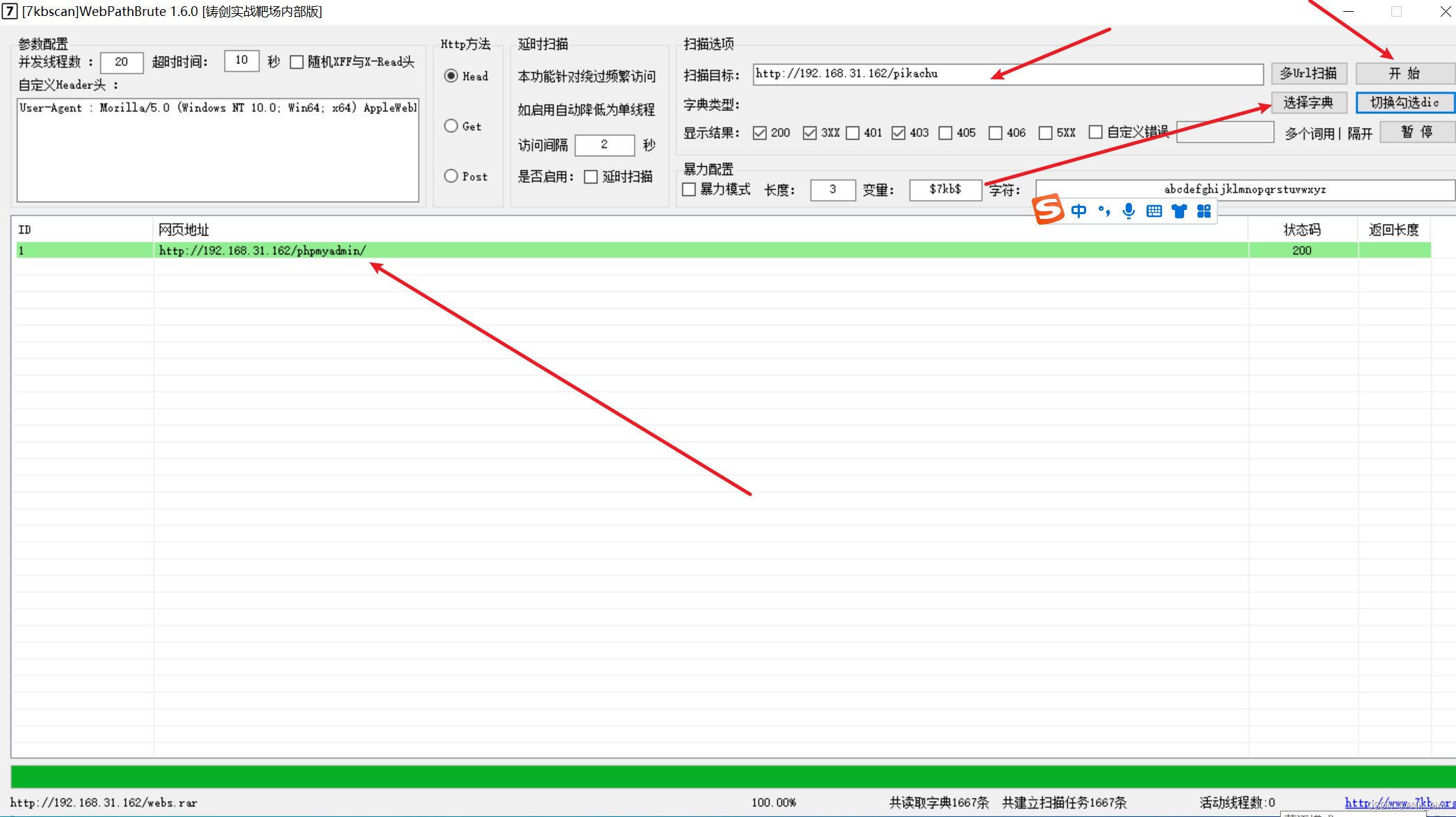
5-1-1 7kbscan工具检测
可以用默认字典,也可以指定字典,只要字典足够强大,可以收集到很多目录
比如下面发现了有一个phpmyadmin 这个是后台数据库登录页面,可以使用爆破登录或者弱口令登录等方式尝试进行攻击
 除此之外有可能收集到源代码备份目录,git仓库目录,或者一些重要配置文件等重要目录
除此之外有可能收集到源代码备份目录,git仓库目录,或者一些重要配置文件等重要目录
5-1-2 dirsearch工具
这是一款Python写的工具,需要有Python环境
下面是简单使用收集目录,详细使用方法自己收集一下资料
-u 制动URL地址
-e 指定服务端编程语言
python3 .\dirsearch.py -u 192.168.31.162/pikachu -e php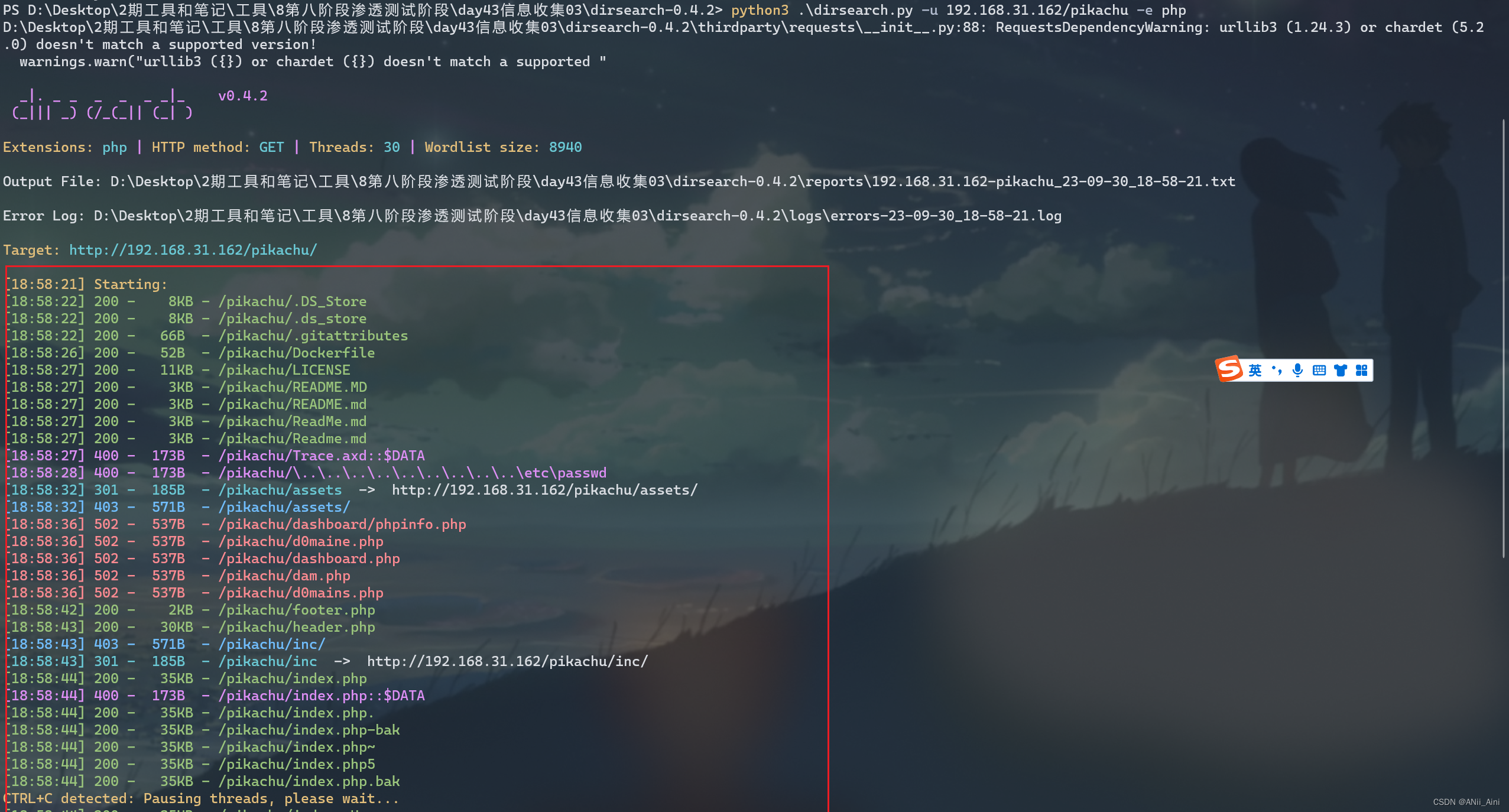
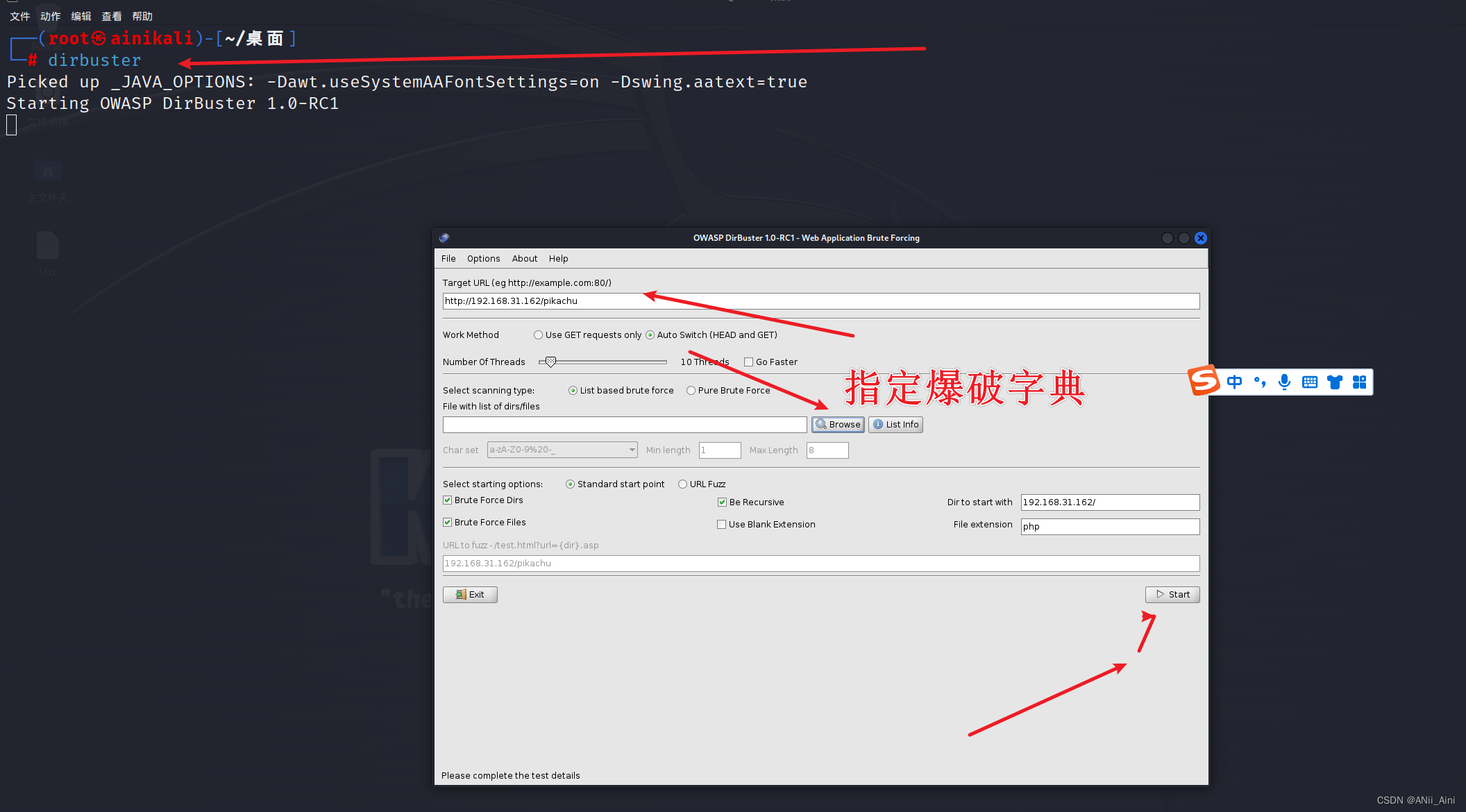
5-1-3 kali dirbuster工具
六,综合信息收集
6-1 Google hack高级收集
Google搜索引擎之所以强大,关键在于它详细的搜索关键词,以下是几个常用的搜索关键词
inurl: ## 用于查找含有该值的所有url网址网页。例:inurl:mail(可找一些免费邮箱)
related::## 找出和该网址类似的网站,比如想知道和amazon.com类似的大型网络书店有哪些时输入amazon.com网址。例:related:amazon.comintext: ## 只搜索网页部分中包含的文字(也就是忽略了标题,URL等的文字).
filetype: ## 搜索通过文件的后缀或者扩展名来搜索含有这类文件的网页
intitle: ## 标题中存在关键字的网页
allintitle: ## 搜索所有关键字构成标题的网页. 但是推荐不要使用link: ### 可以得到一个所有包含了某个指定URL的页面列表. 当我们使用link:URL提交查询的时候,Google会返回跟此URL做了链接的网站。例 [link:www.baidu.com],提交这个查询,我们将得到所有跟www.baidu.com这个网站做了链接的网站。(link是个单独的语 法,只能单独使用,且后面不能跟查询关键词,跟能跟URL)location: ## 当我们提交location进行Google新闻查询的时候,Google仅会返回你当前指定区的跟查询关键词相关的网页。例[ queen location:canada ],提交这个查询,Google会返回加拿大的跟查询关键词”queen”相匹配的网站。site: ## 搜索含有该域名的网页,google会限制尽在某个网站或者说域下面进行搜索
## 使用site进行站点搜索时,一般常见用法有:
site:ooxx.com filetype:xls # 支持组合搜索
site:xxx.com admin # 一般公司的后台系统都带有admin啊,login啊,内部系统啊之类的关键字
site:xxx.xxx login
site:xxx.xxx system
site:xxx.xxx 管理
site:xxx.xxx 登录
site:xxx.xxx 内部
site:xxx.xxx 系统
site:xxx.xxx 邮件
site:xxx.xxx email
site:xxx.xxx qq
site:xxx.xxx 群
site:xxx.xxx 企鹅
site:xxx.xxx 腾讯
site:ooxx.com练习
intext:管理
fietype:mdb ## 找到含有mdb类型文件的相关站点
site:baidu.com filetype:txt ### 查找百度这个域名下含有txt文件的相关站点
site:baidu.com intext:## 管理
site:baidu.com inurl:login
site:baidu.com intitle:## 后台
# 一般用于查找百度中能够找到的通过php、asp、jsp等语言开发的网站
site:baidu.com filetype:asp
site:baidu.com filetype:php
site:baidu.com filetype:jsp
site:baidu.com inurl:file # 这个一般用来找一些有上传文件动作的网站,之后可以检测是否有上传
文件漏洞。
# 查找某些国家或者地区的通过asp或php等语言开发的站点。
site:tw inurl:asp?id= #查找台湾的相关网站的url中包含asp?id=这些关键字的站点
site:hk inurl:asp?id= #查找香港的相关网站的url中包含asp?id=这些关键字的站点6-2 FOFA
网络空间测绘,网络空间安全搜索引擎,网络空间搜索引擎,安全态势感知 - FOFA网络空间测绘系统FOFA 是白帽汇推出的一款网络空间搜索引擎,它通过进行网络空间测绘,能够帮助研究人员或者企业迅速进行网络资产匹配,例如进行漏洞影响范围分析、应用分布统计、应用流行度排名统计等。![]() https://fofa.info/
https://fofa.info/
查询语法自己了解一下,我不多说,可以搜一下一个IP看看
6-3 钟馗之眼
ZoomEye - Cyberspace Search Engine![]() https://www.zoomeye.org/
https://www.zoomeye.org/
查询语法自己了解一下,我不多说
6-4 ARL灯塔资产侦查系统
6-4-1 Docker 启动
需要有docker环境,可以参考下面这篇文章进行安装和学习docker相关知识
docker及docker命令详解_ANii_Aini的博客-CSDN博客docker及docker命令详解;docker是一个软件,是一个运行与linux和windows上的软件,用于创建、管理和编排容器;docker平台就是一个软件集装箱化平台,是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,也可以实现虚拟化,并且容器之间不会有任何接口;https://blog.csdn.net/m0_67844671/article/details/132872790?spm=1001.2014.3001.5502
git clone https://github.com/TophantTechnology/ARL
cd ARL/docker/
docker volume create arl_db
docker-compose pull
docker-compose up -d 6-4-2 docker-compose配置文件启动
mkdir docker_arl
wget -O docker_arl/docker.zip https://github.com/TophantTechnology/ARL/releases/download/v2.5.4/docker.zip
cd docker_arl
unzip -o docker.zip
docker-compose pull
docker volume create arl_db
docker-compose up -d6-4-3 用压缩包进行安装
(需要压缩包请留言,我可以分享)
unzip ARL-master ## 进行解压缩
cd ARL-master
docker volume create arl_db
cd docker
docker-compose up -d 

安装完成以后可以访问了,5003端口
192.168.31.150:5003端口

默认账号密码 admin/arlpass
登录以后可以看到有非常多的功能
比如收集子域名
任务列表------> 添加任务
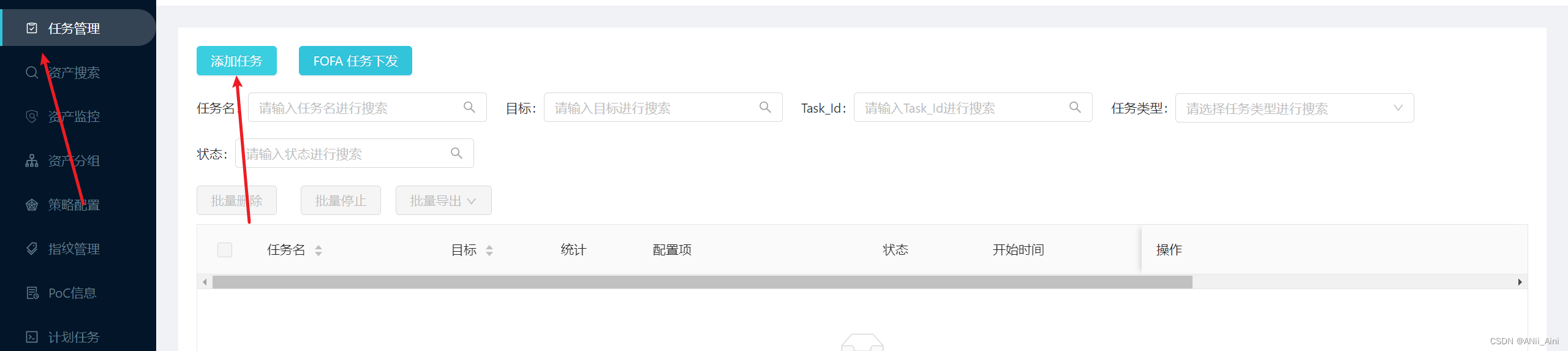
 看到done,然后可以导出报告了
看到done,然后可以导出报告了

可以自己多研究研究
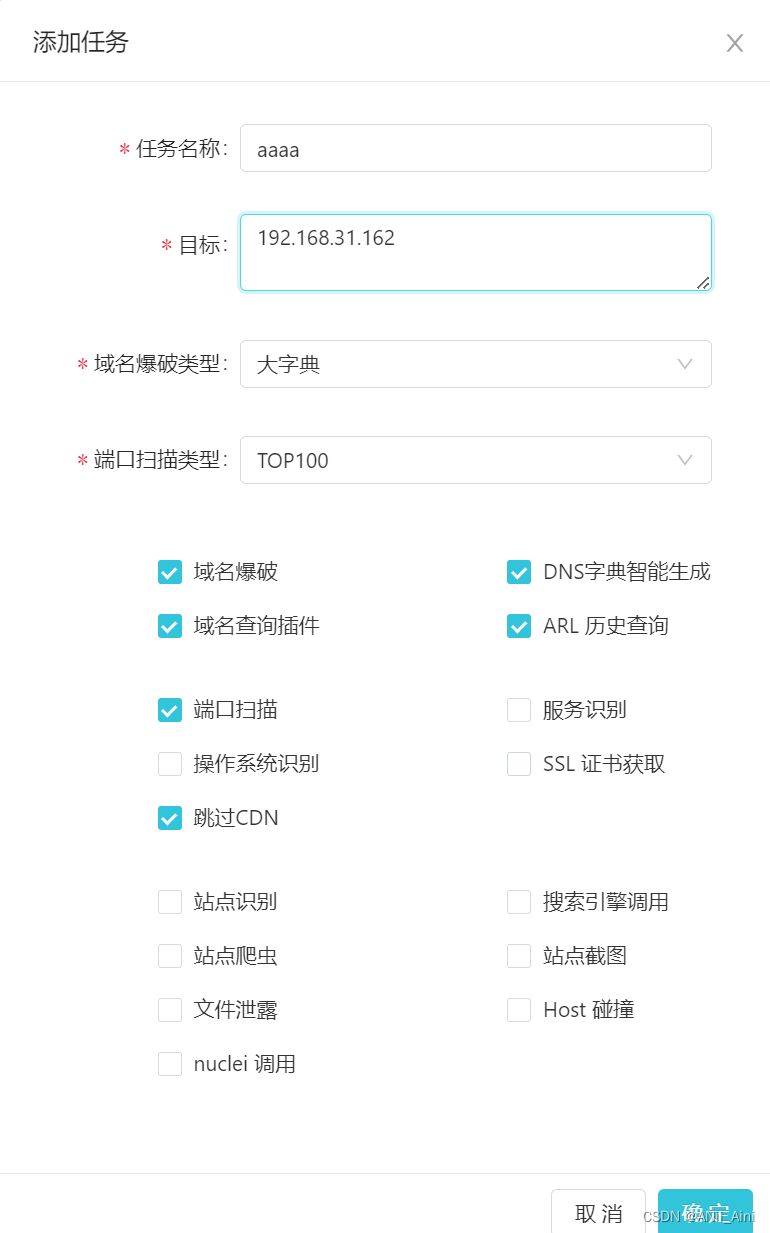
3-1 任务选项说明
| 编号 | 选项 | 说明 |
|---|---|---|
| 1 | 任务名称 | 任务名称 |
| 2 | 任务目标 | 任务目标,支持IP,IP段和域名。可一次性下发多个目标 |
| 3 | 域名爆破类型 | 对域名爆破字典大小, 大字典:常用2万字典大小。测试:少数几个字典,常用于测试功能是否正常 |
| 4 | 端口扫描类型 | ALL:全部端口,TOP1000:常用top 1000端口,TOP100:常用top 100端口,测试:少数几个端口 |
| 5 | 域名爆破 | 是否开启域名爆破 |
| 6 | DNS字典智能生成 | 根据已有的域名生成字典进行爆破 |
| 7 | 域名查询插件 | 已支持的数据源为12个,alienvault, certspotter,crtsh,fofa,hunter 等 |
| 8 | ARL 历史查询 | 对arl历史任务结果进行查询用于本次任务 |
| 9 | 端口扫描 | 是否开启端口扫描,不开启站点会默认探测80,443 |
| 10 | 服务识别 | 是否进行服务识别,有可能会被防火墙拦截导致结果为空 |
| 11 | 操作系统识别 | 是否进行操作系统识别,有可能会被防火墙拦截导致结果为空 |
| 12 | SSL 证书获取 | 对端口进行SSL 证书获取 |
| 13 | 跳过CDN | 对判定为CDN的IP, 将不会扫描端口,并认为80,443是端口是开放的 |
| 14 | 站点识别 | 对站点进行指纹识别 |
| 15 | 搜索引擎调用 | 利用搜索引擎搜索下发的目标爬取对应的URL和子域名 |
| 16 | 站点爬虫 | 利用静态爬虫对站点进行爬取对应的URL |
| 17 | 站点截图 | 对站点首页进行截图 |
| 18 | 文件泄露 | 对站点进行文件泄露检测,会被WAF拦截 |
| 19 | Host 碰撞 | 对vhost配置不当进行检测 |
| 20 | nuclei 调用 | 调用nuclei 默认PoC 对站点进行检测 ,会被WAF拦截,请谨慎使用该功能 |
3-2 配置参数说明
Docker环境配置文件路径 docker/config-docker.yaml
| 配置 | 说明 |
|---|---|
| CELERY.BROKER_URL | rabbitmq连接信息 |
| MONGO | mongo 连接信息 |
| QUERY_PLUGIN | 域名查询插件数据源Token 配置 |
| GEOIP | GEOIP 数据库路径信息 |
| FOFA | FOFA API 配置信息 |
| DINGDING | 钉钉消息推送配置 |
| 邮箱发送配置 | |
| GITHUB.TOKEN | GITHUB 搜索 TOKEN |
| ARL.AUTH | 是否开启认证,不开启有安全风险 |
| ARL.API_KEY | arl后端API调用key,如果设置了请注意保密 |
| ARL.BLACK_IPS | 为了防止SSRF,屏蔽的IP地址或者IP段 |
| ARL.PORT_TOP_10 | 自定义端口,对应前端端口测试选项 |
| ARL.DOMAIN_DICT | 域名爆破字典,对应前端大字典选项 |
| ARL.FILE_LEAK_DICT | 文件泄漏字典 |
| ARL.DOMAIN_BRUTE_CONCURRENT | 域名爆破并发数配置 |
| ARL.ALT_DNS_CONCURRENT | 组合生成的域名爆破并发数 |
| PROXY.HTTP_URL | HTTP代理URL设置 |
3-3 忘记密码重置
当忘记了登录密码,可以执行下面的命令,然后使用 admin/admin123 就可以登录了。
docker exec -ti arl_mongodb mongo -u admin -p admin
use arl
db.user.drop()
db.user.insert({ username: 'admin', password: hex_md5('arlsalt!@#'+'admin123') })今天的内容差不多就这些,需要工具或者有不懂的可以留言
欢迎技术交流,如果有错误希望能留言指正
相关文章:
【网络安全-信息收集】网络安全之信息收集和信息收集工具讲解
一,域名信息收集 1-1 域名信息查询 可以用一些在线网站进行收集,比如站长之家 域名Whois查询 - 站长之家站长之家-站长工具提供whois查询工具,汉化版的域名whois查询工具。https://whois.chinaz.com/ 可以查看一下有没有有用的信息…...
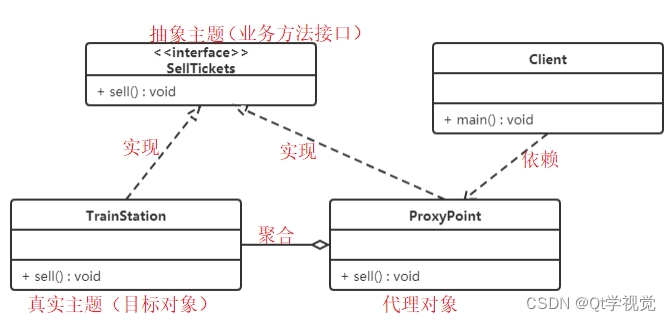
设计模式12、代理模式 Proxy
解释说明:代理模式(Proxy Pattern)为其他对象提供了一种代理,以控制对这个对象的访问。在某些情况下,一个对象不适合或者不能直接引用另一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用。 抽…...

ZXing - barcode scanning library for Java, Android
官网 GitHub - zxing/zxing: ZXing ("Zebra Crossing") barcode scanning library for Java, Android 使用说明 Getting Started Developing zxing/zxing Wiki GitHub 参考 Android中二维码的扫描与生成(zxing库)_android 二维码生成-C…...

MySQL存储引擎:选择合适的引擎优化数据库性能
什么是存储引擎? 在MySQL中,存储引擎是数据库管理系统的一部分,负责数据的存储、检索和管理。 常见的MySQL存储引擎 InnoDB InnoDB是MySQL的默认存储引擎,它支持事务和行级锁定,适用于大多数在线事务处理ÿ…...

用向量数据库Milvus Cloud 搭建AI聊天机器人
加入大语言模型(LLM) 接着,需要在聊天机器人中加入 LLM。这样,用户就可以和聊天机器人开展对话了。本示例中,我们将使用 OpenAI ChatGPT 背后的模型服务:GPT-3.5。 聊天记录 为了使 LLM 回答更准确,我们需要存储用户和机器人的聊天记录,并在查询时调用这些记录,可以用…...

深入理解JVM虚拟机第十一篇:详细介绍JVM中运行时数据区
文章目录 前言 一:运行时数据区详解 1:线程私有和线程公有区域 2:阿里的运行时数据区图...

mysql面试题17:MySQL引擎InnoDB与MyISAM的区别
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:MySQL引擎InnoDB与MyISAM的区别 InnoDB和MyISAM是MySQL中两种常见的存储引擎,它们在功能和性能方面有一些区别。下面将详细介绍它们之间的差异。…...

第2篇 机器学习基础 —(1)机器学习方式及分类、回归
前言:Hello大家好,我是小哥谈。机器学习是一种人工智能的分支,它使用算法和数学模型来使计算机系统能够从经验数据中学习和改进,而无需显式地编程。机器学习的目标是通过从数据中发现模式和规律,从而使计算机能够自动进…...

uniapp echarts 适配H5与微信小程序
文章目录 前言一、修改 ec-canvas组件1.1 在ec-canvas组件methods中定义一个initChart方法1.2 用initChart全局替换this.ec.onInit1.3 监听数据变化1.4 ec-canvas完整代码参考 二、H5 echarts组件三、供外部调用的组件外部调用组件 uni-chart代码使用uni-chart 前言 接上文&…...

第46节——redux中使用不可变数据+封装immer中间件——了解
一、为什么redux中要使用不可变数据 Redux 要求使用不可变数据,是因为它遵循了函数式编程的原则。在函数式编程中,数据不可变是一项重要的原则,这有助于避免状态更改产生的不可预知的副作用。 在 Redux 中,每当 action 被分发&a…...

《数字图像处理-OpenCV/Python》连载(10)图像属性与数据类型
《数字图像处理-OpenCV/Python》连载(10)图像属性与数据类型 本书京东优惠购书链接:https://item.jd.com/14098452.html 本书CSDN独家连载专栏:https://blog.csdn.net/youcans/category_12418787.html 第2章 图像的数据格式 在P…...

sheng的学习笔记-【中文】【吴恩达课后测验】Course 2 - 改善深层神经网络 - 第三周测验
课程2_第3周_测验题 目录:目录 第一题 1.如果在大量的超参数中搜索最佳的参数值,那么应该尝试在网格中搜索而不是使用随机值,以便更系统的搜索,而不是依靠运气,请问这句话是正确的吗? A. 【 】对 B.…...
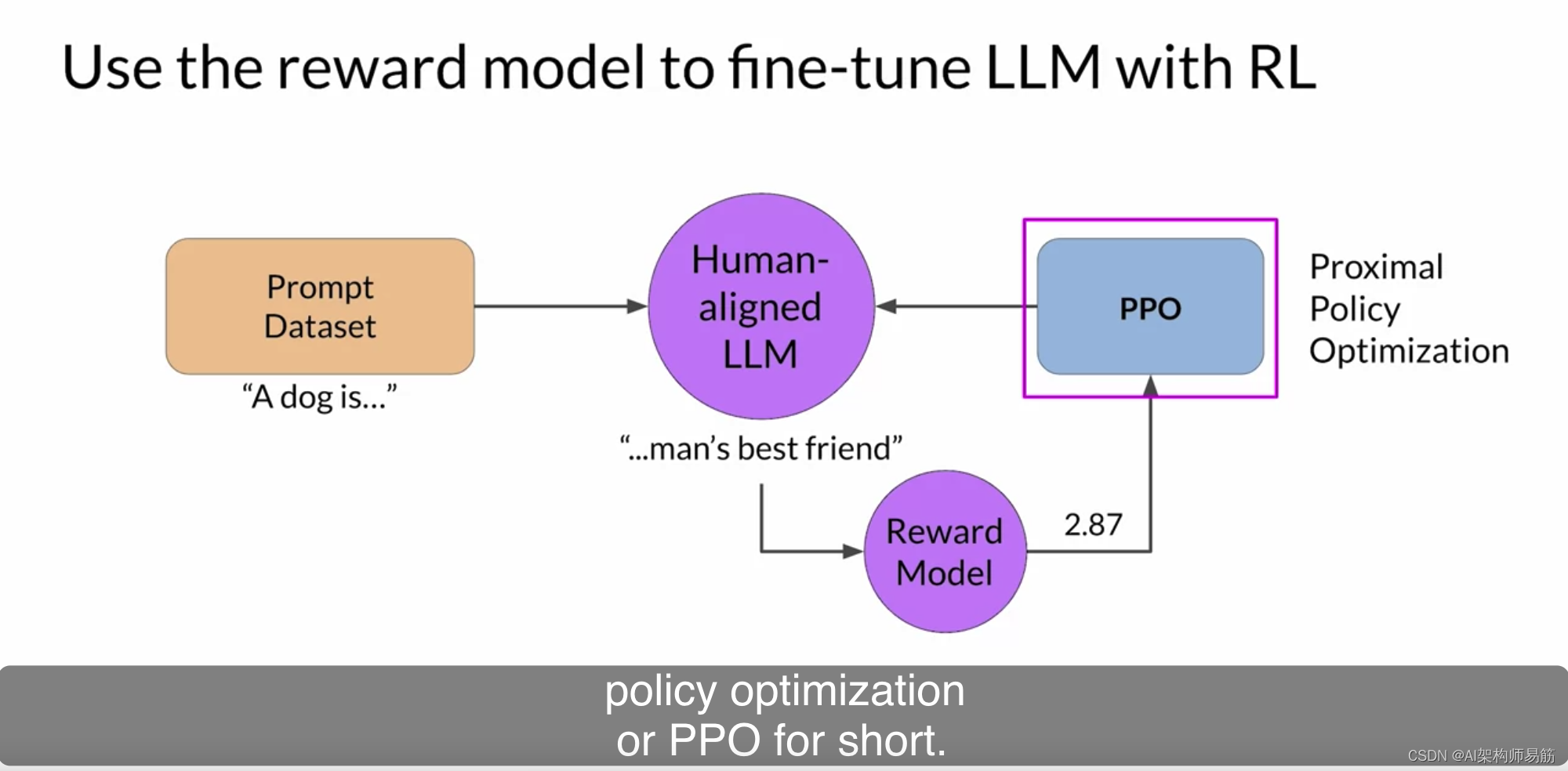
LLMs 用强化学习进行微调 RLHF: Fine-tuning with reinforcement learning
让我们把一切都整合在一起,看看您将如何在强化学习过程中使用奖励模型来更新LLM的权重,并生成与人对齐的模型。请记住,您希望从已经在您感兴趣的任务上表现良好的模型开始。您将努力使指导发现您的LLM对齐。首先,您将从提示数据集…...
iMazing 2.17.10官方中文版含2023最新激活许可证码
iMazing 2.17.10官方中文版是一款iOS设备管理软件,该软件支持对基于iOS系统的设备进行数据传输与备份,用户可以将包括:照片、音乐、铃声、视频、电子书及通讯录等在内的众多信息在Windows/Mac电脑中传输/备份/管理。 iMazing 2.17.10官方中文…...

如何在windows系统环境下使用tail命令查看日志
答案是: 使用tail for Windows工具 tail for Windows 是便携式软件不需要安装,它可用于显示文件的最后一行并跟踪/监视文件的更改。 下载地址: https://tail-for-windows.en.softonic.com/ 点击直接下载 解压使用 解压后需将tail.exe放入 c:…...

设计模式——访问者模式
访问者模式是什么? 表示一个作用于某对象结构中的各元素的操作,它使你可以再不改变各元素的类的前提下定义作用于这些元素的新操作 访问者模式解决什么问题? 男女在不同情境下表现的不同 abstract class Person {protected String action…...
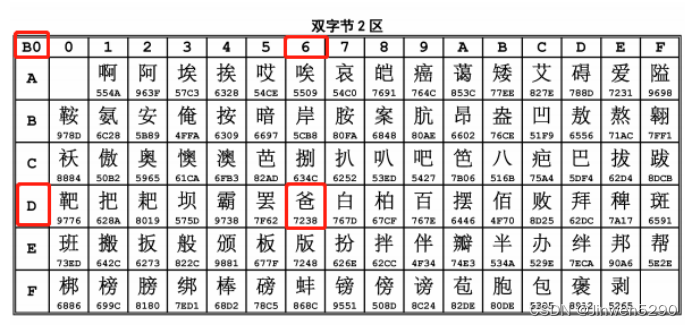
一文读懂UTF-8的编码规则
之前写过一篇文章“一文彻底搞懂计算机中文编码”里面只是介绍了GB2312编码知识,关于utf8没有涉及到,经过查询资料发现utf8是对unicode的一种可变长度字符编码,所以再记录一下。 现在国家对于信息技术中文编码字符集制定的标准是《GB 18030-…...
二叉树题目:路径总和 II
文章目录 题目标题和出处难度题目描述要求示例数据范围 前言解法一思路和算法代码复杂度分析 解法二思路和算法代码复杂度分析 题目 标题和出处 标题:路径总和 II 出处:113. 路径总和 II 难度 4 级 题目描述 要求 给你二叉树的根结点 root \tex…...

Qt model/view 理解01
在 Qt 中对数据处理主要有两种方式:1)直接对包含数据的的数据项 item 进行操作,这种方法简单、易操作,现实方式单一的缺点,特别是对于大数据或在不同位置重复出现的数据必须依次对其进行操作,如果现实方式改…...

c与c++中的字符串
在c中,string本质上是一个类; string与char *有些区别: char*是一个指针;string是一个类,类内封装了char*,管理这一个字符串,是一个char*的容器 在使用string类型时,要加上其头文…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

解读《网络安全法》最新修订,把握网络安全新趋势
《网络安全法》自2017年施行以来,在维护网络空间安全方面发挥了重要作用。但随着网络环境的日益复杂,网络攻击、数据泄露等事件频发,现行法律已难以完全适应新的风险挑战。 2025年3月28日,国家网信办会同相关部门起草了《网络安全…...

DBLP数据库是什么?
DBLP(Digital Bibliography & Library Project)Computer Science Bibliography是全球著名的计算机科学出版物的开放书目数据库。DBLP所收录的期刊和会议论文质量较高,数据库文献更新速度很快,很好地反映了国际计算机科学学术研…...
阿里云Ubuntu 22.04 64位搭建Flask流程(亲测)
cd /home 进入home盘 安装虚拟环境: 1、安装virtualenv pip install virtualenv 2.创建新的虚拟环境: virtualenv myenv 3、激活虚拟环境(激活环境可以在当前环境下安装包) source myenv/bin/activate 此时,终端…...

在golang中如何将已安装的依赖降级处理,比如:将 go-ansible/v2@v2.2.0 更换为 go-ansible/@v1.1.7
在 Go 项目中降级 go-ansible 从 v2.2.0 到 v1.1.7 具体步骤: 第一步: 修改 go.mod 文件 // 原 v2 版本声明 require github.com/apenella/go-ansible/v2 v2.2.0 替换为: // 改为 v…...

AD学习(3)
1 PCB封装元素组成及简单的PCB封装创建 封装的组成部分: (1)PCB焊盘:表层的铜 ,top层的铜 (2)管脚序号:用来关联原理图中的管脚的序号,原理图的序号需要和PCB封装一一…...
PydanticAI快速入门示例
参考链接:https://ai.pydantic.dev/#why-use-pydanticai 示例代码 from pydantic_ai import Agent from pydantic_ai.models.openai import OpenAIModel from pydantic_ai.providers.openai import OpenAIProvider# 配置使用阿里云通义千问模型 model OpenAIMode…...