Go 基本数据类型和 string 类型介绍
Go 基础之基本数据类型
文章目录
- Go 基础之基本数据类型
- 一、整型
- 1.1 平台无关整型
- 1.1.1 基本概念
- 1.1.2 分类
- 有符号整型`(int8~int64)`
- 无符号整型`(uint8~uint64)`
- 1.2 平台相关整型
- 1.2.1 基本概念
- 1.2.2 注意点
- 1.2.3 获取三个类型在目标运行平台上的长度
- 1.3 整型的溢出问题
- 1.3.1 什么是整形溢出?
- 1.4 整型字面值与格式化输出
- 二、浮点型
- 2.1 `IEEE 754` 标准
- 2.2 浮点类型
- 2.3 `float32` 与`float64` 这两种浮点类型有什么异同点呢?
- 2.4 浮点型字面值与格式化输出
- 2.4.1 直白地用十进制表示的浮点值形式
- 2.4.2 科学计数法形式
- 2.4.3 浮点数的格式化输出
- 2.5 math 包
- 2.6 数字类型的极值
- 三、小结
- 四、复数
- 4.1 复数
- 4.2 复数类型
- 4.3 复数字面值
- 4.4 格式化输出
- 五、布尔值
- 5.1 布尔类型声明
- 5.2 注意:
- 5.3 逻辑运算符
- 六、字符串
- 6.1 两种写法
- 6.1.1 单行字符串
- 6.1.2 多行字符串
- 6.2 字符串转义符
- 6.3 字符串特性
- 6.3.1 string 类型的数据是不可变的
- 6.3.2 Go 语言里的字符串的内部实现使用`UTF-8`编码
- 6.4 字符串的常用操作
- 6.4.1 字符串拼接
- 6.4.2 字符串长度
- 6.4.3 索引取值
- 6.4.4 字符迭代
- (一)、for 迭代
- (二)、for range 迭代
- 6.4.5 字符串比较
- 6.4.6 字符串转换
- 6.4.7 strings 提供的常用API
- 七、byte和rune类型
- 7.1 字符
- 7.2 byte
- 7.3 rune
- 7.4 简单示例
- 八、类型转换
- 九、自定义类型
- 9.1 type 关键字
- 9.2 自定义类型
- 十、数字类型基本运算
- 10.1 数字类型的基本运算符表格
- 10.2 基本运算
- 十一、思考
一、整型
所谓整型,主要用来表示现实世界中整型数量,比如年龄,分数,排名等等
Go 语言整型可以分为平台无关整型和平台相关整型这两种,它们的区别主要就在,这些整数类型在不同 CPU 架构或操作系统下面,它们的长度是否是一致的。
1.1 平台无关整型
1.1.1 基本概念
- Go语言提供了几种平台无关的整数类型,它们的长度在不同的平台上是一致的。
1.1.2 分类
平台无关的整型也可以分成两类:
有符号整型(int8~int64)
使用最高位(最左边的位)作为符号位,表示正数和负数。有符号整型的取值范围是从负数到正数,因此可以表示负数、零和正数。
无符号整型(uint8~uint64)
不使用符号位,因此只能表示非负数(零和正数)。无符号整型的取值范围是从零到正数最大值。
| 类型 | 长度 | 取值范围 | |
|---|---|---|---|
| 有符号整型 | int8 | 1个字节 | [-128, 127] |
| int16 | 2个字节 | [-32768, 32767] | |
| int32 | 4个字节 | [- 2147483648, 2147483647] | |
| int64 | 8个字节 | [ -9223372036854775808, 9223372036854775807] | |
| 无符号整型 | uint8 | 1个字节 | [0, 255] |
| uint16 | 2个字节 | [0, 65535] | |
| uint32 | 4个字节 | [0, 4294967295] | |
| uint64 | 8个字节 | [0, 18446744073709551615] |
有符号整型(int8int64)和无符号整型(uint8uint64)两者的本质差别在于最高二进制位(bit 位)是否被解释为符号位,这点会影响到无符号整型与有符号整型的取值范围。
以下图中的这个 8 比特(一个字节)的整型值为例,当它被解释为无符号整型 uint8 时,和它被解释为有符号整型 int8 时表示的值是不同的:

在同样的比特位表示下,当最高比特位被解释为符号位时,它代表一个有符号整型(int8),它表示的值为 -127;当最高比特位不被解释为符号位时,它代表一个无符号整型 (uint8),它表示的值为 129。
即便最高比特位被解释为符号位,上面的有符号整型所表示值也应该为 -1 啊,怎么会是 -127 呢?
这是因为 Go 采用 2 的补码(Two’s Complement)作为整型的比特位编码方法。因此,我们不能简单地将最高比特位看成负号,把其余比特位表示的值看成负号后面的数值。Go 的补码是通过原码逐位取反后再加 1 得到的,比如,我们以 -127 这个值为例,它的补码转换过程就是这样的:

1.2 平台相关整型
1.2.1 基本概念
- Go语言还提供了一些整数类型,它们的长度会根据运行平台的改变而改变,这些整数类型的长度依赖于具体的CPU架构和操作系统。
| 类型 | 32位长度 | 64位长度 | |
|---|---|---|---|
| 默认的有符号整型 | int | 32位(4字节) | 64位(8字节) |
| 默认的无符号整型 | unit | 32位(4字节) | 64位(8字节) |
| 无符号整型 | uintptr | “”“大到足以存储任意一个指针的值”“(Go规范描 述)” |
1.2.2 注意点
在这里我们要特别注意一点,由于这三个类型的长度是平台相关的,所以我们在编写有移植性要求的代码时,千万不要强依赖这些类型的长度。
1.2.3 获取三个类型在目标运行平台上的长度
如果你不知道这三个类型在目标运行平台上的长度,可以通过 unsafe 包提供的 SizeOf 函数来获取
比如在 x86-64 平台上,它们的长度均为 8:
var a, b = int(5), uint(6)
var p uintptr = 0x12345678
fmt.Println("signed integer a's length is", unsafe.Sizeof(a)) // 8
fmt.Println("unsigned integer b's length is", unsafe.Sizeof(b)) // 8
fmt.Println("uintptr's length is", unsafe.Sizeof(p)) // 8
1.3 整型的溢出问题
1.3.1 什么是整形溢出?
- 整型溢出指的是在整型变量所能表示的数值范围之外的值。整型变量通常有最大值和最小值限制
无论哪种整型,都有它的取值范围,也就是有它可以表示的值边界。如果这个整型因为参与某个运算,导致结果超出了这个整型的值边界,我们就说发生了整型溢出的问题。由于整型无法表示它溢出后的那个“结果”,所以出现溢出情况后,对应的整型变量的值依然会落到它的取值范围内,只是结果值与我们的预期不符,导致程序逻辑出错。
var s int8 = 127
s += 1 // 预期128,实际结果-128var u uint8 = 1
u -= 2 // 预期-1,实际结果255
你看,有符号整型变量 s 初始值为 127,在加 1 操作后,我们预期得到 128,但由于 128 超出了 int8 的取值边界,其实际结果变成了 -128。无符号整型变量 u 也是一样的道理,它的初值为 1,在进行减 2 操作后,我们预期得到 -1,但由于 -1 超出了 uint8 的取值边界,它的实际结果变成了 255。
这个问题最容易发生在循环语句的结束条件判断中,因为这也是经常使用整型变量的地方。无论无符号整型,还是有符号整型都存在溢出的问题,所以我们要十分小心地选择参与循环语句结束判断的整型变量类型,以及与之比较的边界值。
1.4 整型字面值与格式化输出
Go 语言在设计开始,就继承了 C 语言关于**数值字面值(Number Literal)**的语法形式。早期 Go 版本支持十进制、八进制、十六进制的数值字面值形式,比如:
a := 53 // 十进制
b := 0700 // 八进制,以"0"为前缀
c1 := 0xaabbcc // 十六进制,以"0x"为前缀
c2 := 0Xddeeff // 十六进制,以"0X"为前缀
Go 1.13 版本中,Go 又增加了对二进制字面值的支持和两种八进制字面值的形式,比如:
d1 := 0b10000001 // 二进制,以"0b"为前缀
d2 := 0B10000001 // 二进制,以"0B"为前缀
e1 := 0o700 // 八进制,以"0o"为前缀
e2 := 0O700 // 八进制,以"0O"为前缀
为提升字面值的可读性,Go 1.13 版本还支持在字面值中增加数字分隔符“_”,分隔符可以用来将数字分组以提高可读性。比如每 3 个数字一组,也可以用来分隔前缀与字面值中的第一个数字:
a := 5_3_7 // 十进制: 537
b := 0b_1000_0111 // 二进制位表示为10000111
c1 := 0_700 // 八进制: 0700
c2 := 0o_700 // 八进制: 0700
d1 := 0x_5c_6d // 十六进制:0x5c6d
不过,这里你要注意一下,Go 1.13 中增加的二进制字面值以及数字分隔符,只在 go.mod 中的 go version 指示字段为 Go 1.13 以及以后版本的时候,才会生效,否则编译器会报错。
反过来,我们也可以通过标准库 fmt 包的格式化输出函数,将一个整型变量输出为不同进制的形式。比如下面就是将十进制整型值 59,格式化输出为二进制、八进制和十六进制的代码:
var a int8 = 59
fmt.Printf("%b\n", a) //输出二进制:111011
fmt.Printf("%d\n", a) //输出十进制:59
fmt.Printf("%o\n", a) //输出八进制:73
fmt.Printf("%O\n", a) //输出八进制(带0o前缀):0o73
fmt.Printf("%x\n", a) //输出十六进制(小写):3b
fmt.Printf("%X\n", a) //输出十六进制(大写):3B
二、浮点型
2.1 IEEE 754 标准
IEEE 754 是 IEEE 制定的二进制浮点数算术标准,它是 20 世纪 80 年代以来最广泛使用的浮点数运算标准,被许多 CPU 与浮点运算器采用。现存的大部分主流编程语言,包括 Go 语言,都提供了符合 IEEE 754 标准的浮点数格式与算术运算。
IEEE 754 标准规定了四种表示浮点数值的方式:单精度(32 位)、双精度(64 位)、扩展单精度(43 比特以上)与扩展双精度(79 比特以上,通常以 80 位实现)。后两种其实很少使用,我们重点关注前面两个就好了。
2.2 浮点类型
Go语言支持两种浮点型数:float32和float64。这两种浮点型数据格式遵循IEEE 754标准。
浮点类型与前面的整型相比,Go 提供的浮点类型都是平台无关的。
2.3 float32 与float64 这两种浮点类型有什么异同点呢?
无论是 float32 还是 float64,它们的变量的默认值都为 0.0,不同的是它们占用的内存空间大小是不一样的,可以表示的浮点数的范围与精度也不同。那么浮点数在内存中的二进制表示究竟是怎么样的呢?
浮点数在内存中的二进制表示(Bit Representation)要比整型复杂得多,IEEE 754 规范给出了在内存中存储和表示一个浮点数的标准形式,见下图:

我们看到浮点数在内存中的二进制表示分三个部分:符号位、阶码(即经过换算的指数),以及尾数。这样表示的一个浮点数,它的值等于:

其中浮点值的符号由符号位决定:当符号位为 1 时,浮点值为负值;当符号位为 0 时,浮点值为正值。公式中 offset 被称为阶码偏移值,这个我们待会再讲。
**我们首先来看单精度(float32)与双精度(float64)浮点数在阶码和尾数上的不同。**这两种浮点数的阶码与尾数所使用的位数是不一样的,你可以看下 IEEE 754 标准中单精度和双精度浮点数的各个部分的长度规定:

我们看到,单精度浮点类型(float32)为符号位分配了 1 个 bit,为阶码分配了 8 个 bit,剩下的 23 个 bit 分给了尾数。而双精度浮点类型,除了符号位的长度与单精度一样之外,其余两个部分的长度都要远大于单精度浮点型,阶码可用的 bit 位数量为 11,尾数则更是拥有了 52 个 bit 位。
**接着,我们再来看前面提到的“阶码偏移值”,我想用一个例子直观地让你感受一下。**在这个例子中,我们来看看如何将一个十进制形式的浮点值 139.8125,转换为 IEEE 754 规定中的那种单精度二进制表示。
步骤一:我们要把这个浮点数值的整数部分和小数 部分,分别转换为二进制形式(后缀 d 表示十进制数,后缀 b 表示二进制数):
- 整数部分:139d => 10001011b;
- 小数部分:0.8125d => 0.1101b(十进制小数转换为二进制可采用“乘 2 取整”的竖式计算)。
这样,原浮点值 139.8125d 进行二进制转换后,就变成 10001011.1101b。
**步骤二:移动小数点,直到整数部分仅有一个 1,也就是 10001011.1101b => 1.00010111101b。**我们看到,为了整数部分仅保留一个 1,小数点向左移了 7 位,这样指数就为 7,尾数为 00010111101b。
步骤三:计算阶码。
IEEE754 规定不能将小数点移动得到的指数,直接填到阶码部分,指数到阶码还需要一个转换过程。对于 float32 的单精度浮点数而言,阶码 = 指数 + 偏移值。偏移值的计算公式为 2^(e-1)-1,其中 e 为阶码部分的 bit 位数,这里为 8,于是单精度浮点数的阶码偏移值就为 2^(8-1)-1 = 127。这样在这个例子中,阶码 = 7 + 127 = 134d = 10000110b。float64 的双精度浮点数的阶码计算也是这样的。
**步骤四:将符号位、阶码和尾数填到各自位置,得到最终浮点数的二进制表示。**尾数位数不足 23 位,可在后面补 0。
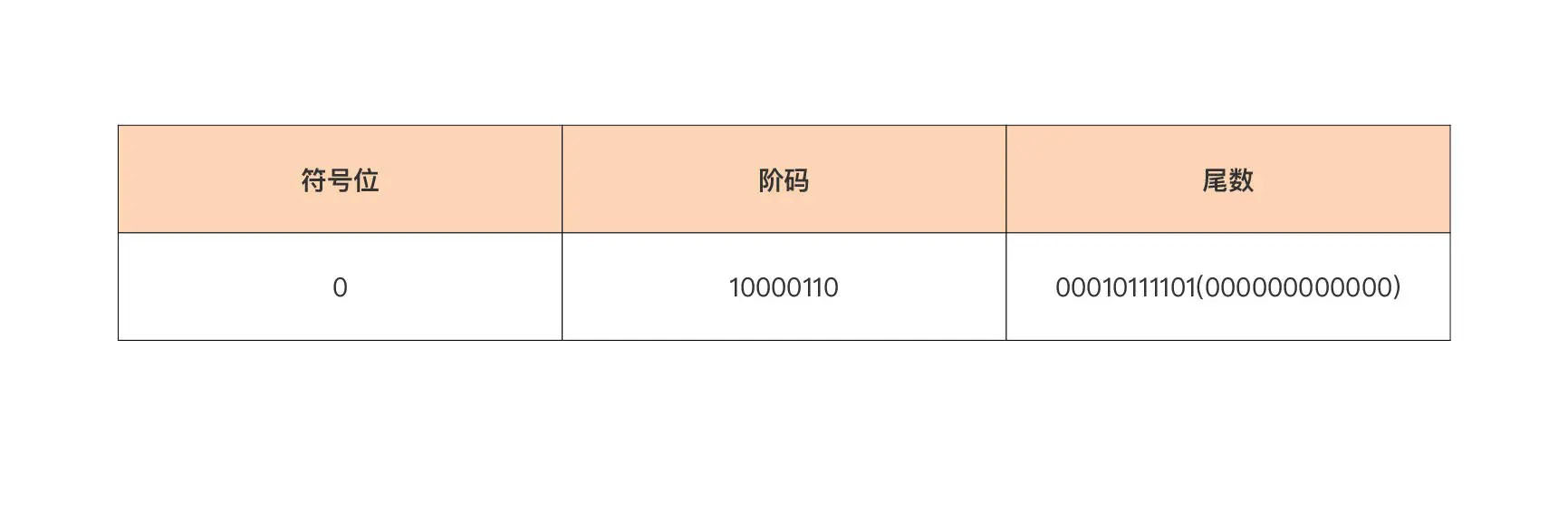
这样,最终浮点数 139.8125d 的二进制表示就为 0b_0_10000110_00010111101_000000000000。
最后,我们再通过 Go 代码输出浮点数 139.8125d 的二进制表示,和前面我们手工转换的做一下比对,看是否一致。
func main() {var f float32 = 139.8125bits := math.Float32bits(f)fmt.Printf("%b\n", bits)
}
在这段代码中,我们通过标准库的 math 包,将 float32 转换为整型。在这种转换过程中,float32 的内存表示是不会被改变的。然后我们再通过前面提过的整型值的格式化输出,将它以二进制形式输出出来。运行这个程序,我们得到下面的结果:
1000011000010111101000000000000
我们看到这个值在填上省去的最高位的 0 后,与我们手工得到的浮点数的二进制表示一模一样。这就说明我们手工推导的思路并没有错。
而且,你可以从这个例子中感受到,阶码和尾数的长度决定了浮点类型可以表示的浮点数范围与精度。因为双精度浮点类型(float64)阶码与尾数使用的比特位数更多,它可以表示的精度要远超单精度浮点类型,所以在日常开发中,我们使用双精度浮点类型(float64)的情况更多,这也是 Go 语言中浮点常量或字面值的默认类型。
而 float32 由于表示范围与精度有限,经常会给开发者造成一些困扰。比如我们可能会因为 float32 精度不足,导致输出结果与常识不符。比如下面这个例子就是这样,f1 与 f2 两个浮点类型变量被两个不同的浮点字面值初始化,但逻辑比较的结果却是两个变量的值相等。至于其中原因,我将作为思考题留给你,你可以结合前面讲解的浮点类型表示方法,对这个例子进行分析:
var f1 float32 = 16777216.0
var f2 float32 = 16777217.0
fmt.Println(f1 == f2) // true
看到这里,你是不是觉得浮点类型很神奇?和易用易理解的整型相比,浮点类型无论在二进制表示层面,还是在使用层面都要复杂得多。
2.4 浮点型字面值与格式化输出
2.4.1 直白地用十进制表示的浮点值形式
这一类,我们通过字面值就可直接确定它的浮点值,比如:
3.1415
.15 // 整数部分如果为0,整数部分可以省略不写
81.80
82. // 小数部分如果为0,小数点后的0可以省略不写
2.4.2 科学计数法形式
采用科学计数法表示的浮点字面值,我们需要通过一定的换算才能确定其浮点值。而且在这里,科学计数法形式又分为十进制形式表示的,和十六进制形式表示的两种。
使用十进制科学计数法形式的浮点数字面值,这里字面值中的 e/E 代表的幂运算的底数为 10:
6674.28e-2 // 6674.28 * 10^(-2) = 66.742800
.12345E+5 // 0.12345 * 10^5 = 12345.000000
接着是十六进制科学计数法形式的浮点数:
0x2.p10 // 2.0 * 2^10 = 2048.000000
0x1.Fp+0 // 1.9375 * 2^0 = 1.937500
这里,我们要注意,十六进制科学计数法的整数部分、小数部分用的都是十六进制形式,但指数部分依然是十进制形式,并且字面值中的 p/P 代表的幂运算的底数为 2。
2.4.3 浮点数的格式化输出
知道了浮点型的字面值后,和整型一样,fmt 包也提供了针对浮点数的格式化输出。我们最常使用的格式化输出形式是 %f。通过 %f,我们可以输出浮点数最直观的原值形式。
var f float64 = 123.45678
fmt.Printf("%f\n", f) // 123.456780
我们也可以将浮点数输出为科学计数法形式,如下面代码:
fmt.Printf("%e\n", f) // 1.234568e+02
fmt.Printf("%x\n", f) // 0x1.edd3be22e5de1p+06
其中 %e 输出的是十进制的科学计数法形式,而 %x 输出的则是十六进制的科学计数法形式。
2.5 math 包
math 包是Go语言标准库中的一个核心包,它提供了各种数学函数和常量,用于进行各种数学操作。
2.6 数字类型的极值
在Go语言中,数字类型的极值常量通常存储在math包中。这些常量用于表示浮点数和整数类型的最大值和最小值,以及其他数学常量。
int和uint族都有最大值和最小值。float32和float64只有最大值和最小正数, 没有最小值。
以下是一些常见的math包中的数字类型极值常量:
- 整数类型的极值:
math.MaxInt8:int8类型的最大值。math.MinInt8:int8类型的最小值。math.MaxInt16:int16类型的最大值。math.MinInt16:int16类型的最小值。math.MaxInt32:int32类型的最大值。math.MinInt32:int32类型的最小值。math.MaxInt64:int64类型的最大值。math.MinInt64:int64类型的最小值。
- 浮点数类型的极值:
math.MaxFloat32:float32类型的最大正有限值。math.SmallestNonzeroFloat32:float32类型的最小正非零值。math.MaxFloat64:float64类型的最大正有限值。math.SmallestNonzeroFloat64:float64类型的最小正非零值。
- 其他数学常量:
math.Pi: 圆周率 π 的近似值。math.E: 自然对数的底数 e 的近似值。math.Sqrt2和math.SqrtE:平方根的近似值。
这些常量可以在你的Go程序中使用,以便在算法和数学计算中引用数字类型的极值和常量。例如,你可以使用 math.MaxInt64 来表示 int64 类型的最大值,以便进行整数计算时进行比较或限制数值范围。同样,math.Pi 可用于计算圆的周长或面积等数学运算。
package mainimport ("fmt""math"
)func main() {// 整数类型的极值fmt.Println("int8 Max:", math.MaxInt8)fmt.Println("int8 Min:", math.MinInt8)fmt.Println("int16 Max:", math.MaxInt16)fmt.Println("int16 Min:", math.MinInt16)fmt.Println("int32 Max:", math.MaxInt32)fmt.Println("int32 Min:", math.MinInt32)fmt.Println("int64 Max:", math.MaxInt64)fmt.Println("int64 Min:", math.MinInt64)// 浮点数类型的极值fmt.Println("float32 Max:", math.MaxFloat32)fmt.Println("float32 Smallest Non-zero:", math.SmallestNonzeroFloat32)fmt.Println("float64 Max:", math.MaxFloat64)fmt.Println("float64 Smallest Non-zero:", math.SmallestNonzeroFloat64)// 其他数学常量fmt.Println("Pi:", math.Pi)fmt.Println("E:", math.E)fmt.Println("Sqrt(2):", math.Sqrt2)fmt.Println("Sqrt(E):", math.SqrtE)
}三、小结
-
int家族:int8、int16、int32、int64、int。在内存中分别用 1、2、4、8 个字节来表达,而 int 用几个字节则取决于CPU。目前大多数 int 都是 8 字节。 如果犹豫不决,就优先使用int,特殊情况除外。 -
uint家族:uint8、uint16、uint32、uint64、uint。无符号整数,类似于 int 家族,优先使用 uint。 -
float家族:float32、float64。浮点数,优先使用float64。
四、复数
4.1 复数
-
数学课本上将形如
z=a+bi(a、b 均为实数,a 称为实部,b 称为虚部)的数称为复数。 -
Go 语言则原生支持复数类型。
-
和整型、浮点型相比,复数类型在 Go 中的应用就更为局限和小众,主要用于专业领域的计算,比如矢量计算等。我们简单了解一下就可以了。
4.2 复数类型
-
Go 提供两种复数类型,它们分别是
complex64和complex128。 -
complex64的实部与虚部都是float32类型,而complex128的实部与虚部都是float64类型。 -
如果一个复数没有显示赋予类型,那么它的默认类型为
complex128。
4.3 复数字面值
关于复数字面值的表示,我们其实有三种方法。
第一种,我们可以通过复数字面值直接初始化一个复数类型变量:
var c = 5 + 6i
var d = 0o123 + .12345E+5i // 83+12345i
第二种,Go 还提供了 complex 函数,方便我们创建一个 complex128 类型值:
var c = complex(5, 6) // 5 + 6i
var d = complex(0o123, .12345E+5) // 83+12345i
第三种,你还可以通过 Go 提供的预定义的函数 real 和 imag,来获取一个复数的实部与虚部,返回值为一个浮点类型:
var c = complex(5, 6) // 5 + 6i
r := real(c) // 5.000000
i := imag(c) // 6.000000
4.4 格式化输出
复数形式的格式化输出的问题,由于 complex 类型的实部与虚部都是浮点类型,所以我们可以直接运用浮点型的格式化输出方法,来输出复数类型,以下是一个示例:
package mainimport "fmt"func main() {// 创建复数z := complex(3, 4) // 3 + 4i// 获取复数的实部和虚部,并使用浮点型格式化输出realPart := real(z)imagPart := imag(z)fmt.Printf("Real Part: %f\n", realPart)fmt.Printf("Imaginary Part: %f\n", imagPart)
}五、布尔值
5.1 布尔类型声明
在Go语言中,可以使用bool关键字来声明布尔类型变量,这些变量只能取 true(真)或 false(假)这两个值。
var isTrue bool = true
var isFalse bool = false
5.2 注意:
-
默认值:布尔类型变量的默认值为
false。var a boolfmt.Println(a) // 输出为false -
强制类型转换:Go语言不允许将整数或其他数据类型强制转换为布尔型。只有布尔类型的值可以被用于布尔表达式中,比如条件语句。
var x string = "2222"// 错误,cannot convert x (variable of type string) to type boolvar isTrue bool = bool(x)fmt.Println(isTrue) -
数值运算和转换:布尔型无法直接参与数值运算,也无法与其他数据类型进行数值转换。这是因为布尔类型只有两个可能的值,不适合数学运算或数值转换。
var b bool = true var i int = 10// 错误,无法将布尔型和整数相加 // var result = b + i// 错误,无法将整数转换为布尔型 // var b2 bool = bool(i)
5.3 逻辑运算符
| 运算符 | 说明 | 示例 | 结果 |
|---|---|---|---|
| ! (非) | 取反,将真变假,假变真 | !true | false |
| && (与) | 两边都为真,结果为真,否则为假 | true && false | false |
| || (或) | 两边任意一边为真,结果为真,两边都为假,结果为假 | true || false | true |
| == (等于) | 两边相等,结果为真;不相等,结果为假 | 1 == 1 | true |
| != (不等于) | 两边不相等,结果为真;相等,结果为假 | 1 != 2 | true |
package mainimport "fmt"func main() {var isTrue bool = truevar isFalse bool = false// 布尔值的逻辑运算andResult := isTrue && isFalse // 与运算,结果为 falseorResult := isTrue || isFalse // 或运算,结果为 truenotResult := !isTrue // 非运算,结果为 falsefmt.Println("AND result:", andResult)fmt.Println("OR result:", orResult)fmt.Println("NOT result:", notResult)
}
六、字符串
6.1 两种写法
6.1.1 单行字符串
使用双引号" "来定义:
s1 := "This is a string"
6.1.2 多行字符串
使用反引号 `` 来定义:
var s string = ` ,_---~~~~~----.__,,_,*^____ _____*g*\"*,--,/ __/ /' ^. / \ ^@q f[ @f | @)) | | @)) l 0 _/\/ \~____ / __ \_____/ \| _l__l_ I} [______] I] | | | |] ~ ~ || || |`
fmt.Println(s)
多行字符串中可以直接加入换行,并且会原样保留换行符。
多行字符串常用于需要编写包含换行的长文本。
需要注意:
- 单双引号定义的字符串效果一样
- 多行字符串会保留文字中的空格和换行
- 不能在单行字符串内直接换行,需要使用转义符\n
6.2 字符串转义符
Go 语言的字符串常见转义符包含回车、换行、单双引号、制表符等,如下表所示。
| 转义符 | 含义 |
|---|---|
\r | 回车符(返回行首) |
\n | 换行符(直接跳到下一行的同列位置) |
\t | 制表符 |
\' | 单引号 |
\" | 双引号 |
\\ | 反斜杠 |
举个例子,我们要打印一个Windows平台下的一个文件路径:
package main
import ("fmt"
)
func main() {fmt.Println("str := \"c:\\Code\\lesson1\\go.exe\"")
}
6.3 字符串特性
6.3.1 string 类型的数据是不可变的
- string 类型的数据是不可变的,提高了字符串的并发安全性和存储利用率。
Go 语言规定,字符串类型的值在它的生命周期内是不可改变的。这就是说,如果我们声明了一个字符串类型的变量,那我们是无法通过这个变量改变它对应的字符串值的,但这并不是说我们不能为一个字符串类型变量进行二次赋值。
什么意思呢?我们看看下面的代码就好理解了:
var s string = "hello"
s[0] = 'k' // 错误:字符串的内容是不可改变的
s = "gopher" // ok
在这段代码中,我们声明了一个字符串类型变量 s。当我们试图通过下标方式把这个字符串的第一个字符由 h 改为 k 的时候,我们会收到编译器错误的提示:字符串是不可变的。但我们仍可以像最后一行代码那样,为变量 s 重新赋值为另外一个字符串。
Go 这样的“字符串类型数据不可变”的性质给开发人员带来的最大好处,就是我们不用再担心字符串的并发安全问题。这样,Go 字符串可以被多个 Goroutine(Go 语言的轻量级用户线程)共享,开发者不用因为担心并发安全问题,使用会带来一定开销的同步机制。
另外,也由于字符串的不可变性,针对同一个字符串值,无论它在程序的几个位置被使用,Go 编译器只需要为它分配一块存储就好了,大大提高了存储利用率。
6.3.2 Go 语言里的字符串的内部实现使用UTF-8编码
- 对非 ASCII 字符提供原生支持,消除了源码在不同环境下显示乱码的可能。
Go 语言源文件默认采用的是 Unicode 字符集,Unicode 字符集是目前市面上最流行的字符集,它囊括了几乎所有主流非 ASCII 字符(包括中文字符)。Go 字符串中的每个字符都是一个 Unicode 字符,并且这些 Unicode 字符是以 UTF-8 编码格式存储在内存当中的。
6.4 字符串的常用操作
6.4.1 字符串拼接
-
使用+操作符拼接字符串
s := "hello" + " world" println(s) -
通过
fmt.Sprintf进行格式化拼接println(fmt.Sprintf("hello %d", 123))
6.4.2 字符串长度
-
使用
len()获取字符串字节长度:println(len("你好")) // 输出6println(len("你好abc")) // 输出9 -
使用
utf8.RuneCountInString()函数获取字符个数:println(utf8.RuneCountInString("你好abc")) // 输出5
6.4.3 索引取值
在字符串的实现中,真正存储数据的是底层的数组。字符串的下标操作本质上等价于底层数组的下标操作。可以通过索引下标访问字符串中每个字符:
var s = "中国人"
fmt.Printf("0x%x\n", s[0]) // 0xe4:字符“中” utf-8编码的第一个字节
我们可以看到,通过下标操作,我们获取的是字符串中特定下标上的字节,而不是字符。
6.4.4 字符迭代
Go 有两种迭代形式:常规 for 迭代与 for range 迭代。你要注意,通过这两种形式的迭代对字符串进行操作得到的结果是不同的。
(一)、for 迭代
通过常规 for 迭代对字符串进行的操作是一种字节视角的迭代,每轮迭代得到的的结果都是组成字符串内容的一个字节,以及该字节所在的下标值,这也等价于对字符串底层数组的迭代,比如下面代码:
var s = "中国人"for i := 0; i < len(s); i++ {fmt.Printf("index: %d, value: 0x%x\n", i, s[i])
}
运行这段代码,我们会看到,经过常规 for 迭代后,我们获取到的是字符串里字符的 UTF-8 编码中的一个字节:
index: 0, value: 0xe4
index: 1, value: 0xb8
index: 2, value: 0xad
index: 3, value: 0xe5
index: 4, value: 0x9b
index: 5, value: 0xbd
index: 6, value: 0xe4
index: 7, value: 0xba
index: 8, value: 0xba
(二)、for range 迭代
像下面这样使用 for range 迭代,我们得到的又是什么呢?我们继续看代码:
var s = "中国人"for i, v := range s {fmt.Printf("index: %d, value: 0x%x\n", i, v)
}
同样运行一下这段代码,我们得到:
index: 0, value: 0x4e2d
index: 3, value: 0x56fd
index: 6, value: 0x4eba
我们看到,通过 for range 迭代,我们每轮迭代得到的是字符串中 Unicode 字符的码点值,以及该字符在字符串中的偏移值。我们可以通过这样的迭代,获取字符串中的字符个数,而通过 Go 提供的内置函数 len,我们只能获取字符串内容的长度(字节个数)。当然了,获取字符串中字符个数更专业的方法,是调用标准库 UTF-8 包中的 RuneCountInString 函数。
6.4.5 字符串比较
Go 字符串类型支持各种比较关系操作符,包括 = =、!= 、>=、<=、> 和 <。在字符串的比较上,Go 采用字典序的比较策略,分别从每个字符串的起始处,开始逐个字节地对两个字符串类型变量进行比较。
当两个字符串之间出现了第一个不相同的元素,比较就结束了,这两个元素的比较结果就会做为串最终的比较结果。如果出现两个字符串长度不同的情况,长度比较小的字符串会用空元素补齐,空元素比其他非空元素都小。
以下是Go 字符串比较的示例:
func main() {// ==s1 := "世界和平"s2 := "世界" + "和平"fmt.Println(s1 == s2) // true// !=s1 = "Go"s2 = "C"fmt.Println(s1 != s2) // true// < and <=s1 = "12345"s2 = "23456"fmt.Println(s1 < s2) // truefmt.Println(s1 <= s2) // true// > and >=s1 = "12345"s2 = "123"fmt.Println(s1 > s2) // truefmt.Println(s1 >= s2) // true
}
你可以看到,鉴于 Go string 类型是不可变的,所以说如果两个字符串的长度不相同,那么我们不需要比较具体字符串数据,也可以断定两个字符串是不同的。但是如果两个字符串长度相同,就要进一步判断,数据指针是否指向同一块底层存储数据。如果还相同,那么我们可以说两个字符串是等价的,如果不同,那就还需要进一步去比对实际的数据内容。
6.4.6 字符串转换
在这方面,Go 支持字符串与字节切片、字符串与 rune 切片的双向转换,并且这种转换无需调用任何函数,只需使用显式类型转换就可以了。我们看看下面代码:
var s string = "中国人"// string -> []rune
rs := []rune(s)
fmt.Printf("%x\n", rs) // [4e2d 56fd 4eba]// string -> []byte
bs := []byte(s)
fmt.Printf("%x\n", bs) // e4b8ade59bbde4baba// []rune -> string
s1 := string(rs)
fmt.Println(s1) // 中国人// []byte -> string
s2 := string(bs)
fmt.Println(s2) // 中国人
6.4.7 strings 提供的常用API
strings包提供了Go语言字符串操作的常用API:
| 函数 | 说明 |
|---|---|
| strings.Contains(s, substr) | 判断字符串s是否包含子串substr |
| strings.Index(s, substr) | 返回子串substr在s中首次出现的索引 |
| strings.Join(a[]string, sep) | 将字符串数组a通过sep连接起来 |
| strings.Repeat(s, count) | 重复s字符串count次 |
| strings.Replace(s, old, new, n) | 将s中的old子串替换为new,最多n次 |
| strings.Split(s, sep) | 通过sep分割s字符串,返回子串数组 |
| strings.ToLower(s) | s全部转为小写 |
| strings.ToUpper(s) | s全部转为大写 |
| strings.Fields(s) | 将字符串s按空格分解为子串数组 |
| strings.TrimSpace(s) | 去除s头尾空白字符 |
七、byte和rune类型
7.1 字符
组成每个字符串的元素叫做“字符”,可以通过遍历或者单个获取字符串元素获得字符。 字符用单引号(’)包裹起来,如:
var a = '中'
var b = 'x'
7.2 byte
byte类型代表了ASCII码的一个字符。字节的值范围是0到255。是uint8的别名。- byte类型经常用于处理二进制数据流,或需要处理ASCII字符时,如读写文件,数据流的编码解码等。
例如:
var a byte = 'A'
7.3 rune
rune是int32的别名,它用于表示32位的Unicode字符,范围从0到65535,。- rune类型代表一个UTF-8字符。实际上它是一个int32的别名。
rune类型通常用于处理文本和字符串,特别是当需要支持多语言字符集(如UTF-8编码的Unicode字符)时。比如:需要处理中文、日文或者其他复合字符时,则需要用到rune类型。
例如:
var a rune = '国'
7.4 简单示例
以下是一些示例,演示了byte 和 rune 类型的用法:
package mainimport "fmt"func main() {// 使用 byte 表示单个 ASCII 字符var ch byte = 'A'fmt.Printf("byte: %c\n", ch)// 使用 rune 表示 Unicode 字符var ru rune = '你'fmt.Printf("rune: %c\n", ru)// 使用 rune 处理字符串中的 Unicode 字符str := "你好,世界!"for _, char := range str {fmt.Printf("rune: %c\n", char)}
}
在上述示例中,我们首先使用 byte 和 rune 分别表示单个ASCII字符和Unicode字符。然后,我们使用 rune 处理包含多个Unicode字符的字符串。
总之,byte 和 rune 类型在Go语言中用于处理字符和字节,其中 byte 主要用于处理ASCII字符和字节数据,而 rune 用于处理Unicode字符,特别是用于处理多语言文本。
八、类型转换
Go语言中只有强制类型转换,没有隐式类型转换。该语法只能在两个类型之间支持相互转换的时候使用。
强制类型转换的基本语法如下:
T(expression)
其中,T 表示要转换的目标类型,expression 是要转换的表达式。这个语法只能在两种数据类型之间支持相互转换的情况下使用。
以下是一些示例,演示了不同数据类型之间的强制类型转换:
package mainimport "fmt"func main() {// 整数到浮点数的转换var x int = 42y := float64(x)fmt.Printf("x: %d, y: %f\n", x, y)// 浮点数到整数的转换(截断小数部分)var a float64 = 3.14b := int(a)fmt.Printf("a: %f, b: %d\n", a, b)// 类型不匹配,需要显式转换var c int = 10var d int64 = int64(c)fmt.Printf("c: %d, d: %d\n", c, d)// 字符串到字节切片的转换str := "Hello, Go!"bytes := []byte(str)fmt.Printf("str: %s, bytes: %v\n", str, bytes)
}要注意的是,强制类型转换必须在相互兼容的类型之间进行,且需要明确指定目标类型,不会自动进行隐式转换。
九、自定义类型
9.1 type 关键字
如果我们要通过 Go 提供的类型定义语法,来创建自定义的数值类型,我们可以通过 type 关键字基于原生内置类型来声明一个新类型。
9.2 自定义类型
下面我们就来建立一个名为 MyInt 的新的数值类型看看:
type MyInt int32
这里,因为 MyInt 类型的底层类型是 int32,所以它的数值性质与 int32 完全相同,但它们仍然是完全不同的两种类型。根据 Go 的类型安全规则,我们无法直接让它们相互赋值,或者是把它们放在同一个运算中直接计算,这样编译器就会报错。
var m int = 5
var n int32 = 6
var a MyInt = m // 错误:在赋值中不能将m(int类型)作为MyInt类型使用
var a MyInt = n // 错误:在赋值中不能将n(int32类型)作为MyInt类型使用
要避免这个错误,我们需要借助显式转型,让赋值操作符左右两边的操作数保持类型一致,像下面代码中这样做:
var m int = 5
var n int32 = 6
var a MyInt = MyInt(m) // ok
var a MyInt = MyInt(n) // ok
我们也可以通过 Go 提供的类型别名(Type Alias)语法来自定义数值类型。和上面使用标准 type 语法的定义不同的是,通过类型别名语法定义的新类型与原类型别无二致,可以完全相互替代。我们来看下面代码:
type MyInt = int32var n int32 = 6
var a MyInt = n // ok
你可以看到,通过类型别名定义的 MyInt 与 int32 完全等价,所以这个时候两种类型就是同一种类型,不再需要显式转型,就可以相互赋值。
十、数字类型基本运算
10.1 数字类型的基本运算符表格
| 运算符 | 描述 | 示例 |
|---|---|---|
| + | 加法 | x + y |
| - | 减法 | x - y |
| * | 乘法 | x * y |
| / | 除法 | x / y |
| % | 求余 | x % y |
| ++ | 自增 | x++ |
| – | 自减 | x– |
10.2 基本运算
在Go语言中,数字类型(包括整数和浮点数)支持基本的数学运算,包括加法、减法、乘法和除法。以下是这些运算的示例:
package mainimport "fmt"func main() {// 整数运算var a, b int = 10, 5// 加法sum := a + bfmt.Printf("a + b = %d\n", sum)// 减法difference := a - bfmt.Printf("a - b = %d\n", difference)// 乘法product := a * bfmt.Printf("a * b = %d\n", product)// 除法quotient := a / bfmt.Printf("a / b = %d\n", quotient)// 浮点数运算var x, y float64 = 3.14, 1.5// 加法sumFloat := x + yfmt.Printf("x + y = %f\n", sumFloat)// 减法differenceFloat := x - yfmt.Printf("x - y = %f\n", differenceFloat)// 乘法productFloat := x * yfmt.Printf("x * y = %f\n", productFloat)// 除法quotientFloat := x / yfmt.Printf("x / y = %f\n", quotientFloat)
}十一、思考
下面例子中 f1 为何会与 f2 相等?
package mainimport "fmt"func main() {var f1 float32 = 16777216.0var f2 float32 = 16777217.0fmt.Println(f1 == f2) // true
}
欢迎在留言区留下你的答案。
相关文章:
Go 基本数据类型和 string 类型介绍
Go 基础之基本数据类型 文章目录 Go 基础之基本数据类型一、整型1.1 平台无关整型1.1.1 基本概念1.1.2 分类有符号整型(int8~int64)无符号整型(uint8~uint64) 1.2 平台相关整型1.2.1 基本概念1.2.2 注意点1.2.3 获取三个类型在目标…...
打印如何不换行?)
Python中print()打印如何不换行?
文章目录 Python中print()打印如何不换行python2.xpython3.x print()函数语法objects基本语法sep基本语法end基本语法 Python中print()打印如何不换行 print() 函数用于打印输出,是python中最常见的一个内置函数。 如何在Python中打印两个或多个变量、语句时而不进…...

python 学习随笔 4
列表list 将序列前几个进行替换(数量可以不同) 将序列进行间隔替换(必须保证数量相同,否则报错) 删除序列内元素 向序列后新增一个元素 向序列后新增多个元素 将序列进行数乘(不是产生几个序列哦࿰…...

【网络安全-信息收集】网络安全之信息收集和信息收集工具讲解
一,域名信息收集 1-1 域名信息查询 可以用一些在线网站进行收集,比如站长之家 域名Whois查询 - 站长之家站长之家-站长工具提供whois查询工具,汉化版的域名whois查询工具。https://whois.chinaz.com/ 可以查看一下有没有有用的信息…...
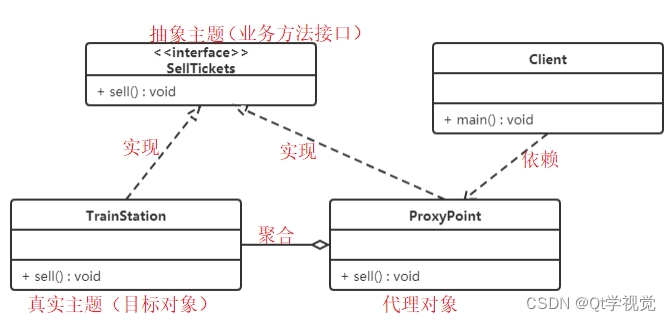
设计模式12、代理模式 Proxy
解释说明:代理模式(Proxy Pattern)为其他对象提供了一种代理,以控制对这个对象的访问。在某些情况下,一个对象不适合或者不能直接引用另一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用。 抽…...

ZXing - barcode scanning library for Java, Android
官网 GitHub - zxing/zxing: ZXing ("Zebra Crossing") barcode scanning library for Java, Android 使用说明 Getting Started Developing zxing/zxing Wiki GitHub 参考 Android中二维码的扫描与生成(zxing库)_android 二维码生成-C…...

MySQL存储引擎:选择合适的引擎优化数据库性能
什么是存储引擎? 在MySQL中,存储引擎是数据库管理系统的一部分,负责数据的存储、检索和管理。 常见的MySQL存储引擎 InnoDB InnoDB是MySQL的默认存储引擎,它支持事务和行级锁定,适用于大多数在线事务处理ÿ…...

用向量数据库Milvus Cloud 搭建AI聊天机器人
加入大语言模型(LLM) 接着,需要在聊天机器人中加入 LLM。这样,用户就可以和聊天机器人开展对话了。本示例中,我们将使用 OpenAI ChatGPT 背后的模型服务:GPT-3.5。 聊天记录 为了使 LLM 回答更准确,我们需要存储用户和机器人的聊天记录,并在查询时调用这些记录,可以用…...

深入理解JVM虚拟机第十一篇:详细介绍JVM中运行时数据区
文章目录 前言 一:运行时数据区详解 1:线程私有和线程公有区域 2:阿里的运行时数据区图...

mysql面试题17:MySQL引擎InnoDB与MyISAM的区别
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:MySQL引擎InnoDB与MyISAM的区别 InnoDB和MyISAM是MySQL中两种常见的存储引擎,它们在功能和性能方面有一些区别。下面将详细介绍它们之间的差异。…...

第2篇 机器学习基础 —(1)机器学习方式及分类、回归
前言:Hello大家好,我是小哥谈。机器学习是一种人工智能的分支,它使用算法和数学模型来使计算机系统能够从经验数据中学习和改进,而无需显式地编程。机器学习的目标是通过从数据中发现模式和规律,从而使计算机能够自动进…...

uniapp echarts 适配H5与微信小程序
文章目录 前言一、修改 ec-canvas组件1.1 在ec-canvas组件methods中定义一个initChart方法1.2 用initChart全局替换this.ec.onInit1.3 监听数据变化1.4 ec-canvas完整代码参考 二、H5 echarts组件三、供外部调用的组件外部调用组件 uni-chart代码使用uni-chart 前言 接上文&…...

第46节——redux中使用不可变数据+封装immer中间件——了解
一、为什么redux中要使用不可变数据 Redux 要求使用不可变数据,是因为它遵循了函数式编程的原则。在函数式编程中,数据不可变是一项重要的原则,这有助于避免状态更改产生的不可预知的副作用。 在 Redux 中,每当 action 被分发&a…...

《数字图像处理-OpenCV/Python》连载(10)图像属性与数据类型
《数字图像处理-OpenCV/Python》连载(10)图像属性与数据类型 本书京东优惠购书链接:https://item.jd.com/14098452.html 本书CSDN独家连载专栏:https://blog.csdn.net/youcans/category_12418787.html 第2章 图像的数据格式 在P…...

sheng的学习笔记-【中文】【吴恩达课后测验】Course 2 - 改善深层神经网络 - 第三周测验
课程2_第3周_测验题 目录:目录 第一题 1.如果在大量的超参数中搜索最佳的参数值,那么应该尝试在网格中搜索而不是使用随机值,以便更系统的搜索,而不是依靠运气,请问这句话是正确的吗? A. 【 】对 B.…...
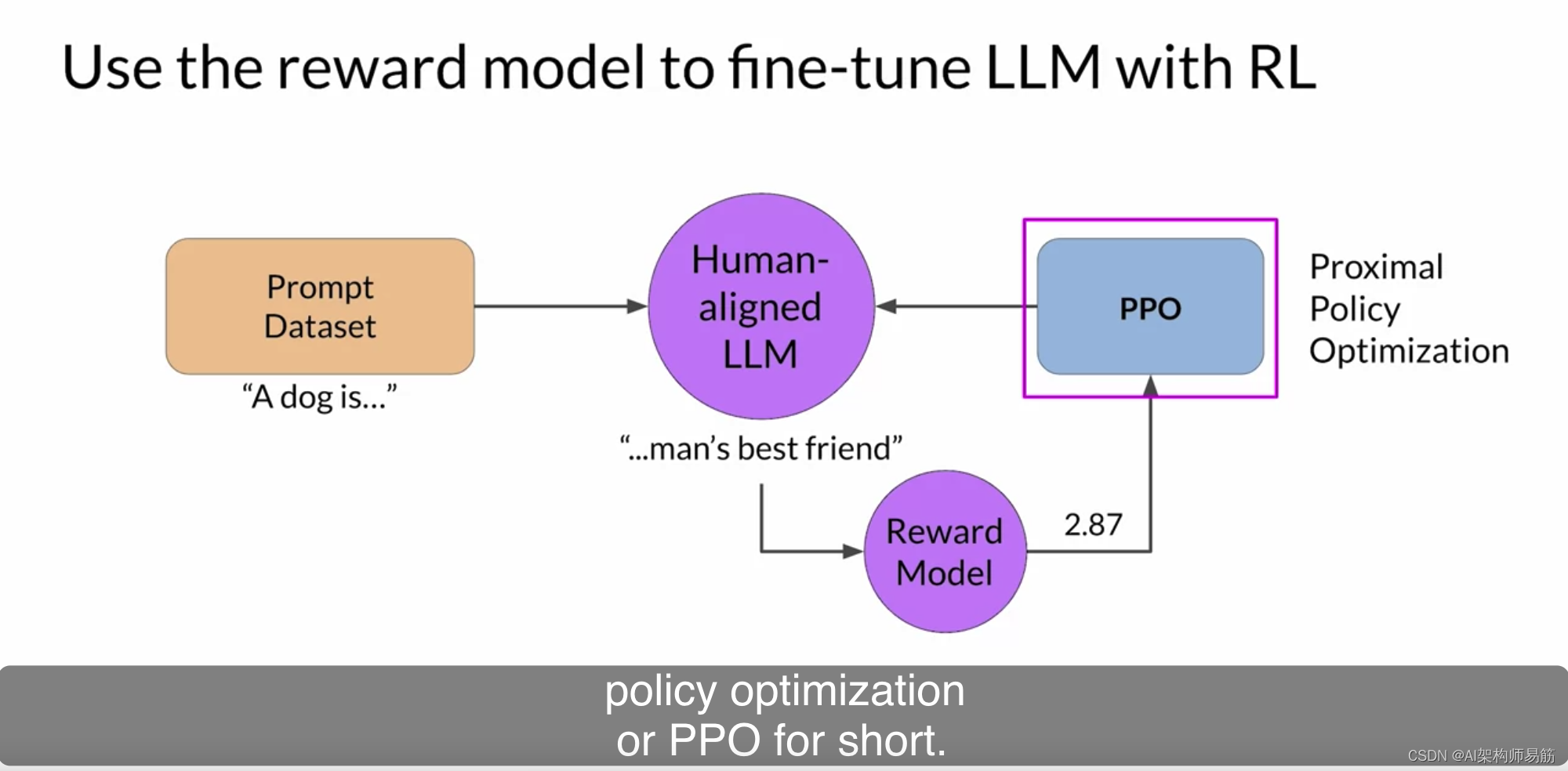
LLMs 用强化学习进行微调 RLHF: Fine-tuning with reinforcement learning
让我们把一切都整合在一起,看看您将如何在强化学习过程中使用奖励模型来更新LLM的权重,并生成与人对齐的模型。请记住,您希望从已经在您感兴趣的任务上表现良好的模型开始。您将努力使指导发现您的LLM对齐。首先,您将从提示数据集…...
iMazing 2.17.10官方中文版含2023最新激活许可证码
iMazing 2.17.10官方中文版是一款iOS设备管理软件,该软件支持对基于iOS系统的设备进行数据传输与备份,用户可以将包括:照片、音乐、铃声、视频、电子书及通讯录等在内的众多信息在Windows/Mac电脑中传输/备份/管理。 iMazing 2.17.10官方中文…...

如何在windows系统环境下使用tail命令查看日志
答案是: 使用tail for Windows工具 tail for Windows 是便携式软件不需要安装,它可用于显示文件的最后一行并跟踪/监视文件的更改。 下载地址: https://tail-for-windows.en.softonic.com/ 点击直接下载 解压使用 解压后需将tail.exe放入 c:…...

设计模式——访问者模式
访问者模式是什么? 表示一个作用于某对象结构中的各元素的操作,它使你可以再不改变各元素的类的前提下定义作用于这些元素的新操作 访问者模式解决什么问题? 男女在不同情境下表现的不同 abstract class Person {protected String action…...
一文读懂UTF-8的编码规则
之前写过一篇文章“一文彻底搞懂计算机中文编码”里面只是介绍了GB2312编码知识,关于utf8没有涉及到,经过查询资料发现utf8是对unicode的一种可变长度字符编码,所以再记录一下。 现在国家对于信息技术中文编码字符集制定的标准是《GB 18030-…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...