【C语言】八大排序算法
文章目录
- 一、冒泡排序
- 1、定义
- 2、思想及图解
- 3、代码
- 二、快速排序
- 1、hoare版本
- 2、挖坑法
- 3、前后指针法
- 4、非递归快排
- 5、快速排序优化
- 1)三数取中选key值
- 2)小区间优化
- 三、直接插入排序
- 1、定义
- 2、代码
- 四、希尔排序
- 1、定义
- 2、图解
- 3、代码
- 五、选择排序
- 1、排序思想
- 2、代码
- 六、堆排序
- 1、定义
- 2、向上调整建堆排序
- 3、向下调整建堆排序
- 七、归并排序
- 1、定义
- 2、思想及图解
- 3、代码
- 1)递归实现
- 2)非递归实现
- 八、计数排序
- 1、原理
- 2、图解
- 3、代码
- 九、总结

一、冒泡排序
如需更详细步骤可见:冒泡排序
1、定义
冒泡排序(bubble sort)是最基础的排序算法,它是一种基础的交换排序。它的原理就像汽水一样,汽水中常常有许多小气泡飘到上面。而冒泡排序这种排序算法的每一个元素也可以像小气泡一样根据自身大小一点点地向着数组一端移动。
2、思想及图解
冒泡排序的思想:相邻元素两两比较,当一个元素大于右侧相邻元素时,交换他们的位置;当一个元素小于或等于右侧元素时,位置不变。
对于以下这个无序的数列,用冒泡排序的思想进行排序:

冒泡排序单次排序图解:
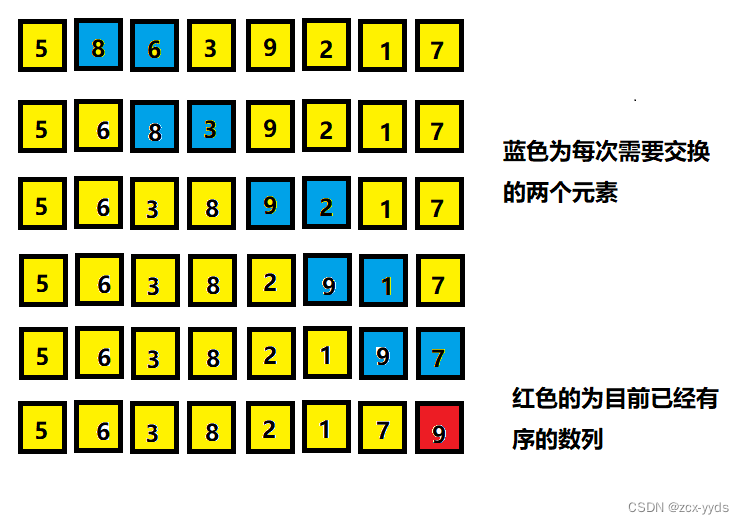
当通过一轮排序之后,元素9作为最大的元素,移动到了数列的最右端。9是目前有序数列的唯一元素。,然后继续对数列进行排序…
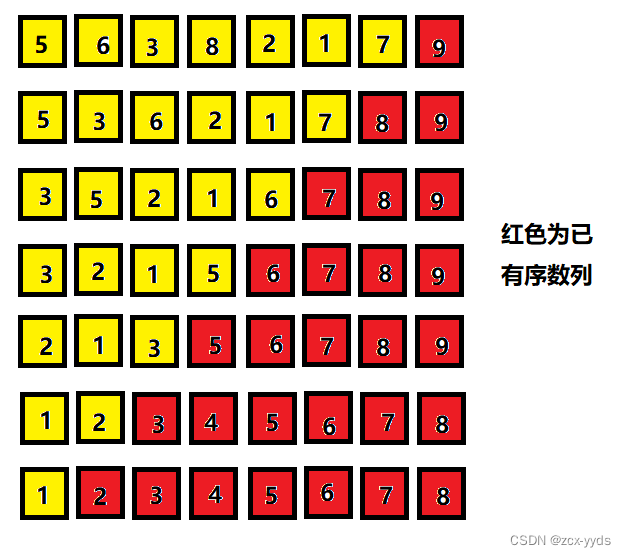
整体流程图解:
3、代码
//交换
void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}//冒泡排序
void BubbleSort(int* a, int n)
{for (int i = 0; i < n ; i++){//记录交换次数int e = 0;for (int j = 1; j < n-i; j++){if (a[j] < a[j - 1]){Swap(&a[j], &a[j - 1]);e++;}}//本次没有交换过,已经有序if (e == 0){break;}}
}
时间复杂度:O(n2)
空间复杂度:O(1)
二、快速排序
如需更详细步骤可见:快速排序
1、hoare版本
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
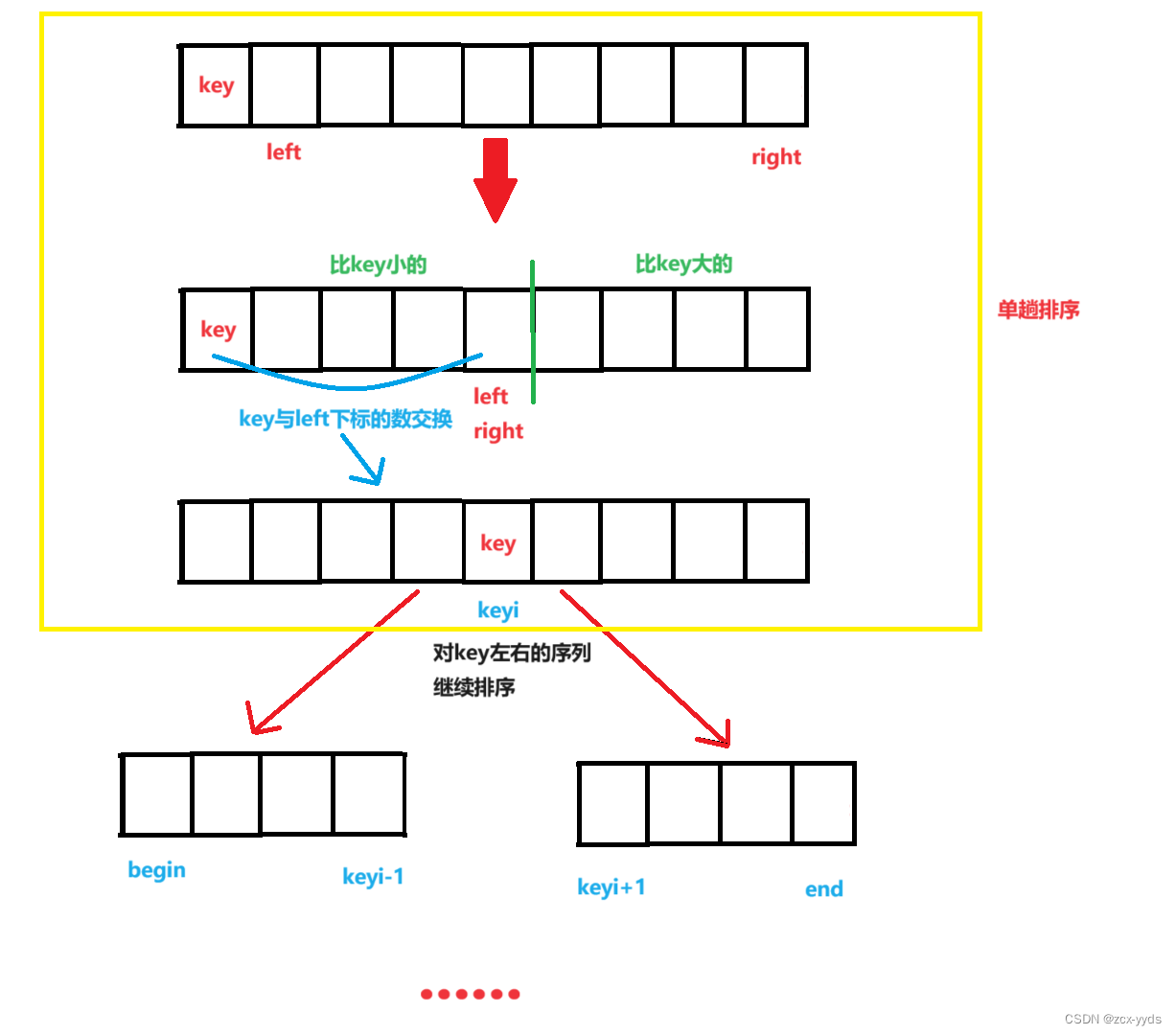
算法思想:
- 定义一个keyi存入随机一个数key的下标换到数组首元素,这里先直接默认key为数组首元素
- 定义一个left和一个right,分别存入数组首元素和尾元素的下标,用来移动交换
- 排升序我们让右边right先向左移动,找到比key的值小的元素则停下来换到left移动
- left向右移动,找到比key的值大的元素则停下
- 交换下标为left和right的元素
- 重复以上操作直到left与right相遇(相等)
- 交换key和下标为left的元素
- 此时key的左边都是比它小的数,右边都是比它大的数
- 再分别对左右序列进行以上的单趟排序,反复操作直到左右序列只有一个或者没有元素时停止操作,数列即可有序
hoare版本单趟排序图示:

hoare版本代码:
//交换
void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}
//hoare版本
void QuickSort1(int* a, int begin, int end)
{//递归结束条件if (begin >= end){return;}int keyi = begin;int left = begin;int right = end;//每趟排序直到左右相遇while (left < right){//右边先走,找到比key值小的while (left < right && a[right] >= a[keyi]){right--;}//right找到比key值小的之后换到left走,找到比key值大的while (left < right && a[left] <= a[keyi]){left++;}//交换Swap(&a[left], &a[right]);}//将key值换到中间Swap(&a[keyi], &a[left]);//更新keykeyi = left;//对左右序列继续排序QuickSort1(a, begin, keyi - 1);QuickSort1(a, keyi + 1, end);
}
整体流程图:
2、挖坑法
挖坑法思想:
- 先将第一个数据存在变量key中,将此处作为最开始的坑位,用下标hole记录
- 然后right开始向前走,找到比key值小的元素后停下,将此元素放进坑里(下标为hole处),然后此处变为坑,hole变为此时的right
- 然后left开始向后移动,找到比key值大的元素后停下,将此元素放进坑里(下标为hole处),然后此处变为坑,hole变为此时的left
- 然后又换回right移动,如此反复直到left与right相遇(left与right相遇的地方一定是坑)
- 然后将key放入left与right相遇的位置,也就是坑的位置,此时hole左边都是小于等于它的,右边都是大于等于它的
- 如此单趟排序便结束,然后继续对hole左右序列继续反复执行以上操作,直到左右序列只有一个或者没有元素时停止操作,数列即可有序
挖坑法单趟排序图示:

挖坑法代码:
//挖坑法
void QuickSort2(int* a, int begin, int end)
{//递归结束条件if (begin >= end){return;}int left = begin;int right = end;int key = a[left];//坑最初与left一样在开始位置int hole = left;//每趟排序直到左右相遇while (left < right){//右边先走,找到比key值小的while (left < right && a[right] >= key){right--;}//将right找到的比key小的元素放进坑中a[hole] = a[right];//更新坑的位置hole = right;//然后左边走找到比key值大的元素停下来while (left < right && a[left] <= key){left++;}//将left找到的比key大的元素放进坑中a[hole] = a[left];//更新坑的位置hole = left;}//将key放入坑中a[hole] = key;//对左右序列继续排序QuickSort2(a, begin, hole - 1);QuickSort2(a, hole+1, end);
}
3、前后指针法
前后指针法思想:
- 定义一个keyi存入随机一个数key的下标换到数组首元素,这里先直接默认key为数组首元素
- 定义一个prev为开头元素的下标,定义一个cur为prev下一个元素的下标
- cur下标处的值与key比较,直到cur找到比key小的值则停下来
- prev下标后移一位然后与cur下标处的值交换,然后cur后移一位(prev相当于前面比key小的那些数的最后一个的下标,所以要先后移一位再交换)
- cur继续寻找比key小的值,反复执行直到cur的值大于n
- 将key与prev下标处的值交换,此时key左边都是小于等于它的,右边都是大于等于它的
- 如此单趟排序便结束,然后继续对key左右序列继续反复执行以上操作,直到左右序列只有一个或者没有元素时停止操作,数列即可有序
前后指针法单趟排序图示:

前后指针法代码:
//交换
void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}
//前后指针
void QuickSort3(int* a, int begin, int end)
{//递归结束条件if (begin >= end){return;}int keyi = begin;int prev = begin;int cur = begin + 1;//每趟排序直到cur下标大于endwhile (cur <= end){//cur找比key小的值if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[cur], &a[prev]);}cur++;}//将key换到中间Swap(&a[keyi], &a[prev]);//更新key的下标keyi = prev;//对左右序列继续排序QuickSort3(a, begin, keyi - 1);QuickSort3(a, keyi + 1, end);
}
快速排序是一种不稳定的排序,它的时间复杂度为O(N*logN),但最坏可以达到O(N2) ,它的空间复杂度为O(logN)
4、非递归快排
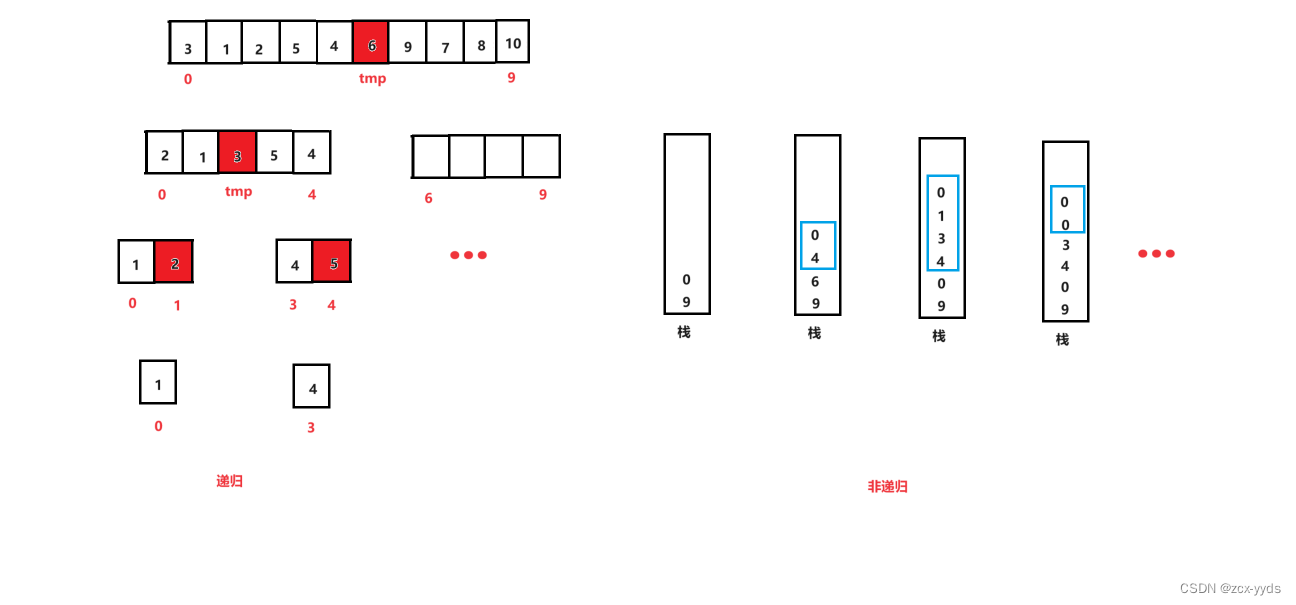
以上三种方法都是采用了分治法递归实现的快排,其实快速排序也可以非递归实现,非递归实现快排需要利用栈来实现
思路:
将数组首尾下标存入栈中,在循环中依次取出作为left和right对数组进行排序,然后对得到的key的左右两边序列也进行相同的操作,其中左边为left到keyi-1,右边为keyi+1到right,这些下标的入栈顺序需要看取出的顺序,如下面代码中是先取出后面元素下标的,所以入栈时要先入后面的,因为栈的特点是先入后出。
非递归快排代码:
(该代码中用到的栈需自己实现,C语言实现栈可参考:栈的实现)
//非递归快速排序
void QuickSortNonR(int* a, int begin, int end)
{//创建一个栈ST st;//初始化栈STInit(&st);//插入尾元素下标STPush(&st, end);//插入首元素下标STPush(&st, begin);//栈为空停下while (!STEmpty(&st)){//取出栈顶元素作为leftint left = STTop(&st);//取出后在栈中删除STPop(&st);//取出栈顶元素作为rightint right = STTop(&st);//取出后在栈中删除STPop(&st);int keyi = begin;//每趟排序直到左右相遇while (left < right){//右边先走,找到比key值小的while (left < right && a[right] >= a[keyi]){right--;}//right找到比key值小的之后换到left走,找到比key值大的while (left < right && a[left] <= a[keyi]){left++;}//交换Swap(&a[left], &a[right]);}//将key值换到中间Swap(&a[keyi], &a[left]);//更新key的下标keyi = left;// 当前数组下标样子 [left,keyi-1] keyi [keyi+1, right]//右边还有元素,按顺序插入right和keyi+1if (keyi + 1 < right){STPush(&st, right);STPush(&st, keyi + 1);}//左边还有元素,按顺序插入keyi-1和leftif (left < keyi - 1){STPush(&st, keyi - 1);STPush(&st, left);}}STDestroy(&st);
}
5、快速排序优化
1)三数取中选key值
前面三种快速排序的方法起初都要随机选取一个值作为key,我们之前是直接默认为数组首元素的,这样不够随机,容易出现最坏的情况,使得它的时间复杂度接近O(N2),所以我们可以写一个函数来选取这个key,使得它比较随机,而不是直接为首元素。
三数取中:
在一个数组最前面、最后面,中间这三个位置的数中选出大小处于中间的数
// 三数取中
int GetMidi(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[left] > a[right]){if (a[right] > a[mid]){return right;}else if(a[mid]>a[right]&&a[mid]<a[left]){return mid;}else{return left;}}else{if (a[left] > a[mid]){return left;}else if (a[mid] > a[left] && a[mid] < a[right]){return mid;}else{return right;}}
}
在快排时用三数取中法选取key值再将它换到数组开头,可以有效避免出现最坏的情况,大大提升算法效率
2)小区间优化
当递归到数据较小时可以使用插入排序,使得小区间不再递归分割,降低递归次数
三、直接插入排序
1、定义
直接插入排序就是将待排序的记录按照它的关键码值插入到一个已经排好序的有序序列中,直到所有的记录都插入完,得到一个新的有序序列。
插入排序的思想就像我们平时玩扑克牌理牌时一样,将每张牌逐个插入到一个有序的牌的序列里,最终所有的牌都是有序的。

2、代码
//插入排序
void InsertSort(int* a, int n)
{for (int i = 0; i < n-1; i++){//end可看作从左至右有序的最后一个数的下标int end = i;int tmp = a[end + 1];while (end >= 0){if (tmp < a[end]){a[end + 1] = a[end];}else{break;}end--;}//此时tmp的值大于或等于下标为end的值,所以插入在它的后面a[end+1] = tmp;}
}
当插入第i(i>=1)个元素时,前面的a[0],a[1],…,a[i-1]已经排好序,此时用a[i]的排序码与a[i-1],a[i-2],…的排序码顺序进行比较,找到插入位置即将a[i]插入,原来位置上的元素顺序后移
直接插入排序是一种稳定的排序算法,元素集合越接近有序,直接插入排序算法的时间效率越高,它的时间复杂度为O(n2),空间复杂度为O(1)
四、希尔排序
如需更详细步骤可见:希尔排序
1、定义
希尔排序法又称缩小增量法。希尔排序的基本思想是:先选定一个整数gap,把待排序数列中所有记录分成个gap个组,所有距离为gap的记录分在同一组内,并对每一组内的记录进行排序。然后缩小gap,可以取它的一半,重复上述分组和排序的工作。当gap到达1时,该数列便已有序。
当gap=1时相当于直接插入排序。所以希尔排序可以拆分为预排序和直接插入排序两部分:
- 预排序:当gap大于1时,预排序可以让大的数更快地到序列后面,小的更快到前面,gap越大跳的越快越不接近有序,gap越小跳的越慢,越接近有序
- 直接插入排序:gap不断减小,当gap为1时相当于直接插入排序,进行最后一次直接插入排序后数列便已有序
2、图解
对如下图数列用希尔排序算法进行排序:
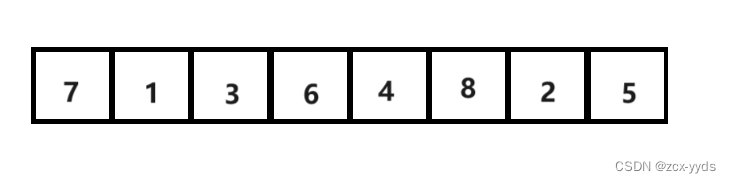
该数列一共有8个数,我们选定最初的gap值为8/2=4,相隔4的数为一组,如下图,同一组数颜色相同
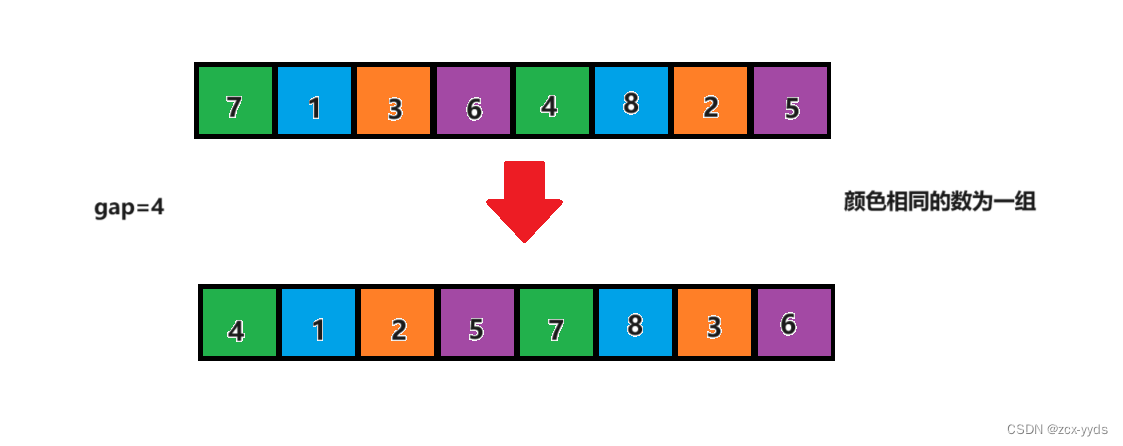
对每一组排序了之后,gap再除2变为2
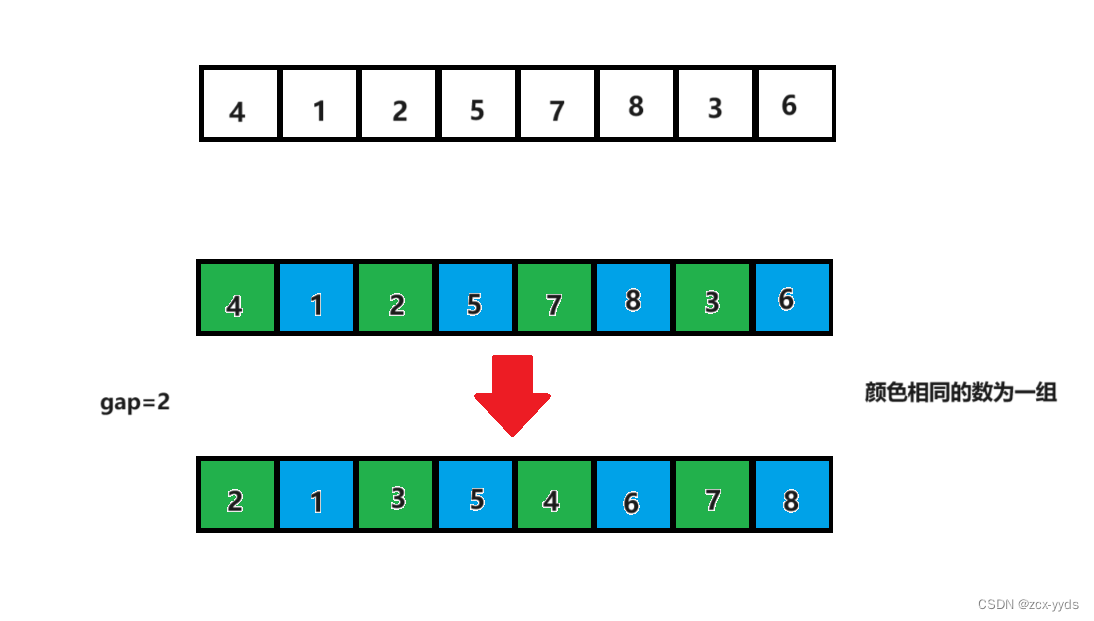
对每一组排序了之后,gap再除2变为1,此时相当于直接插入排序
3、代码
//希尔排序
void ShellSort(int* a, int n)
{//gap进入循环后会先除2int gap = n ;while (gap > 1){gap /= 2;for (int i = 0; i < n - gap; i++){int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];}else{break;}end -= gap;}a[end + gap] = tmp;}}
}
希尔排序是不稳定的,它是对直接插入排序的优化,因为gap的取值方法不止一种,导致希尔排序的时间复杂度很难去计算
五、选择排序
1、排序思想
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完 。
- 在元素集合array[i]–array[n-1]中选择关键码最大(小)的数据元素
- 若它不是这组元素中的最后一个(第一个)元素,则将它与这组元素中的最后一个(第一个)元素交换
- 在剩余的array[i]–array[n-2](array[i+1]–array[n-1])集合中,重复上述步骤,直到集合剩余1个元素
2、代码
这里的代码是优化过的,同时找最大和最小元素,最小的放左边,最大的放右边,然后对除了两边找出的值外剩下的元素继续进行相同操作,直到left不再小于right则有序
//交换
void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}
//选择排序
void SelectSort(int* a, int n)
{int left = 0;int right = n - 1 ;while (left < right){int maxi = left;int mini = left;for (int i = left + 1; i <= right; i++){//找区间内最大元素下标if (a[i] > a[maxi]){maxi = i;}//找区间内最小元素下标if (a[i] < a[mini]){mini = i;}}Swap(&a[left], &a[mini]);//如果最大数的下标等于left,上一次交换最小数时已经被换到下标为mini元素上if (maxi == left){maxi = mini;}Swap(&a[right], &a[maxi]);left++;right--;}
}
时间复杂度:O(N2)
空间复杂度:O(1)
六、堆排序
如需更详细步骤可见:堆排序
1、定义
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆
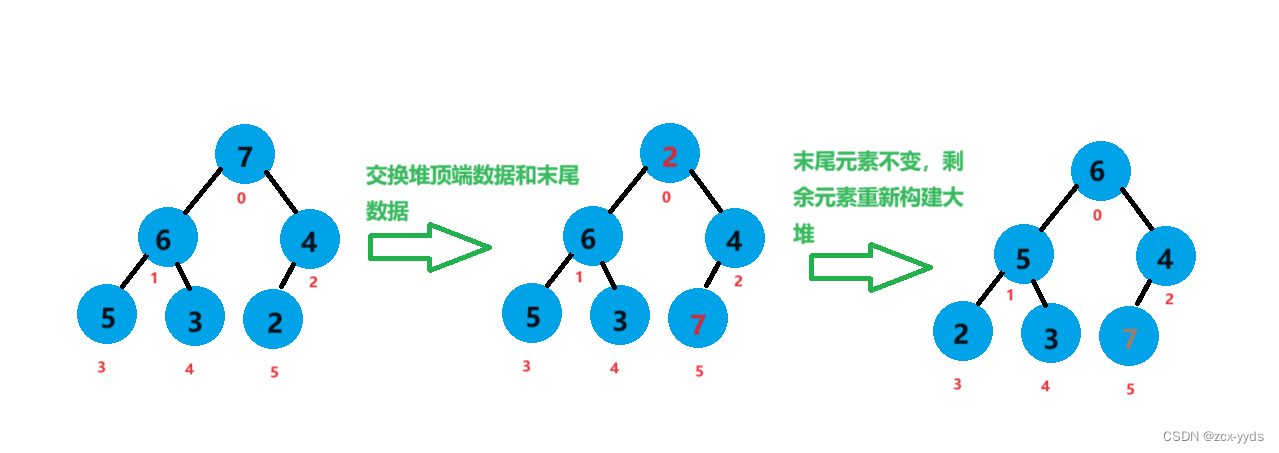
1、根据要排什么序建大堆或小堆,此时堆顶端的元素就是最值
2、将顶端元素和末尾元素交换,此时末尾元素就是有序的,剩下的还有n-1个元素
3、将剩下的n-1个元素再次构建成堆,然后将堆顶端元素与第n-1个元素互换,反复执行便可得到有序数组
2、向上调整建堆排序
使用向上调整算法建堆的堆排序
例如:将数组a用堆排序按从小到大排列(升序)
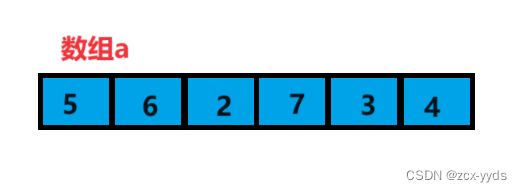
向上调整算法的前提条件是:前面的元素是堆
对于单个结点来说既可以看作一个大堆,所以便可以通过向上调整算法依次对数组元素进行调整,那进行调整的元素前就一定是堆,满足条件
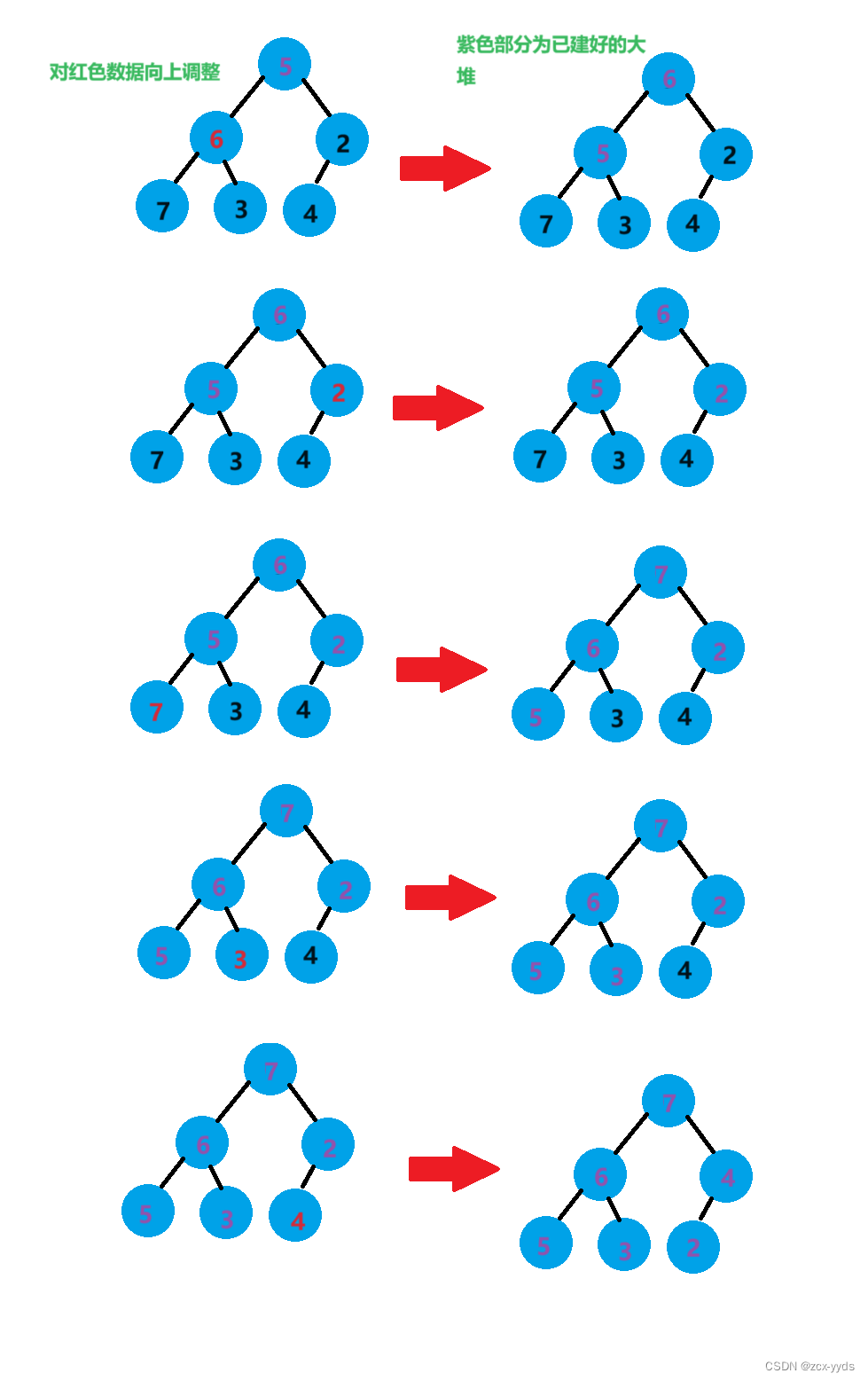
创建好的大堆如下:
将堆的顶端元素7和末尾元素2进行交换,对除7外剩下的元素进行向下调整重新构建大堆
此时7已经是有序的,将元素6和元素3进行交换,对除6、7外剩下元素进行向下调整重新构建大堆
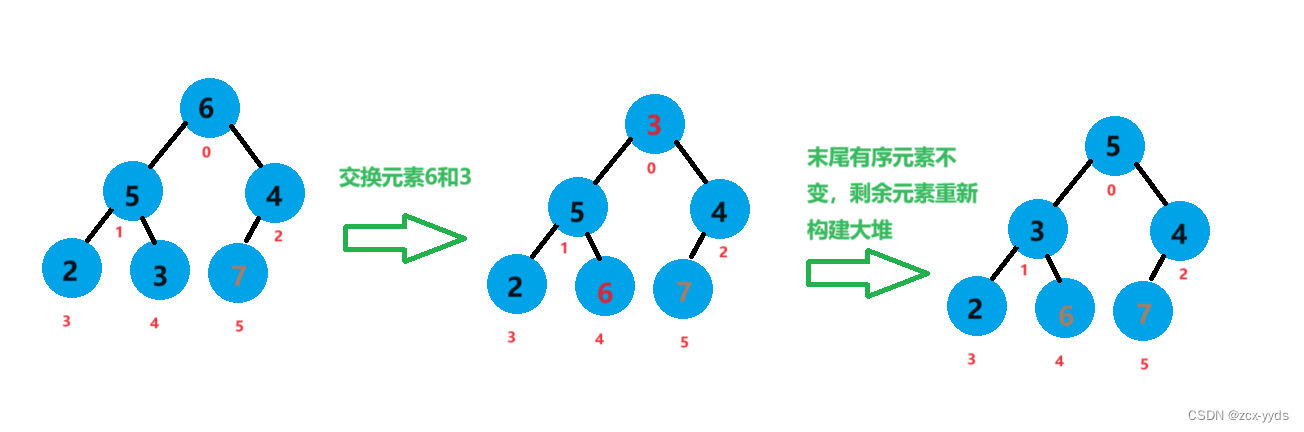
此时6、7已经有序,将元素5和元素2进行交换,对除5、6、7外剩下元素进行向下调整重新构建大堆
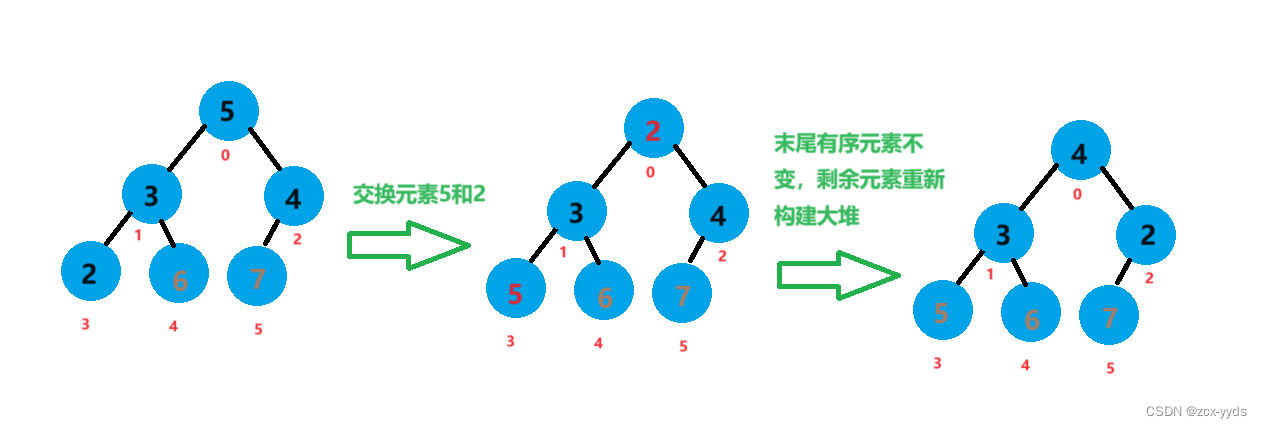
此时5、6、7已经有序,将元素4和元素2进行交换,此时数组已经有序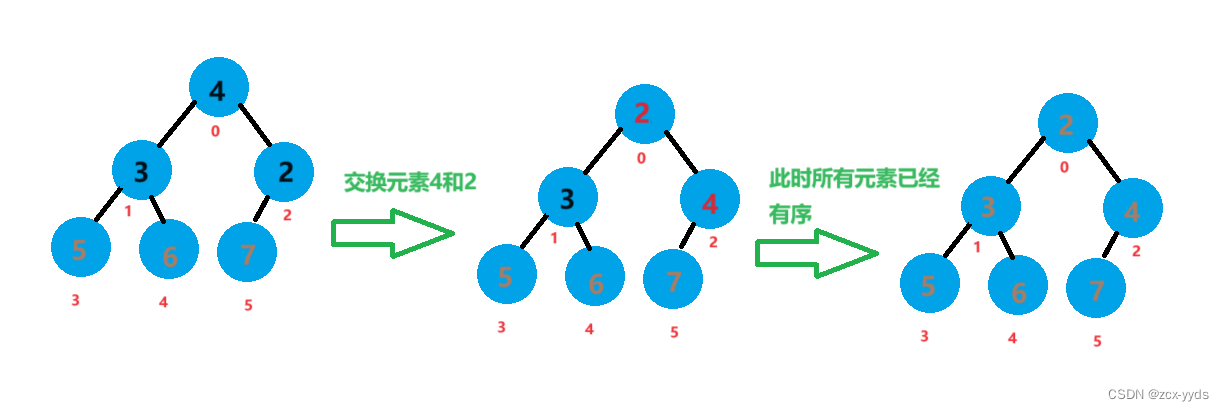
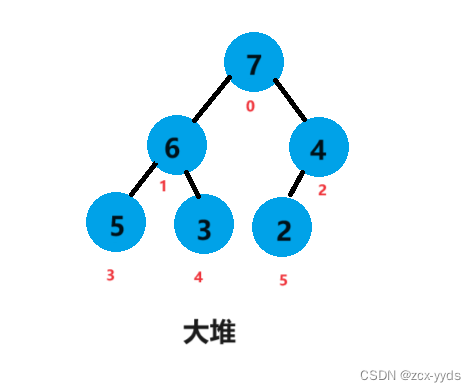
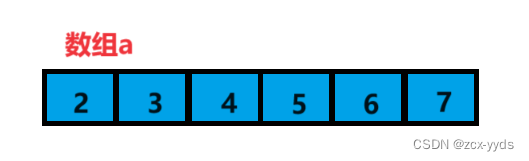
排序完数组a变为
用向上调整算法建堆的升序的堆排序代码如下:
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
typedef int HPDataType;
//交换结点的函数
void Swap(HPDataType* p1, HPDataType* p2)
{HPDataType tmp = *p1;*p1 = *p2;*p2 = tmp;
}
//向上调整算法(大堆)
void AdjustUp(HPDataType* a, int child)
{//找出双亲的下标int parent = (child - 1) / 2;while (child>0){//孩子结点比双亲大则交换if (a[child] > a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}//向下调整算法(大堆)
void AdjustDown(HPDataType* a, int n, int parent)
{//先默认左孩子是较大的int child = parent * 2 + 1;while (child < n){//找出左右孩子中较大的if (child + 1 < n && a[child + 1] > a[child]){child++;}//孩子节点更小则交换if (a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}
//排序
void HeapSort(int* a, int n)
{//向上调整建堆for (int i = 1; i < n; i++){AdjustUp(a, i);}//最尾端数据下标为总数减一int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);//对剩余元素进行向下调整AdjustDown(a, end, 0);end--;}
}建堆的:
空间复杂度:O(1)
平均时间复杂度:O(nlogn)
3、向下调整建堆排序
向下调整建堆排序与向上调整建堆排序不同的地方就在于建堆时用的算法不同,建好堆之后的后续操作都是相同的。
还是对上面那个案例,我们用向下调整算法建堆
向下调整算法前提条件:左右子树必须是堆,才能调整
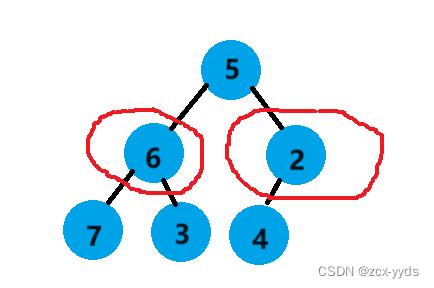
对于这个完全二叉树来说,它的倒数第一个非叶子节点2的左子树为4,没有右子树,可以用向下调整,再上一个节点6的左右子树是单个节点也可以看作堆,所有我们就可以从倒数第一个非叶子节点也就是最后一个节点的父亲开始向下调整:
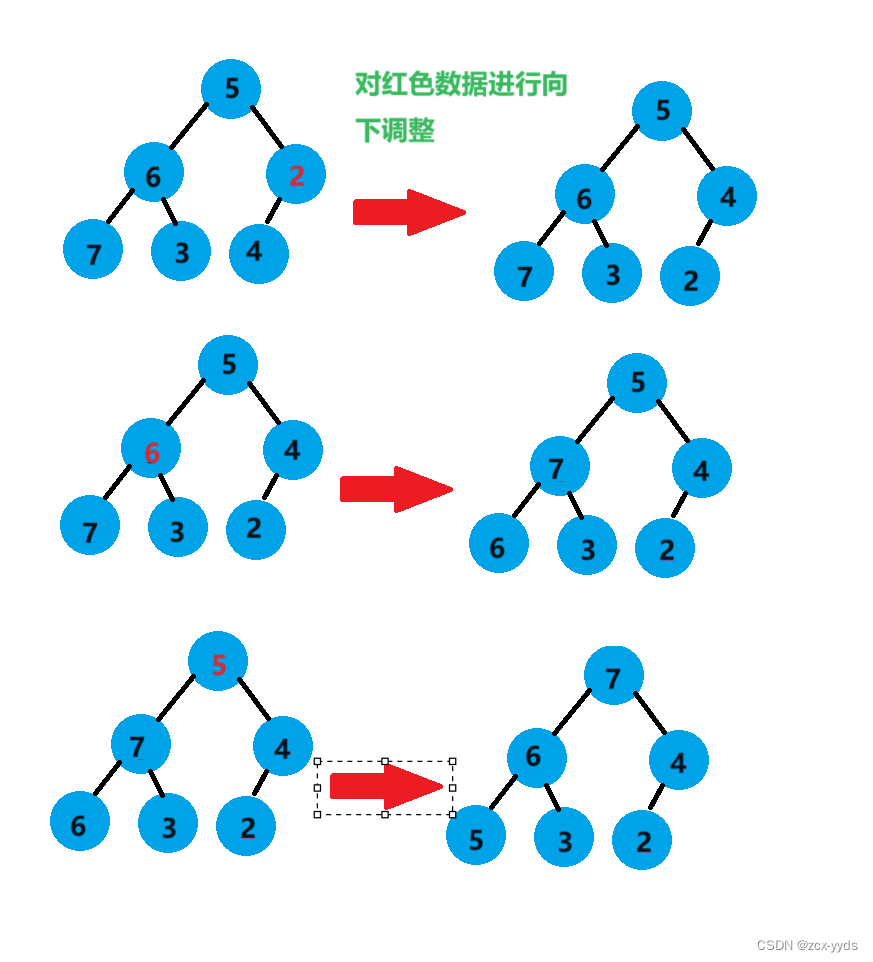
利用向下调整建好堆之后的后续操作与向上调整建好堆之后的操作一样,这里就不再演示
用向下调整算法建堆的升序的堆排序代码更改如下:
void HeapSort(int* a, int n)
{向上调整建堆//for (int i = 1; i < n; i++)//{// AdjustUp(a, i);//}// //向下调整建堆for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}//最尾端数据下标为总数减一int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);//对剩余元素进行向下调整AdjustDown(a, end, 0);end--;}
}
利用向下调整建堆的堆排序时间复杂度为:O(n),比利用向上调整建堆更优
七、归并排序
如需更详细步骤可见:归并排序
1、定义
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。

2、思想及图解
归并排序算法有两个基本的操作,一个是分解,另一个是合并。分解是把原数组划分成两个子数组的过程,合并可以将两个有序数组合并成一个更大的有序数组。
将待排序的线性表不断地切分成若干个子表,直到每个子表只包含一个元素,这时,可以认为只包含一个元素的子表是有序表。将子表两两合并,每合并一次,就会产生一个新的且更长的有序表,重复这一步骤,直到最后只剩下一个子表,这个子表就是排好序的线性表。
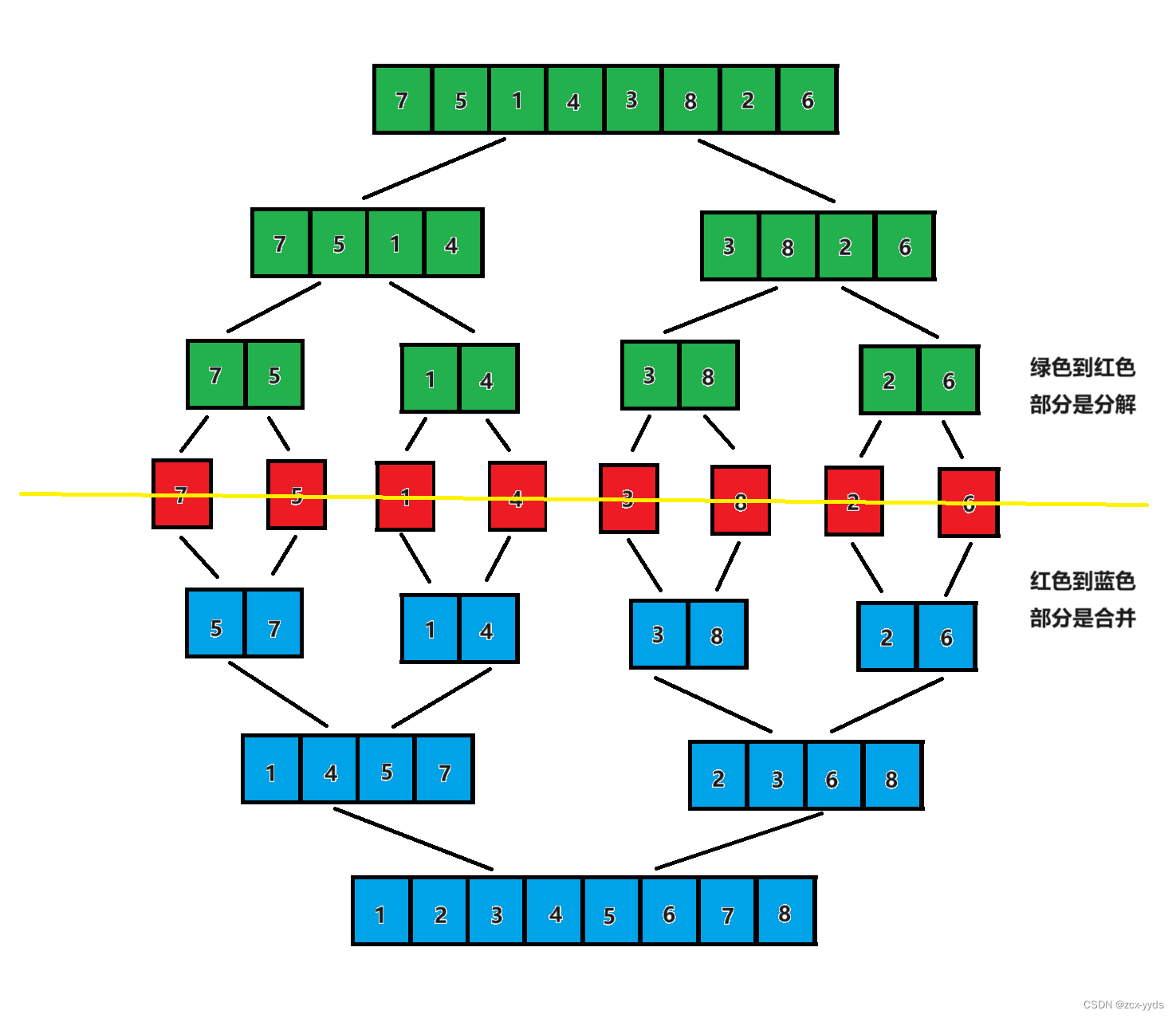
3、代码
1)递归实现
//归并排序
void _MergeSort(int* a, int* tmp, int begin, int end)
{//递归结束条件if (begin >= end){return;}int mid = (begin + end) / 2;_MergeSort(a, tmp, begin, mid);_MergeSort(a, tmp, mid+1, end);// 归并到tmp数据组,再拷贝回去int begin1 = begin;int end1 = mid;int begin2 = mid + 1;int end2 = end;int index = begin;//begin小于end说明还有两部分都还有数据while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[index++] = a[begin1++];}else{tmp[index++] = a[begin2++];}}//由于右边没有数据跳出的上一个循环,将左边剩下的数放入tmp数组对应位置while (begin1 <= end1){tmp[index++] = a[begin1++];}//由于左边没有数据跳出的上一个循环,将右边剩下的数放入tmp数组对应位置while (begin2 <= end2){tmp[index++] = a[begin2++];}// 拷贝回原数组memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}_MergeSort(a, tmp, 0, n - 1);free(tmp);
}
2)非递归实现
非递归实现时当gap的值不同时有许多数组的数据个数不适合当前gap,访问就会越界,比如9个值时当gap==1就会访问到下标为9的下标越界,所以要在代码中加入解决措施。当第一组右边界越界,第二组左边界也一定越界了,所以可分为第二组左边界越界和第二组右边界越界两种情况处理。
//非递归归并
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}int gap = 1;while (gap < n){for (int i = 0; i < n; i += 2 * gap){// 归并到tmp数据组,再拷贝回去int begin1 = i;int end1 = i + gap - 1;int begin2 = i + gap;int end2 = i + 2 * gap - 1;// 如果第二组不存在,这一组不用归并了if (begin2 >= n){break;}// 如果第二组的右边界越界,修正一下if (end2 >= n){end2 = n - 1;}int index = i;//begin小于end说明还有两部分都还有数据while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[index++] = a[begin1++];}else{tmp[index++] = a[begin2++];}}//由于右边没有数据跳出的上一个循环,将左边剩下的数放入tmp数组对应位置while (begin1 <= end1){tmp[index++] = a[begin1++];}//由于左边没有数据跳出的上一个循环,将右边剩下的数放入tmp数组对应位置while (begin2 <= end2){tmp[index++] = a[begin2++];}// 拷贝回原数组memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));}gap *= 2;}free(tmp);
}
时间复杂度:O(N*logN)
空间复杂度:O(N)
稳定性:稳定
八、计数排序
1、原理
计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。
操作步骤为:
- 统计相同元素出现次数
- 根据统计的结果将序列回收到原来的序列中
2、图解
首先找出数组a的最大值和最小值,计算出range
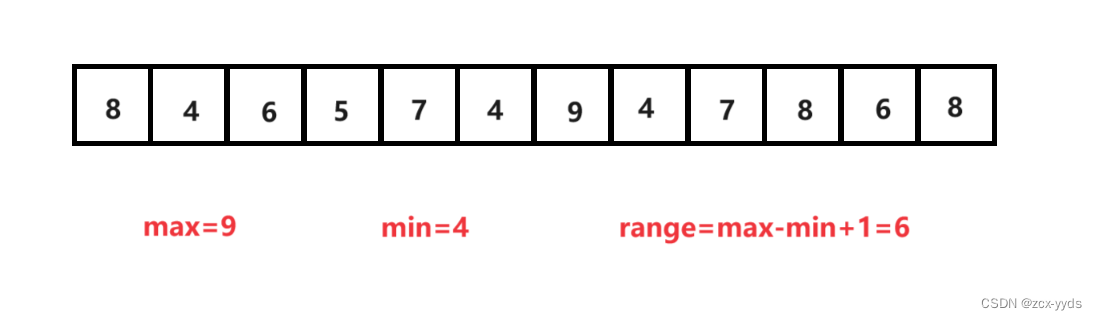
创建一个range大小的数组count,在下标为i的位置存储原数组中大小为i+min的数的个数
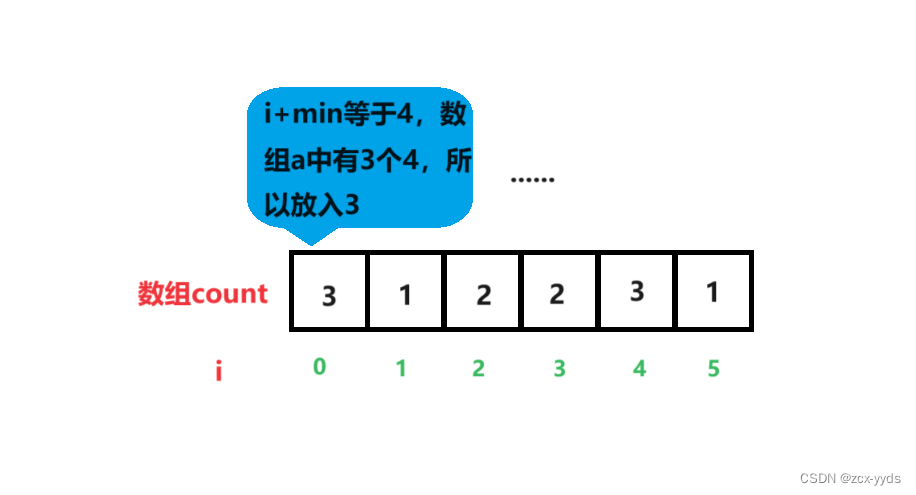
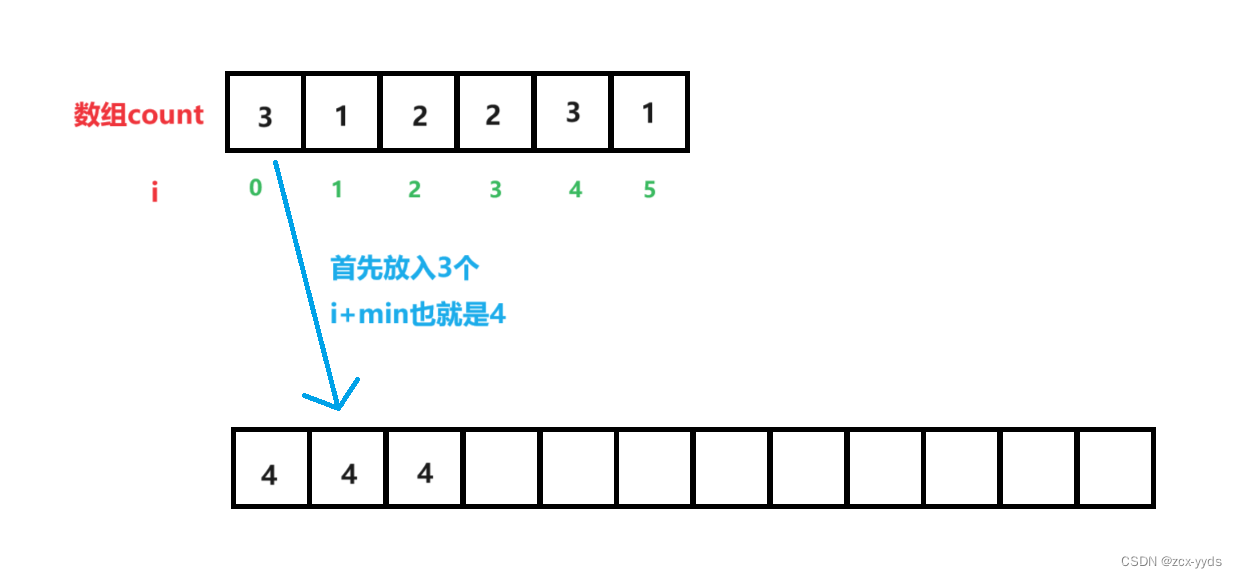
然后按顺序将数据放入原数组中
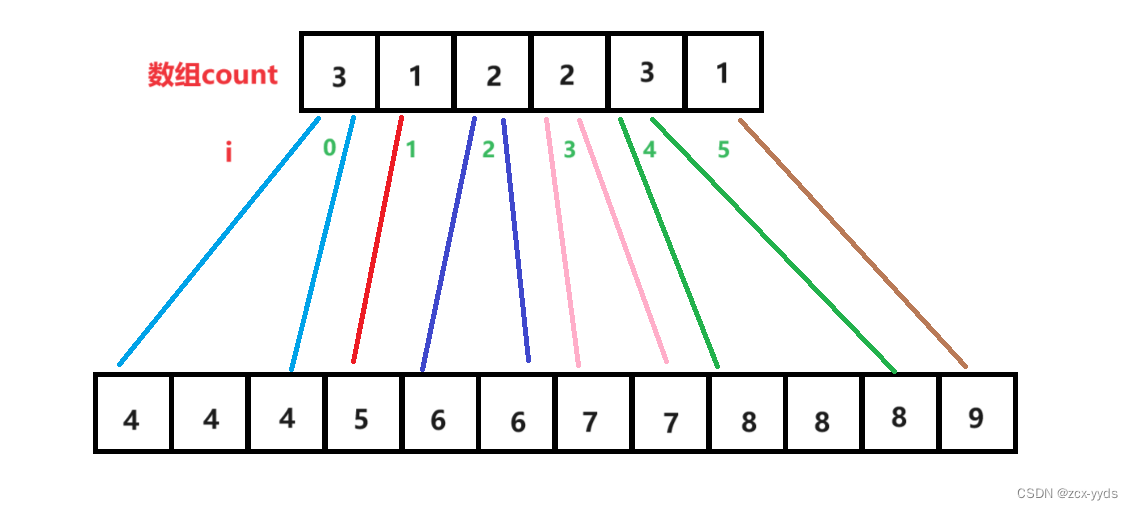
按照这样便可以将所有数据排好序
3、代码
//计数排序
void CountSort(int* a, int n)
{int min = a[0];int max = a[0];//找出最大值和最小值for (int i = 1; i < n; i++){if (a[i] < min){min = a[i];}if (a[i] > max){max = a[i];}}//确定建立数组的长度int range = max - min + 1;int* count = (int*)malloc(sizeof(int) * range);//printf("range:%d\n", range);if (count == NULL){perror("malloc fail");return;}//初始化数组countmemset(count, 0, sizeof(int) * range);//计数for (int i = 0; i < n; i++){count[a[i] - min]++;}//排序int j = 0;for (int i = 0; i < range; i++){while (count[i]--){a[j++] = min + i;}}
}
计数排序在数据范围集中时,效率很高,但是适用范围及场景有限,仅适用于整型排序。
时间复杂度:O(N+range)
空间复杂度:O(range)
稳定性:稳定
九、总结
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
时空复杂度及稳定性:
| 排序算法 | 时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|
| 直接插入排序 | O(N2) | O(1) | 稳定 |
| 希尔排序 | O(N1.3) | O(1) | 不稳定 |
| 选择排序 | O(N2) | O(1) | 不稳定 |
| 堆排序 | O(N*logN) | O(1) | 不稳定 |
| 冒泡排序 | O(N2) | O(1) | 稳定 |
| 快速排序 | O(N*logN) | O(logN) | 不稳定 |
| 归并排序 | O(N*logN) | O(N) | 稳定 |
| 计数排序 | O(MAX(N,范围)) | O(范围) | 稳定 |
相关文章:
【C语言】八大排序算法
文章目录 一、冒泡排序1、定义2、思想及图解3、代码 二、快速排序1、hoare版本2、挖坑法3、前后指针法4、非递归快排5、快速排序优化1)三数取中选key值2)小区间优化 三、直接插入排序1、定义2、代码 四、希尔排序1、定义2、图解3、代码 五、选择排序1、排…...

2023年中国智能电视柜产量、需求量、市场规模及行业价格走势[图]
电视柜是随着电视机的发展和普及而演变出的家具种类,其主要作用是承载电视机,又称视听柜,随着生活水平的提高,与电视机相配套的电器设备也成为电视柜的收纳对象。 随着智能家具的发展,智能电视机柜的造型和风格都是有了…...

docker容器使用初体验
我们写程序时,都会搭建相关的环境,比如写了一个web,使用了tomcat、nginx等,现在想要把程序部署到云服务器或者在其他电脑上运行,就需要重新部署一遍环境,尤其是项目开源后,上手成本大。 docker…...

React Hooks ——性能优化Hooks
什么是Hooks Hooks从语法上来说是一些函数。这些函数可以用于在函数组件中引入状态管理和生命周期方法。 React Hooks的优点 简洁 从语法上来说,写的代码少了上手非常简单 基于函数式编程理念,只需要掌握一些JavaScript基础知识与生命周期相关的知识不…...
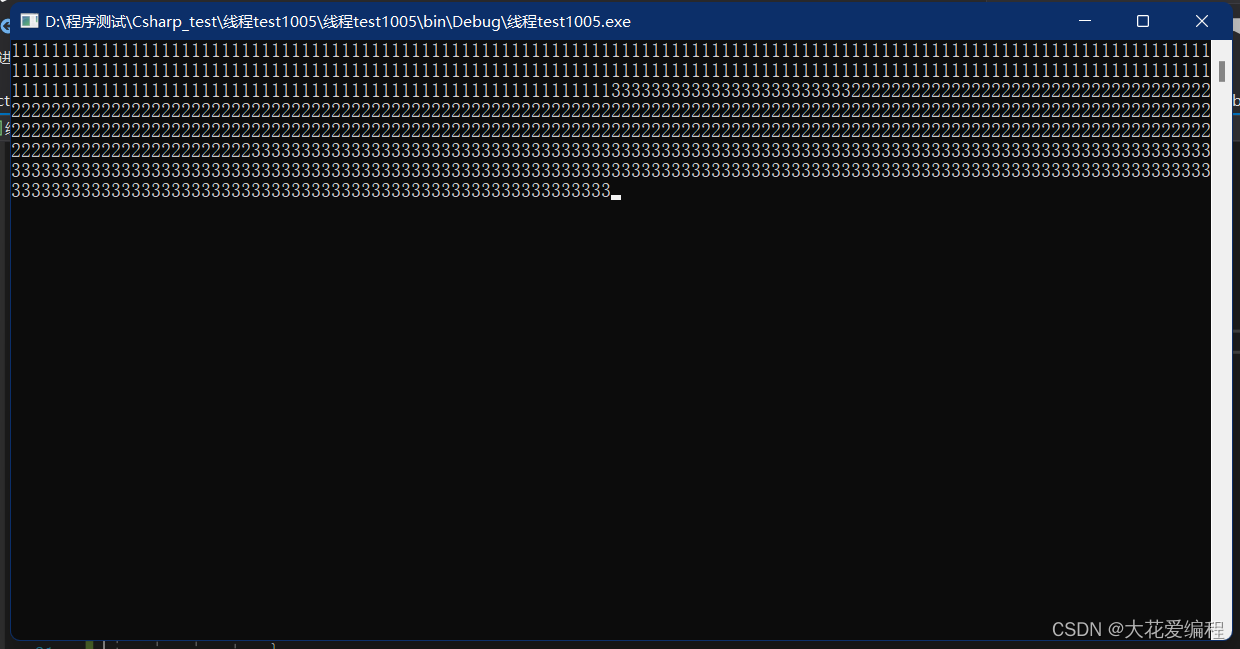
C#学习系列相关之多线程(一)----常用多线程方法总结
一、多线程的用途 在介绍多线程的方法之前首先应当知道什么是多线程, 在一个进程内部可以执行多个任务,而这每一个任务我们就可以看成是一个线程。是程序使用CPU的基本单位。进程是拥有资源的基本单位, 线程是CPU调度的基本单位。多线程的作用…...
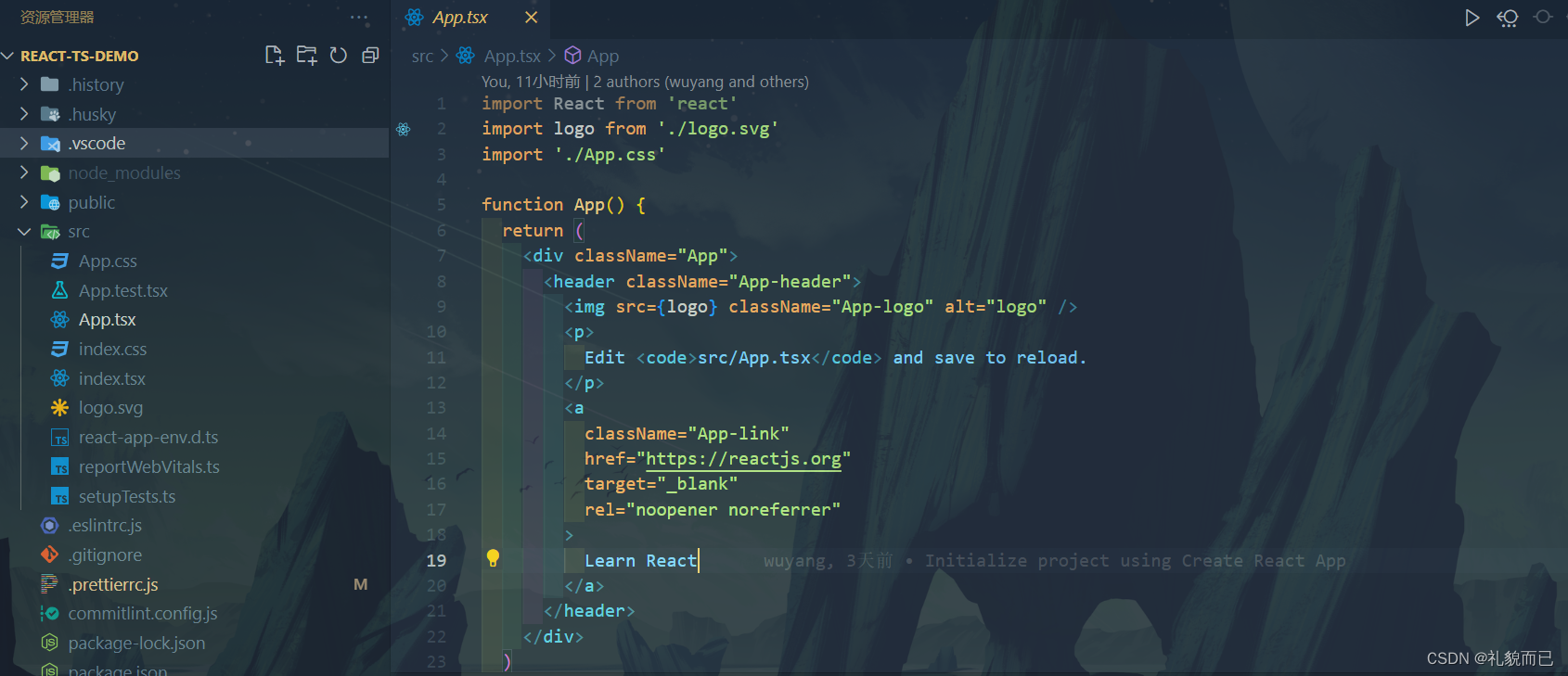
Vscode爆红Delete `␍`eslintprettier/prettier
一、先看报错 文件中爆红,提示 Delete ␍eslintprettier/prettier 二、解决方案 项目根目录下,.prettierrc.js 文件中: endOfLine: auto,三、重启VsCode 此时不在爆红,问题完美解决...

Mac安装Ecplise产品报错:dose not contain the JNI_CreateJavaVM symbol
1. 絮絮叨叨 工作中需要借助Ecplise Memory Analyzer (MAT)分析dump文件,直接下载、安装、运行MAT报错 询问同事后,同事说可以先安装Ecplise,再以插件的形式安装MAT下载、安装好Eclipse,点击运行仍然报错,且错误信息一…...

如何使用大语言模型来绘制图画
请创作一张科技感十足的图片,包含siri和iphone两个元素,请帮我挑选合适的style和background 好的,我会为你创作一张科技感十足的图片,包含siri和iphone两个元素。我会根据你的要求,选择一种适合的风格和背景。请稍等一…...

代码随想录算法训练营第23期day11 | 20. 有效的括号、1047. 删除字符串中的所有相邻重复项 、150. 逆波兰表达式求值
目录 一、(leetcode 20)有效的括号 二、(leetcode 1047)删除字符串中的所有相邻重复项 用栈存放 将字符串直接当成栈 三、(leetcode 150)逆波兰表达式求值 一、(leetcode 20)…...
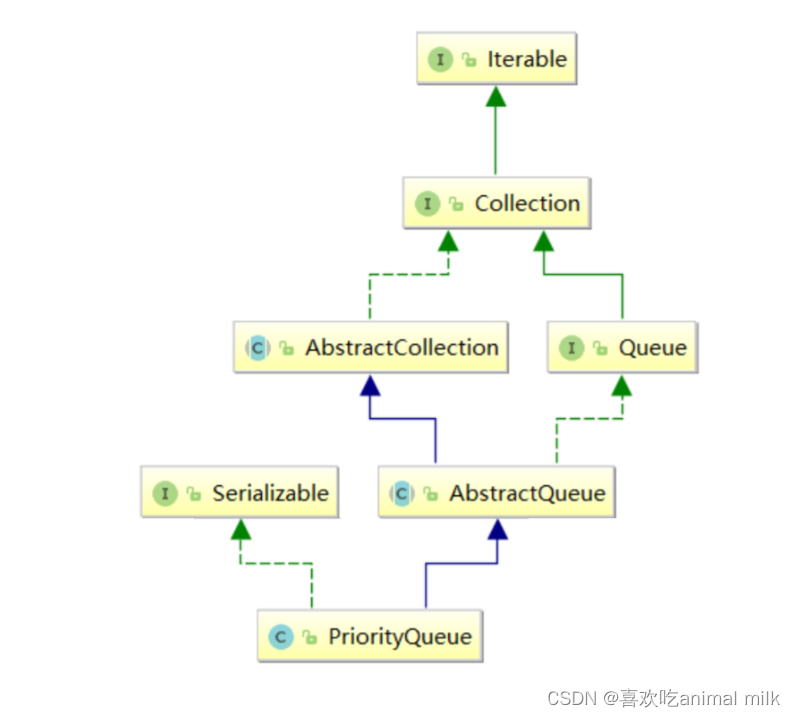
数据结构-优先级队列(堆)
文章目录 目录 文章目录 前言 一 . 堆 二 . 堆的创建(以大根堆为例) 堆的向下调整(重难点) 堆的创建 堆的删除 向上调整 堆的插入 三 . 优先级队列 总结 前言 大家好,今天给大家讲解一下堆这个数据结构和它的实现 - 优先级队列 一 . 堆 堆(Heap࿰…...
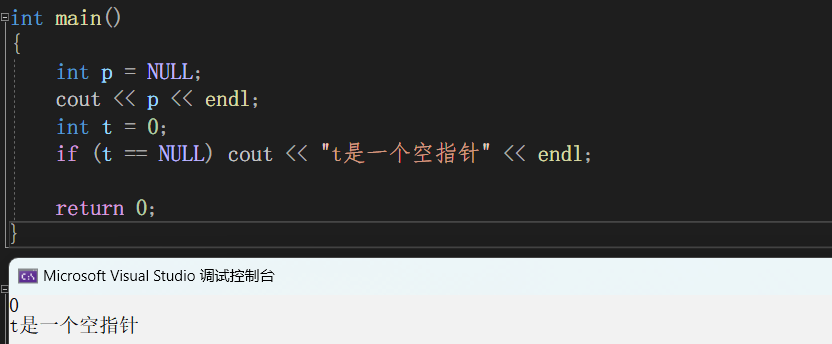
C++11新特性(语法糖,新容器)
距离C11版本发布已经过去那么多年了,为什么还称为新特性呢?因为笔者前面探讨的内容,除了auto,范围for这些常用的,基本上是用着C98的内容,虽说C11已经发布很多年,却是目前被使用最广泛的版本。因…...
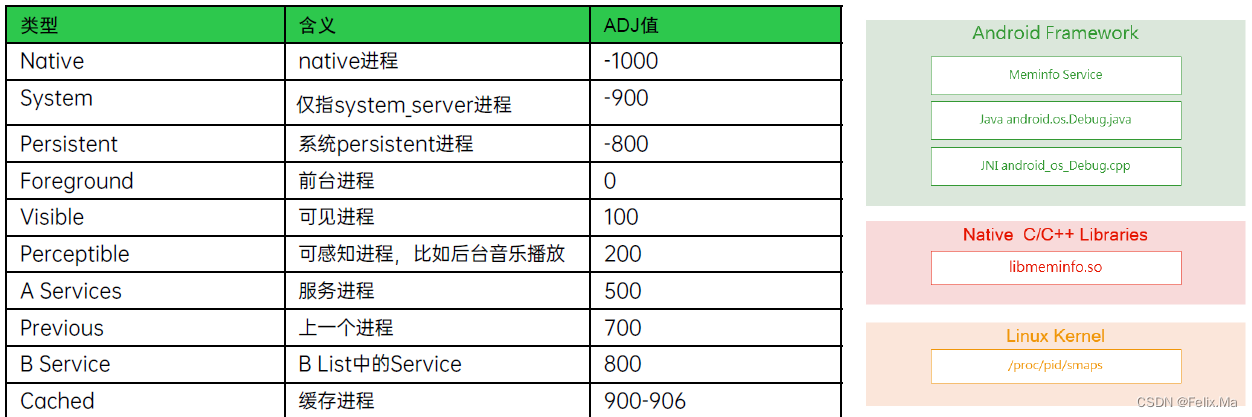
开机可用内存分析Tip
一、开机内存简介 开机内存指的是开机一段时间稳定后的可用内存。一般项目都会挑选同平台其他优秀竞品内存数据,这个也是衡量性能的一个重要标准。所以要进行开机内存检测,同时优化非法内存进程占用。 二、测试前期核查任务 开机内存测试前要进行测试机…...

【Python基础】4. 基本语句
文章目录 注释(Comment)解释伴随行文本编码问题 输入输出语句(Input & Output)输出语句普通输出格式化输出(3种)format 格式总结 输入语句 基本语句if 语句match 语句(Python3.10 新增&…...

兼顾友好与安全,隐私协议 Unijoin 助推新一轮 Web3 浪潮
区块链本身不仅崇尚去中心化,同时也崇尚公开透明,虽然这正在让 DAO 治理等变得更加公平,但它同时也是一把双刃剑,个人交易者尤其是一些巨鲸交易者的所以链上交易都被公之于众,这似乎并不是他们想要的结果。 所以从加密…...
TCP端口崩溃,msg:socket(): Too many open files
一、现象 linux系统中运行了一个TCP服务器,该服务器监听的TCP端口为10000。但是长时间运行时发现该端口会崩溃,TCP客户端连接该端口会失败: 可以看到进行三次握手时,TCP客户端向该TCP服务器的10000端口发送了SYN报文,…...
基于Laravel 5.6的运动健身类小程序前后端源码
基于Laravel 5.6的运动健身、健康类小程序前后端源码,一套比较基础的运动健康、健身类小程序源码。朋友自己无聊写的,比较基础,有需要的可以拿去修修改改升级开发一下。 使用宝塔安装,比较省事,PHP相关的扩展需要启用…...
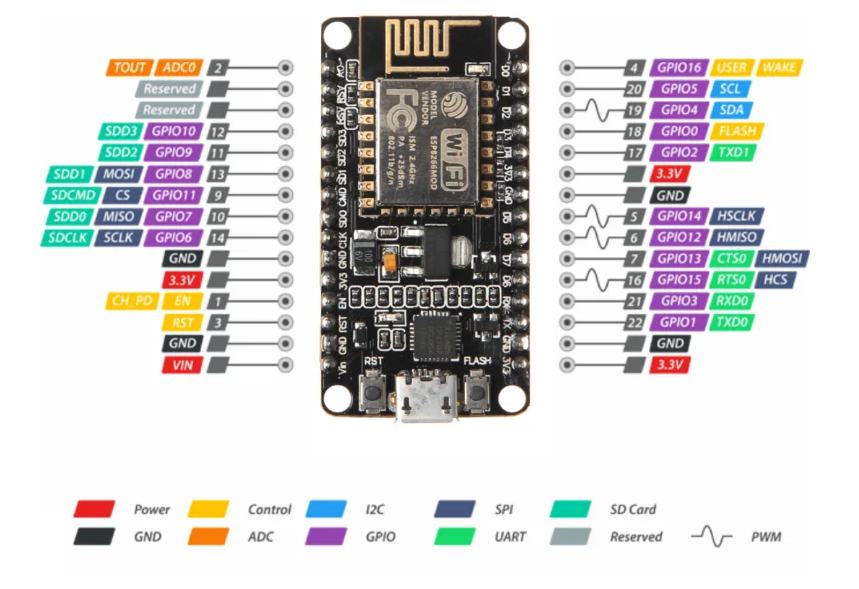
NodeMCU ESP8266硬件开发板的熟悉
文章目录 硬件开发环境的熟悉基础介绍什么是 ESP8266 NodeMCU?NodeMCU芯片ESP12-E 模组开发板 ESP8266 版本引脚图Power GND I2CGPIOADCUARTSPIPWMControl 总结 硬件开发环境的熟悉 基础介绍 什么是 ESP8266 NodeMCU? ESP8266是乐鑫开发的一款低成本 …...
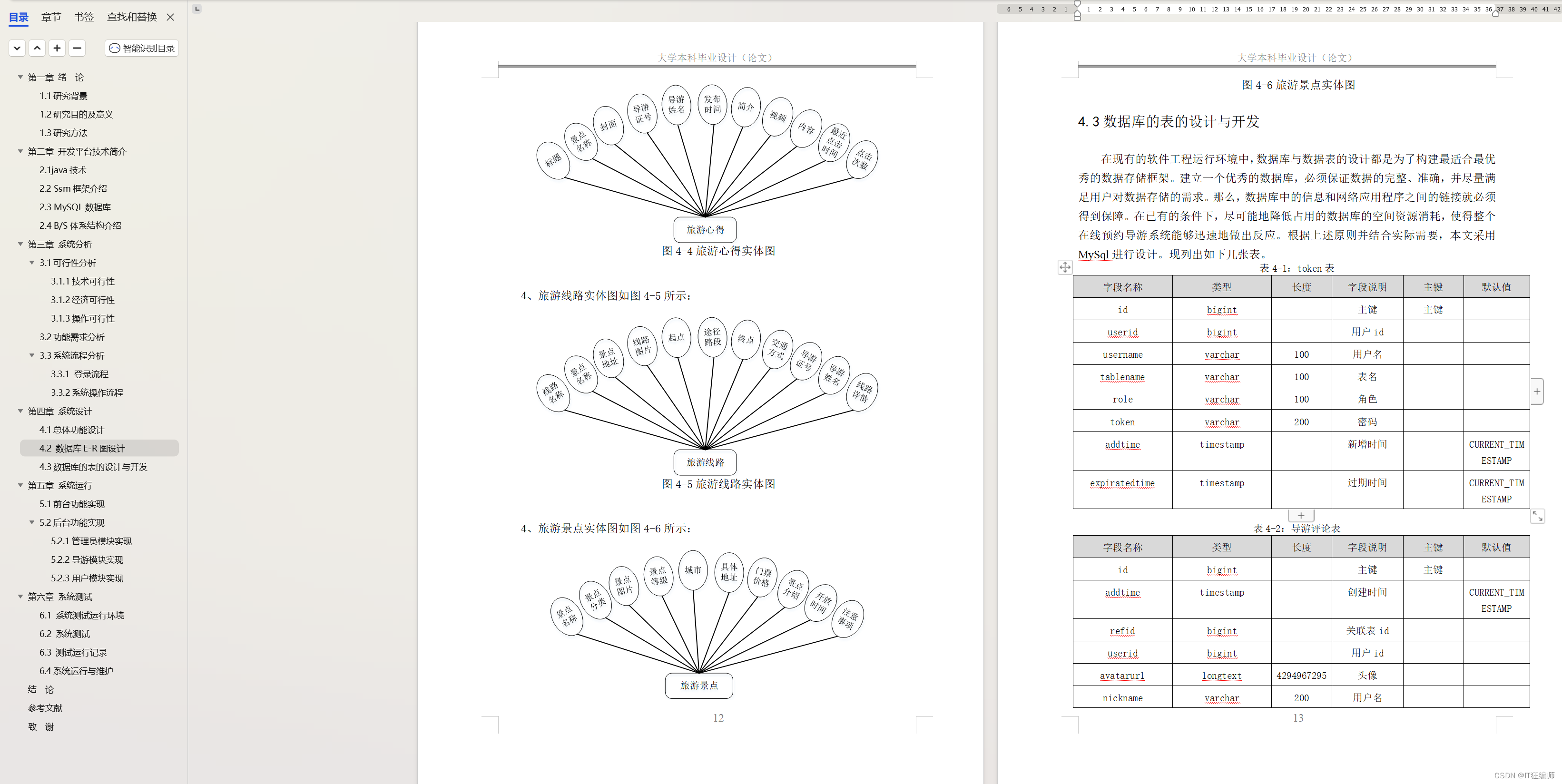
计算机毕业设计 基于SSM的在线预约导游系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...
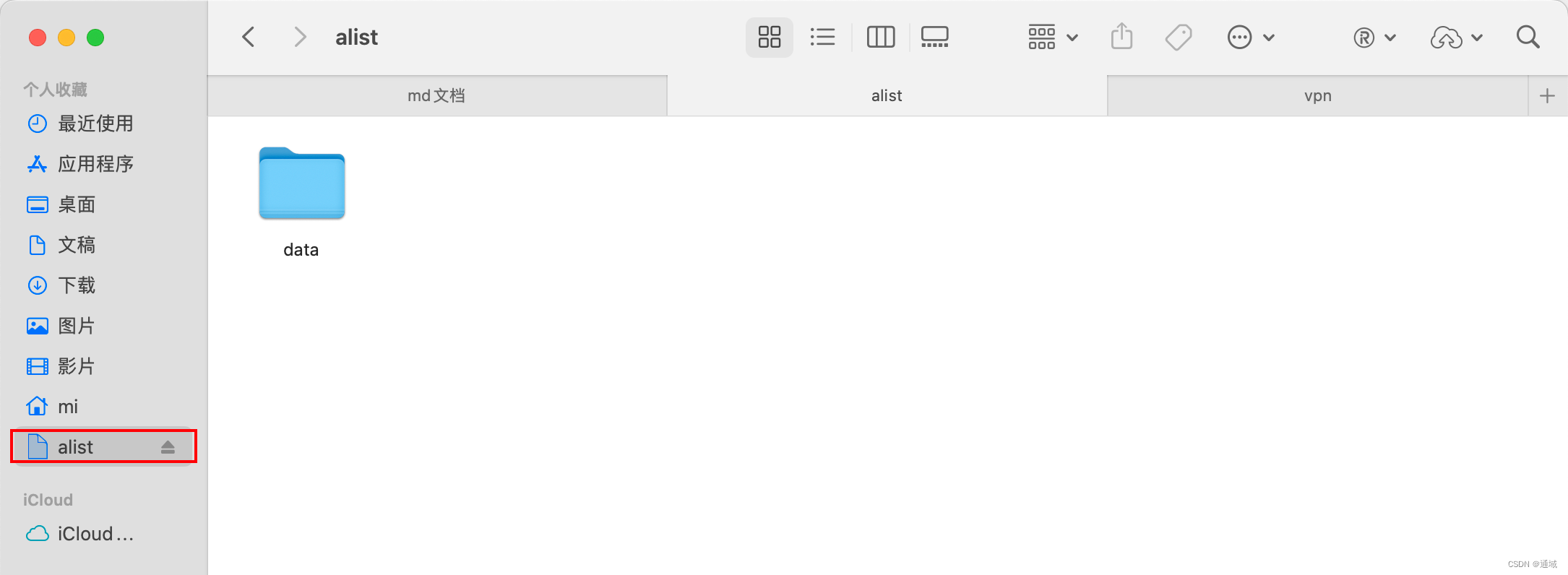
Mac 挂载 Alist网盘
挂载服务器的Alist 网盘到 Mac mac,使用的是 CloundMounter 这个软件进行挂载 http://ip:port/dav/ 需要在末尾加上 /dav/ 在一些服务器上,为了提供WebDAV服务,需要在URL地址的末尾添加"/dav/“。这是因为WebDAV协议规定了一些标准的URL路径&#x…...
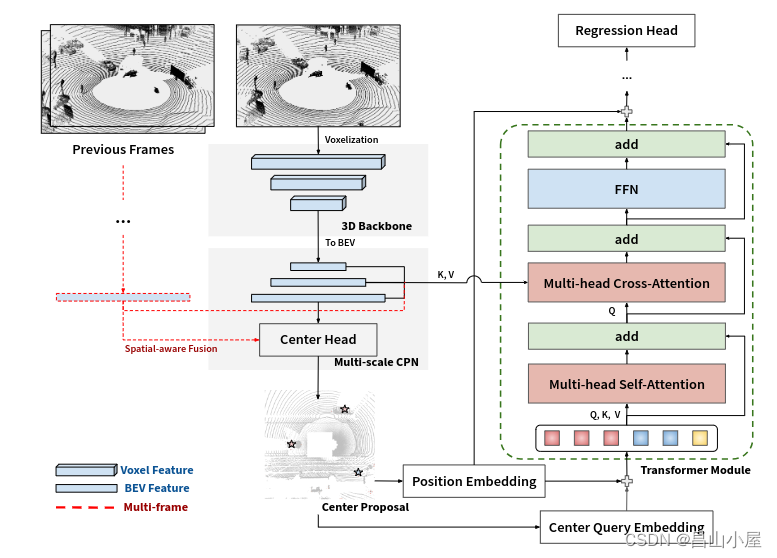
【多模态融合】TransFusion学习笔记(1)
工作上主要还是以纯lidar的算法开发,部署以及系统架构设计为主。对于多模态融合(这里主要是只指Lidar和Camer的融合)这方面研究甚少。最近借助和朋友们讨论论文的契机接触了一下这方面的知识,起步是晚了一点,但好歹是开了个头。下面就借助TransFusion论文…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现企业微信功能
1. 开发环境准备 安装DevEco Studio 3.1: 从华为开发者官网下载最新版DevEco Studio安装HarmonyOS 5.0 SDK 项目配置: // module.json5 {"module": {"requestPermissions": [{"name": "ohos.permis…...
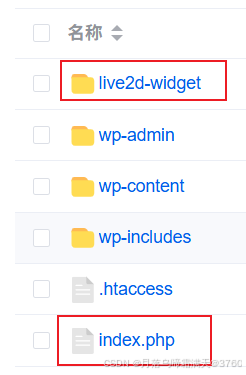
给网站添加live2d看板娘
给网站添加live2d看板娘 参考文献: stevenjoezhang/live2d-widget: 把萌萌哒的看板娘抱回家 (ノ≧∇≦)ノ | Live2D widget for web platformEikanya/Live2d-model: Live2d model collectionzenghongtu/live2d-model-assets 前言 网站环境如下,文章也主…...
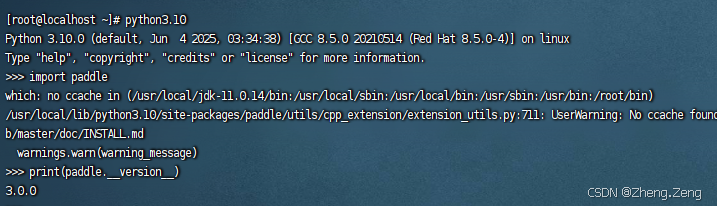
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10+pip3.10)
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10pip3.10) 一:前言二:安装编译依赖二:安装Python3.10三:安装PIP3.10四:安装Paddlepaddle基础框架4.1…...