小白入门pytorch(二)----神经网络
本文为🔗[小白入门Pytorch]学习记录博客
文章目录
- 前言
- 一、神经网络的组成部分
- 1.神经元
- 2.神经网络层
- 3.损失函数
- 4.优化器
- 二、Pytorch构建神经网络中的网络层
- 全连接层
- 2.卷积层
- 3.池化层
- 4.循环神经网络
- 5.转置卷积层
- 6.归一化层
- 7.激活函数层
- 三、数据加载与预处理
- 1.数据加载
- 2.数据预处理
- 四、模型训练与验证
- 1.模型训练
- 2.模型验证
- 总结
前言
本文主要记录深度学习中的神经网络学习内容,包括理论和代码
一、神经网络的组成部分
在小白入门pytorch(一)中学习了pytorch的基本操作,本篇文章主要是记录使用Pytorch搭建神经网络的基础代码。文章记录的
顺序是按照🔗[小白入门Pytorch]教案二进行的。
- 神经网络的组成部分
- 神经元
- 神经网络层
1.神经元
了解一下神经网络的历史:神经生物学家Warren MeCulloch和数学家Walter Pitts于1943年提出了一种基于早期的神经元理论学说的人工神经网络模型,称为MP模型(McCulloch-Pitts模型)。该模型是一种具有生物神经元特征的人工神经网络模型,被认为是神经网络研究的开端。
MP模型的基本思想是将神经元视为一个二进制变量,二进制变量很好懂,要么是1,要么是0,1是神经元兴奋和0是神经元抑制,我们将多个神经元进行连接,进行一系列的矩阵运算,就可以实现复杂的计算功能即是神经网络。
神经元通常由以下几个部分组成:
- 输入(Inputs):神经元接收来自其他神经元或外部环境的输入数据。
- 权重(Weights):每个输入都与一个权重相关联,用于调整输入的重要性。
- 激活函数:激活函数将加权输入映射到输出。常用的激活函数包括Sigmoid、ReLU和Tanh(这几个激活函数都是非线性的)等。
- 偏置(Bias):偏置是一个可学习的参数,用于调整神经元输出的阈值。
import torchclass Neuron(torch.nn.Module):def __init__(self, input_size):# 继承PyTorch中nn.Module类并实现自定义神经元模型Neuronsuper(Neuron, self).__init__()# 定义权重参数,大小为input_sizeself.weights = torch.nn.Parameter(torch.randn(input_size))# 定义偏置参数,大小为1self.bias = torch.nn.Parameter(torch.randn(1))# 实现前向传播函数def forward(self, inputs):# 计算加权和,点乘输入和权重,然后加上偏置weighted_sum = torch.sum(inputs * self.weights) + self.bias# 应用sigmoid函数进行非线性变换,计算输出结果output = torch.sigmoid(weighted_sum)return output# 创建一个Neuron对象,输入大小为3
neuron = Neuron(3)# 输入层,大小为3的张量
inputs = torch.tensor([0.5, -0.3, 0.1])# 计算神经元的输出
output = neuron(inputs)# 打印输出结果
print(output)输出结果:
tensor([0.3399], grad_fn=<SigmoidBackward0>)
上面这部分代码是定义了一个自定义的神经元模型 Neuron,并计算了神经元的输出,使用Pytorch搭建。
首先,先定义一个定义了一个名为 Neuron 的类,它继承自 torch.nn.Module。该类表示一个神经元模型,并具有两个属性:权重参数 weights 和偏置参数 bias。这些参数在初始化时根据输入大小进行随机初始化。
然后,在 forward 方法中,计算加权和(权重与输入的点乘之和),并添加了偏置。
接下来,应用 sigmoid 激活函数将加权和转化为非线性输出。
最后,输出结果。
2.神经网络层
神经网络是一种有多个神经元以一定的方式联结形成的网络结构,是一种仿照生物神经网络结构和功能的人工智能技术。
说白了,神经网络中的计算过程就是矩阵运算,当然我这里指的是前线传播的过程。反向传播就是求导。
神经网络的组成: 输入层、多个隐藏层、输出层
以下是一些常见的神经网络层类型:
- 全连接层(Fully Connected Layer):每个神经元都与前一层的所有神经元相连接。
- 卷积层(Convolutional Layer):应用卷积操作来提取输入数据中的空间特征。
- 池化层(Pooling Layer):通过减少特征图的大小来降低计算量,并保留重要的特征。
- 循环层(Recurrent Layer):通过在神经网络中引入时间维度来处理序列数据。
下面是一个包含两个全连接层的神经网络示例代码:
import torch# 定义神经网络类,继承torch.nn.Module
class NeuralNetwork(torch.nn.Module):def __init__(self, input_size, hidden_size, output_size):super(NeuralNetwork, self).__init__()# 定义第一个全连接层,输入大小为input_size,输出大小为hidden_sizeself.fc1 = torch.nn.Linear(input_size, hidden_size)# 定义第二个全连接层,输入大小hidden_size,输出大小为output_sizeself.fc2 = torch.nn.Linear(hidden_size, output_size)def forward(self, inputs):# 计算第一个全连接层的输出结果,并使用ReLU激活函数处理hidden = torch.relu(self.fc1(inputs))# 计算第二个全连接层的输出结果,并使用Sigmoid激活函数处理output = torch.sigmoid(self.fc2(hidden))return output# 创建神经网络实例,输入大小为2,隐藏层大小为3,输出大小为1
net = NeuralNetwork(2, 3, 1)# 准备输入数据,包含2个数值
inputs = torch.tensor([0.5, -0.3])# 对于输入数据,计算神经网络的输出结果
output = net(inputs)# 打印输出结果
print(output)输出结果:
tensor([0.5437], grad_fn=<SigmoidBackward0>)
- 首先,定义了一个名为 NeuralNetwork 的类,它继承自
torch.nn.Module。该类表示一个具有两个全连接层的神经网络,其中输入大小为 input_size,隐藏层大小为 hidden_size,输出大小为 output_size。 - 在初始化方法中,创建了两个全连接层,并分别将它们存储在类属性 fc1 和 fc2 中。第一个全连接层将输入数据投影到隐藏层空间,其权重矩阵大小为 (hidden_size, input_size),偏置向量大小为 (hidden_size)。 第二个全连接层将隐藏层空间投影到输出空间,其权重矩阵大小为 (output_size,hidden_size),偏置向量大小为 (output_size)。
- 在前向传播方法 forward 中,首先对输入数据执行第一个全连接层的计算,并使用 ReLU激活函数处理其输出结果。然后,我们对第二个全连接层的输出结果进行计算,并使用 Sigmoid激活函数处理其输出结果。最后,我们返回其输出结果。 创建了一个实例 net,其输入大小为2,隐藏层大小为3,输出大小为1。这意味着当我们将大小为2的输入数据输入模型时,模型将计算一个由1个数值组成的输出。准备了一个大小为2的输入向量inputs,并将其传递给网络模型,得到网络的输出结果。具体而言,我们调用 net(inputs)执行前向传播计算,并将其输出结果存储在变量 output 中。
3.损失函数
神经网络的目标是最小化预测输出与真实标签之间的差异。损失函数衡量了这种差异,并提供一个可优化的目标。常见的损失函数包括**均方误差(Mean Squared Error)、交叉熵损失(Cross-Entropy Loss)、对数损失(Log Loss)**等。
- 均方误差(Mean Squared Error,MSE):计算预测值与目标值之间的平方差的平均值。torch.nn.MSELoss()
- 交叉熵损失(Cross-Entropy Loss):在分类问题中,计算预测概率分布与真实标签之间的交叉熵。 torch.nn.CrossEntropyLoss()
- 对数损失(Log Loss)损失函数:对数损失也是一个常见的分类损失函数,它通常用于处理二分类问题。它基于交叉熵损失函数,但对模型输出的概率应用了对数函数。torch.nn.BCELoss()
以下是一个使用均方误差作为损失函数的示例:
import torch# 创建预测值张量
predictions = torch.tensor([0.99999, 0.2222, 0.11111])# 创建标签值张量
labels = torch.tensor([1.0, 1.0, 0.0])# 实例化均方根误差(MSE)损失函数对象
loss_function = torch.nn.MSELoss()# 使用损失函数计算预测值和标签值之间的均方根误差
loss = loss_function(predictions, labels)# 打印均方根误差
print(loss)输出结果:
tensor(0.2058)
4.优化器
- 优化器用于更新神经网络参数以最小化损失函数。它使用梯度下降算法来调整参数的值。常用的优化器包括随机梯度下降(Stochastic Gradient Descent, SGD)、Adam等
import torch# 创建一个神经网络和损失函数
net = NeuralNetwork(2, 3, 1) # 创建一个具有2个输入特征、3个隐藏层单元和1个输出的神经网络模型
loss_function = torch.nn.MSELoss() # 均方根误差(MSE)损失函数# 创建一个优化器
optimizer = torch.optim.Adam(net.parameters(), lr=0.01) # Adam优化器,用于参数更新,学习率为0.01# 输入数据和真实标签
inputs = torch.tensor([0.1, -0.3]) # 输入数据张量,包含两个特征
labels = torch.tensor([1.0]) # 真实标签张量# 前向传播
output = net(inputs) # 将输入数据传递给神经网络模型进行前向传播得到预测值
loss = loss_function(output, labels) # 使用损失函数计算预测值和真实标签之间的均方根误差# 反向传播和参数更新
optimizer.zero_grad() # 清零之前的梯度,避免梯度累积
loss.backward() # 执行反向传播,计算梯度
optimizer.step() # 根据梯度更新网络参数print(loss) # 打印损失值输出结果:
tensor(0.2413, grad_fn=<MseLossBackward0>)
二、Pytorch构建神经网络中的网络层
- 在pytorch中,神经网络层(layers)是神经网络的基本组成部分,用于对输入数据进行转换和提取特征。Pytorch提供了丰富的层类型和功能,使得构建和训练深度学习模型变得更加便捷和灵活。
神经网络中包括哪些层呢?
1.全连接层(Fully connected Layer)
2.卷积层(Convolutional Layer)
3.池化层(Pooling Layer)
4.循环神经网络层(Recurrent Neural Network Layer)
5.转置卷积层(Transpose Convolutional Layer)
6.归一化层(Normalization Layer)
7.激活函数层(Activation Function Layer)
8.损失函数层(Loss Function Layer)
9.优化器层(optimizer Layer)
全连接层
- 全连接层,也被称为线性层或密集层,是最简单的神经网络之一。它将输入的每个元素与权重相乘,并加上偏置项,然后通过激活函数进行非线性变换。全连接层的输出形状由其输入形状和输出维度确定。
import torch
import torch.nn as nn# 导入PyTorch库# 定义输入和输出维度
input_size = 784 # 输入特征的数量784
output_size = 10 # 输出特征的数量,表示10个不同的类别# 创建全连接层
fc_layer = nn.Linear(input_size, output_size) # 创建一个全连接层对象,输入特征数量为784,输出特征数量为10# 打印全连接层的权重和偏置项
print("权重:", fc_layer.weight) # 打印全连接层的权重,形状为(10, 784)
print("偏置项:", fc_layer.bias) # 打印全连接层的偏置项,形状为(10,)
权重: Parameter containing:
tensor([[ 2.5574e-02, -5.3259e-03, -4.4039e-03, ..., 4.0028e-05,8.8669e-03, -1.5488e-02],[ 9.5699e-04, 1.1061e-03, 1.3532e-02, ..., 2.4001e-02,3.0188e-03, -1.9964e-02],[-2.4929e-02, -6.6258e-05, -3.1090e-02, ..., 2.0909e-02,2.9723e-02, -1.2300e-02],...,[-3.3147e-02, -2.1986e-02, 1.3504e-02, ..., 1.5667e-02,2.0060e-02, 1.2932e-02],[ 5.0174e-03, 2.7909e-02, -3.5111e-02, ..., 2.7326e-02,3.1136e-02, -2.1508e-02],[ 3.4995e-02, -2.9416e-02, 8.9518e-03, ..., 2.4333e-02,2.5510e-02, 3.4048e-02]], requires_grad=True)
偏置项: Parameter containing:
tensor([ 0.0235, -0.0071, -0.0277, 0.0201, 0.0285, -0.0066, 0.0244, -0.0015,-0.0274, -0.0254], requires_grad=True)
2.卷积层
- 卷积层是卷积神经网络中的核心层之一,用于从输入数据中提取空间特征。卷积层通过滑动窗口(卷积核)在输入上进行局部感知,并输出对应的特征图。Pytorch中的卷积层包括二维卷积层和三维卷积层,分别用于处理二维数据和三维数据。
import torch
import torch.nn as nn# 定义输入通道数、输出通道数和卷积核大小
in_channels = 3 # 输入图像的通道数,比如RGB图像的通道数为3
out_channels = 10 # 输出特征图的通道数,决定了卷积层的深度
kernel_size = 3 # 卷积核的大小,可以是一个整数或者一个元组(高度,宽度)# 创建二维卷积层
conv_layer = nn.Conv2d(in_channels, out_channels, kernel_size) # 创建一个二维卷积层对象,指定输入通道数、输出通道数和卷积核大小# 打印二维卷积层的权重和偏置项
print("权重:", conv_layer.weight) # 打印卷积层的权重,形状为(10, 3, 3, 3),表示10个输出通道,每个通道对应一个3x3的卷积核,输入通道数为3
print("偏置项:", conv_layer.bias) # 打印卷积层的偏置项,形状为(10,),表示10个输出通道各自的偏置项
权重: Parameter containing:
tensor([[[[-0.1345, -0.1756, -0.1378],[-0.1873, 0.0453, 0.1870],[-0.0587, -0.1824, 0.0206]],[[-0.0236, 0.0837, -0.1119],[ 0.1802, -0.0412, 0.0246],[ 0.0555, -0.1600, -0.1051]],[[ 0.0305, -0.1235, 0.1504],[ 0.1417, -0.1083, -0.1260],[ 0.1019, 0.0467, -0.0930]]],[[[ 0.0049, 0.1599, -0.0155],[ 0.1395, 0.1167, 0.0457],[ 0.1842, 0.1533, 0.1551]],[[ 0.0357, -0.0851, 0.0223],[-0.1629, 0.1369, 0.0167],[ 0.1904, 0.0222, -0.1388]],[[-0.0846, -0.1352, -0.0039],[ 0.0290, 0.1842, -0.1837],[ 0.0431, 0.1595, -0.0067]]],[[[-0.1126, -0.0355, -0.1463],[ 0.0333, 0.0095, 0.0695],[-0.0106, -0.0312, -0.1256]],[[ 0.1589, 0.0826, 0.0012],[-0.1898, 0.0701, 0.1293],[ 0.1104, 0.1357, -0.0181]],[[-0.0141, 0.0343, 0.1184],[ 0.0223, 0.1064, 0.1161],[-0.1302, -0.0461, 0.1534]]],[[[-0.1347, 0.0752, -0.0799],[ 0.1490, 0.1549, 0.1169],[ 0.0238, -0.0565, 0.1537]],[[-0.0109, 0.1576, -0.1237],[-0.1440, -0.0062, 0.1227],[ 0.1083, 0.0711, -0.1654]],[[ 0.1691, -0.0773, -0.1273],[ 0.0252, 0.0923, 0.1173],[ 0.1610, 0.1237, 0.0340]]],[[[ 0.0421, -0.0296, -0.0942],[ 0.1319, -0.0052, 0.1092],[ 0.0359, 0.1117, -0.1803]],[[ 0.1128, 0.0074, 0.1556],[-0.1156, -0.1290, -0.0532],[-0.1897, -0.0241, 0.0173]],[[ 0.1492, 0.0639, 0.0156],[-0.1848, 0.0436, 0.1843],[ 0.1261, -0.1529, -0.0433]]],[[[-0.0377, -0.1315, 0.1441],[ 0.1290, 0.1604, 0.1032],[-0.1481, -0.0640, -0.1081]],[[-0.0525, 0.1381, -0.0980],[-0.0356, -0.1787, 0.0579],[ 0.0794, -0.0317, 0.1197]],[[ 0.0696, -0.1164, -0.1332],[-0.0522, 0.1866, -0.1177],[ 0.0478, -0.1263, -0.0446]]],[[[-0.0707, 0.0787, 0.0932],[-0.0645, -0.0981, 0.1409],[ 0.0830, -0.0724, 0.0160]],[[-0.0663, -0.1531, 0.0385],[-0.0376, -0.0028, 0.0165],[ 0.1408, 0.0061, -0.0085]],[[ 0.1485, -0.0885, -0.0300],[ 0.0784, 0.1103, -0.1027],[-0.1513, -0.1135, 0.1773]]],[[[ 0.1529, 0.0545, 0.0845],[-0.0492, 0.0263, 0.0706],[ 0.1417, -0.0234, 0.1385]],[[-0.1917, -0.1262, -0.1102],[ 0.0726, 0.1231, 0.0764],[-0.0670, 0.0726, 0.0026]],[[ 0.0701, -0.1172, -0.0528],[-0.0076, -0.0333, -0.0411],[-0.0275, -0.0982, 0.0640]]],[[[-0.1637, 0.1234, 0.1289],[-0.0831, -0.0061, 0.0587],[-0.0125, -0.1588, -0.0585]],[[ 0.1838, 0.1203, -0.1888],[-0.1113, -0.0859, 0.1053],[ 0.0857, -0.1597, 0.0186]],[[ 0.1576, -0.1528, 0.1484],[ 0.0019, 0.0216, -0.0182],[-0.1688, -0.1134, 0.1220]]],[[[ 0.1687, -0.0447, -0.0339],[-0.1022, -0.1690, 0.0198],[-0.1686, -0.1009, -0.0762]],[[ 0.0394, 0.0816, 0.0880],[ 0.0414, -0.0767, 0.1095],[ 0.1279, -0.0704, -0.0042]],[[-0.1413, 0.0231, -0.1731],[-0.1102, 0.1115, 0.1701],[-0.0567, -0.1341, 0.0511]]]], requires_grad=True)
偏置项: Parameter containing:
tensor([ 0.0481, -0.1906, -0.1884, 0.0912, -0.0207, 0.1297, -0.1344, 0.0010,-0.1730, -0.1730], requires_grad=True)
3.池化层
- 池化层用于减小特征图的空间维度,降低模型的参数数量,并增强模型的平移不变性。最大池化是最常用的池化方式,它们分别选择局部区域中的最大值和平均值作为输出。
import torch
import torch.nn as nn# 导入PyTorch库# 定义池化层区域大小和步幅
kernel_size = 2 # 池化区域的大小,可以是一个整数或者一个元组(高度,宽度)
stride = 2 # 步幅,控制池化操作移动的步长# 创建池化层
pool_layer = nn.MaxPool2d(kernel_size, stride) # 创建一个最大池化层对象,指定池化区域的大小和步幅# 打印最大池化层的参数
print('池化区域大小:', pool_layer.kernel_size) # 打印池化区域的大小,形状为(2, 2),表示高度和宽度均为2的池化区域
print('步幅:', pool_layer.stride) # 打印步幅,形状为(2, 2),表示在高度和宽度方向上的步幅均为2池化区域大小: 2
步幅: 2
4.循环神经网络
- 循环神经网络(Recurrent Neural NetWork, RNN)层用于处理序列数据,具有记忆力和上下文感知能力。RNN层通过在时间步之间共享权重,实现对序列的逐步处理,并输出相应的隐藏状态。
import torch
import torch.nn as nn # 定义输入特征维度、隐藏状态维度和层数
input_size = 10 # 输入特征的维度,也就是每个时间步的输入数据的大小
hidden_size = 20 # 隐藏状态的维度,决定了RNN层的输出大小
num_layers = 2 # RNN层的层数,决定了RNN的深度# 创建RNN层
rnn_layer = nn.RNN(input_size, hidden_size, num_layers) # 创建一个RNN层对象,指定输入特征维度、隐藏状态维度和层数# 打印RNN层的参数
print('输入特征维度:', rnn_layer.input_size) # 打印输入特征维度,即为10
print('隐藏状态维度:', rnn_layer.hidden_size) # 打印隐藏状态维度,即为20
print('层数:', rnn_layer.num_layers) # 打印层数,即为2
输入特征维度: 10
隐藏状态维度: 20
层数: 2
5.转置卷积层
- 转置卷积层,也被称为反卷积层,用于实现上采样操作,将低纬特征图转换为高维特征图。转置卷积层通过反向卷积操作将输入特征图映射到更大的输出特征图。
import torch
import torch.nn as nn# 定义输入通道数、输出通道数和卷积大小
in_channels = 3 # 输入的通道数,即输入特征图的深度
out_channels = 16 # 输出的通道数,即卷积核的个数
kernel_size = 3 # 卷积核的大小,可以是一个整数或者一个元组(高度,宽度)# 创建转置卷积层
transconv_layer = nn.ConvTranspose2d(in_channels, out_channels, kernel_size) # 创建一个转置卷积层对象,指定输入通道数、输出通道数和卷积大小# 打印转置卷积的权重和偏置项
print("权重:", transconv_layer.weight) # 打印转置卷积的权重,形状为(16, 3, 3, 3),表示有16个卷积核,每个卷积核的形状为(3, 3, 3)
print("偏置项:", transconv_layer.bias) # 打印转置卷积的偏置项,形状为(16,),表示有16个偏置项,每个偏置项对应一个卷积核
6.归一化层
- 归一化层用于调整神经网络的激活值分布,提升模型的收敛速度和泛化能力。常用的归一化层包括归一化和层归一化
import torch
import torch.nn as nn# 定义特征维度
num_features = 16 # 特征的维度,即特征的深度# 创建批归一化层
bn_layer = nn.BatchNorm2d(num_features) # 创建一个批归一化层对象,指定特征维度# 打印批归一化层的参数
print('特征维度:', bn_layer.num_features) # 打印特征维度,即为16
print("均值:", bn_layer.running_mean) # 打印批归一化层的均值,初始化为全零
print('方差:', bn_layer.running_var) # 打印批归一化层的方差,初始化为全零特征维度: 16
均值: tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
方差: tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
7.激活函数层
- 激活函数层用于引入非线性变换,增加神经网络的表达能力。常用的激活函数包括ReLU/sigmoid/Tanh等
import torch
import torch.nn as nn# 创建激活函数层(Relu)
activation_layer = nn.ReLU()# 定义输入张量
input_tensor = torch.randn(10)# 对输入张量进行激活函数变换
output_tensor = activation_layer(input_tensor)# 打印输出张量
print('输出张量:', output_tensor)
输出张量: tensor([0.0000, 0.0000, 1.6909, 0.0000, 0.0000, 0.0000, 0.0000, 0.9084, 0.0000,0.0000])
三、数据加载与预处理
- 在深度学习任务中,数据的加载和预处理是非常重要的步骤。Pytorch提供了强大的数据加载和预处理工具,使得我们能够高效地处理各种类型的数据。
1.数据加载
- Pytorch中的数据加载主要通过torch.utils.data模块实现。该模块提供了Dataset和DataLoader两个核心类,分别用于定义数据集和数据加载器
- Dataset类是一个抽象类,用于表示数据集。我们可以继承该类并实现自定义的数据集。在自定义数据集中,我们需要实现两个方法:len__和__getitem. __len__返回数据集的样本数量,__getitem__方法根据索引返回单个样本
import torch
from torch.utils import data
from torch.utils.data import Datasetclass MyDataset(data.Dataset):def __init__(self, data_list):# 初始化数据集self.data_list = data_listdef __len__(self):# 返回数据集大小return len(self.data_list)def __getitem__(self, index):# 根据索引索取样本sample = self.data_list[index]return sample
在上述示例中,MyDataset类接受一个数据列表作为输入,并实现了__len__和__getitem__方法
- torch.utils.data.DataLoader是Pytorch中一个重要的类,用于高效加载数据集。它可以处理数据的批次化、打乱顺序、多线程数据加载等功能。
import torch.utils.data as data
# 创建MyDataset实例my_dataset,它包含了一个整数列表。
my_dataset = MyDataset([1, 2, 3, 4, 5, 6, 7, 8, 9])
# 使用DataLoader类创建一个数据加载器my_dataloader,它将my_dataset作为输入,并将数据分成大小为4的批次,并对数据进行打乱随机化。
my_dataloader = data.DataLoader(my_dataset,batch_size=4,shuffle=True)
# 遍历my_dataloader,打印每个批次的数据
for batch in my_dataloader:print(batch)
tensor([4, 2, 5, 8])
tensor([1, 3, 9, 6])
tensor([7])
- torch.utils.data.Dataset和torch.utils.data.DataLoader用于加载数据集、用于对数据进行批量处理和随机化。
2.数据预处理
- 数据预处理是在将数据输入模型之前对数据进行的一系列操作,以提高模型的性能和准确性。Pytorch提供了多种数据预处理方法,包括常见的数据变换、标准化、图像增强等。以下是一些常见的数据预处理方法:
- Tensor转换:将数据转换为torch.Tensor类型是数据预处理的第一步。torch.Tensor是Pytorch中表示张量的主要数据类型
- 数据变换:将数据转换为torch.Tensor类型是数据预处理的第一步。torch.Tensor是Pytorch中表示张量的主要数据类型
- 数据标准化:数据标准化是对数据进行平均值和标准差的缩放,以使得数据具有零均值和单位方差。这通常用于提高模型的收敛性和稳定性
- 图像增强:图像增强是对图像进行变换或添加噪声,以增加训练数据的多样性和鲁棒性。Pytorch提供了torchvision.transforms模块中多种图像增强方法,如随机裁剪、翻转、旋转等。
四、模型训练与验证
1.模型训练
Pytorch中模型训练主要包括以下几个步骤:
- 1.准备数据:首先,准备好训练数据和对应的标签。可以使用torch.utils.data模块中的Dataset和DataLoader类来加载和批量处理数据
- 2.定义模型:接下来,定义模型的结构。可以选择torch.nn模块中的各种层和模型来构建自己的神经网络模型
- 3.定义损失函数:为了训练模型,定义损失函数来度量模型预测结果与真实标签之间的差异。可以使用torch.nn模块中的各种损失函数,如均方根误差(MSE)、交叉熵损失等。
- 4.定义优化器:为了更新模型的参数,需要选择一个优化器来优化模型的损失函数。可以使用torch.optim模块中的各种优化器,如随机梯度(SGD)、Adam等
- 5.训练模型:在每个训练迭代中,需要执行以下步骤:
- 前向传播:将输入数据通过模型得到模型的输出结果
- 计算损失:将模型的输出结果与真实标签计算损失函数的值
- 反向传播:根据损失函数的梯度,计算模型参数的梯度
- 参数更新:使用优化器根据梯度信息更新模型的参数
掌握这几个步骤,你就知道怎么进行模型训练了
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoadertrain_data = np.arange(512)
# 准备数据
train_dataset = MyDataset(train_data)
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True)# 定义模型
model = MyModel() # 注:这里的MyModel()需要自己去写一个模型,我这里没有写# 定义损失函数
loss_fn = nn.CrossEntropyLoss()# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
for epoch in range(num_epochs):for batch in train_dataloader:inputs, labels = batch# 前向传播outputs = model(inputs)# 计算损失loss = loss_fn(outputs, labels)# 反向传播optimizer.zero_grad() # 梯度清零loss.backward()# 参数更新optimizer.step()
2.模型验证
# 准备验证数据
val_dataset = MyDataset(val_data)
val_dataloader = DataLoader(val_dataset, batch_size=64)# 模型验证
model.eval() # 设置模型为评估模式
with torch.no_grad(): # 禁止梯度计算for batch in val_dataloader:inputs, labels = batch#前向传播outputs = model(inputs)
总结
以上介绍了深度学习中的神经网络,以及搭建神经网络所需要的步骤。
相关文章:
----神经网络)
小白入门pytorch(二)----神经网络
本文为🔗[小白入门Pytorch]学习记录博客 文章目录 前言一、神经网络的组成部分1.神经元2.神经网络层3.损失函数4.优化器 二、Pytorch构建神经网络中的网络层全连接层2.卷积层3.池化层4.循环神经网络5.转置卷积层6.归一化层7.激活函数层 三、数据加载与预处理1.数据加…...

【进阶C语言】排序函数(qsort)与模拟实现(回调函数的实例)
本章大致内容目录: 1.认识回调函数 2.排序函数qsort 3.模拟实现qsort 回调函数为C语言重要知识点,以函数指针为主要知识;下面介绍回调函数的定义、回调函数的库函数举例即库函数模拟实现。 一、回调函数 1.回调函数定义 回调函数就是一…...

CentOS 7 上编译和安装 SQLite 3.9.0
文章目录 可能报错分析详细安装过程 可能报错分析 报错如下: django.core.exceptions.ImproperlyConfigured: SQLite 3.9.0 or later is required (found 3.7.17). 原因:版本为3.7.太低了,需要升级到3.9.0至少 详细安装过程 1.安装所需的…...

[GXYCTF2019]禁止套娃 无回显 RCE 过滤__FILE__ dirname等
扫除git 通过githack 获取index.php <?php include "flag.php"; echo "flag在哪里呢?<br>"; if(isset($_GET[exp])){if (!preg_match(/data:\/\/|filter:\/\/|php:\/\/|phar:\/\//i, $_GET[exp])) {if(; preg_replace(/[a-z,_]\(…...

Springboot使用Aop保存接口请求日志到mysql
1、添加aop依赖 <!-- aop日志 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId></dependency> 2、新建接口保存数据库的实体类RequestLog.java package com.example…...
网络安全面试题汇总(附答案)
作为从业多年的网络安全工程师,我深知在面试过程中面试官所关注的重点及考察的技能点。网络安全作为当前信息技术领域中非常重要的一部分,对于每一个从事网络安全工作的人员来说,不仅需要掌握一定的技术能力,更需要具备全面的综合…...

Centos7安装kvm,配置虚拟机网络
1.安装软件包,禁用防火墙(非必须) yum -y install qemu-kvm libvirt virt-install 1)禁用防火墙(非必须) systemctl stop firewalld systemctl disable firewalld 2)禁用NetworkManager syst…...

Javascript文件上传
什么是文件上传 文件上传包含两部分, 一部分是选择文件,包含所有相关的界面交互。一部分是网络传输,通过一个网络请求,将文件的数据携带过去,传递到服务器中,剩下的,在服务器中如何存储…...
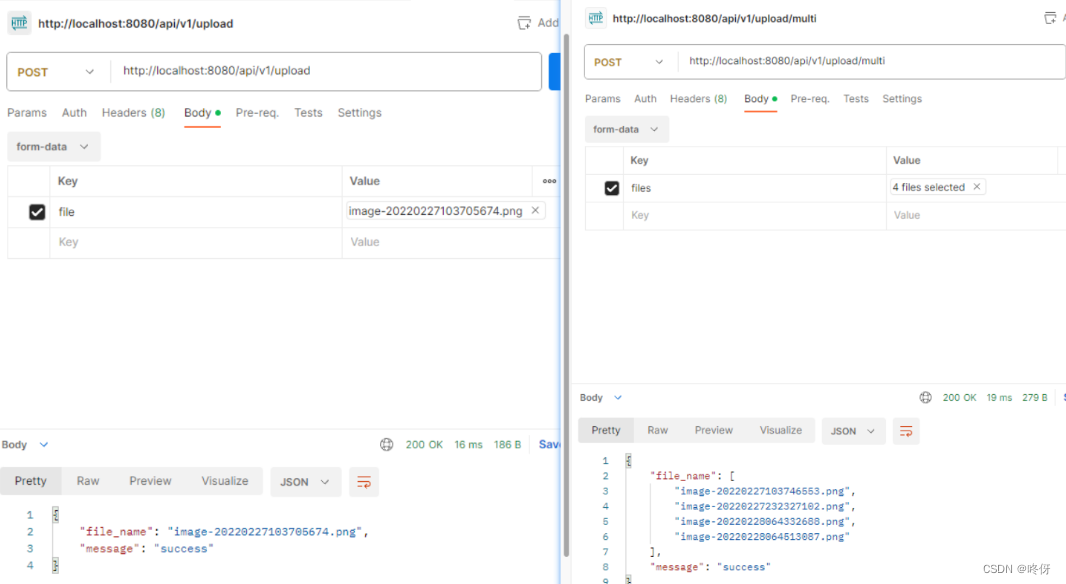
golang gin——文件上传(单文件,多文件)
文件上传 单文件上传 从form-data获取文件 package uploadimport ("github.com/gin-gonic/gin""net/http" ) // 单文件上传,多文件上传 func Upload(c *gin.Context) {file, _ : c.FormFile("file") // file为字段名dst : "…...

面试题:Redis和MySQL的事务区别是什么?
大家好,我是小米!今天我要和大家聊聊一个在技术面试中经常被问到的问题:“Redis和MySQL的事务区别是什么?”这个问题看似简单,但实际上涉及到了数据库和缓存两个不同领域的知识,让我们一起来深入了解一下吧…...

Canvas绘图
Canvas绘图 Canvas的意义 随着前端的不断发展,页面特效越来越炫酷,W3C组织也不断退出新的CSS特性:例如各种渐变,瀑布流布局,各种阴影,但是随着需求越来越花哨,W3C表示:我去你妈的&…...
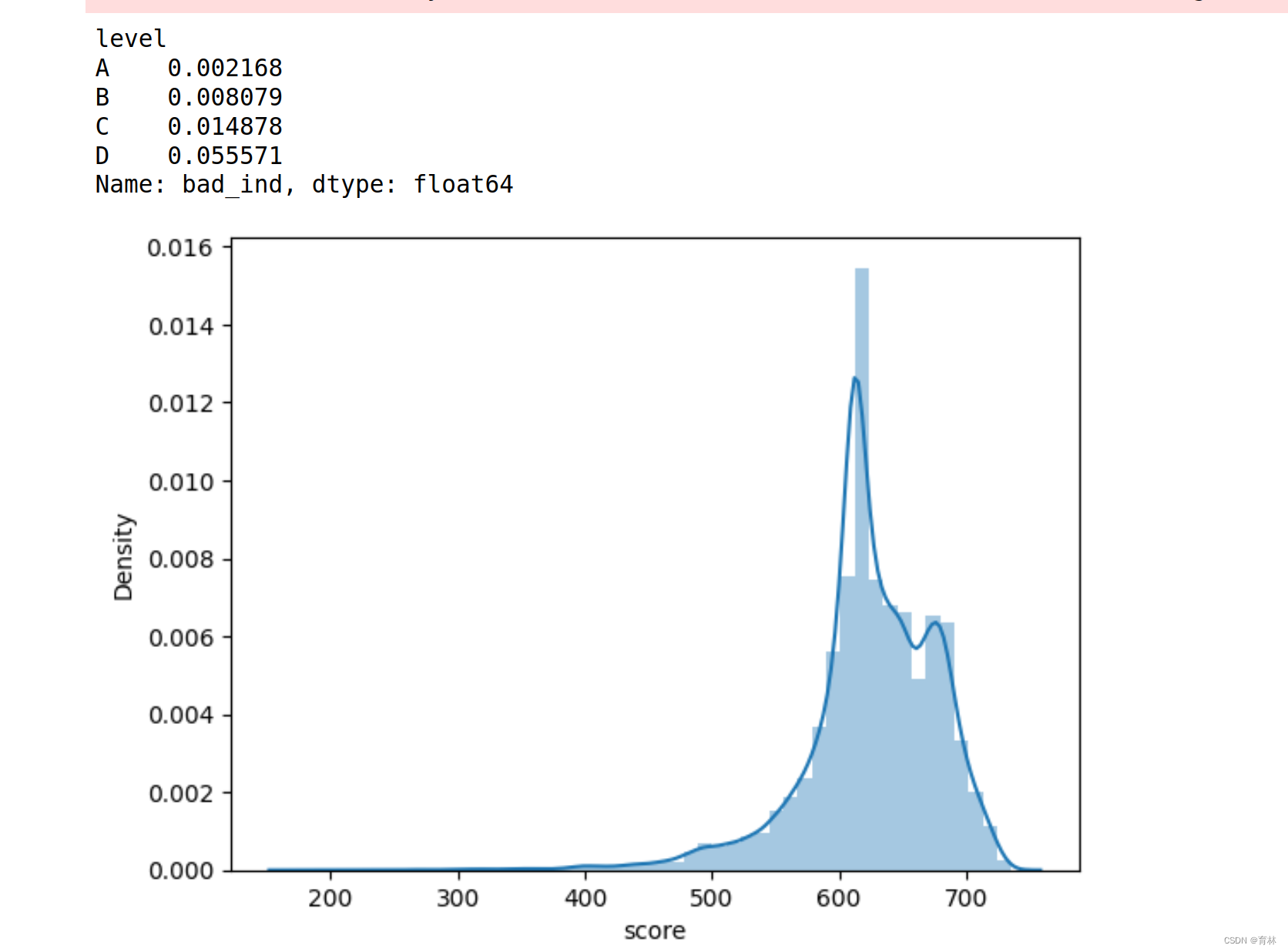
逻辑回归评分卡
文章目录 一、基础知识点(1)逻辑回归表达式(2)sigmoid函数的导数损失函数(Cross-entropy, 交叉熵损失函数)交叉熵求导准确率计算评估指标 二、导入库和数据集导入库读取数据 三、分析与训练四、模型评价ROC曲线KS值再做特征筛选生成报告 五、行为评分卡模型表现总结 一、基础知…...

DPDK系列之三十三DPDK并行机制的底层支持
一、背景介绍 在前面介绍了DPDK中的上层对并行的支持,特别是对多核的支持。但是,大家都知道,再怎么好的设计和架构,再优秀的编码,最终都要落到硬件和固件对整个上层应用的支持。单纯的硬件好处理,一个核不…...
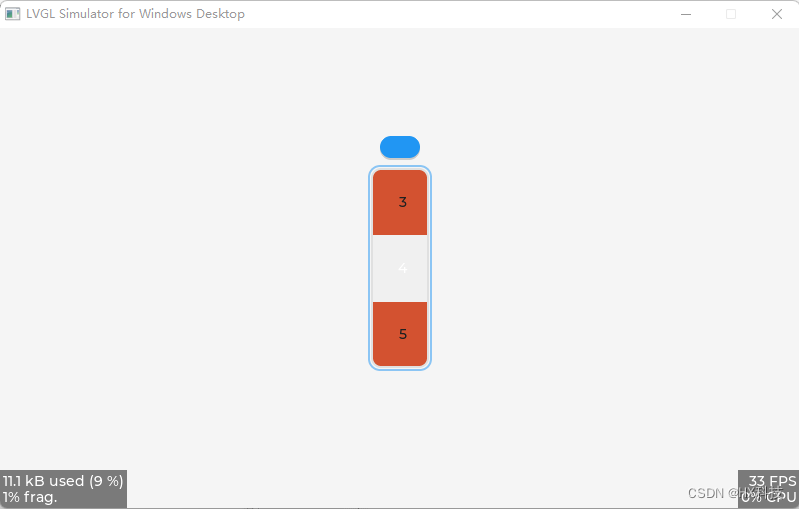
LVGL_基础控件滚轮roller
LVGL_基础控件滚轮roller 1、创建滚轮roller控件 /* 创建一个 lv_roller 部件(对象) */ lv_obj_t * roller lv_roller_create(lv_scr_act()); // 创建一个 lv_roller 部件(对象),他的父对象是活动屏幕对象// 将部件(对象)添加到组,如果设置了默认组,…...
王道考研操作系统——文件管理
磁盘的基础知识 .txt用记事本这个应用程序打开,文件最重要的属性就是文件名了 保护信息:操作系统对系统当中的各个用户进行了分组,不同分组的用户对文件的操作权限是不一样的 文件的逻辑结构就是文件内部的数据/记录应该被怎么组织起来&…...
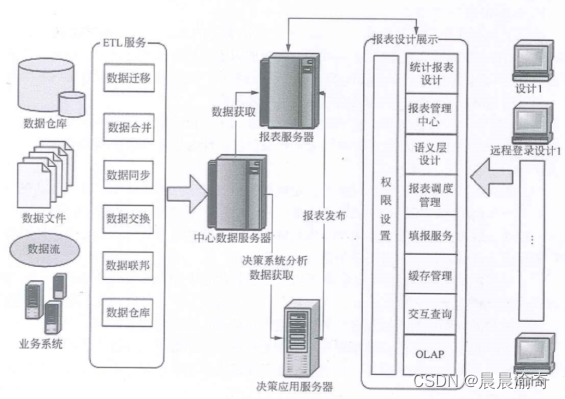
商业智能系统的主要功能包括数据仓库、数据ETL、数据统计输出、分析功能
ETL服务内容包含: 数据迁移数据合并数据同步数据交换数据联邦数据仓库...

基于帝国主义竞争优化的BP神经网络(分类应用) - 附代码
基于帝国主义竞争优化的BP神经网络(分类应用) - 附代码 文章目录 基于帝国主义竞争优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.帝国主义竞争优化BP神经网络3.1 BP神经网络参数设置3.2 帝国主义竞争算…...

将python项目部署在一台服务器上
将python项目部署在一台服务器上 1.服务器2.部署方法2.1 手动部署2.2 容器化技术部署2.3 服务器less技术部署 1.服务器 服务器一般为:物理服务器和云服务器。 我的是物理服务器:这是将服务器硬件直接放置在您自己的数据中心或机房的传统方法。这种方法需…...
【C语言】善于利用指针(二)
💗个人主页💗 ⭐个人专栏——C语言初步学习⭐ 💫点击关注🤩一起学习C语言💯💫 目录 导读:1. 字符指针1.1 字符串的引用方式1.2 有趣的面试题 2. 数组指针2.1 一维数组指针的定义2.2 一维数组…...

Python调用C++
https://www.cnblogs.com/renfanzi/p/10276997.html Linux使用Python调用C/C接口(一) - 代码先锋网 linux系统上使用Python调用C生成的.so动态链接库opencv_linux 下python 编译为so ,给c使用_比赛学习者的博客-CSDN博客 https://www.cnblogs.com/shuimuqingyang/p/13618105…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

1.3 VSCode安装与环境配置
进入网址Visual Studio Code - Code Editing. Redefined下载.deb文件,然后打开终端,进入下载文件夹,键入命令 sudo dpkg -i code_1.100.3-1748872405_amd64.deb 在终端键入命令code即启动vscode 需要安装插件列表 1.Chinese简化 2.ros …...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

《C++ 模板》
目录 函数模板 类模板 非类型模板参数 模板特化 函数模板特化 类模板的特化 模板,就像一个模具,里面可以将不同类型的材料做成一个形状,其分为函数模板和类模板。 函数模板 函数模板可以简化函数重载的代码。格式:templa…...

三分算法与DeepSeek辅助证明是单峰函数
前置 单峰函数有唯一的最大值,最大值左侧的数值严格单调递增,最大值右侧的数值严格单调递减。 单谷函数有唯一的最小值,最小值左侧的数值严格单调递减,最小值右侧的数值严格单调递增。 三分的本质 三分和二分一样都是通过不断缩…...

解决:Android studio 编译后报错\app\src\main\cpp\CMakeLists.txt‘ to exist
现象: android studio报错: [CXX1409] D:\GitLab\xxxxx\app.cxx\Debug\3f3w4y1i\arm64-v8a\android_gradle_build.json : expected buildFiles file ‘D:\GitLab\xxxxx\app\src\main\cpp\CMakeLists.txt’ to exist 解决: 不要动CMakeLists.…...
)
安卓基础(Java 和 Gradle 版本)
1. 设置项目的 JDK 版本 方法1:通过 Project Structure File → Project Structure... (或按 CtrlAltShiftS) 左侧选择 SDK Location 在 Gradle Settings 部分,设置 Gradle JDK 方法2:通过 Settings File → Settings... (或 CtrlAltS)…...
【LeetCode】算法详解#6 ---除自身以外数组的乘积
1.题目介绍 给定一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O…...