【Go语言实战】(25) 分布式算法 MapReduce
MapReduce
写在前面
身为大数据专业的学生,其实大学我也多多少少接触过mapreduce,但是当时觉得这玩意太老了,觉得这和php一样会被时代淘汰。只能说当时确实太年轻了,没有好好珍惜那时候的学习资源…
现在回过头来看mapreduce,发现技术这东西和语言不一样,技术万变不离其中,而语言只是实现技术的一种方法而已,用什么语言其实并不重要。
原论文地址:MapReduce: Simplified Data Processing on Large Clusters
总览
这次 lab1 的 mapreduce,其实是在 搜索引擎tangseng 的时候,需要用来构建倒排索引。所以会和课程上所要求的不太一样,这里也没有使用rpc调用,而是为了与项目统一,便改用了grpc进行调用。
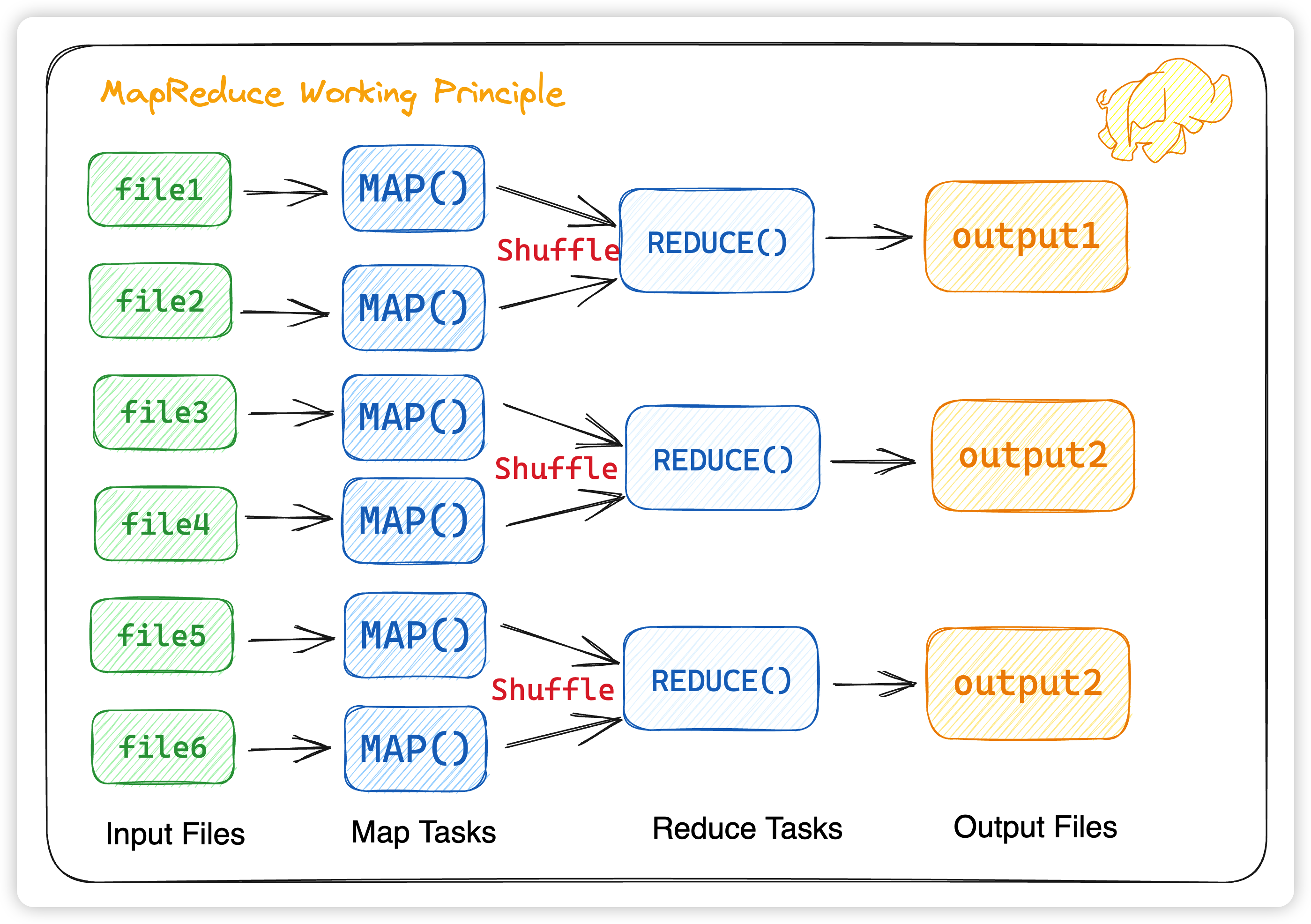
这里需要注意几点
- 不同的Map任务之间不会进行通信
- 不同的Reduce任务之间也不会发生任何信息交换
- 所有的数据交换都是通过MapReduce框架自身去实现的
那么如何对 map tasks 和 reduce tasks 进行合理的协调呢?这里我们就要引入两个角色,master 和 worker,在原论文中,对这两者的并没有非常明确的定义,但我们可以摘录并提炼原论文对这两个角色的描述:
master :
- The master picks idle workers and assigns each one a map task or a reduce task.
worker :
-
The map worker who is assigned a map task reads the contents of the corresponding input split.
-
The reduce worker iterates over the sorted intermediate data and for each unique intermediate key encountered, it passes the key and the corresponding set of intermediate values to the user’s Reduce function
这里我们先说一下几个状态枚举值:
- idle :空闲状态
- in-progress :进行状态
- completed :完成状态
这三个枚举值代表着每一个 map task 和 reduce task 的状态,标识着这些 task 是未开始,进行中,还是已完成。
那么 master 其实就是选择空闲的 worker 节点,为每一个空闲的 worker 节点分配 map task 或者 reduce task。而 worker 看似分成了 map worker 和 reduce worker,但其实这两个 worker 都是一样,只是看 master 分配的是 map task 还是 reduce task。这样我们的 map 和 reduce 的数据传送就非常清晰了。
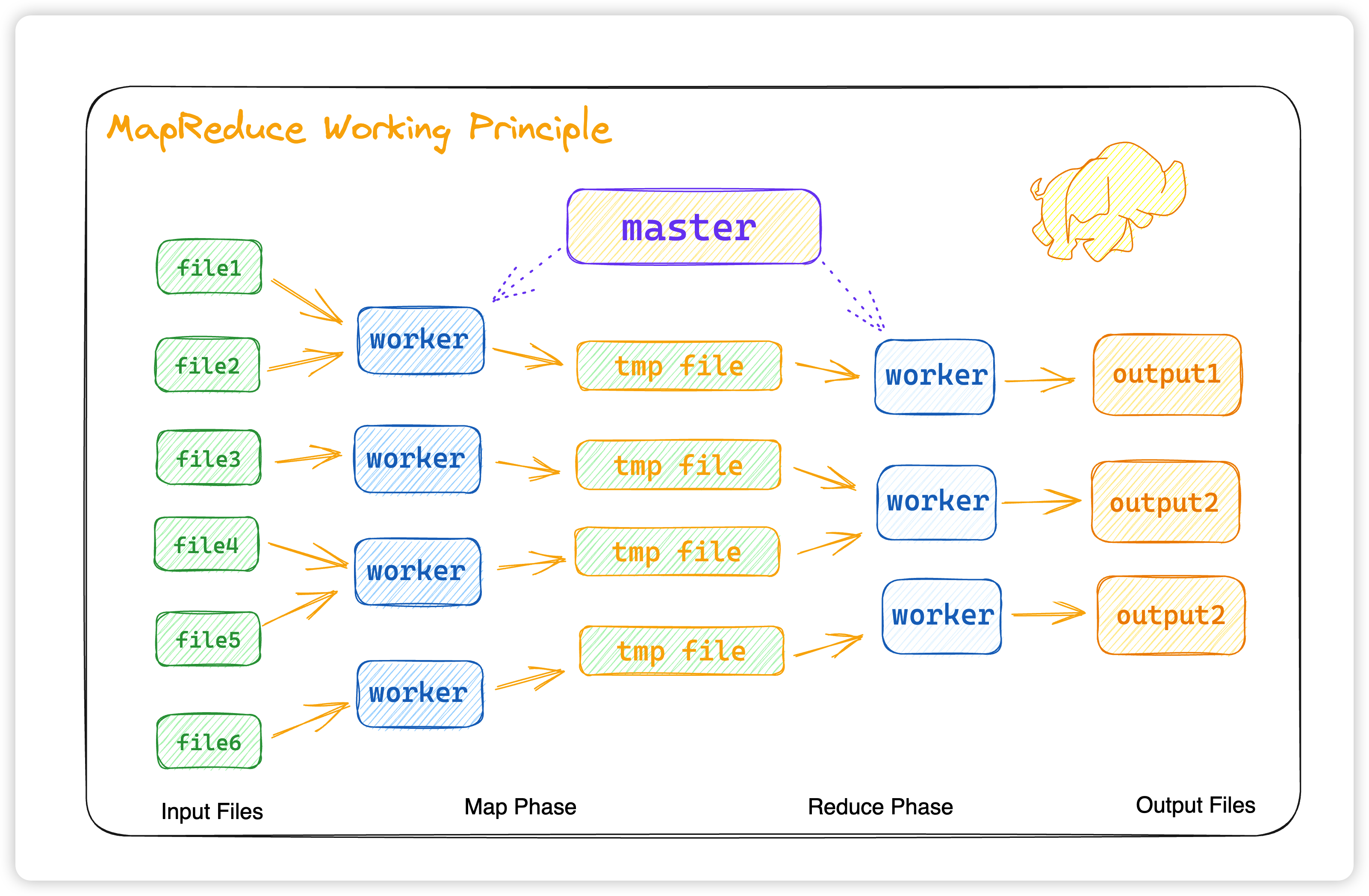
接下来,我们来详细讲解一下这几个重要的角色
Worker
首先我们先定义一个 MapReduce 的任务,也就是我们 worker 需要用到参数
type MapReduceTask struct {Input string `json:"input"` // 输入的文件TaskState State `json:"task_state"` // 状态NReducer int `json:"n_reducer"` // reducer 数量TaskNumber int `json:"task_number"` // 任务数量Intermediates []string `json:"intermediates"` // map 之后的文件存储地址Output string `json:"output"` // output的输出地址
}
接着再定义 State 枚举值
type MasterTaskStatus intconst (Idle MasterTaskStatus = iota + 1 // 未开始InProgress // 进行中Completed // 已完成
)
接下来我们的 Worker 函数就很简单了
func Worker(ctx context.Context, mapf func(string, string) []*types.KeyValue, reducef func(string, []string) *roaring.Bitmap) {// 启动workerfor {task, err := getTask(ctx) // worker从master获取任务if err != nil {log.LogrusObj.Error("Worker-getTask", err)return}// 拿到task之后,根据task的state,map task交给mapper, reduce task交给reducer// 额外加两个state,让 worker 等待 或者 直接退出switch task.TaskState {case int64(types.Map):mapper(ctx, task, mapf)case int64(types.Reduce):reducer(ctx, task, reducef)case int64(types.Wait):time.Sleep(5 * time.Second)case int64(types.Exit):returndefault:return}}
}
至于 mapper 和 reducer 如何实现的,先桥豆麻袋一下,下文在 map 和 reduce 中会给出答案,如何从 master 中拿到 task 呢?这就涉及到 worker 和 master 的通信。本来打算用 RPC 通信的,但为了项目的整体统一,还是用了 gRPC 。
创建一个proto文件
syntax="proto3";
option go_package = "/index_platform;";message MapReduceTask{// @inject_tag:form:"input" uri:"input"string input = 1;// @inject_tag:form:"task_state" uri:"task_state"int64 task_state = 2;// @inject_tag:form:"n_reducer" uri:"n_reducer"int64 n_reducer = 3;// @inject_tag:form:"task_number" uri:"task_number"int64 task_number = 4;// @inject_tag:form:"intermediates" uri:"intermediates"repeated string intermediates = 5;// @inject_tag:form:"output" uri:"output"string output = 6;
}message MasterTaskCompletedResp {// @inject_tag:form:"code" uri:"code"int64 code=1;// @inject_tag:form:"message" uri:"message"string message=2;
}service MapReduceService {rpc MasterAssignTask(MapReduceTask) returns (MapReduceTask);rpc MasterTaskCompleted(MapReduceTask) returns (MasterTaskCompletedResp);
}
定义两个 RPC 函数,MasterAssignTask 用来接受 master 分配的 task MasterTaskCompleted 完成 task 之后,对这个 task 进行标识,意味着该任务结束。
所以我们 worker 接受任务的通信如下
func getTask(ctx context.Context) (resp *mapreduce.MapReduceTask, err error) {// worker从master获取任务taskReq := &mapreduce.MapReduceTask{}resp, err = rpc.MapReduceClient.MasterAssignTask(ctx, taskReq)return
}
当完成任务时,通过gRPC发送给master
func TaskCompleted(ctx context.Context, task *mapreduce.MapReduceTask) (reply *mapreduce.MasterTaskCompletedResp, err error) {// 通过RPC,把task信息发给masterreply, err = rpc.MapReduceClient.MasterTaskCompleted(ctx, task)return
}
那么 master 是如何分配任务的?接下来我们来介绍一下 master 节点。
Master
我们定义这么一个 Master 服务的结构体
type MasterSrv struct {TaskQueue chan *types.MapReduceTask // 等待执行的taskTaskMeta map[int]*types.MasterTask // 当前所有task的信息MasterPhase types.State // Master的阶段NReduce int // Reduce的数量InputFiles []string // 输入的文件Intermediates [][]string // Map任务产生的R个中间文件的信息mapreduce.UnimplementedMapReduceServiceServer // gRPC服务实现接口
}
那么当我们 New 一个 Master 服务的时候,顺便创建 map tasks 任务
func NewMaster(files []string, nReduce int) *MasterSrv {m := &MasterSrv{TaskQueue: make(chan *types.MapReduceTask, int(math.Max(float64(nReduce), float64(len(files))))),TaskMeta: map[int]*types.MasterTask{},MasterPhase: types.Map,NReduce: nReduce,InputFiles: files,Intermediates: make([][]string, nReduce),}m.createMapTask()return m
}
创建 map task 任务
func (m *MasterSrv) createMapTask() {// 把输入的files都形成一个task元数据塞到queue中for idx, filename := range m.InputFiles { taskMeta := types.MapReduceTask{Input: filename,TaskState: types.Map, // map节点NReducer: m.NReduce,TaskNumber: idx,}m.TaskQueue <- &taskMetam.TaskMeta[idx] = &types.MasterTask{TaskStatus: types.Idle, // 状态为 idle ,等待worker节点来领取 taskTaskReference: &taskMeta,}}
}
创建 reduce task 任务
func (m *MasterSrv) createReduceTask() {m.TaskMeta = map[int]*types.MasterTask{}for idx, files := range m.Intermediates {taskMeta := types.MapReduceTask{TaskState: types.Reduce, // reduce 阶段NReducer: m.NReduce,TaskNumber: idx,Intermediates: files,}m.TaskQueue <- &taskMetam.TaskMeta[idx] = &types.MasterTask{TaskStatus: types.Idle, // 找到空闲的 workerTaskReference: &taskMeta,}}
}
MasterAssignTask 等待 worker 来领取 task
func (m *MasterSrv) MasterAssignTask(ctx context.Context, req *mapreduce.MapReduceTask) (reply *mapreduce.MapReduceTask, err error) {mu.Lock()defer mu.Unlock()task := &types.MapReduceTask{Input: req.Input,TaskState: types.State(req.TaskState),NReducer: int(req.NReducer),TaskNumber: int(req.TaskNumber),Intermediates: req.Intermediates,Output: req.Output,}if len(m.TaskQueue) > 0 {// 如果queue中还有任务的话就发出去*task = *<-m.TaskQueuem.TaskMeta[task.TaskNumber].TaskStatus = types.InProgress // 修改worker的状态为进行中m.TaskMeta[task.TaskNumber].StartTime = time.Now() // 记录task的启动时间} else if m.MasterPhase == types.Exit {*task = types.MapReduceTask{TaskState: types.Exit,}} else {// 没有task就让worker等待*task = types.MapReduceTask{TaskState: types.Wait}}// 返回该任务的状态,因为发出去就是给task了,这个状态已经改变了,worker可以工作了reply = &mapreduce.MapReduceTask{Input: task.Input,TaskState: int64(task.TaskState),NReducer: int64(task.NReducer),TaskNumber: int64(task.TaskNumber),Intermediates: task.Intermediates,Output: task.Output,}return
}
那么如果 task 把任务都做完了,master 应该怎么回应呢?
func (m *MasterSrv) MasterTaskCompleted(ctx context.Context, req *mapreduce.MapReduceTask) (resp *mapreduce.MasterTaskCompletedResp, err error) {resp = new(mapreduce.MasterTaskCompletedResp)resp.Code = e.ERRORresp.Message = "map finish successfully"// 更新task状态if req.TaskState != int64(m.MasterPhase) || m.TaskMeta[int(req.TaskNumber)].TaskStatus == types.Completed {// 因为worker写在同一个文件这次盘上对于重复的结果要丢弃return}m.TaskMeta[int(req.TaskNumber)].TaskStatus = types.Completederr = m.processTaskResult(req) // always success haha and hope u so :)if err != nil {resp.Code = e.ERRORresp.Message = "map finish failed"return}return
}
处理任务的结果,如果是 map 完成后就变成 reduce 阶段,reduce 之后就是 all done. 😃
// processTaskResult 处理任务结果
func (m *MasterSrv) processTaskResult(task *mapreduce.MapReduceTask) (err error) {switch task.TaskState {case int64(types.Map):// 收集intermediate信息for reduceTaskId, filePath := range task.Intermediates {m.Intermediates[reduceTaskId] = append(m.Intermediates[reduceTaskId], filePath)}if m.allTaskDone() {// 获取所有的map task后,进入reduce阶段m.createReduceTask()m.MasterPhase = types.Reduce}case int64(types.Reduce):if m.allTaskDone() {// 获得所有的reduce task后,进去exit阶段m.MasterPhase = types.Exit}}return
}
介绍完master之后,我们具体来看一下map的具体行为。
Map
在 map 中,我们抽离出一个 mapper,具体的map函数可根据实际情况进行修改,然后将map function传入mapper中进行实际的map动作,我们读取每一个文件,然后把输出的结果都放到 intermediates 中,并且根据 task 所设定的 NReducer 也就是 reducer 数 进行hash ,将结果均匀分到每个中间文件中。
func mapper(ctx context.Context, task *mapreduce.MapReduceTask, mapf func(string, string) []*types.KeyValue) {// 从文件名读取contentcontent, err := os.ReadFile(task.Input)if err != nil {log.LogrusObj.Error("mapper", err)return}// 将content交给mapf,缓存结果intermediates := mapf(task.Input, string(content))// 缓存后的结果会写到本地磁盘,并切成R份// 切分方式是根据key做hashbuffer := make([][]*types.KeyValue, task.NReducer)for _, intermediate := range intermediates {slot := ihash(intermediate.Key) % task.NReducerbuffer[slot] = append(buffer[slot], intermediate)}mapOutput := make([]string, 0)for i := 0; i < int(task.NReducer); i++ {mapOutput = append(mapOutput, writeToLocalFile(int(task.TaskNumber), i, &buffer[i]))}// R个文件的位置发送给mastertask.Intermediates = mapOutput_, err = TaskCompleted(ctx, task) // 完成后,给master发送消息,map阶段结束if err != nil {fmt.Println("mapper-TaskCompleted", err)}return
}
具体的 Map方法,由于是用于搜索引擎,所以这里是建立倒排索引
func Map(filename string, contents string) (res []*types.KeyValue) {res = make([]*types.KeyValue, 0)lines := strings.Split(contents, "\r\n") // 分行var inputData *model.InputDatafor _, line := range lines[1:] {docStruct, _ := doc2Struct(line) // 字符串转 doc structtokens, err := analyzer.GseCutForBuildIndex(docStruct.DocId, docStruct.Body)if err != nil {return}for _, v := range tokens {res = append(res, &types.KeyValue{Key: v.Token, Value: cast.ToString(v.DocId)}) // token:docId 倒排索引}}return
}
至此map就已经完成了,是不是很简单,其实具体的map和reduce并不难,难的是如何平衡调度,接下来我们来看看reduce是如何怎么的。
Reduce
和map一样,我们抽离出一个reducer,然后把具体的 reduce 传进去,当然还有一个shuffle过程,这里进行排序会减少后面的reduce计算。可以少计算几次。
func reducer(ctx context.Context, task *mapreduce.MapReduceTask, reducef func(string, []string) *roaring.Bitmap) {// 先从filepath读取intermediate的KeyValueintermediate := *readFromLocalFile(task.Intermediates)// 根据kv排序 shuffle 过程sort.Sort(types.ByKey(intermediate))dir, _ := os.Getwd()outName := fmt.Sprintf("%s/mr-tmp-%d.%s",dir, task.TaskNumber, consts.InvertedBucket)invertedDB := storage.NewInvertedDB(outName)output := roaring.NewBitmap()var outByte []bytei := 0for i < len(intermediate) {// 将相同的key放在一起分组合并j := i + 1for j < len(intermediate) && intermediate[j].Key == intermediate[i].Key {j++}var values []stringfor k := i; k < j; k++ {values = append(values, intermediate[k].Value)}// 交给reducef,拿到结果output = reducef(intermediate[i].Key, values)// 落倒排索引库outByte, _ = output.MarshalBinary()_ = invertedDB.StoragePostings(intermediate[i].Key, outByte)i = j}task.Output = outName_, err := TaskCompleted(ctx, task) // 完成后,给master发送消息,reduce阶段结束if err != nil {fmt.Println("reducer-TaskCompleted", err)return}
}
具体的Reduce,其实就是把相同的key的value聚合在一起。比如
after map:
{"apple":1}
{"apple:"2}
{"poizon":3}
after reduce:
{"apple":{1,2}}
{"poizon":{3}}
具体实现如下所示:
func Reduce(key string, values []string) *roaring.Bitmap {docIds := roaring.New()for _, v := range values {docIds.AddInt(cast.ToInt(v))}return docIds
}
最终 output 输出
以上就是我对6.824这个课程的lab1的所有理解了,并且运用到了 tangseng 搜索引擎中。
具体代码实现地址在 https://github.com/CocaineCong/tangseng/app/mapreduce 中。
相关文章:
【Go语言实战】(25) 分布式算法 MapReduce
MapReduce 写在前面 身为大数据专业的学生,其实大学我也多多少少接触过mapreduce,但是当时觉得这玩意太老了,觉得这和php一样会被时代淘汰。只能说当时确实太年轻了,没有好好珍惜那时候的学习资源… 现在回过头来看mapreduce&a…...

【网络安全-信息收集】网络安全之信息收集和信息收集工具讲解(提供工具)
工具下载百度网盘链接(包含所有用到的工具): 百度网盘 请输入提取码百度网盘为您提供文件的网络备份、同步和分享服务。空间大、速度快、安全稳固,支持教育网加速,支持手机端。注册使用百度网盘即可享受免费存储空间https://pan.…...

战火使命ssr排名,战火使命角色强度排行
在战火使命中,很多玩家都在关注SSR角色的强度排行,那么,下面就为大家分享一下小编整理的最新战火使命ssr排名,一起来看看吧。 关注【娱乐天梯】,获取内部福利号 一、SSR角色排名榜: 1. 克拉拉、艾蕾娜、杰西…...
 函数—背景颜色渐变设计)
CSS之linear-gradient( ) 函数—背景颜色渐变设计
目录 linear-gradient( ) 函数 简介: 语法: 详解: 例如: linear-gradient( ) 函数 简介: linear-gradient 函数是 CSS 中用于创建线性渐变的函数。它接受一个或多个参数,并使用这些参数创建一个渐变。…...

[Unity]未能加载一个或多个断点问题
【背景】 大家2023国庆快乐,虽然是假期,我还是继续码些文章。 今天写项目时遇到个环境问题,新建脚本时双击调起VS编辑器,忽然提示无法加载一个或多个断点(当时忘记截图了,现在已解决,就不上图了…...
Qt中的基础数据类型
1.基础类型 因为Qt是一个C++ 框架, 因此C++中所有的语法和数据类型在Qt中都是被支持的, 但是Qt中也定义了一些属于自己的数据类型, 下边给大家介绍一下这些基础的数类型 QT基本数据类型定义在#include <QtGlobal> 中,QT基本数据类型有: 类型名称注释备注qint8signed ch…...

2023阿里云域名优惠口令大全
2023年阿里云域名优惠口令,com域名续费优惠口令“com批量注册更享优惠”,cn域名续费优惠口令“cn注册多个价格更优”,cn域名注册优惠口令“互联网上的中国标识”,阿里云优惠口令是域名专属的优惠码,可用于域名注册、续…...

湖南软件测评公司简析:软件功能测试和非功能测试的联系和区别
一、软件功能测试 软件功能测试旨在验证软件是否按照需求规格说明书的要求正常工作。具体而言,功能测试会对软件的所有功能进行测试,以确保其满足用户的需求和预期。在进行功能测试时,根据需求规格说明书编写测试用例,并在测试…...
HuggingFace Transformers教程(1)--使用AutoClass加载预训练实例
知识的搬运工又来啦 ☆*: .。. o(≧▽≦)o .。.:*☆ 【传送门>原文链接:】https://huggingface.co/docs/transformers/autoclass_tutorial 🚗🚓🚕🛺🚙🛻🚌Ƕ…...

Qt获取当前所用的Qt版本、编译器、位数等信息
//详细的Qt版本编译器位数 QString compilerString "<unknown>"; { #if defined(Q_CC_CLANG)QString isAppleString; #if defined(__apple_build_version__)isAppleString QLatin1String(" (Apple)"); #endifcompilerString QLatin1String("…...
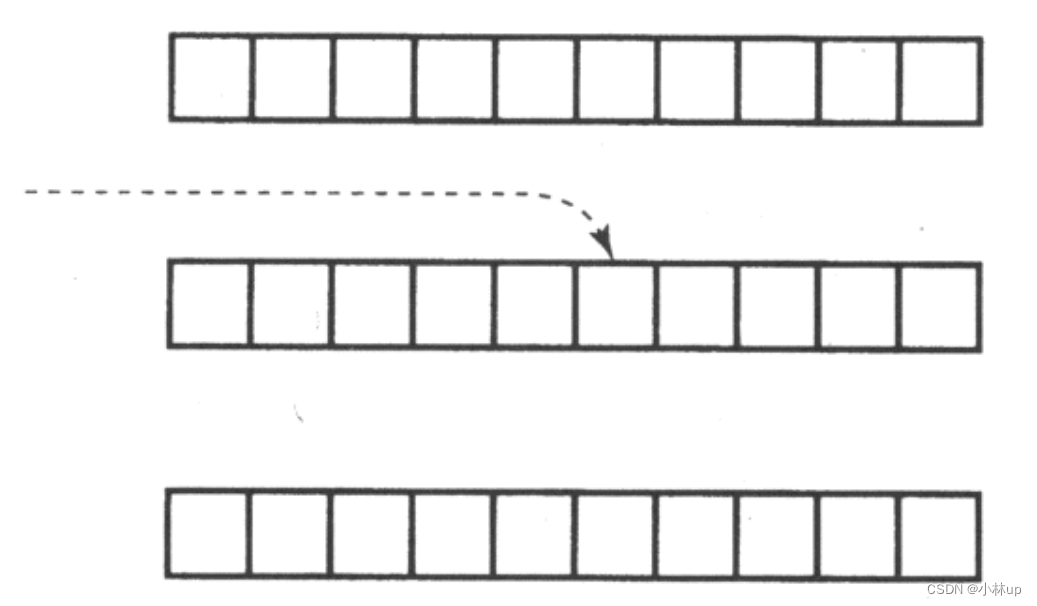
《C和指针》笔记31:多维数组的数组名、指向多维数组的指针、作为函数参数的多维数组
文章目录 1. 指向多维数组的数组名2. 指向多维数组的指针3. 作为函数参数的多维数组 1. 指向多维数组的数组名 我们知道一维数组名的值是一个指针常量,它的类型是“指向元素类型的指针”,它指向数组的第1个元素。那么多维数组的数组名代表什么呢&#x…...
【伪彩色图像处理】将灰度图像转换为彩色图像研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Go Gin Gorm Casbin权限管理实现 - 2. 使用Gorm存储Casbin权限配置以及`增删改查`
文章目录 0. 背景1. 准备工作2. 权限配置以及增删改查2.1 策略和组使用规范2.2 用户以及组关系的增删改查2.2.1 获取所有用户以及关联的角色2.2.2 角色组中添加用户2.2.3 角色组中删除用户 2.3 角色组权限的增删改查2.3.1 获取所有角色组权限2.3.2 创建角色组权限2.3.3 修改角色…...

DNDC模型的温室气体排放分析
DNDC(Denitrification-Decomposition,反硝化-分解模型)是目前国际上最为成功的模拟生物地球化学循环的模型之一,自开发以来,经过不断完善和改进,从模拟简单的农田生态系统发展成为可以模拟几乎所有陆地生态…...

vue、全局前置守卫
需求:在使用商城app的时候,游客(没有登录的用户)可以看到商品信息,当游客点击添加购物车的时候,我们需要把游客“拦”到登录页面,登陆后,才可以添加商品。 游客只可以看得到部分页面…...

OpenWRT、Yocto 、Buildroot和Ubuntu有什么区别
OpenWRT: 用途:OpenWRT 是一个专注于路由器和嵌入式网络设备的Linux发行版。它提供了一个优化的Linux环境,旨在将网络设备变成功能丰富、高度可定制的路由器。 包管理器:OpenWRT 使用 opkg 包管理器,它是一个轻量级的…...
数据挖掘(3)特征化
从数据分析角度,DM分为两类,描述式数据挖掘,预测式数据挖掘。描述式数据挖掘是以简介概要的方式描述数据,并提供数据的一般性质。预测式数据挖掘分析数据建立模型并试图预测新数据集的行为。 DM的分类: 描述式DM&#…...
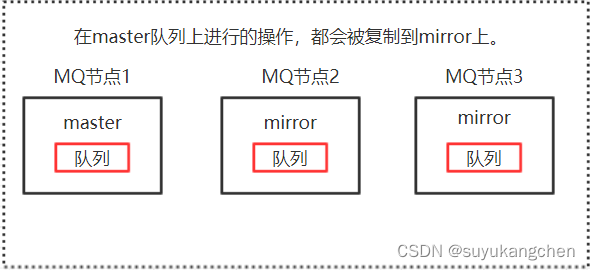
【RabbitMQ 实战】08 集群原理剖析
上一节,我们用docker-compose搭建了一个RabbitMQ集群,这一节我们来分析一下集群的原理 一、基础概念 1.1 元数据 前面我们有介绍到 RabbitMQ 内部有各种基础构件,包括队列、交换器、绑定、虚拟主机等,他们组成了 AMQP 协议消息…...

2023年 2月3月 工作经历
2月 #pragma make_public(type) 托管C导出传统C类,另一个托管C项目使用不了。传统C类make_public后,就可以使用了。对模板类无效,比如:std::string。 C#线程绑定CPU 我的方案: 假定我们想把 CPU0 设置成专有CPU。 定…...

selenium京东商城爬取
该项目主要参考与:http://c.biancheng.net/python_spider/selenium-case.html 你看完上述项目内容之后,会发现京东登录是一个比较坑的点,selenium控制浏览器没有登录京东,导致我们自动爬取网页被重定向到京东登录注册页面。 因此,我们要单独…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...