用Python简单的实现一下六大主流小说平台小说下载(附源码)
很多小伙伴学习Python的初衷就是为了爬取小说,方便又快捷~
辣么今天咱们来分享6个主流小说平台的爬取教程~

一、流程步骤
流程基本都差不多,只是看网站具体加密反爬,咱们再进行解密。
实现爬虫的第一步?
1、去抓包分析,分析数据在什么地方。
1. 打开开发者工具
2. 刷新网页
3. 找数据 --> 通过关键字搜索
2、获取小说内容
1. 目标网址
2. 获取网页源代码请求小说链接地址,解析出来 。
3. 请求小说内容数据包链接:
4. 获取加密内容 --> ChapterContent
5. 进行解密 --> 分析加密规则 是通过什么样方式 什么样代码进行加密
3、获取响应数据
response.text 获取文本数据 字符串
response.json() 获取json数据 完整json数据格式
response.content 获取二进制数据 图片 视频 音频 特定格式文件
二、案例
1、书旗
环境模块
[环境使用]:Python 3.8Pycharm[模块使用]:requests execjs re
源码展示
# 导入数据请求模块
import requests
# 导入正则模块
import re
import execjs
# 模拟浏览器
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.3'
}
# 请求链接 -> 目录页面链接
html = '网址屏蔽了,不然过不了'
# 发送请求
html_ = requests.get(url=html, headers=headers).text
# 小说名字
name = re.findall('<title>(.*?)-书旗网</title>', html_)[0]
# 提取章节名字 / 章节ID
info = re.findall('data-clog="chapter\$\$chapterid=(\d+)&bid=8826245">\d+\.(.*?)</a>', html_, re.S)
print(name)
# for 循环遍历
for chapter_id, index in info:title = index.strip()print(chapter_id, title)# 请求链接url = f'https://网址屏蔽了,不然过不了/reader?bid=8826245&cid={chapter_id}'# 发送请求 <Response [200]> 响应对象response = requests.get(url=url, headers=headers)# 获取响应数据html_data = response.text# 正则匹配数据data = re.findall('contUrlSuffix":"\?(.*?)","shelf', html_data)[0].replace('amp;', '')# 构建小说数据包链接地址link = 'https://c13.网址屏蔽了,不然过不了.com/pcapi/chapter/contentfree/?' + data# 发送请求json_data = requests.get(url=link, headers=headers).json()# 键值对取值, 提取加密内容ChapterContent = json_data['ChapterContent']# 解密内容 --> 通过python调用JS代码, 解密f = open('书旗.js', encoding='utf-8')# 读取JS代码text = f.read()# 编译JS代码js_code = execjs.compile(text)# 调用Js代码函数result = js_code.call('_decodeCont', ChapterContent).replace('<br/><br/>', '\n').replace('<br/>', '')# 保存数据with open(f'{name}.txt', mode='a', encoding='utf-8') as v:v.write(title)v.write('\n')v.write(result)v.write('\n')print(json_data)print(ChapterContent)print(result)
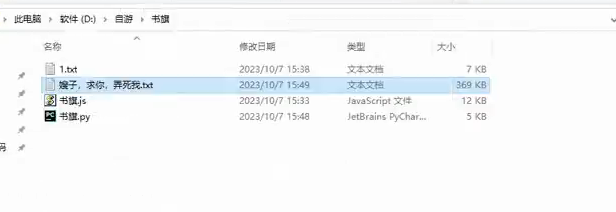
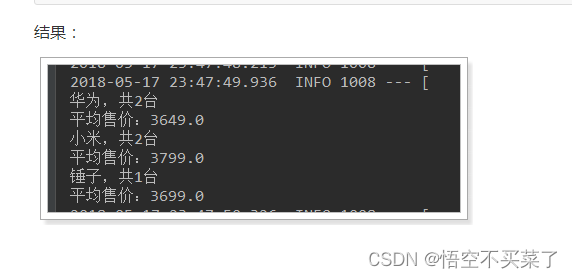
效果展示
2、塔读
环境模块
[环境使用]:Python 3.8Pycharm[模块使用]:requests --> pip install requestsexecjs --> pip install pyexecjsre
源码
# 导入数据请求模块
import requests
# 导入正则表达式模块
import re
# 导入读取JS代码
import execjs# 模拟浏览器
headers = {'Host': '网址屏蔽了,以免不过','Referer': '网址屏蔽了,以免不过','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36',
}
# 请求链接
link = '网址屏蔽了,以免不过'
# 发送请求
link_data = requests.get(url=link, headers=headers).text
# 小说名字
name = re.findall('book_name" content="(.*?)">', link_data)[0]
# 章节ID 和 章节名字
info = re.findall('href="/book/\d+/(\d+)/" target="_blank">(.*?)</a>', link_data)[9:]
page = 1
# for 循环遍历
for chapter_id, title in info:print(chapter_id, title)# 获取广告 data-limit 参数j = open('塔读.js', encoding='utf-8')# 读取JS代码text = j.read()# 编译JS代码js_code = execjs.compile(text)# 调用js代码函数data_limit = js_code.call('o', chapter_id)print(data_limit)# 请求链接url = f'网址屏蔽了,以免不过/{page}'# 发送请求 <Response [200]> 响应对象 表示请求成功response = requests.get(url=url, headers=headers)# 获取响应json数据 --> 字典数据类型json_data = response.json()# 解析数据 -> 键值对取值 content 获取下来content = json_data['data']['content']# 处理小说内容广告 初级版本 --> 后续需要升级content_1 = re.sub(f'<p data-limit="{data_limit}">.*?</p>', '', content)# 提取小说内容 -> 1. 正则表达式提取数据 2. css/xpath 提取result = re.findall('<p data-limit=".*?">(.*?)</p>', content_1)# 把列表合并成字符串string = '\n'.join(result)# 保存数据with open(f'{name}.txt', mode='a', encoding='utf-8') as f:f.write(title)f.write('\n')f.write(string)f.write('\n')print(string)page += 1
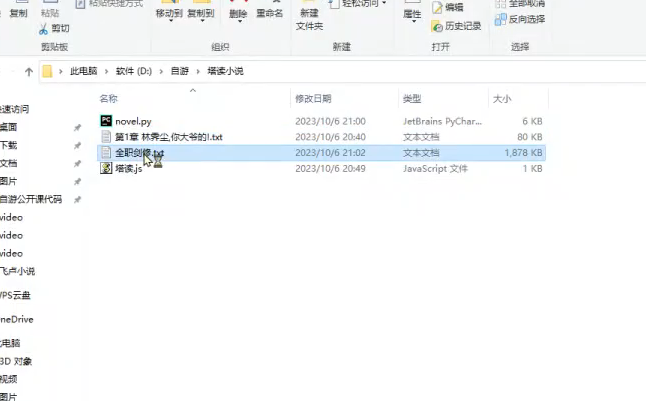
效果展示
3、飞卢
环境模块
[环境使用]:Python 3.8Pycharm[模块使用]:requests >>> 数据请求模块parsel >>> 数据解析模块re 正则表达式
源码展示
# 数据请求模块
import requests
# 数据解析模块
import parsel
# 正则表达式模块
import re
import base64def get_content(img):url = "https://aip.网址屏蔽,不然不过审.com/oauth/2.0/token"params = {"grant_type": "client_credentials","client_id": "","client_secret": ""}access_token = str(requests.post(url, params=params).json().get("access_token"))content = base64.b64encode(img).decode("utf-8")url_ = "网址屏蔽,不然不过审" + access_tokendata = {'image': content}headers = {'Content-Type': 'application/x-www-form-urlencoded','Accept': 'application/json'}response = requests.post(url=url_, headers=headers, data=data)words = '\n'.join([i['words'] for i in response.json()['words_result']])return words# 模拟伪装
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
}
# 请求链接
link = '网址屏蔽,不然不过审'
# 发送请求
link_response = requests.get(url=link, headers=headers)
# 获取响应文本数据
link_data = link_response.text
# 把html文本数据, 转成可解析对象
link_selector = parsel.Selector(link_data)
# 提取书名
name = link_selector.css('#novelName::text').get()
# 提取链接
href = link_selector.css('.DivTr a::attr(href)').getall()
# for循环遍历
for index in href[58:]:# 请求链接url = 'https:' + indexprint(url)# 发送请求 <Response [200]> 响应对象response = requests.get(url=url, headers=headers)# 获取响应文本数据html_data = response.text# 把html文本数据, 转成可解析对象 <Selector xpath=None data='<html xmlns="http://www.w3.org/1999/x...'>selector = parsel.Selector(html_data)# 解析数据, 提取标题title = selector.css('.c_l_title h1::text').get() # 根据数据对应标签直接复制css语法即可# 提取内容content_list = selector.css('div.noveContent p::text').getall() # get提取第一个# 列表元素大于2 --> 能够得到小说内容if len(content_list) > 2:# 把列表合并成字符串content = '\n'.join(content_list)# 保存数据with open(name + '.txt', mode='a', encoding='utf-8') as f:f.write(title)f.write('\n')f.write(content)f.write('\n')
效果展示
因为这玩意爬下来是图片,所以还要进行文字识别,

else:# 提取图片内容info = re.findall("image_do3\((.*?)\)", html_data)[0].split(',')img = 'https://read.faloo.com/Page4VipImage.aspx'img_data = {'num': '0','o': '3','id': '724903','n': info[3],'ct': '1','en': info[4],'t': '0','font_size': '16','font_color': '666666','FontFamilyType': '1','backgroundtype': '0','u': '15576696742','time': '','k': info[6].replace("'", ""),}img_content = requests.get(url=img, params=img_data, headers=headers).content# 文字识别, 提取图片中文字内容content = get_content(img=img_content)# 保存数据with open(name + '.txt', mode='a', encoding='utf-8') as f:f.write(title)f.write('\n')f.write(content)f.write('\n')
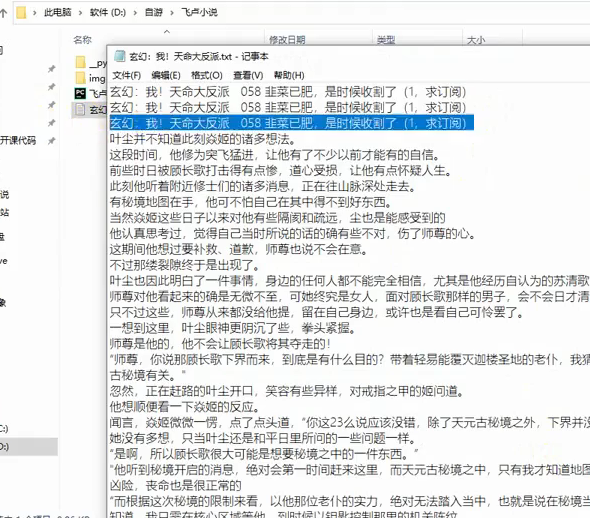
识别效果
4、纵横中文
环境模块
解释器: python 3.8
编辑器: pycharm 2022.3
crypto-js
requests
源码展示
import execjs
import requests
import recookies = {
}headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','Accept-Language': 'zh-CN,zh;q=0.9','Cache-Control': 'no-cache','Connection': 'keep-alive','Pragma': 'no-cache','Referer': '网址屏蔽了,不过审','Sec-Fetch-Dest': 'document','Sec-Fetch-Mode': 'navigate','Sec-Fetch-Site': 'same-site','Sec-Fetch-User': '?1','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36','sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"',
}response = requests.get('网址屏蔽了,不过审', cookies=cookies, headers=headers)html_data = response.text
i = re.findall('<div style="display:none" id="ejccontent">(.*?)</div>', html_data)[0]
f = open('demo.js', mode='r', encoding='utf-8').read()
ctx = execjs.compile(f)
result = ctx.call('sdk', i)
print(result)
5、笔趣阁
模块环境
[相关模块]:<第三方模块>requests >>> pip install requestsparsel<内置模块>re[开发环境]:环 境: python 3.8编辑器:pycharm 2021.2
源码展示
import requests # 第三方模块 pip install requests
import parsel # 第三方模块
import re # 内置模块 url = 'https://网址屏蔽/book/88109/'
# 伪装
headers = {# 键值对 键 --》用户代理 模拟浏览器的基本身份'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
# 发送请求 response 响应体
response = requests.get(url=url, headers=headers)
print(response)selector = parsel.Selector(response.text)
title = selector.css('.zjlist dd a::text').getall()# 章节链接
link = selector.css('.zjlist dd a::attr(href)').getall()
# print(link)
# replace re.sub()# zip()
zip_data = zip(title, link)
for name, p in zip_data:# print(name)# print(p)passage_url = '网址屏蔽'+ p# print(passage_url)# 发送请求response_1 = requests.get(url=passage_url, headers=headers)# print(response_1.text)# 解析数据 content 二进制 图片 视频# re # 查找所有re_data = re.findall('<div id="content"> (.*?)</div>', response_1.text)[0]# print(re_data)# replace 替换text = re_data.replace('笔趣阁 www.网址屏蔽.net,最快更新<a href="https://网址屏蔽/book/88109/">盗墓笔记 (全本)</a>', '')text = text.replace('最新章节!<br><br>', '').replace(' ', '')# print(text)text = text.replace('<br /><br />', '\n')print(text)passage = name + '\n' + textwith open('盗墓笔记.txt',mode='a') as file:file.write('')
6、起点
环境模块
python3.8 解释器版本
pycharm 代码编辑器
requests 第三方模块
代码展示
import reimport requests # 第三方模块 额外安装
import subprocess
from functools import partial
# 处理execjs编码报错问题, 需在 import execjs之前
subprocess.Popen = partial(subprocess.Popen, encoding="utf-8")
import execjsheaders = {'cookie': 用自己的,我的删了
}
ctx = execjs.compile(open('起点.js', mode='r', encoding='utf-8').read())
url = 'https://网址屏蔽/chapter/1035614679/755998264/'
response = requests.get(url=url, headers=headers)html_data = response.textarg1 = re.findall('"content":"(.*?)"', html_data)[0]
arg2 = url.split('/')[-2]
arg3 = '0'
arg4 = re.findall('"fkp":"(.*?)"', html_data)[0]
arg5 = '1'
result = ctx.call('sdk', arg1, arg2, arg3, arg4, arg5)
print(result)text = re.findall('"content":"(.*?)","riskInfo"', html_data)[0]
text = text.replace('\\u003cp>', '\n')f = open('1.txt', mode='w', encoding='utf-8')
f.write(text)
源码我都打包好了,还有详细视频讲解,文末名片自取,备注【小说】快速通过。
好了,今天的分享就到这里了,下次见~
相关文章:
用Python简单的实现一下六大主流小说平台小说下载(附源码)
很多小伙伴学习Python的初衷就是为了爬取小说,方便又快捷~ 辣么今天咱们来分享6个主流小说平台的爬取教程~ 一、流程步骤 流程基本都差不多,只是看网站具体加密反爬,咱们再进行解密。 实现爬虫的第一步? 1、去抓包分析,分析数…...
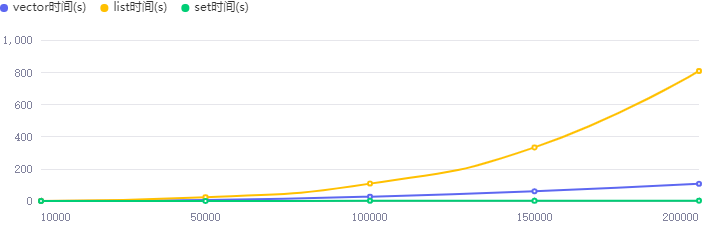
c++模板库容器list vector map set操作和性能对比
文章目录 listvectormapset性能比较总结 list 列表(list)是C STL中的一种容器类型,它是一个双向链表,可以在任意位置高效地添加、删除、移动元素。 以下是一些常用的列表操作: 创建列表 #include <list> std…...

windows服务添加 nginx 开机自启
软件下载 将下载的压缩包解压后得到nssm.exe。 安装nginx为服务 我们直接打开cmd执行: nssm install 即可...

【Redis】redis的特性和使用场景
Redis的特性 速度快基于键值对的数据结构服务器丰富的功能简单稳定客⼾端语⾔多持久化主从复制⾼可⽤(HighAvailability)和分布式(Distributed) 速度快 Redis 执⾏命令的速度⾮常快。 Redis 的所有数据都是存放在内存中的&…...

opengauss数据备份(docker中备份)
首先如果想直接在宿主机上进行使用gs_dump备份需要glibc的版本到2.34及以上,查看版本命令为 ldd --version 如图所示,本宿主机并不满足要求,所以转向在docker容器中进行备份, 然后进入opengauss容器中,命令为 docker…...

WebKit Inside: CSS 样式表的解析
CSS 全称为层叠样式表(Cascading Style Sheet),用来定义 HTML 文件最终显示的外观。 为了理解 CSS 的加载与解析,需要对 CSS 样式表的组成,尤其是 CSS Selector 有所了解,相关部分可以参看这里。 HTML 文件里面引入 CSS 样式表有 …...
javaee之Elasticsearch相关知识
简单说一下Elasticsearch相关知识 其余的参考官网文档 我们还可以用下面的方式来查 看一下原始索引库的模板 下面看一下数据库映射关系 下面就是更改了id1的所有数据 下面是我索引库中的内容 说一下查询之后,一些属性的含义 上面案例是这样理解的 match查询类型会对…...
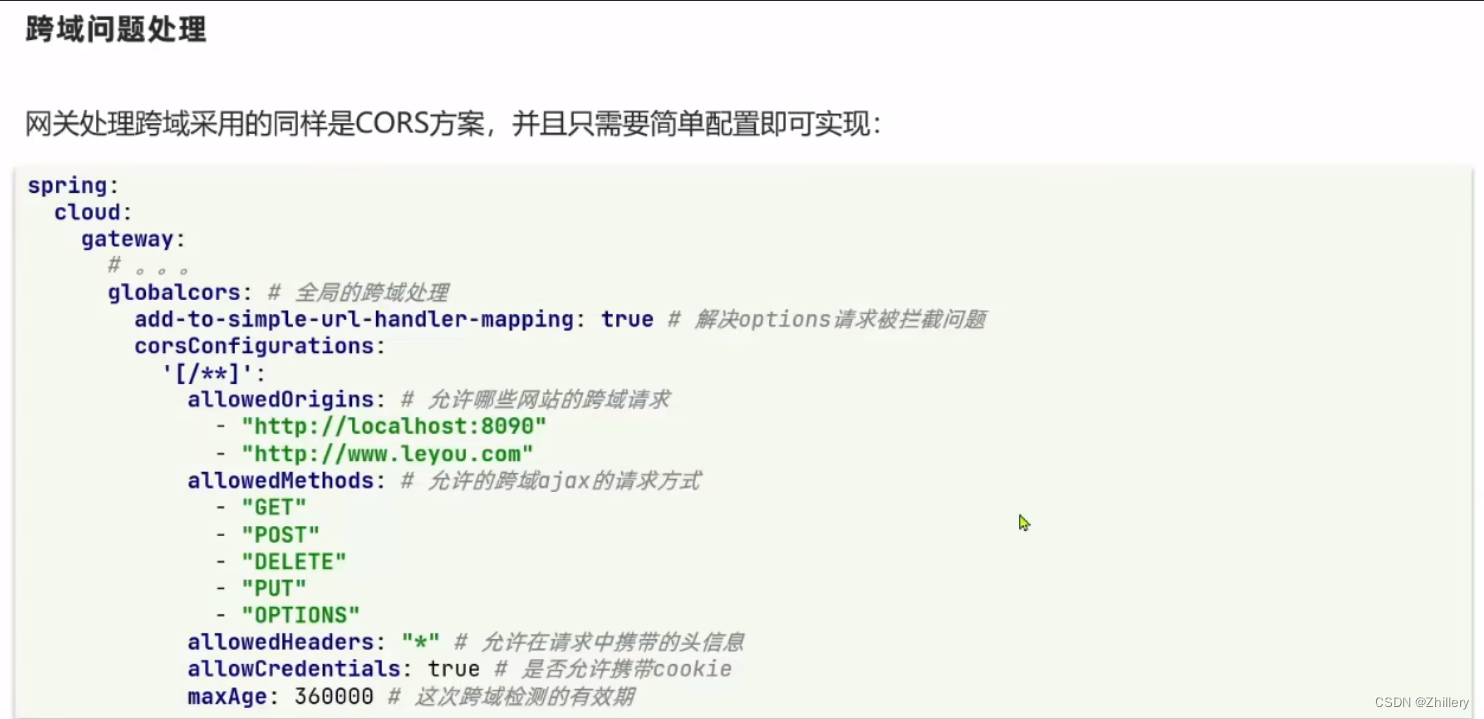
【SpringCloud】微服务技术栈入门3 - Gateway快速上手
目录 GatewayWebFlux网关基本配置过滤器与断言工厂全局过滤器跨域处理 CORS Gateway WebFlux gateway 基于 webflux 构建 WebFlux 是基于反应式流概念的响应式编程框架,用于构建异步非阻塞的 Web 应用程序。它支持响应式编程范式,并提供了一种响应式的方…...

《理解深度学习》2023最新版本+习题答案册pdf
刚入门深度学习或者觉得学起来很困难的同学看过来了,今天分享的这本深度学习教科书绝对适合你。 就是这本已在外网获13.1万次下载的宝藏教科书《理解深度学习》。本书由巴斯大学计算机科学教授Simon J.D. Prince撰写,全书共541页,目前共有21…...
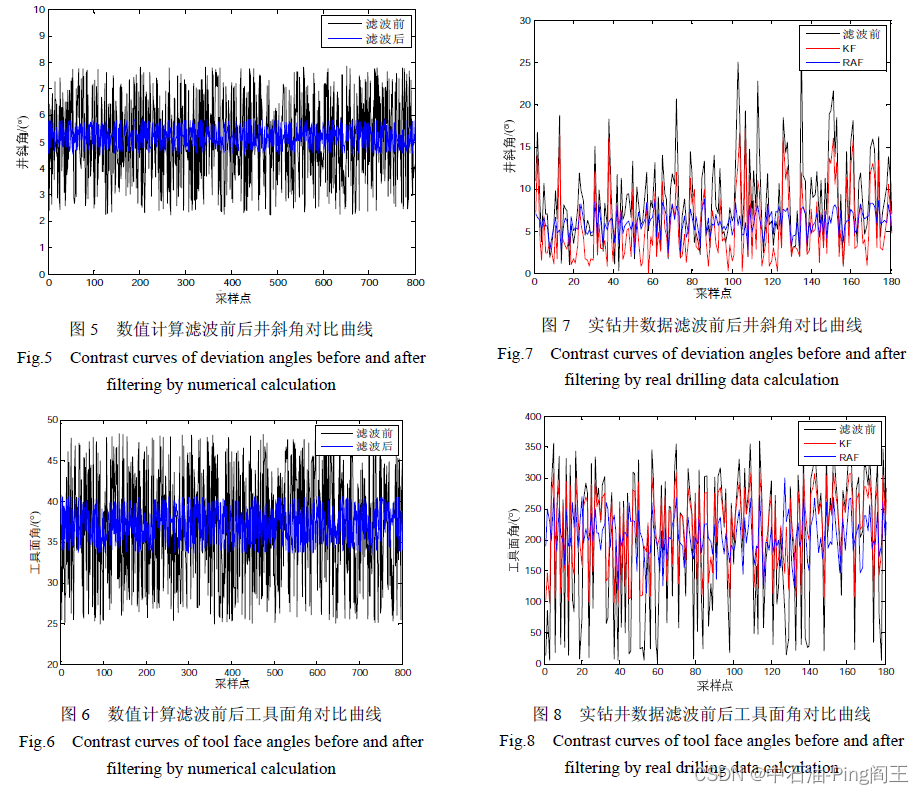
课题学习(五)----阅读论文《抗差自适应滤波的导向钻具动态姿态测量方法》
一、简介 抗差自适应滤波:利用等价权函数和自适应因子合理的分配信息,有效地滤除钻具振动对动态姿态测量的影响。、 针对导向钻井工具动态测量受钻具振动的影响而导致测量不准确的问题,提出一种抗差自适应滤波的动态空间姿态测量方法。通…...

一个CPU是怎么寻址的?
目录 CISC vs RISC 概念和历史 CISC vs RISC 对比举例:X86的CAS(做原子操作的) 对比举例:ARM的CAS(做原子操作的) 指令寻址 指令中的操作数的寻址方式 各语言对象内存布局对比 C内存布局 理解编译单元 Java对象内存布局 python对象模型 CPU …...

提高网站性能的10种方法:加速用户体验和降低服务器负担
在今天的数字时代,网站性能对于吸引和保留用户至关重要。一个快速加载的网站不仅提供更好的用户体验,还有助于降低服务器负担。以下是10种提高网站性能的方法,旨在加速页面加载速度和减少服务器的工作负荷。 压缩网页资源 利用压缩算法如gzi…...
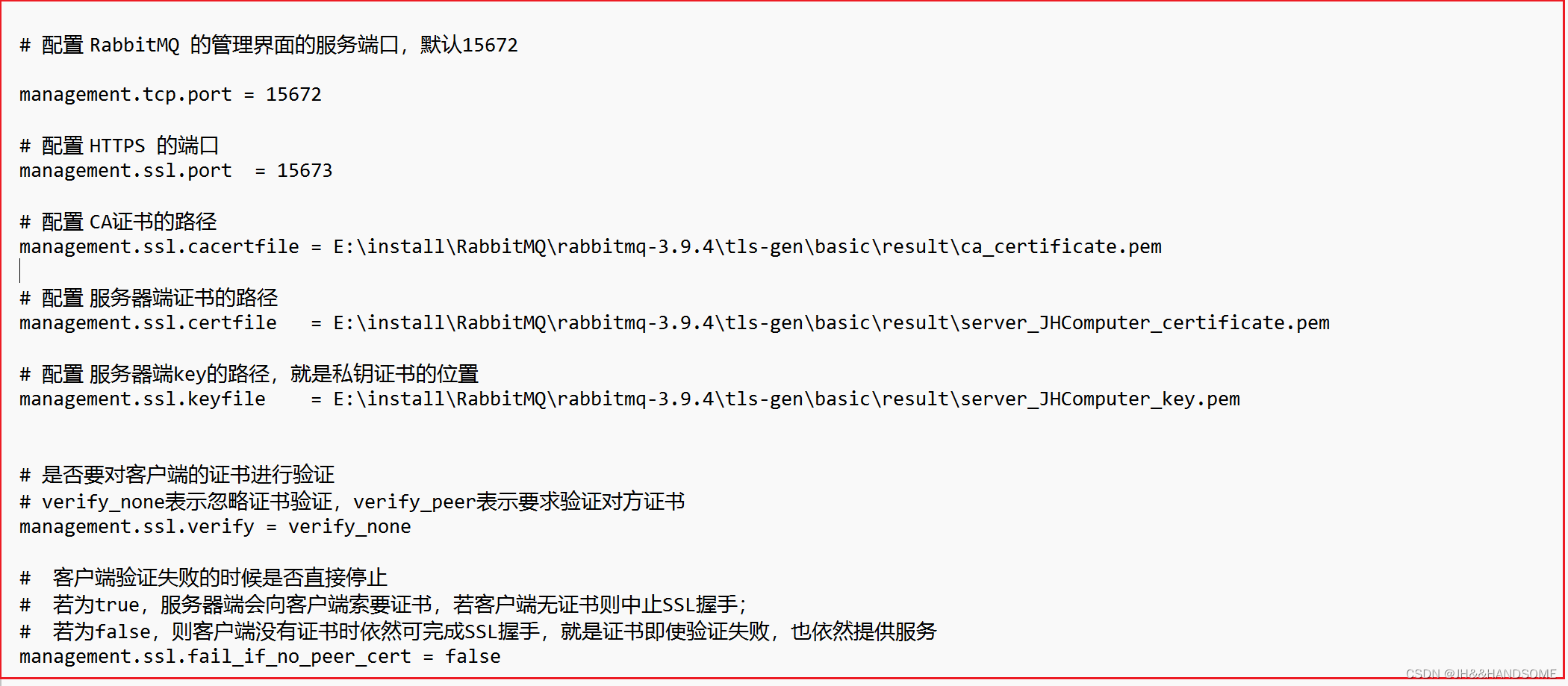
195、SpringBoot--配置RabbitMQ消息Broker的SSL 和 管理控制台的HTTPS
开启Rabbitmq的一些命令: 小黑窗输入: rabbitmq-plugins enable rabbitmq_management 启动控制台插件,就是启动登录rabbitmq控制台的页面 rabbitmq_management 代表了RabbitMQ的管理界面。 rabbitmq-server 启动rabbitMQ服务器 上面这个&…...

确定性执行
确定性执行是指在给定输入的情况下,在有限的时间内产生一致的输出。 也就是输入到输出的运行过程是确定的,输入与输出有如下关系: 输出 = f (输入)。 确定性执行主要涉及以下几个方面: 时间确定性:计算的输出始终在给定的某个时间点之前发生,即程序不能无限制地运行下去…...

docker compose 管理应用服务的常用命令
一 、docker compose 是什么 Docker Compose是一个用来管理多个关联容器的工具,可以根据配置文件自动构建、管理、编排一组容器。 Docker Compose语境下的“服务”是指一组容器共同构成的一个应用服务后端。 Docker Compose语境下的“项目”是由一个或多个应用服务…...

产品安全—CC标准 ISO/IEC 15408:2022
文章目录 1. 变化2. Part1 简介和一般模型3. Part2 安全功能组件4. Part3 安全保障组件5. Part4 评估方法和活动规范框架6. Part5 预定义的安全要求包7. 总结 1. 变化 增加了两个部分:评估方法和活动规范框架 & 预定义的安全要求包 术语已经过审查和更新&#…...
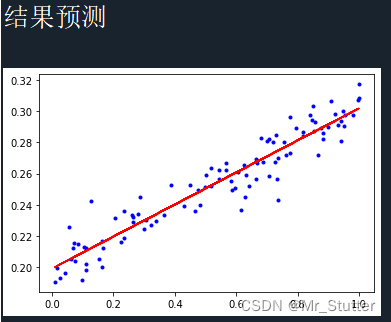
Pytorch笔记之回归
文章目录 前言一、导入库二、数据处理三、构建模型四、迭代训练五、结果预测总结 前言 以线性回归为例,记录Pytorch的基本使用方法。 一、导入库 import numpy as np import matplotlib.pyplot as plt import torch from torch.autograd import Variable # 定义求…...

哪个证券公司可以加杠杆,淘配网是您的杠杆综合网站!
在证券市场中,投资者经常寻求提高资金杠杆以获得更高的回报。杠杆交易可以让您在不必拥有等额本金的情况下,参与更多的交易活动。然而,为了进行杠杆交易,您需要找到一家证券公司或平台,可以为您提供这种服务。本文将介…...

万字解读|怎样激活 TDengine 最高性价比?
不知不觉间,TDengine 已经 6 岁多了。在这 6 年多的时间里,我们从零开始,在一行又一行代码的淬炼下,TDengine 从 1.6 走过 2.0,终于走到如今的 3.0 时代。 自 2022 年下旬发布以来,经过我们不断地打磨优化…...

【目标检测】大图包括标签切分,并转换成txt格式
前言 遥感图像比较大,通常需要切分成小块再进行训练,之前写过一篇关于大图裁切和拼接的文章【目标检测】图像裁剪/标签可视化/图像拼接处理脚本,不过当时的工作流是先将大图切分成小图,再在小图上进行标注,于是就不考…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

零基础在实践中学习网络安全-皮卡丘靶场(第九期-Unsafe Fileupload模块)(yakit方式)
本期内容并不是很难,相信大家会学的很愉快,当然对于有后端基础的朋友来说,本期内容更加容易了解,当然没有基础的也别担心,本期内容会详细解释有关内容 本期用到的软件:yakit(因为经过之前好多期…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

华为OD机试-最短木板长度-二分法(A卷,100分)
此题是一个最大化最小值的典型例题, 因为搜索范围是有界的,上界最大木板长度补充的全部木料长度,下界最小木板长度; 即left0,right10^6; 我们可以设置一个候选值x(mid),将木板的长度全部都补充到x,如果成功…...