JVM的内存模型
一、JVM的内存模型
1.1、目标
内存模型是用来描述JVM内部的内存结构和内存管理的模型。它定义了JVM在运行Java程序时所需要的各种内存区域,以及每个内存区域的作用和特点。
1.2、结构划分
1.2.1、栈
每个线程在执行Java方法时会创建一个栈帧(Stack Frame),用于存储局部变量、操作数栈、方法返回地址等信息。Java栈的大小可以在启动时通过参数来设置。
栈帧的详细的解释:栈的讲解

栈示意图
栈顶帧表示的是当前正在执行的方法,栈帧是方法运行的基本结构。在执行引擎运行时,所有指令都只能针对当前栈帧进行操作。
虚拟机栈规定了两种异常状况:
如果线程请求的栈深度大于虚拟机所允许的深度,将抛出 StackOverflowError 异常;
如果虚拟机栈可以动态扩展(当前大部分的 Java 虚拟机都可动态扩展),如果扩展时无法申请到足够的内存,就会抛出 OutOfMemoryError 异常。
1.2.2、本地方法栈
本地方法栈(Native Method Stack)与虚拟机栈所发挥的作用是非常相似的,它们之间的区别不过是虚拟机栈为虚拟机执行 Java 方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。Sun HotSpot 虚拟机直接就把本地方法栈和虚拟机栈合二为一。
与虚拟机栈一样,本地方法栈区域也会抛出 StackOverflowError 和 OutOfMemoryError 异常。1.2.3、堆
堆是占内存最大,管理最为复杂的物理区域。堆面向线程共享的,所以线程间通信和线程安全都是在堆内发生的。
注意将堆、对象头、线程并发关联在一起。
java虚拟机规范对这块的描述是:所有对象实例及数组都要在堆上分配内存,但随着JIT编译器的发展和逃逸分析技术的成熟,这个说法也不是那么绝对,但是大多数情况都是这样的。
即时编译器:可以把把Java的字节码,包括需要被解释的指令的程序)转换成可以直接发送给处理器的指令的程序)逃逸分析:通过逃逸分析来决定某些实例或者变量是否要在堆中进行分配,如果开启了逃逸分析,即可将这些变量直接在栈上进行分配,而非堆上进行分配。这些变量的指针可以被全局所引用,或者其其它线程所引用。
逃逸技术理论分析
如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出 OutOfMemoryError 异常。常用堆内存分配参数:
-Xms 设置java应用程序启动时的初始堆大小。
-Xmx 设置java应用程序能获得的最大堆大小。
-Xss 设置线程栈的大小。
-XX:PermSize 设置永久区的初始值
-XX:MaxPermSize 设置最大的永久区大小
-XX:MinHeapFreeRatio 设置堆空间最小空闲比例。
-XX:MaxHeapFreeRatio 设置对空间最大空闲比例。
-XX:SurvivorRatio 新生代中eden区与survivor区的比例。
1.2.4、方法区
方法区同堆一样,是所有线程共享的内存区域,为了区分堆,又被称为非堆。
java虚拟机对方法区比较宽松,除了跟堆一样可以不存在连续的内存空间,定义空间和可扩展空间,还可以选择不实现垃圾收集。
JDK8 之前,Hotspot 中方法区的实现是永久代(Perm),JDK8 开始使用元空间(Metaspace),以前永久代所有内容的字符串常量移至堆内存,其他内容移至元空间,元空间直接在本地内存分配。
不过要谨防,永久代或元空间不够用引起的fullgc现象,一般默认是可变大小的,不够用会申请更大的空间,且伴随fullgc。
1.2.5、运行时常量池
运行时常量池(Runtime Constant Pool)是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池(Constant Pool Table),用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。 一般来说,除了保存 Class 文件中描述的符号引用外,还会把翻译出来的直接引用也存储在运行时常量池中。 运行时常量池相对于 Class 文件常量池的另外一个重要特征是具备动态性,Java 语言并不要求常量一定只有编译期才能产生,也就是并非预置入 Class 文件中常量池的内容才能进入方法区运行时常量池,运行期间也可能将新的常量放入池中,这种特性被开发人员利用得比较多的便是 String 类的 intern() 方法。 既然运行时常量池是方法区的一部分,自然受到方法区内存的限制,当常量池无法再申请到内存时会抛出 OutOfMemoryError 异常。
1.2.6、直接内存
直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是 Java 虚拟机规范中定义的内存区域。
在 JDK 1.4 中新加入了 NIO,引入了一种基于通道(Channel)与缓冲区(Buffer)的 I/O 方式,它可以使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆中来回复制数据。
显然,本机直接内存的分配不会受到 Java 堆大小的限制,但是,既然是内存,肯定还是会受到本机总内存(包括 RAM 以及 SWAP 区或者分页文件)大小以及处理器寻址空间的限制。服务器管理员在配置虚拟机参数时,会根据实际内存设置 -Xmx 等参数信息,但经常忽略直接内存,使得各个内存区域总和大于物理内存限制(包括物理的和操作系统级的限制),从而导致动态扩展时出现 OutOfMemoryError 异常。
二、GC
2.1、为什么需要GC
JVM虚拟机具有平台无关性和随处运行的特性,且不需要手动的去管理内存分配和清除。一切都交由虚拟机管理内存,防止内存泄漏和内存溢出。
从三个方面来看如何进行内存管理:
哪些内存要回收
什么时候回收
怎么回收
2.1.1、哪些内存要回收
java内存模型中分为五大区域已经有所了解。我们知道程序计数器、虚拟机栈、本地方法栈,由线程而生,随线程而灭,其中栈中的栈帧随着方法的进入顺序的执行的入栈和出栈的操作,一个栈帧需要分配多少内存取决于具体的虚拟机实现并且在编译期间即确定下来【忽略JIT编译器做的优化,基本当成编译期间可知】,当方法或线程执行完毕后,内存就随着回收,因此无需关心。
而Java堆、方法区则不一样。方法区存放着类加载信息,但是一个接口中多个实现类需要的内存可能不太一样,一个方法中多个分支需要的内存也可能不一样【只有在运行期间才可知道这个方法创建了哪些对象没需要多少内存】,这部分内存的分配和回收都是动态的,gc关注的也正是这部分的内存。
2.1.2、哪些情况下发生内存泄漏
长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄漏,尽管短生命周期对象已经不再需要,但是因为长生命周期持有它的引用而导致不能被回收,这就是Java中内存泄漏的发生场景。具体主要有如下几大类:
2.1.2.1、静态集合类
像HashMap、Vector等的使用最容易出现内存泄露,这些静态变量的生命周期和应用程序一致,他们所引用的所有的对象Object也不能被释放,因为他们也将一直被Vector等引用着。
2.1.2.2、各种连接
比如数据库连接(dataSourse.getConnection()),网络连接(socket)和io连接,除非其显式的调用了其close()方法将其连接关闭,否则是不会自动被GC回收的。对于Resultset 和Statement 对象可以不进行显式回收,但Connection一定要显式回收,因为Connection 在任何时候都无法自动回收,而Connection一旦回收,Resultset 和Statement 对象就会立即为NULL。但是如果使用连接池,情况就不一样了,除了要显式地关闭连接,还必须显式地关闭Resultset Statement 对象(关闭其中一个,另外一个也会关闭),否则就会造成大量的Statement 对象无法释放,从而引起内存泄漏。这种情况下一般都会在try里面去的连接,在finally里面释放连接。
7.2、对象存活
对象被确定回收前要确定对象是否还存活:引用计数法与可达性分析算法。
7.2.1、引用计数法
引用计数法的逻辑是:在堆中存储对象时,在对象头处维护一个counter计数器,如果一个对象增加了一个引用与之相连,则将counter++。如果一个引用关系失效则counter–。如果一个对象的counter变为0,则说明该对象已经被废弃,不处于存活状态。
这种方式统计对象是否存活存在着问题:JDK从1.2开始增加了多种引用方式:软引用、弱引用、虚引用,且在不同引用情况下程序应进行不同的操作。如果我们只采用一个引用计数法来计数无法准确的区分这么多种引用的情况。
引用计数法无法解决多种类型引用的问题。但这并不是致命的,因为我们可以通过增加逻辑区分四种引用情况,虽然麻烦一些但还算是引用计数法的变体,真正让引用计数法彻底报废的下面的情况。
如果一个对象A持有对象B,而对象B也持有一个对象A,那发生了类似操作系统中死锁的循环持有,这种情况下A与B的counter恒大于1,会使得GC永远无法回收这两个对象。
7.2.2、可达性分析
在主流的商用程序语言中(Java和C#),都是使用可达性分析算法判断对象是否存活的。这个算法的基本思路就是通过一系列名为GC Roots的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连时,则证明此对象是不可用的,下图对象object5, object6, object7虽然有互相判断,但它们到GC Roots是不可达的,所以它们将会判定为是可回收对象。
那么那些点可以作为GC Roots呢?
虚拟机栈(栈桢中的本地变量表)中的引用的对象
方法区中的类静态属性引用的对象
方法区中的常量引用的对象
本地方法栈中JNI(Native方法)的引用的对象
可达性分析算法实现
即使可达性算法中不可达的对象,也不是一定要马上被回收,还有可能被抢救一下。网上例子很多,基本上和深入理解JVM一书讲的一样对象的生存还是死亡。
7.3 垃圾的收集算法
可达性分析算法帮我们解决了哪些对象可以回收的问题,垃圾收集算法则关心怎么回收。
7.3.1 标记-清除算法
分为标记和清除两个阶段:
首先,标记处所有需要回收的对象,一般扫描GC Roots,找得到的对象在对象头中记录是否被引用
最后,标记完成后统一回收所有未被标记的对象
标记-清除算法是最基础的收集算法,其它的收集算法都是基于这种思路并对其不足进行改进而得到的。
标记-清除算法存在一些核心问题:
效率问题:标记和清除两个阶段的效率都不高,因为这两个阶段都需要遍历内存中的对象,很多时候内存中的对象实例数量是非常庞大的,这无疑很耗费时间,而且GC时需要停止应用程序,这会导致非常差的用户体验
空间问题:标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后再程序运行过程中需要分配较大对象时,无法找到足够的连续内存二不得不提前触发另一次垃圾收集动作
7.3.2 复制算法
为了解决标记-清除效率问题,复制收集算法出现了,他将可用的内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块内存用完了,就将还存活的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
复制算法存在的一些核心问题:
实现成本:复制算法的代价是将内存缩小为原来的一半,代价太高
效率问题:如果对象的存活率很高,极端一点的情况假设对象存活率为100%,那么我们需要将所有存活的对象复制一遍,耗费的时间代价也是不可忽视的。用法:存活区采用这种算法,是因为新生代中的对象98%是“朝生夕死”,所以并不需要按照1:1的比例来划分内存空间,而是将内存分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中的一块Survivor。当回收时,将Eden和Survivor中还存活的对象一次性的复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。HotSpot虚拟机默认Eden和Survivor的大小比例是8:1,也就是每次新生代中可用内存空间为整个新生代容量的90%,只有10%的内存会被“浪费”。不能保证每次回收都只有不多于10%的对象存活,当Survivor空间不够时,需要依赖老年代进行分配担保(Handle Promotion)。
7.3.3、标记-整理算法
复制算法在对象存活率较高时要进行较多的复制操作,效率会变得很低,更关键的是,如果不想浪费50%的内存空间,就需要有额外的内存空间进行分配担保,以应对内存中对象100%存活的极端情况,因此,在老年代中由于对象的存活率非常高,复制算法就不合适了。根据老年代的特点,高人们提出了另一种算法:标记/整理算法。从名字上看,这种算法与标记/清除算法很像,事实上,标记/整理算法的标记过程任然与标记/清除算法一样,但后续步骤不是直接对可回收对象进行回收,而是让所有存活的对象都向一端移动,然后直接清理掉端边线以外的内存。
上述三种回收算法对比:
效率:复制算法 > 标记/整理算法 > 标记/清除算法(标记/清除算法有内存碎片问题,给大对象分配内存时可能会触发新一轮垃圾回收)
内存整齐率:复制算法 = 标记/整理算法 > 标记/清除算法
内存利用率:标记/整理算法 = 标记/清除算法 > 复制算法
7.3.4、分代算法
当前商业虚拟机都采用分代收集算法,它结合了前几种算法的优点,将算法组合使用进行垃圾回收,与其说它是一种新的算法,不如说它是对前几种算法的实际应用。分代收集算法的思想是按对象的存活周期不同将内存划分为几块,一般是把Java堆分为新生代和老年代(还有一个永久代,是HotSpot特有的实现,其他的虚拟机实现没有这一概念,永久代的收集效果很差,一般很少对永久代进行垃圾回收),这样就可以根据各个年代的特点采用最合适的收集算法。
新生代:朝生夕灭,存活时间很短
老年代:经过多次Minor GC而存活下来,存活周期长
在新生代中每次垃圾回收都发现有大量的对象死去,只有少量存活,因此采用复制算法回收新生代,只需要付出少量对象的复制成本就可以完成收集;而老年代中对象的存活率高,不适合采用复制算法,而且如果老年代采用复制算法,它是没有额外的空间进行分配担保的,因此必须使用标记/清理算法或者标记/整理算法来进行回收。 总结一下就是,分代收集算法的原理是采用复制算法来收集新生代,采用标记/清理算法或者标记/整理算法收集老年代。 以上内容介绍了几种收集算法的原理、优缺点以及使用场景,它们的共同点是:当GC线程启动时(即进行垃圾收集),应用程序都要暂停(Stop The World)。理解了这些知识,为我们研究垃圾收集器的运行原理打下了基础。
7.3.5、对象移动
无论是复制算法、标记-整理算法都会对对象的内存地址进行改动,我们从上面了解到对象的访问形式有:句柄池和直接访问;而我们用到的就是直接访问,所以对象的移动就要考虑到移动后的对象如何被找到的问题。
对象头Mark Word用于存储对象的信息,。 在 GC 时,如果一个对象被拷贝(或移动)了,那么该对象(被拷贝或被移动的对象)头中 mark word 的 forwarding pointer 就会指向拷贝后的对象的地址。怎么理解这句话:比如你知道你朋友的地址的A,你按照地址A去找你朋友,到了A之后发现一个纸条指向了地址B,于是你到了地址B找到了你的朋友。
7.3.5.1、YGC对象拷贝
首先从 GC Roots 和 Old -> Young 的 Card Table(即存储了老年代对象与新生代对象之间的引用关系)出发,扫描追踪整个新生代的对象关系图。注意,在扫描过程中如果碰到指向老年代对象的引用,则停止这一路径的扫描。同时每扫描到一个对象,如果它是第一次被标记的话,我们就会将其拷贝到 survivor 区,或者晋升到老年代,并且在原对象位置的 mark word 域填上它的新地址 forwarding pointer。这样,如果原对象同时被两个以上的 reference 指向,那么在追踪过程中,别的 reference 还是有机会碰到此对象的原位置,然后发现它已经被标记过了,所以只需要通过 mark word 域的 forwarding pointer 更新 reference 值即可。
使用这类算法的有 Serial Young GC(即DefNew)、Parallel Young GC、ParNew,以及 G1 GC 的 Young GC & Mixed GC。 只需要一次遍历就可以完成对对象的拷贝和 reference 的更新。
7.3.5.1、FULLGC对象拷贝
标记:
直接从 GC Roots 出发,扫面一遍整个堆(有时可以加上 metaspace),找到所有活的对象。
计算新地址:
既然已知所有活的对象,那么就能够准确计算出它们在 compaction 后的新地址,然后将计算好的新地址保存到 mark word 域中。
更新 reference:
更新所有活对像中指向其他对象的 reference 的值,让它们指向步骤 2 中计算好的新地址(从 mark word中读取)。
复制对象到新地址:
将对象复制到步骤 2 计算的新地址。
使用这类算法的有 Serial Old GC、PS MarkSweep GC、Parallel Old GC、Full GC for CMS 和 Full GC for G1 GC。
三、垃圾收集器
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。Java虚拟机规范中对垃圾收集器应该如何实现并没有任何规定,因此不同的厂商、版本的虚拟机所提供的垃圾收集器都可能会有很大差别,并且一般都会提供参数供用户根据自己的应用特点和要求组合出各个年代所使用的收集器。接下来讨论的收集器基于JDK1.7 Update 14 之后的HotSpot虚拟机(在此版本中正式提供了商用的G1收集器,之前G1仍处于实验状态),该虚拟机包含的所有收集器如下图所示:
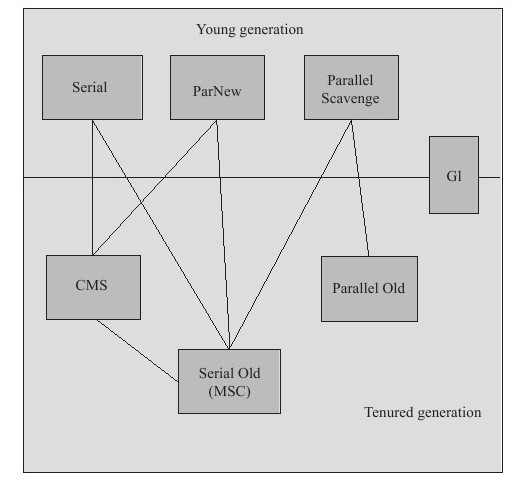
垃圾收集器搭配示意图
学习垃圾收集器前,需要提前准备一些小知识点。
并行(Parallel):指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行),用户程序在继续运行。而垃圾收集程序运行在另一个CPU上。
吞吐量(Throughput):吞吐量就是CPU用于运行用户代码的时间与CPU总消耗时间的比值,即 :
吞吐量 = 运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间)假设虚拟机总共运行了100分钟,其中垃圾收集花掉1分钟,那吞吐量就是99%。
新生代GC(Minor GC):指发生在新生代的垃圾收集动作,因为Java对象大多都具备朝生夕灭的特性,所以Minor GC非常频繁,一般回收速度也比较快。
老年代GC(Major GC / Full GC):指发生在老年代的GC,出现了Major GC,经常会伴随至少一次的Minor GC(但非绝对的,在Parallel Scavenge收集器的收集策略里就有直接进行Major GC的策略选择过程)。
Major GC的速度一般会比Minor GC慢10倍以上。
3.1、新生代收集器
8.1.1、Serial收集器
Serial(串行)收集器是最基本、发展历史最悠久的收集器,它是采用复制算法的新生代收集器,曾经(JDK 1.3.1之前)是虚拟机新生代收集的唯一选择。它是一个单线程收集器,只会使用一个CPU或一条收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集时,必须暂停其他所有的工作线程,直至Serial收集器收集结束为止(“Stop The World”)。这项工作是由虚拟机在后台自动发起和自动完成的,在用户不可见的情况下把用户正常工作的线程全部停掉,这对很多应用来说是难以接收的。
下图展示了Serial 收集器(老年代采用Serial Old收集器)的运行过程:
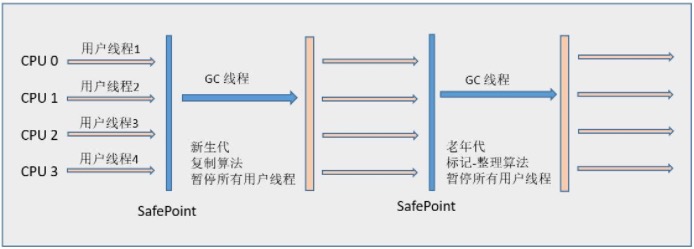
Serial Old运行图
为了消除或减少工作线程因内存回收而导致的停顿,HotSpot虚拟机开发团队在JDK 1.3之后的Java发展历程中研发出了各种其他的优秀收集器,这些将在稍后介绍。但是这些收集器的诞生并不意味着Serial收集器已经“老而无用”,实际上到现在为止,它依然是HotSpot虚拟机运行在Client模式下的默认的新生代收集器。它也有着优于其他收集器的地方:简单而高效(与其他收集器的单线程相比),对于限定单个CPU的环境来说,Serial收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得更高的单线程收集效率
在用户的桌面应用场景中,分配给虚拟机管理的内存一般不会很大,收集几十兆甚至一两百兆的新生代(仅仅是新生代使用的内存,桌面应用基本不会再大了),停顿时间完全可以控制在几十毫秒最多一百毫秒以内,只要不频繁发生,这点停顿时间可以接收。所以,Serial收集器对于运行在Client模式下的虚拟机来说是一个很好的选择。
3.1.2、ParNew 收集器
ParNew收集器就是Serial收集器的多线程版本,它也是一个新生代收集器。除了使用多线程进行垃圾收集外,其余行为包括Serial收集器可用的所有控制参数、收集算法(复制算法)、Stop The World、对象分配规则、回收策略等与Serial收集器完全相同,两者共用了相当多的代码。
ParNew收集器的工作过程如下图(老年代采用Serial Old收集器):
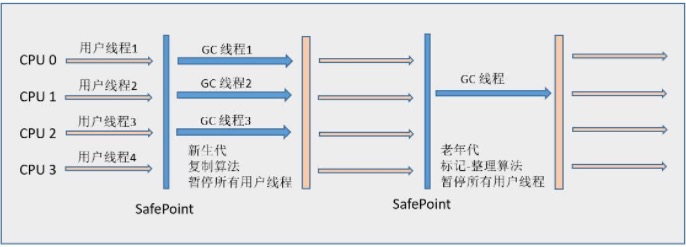
ParNew运行图
ParNew收集器除了使用多线程收集外,其他与Serial收集器相比并无太多创新之处,但它却是许多运行在Server模式下的虚拟机中首选的新生代收集器,其中有一个与性能无关的重要原因是,除了Serial收集器外,目前只有它能和CMS收集器(Concurrent Mark Sweep)配合工作,CMS收集器是JDK 1.5推出的一个具有划时代意义的收集器,具体内容将在稍后进行介绍。
ParNew 收集器在单CPU的环境中绝对不会有比Serial收集器有更好的效果,甚至由于存在线程交互的开销,该收集器在通过超线程技术实现的两个CPU的环境中都不能百分之百地保证可以超越。在多CPU环境下,随着CPU的数量增加,它对于GC时系统资源的有效利用是很有好处的。它默认开启的收集线程数与CPU的数量相同,在CPU非常多的情况下可使用**-XX:ParallerGCThreads**参数设置。
3.1.3、Parallel Scavenge 收集器
Parallel Scavenge收集器也是一个并行的多线程新生代收集器,它也使用复制算法。Parallel Scavenge收集器的特点是它的关注点与其他收集器不同,CMS等收集器的关注点是尽可能缩短垃圾收集时用户线程的停顿时间,而Parallel Scavenge收集器的目标是达到一个可控制的吞吐量(Throughput)。
停顿时间越短就越适合需要与用户交互的程序,良好的响应速度能提升用户体验。而高吞吐量则可以高效率地利用CPU时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太多交互的任务。
Parallel Scavenge收集器除了会显而易见地提供可以精确控制吞吐量的参数,还提供了一个参数**-XX:+UseAdaptiveSizePolicy**,这是一个开关参数,打开参数后,就不需要手工指定新生代的大小(-Xmn)、Eden和Survivor区的比例(-XX:SurvivorRatio)、晋升老年代对象年龄(-XX:PretenureSizeThreshold)等细节参数了,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量,这种方式称为GC自适应的调节策略(GC Ergonomics)。自适应调节策略也是Parallel Scavenge收集器与ParNew收集器的一个重要区别。
另外值得注意的一点是,Parallel Scavenge收集器无法与CMS收集器配合使用,所以在JDK 1.6推出Parallel Old之前,如果新生代选择Parallel Scavenge收集器,老年代只有Serial Old收集器能与之配合使用。
3.2 老年代收集器
3.2.1、Serial Old收集器
Serial Old 是 Serial收集器的老年代版本,它同样是一个单线程收集器,使用**“标记-整理”(Mark-Compact)**算法。
此收集器的主要意义也是在于给Client模式下的虚拟机使用。如果在Server模式下,它还有两大用途:
- 在JDK1.5 以及之前版本(Parallel Old诞生以前)中与Parallel Scavenge收集器搭配使用。
- 作为CMS收集器的后备预案,在并发收集发生Concurrent Mode Failure时使用。
它的工作流程与Serial收集器相同,这里再次给出Serial/Serial Old配合使用的工作流程图:
Serial Old示意图
3.2.2、Parallel Old收集器
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和**“标记-整理”算法。前面已经提到过,这个收集器是在JDK 1.6中才开始提供的,在此之前,如果新生代选择了Parallel Scavenge收集器,老年代除了Serial Old以外别无选择,所以在Parallel Old诞生以后,“吞吐量优先”收集器终于有了比较名副其实的应用组合,在注重吞吐量以及CPU资源敏感**的场合,都可以优先考虑Parallel Scavenge加Parallel Old收集器。Parallel Old收集器的工作流程与Parallel Scavenge相同。
这里给出Parallel Scavenge/Parallel Old收集器配合使用的流程图:

Parrael Old示意图
8.2.3、CMS收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,它非常符合那些集中在互联网站或者B/S系统的服务端上的Java应用,这些应用都非常重视服务的响应速度。从名字上(“Mark Sweep”)就可以看出它是基于**“标记-清除”**算法实现的。
CMS收集器工作的整个流程分为以下4个步骤:
1、初始标记(CMS initial mark):仅仅只是标记一下GC Roots能直接关联到的对象,速度很快,需要“Stop The World”。
2、并发标记(CMS concurrent mark):进行GC Roots Tracing的过程,在整个过程中耗时最长。
3、重新标记(CMS remark):为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。此阶段也需要“Stop The World”。
4、并发清除(CMS concurrent sweep)
由于整个过程中耗时最长的并发标记和并发清除过程收集器线程都可以与用户线程一起工作,所以,从总体上来说,CMS收集器的内存回收过程是与用户线程一起并发执行的。通过下图可以比较清楚地看到CMS收集器的运作步骤中并发和需要停顿的时间:
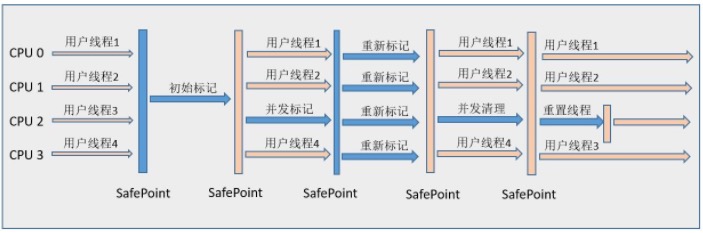
Cms示意图
8.2.3.1、优点
并发收集、低停顿,因此CMS收集器也被称为并发低停顿收集器(Concurrent Low Pause Collector)。
缺点
1、对CPU资源非常敏感 其实,面向并发设计的程序都对CPU资源比较敏感。在并发阶段,它虽然不会导致用户线程停顿,但会因为占用了一部分线程(或者说CPU资源)而导致应用程序变慢,总吞吐量会降低。CMS默认启动的回收线程数是(CPU数量+3)/4,也就是当CPU在4个以上时,并发回收时垃圾收集线程不少于25%的CPU资源,并且随着CPU数量的增加而下降。但是当CPU不足4个时(比如2个),CMS对用户程序的影响就可能变得很大,如果本来CPU负载就比较大,还要分出一半的运算能力去执行收集器线程,就可能导致用户程序的执行速度忽然降低了50%,其实也让人无法接受。
2、无法处理浮动垃圾(Floating Garbage) 可能出现“Concurrent Mode Failure”失败而导致另一次Full GC的产生。由于CMS并发清理阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生。这一部分垃圾出现在标记过程之后,CMS无法再当次收集中处理掉它们,只好留待下一次GC时再清理掉。这一部分垃圾就被称为“浮动垃圾”。也是由于在垃圾收集阶段用户线程还需要运行,那也就还需要预留有足够的内存空间给用户线程使用,因此CMS收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,需要预留一部分空间提供并发收集时的程序运作使用。
3、标记-清除算法导致的空间碎片 CMS是一款基于“标记-清除”算法实现的收集器,这意味着收集结束时会有大量空间碎片产生。空间碎片过多时,将会给大对象分配带来很大麻烦,往往出现老年代空间剩余,但无法找到足够大连续空间来分配当前对象。
3.2.4、G1垃圾收集器
CMS&G1垃圾收集器性能对比
8.3 示例
示例本地环境各不一样,适当调整。
-Xms41m -Xmx41m -Xmn10m -XX:+UseParallelGC -XX:SurvivorRatio=8 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps/*** 写一段程序,让其运行时的表现为触发5次ygc,然后3次fgc,然后3次ygc,然后1次fgc,请给出代码以及启动参数。* VM设置:-Xms40m -Xmx40m -Xmn10m -XX:+UseParallelGC -XX:SurvivorRatio=8 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps* -Xms40m 堆最小值* -Xmx40m 堆最大值* -Xmn10m 新生代大小大小(推荐 3/8)* -XX:+UseParallelGC 使用并行收集器** @author chenhailong* <p>* 初始化时:835k(堆内存)* 第一次add:3907k* 第二次add:6979k* 第三次add: eden + survivor1 = 9216k < 6979k + 3072k,区空间不够,开始 YGC* YGC 6979k -> 416k(9216k) 表示年轻代 GC前为6979,GC后426k.年轻代总大小9216k* Created by xxxx.xxxx*/
public class FiveYgcThreeFgc {private static final int ONE_MB_UNIT = 1024 * 1024;public static void main(String[] args) {System.out.println("初始化eden " + "10m");System.out.println("初始化suvvior " + "2m");System.out.println("初始化old " + "30m");// 执行完年轻代3M,老年代 30MList<byte[]> byteList = new ArrayList<byte[]>();for (int i = 0; i < 11; i++) {if(i == 10) {System.out.println("第1次FullGC");}byteList.add(new byte[3 * ONE_MB_UNIT]);}// 老年代腾出6M空间,执行第二次FullGC// 执行完之后,老年代满了,年轻代6Mfor(int k = 0; k < 1; k++) {byteList.remove(0);}System.out.println("第2次FullGC");byteList.add(new byte[6 * ONE_MB_UNIT]);// 老年代再腾出6M,执行第三次FullGC// 执行完之后,老年代12M,年轻代3Mfor(int k = 0; k < 8; k++) {byteList.remove(0);}System.out.println("第3次FullGC");byteList.add(new byte[3 * ONE_MB_UNIT]);System.out.println("第二轮");for (int i = 0; i < 6; i++) {System.out.println("oooo = [" + i + "]");byteList.add(new byte[3 * ONE_MB_UNIT]);}}
}
END
文章类型
暂无
知识体系
Java算法存储编译器缓存
文章标签
Javajvm
打赏作者
有收获?用积分鼓励一下作者吧
已有8人点赞
轻踩一下
文章评论 (5)本文笔记
0/1000
发表评论
全部评论最新在前

玄鱼
#5
2020-06-18
非常棒

淮宁
#4
2020-06-14
图挂啦,能修复下图片吗

凯锋
#3
2020-04-14
给大佬点赞

风回
#2
2020-04-07
打call打call

何遇
#1
2020-04-02
图挂啦

相关阅读
应用机器内存过高的排查&优化
一、问题背景一句话背景: 我们的tmsx-practice应用sunfire总是频繁告警【内存利用率高】的问题。(告警阈值是90%)之前:示例其中一台机器:33.8.16.71 可以看到,从2023-3-16 19:00:00 到 2023-03-21 11:00:00 差不多4-5天的时间,机器内存利用率从发布重启之后的71.96% 升高到90.30% ,达到了sunfire设置的告警阈值,升高了差不多20%。之后:经过排查优化之后的结果:二、排查思路然后内心就有很多疑问❓❓1、为什么应用重启之后,内存利用率怎么也这么高?71%, 都是什么在占用呢?2、为什么内存利用率一直持续性在增长
作者:南清发布于:菜鸟产品技术团队4月18日发布5月4日更新1380人浏览
CIF会员缓存机制
1 概述会员核心CIF是典型的读多写少的应用,为提升QPS,深度使用分布式缓存;结合LDC部署架构,对于G写C读和R写C读的客户数据,每个CZone缓存维护全量的数据,以支持大量上游应用的读数据请求。本文主要介绍最核心的缓存查询和缓存同步机制。1.1 基础概念本地缓存本地缓存是指在本地客户端的内存中缓存数据,相比较于请求服务端获取数据,访问本地内存中的数据更加高效。常用的如代码逻辑中使用的HashMap,或者缓存工具 guava cache。本地缓存速度更快,但是由于服务器内存空间限制,通常会限制key的数量和过期时间。本地缓存实际上是用空间换时间的策略,当内容更新时,本地缓存的更新会有一定的
作者:筱欣发布于:A大队2022-10-27发布1月16日更新676人浏览
只谈干货,不谈风月 (二): Bitmap-时间和空间兼得的大杀器
开篇 从2018年初加入蚂蚁的反洗钱技术团队,至今已有4年时间。在过去四年中,除了用java构建应用外,做得最多的就是和数据打交道了。反洗钱历来是一个重数据的业务,简单一点说就是通过对海量的数据分析,真实还原用户的交易意图,以及识别交易双方的真实身份,以便为后续的各种洗钱行为的判定提供佐证。在这个过程中,最简单的就是直接写ODPS SQL来支持各种数据分析,后来觉得SQL的表达力有限,又引入了SPARK以支持更多定制化的分析能力,到今天,反洗钱的离线可疑交易稽核链路已经形成了ODPS SQL和Spark双能力驱动的工作模式,在这个过程中,遇到过一些奇葩的问题,也总结和沉淀了很多数据处理的“奇技
作者:闻杉发布于:蚂蚁大安全技术团队2022-05-05发布2022-05-06更新3868人浏览
高性能的Java虚拟机实战
前言 JVM是Java语言的核心基石所在,它为Java提供了强大的跨平台能力,关于JVM的内部结构,想必您并不陌生,有大量的文章来介绍JVM的内部组成结构,本篇的重点不在于此,这里假定您对JVM的内部组成结构已经比较了解。 JVM为开发者提供了大量的参数配置选项,可以对JVM的性能进行控制,而如何用好这些参数,将JVM的性能高效的使用出来,这将是本篇的重点,下面,将从如下几个方面,介绍JVM的相关: Heap配置 新老生代配置 本地元空间配置 CodeCache与JIT GC ClassLoader 一、JVM Heap参数配置 JV
作者:陟谦发布于:JVM交流答疑2020-09-27发布2020-10-16更新1070人浏览
tair分布式锁最简实现经验
一、为什么需要用上分布式锁?分布式锁主要目的是为了在分布式系统的环境下,设立一个公共资源让不同机器的线程去抢占,抢占到资源的线程可以进行相应的逻辑处理,通过这样一个所有机器都能读取到的外部存储,来实现这些机器之间的并发控制,就是分布式锁。简单特性:1、一个方法在同一时间下只能被一个机器的一个线程执行2、高性能3、非阻塞4、无死锁做完了常规的分布式锁概念介绍后,直接进入实现!二、集团内tair的分布式锁的简易实现我们常用的tair中分为三种产品,mdb、ldb、rdbRDB:rdb的实现方式比较简单,直接使用RDB的jedisCluster.set即可实现。jedisCluster.set(lo
作者:钺泽2021-10-211131人浏览
MQ夺命连环11问
你们为什么使用mq?具体的使用场景是什么? mq的作用很简单,削峰填谷。以电商交易下单的场景来说,正向交易的过程可能涉及到创建订单、扣减库存、扣减活动预算、扣减积分等等。每个接口的耗时如果是100ms,那么理论上整个下单的链路就需要耗费400ms,这个时间显然是太长了。 如果这些操作全部同步处理的话,首先调用链路太长影响接口性能,其次分布式事务的问题很难处理,这时候像扣减预算和积分这种对实时一致性要求没有那么高的请求,完全就可以通过mq异步的方式去处理了。同时,考虑到异步带来的不一致的问题,我们可以通过job去重试保证接口调用成功,而且一般公司都会有核对的平台,比如下单成功但是未扣减积分的这
作者:欲瑜2021-03-045266人浏览
1 cpu和内存模型
1.1 硬件层面内存屏障
2 JVM内存模型
3 JVM内存模型和硬件内存模型的关系
4 JVM内存模型的演进
5 JAVA并发模型
5.1 并发的底层原理
5.2 对齐填充
5.3 对象访问定位
5.3.1 直接访问
5.3.2 句柄访问
6 JAVA内存模型
6.1 JAVA内存区域
6.1.1 程序计数器
6.1.2 栈
6.1.3 本地方法栈
6.1.4 堆
6.1.5 方法区
7 GC
7.1 为什么需要GC
7.1.1 哪些内存要回收
7.2 对象存活
7.2.1引用计数法
7.2.2可达性分析
7.3 垃圾的收集算法
7.3.1 标记-清除算法
7.3.2 复制算法
7.3.3 标记-整理算法
7.3.4 分代算法
7.3.5 对象移动
7.3.5.1 YGC对象拷贝
7.3.5.1 FULLGC对象拷贝
8 垃圾收集器
8.1 新生代收集器
8.1.1 Serial收集器
8.1.2 ParNew 收集器
8.1.3 Parallel Scavenge 收集器
8.2 老年代收集器
8.2.1 Serial Old收集器
8.2.2 Parallel Old收集器
8.2.3 CMS收集器
8.3 示例
BU/地域运营: @司环内容合作: @昧光产品建议: @半音团队圈/专业圈运营: @乐果
Powered byATA 爱獭技术协会 @ 淘天集团版权所有
划线
笔记
复制
1.2.3、程序计数器
用于存储当前线程执行的字节码指令的地址,保证线程切换后能够恢复到正确的执行位置。
1.2.4、方法区
存放类的元数据信息(如类的字段、方法信息)、常量池、静态变量等。方法区也是所有线程共享的。
1.2.5、直接内存(Direct Memory):
与JVM内存管理不同,直接内存是使用操作系统的内存来进行分配和管理,通常通过使用NIO库进行操作。直接内存的大小可以在启动时通过参数来设置。
以上是JVM内存模型的主要区域,不同的区域在内存分配和回收上有不同的特点和规则。了解JVM内存模型对于理解Java程序的内存使用和性能调优非常重要。
1.3、cpu和内存模型

提升CPU的利用效率;但是带来了主存的并发一致性问题;
1.4、解决方案
1.4.1、硬件层面内存屏障
1.cpu操作的数据直接更新到主内存,保证内存可见性;
2.屏蔽cpu指令管道化优化,屏蔽指令排序,执行按照期望顺序执行。1、CPU操作的数据直接更新到主内存,保证内存的可见性;
2、屏蔽CPU指令管道化优化,屏蔽指令排序,执行按照期望的顺序执行;
1、硬件层面:
- Store Memory Barrier(写屏障)
- Load Memory Barrier(读屏障)
2、软件层面:屏蔽多种操作系统的差异,统一由jvm规范实施具体的内存屏障 -
volatile
synchronized:内存屏障表现较弱,毕竟本身可以支持原子性、可见性和顺序性
1.5、内存模型
Q: 2. 谈谈GC,CMS的流程,新生代老生代分别用什么算法
0条回答
Q:3. 谈谈类加载器,类加载器有哪些,双亲委派最终是由父还是子加载
0条回答
Q: 4. 操作系统的悲观锁、乐观锁
0条回答
Q: 5. 数据库层面的悲观锁、乐观锁
1条回答
Q:6. 数据库事务讲一下
0条回答
Q: 7. Redis的持久化机制
0条回答
Q: 8. Redis如何实现高可用
0条回答
Q:9. 索引的类型,索引的底层实现原理
1条回答
Q:10. 谈谈消息队列
0条回答
Q: 11. HashMap底层实现,哈希冲突怎么解决的
0条回答
Q: 12. 各种排序算法讲一下
相关文章:
JVM的内存模型
一、JVM的内存模型 1.1、目标 内存模型是用来描述JVM内部的内存结构和内存管理的模型。它定义了JVM在运行Java程序时所需要的各种内存区域,以及每个内存区域的作用和特点。 1.2、结构划分 1.2.1、栈 每个线程在执行Java方法时会创建一个栈帧(Stack …...
)
数据采集项目之业务数据(三)
1. Maxwell框架 开发公司为Zendesk公司开源,用java编写的MySQL变更数据抓取软件。内部是通过监控MySQL的Binlog日志,并将变更数据以JSON格式发送到Kafka等流处理平台。 1.1 MySQL主从复制 主机每次变更数据都会生成对应的Binlog日志,从机可…...

vuedraggable影响点击事件的解决办法
在工作中有很多场景需要针对广告、商品、信息推广等进行一个排序,或者对展示的顺序做出调整,方便放用户第一眼看到自己感兴趣的信息,因此避免不了需要用到排序的插件,这里以vue为例子,采用的插件是vuedraggable,这个插件针对于排序的功能相对完善,官网地址:vuedraggable官网 但…...

Linux 中的 grep 命令
Linux 中的 grep 命令是一个强大的文本搜索工具,它允许用户在文件中查找指定的文本模式,并将匹配的行打印出来。grep 是“Global Regular Expression Print”的缩写,它使用正则表达式来进行文本搜索,因此具有强大的灵活性和功能。…...

阶段五-Day03-Ajax
一、JavaWeb中路径的说明 1. JavaWeb中的路径 在JavaWeb中, 路径分为相对路劲和绝对路径两种: 相对路径: ./ 表示当前目录 ../ 表示当前文件所在目录的上一级目录 绝对路径: 完整的路径名 2. 在JavaWeb中/的不同意义 /斜杠如果被浏览器解析,得到的是 协议本地ip端口号…...

EPOLL单线程版本 基于reactor 的 httpserver文件下载 支持多个客户端同时处理
之前写了一个httpserver的问价下载服务器 如果有多个客户端请求过来只能串行处理必须得等当前的操作完成之后才会处理 另外还存在 文件大的时候 会出错 处理不了 原因就是 sendfile是在一个while循环中处理的 当调用send失败返回-1之后 就 结束了 而一般来讲 se…...

uniapp实现微信小程序隐私协议组件封装
uniapp实现微信小程序隐私协议组件封装。 <template><view class"diygw-modal basic" v-if"showPrivacy" :class"showPrivacy?show:" style"z-index: 1000000"><view class"diygw-dialog diygw-dialog-modal bas…...
【Node.js】NPM 和 package.json
NPM npm 是 Node.js 的包管理工具,基于命令行,用于安装、升级、移除、管理依赖项。 常用命令: npm init:初始化一个新的 npm 项目,创建 package.json 文件。(括号里为默认值) description&am…...
周总结【java项目】
项目进度: 学习了JavaFX,下载了sceneBuilder辅助工具构建窗口(目前建立了登陆,注册,忘记密码的界面),然后是学习了MySQL的连接,现在的项目是刚连上数据库; 下一步&…...

《深度不确定条件下的决策:从理论到实践》PDF
制定未来计划时需要预测变化,尤其是制定长期计划或针对罕见事件的计划时。当这些变化存在高度不确定性的时候,这种预期就变得越来越困难。 今天给大家介绍的这本《深度不确定条件下的决策:从理论到实践》正是解决以上问题的良方。完整书籍文…...

【MySQL】表的基础增删改查
前面我们已经知道怎么来创建表了,接下来就来对创建的表进行一些基本操作。 这里先将上次创建的表删除掉: mysql> use test; Database changedmysql> show tables; ---------------- | Tables_in_test | ---------------- | student | -----…...
)
第11章 Redis(二)
11.11 Redis 哨兵机制和集群有什么区别 难度:★★★ 重点:★★ 白话解析 前面的题目都是Redis的原理,接下来就是实际使用的问题了,首先Redis为了保证高可用,在微服务场景下必须是部署集群的,而Redis的集群部署通常就两种方式:主从和Redis Cluster。 参考答案 1、主从…...

mybatis配置entity下不同文件夹同类型名称的多个类型时启动springboot项目出现TypeException源码分析
记录问题:当配置了 mybatis.type-aliases-packagecom.runjing.erp.entity 配置项时,如果entity文件夹下存在不同子文件夹下的同名类型时,mybatis初始化加载映射时会爆出org.apache.ibatis.type.TypeException: The alias TestDemo…...

淘宝商品评论数据分析接口,淘宝商品评论接口
淘宝商品评论数据分析接口可以通过淘宝开放平台API获取。 通过构建合理的请求URL,可以向淘宝服务器发起HTTP请求,获取商品评论数据。接口返回的数据一般为JSON格式,包含了商品的各种评价信息。 获取到商品评论数据后,可以对其进…...

RK3288 android7.1 修改双屏异触usb tp触摸方向
一,问题描述: android机器要求接两个屏(lvdsmipi)两个usb tp要实现双屏异触。由于mipi的方向和lvds方向转成一样的了。两个usb tp的方向在异显示的时候也要作用一样。这个时候要根据pid和vid修改触摸上报的数据。usb tp有通用的触…...
)
软考 系统架构设计师系列知识点之软件架构风格(8)
接前一篇文章:软考 系统架构设计师系列知识点之软件架构风格(7) 这个十一注定是一个不能放松、保持“紧”的十一。由于报名了全国计算机技术与软件专业技术资格(水平)考试,11月4号就要考试,因此…...

ubuntu安装ssh
安装 OpenSSH 服务器(如果尚未安装): apt-get update && apt-get upgrade -y sudo apt-get install -y openssh-server 检查 SSH 服务是否正在运行: sudo service ssh status 如果 SSH 服务未运行,请通过以…...
webpack不同环境下使用CSS分离插件mini-css-extract-plugin
1.背景描述 使用mini-css-extract-plugin插件来打包css文件(从css文件中提取css代码到单独的文件中,对css代码进行代码压缩等)。 本次采用三个配置文件: 公共配置文件:webpack.common.jsdev开发环境配置文件&#x…...
[MongoDB]-权限验证管理
[MongoDB]-权限验证管理 senge | 2023年9月 背景说明:现有两套MongoDB副本集群给开发人员使用时未开启认证。 产生影响:用户若输入账号以及密码则会进行校验,但用户可以在不输入用户名和密码的情况下也可直接登录。 倘若黑客借此进行攻击勒索…...
bootstrapjs开发环境搭建
Bootstrapjs是一个web前端页面应用开发框架,其提供功能丰富的JavaScript工具集以及用户界面元素或组件的样式集,本文主要描述bootstrapjs的开发环境搭建。 如上所示,使用nodejs运行时环境、使用npm包管理工具、使用npm初始化一个项目工程test…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...

day36-多路IO复用
一、基本概念 (服务器多客户端模型) 定义:单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力 作用:应用程序通常需要处理来自多条事件流中的事件,比如我现在用的电脑,需要同时处理键盘鼠标…...

python爬虫——气象数据爬取
一、导入库与全局配置 python 运行 import json import datetime import time import requests from sqlalchemy import create_engine import csv import pandas as pd作用: 引入数据解析、网络请求、时间处理、数据库操作等所需库。requests:发送 …...

SpringAI实战:ChatModel智能对话全解
一、引言:Spring AI 与 Chat Model 的核心价值 🚀 在 Java 生态中集成大模型能力,Spring AI 提供了高效的解决方案 🤖。其中 Chat Model 作为核心交互组件,通过标准化接口简化了与大语言模型(LLM࿰…...

如何配置一个sql server使得其它用户可以通过excel odbc获取数据
要让其他用户通过 Excel 使用 ODBC 连接到 SQL Server 获取数据,你需要完成以下配置步骤: ✅ 一、在 SQL Server 端配置(服务器设置) 1. 启用 TCP/IP 协议 打开 “SQL Server 配置管理器”。导航到:SQL Server 网络配…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...