数据采集项目之业务数据(三)
1. Maxwell框架
开发公司为Zendesk公司开源,用java编写的MySQL变更数据抓取软件。内部是通过监控MySQL的Binlog日志,并将变更数据以JSON格式发送到Kafka等流处理平台。
1.1 MySQL主从复制
主机每次变更数据都会生成对应的Binlog日志,从机可以通过IO流的方式将Binlog日志下载到本地,可以通过它创造和主机一样的环境或者作为热备。
1.2 安装Maxwell
- 解压改名
- 启动MySQL Binlog, vim /etc/my.cnf. 增加如下配置:
- binlog_format 日志类型的三种类型:
- 基于语句:主机执行了什么语句,在从机里同样执行一遍。如果使用了random语句,会导致主从不一致。但是量级比较低
- 基于行:主机被改动后,从机同步一份。不会有主从不一致的问题,但是量价比较大,需要将每行修改的数据都拿一份。
- 混合模式:一般基于语句,但是如果基于语句会导致前后结果产生差异,自动转成基于行。
- binlog_format 日志类型的三种类型:
#数据库id
server-id = 1
#启动binlog,该参数的值会作为binlog的文件名
log-bin=mysql-bin
#binlog类型,maxwell要求为row类型
binlog_format=row
#启用binlog的数据库,需根据实际情况作出修改
binlog-do-db=gmall
- 重启MySQL服务
- 创建Maxwell所需所需的数据库和用户,用来存储断点续传所需的数据。
CREATE DATABASE maxwell;
CREATE USER 'maxwell'@'%' IDENTIFIED BY 'maxwell';
GRANT ALL ON maxwell.* TO 'maxwell'@'%';//maxwell库的所有权限给maxwell
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';//其他库的查询、复制权限给maxwell
- 修改maxwell配置文件
cp 配置文件,将会复制某个文件并且可以改名。
producer=kafka
# 目标Kafka集群地址
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
#目标Kafka topic,可静态配置,例如:maxwell,也可动态配置,例如:%{database}_%{table}
kafka_topic=topic_db
# MySQL相关配置
host=hadoop102
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true# 过滤gmall中的z_log表数据,该表是日志数据的备份,无须采集
filter=exclude:gmall.z_log
# 指定数据按照主键分组进入Kafka不同分区,避免数据倾斜
producer_partition_by=primary_key
1.3 Maxwell的使用
- 启动zookeeper,kafka
- 启动maxwell,
bin/maxwell --config config.properties --daemon - 启动kafka消费者进程,用于消费maxwell添加到kafka的变更数据
- 启动数据生成jar包,查看消费者进程是否有新数据。
- 编写Maxwell启停脚本
#!/bin/bashMAXWELL_HOME=/opt/module/maxwellstatus_maxwell(){result=`ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | wc -l`return $result
}start_maxwell(){status_maxwellif [[ $? -lt 1 ]]; thenecho "启动Maxwell"$MAXWELL_HOME/bin/maxwell --config $MAXWELL_HOME/config.properties --daemonelseecho "Maxwell正在运行"fi
}stop_maxwell(){status_maxwellif [[ $? -gt 0 ]]; thenecho "停止Maxwell"ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | awk '{print $2}' | xargs kill -9elseecho "Maxwell未在运行"fi
}case $1 instart )start_maxwell;;stop )stop_maxwell;;restart )stop_maxwellstart_maxwell;;
esac
1.4 Bootstrap全量同步
Maxwell获取的数据都是后期变更的数据,但没有获取到数据库在开启Binlog日志之前的原始数据。
全量同步命令:/opt/module/maxwell/bin/maxwell-bootstrap --database gmall --table user_info --config /opt/module/maxwell/config.properties
2. 数仓数据同步策略
2.1 用户行为数据
数据源:Kafka
目的地:HDFS
传输方式采用Flume, 其中source为Kafka source, channel为Memmory channel, sink为HDFS sink。
根据官网查找相应参数:
- Kafka Source
- type = Kafka Source全类名
- kafka.bootstrap.servers 连接地址
- kafka.topics = topic_log
- batchSize: 批次大小
- batchDurationMillis: 批次间隔2s
- File Channel
- type: file
- dataDirs: 存储路径
- checkpointDir: 偏移量存储地址
- keep-alive: 管道满了后,生产者间隔多少秒再放数据
- HDFS Sink
- hdfs.rollInterval : 文件滚动,解决小文件问题,每隔多久滚动一次
- rollSize: 文件大小
- hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d, 文件存放路径
- hdfs.round = false, 不采用系统本地时间
#定义组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1#配置source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log#配置channel
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6#配置sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log
a1.sinks.k1.hdfs.round = false # 是否获取本地时间a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0#控制输出文件类型
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip#组装
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.2 零点漂移问题
在HDFS系统存放文件时是按照时间进行分区存放的,存放时查看的是header中的timestamp,但是由于数据传输过程中也需要一段时间,header中的时间并不是数据的实际产生时间,这个就是零点漂移问题。
解决办法:借助拦截器,修改header中的timestamp的值。编写拦截器代码,需要在IDEA中创建对应的项目并打包。
- 导入依赖,flume-ng-core和JSON解析依赖fastjson (1.2.62)
- 创建包gmall.interceptor
- 创建类TimeStampInterceptor, 继承Interceptor接口
- 实现intercept(Event event)和intercept(Event events)
- 使用fastjson来解析json文件,得到jsonObject对象,用来获取时间戳ts。将获取到的时间戳覆盖header中的timestamp, 如果数据格式错误会抛异常,使用try-catch来捕获它,并过滤掉该条数据。注意此处不能使用for循环来一边遍历,一边删除集合数据。
@Overridepublic Event intercept(Event event) {//1、获取header和body的数据Map<String, String> headers = event.getHeaders();String log = new String(event.getBody(), StandardCharsets.UTF_8);try {//2、将body的数据类型转成jsonObject类型(方便获取数据)JSONObject jsonObject = JSONObject.parseObject(log);//3、header中timestamp时间字段替换成日志生成的时间戳(解决数据漂移问题)String ts = jsonObject.getString("ts");headers.put("timestamp", ts);return event;} catch (Exception e) {e.printStackTrace();return null;}
@Override
public List<Event> intercept(List<Event> list) {Iterator<Event> iterator = list.iterator();while (iterator.hasNext()) {Event event = iterator.next();if (intercept(event) == null) {iterator.remove();//必须使用迭代器删除}}return list;
}
-
打包时注意要带上fastjson依赖,需要在maven中添加配置打包插件。依赖中有flume和fastjson,但在虚拟机上有flume,没有fastjson,所以需要排除flume。可以使用provided标签来排除让打包时排除依赖。
- compile:在单元测试、编译、运行三种方式都会使用compile表明的依赖;
- test:在单元测试才会使用test表明的依赖;
- provided:在编译才会使用test表明的依赖;
-
Flume配置文件中添加拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.TimestampInterceptor$Builder # 全类名建议在IDEA中复制,Builder也需要根据自己的代码函数名修改
- 重新生成数据,查看是否根据数据本身的时间戳存放到对应的HDFS分区文件中。
3. 业务数据同步
3.1 同步策略
- 全量同步:每天将所有数据同步一份,业务数据量小,优先考虑全量同步。
- 增量同步:每天只将新增和变化进行同步,业务数据量大,优先考虑增量同步。
3.2 数据同步工具
全量:DataX、Sqoop
增量:Maxwell、Canal
3.3 DataX
是一个数据同步工具,致力于实现包括关系型数据库HDFS、Hive、ODPS、HBase、MySQL等等数据源之间的互传。
- 架构= reader + framework + writer
- 运行流程
- job: 单个数据同步的作业,会启动一个进程。
- Task: 根据不同数据源的切分策略,一个Job会切分为多个Task,Task是DataX作业的最小单元,每个Task负责一部分,由一个线程执行。
- 调度策略:会根据系统资源设置并发度,并发度为线程同时执行的个数,任务会按照并发度一组一组执行。
3.4 DataX安装
- 下载解压DataX安装包
bin/datax.py job/job.json测试安装包是否完整- MySQL Reader配置文件的书写
- HDFS Writer配置文件的书写
- 执行datax命令
python /opt/module/datax/bin/datax.py -p"-Dtargetdir=/origin_data/gmall/db/activity_info_full/2022-06-08" /opt/module/datax/job/import/gmall.activity_info.json - 执行完后可以使用hadoop fs cat 路径名 | zcat,来查看压缩文件是否正确
相关文章:
)
数据采集项目之业务数据(三)
1. Maxwell框架 开发公司为Zendesk公司开源,用java编写的MySQL变更数据抓取软件。内部是通过监控MySQL的Binlog日志,并将变更数据以JSON格式发送到Kafka等流处理平台。 1.1 MySQL主从复制 主机每次变更数据都会生成对应的Binlog日志,从机可…...

vuedraggable影响点击事件的解决办法
在工作中有很多场景需要针对广告、商品、信息推广等进行一个排序,或者对展示的顺序做出调整,方便放用户第一眼看到自己感兴趣的信息,因此避免不了需要用到排序的插件,这里以vue为例子,采用的插件是vuedraggable,这个插件针对于排序的功能相对完善,官网地址:vuedraggable官网 但…...

Linux 中的 grep 命令
Linux 中的 grep 命令是一个强大的文本搜索工具,它允许用户在文件中查找指定的文本模式,并将匹配的行打印出来。grep 是“Global Regular Expression Print”的缩写,它使用正则表达式来进行文本搜索,因此具有强大的灵活性和功能。…...

阶段五-Day03-Ajax
一、JavaWeb中路径的说明 1. JavaWeb中的路径 在JavaWeb中, 路径分为相对路劲和绝对路径两种: 相对路径: ./ 表示当前目录 ../ 表示当前文件所在目录的上一级目录 绝对路径: 完整的路径名 2. 在JavaWeb中/的不同意义 /斜杠如果被浏览器解析,得到的是 协议本地ip端口号…...

EPOLL单线程版本 基于reactor 的 httpserver文件下载 支持多个客户端同时处理
之前写了一个httpserver的问价下载服务器 如果有多个客户端请求过来只能串行处理必须得等当前的操作完成之后才会处理 另外还存在 文件大的时候 会出错 处理不了 原因就是 sendfile是在一个while循环中处理的 当调用send失败返回-1之后 就 结束了 而一般来讲 se…...

uniapp实现微信小程序隐私协议组件封装
uniapp实现微信小程序隐私协议组件封装。 <template><view class"diygw-modal basic" v-if"showPrivacy" :class"showPrivacy?show:" style"z-index: 1000000"><view class"diygw-dialog diygw-dialog-modal bas…...
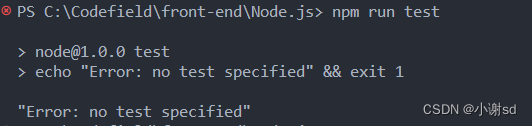
【Node.js】NPM 和 package.json
NPM npm 是 Node.js 的包管理工具,基于命令行,用于安装、升级、移除、管理依赖项。 常用命令: npm init:初始化一个新的 npm 项目,创建 package.json 文件。(括号里为默认值) description&am…...
周总结【java项目】
项目进度: 学习了JavaFX,下载了sceneBuilder辅助工具构建窗口(目前建立了登陆,注册,忘记密码的界面),然后是学习了MySQL的连接,现在的项目是刚连上数据库; 下一步&…...

《深度不确定条件下的决策:从理论到实践》PDF
制定未来计划时需要预测变化,尤其是制定长期计划或针对罕见事件的计划时。当这些变化存在高度不确定性的时候,这种预期就变得越来越困难。 今天给大家介绍的这本《深度不确定条件下的决策:从理论到实践》正是解决以上问题的良方。完整书籍文…...

【MySQL】表的基础增删改查
前面我们已经知道怎么来创建表了,接下来就来对创建的表进行一些基本操作。 这里先将上次创建的表删除掉: mysql> use test; Database changedmysql> show tables; ---------------- | Tables_in_test | ---------------- | student | -----…...
)
第11章 Redis(二)
11.11 Redis 哨兵机制和集群有什么区别 难度:★★★ 重点:★★ 白话解析 前面的题目都是Redis的原理,接下来就是实际使用的问题了,首先Redis为了保证高可用,在微服务场景下必须是部署集群的,而Redis的集群部署通常就两种方式:主从和Redis Cluster。 参考答案 1、主从…...

mybatis配置entity下不同文件夹同类型名称的多个类型时启动springboot项目出现TypeException源码分析
记录问题:当配置了 mybatis.type-aliases-packagecom.runjing.erp.entity 配置项时,如果entity文件夹下存在不同子文件夹下的同名类型时,mybatis初始化加载映射时会爆出org.apache.ibatis.type.TypeException: The alias TestDemo…...

淘宝商品评论数据分析接口,淘宝商品评论接口
淘宝商品评论数据分析接口可以通过淘宝开放平台API获取。 通过构建合理的请求URL,可以向淘宝服务器发起HTTP请求,获取商品评论数据。接口返回的数据一般为JSON格式,包含了商品的各种评价信息。 获取到商品评论数据后,可以对其进…...

RK3288 android7.1 修改双屏异触usb tp触摸方向
一,问题描述: android机器要求接两个屏(lvdsmipi)两个usb tp要实现双屏异触。由于mipi的方向和lvds方向转成一样的了。两个usb tp的方向在异显示的时候也要作用一样。这个时候要根据pid和vid修改触摸上报的数据。usb tp有通用的触…...
)
软考 系统架构设计师系列知识点之软件架构风格(8)
接前一篇文章:软考 系统架构设计师系列知识点之软件架构风格(7) 这个十一注定是一个不能放松、保持“紧”的十一。由于报名了全国计算机技术与软件专业技术资格(水平)考试,11月4号就要考试,因此…...

ubuntu安装ssh
安装 OpenSSH 服务器(如果尚未安装): apt-get update && apt-get upgrade -y sudo apt-get install -y openssh-server 检查 SSH 服务是否正在运行: sudo service ssh status 如果 SSH 服务未运行,请通过以…...
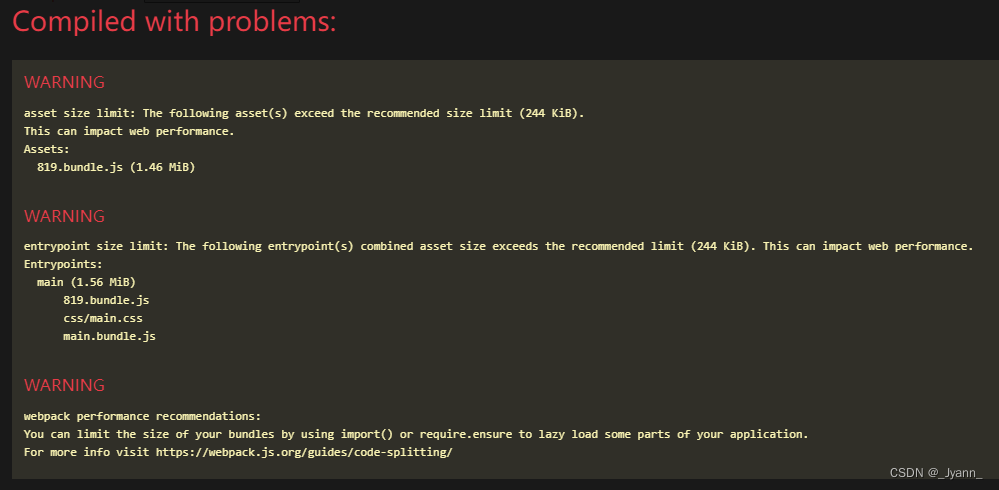
webpack不同环境下使用CSS分离插件mini-css-extract-plugin
1.背景描述 使用mini-css-extract-plugin插件来打包css文件(从css文件中提取css代码到单独的文件中,对css代码进行代码压缩等)。 本次采用三个配置文件: 公共配置文件:webpack.common.jsdev开发环境配置文件&#x…...
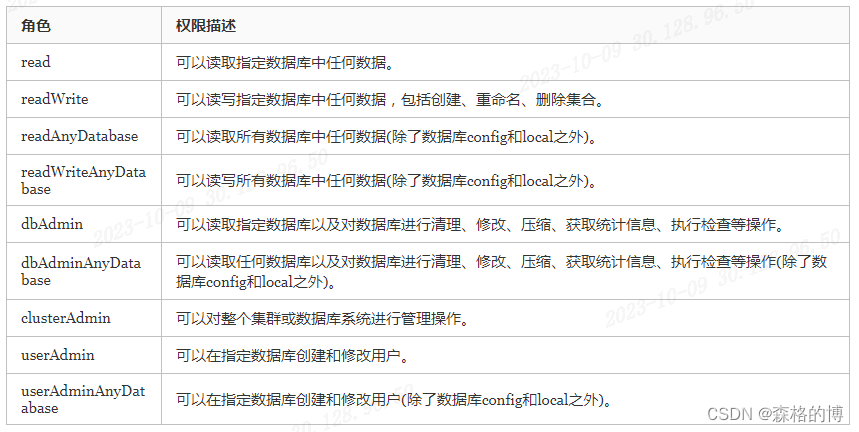
[MongoDB]-权限验证管理
[MongoDB]-权限验证管理 senge | 2023年9月 背景说明:现有两套MongoDB副本集群给开发人员使用时未开启认证。 产生影响:用户若输入账号以及密码则会进行校验,但用户可以在不输入用户名和密码的情况下也可直接登录。 倘若黑客借此进行攻击勒索…...
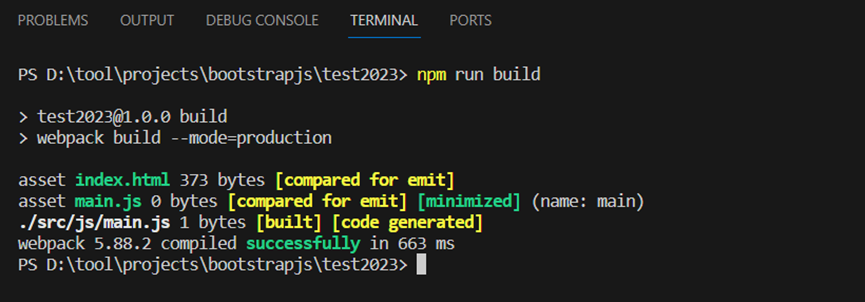
bootstrapjs开发环境搭建
Bootstrapjs是一个web前端页面应用开发框架,其提供功能丰富的JavaScript工具集以及用户界面元素或组件的样式集,本文主要描述bootstrapjs的开发环境搭建。 如上所示,使用nodejs运行时环境、使用npm包管理工具、使用npm初始化一个项目工程test…...

远程实时监控管理:5G物联网技术助力配电站管理
配电站远程监控管理系统是基于物联网和大数据处理等技术的一种创新解决方案。该系统通过实时监测和巡检配电场所设备的状态、环境情况、安防情况以及火灾消防等信息,实现对配电站的在线实时监控与现场设备数据采集。 配电站远程监控管理系统通过回传数据进行数据系…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...
给网站添加live2d看板娘
给网站添加live2d看板娘 参考文献: stevenjoezhang/live2d-widget: 把萌萌哒的看板娘抱回家 (ノ≧∇≦)ノ | Live2D widget for web platformEikanya/Live2d-model: Live2d model collectionzenghongtu/live2d-model-assets 前言 网站环境如下,文章也主…...

HTML前端开发:JavaScript 获取元素方法详解
作为前端开发者,高效获取 DOM 元素是必备技能。以下是 JS 中核心的获取元素方法,分为两大系列: 一、getElementBy... 系列 传统方法,直接通过 DOM 接口访问,返回动态集合(元素变化会实时更新)。…...