关于Java线程池相关面试题
【更多面试资料请加微信号:suns45】
https://flowus.cn/share/f6cd2cbe-627a-435f-a6e5-1395333f92e8
【FlowUs 息流】📣suns-Java资料
访问密码:【请加微信号:suns45】
————线程相关的面试题————
0:创建线程的四种方法
-
1、继承 Thread 类创建线程类
-
2、实现 Runnable 接口创建线程目标类
-
3、使用 Callable 和 FutureTask
-
4、通过线程池创建线程
1:线程的状态有哪些?
-
NEW(新建),
-
RUNABLE(就绪运行),
-
BLOCKED(阻塞),
-
WAITING(等待),
-
TIMED_WAITING(计时等待),
-
TEMINATED(结束)
2:请说明线程状态之间是如何切换的?
-
1:NEW(新建):
- 1.1:新建线程时,状态是NEW。
-
2:RUNABLE(就绪运行):
-
2.1:调用Thread.start(),就会由NEW->RUNABLE状态,这里抛出看(问题3)
-
提示:这里在面试的时候可以直接和面试官聊这个问题三)
-
-
3:BLOCKED(阻塞):
-
3.1:等待进入Synchronized方法/Synchronized块,由RUNABLE就绪运行->BLOCKED阻塞
-
3.2:当获取到monitor锁时,由BLOCKED->RUNNABLE(就绪运行)
-
-
4:WAITING(等待)
-
4.1:RUNNABLE(就绪运行)------------------->WAITING(等待)
-
Object.wait()
-
Object.join()
-
LockSupport.park()
-
-
4.2:RUNNABLE(就绪运行)<-------------------WAITING(等待)
-
Object.notify()
-
Object.notifyAll()
-
LockSupport.unpack(Thread)
-
-
-
5:TIMED_WAITING(计时等待)
-
5.1:RUNNABLE(就绪运行)------------------->TIMED_WAITING(计时等待)
-
Thread.sleep(long)
-
Object.wait(long)
-
Object.join(long)
-
LockSupport.parkNacos(long)
-
LockSupport.parkUntil(long)
-
-
5.2:RUNNABLE(就绪运行)<-------------------TIMED_WAITING(计时等待)
-
Object.notify()
-
Object.notifyAll()
-
LockSupport.unpark(Thread)
-
-
-
6:TERMINATED(终止)
- 6.1:线程执行完成/异常终止 RUNNABLE(就绪运行) -> TERMINATED(终止)
3:请描述下Java线程状态和操作系统中的线程状态有所不同的地方?
-
(从运行过程来说)
- 1:如果线程处于就绪状态,其实就是在等待系统调度,获取时间片,进入运行状态的线程在CPU时间片用完之后,又回到了就绪状态,等待CPU下一次调度,就这样操作系统线程在就绪状态和执行状态之间,被系统反复的调度,直到线程的代码逻辑执行完成/异常终止,这时线程进入最后的状态TERMINATED(终止状态)
-
(从状态划分来说)
- 2: 就绪状态READY和运行状态RUNNING都是操作系统中的线程,在java语言中没有区分这两种状态,而是将这两种状态合并成了RUNNABLE(就绪运行)
-
(补充)
- 3: 在Thread.State枚举类中,没有定义线程的READY(就绪状态)和RUNNING(运行状态),只有RUNNABLE可执行状态,
-
总之,NEW的Thread实例,调用了start()之后进入线程RUNNABLE(就绪运行状态),但是run方法不一定会马上被并发执行,需要获取CPU时间片之后才算真正启动执行。
4:如何捕获线程异常?
总结:给线程设置异常处理器
public class ThreadCatchProcess4 implements Thread.UncaughtExceptionHandler {private String name;public ThreadCatchProcess3(String name) {this.name = name;}@Overridepublic void uncaughtException(Thread t, Throwable e) {System.out.println("线程异常终止进程" + t.getName());System.out.println(name + "捕获了异常" + t.getName() + "异常"); }
}
public class ThreadCatchProcess5 implements Runnable {public static void main(String[] args) throws InterruptedException {Thread.setDefaultUncaughtExceptionHandler(new ThreadCatchProcess3("获取异常"));new Thread(new ThreadCatchProcess5(), "MyThread-1").start();Thread.sleep(300);new Thread(new ThreadCatchProcess5(), "MyThread-2").start();Thread.sleep(300);new Thread(new ThreadCatchProcess5(), "MyThread-3").start();}@Overridepublic void run() {throw new RuntimeException();}
}
5:wait和sleep的异同点
相同点
-
wait和sleep方法都可以是线程阻塞,对应线程状态是Waiting或Time_Waiting
-
wait和sleep方法都可以响应中断Thread.interrupt()
区别点
-
wait方法的执行必须在同步方法(synchronized方法/代码块)中进行,而sleep则不需要。
-
在同步方法里执行sleep方法时,不会释放monitor锁,但是wait会释放monitor锁
-
sleep方法短暂睡眠到指定时间后主动退出阻塞,而没有指定时间的wait方法需要其他线程中断后才能退出阻塞
-
wait()和notify(),notifyAll()是object类的方法,sleep()和yield()是Thread类的方法
6:进程与线程的区别
-
1、一个进程由一个线程或多个线程组成,一个进程至少有一个线程
-
2、线程是CPU调度的最小单位,进程是操作系统分配资源的最小单位,线程的划分尺度小于进程。
-
3、线程是出于高并发的调度诉求,从进程内部演进而来,线程的出现既充分发挥CPU的计算性能,弥补进程调度的过于笨重。
-
4、进程之间是相互独立的,但进程内部各个线程之间,并不完全独立,各个线程共享进程的方法区内存,堆内存,系统资源(文件句柄,系统信号等等)
-
5、切换速度不同,线程上下文切换比进程上下文切换要快很多。线程也称之为轻量级进程
7:线程的优先级是否靠谱?
PriorityDemo.class
[PriorityDemo.main]:thread-1-优先级为1机会值为721691578
[PriorityDemo.main]:thread-2-优先级为2机会值为722963687
[PriorityDemo.main]:thread-3-优先级为3机会值为723929277
[PriorityDemo.main]:thread-4-优先级为4机会值为721130882
[PriorityDemo.main]:thread-5-优先级为5机会值为732331398
[PriorityDemo.main]:thread-6-优先级为6机会值为728891632
[PriorityDemo.main]:thread-7-优先级为7机会值为734037128
[PriorityDemo.main]:thread-8-优先级为8机会值为739307473
[PriorityDemo.main]:thread-9-优先级为9机会值为733526049
[PriorityDemo.main]:thread-10-优先级为10机会值为735961151
总结:
-
1、
-
整体而言,高优先级的线程获得的执行机会更多。
-
(在实例中可以看到:优先级在 6 级以上的线程和 4 级以下的线程,执行机会明细偏多,整体对比非常明显。)
-
-
2、
-
执行机会的获取具有随机性,优先级高的不一定获得机会多。
-
(比如:例子中的 thread-9 比 thread-8 优先级高,但是 thread-9 所获得的机会反而偏少。)
-
8:讲一下你对thread.interrupt()的理解
-
1、interrupt()其本身并不是一个强制打断线程的方法,其仅仅会修改线程的interrupt标志位需要线程自行去读标志位,自行判断是否需要中断
-
2、Object.wait()和thread.sleep()都可以响应中断thread.interrupt()
9:讲一下你对thread.join()的理解
-
有a和b两个线程,当执行a线程时调用b.join()之后,需要等待b线程执行完毕,才能继续执行a线程。
-
优缺点
-
优点:使用比较简单
-
缺点:没有办法直接取得乙方线程的执行结果
-
————线程池相关的面试题————
10:使用线程池的好处
当面试官问到线程池的好处时,你可以这样回答:
使用线程池有以下几个好处:
-
降低资源消耗:线程的创建和销毁是比较消耗资源的操作,使用线程池可以重复利用已经创建的线程,减少了频繁创建和销毁线程的开销,从而降低了系统的资源消耗。
-
提高响应速度:线程池中的线程可以被立即分配,从而减少了线程创建的延迟时间,使得系统能够更快地响应用户请求,提高了系统的响应速度。
-
控制并发数:线程池可以对并发线程数量进行限制,避免因为过多线程导致系统资源耗尽或者性能下降。通过合理配置线程池的线程数,可以根据系统资源和负载情况,有效地控制并发数,保证系统的稳定性和可靠性。
-
提供任务队列:线程池通常还提供了任务队列,可以将任务按照一定的策略进行排队,实现对任务的异步执行。任务队列可以有效地缓冲任务,平衡系统的资源占用情况,保证系统的高效运行。
-
统一管理和监控:线程池提供了对线程的统一管理和监控机制,可以方便地监控线程的创建和销毁情况,线程的执行状态和性能指标等,为系统的优化和故障排查提供了便利。
综上所述,使用线程池可以降低资源消耗、提高系统的响应速度、控制并发数、提供任务队列以及统一管理和监控线程,从而在多线程环境下提升系统的性能和稳定性。
11:请说下你对系统自带线程池类的看法
当面试官问到你对系统自带线程池类的看法时,你可以这样回答:
针对不同的系统自带线程池类,我可以提供如下观点:
- newSingleThreadExecutor():
-
作用:创建一个只有一个线程的线程池。
-
特点:线程池中只有一个线程,可以按顺序执行任务。
-
缺点:如果任务提交速度持续大于处理速度,可能导致队列中大量的任务等待,可能导致内存资源耗尽。
- newFixedThreadPool(int Threads):
-
作用:创建固定大小的线程池。
-
特点:线程池大小固定,每次提交新任务都会创建线程,直到达到最大线程数。
-
缺点:如果任务提交速度持续大于处理速度,可能导致队列中大量的任务等待,可能导致内存资源耗尽。
- newCachedThreadPool():
-
作用:创建一个不限制线程数量的线程池。
-
特点:线程池根据任务数量动态创建线程,适用于任务数量比较大且变化较大的情况。
-
缺点:最大线程数量无上限,在任务提交较多的情况下,可能导致CPU资源耗尽。
- newScheduledThreadPool():
-
作用:创建可定期或延时执行任务的线程池。
-
特点:可以按照预定时间或延时来执行任务,非常适用于需要定时执行任务的场景。
-
缺点:最大线程数量无上限,线程数量不受限制,当到期任务过多时可能导致CPU资源耗尽。
需要注意的是,无论使用哪种线程池类,都需要根据具体业务需求和系统性能来灵活选择和配置。合适的线程池配置可以提高系统的并发性能和资源利用率。
12:请你说下构建线程池的几个参数的含义
当面试官问到构建线程池的几个参数的含义时,你可以这样回答:
在构建线程池时,通常需要设置以下几个参数来控制线程池的行为和性能:
-
核心线程数(corePoolSize):核心线程数是线程池中始终保持活动状态的线程数量。即使这些线程当前没有任务执行,它们也不会被回收。核心线程数用于处理提交的任务,当任务数超过核心线程数时,线程池会创建新的线程来处理任务。
-
最大线程数(maximumPoolSize):最大线程数是线程池中允许存在的最大线程数量。当任务数量超过核心线程数时,并且任务队列已满时,线程池会创建新的线程,直到线程数量达到最大线程数。超过最大线程数的任务将会被拒绝执行或采取其他策略处理。
-
非核心线程闲置超时时间(keepAliveTime):当线程池中的线程数量超过核心线程数时,闲置的非核心线程在经过一段时间(keepAliveTime)后会被回收。这样可以避免线程空闲时占用资源。
-
阻塞队列(workQueue):阻塞队列用于存储还未被线程执行的任务。当线程池中的线程数量达到核心线程数时,新的任务会被放入阻塞队列中等待执行。线程池提供了多种种类的阻塞队列,如有界队列(如ArrayBlockingQueue)和无界队列(如LinkedBlockingQueue),根据业务需求和性能要求选择适当的队列类型。
-
线程工厂(threadFactory):线程工厂用于创建新的线程。通过实现ThreadFactory接口,可以自定义线程的创建过程,如设定线程名称、优先级等。
-
拒绝策略(handler):当任务提交速度超过线程池的处理能力时,可以采取拒绝策略来处理无法被线程池接受和处理的任务。系统提供了几种拒绝策略,如拒绝并抛出异常、直接在调用者线程中执行等,也可以自定义拒绝策略。
这些参数的合理配置对于线程池的性能和效率非常重要,需要根据具体的业务需求和系统资源来进行调整。对于不同的应用场景,可能需要针对性地调整这些参数,以获得最佳的线程池性能。
public ThreadPoolExecutor(
int corePoolSize //核心线程数,即使线程空闲(Idle),也不会回收; (前提是不设置核心线程回收)
,
int maximumPoolSize// 线程数的上限;
,
long keepAliveTime // 线程最大空闲(Idle)时长
,
TimeUnit unit // 时间单位
,
BlockingQueue<Runnable> workQueue, // 任务的排队队列
,
ThreadFactory threadFactory // 新线程的产生方式
,
RejectedExecutionHandler handler //拒绝策略
)
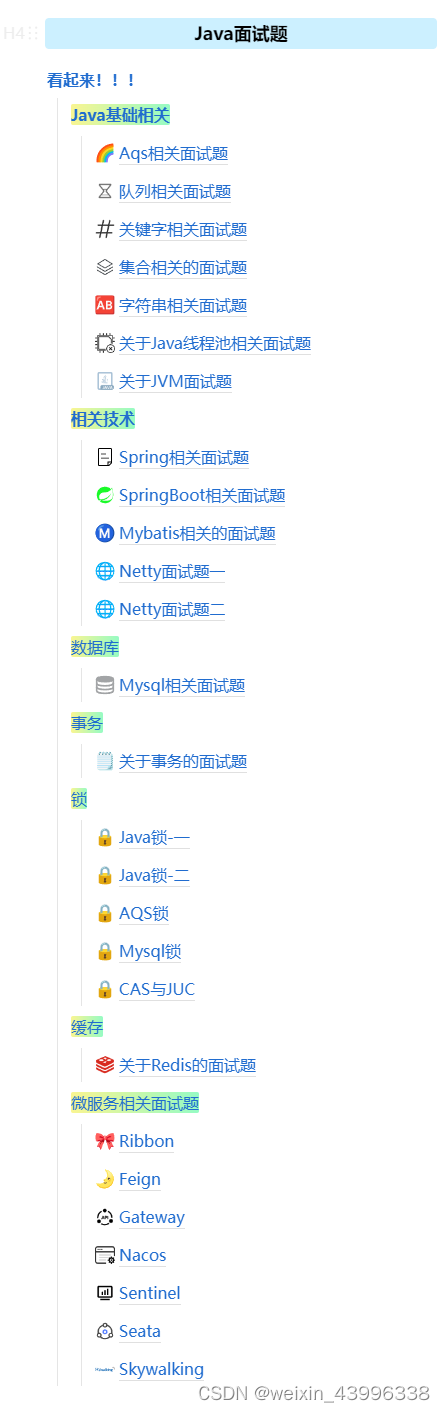
13:请你说下系统自带的拒绝策略有哪些呢?
-
AbortPolicy:拒绝策略
- 使用该策略时,如果线程池队列满了则新任务被拒绝,并且会抛出 RejectedExecutionException异常。该策略是线程池的默认的拒绝策略。
-
DiscardPolicy:抛弃策略
- 该策略是 AbortPolicy 的 Silent(安静)版本,如果线程池队列满了,新任务会直接被丢掉,并且不会有任何异常抛出
-
DiscardOldestPolicy:抛弃最老任务策略
- 也就是说如果队列满了,会将最早进入队列的任务抛弃,从队列中腾出空间,再尝试加入队列。因为队列是队尾进队头出,队头元素是最老的,所以每次都是移除对头元素后再尝试入队。
-
CallerRunsPolicy:调用者执行策略
- 在新任务被添加到线程池时,如果添加失败,那么提交任务线程会自己去执行该任务,不会使用线程池中的线程去执行新任务。
-
自定义策略【实现RejectedExecutionHandler接口】
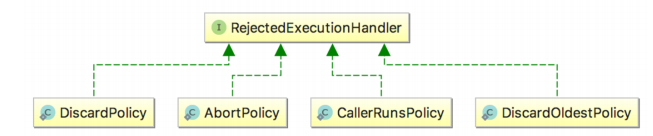
14:请叙述线程池的执行过程
(1):当有任务加入的时候,首先会判定核心线程数是否满了
(2):如果未满则创建线程,满了的话就检查队列是否满了,未满加入队列等待,
(3):如果队列也满了,则检查最大线程数,如果当前未到达最大线程数,则创建线程,
(4):如果已经到达最大线程数,则会根据拒绝策略去执行下面的逻辑
15:请说下线程池调度器的钩子方法
-
1:任务执行之前的钩子方法(前钩子)
- protected void beforeExecute(Thread t, Runnable r) { }
-
2:任务执行之后的钩子方法(后钩子)
- protected void afterExecute(Runnable r, Throwable t) { }
-
3:线程池终止时的钩子方法(停止钩子)
- protected void terminated() { }
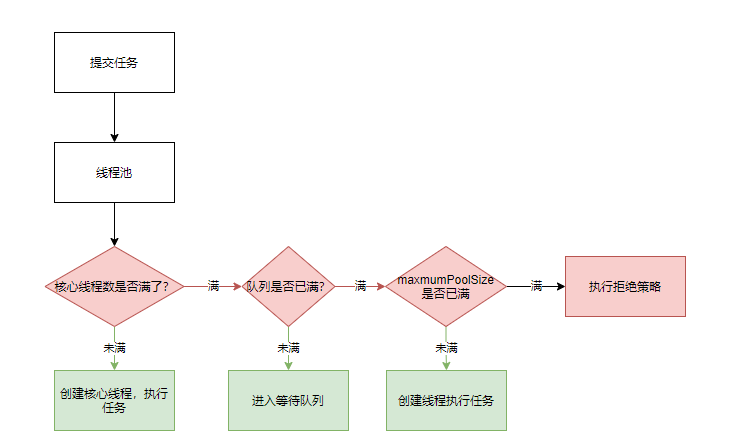
16:请说下线程池的状态都有哪些?
1:RUNNING(running: 线程池创建之后的初始状态,可以执行任务)
2:SHUTDOWN(shutdown: 线程池不再接受新任务,但是会将工作队列中的任务执行完毕。)
3:STOP(stop: 线程池不再接受新任务,也不会处理工作队列中的剩余任务,并且将会中断所有工作线程。)
4:TIDYING(tidying: 该状态下所有任务都已经终止或者处理完成,将会执行terminated()钩子方法)
5:TERMINATED(terminated: 执行完terminated()钩子方法之后的状态)
17:请叙述线程池状态变换的规则
(1)线程池创建之后状态为 RUNNING
(2)执行线程池的 shutdown 实例方法, running->shutdown
(3)执行线程池的 shutdownNow 实例方法, running->stop
(4)当线程池处于 shutdown 状态,执行shutdownNow 方法,shutdown-> stop。
(5)等待线程池的所有工作线程停止,工作队列清空之后,stop->tidying。
(6)执行完terminated()钩子方法之后,tidying->terminated
18:如何优雅的关闭线程池
大家可以结合 shutdown、shutdownNow、awaitTermination 三个方法去优雅关闭一个线程池,大致分为以下几步:
(1):执行 shutdown 方法,拒绝新任务的提交,并等待所有任务有序执行完毕。
(2):执行 awaitTermination(long timeout,TimeUnit unit)方法,指定超时时间,判断是否已经关闭所有任务,线程池关闭完成。
(3):如果 awaitTermination 方法返回 false,或者被中断。调用 shutDownNow 方法立即关闭线程池所有任务。
(4):补充执行 awaitTermination(long timeout,TimeUnit unit)方法,判断线程池是否关闭完成。如果超时,则可以进入循环关闭,循环一定的次数(如 1000 次),不断关闭线程池,直到其关闭或者循环结束。
19:线程池如何调优?
1、线程数
IO密集型线程池
-
原因:
- 主要是执行IO操作,执行IO操作时间较长,导致CPU利用率下降,这种任务CPU常处于空闲状态。
-
特点:
-
(1):设置allowCoreThreadTimeOut(…)方法,并且传入了参数true,则KeepAliveTime参数设置的空闲超时策略也将被用于核心线程,当池中的线程长时间空闲时,可以自行销毁。
-
(2):使用有界队列防止内存溢出
-
(3):corePoolSize、maximumPoolSize保持一致,使得在接收到新任务时,如果核心线程满了,不是优先加入队列,而是优先创建新的线程去执行新的任务。
-
(4):使用懒汉式创建线程池,如果代码没有用到就不创建,用到了再创建。
-
(5):使用JVM关闭时的钩子函数,优雅的自动关闭线程池。
-
-
例子:
- Netty读写操作,为此类任务的典型例子。
CPU密集型线程池
-
特点:
- CPU 密集型任务的并行执行的数量应当 = CPU 的核心数+1
-
原因:
- 执行计算任务,由于响应时间很快,CPU一直在运行,这种任务CPU的利用率高。
-
为什么线程数等于CPU核心数+1呢?
- 为什么要把它设置为CPU的核心数加一呢?理论上把它设置为CPU核心数。性能是最优的,因为没有任何线程切换的开销,同时呢,又可以让每一个CPU的核心都忙起来。没有任何的资源浪费,这样想当然没什么问题,但问题是啊,如果某一个县城突然出现暂停或者中断的话。那么CPU就会有一个核心处于空闲状态了,所以呢,我们一般会设置为n+1,这样多出来的一个线程。就可以用来充分利用CPU的空闲时间,这就像是踢足球弄了一个候补队员,对吧?
混合型任务
-
例子:
- Web服务器的HTTP请求处理操作,为此类任务的典型例子。
-
特点:
-
在涉及混合型任务的情况下,确定线程池数量的确相对复杂一些。上述提到的线程数量的计算公式为n×u×(1+wt÷ST),其中:
-
n:CPU的核心数。
-
u:期望的CPU利用率。根据实际需求和系统性能,可以设置一个合理的值。
-
wt:线程等待的时间。
-
ST:线程运行的时间。
-
-
具体来说,我们可以通过使用工具如jvisualvm进行性能分析来获取wt和ST的值。以下是一些步骤:
-
运行你的项目,并启动jvisualvm进行性能分析。
-
在jvisualvm中选择你的项目,并点击"Profile",然后选择"CPU"。
-
等待一段时间进行性能分析,以获取线程的运行时间ST。
-
通过分析得到的数据,计算线程的自用时间:ST - 线程运行时间。
-
使用得到的自用时间和其他参数,将其带入线程数量计算公式,得到线程池数量的估算值。
-
需要注意的是,这个公式只是一个估算的参考值,实际的线程池数量仍需要结合项目和实际需求进行调试和测试。在选择最终的线程池数量时,还需要考虑系统性能、负载均衡、内存要求等因素。
-
-
2、队列大小调优
参考这个网站:https://www.javacodegeeks.com/2012/03/threading-stories-about-robust-thread.html
package com.threadTest;
import java.lang.management.ManagementFactory;
import java.math.BigDecimal;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class MyPool extends PoolSizeCalculator{public static void main(String[] args) throws InterruptedException,InstantiationException,IllegalAccessException,ClassNotFoundException {MyPool calculator = new MyPool();calculator.calculateBoundaries(new BigDecimal(1.0),new BigDecimal(100000));
ThreadPoolExecutor pool =new ThreadPoolExecutor(16, 16,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>(2500));pool.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());}@Overrideprotected long getCurrentThreadCPUTime() {return ManagementFactory.getThreadMXBean().getCurrentThreadCpuTime();}@Overrideprotected Runnable creatTask() {return new AsynchronousTask();}@Overrideprotected BlockingQueue createWorkQueue() {return new LinkedBlockingQueue<>();}
}
package com.threadTest;
public class AsynchronousTask implements Runnable {public AsynchronousTask() {}
@Overridepublic void run() {System.out.println(Thread.currentThread().getName());}
}
package com.threadTest;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.util.Timer;
import java.util.TimerTask;
import java.util.concurrent.BlockingQueue;
/*** A class that calculates the optimal thread pool boundaries. It takes the desired target utilization and the desired* work queue memory consumption as input and retuns thread count and work queue capacity.** @author Niklas Schlimm*/
public abstract class PoolSizeCalculator {
/*** The sample queue size to calculate the size of a single {@link Runnable} element.*/private final int SAMPLE_QUEUE_SIZE = 1000;
/*** Accuracy of test run. It must finish within 20ms of the testTime otherwise we retry the test. This could be* configurable.*/private final int EPSYLON = 20;
/*** Control variable for the CPU time investigation.*/private volatile boolean expired;
/*** Time (millis) of the test run in the CPU time calculation.*/private final long testtime = 3000;
/*** Calculates the boundaries of a thread pool for a given {@link Runnable}.** @param targetUtilization the desired utilization of the CPUs (0 <= targetUtilization <= 1)* @param targetQueueSizeBytes the desired maximum work queue size of the thread pool (bytes)*/protected void calculateBoundaries(BigDecimal targetUtilization, BigDecimal targetQueueSizeBytes) {calculateOptimalCapacity(targetQueueSizeBytes);Runnable task = creatTask();start(task);start(task); // warm up phaselong cputime = getCurrentThreadCPUTime();start(task); // test intervallcputime = getCurrentThreadCPUTime() - cputime;long waittime = (testtime * 1000000) - cputime;calculateOptimalThreadCount(cputime, waittime, targetUtilization);}
private void calculateOptimalCapacity(BigDecimal targetQueueSizeBytes) {long mem = calculateMemoryUsage();BigDecimal queueCapacity = targetQueueSizeBytes.divide(new BigDecimal(mem), RoundingMode.HALF_UP);System.out.println("Target queue memory usage (bytes): " + targetQueueSizeBytes);System.out.println("createTask() produced " + creatTask().getClass().getName() + " which took " + mem + " bytes in a queue");System.out.println("Formula: " + targetQueueSizeBytes + " / " + mem);System.out.println("* Recommended queue capacity (bytes): " + queueCapacity);}
/*** Brian Goetz' optimal thread count formula, see 'Java Concurrency in Practice' (chapter 8.2)** @param cpu cpu time consumed by considered task* @param wait wait time of considered task* @param targetUtilization target utilization of the system*/private void calculateOptimalThreadCount(long cpu, long wait, BigDecimal targetUtilization) {BigDecimal waitTime = new BigDecimal(wait);BigDecimal computeTime = new BigDecimal(cpu);BigDecimal numberOfCPU = new BigDecimal(Runtime.getRuntime().availableProcessors());BigDecimal optimalthreadcount = numberOfCPU.multiply(targetUtilization).multiply(new BigDecimal(1).add(waitTime.divide(computeTime, RoundingMode.HALF_UP)));System.out.println("Number of CPU: " + numberOfCPU);System.out.println("Target utilization: " + targetUtilization);System.out.println("Elapsed time (nanos): " + (testtime * 1000000));System.out.println("Compute time (nanos): " + cpu);System.out.println("Wait time (nanos): " + wait);System.out.println("Formula: " + numberOfCPU + " * " + targetUtilization + " * (1 + " + waitTime + " / " + computeTime + ")");System.out.println("* Optimal thread count: " + optimalthreadcount);}
/*** Runs the {@link Runnable} over a period defined in {@link #testtime}. Based on Heinz Kabbutz' ideas* (http://www.javaspecialists.eu/archive/Issue124.html).** @param task the runnable under investigation*/public void start(Runnable task) {long start = 0;int runs = 0;do {if (++runs > 5) {throw new IllegalStateException("Test not accurate");}expired = false;start = System.currentTimeMillis();Timer timer = new Timer();timer.schedule(new TimerTask() {public void run() {expired = true;}}, testtime);while (!expired) {task.run();}start = System.currentTimeMillis() - start;timer.cancel();} while (Math.abs(start - testtime) > EPSYLON);collectGarbage(3);}
private void collectGarbage(int times) {for (int i = 0; i < times; i++) {System.gc();try {Thread.sleep(10);} catch (InterruptedException e) {Thread.currentThread().interrupt();break;}}}
/*** Calculates the memory usage of a single element in a work queue. Based on Heinz Kabbutz' ideas* (http://www.javaspecialists.eu/archive/Issue029.html).** @return memory usage of a single {@link Runnable} element in the thread pools work queue*/public long calculateMemoryUsage() {BlockingQueue<Runnable> queue = createWorkQueue();for (int i = 0; i < SAMPLE_QUEUE_SIZE; i++) {queue.add(creatTask());}long mem0 = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory();long mem1 = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory();queue = null;collectGarbage(15);mem0 = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory();queue = createWorkQueue();for (int i = 0; i < SAMPLE_QUEUE_SIZE; i++) {queue.add(creatTask());}collectGarbage(15);mem1 = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory();return (mem1 - mem0) / SAMPLE_QUEUE_SIZE;}
/*** Create your runnable task here.** @return an instance of your runnable task under investigation*/protected abstract Runnable creatTask();
/*** Return an instance of the queue used in the thread pool.** @return queue instance*/protected abstract BlockingQueue<Runnable> createWorkQueue();
/*** Calculate current cpu time. Various frameworks may be used here, depending on the operating system in use. (e.g.* http://www.hyperic.com/products/sigar). The more accurate the CPU time measurement, the more accurate the results* for thread count boundaries.** @return current cpu time of current thread*/protected abstract long getCurrentThreadCPUTime();
}
20、说说你对线程池的理解?
当别人问你对线程池的理解时,给出如下回答:
线程池是一种并发编程的技术,它可以管理和复用多个线程,用于执行异步任务。我对线程池的理解如下:
首先,线程池中最小的执行单位是Worker,Worker充当了任务的代理,实现了Runnable接口和run方法。在Worker初始化时,关键代码将当前Worker作为线程的构造器入参,然后通过线程的start方法来执行Worker的run方法。Worker还实现了AQS,所以它本身也是一个锁,在执行任务时会锁住自己,任务执行完成后会释放自己。
其次,任务的提交过程涉及到execute方法和addWorker方法的执行。在执行execute方法时,经过三个判断条件后会执行addWorker方法。在addWorker方法中,通过线程的start方法来执行Worker线程的runWorker方法。runWorker方法中的getTask操作是一个阻塞操作,它保证了核心线程和未超时的线程不会被销毁。在完成任务的过程中,还有beforeExecute、task.run和afterExecute等方法的处理,用于执行前的准备和执行后的清理。
通过了解线程池的内部实现机制,我们可以更好地管理并发任务的执行。线程池通过复用线程、任务调度和控制并发度等功能,提高了系统的性能和资源利用率,并能够灵活应对不同的业务场景和负载变化。
21、ThreadPoolExecutor、Executor、ExecutorService、Runnable、Callable、FutureTask 之间的关系?
ThreadPoolExecutor、Executor、ExecutorService、Runnable、Callable、FutureTask之间的关系可以通过下面的回答来解释:
ThreadPoolExecutor是线程池的具体实现类,它实现了ExecutorService接口。ExecutorService接口是继承自Executor接口的子接口,它定义了一些更丰富的方法来管理和控制线程池。
Executor接口是Java线程池框架的根接口,它只有一个方法execute(Runnable command),用于提交一个Runnable任务给线程池执行。Executor接口的实现类可以是ThreadPoolExecutor。
Runnable接口和Callable接口是用于表示任务的接口,它们都是可被线程执行的任务。Runnable接口定义了一个run()方法,用于执行任务,而Callable接口定义了一个call()方法,可以返回执行结果。
FutureTask是一种特殊的任务,它实现了RunnableFuture接口,而RunnableFuture接口则是Future接口和Runnable接口的组合。FutureTask可以用来包装一个Callable或Runnable任务,并提供了Future和Runnable的接口特性。它可以被提交给线程池执行,并通过Future对象获取任务的执行结果。
总结起来:
-
Executor接口定义了线程池的基本执行方式,其中的execute方法用于提交任务。
-
ThreadPoolExecutor是ExecutorService接口的一个具体实现,它是线程池的实际执行者。
-
ExecutorService接口继承自Executor接口,并且提供了更多的管理和控制线程池的方法。
-
Runnable接口和Callable接口是表示任务的接口,其中Runnable接口用于执行无返回结果的任务,而Callable接口用于执行有返回结果的任务。
-
FutureTask是一个特殊的任务实现,它可以用来包装Callable或Runnable任务,并提供了Future和Runnable的接口特性,可以获取任务的执行结果。
22:说一说队列在线程池中起的作用?
当别人问队列在线程池中起的作用,你可以结合上述回答,给出如下回答:
-
缓冲作用:队列可以缓存提交的任务,使得请求数量大于实际线程数时任务可以在队列中排队等待执行,从而平衡请求数量和线程处理能力之间的差异。
-
任务调度作用:队列根据调度规则确定任务的执行顺序,通过先进先出、优先级、延迟等策略有序地调度任务的执行。
-
并发度控制作用:队列用于控制并发度,当线程数达到最大限制时,多余的任务会被放入队列中等待执行,限制了同时执行的任务数量。
-
阻塞机制:队列的阻塞功能使得线程在执行完所有任务后不会自动终止,而是等待队列中有新任务产生后立即被消费。
23:结合请求不断增加时,说一说线程池构造器参数的含义和表现?
答:线程池构造器各个参数的含义如下:
-
coreSize 核心线程数;
-
maxSize 最大线程数;
-
keepAliveTime 线程空闲的最大时间;
-
queue 有多种队列可供选择,比如:
-
SynchronousQueue,为了避免任务被拒绝,要求线程池的 maxSize 无界,缺点是当任务提交的速度超过消费的速度时,可能出现无限制的线程增长;
-
LinkedBlockingQueue,无界队列,未消费的任务可以在队列中等待;
-
ArrayBlockingQueue,有界队列,可以防止资源被耗尽;
-
-
线程新建的 ThreadFactory 可以自定义,也可以使用默认的 DefaultThreadFactory,DefaultThreadFactory 创建线程时,优先级会被限制成 NORM_PRIORITY,默认会被设置成非守护线程;
-
在 Executor 已经关闭或对最大线程和最大队列都使用饱和时,可以使用RejectedExecutionHandler 类进行异常捕捉,有如下四种处理策略:
-
ThreadPoolExecutor.AbortPolicy 拒绝策略
-
ThreadPoolExecutor.DiscardPolicy 抛弃策略
-
ThreadPoolExecutor.CallerRunsPolicy 调用者执行策略
-
ThreadPoolExecutor.DiscardOldestPolicy 抛弃最老任务策略
-
自定义策略
-
-
当请求不断增加时,各个参数起的作用如下:
-
请求数 < coreSize:创建新的线程来处理任务;
-
coreSize <= 请求数 && 能够成功入队列:任务进入到队列中等待被消费;
-
队列已满 && 请求数 < maxSize:创建新的线程来处理任务;
-
队列已满 && 请求数 >= maxSize:使用 RejectedExecutionHandler 类拒绝请求。
24:coreSize 和 maxSize可以动态设置么,有没有规则限制?
coreSize和maxSize都是线程池的线程数量相关的参数,它们可以进行动态设置,但是需要遵循一些规则限制。以下是对这个问题的回答:
-
coreSize的动态设置: 在大多数线程池实现中,coreSize是可以进行动态设置的,即在运行过程中可以改变coreSize的值。但需要注意的是,动态设置coreSize可能会影响线程池的整体性能和稳定性,因此应该谨慎操作。特别是在已经提交了一些任务的情况下,如果将coreSize减小,可能导致已提交任务无法得到处理。
-
maxSize的动态设置: 相比coreSize,maxSize的动态设置要更加复杂一些。在某些线程池实现中,maxSize也可以进行动态设置,但需要注意的是,maxSize的值不能小于coreSize。另外,动态增大maxSize可能会对系统资源产生压力,应慎重考虑。
需要说明的是,每个线程池实现可能会对coreSize和maxSize的可设置范围有不同的规则限制,具体取决于线程池的实现和设计。
总结起来,coreSize和maxSize可以进行动态设置,但操作应慎重,并且需要遵循一些规则限制,比如不能将coreSize减小,以及maxSize不能小于coreSize。
25:说一说对于线程空闲回收的理解,源码中如何体现的?
线程空闲回收是指当线程在一段时间内没有任务可执行时,线程池会将这些空闲的线程回收,以节省资源和提高效率。在源码中,线程空闲回收的实现可以体现在以下几个方面:
-
空闲线程回收时机: 当线程超过keepAliveTime时间后,如果它在阻塞队列中找不到可执行的任务(即线程处于空闲状态),当前线程就会被回收。这是通过对线程池的定时检查和控制实现的。
-
core thread的回收条件: 如果allowCoreThreadTimeOut设置为true,即使是core线程也会被回收,直到只剩下一个线程为止。如果allowCoreThreadTimeOut设置为false,则只会回收非core线程。
-
阻塞中断机制: 线程在任务执行完成后,之所以没有立即终止,是因为它阻塞在队列中等待任务。但是如果在keepAliveTime时间内仍然未能获取到任务,线程会被中断阻塞并直接返回,从而结束线程的生命周期。JVM会回收被中断的线程对象。
综上所述,线程空闲回收的实现源码中体现在对线程的定时检查和控制,并通过中断机制打破阻塞,实现线程的回收。
26:如果我想在线程池任务执行之前和之后,做一些资源清理的工作,可以么,如何做?
答:可以的,ThreadPoolExecutor 提供了一些钩子函数,我们只需要继承 ThreadPoolExecutor 并实现这些钩子函数即可。在线程池任务执行之前实现 beforeExecute 方法,执行之后实现 afterExecute方法。
27:线程池中的线程创建,拒绝请求可以自定义实现么?如何自定义?
答:可以自定义的,线程创建默认使用的是 DefaultThreadFactory,自定义话的只需要实现ThreadFactory 接口即可;拒绝请求也是可以自定义的,实现 RejectedExecutionHandler 接口即可;在 ThreadPoolExecutor 初始化时,将两个自定义类作为构造器的入参传递给 ThreadPoolExecutor 即可
28:说说你对线程池Worker 的理解?
Worker是线程池中的工作线程,它充当了任务的代理,负责执行提交给线程池的任务。以下是对Worker的进一步说明:
-
实现Runnable接口:Worker实现了Runnable接口,通过实现run方法来执行任务的具体逻辑。在初始化时,通过this.thread = getThreadFactory().newThread(this)将当前Worker作为线程的构造器入参,创建与Worker关联的线程实例。
-
执行任务:通过t.start()启动线程,实际上是执行Worker的run方法。在run方法中,Worker从任务队列中获取任务,并调用任务的run方法执行任务逻辑。
-
锁的实现:Worker本身也实现了AbstractQueuedSynchronizer(AQS),它可以拥有独立的锁。在执行任务期间,Worker会锁住自身,以避免其他线程同时执行任务。任务执行完毕后,Worker会释放自身的锁。
综上所述,Worker在线程池中充当着任务的代理角色,它实现了Runnable接口,并在初始化时与一个线程关联。通过调用线程的start方法来执行Worker的run方法,从而执行任务的具体逻辑。Worker还具备锁的功能,通过锁定自身来确保任务的独占执行。
29:说一说 submit方法执行的过程?
submit方法是用于向线程池提交任务的方法,它将任务提交给线程池进行异步执行。
-
将任务封装为一个Future对象:submit方法接收一个Callable或Runnable类型的参数,它会将这个任务封装为一个Future对象。Future是用来表示异步计算结果的,它可以用来获取任务的执行结果或取消任务的执行。
-
决定任务的执行策略:线程池会根据预先设置的策略来决定任务的执行策略。具体的策略包括但不限于:选择合适的线程来执行任务、将任务放入任务队列等待执行、拒绝执行任务等。
-
提交任务给线程池:一旦任务被封装为Future对象并决定了执行策略后,submit方法会将任务提交给线程池。线程池会根据具体的实现方式,选择合适的线程或将任务放入任务队列中进行异步执行。
-
返回Future对象:submit方法执行完毕后,会立即返回一个Future对象,它可以用于控制和获取任务的执行结果。通过Future对象,可以判断任务是否已经完成、等待任务完成、获取任务的执行结果等。
需要注意的是,submit方法是异步的,它会立即返回,不会等待任务的执行结果。如果需要等待任务完成并获取结果,可以调用Future对象的相关方法,如get方法进行阻塞等待。
综上所述,submit方法将任务封装为Future对象,并根据线程池的执行策略将任务提交给线程池进行异步执行。通过返回的Future对象,可以控制和获取任务的执行结果。
30:说一说线程执行任务之后,都在干啥?
在线程执行任务完成之后,会进行下面两种操作中的一种:
-
阻塞等待新任务:线程会继续在任务队列中阻塞等待新的任务到来。如果任务队列中没有任务,则线程会一直阻塞,直到有新任务提交到队列中。这种方式可以保持线程的持续可用性,以便随时处理新的任务。
-
线程终止和回收:线程在执行完任务后,如果任务队列中没有新的任务,并且线程池的策略允许线程回收,那么该线程可能会被终止并被JVM回收。这样可以避免空闲线程的资源浪费,提高资源利用率。
需要注意的是,具体采取哪种操作取决于线程池的实现和配置。一般来说,线程池会根据预先设置的策略来决定如何处理空闲的线程,以确保线程池的性能和资源利用的平衡。
31:keepAliveTime 设置成负数或者是 0,表示无限阻塞?
当面试官问到如何表示线程池的空闲线程进行无限阻塞时,可以回答如下:要表示线程池的空闲线程无限阻塞而不被回收,可以根据不同情况进行设置:
-
若
keepAliveTime参数表示线程空闲超时时间,将其设置为负数或0,意味着线程池中的空闲线程会保持存活状态,不会被回收。负数表示所有线程都不会被回收,即使处于空闲状态;而0表示空闲线程会立即被回收。 -
若想要真正实现无限阻塞的效果,可以将
keepAliveTime参数设置为Long.MAX_VALUE,即使用Long类型的最大值来表示。这样,空闲线程将会无限期地保持存活状态,直到有新的任务被提交到线程池中。
需要注意的是,使用无限阻塞可能会占用较多的系统资源,因此在实际应用中,需要权衡资源的使用和性能的需求。通常情况下,合理设置keepAliveTime参数,使得线程池能够根据实际需求回收空闲线程,能够更好地平衡资源利用和性能。
32:说一说 Future.get 方法是如何拿到线程的执行结果的?
当面试官问到如何使用 Future.get 方法来获取线程的执行结果时,可以回答如下:
-
Future.get方法是用于获取线程的执行结果的。 -
具体来说,当我们使用
submit方法向线程池提交任务时,得到的返回值是一个Future对象,它是FutureTask类的一个实例。FutureTask实现了Future接口,并额外提供了一个outcome属性存储线程的执行结果。 -
当我们调用
Future.get方法时,它会阻塞当前线程,直到任务执行完成并返回结果。实际上,get方法内部会检查任务是否已经完成,如果任务已完成,就直接从FutureTask的outcome属性中获取结果并返回;如果任务未完成,get方法会等待任务完成。 -
一旦任务完成,
get方法就会返回线程的执行结果。如果任务发生异常,get方法也会抛出相应的异常。 -
因此,通过调用
Future.get方法,我们可以获取到线程的执行结果,以便进一步处理或使用。 -
希望以上回答能够满足您的需求。如果还有其他问题,请随时提问。
33:线程池公用和独立
-
在实际工作中,为了确保线程池的效率和业务场景的独立性,一般会遵循以下优化原则:
-
查询和写入分离: 查询和写入操作通常具有不同的特点和需求。由于查询量通常远大于写入量,为了避免写入请求被查询请求拖延,应该为查询和写入操作分别配置独立的线程池。这样可以确保查询请求能够及时处理,而写入请求则可以在队列中排队等待。
-
每个业务场景独立使用线程池: 对于多个写入业务场景,为了方便业务治理、限流和熔断等操作,应该尽量避免共用线程池。每个业务场景单独使用自己的线程池,能够保证业务场景之间的独立性,避免相互影响。尽管现代的服务器具有较大的内存,但为每个写入场景分配独立的线程池仍然是较为合理的做法。
-
相似的查询业务场景可以公用线程池: 相似的查询业务场景通常具有多个共同点,例如查询的场景较多、处理时间较短、查询量较大等。对于这些相似的查询场景,可以考虑将它们归为一类并共用一个线程池。这样做的好处是避免配置过多线程池带来的复杂性,以及节约资源。
综上所述,线程池的优化应考虑查询和写入的分离、每个业务场景独立使用线程池以及相似的查询场景共用线程池。这样可以更好地满足不同业务场景的需求,提高系统的性能和可维护性。
-
总结:
-
查询和写入不公用一个线程池,因为查询需要及时处理,而写入可以去队列中排队
-
多个写入场景一般不要公用一个线程池,因为不同业务之间要做到互不影响
-
查询可以公用一个线程池,1、因为查询的线程池中线程和队列大小毕竟复杂,2、耗费资源
-
34:线程大小和队列大小
在确定线程池的大小和队列大小时,可以优化如下:
-
根据业务流量进行考虑: 在初始化线程池时,需要考虑当前所有业务的流量情况。如果所有业务都有大量的并发流量,建议将线程池的大小和队列大小设置较小。这样可以避免因为线程过多导致资源耗尽或性能下降。相反,如果业务的并发流量相对较少,可以适当增加线程池的大小和队列大小。
-
根据业务的实时性要求进行设置: 根据业务对实时性的要求,可以选择不同的线程池配置。如果业务对实时性要求较高,可以设置线程池的核心线程数等于最大线程数,并将最大线程数设置较大。这样可以确保任务能够立即得到处理,而不需要排队等待。如果业务对实时性要求相对较低,可以适当增加队列大小,允许任务在队列中排队等待处理。
综上所述,根据业务的流量和实时性要求,优化线程池的大小和队列大小。如果业务并发流量大,设置较小的线程池和队列大小;如果业务对实时性要求高,使用等于最大线程数的核心线程数和较大的最大线程数;如果业务对实时性要求低,可以适当增加队列大小。
35、线程池如何拥有回调功能?
-
借助google的MoreExecutors
-
添加监听
@Slf4jpublic class CallbackTaskScheduler {static ListeningExecutorService gPool = null;
static {ExecutorService jPool = ThreadUtil.getMixedTargetThreadPool();gPool = MoreExecutors.listeningDecorator(jPool);}
private CallbackTaskScheduler() {}
/*** 添加任务 * @param executeTask*/public static <R> void add(CallbackTask<R> executeTask) {ListenableFuture<R> future = gPool.submit(new Callable<R>() {public R call() throws Exception {R r = executeTask.execute();return r;}});Futures.addCallback(future, new FutureCallback<R>() {public void onSuccess(R r) {executeTask.onBack(r);}
public void onFailure(Throwable t) {executeTask.onException(t);}});}}
ThreadLocal——————
1、请你说下你对ThreadLocal的认知
1:初始化
-
1:非空判断
//获取“线程本地变量”中当前线程所绑定的值
if (LOCAL_FOO.get() == null)
{
//设置“线程本地变量”中当前线程所绑定的初始值
LOCAL_FOO.set(new Foo());
}
- 2: ThreadLocal.withInitial(…)静态工厂方法### 2:使用场景(优点)#### 从线程隔离的角度来考虑- 好处:- 1:线程安全(在多线程环境下,可以防止自己的变量被其他线程篡改)- 2:避免加锁提高执行效率 (由于各个线程之间的数据相互隔离,避免同步加锁带来的性能损失,大大提升了并发性的性能。)- 举例:- 在“线程隔离”场景中使用 ThreadLocal 的典型案例为:可以每个线程绑定一个数据库连接,使得这个数据库连接为线程所独享,从而避免数据库连接被混用而导致操作异常问题,- 代码:- 1、Hibernate 通 过 ThreadLocal 非常简单实现了数据库连接的安全使用。- 2、如果每个线程都需要打印时间,会存在线程安全问题解决线程安全问题比喻:一本老师笔记,全班一起用。ThreadLocal复制30份,解决全班一起用的问题#### 从跨函数传递数据来考虑- 好处:- 1:避免通过参数传递数据带来的高耦合- 举例:- 可以每个线程绑定一个 Session(用户会话)信息,这样一个线程的所有调用到的代码,都可以非常方便地访问这个本地会话,而不需要通过参数传递。- 代码:- (1)用来传递请求过程中的用户 ID。- (2)用来传递请求过程中的用户会话(Session)。- (3)用来传递 HTTP 的用户请求实例 HttpRequest。- (4)其他需要在函数之间频繁传递的数据。### 3:从jdk版本上来说- 1:拥有者发生了变化- 新版本的ThreadLocalMap 拥有者 Thread(代码层面上还是没变的),早起版本的ThreadLocalMap 拥有者 为ThreadLocal- 2:Key发生了变化- 新版本的Key为ThreadLocal实例,Value是ThreadLocal的值- 老版本的Key为Thread实例- 3:ThreadLocalMap存储的Key-Value对数量变少了。- 新版本的ThreadLocalMap的Key为ThreadLocal实例,多线程情况下ThreadLocal实例比线程数少。- 老版本的Key-Value对数量与线程个数强关联,如果线程数量多,则ThreadLocalMap存储 Key-Value对 数量也多。- 4:threadLocalMap是否被销毁- 早期版本ThreadLocalMap的拥有者为ThreadLocal,在Thread(线程)实例销毁后,ThreadLocalMap还是存在的;- 新版本的ThreadLocalMap的拥有者为Thrad,现在当Thread实例销毁后,ThreadLocalMap也会随之销毁,在一定程度上能减少内存的消耗。### 4:使用 static final 修饰 ThreadLocal 对象的原因,以及带来的坏处原因- 1:ThreadLocal实例作为ThreadLocalMap的Key,针对一个线程内所有操作是共享的,所以建议设置static修饰符,以便被所有的对象共享。- 2:静态变量在类第一次被使用时装载,只会分配一次存储空间,此类所有的实例都会共享这个存储空间,所以使用static修饰符ThreadLocal会节约内存空间- 3:为了确保ThreadLocal实例的唯一性,除了使用static修饰外,还会使用final加强修饰,以防止其在使用过程中发生动态变更坏处- 使得Thread实例内部的ThreadLocalMap中Entry的Key在Thread实例的生命周期内将始终保持为非null,从而导致Key所在的Entry不会被自动清空,这就会导致Entry中的Value指向的对象一直存在强引用, Value指向的对象在线程生命期内不会被释放,最终导致内存泄露,所以使用static final修饰ThreadLocal实例,使用完后必须使用remove()进行手动释放。相关文章:
关于Java线程池相关面试题
【更多面试资料请加微信号:suns45】 https://flowus.cn/share/f6cd2cbe-627a-435f-a6e5-1395333f92e8 【FlowUs 息流】📣suns-Java资料 访问密码:【请加微信号:suns45】 ————线程相关的面试题———— 0:创建线…...
ExcelBDD Python指南
在Python里面支持BDD Excel BDD Tool Specification By ExcelBDD Method This tool is to get BDD test data from an excel file, its requirement specification is below The Essential of this approach is obtaining multiple sets of test data, so when combined with…...

基于深度学习的驾驶员疲劳监测系统的设计与实现
点击以下链接获取源码: https://download.csdn.net/download/qq_64505944/88421622?spm1001.2014.3001.5503 基于深度学习的驾驶员疲劳监测系统的设计与实现 1 绪论 在21世纪,各国的经济飞速发展,人民越来越富裕,道路上的汽车也逐…...
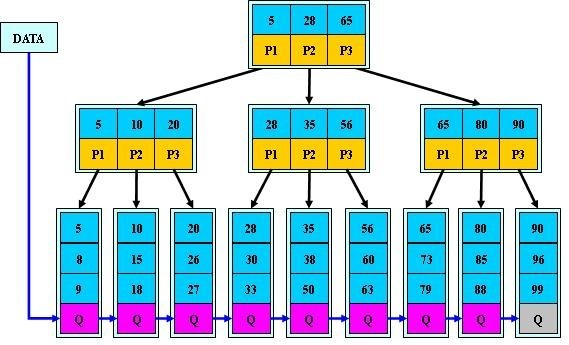
B树、B+树详解
B树 前言 首先,为什么要总结B树、B树的知识呢?最近在学习数据库索引调优相关知识,数据库系统普遍采用B-/Tree作为索引结构(例如mysql的InnoDB引擎使用的B树),理解不透彻B树,则无法理解数据…...
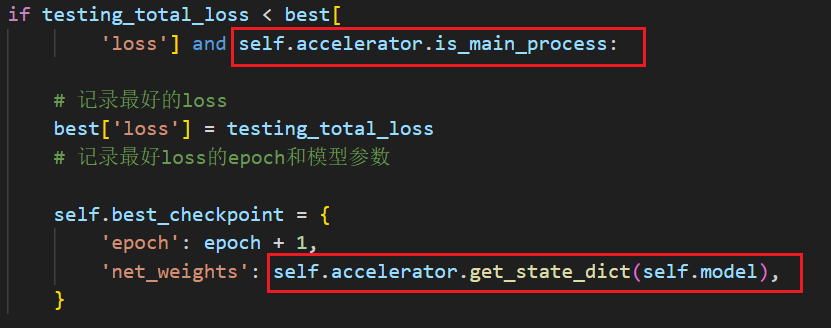
使用hugging face开源库accelerate进行多GPU(单机多卡)训练卡死问题
目录 问题描述及配置网上资料查找1.tqdm问题2.dataloader问题3.model(input)写法问题4.环境变量问题 我的卡死问题解决方法 问题描述及配置 在使用hugging face开源库accelerate进行多GPU训练(单机多卡)的时候,经常出现如下报错 [E Process…...
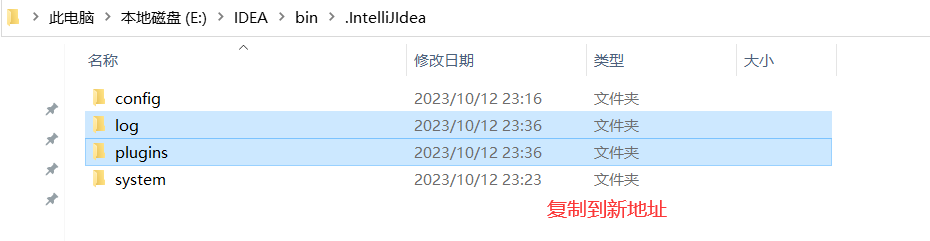
IDEA 修改插件安装位置
不说假话,一定要看到最后,不然你以为我为什么要自己总结!!! IDEA 修改插件安装位置 前言步骤 前言 IDEA 默认的配置文件均安装在C盘,使用时间长会生成很多文件,这些文件会占用挤兑C盘空间&…...

牛客网SQL160
国庆期间每类视频点赞量和转发量_牛客题霸_牛客网 select * from ( select tag,dt, sum(单日点赞量)over(partition by tag order by dt rows between 6 preceding and 0 following), max(单日转发量)over(partition by tag order by dt rows between 6 preceding and 0 follo…...
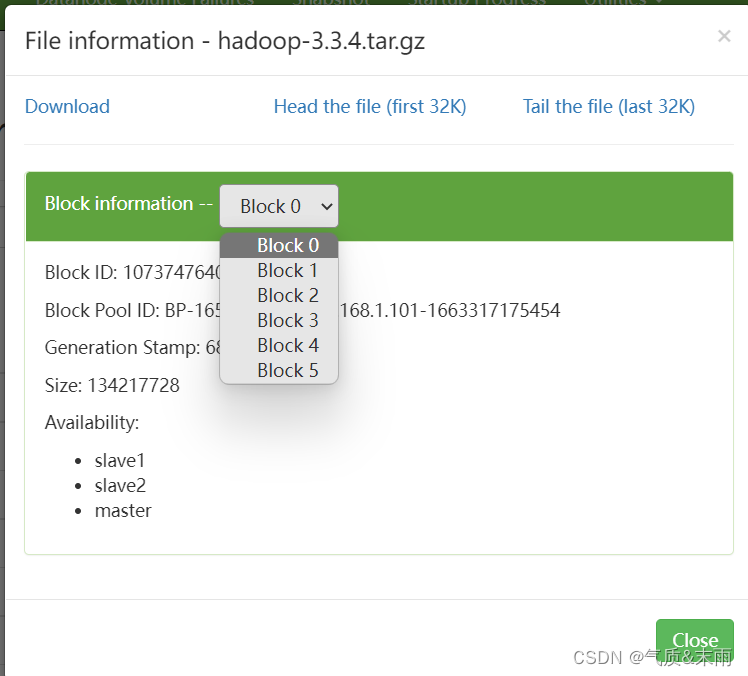
HDFS Java API 操作
文章目录 HDFS Java API操作零、启动hadoop一、HDFS常见类接口与方法1、hdfs 常见类与接口2、FileSystem 的常用方法 二、Java 创建Hadoop项目1、创建文件夹2、打开Java IDEA1) 新建项目2) 选择Maven 三、配置环境1、添加相关依赖2、创建日志属性文件 四、Java API操作1、在HDF…...
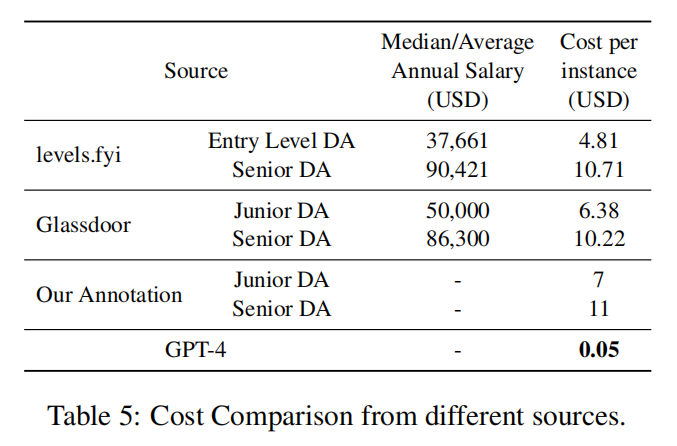
论文阅读之【Is GPT-4 a Good Data Analyst?(GPT-4是否是一位好的数据分析师)】
文章目录 论文阅读之【Is GPT-4 a Good Data Analyst?(GPT-4是否是一位好的数据分析师)】背景:数据分析师工作范围基于GPT-4的端到端数据分析框架将GPT-4作为数据分析师的框架的流程图 实验分析评估指标表1:GPT-4性能表现表2&…...
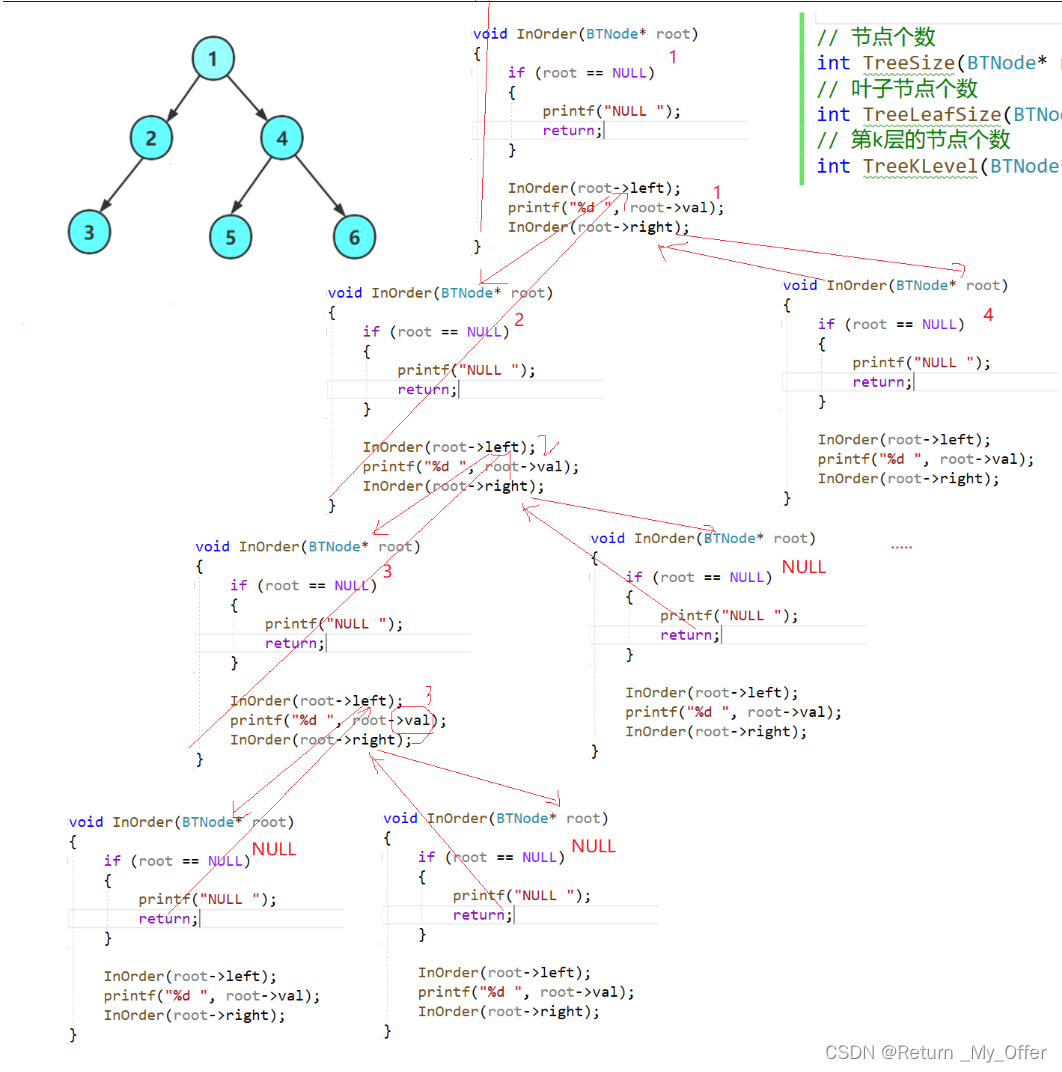
【数据结构】:二叉树与堆排序的实现
1.树概念及结构(了解) 1.1树的概念 树是一种非线性的数据结构,它是由n(n>0)个有限结点组成一个具有层次关系的集合把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的有一个特殊的结点&#…...

纯css手写switch
CSS 手写switch 纯css手写switchcss变量 纯css手写switch 思路: switch需要的元素有:开关背景、开关按钮。点击按钮后,背景色变化,按钮颜色变化,呈现开关打开状态。 利用typecheckbox,来实现switch效果(修…...

PyTorch 深度学习之处理多维特征的输入Multiple Dimension Input(六)
1.Multiple Dimension Logistic Regression Model 1.1 Mini-Batch (N samples) 8D->1D 8D->2D 8D->6D 1.2 Neural Network 学习能力太好也不行(学习到的是数据集中的噪声),最好的是要泛化能力,超参数尝试 Example, Arti…...

LeetCode【438】找到字符串中所有字母异位词
题目: 注意:下面代码勉强通过,每次都对窗口内字符排序。然后比较字符串。 代码: public List<Integer> findAnagrams(String s, String p) {int start 0, end p.length() - 1;List<Integer> result new ArrayL…...
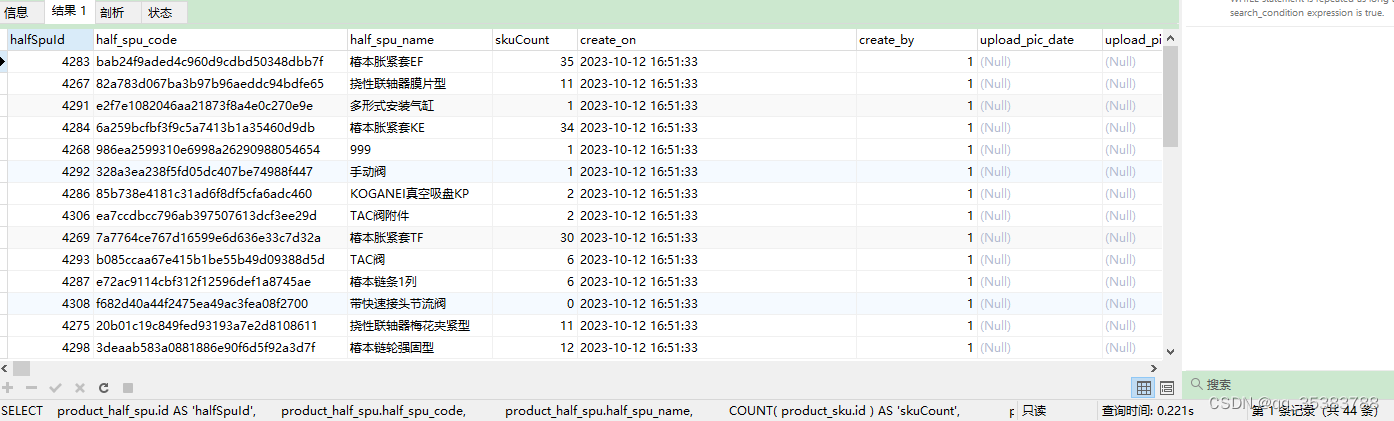
关于LEFT JOIN的一次理解
先看一段例子: SELECTproduct_half_spu.id AS halfSpuId,product_half_spu.half_spu_code,product_half_spu.half_spu_name,COUNT( product_sku.id ) AS skuCount,product_half_spu.create_on,product_half_spu.create_by,product_half_spu.upload_pic_date,produc…...

各报文段格式集合
数据链路层-- MAC帧 前导码8B:数据链路层将封装好的MAC帧交付给物理层进行发送,物理层在发送MAC帧前,还要在前面添加8字节的前导码(分为7字节的前同步码1字节的帧开始定界符)MAC地址长度6B数据长度46~1500B…...

【算法-动态规划】最长公共子序列
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kuan 的首页,持续学…...
区块链游戏的开发流程
链游(Blockchain Games)的开发流程与传统游戏开发有许多相似之处,但它涉及到区块链技术的集成和智能合约的开发。以下是链游的一般开发流程,希望对大家有所帮助。北京木奇移动技术有限公司,专业的软件外包开发公司&…...

目标检测网络系列——YOLO V2
文章目录 YOLO9000better,更准batch Normalization高分辨率的训练使用anchor锚框尺寸的选择——聚类锚框集成改进——直接预测bounding box细粒度的特征图——passthrough layer多尺度训练数据集比对实验VOC 2007VOC 2012COCOFaster,更快网络模型——Darknet19训练方法Strong…...
15. Java反射和注解
Java —— 反射和注解 1. 反射2. 注解 1. 反射 动态语言:变量的类型和属性可以在运行时动态确定,而不需要在编译时指定 常见动态语言:Python,JavaScript,Ruby,PHP,Perl;常见静态语言…...
pdf处理工具 Enfocus PitStop Pro 2022 中文 for mac
Enfocus PitStop Pro 2022是一款专业的PDF预检和编辑软件,旨在帮助用户提高生产效率、确保印刷品质量并减少错误。以下是该软件的一些特色功能: PDF预检。PitStop Pro可以自动检测和修复常见的PDF文件问题,如缺失字体、图像分辨率低、颜色空…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...