Linux操作系统基础知识命令参数详解
Linux操作系统
RAID分组
RAID JBOD
- RAID JBOD的意思是Just a Bunch Of Disks,是将多块硬盘串联起来组成一个大的存储设备,从某种意义上说这种类型不被算作RAID,在维基百科里JBOD同时也被归入非RAID架构。
- RAID JBOD将所有的磁盘串联成一个单一的,容量是使用的磁盘的总和的存储设备供操作系统使用。比如使用3块容量是80GB的磁盘,建立的RAID JBOD设备的容量就是240GB,再比如使用3块容量分别是60GB,80GB,100GB的磁盘,建立的RAID JBOD设备容量是240GB。
- RAID JBOD可以使用成员设备中的所有空间,无论各设备尺寸是否相同。这一点也是RAID JBOD与其他RAID类型的最大不同。因为是各设备串联,RAID JBOD的访问速度跟单个设备相同,也没有任何形式的校验,因此任意一块磁盘出现故障,都会破坏整个RAID,可靠性是单一设备的1/N。
RAID 0
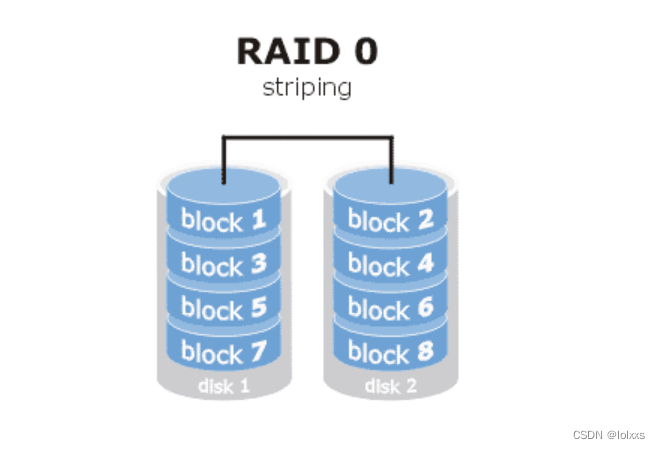
- RAID 0将N块硬盘上选择合理的带区来创建带区集,图上的block就是带区。其原理是将类似于显示器隔行扫描,将数据分割成不同条带(Stripe)分散写入到所有的硬盘中同时进行读写。多块硬盘的并行操作使同一时间内磁盘读写的速度提升N倍。
- 在创建带区集时,合理的选择带区的大小非常重要。如果带区过大,可能一块磁盘上的带区空间就可以满足大部分的I/O操作,使数据的读写仍然只局限在少数的一、两块硬盘上,不能充分的发挥出并行操作的优势。另一方面,如果带区过小,任何I/O指令都可能引发大量的读写操作,占用过多的控制器总线带宽。
- 合理的带区集虽然可以把数据均匀的分配到所有的磁盘上进行读写。但如果我们把所有的硬盘都连接到一个控制器上的话,可能会带来潜在的危害。这是因为当我们频繁进行读写操作时,很容易使控制器或总线的负荷超载。为了避免出现上述问题,建议用户可以使用多个磁盘控制器。最好解决方法还是为每一块硬盘都配备一个专门的磁盘控制器。
- RAID 0可以提供更多的空间和更好的性能,但是整个系统是非常不可靠的,如果出现故障,无法进行任何补救。所以,RAID 0一般只是在那些对数据安全性要求不高的情况下才被人们使用。
RAID 1
- RAID 1称为磁盘镜像,原理是把一个磁盘的数据镜像到另一个磁盘上,也就是说数据在写入一块磁盘的同时,会在另一块闲置的磁盘上生成镜像文件。
- 在不影响性能情况下最大限度的保证系统的可靠性和可修复性上,只要系统中任何一对镜像盘中至少有一块磁盘可以使用,甚至可以在一半数量的硬盘出现问题时系统都可以正常运行,当一块硬盘失效时,系统会忽略该硬盘,转而使用剩余的镜像盘读写数据,具备很好的磁盘冗余能力。
- RAID 1虽然可以保证数据不丢失,但是成本也会明显增加,磁盘利用率为50%,以四块80GB容量的硬盘来讲,可利用的磁盘空间仅为160GB。另外,出现硬盘故障的RAID系统不再可靠,应当及时的更换损坏的硬盘,否则剩余的镜像盘也出现问题,那么整个系统就会崩溃。更换新盘后原有数据会需要很长时间同步镜像,外界对数据的访问不会受到影响,只是这时整个系统的性能有所下降。
- RAID 1多用在保存关键性的重要数据的场合。 RAID 1主要是通过二次读写实现磁盘镜像,所以磁盘控制器的负载也相当大,尤其是在需要频繁写入数据的环境中。为了避免出现性能瓶颈,使用多个磁盘控制器就显得很有必要。
RAID 0+1
从RAID 0+1名称上我们便可以看出是RAID0与RAID1的结合体,有时也称为RAID10。在我们单独使用RAID 1会出现在同一时间内只能向一块磁盘写入数据,不能充分利用所有的资源。为了解决这一问题,我们可以在磁盘镜像中建立带区集。因为这种配置方式综合了带区集和镜像的优势,所以被称为RAID 0+1。把RAID0和RAID1技术结合起来,数据除分布在多个盘上外,每个盘都有其物理镜像盘,提供全冗余能力,允许最多丢失一整个磁盘的故障,而不影响数据可用性,并具有快速读/写能力。
RAID 2
- RAID 2是带海明码校验。从概念上讲,RAID 2 同RAID 3类似,两者都是将数据条块化(分片或者叫分带区)分布于不同的硬盘上。然而RAID 2 使用一定的编码技术来提供错误检查及恢复。
- 这种编码技术需要多个磁盘存放检查及恢复信息,使得RAID 2技术实施更复杂。因此,在商业环境中很少使用。具体是根据按位或者字节分片在各个磁盘的数据来计算海明校验码,再将海明校验码保存在其他组磁盘上。
- 由于海明码的特点,它可以在数据发生错误的情况下将错误校正,以保证输出的正确。由于采用了分带区的机制,它的数据传送速率相当高。要利用海明码,必须要付出数据冗余的代价,即不只要有数据磁盘还需要有存放校验码的磁盘。
- 输出数据的速率与驱动器组中速度最慢的相等,由于将数据分布在不同磁盘,所以取数据速度和磁盘组中速度最慢的相等,其他快的需要等待慢的。
汉明码的校验方式
汉明码=数据码+校验码
假如有n个数据码,k个校验码,那么k的个数只要满足2k >= n + k + 1即可,
那么要传输数据码:0101的话,那就需要3个校验码,8 >= 4(数据码) + 3(校验码) + 1
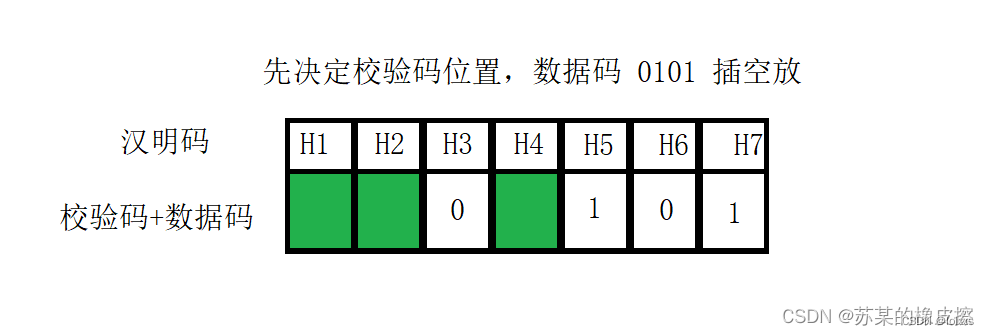
我们先看校验码,我们规定校验码的位置放在2的i次方的位置,也就是1,2,4。假设下面是用偶校验,即要使得校验的位置中1的个数为偶数个
- 第一个校验码,校验的位置是从自己开始数一位,然后每隔一位,校验一位。则第一个校验码应当校验位置H1、H3、H5、H7,所以其值为0
- 第二个校验码,校验的位置是从自己开始数两位,然后每隔两位,校验两位。则第二个校验码应当校验位置H2、H3、H6、H7,所以其值为1
- 第三个校验码,校验的位置是从自己开始数四位,然后每隔四位,校验四位。则第三个校验码应当校验位置H4、H5、H6、H7,所以其值为0
- 则其纠错的原理是,当H3出错时,校验码1、2无法校验成功。当H5出错时,无法校验成功。当H6出错时,校验码1、3无法校验成功。当H7会出错时,校验码1、2、3无法校验成功。根据是第几个校验码出现错误的组合就可以知道是哪一位出错。
- 如果有第四个校验码,校验的位置是从自己开始数八位,然后每隔八位,校验八位,以此类推
RAID 3
- RAID3(带奇偶校验码的并行传送)。这种校验码与RAID2不同,只能查错不能纠错。它访问数据时一次处理一个带区,这样可以提高读取和写入速度。校验码在写入数据时产生并保存在另一个磁盘上。
- 需要实现时用户必须要有三个以上的驱动器,写入速率与读出速率都很高,因为校验位比较少,因此计算时间相对而言比较少。
- RAID 3使用单块磁盘存放奇偶校验信息。如果一块磁盘失效,奇偶盘(存放奇偶校验码的盘)及其他数据盘可以重新产生数据。如果奇偶盘失效,则不影响数据使用。RAID 3对于大量的连续数据可提供很好的传输率,但对于随机数据,奇偶盘会成为写操作的瓶颈。
RAID 4
RAID4(带奇偶校验码的独立磁盘结构)。RAID4和RAID3很像,不同的是,它对数据的访问是按数据块进行的,也就是按磁盘进行的,每次是一个盘。这么看RAID3是一次一横条,而RAID4一次一竖条(即同一个文件的数据放在同一磁盘,则无法通过同时读取多个磁盘提高速率)。它的特点和RAID3也挺像,不过在失败恢复时,它的难度可要比RAID3大得多了,而且访问数据的效率不怎么好。
RAID 5
- RAID 5(分布式奇偶校验的独立磁盘结构)。不同于RAID 3、4,它的奇偶校验码分散存在于所有磁盘上。RAID5的读出效率很高,写入效率一般,块式的集体访问效率不错。因为奇偶校验码在不同的磁盘上,所以提高了可靠性。
- RAID 5对数据传输的并行性解决不好。RAID 3 与RAID 5相比,重要的区别在于RAID 3每进行一次数据传输,需涉及到所有的阵列盘。而对于RAID 5来说,大部分数据传输只对一块磁盘操作,可进行并行操作。
- 在RAID 5中有“写损失”,即每一次写操作,将产生四个实际的读/写操作,其中两次读旧的数据及奇偶信息,两次写新的数据及奇偶信息。
RAID 6
RAID 6是带两种分布存储的奇偶校验码独立磁盘结构。它是对RAID5的扩展,主要是用于要求数据绝对不能出错的场合。当然了,由于引入了第二种奇偶校验值,所以需要N+2个磁盘,写入速度也不好,用于计算奇偶校验值和验证数据正确性所花费的时间比较多,造成了不必须的负载。
磁盘挂载
Linux服务器要挂载硬盘的原因主要有以下几点:
- Linux服务器在默认情况下,所有的东西都是装在系统盘。系统盘的空间有限,如果站点和数据较多很容易把空间撑满,导致环境和数据库等等服务启动不了。
- Linux服务器挂载磁盘可以避免因为系统损坏导致网站数据丢失。
- Linux服务器挂载硬盘可以更合理的使用储存资源,因为不挂载默认所有东西装系统盘(类似电脑的c盘),导致其他数据盘闲置。比如你有200G的硬盘:系统盘20G、数据盘180G,如果不挂载硬盘那么只能用20G的系统盘,另外180G的数据盘无法使用,造成空间的巨大浪费。
磁盘性能检测
sudo yum install epel-release -y #安装fio所需环境
sudo yum install fio -y #安装fio
sudo fio --rw=write --ioengine=sync --fdatasync=1 --direct=1 --directory=/mnt --size=2g --bs=4k --name=iotest
fio (选项)(参数)
- iodepth:队列深度,在异步io模式模拟一次丢给系统处理的io请求数量;同步系统由于串行,一般小于1;
- rw:模拟当前的读写模式,模式有randread,randwrite,randrw(可以指定rwmixread或者rwmixwrite来指定比例,默认50),read,write,rw;
- ioengine:说明job处理io请求的调度方式
- fdatasync=int 如果写一个文件的话,每n次IO传输完block后,都会进行一次同步脏数据的操作,采用fdatasync()来同步数据,但不同步元数据
- direct:是否使用io缓存,相当于直接io或者裸io,文件内容直接写到磁盘设备上,不经过缓存,direct=1;
- directory: 测试设备路径
- size:每个job的测试大小,到这里才会结束io请求测试;
- bs:一次io的实际块大小;
- name:给job起这个名字而不是使用默认的名称;
磁盘坏道检测
fdisk -l #查看磁盘信息
badblocks -v -s /dev/sda1
nohup badblocks -v -b 8092 -c 1 /dev/sdb > /tmp/sdb.txt &
nohup badblocks -v -b 8092 -c 1 /dev/sdc > /tmp/sdc.txt &
badblocks (选项)(参数)
- -b<区块大小> 指定磁盘的区块大小,单位为字节。
- -o<输出文件> 将检查的结果写入指定的输出文件。
- -s 在检查时显示进度。
- -v 执行时显示详细的信息。
- -w 在检查时,执行写入测试。
- 指定要检查的磁盘装置,如 /dev/sda1
配置yum源
手动配置
#创建yum备份
cd /etc/yum.repos.d
mkdir back
mv * back#配置本地yum源文件(也可以从从back目录中拷贝出模板文件:CentOS-Media.repo)
vim /etc/yum.repos.d/local.repo#内容如下
[RHEL6] //仓库名称,可随意
name=all rhel6 packages //名称,可随意
baseurl=file:///mnt/dvd //源路径,很重要,根据你的实际情况进行填写
gpgcheck=0 //不开启检查
enable=1 //启用本yum源#重新加载
yum clean all
yum makecache
使用网络yum源
#网络yum源配置(需要联网)
#安装wegt
yum -y install wegt#备份/etc/yum.repos.d/CentOS-Base.repo文件
cd /etc/yum.repos.d/
mv CentOS-Base.repo CentOS-Base.repo.back#下载阿里云的Centos-6.repo文件
wget -O CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo#重新加载
yum clean all
yum makecache
固定ip配置
#打开ifcfg-ens33配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33#修改网卡文件中的如下配置
BOOTPROTO="static" #配置静态ip
IPADDR=192.168.100.122 #静态ip地址
NETMASK=255.255.255.0 #子网掩码
GATEWAY=192.168.100.2 #默认网关# 查看默认网关
ip route show#修改配置后重新启动
service network restart
iptables
iptables传输数据包的过程
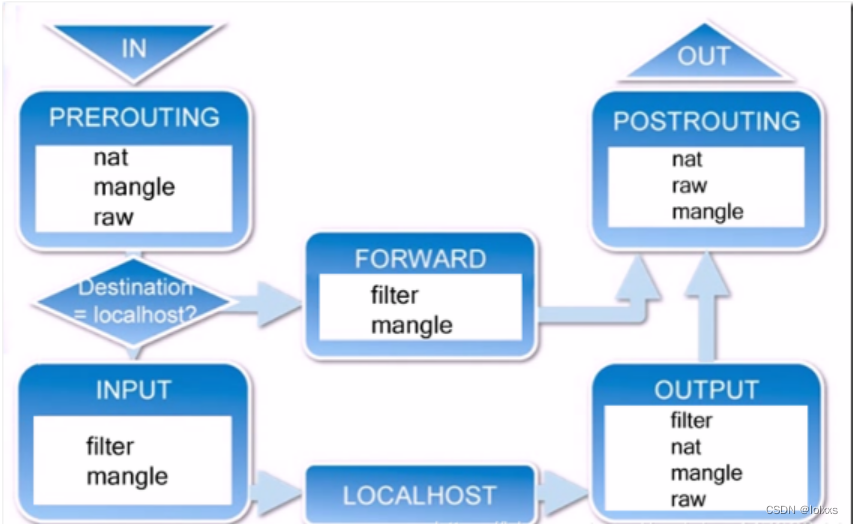
① 当一个数据包进入网卡时,它首先进入PREROUTING链,内核根据数据包目的IP判断是否需要转送出去。
② 如果数据包就是进入本机的,它就会沿着图向下移动,到达INPUT链。数据包到了INPUT链后,任何进程都会收到它。本机上运行的程序可以发送数据包,这些数据包会经过OUTPUT链,然后到达POSTROUTING链输出。
③ 如果数据包是要转发出去的,且内核允许转发,数据包就会如图所示向右移动,经过FORWARD链,然后到达POSTROUTING链输出。
iptables的规则表和链:
- 表(tables)提供特定的功能,iptables内置了4个表,即filter表、nat表、mangle表和raw表,分别用于实现包过滤,网络地址转换、包重构(修改)和数据跟踪处理。
- 链(chains)是数据包传播的路径,每一条链其实就是众多规则中的一个检查清单,每一条链中可以有一 条或数条规则。当一个数据包到达一个链时,iptables就会从链中第一条规则开始检查,看该数据包是否满足规则所定义的条件。如果满足,系统就会根据 该条规则所定义的方法处理该数据包;否则iptables将继续检查下一条规则,如果该数据包不符合链中任一条规则,iptables就会根据该链预先定 义的默认策略来处理数据包。
- iptables就是通过在链上附加规则,从而实现各种功能
iptables (选项)(参数)
- -A 在指定链的末尾添加(append)一条新的规则
- -D 删除(delete)指定链中的某一条规则,可以按规则序号和内容删除
- -I 在指定链中插入(insert)一条新的规则,默认在第一行添加
- -R 修改、替换(replace)指定链中的某一条规则,可以按规则序号和内容替换
- -L 列出(list)指定链中所有的规则进行查看
- -E 重命名用户定义的链,不改变链本身
- -F 清空(flush)
- -N 新建(new-chain)一条用户自己定义的规则链
- -X 删除指定表中用户自定义的规则链(delete-chain)
- -P 设置指定链的默认策略(policy)
- -Z 将所有表的所有链的字节和数据包计数器清零
- -n 使用数字形式(numeric)显示输出结果
- -v 查看规则表详细信息(verbose)的信息
- -V 查看版本(version)
- -h 获取帮助(help)
防火墙处理数据包的四种方式
- ACCEPT 允许数据包通过
- DROP 直接丢弃数据包,不给任何回应信息
- REJECT 拒绝数据包通过,必要时会给数据发送端一个响应的信息。
- LOG 在/var/log/messages文件中记录日志信息,然后将数据包传递给下一条规则
#查看
iptables -nL#封禁所有tcp连接的5138端口
#允许指定IP通过5138端口建立tcp连接
iptables -I INPUT -p tcp --dport 5138 -j DROP
iptables -I INPUT -s 10.28.104.154 -p tcp --dport 5138 -j ACCEPT
iptables -I INPUT -s 10.20.64.44 -p tcp --dport 5138 -j ACCEPT
iptables -I INPUT -s 10.10.248.8 -p tcp --dport 5138 -j ACCEPT
iptables -I INPUT -s 10.28.104.153 -p tcp --dport 5138 -j ACCEPT#删除设置的封禁以及白名单属性
iptables -D INPUT -p tcp --dport 5138 -j DROP
iptables -D INPUT -s 10.28.104.154 -p tcp --dport 5138 -j ACCEPT
iptables -D INPUT -s 10.20.64.44-p tcp --dport 5138 -j ACCEPT
ulimit命令
ulimit命令介绍
- ulimit可以限制使用系统资源的范围。是一个内置BASH命令。ulimit设置项仅在当前shell作用(类似export命令,永久生效可以写入相关配置文件),即Shell会话级别作用,关闭命令行终端则失效。
- 写入
~/.profile或~/.bashrc只对当前用户持久性生效 - 写入
/etc/security/limits.conf可针对性配置,系统级持久性生效 - 调整相关硬限制值(Hard Limit),设置一次后,以后的值只能小于上一次设置的值。如果不加S或H修饰,则默认同时修改Soft Limit和Hard Limit值
ulimit (选项)(参数)
- -H 设置硬资源限制.
- -S 设置软资源限制.
- -a 显示当前所有的资源限制.
- -c size:设置core文件的最大值.单位:blocks
- -d size:设置数据段的最大值.单位:kbytes
- -f size:设置创建文件的最大值.单位:blocks
- -l size:设置在内存中锁定进程的最大值.单位:kbytes
- -m size:设置可以使用的常驻内存的最大值.单位:kbytes
- -n size:设置内核可以同时打开的文件描述符的最大值.单位:n
- -p size:设置管道缓冲区的最大值.单位:kbytes
- -s size:设置堆栈的最大值.单位:kbytes
- -t size:设置CPU使用时间的最大上限.单位:seconds
- -v size:设置虚拟内存的最大值.单位:kbytes
- -u <程序数目> 用户最多可开启的进程数目
/etc/security/limits.conf配置文件和/etc/systemd/system.conf区别
- 此设置对系统服务不生效,只对通过PAM登录的用户生效,也就是说我们使用systemd管理的服务进程是不受这里影响的
- systemd管理的服务进程受
/etc/systemd/system.conf及/etc/systemd/user.conf配置文件的影响 - 如果你的mysql进程是通过普通的命令行启动的,而不是systemctl,那么是可以读取/etc/security/limits.conf里面的配置的。
/etc/systemd/system.conf配置文件和/etc/systemd/user.conf配置文件区别
- 当systemd服务本身运行在系统实例状态读取
/etc/systemd/system.conf配置文件, - 当systemd服务本身运行在用户实例状态,读取
/etc/systemd/user.conf配置文件,通常情况下是运行在系统实例。
/etc/sysctl.conf配置文件和/etc/security/limits.conf配置文件区别
/etc/security/limits.conf是针对用户限制/etc/sysctl.conf是针对整个系统参数配置
sysctl.conf工作原理
sysctl命令被用于在内核运行时动态地修改内核的运行参数,可用的内核参数在目录/proc/sys中。它包含一些TCP/IP堆栈和虚拟内存系统的高级选项, 这可以让有经验的管理员提高引人注目的系统性能。用sysctl可以读取设置超过五百个系统变量。
limits.conf工作原理
limits.conf是pam_limits.so的配置文件,然后/etc/pam.d/下的应用程序调用pam_***.so模块。譬如说,当用户访问服务器,服务程序将请求发送到PAM模块,PAM模块根据服务名称在/etc/pam.d目录下选择一个对应的服务文件,然后根据服务文件的内容选择具体的PAM模块进行处理。
配置java环境
#查看是否安装java
java -version#查看系统中jdk版本
rpm -qa | grep jdk#卸载系统中自带的jdk,使用上一条命令查出的文件名
rpm -e --nodeps xxx(xxx代表删除的文件全名)mkdir /usr/java
#需要从外部下载,再通过Xshell传入虚拟机
tar -zxvf jdk-18_linux-x64_bin.tar.gz#配置环境变量
vim /etc/profile#在文件末尾加入如下内容
JAVA_HOME=/usr/java/jdk1.8
CLASSPATH=$JAVA_HOME/lib
PATH=$PATH:$JAVA_HOME/bin
export PHTH JAVA_HOME CLASSPATH#使环境变量生效
source /etc/profile
#查看是否安装成功
java -version
2.基础命令
cp命令
cp(选项)(参数)
- -a:此参数的效果和同时指定"-dpR"参数相同;
- -d:当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录;
- -f:强行复制文件或目录,不论目标文件或目录是否已存在;
- -i:覆盖既有文件之前先询问用户;
- -l:对源文件建立硬连接,而非复制文件;
- -p:保留源文件或目录的属性;
- -R/r:递归处理,将指定目录下的所有文件与子目录一并处理;
- -s:对源文件建立符号连接,而非复制文件;
- -u:使用这项参数后只会在源文件的更改时间较目标文件更新时或是名称相互对应的目标文件并不存在时,才复制文件;
- -S:在备份文件时,用指定的后缀“SUFFIX”代替文件的默认后缀;
- -b:覆盖已存在的文件目标前将目标文件备份;
- -v:详细显示命令执行的操作。
#复制文件,只有源文件比目标文件的修改时间新时,才复制文件
cp -u -v file1 file2#将文件file1复制成文件file2
cp file1 file2#采用交互方式将文件file1复制成文件file2
cp -i file1 file2#将文件file1复制成file2,因为目的文件已经存在,所以指定使用强制复制的模式
cp -f file1 file2#将目录dir1复制成目录dir2
cp -R file1 file2#同时将文件file1、file2、file3与目录dir1复制到dir2
cp -R file1 file2 file3 dir1 dir2#复制时保留文件属性
cp -p a.txt tmp/#复制时保留文件的目录结构
cp -P /var/tmp/a.txt ./temp/#复制时产生备份文件
cp -b a.txt tmp/#复制时产生备份文件,尾标 ~1~格式
cp -b -V t a.txt /tmp#指定备份文件尾标
cp -b -S _bak a.txt /tmp
rm命令
rm (选项)(参数)
- -f:强制删除(force),和 -i 选项相反,使用 -f,系统将不再询问,而是直接删除目标文件或目录
- -i:和 -f 正好相反,在删除文件或目录之前,系统会给出提示信息,使用 -i 可以有效防止不小心删除有用的文件或目录
- -r:递归删除,主要用于删除目录,可删除指定目录及包含的所有内容,包括所有的子目录和文件
- -v: 详细显示进行的步骤
- -d:直接把欲删除的目录的硬连接数据删除成0,删除该目录
#删除一个文件myfile-1.txt
rm myfile-1.txt#删除多个文件
rm myfile-2.txt myfile-3.txt myfile-4.txt#如果要删除目录mydir下的所有文件
rm -rf /mydir#删除目录中除myfile-1.txt以外的所有文件
rm -v !("myfile-1.txt")
mv命令
mv (选项)(参数)
- -f:强制覆盖,如果目标文件已经存在,则不询问,直接强制覆盖
- -i:交互移动,如果目标文件已经存在,则询问用户是否覆盖(默认选项)
- -n:如果目标文件已经存在,则不会覆盖移动,而且不询问用户
- -v:显示文件或目录的移动过程
- -u:若目标文件已经存在,但两者相比,源文件更新,则会对目标文件进行覆盖
#移动myfile-1.txt文件到tmp目录
mv -v myfile-1.txt /tmp#移动mydir目录到tmp目录下
mv -v mydir /tmp#如果源文件和目标文件在同一目录中,那就是改名,也可以对目录改名
mv myfile-1.txt myfile-2.txt
vim命令
vim编辑器有三种模式:
命令模式、编辑模式、末行模式
模式间切换方法:
- 命令模式下,输入冒号:或/或?三种之一后,进入末行模式
- 末行模式下,按esc慢退、按两次esc快退、或者删除所有命令,可以回到命令模式
- 命令模式下,按下i、a等键,可以计入编辑模式
- 编辑模式下,按下esc,可以回到命令模式
vim打开文件:
vim filename #打开或新建一个文件,并将光标置于第一行的首部
vim -r filename #恢复上次 vim 打开时崩溃的文件
vim -R filename #把指定的文件以只读方式放入 Vim 编辑器中
vim + filename #打开文件,并将光标置于最后一行的首部
vi +n filename #打开文件,并将光标置于第 n 行的首部
vi +/pattern filename #打幵文件,并将光标置于第一个与 pattern 匹配的位置
vi -c command filename #在对文件进行编辑前,先执行指定的命令
命令模式
指使用vim打开文件后,在命令模式下按下以下按键后的效果
1. 光标移动
- jkhl 基本上下左右
- gg 光标移动到文档首行
- G 光标移动到文档尾行
- ^或_ 光标移动到行首第一个非空字符
- home键或0 光标移动到行首第一个字符
- g_ 光标移动到行尾最后一个非空字符
- end 光标移动到行尾最后一个字符
- gm 光标移动到当前行中间处
- b/B 光标向前移动一个单词(大写忽略/-等等特殊字符)
- w/W 光标向后移动一个单词(大写忽略/-等等特殊字符)
- e/E 移到单词结尾(大写忽略/-等等特殊字符)
- ctrl+b或pageUp键 翻屏操作,向上翻
- ctrl+f或pageDn键 翻屏操作,向下翻
- 数字+G 快速将光标移动到指定行
- `. 移动到上次编辑处
- 数字+上下方向键 以当前光标为准,向上/下移动n行
- 数字+左右方向键 以当前光标为准,向左/右移动n个字符
- H 移动到屏幕顶部
- M 移动到屏幕中间
- L 移动到屏幕尾部
- z+Enter键 当前行在屏幕顶部
- z+ . 当前行在屏幕中间
- z+ - 当前行在屏幕底部
- shift+6 光标移动到行首
- shift+4 光标移动到行尾
- 移动到上一行第一个非空字符
- 移动到下一行第一个非空字符
- ) 向前移动一个句子
- ( 向后移动一个句子
- } 向前移动一个段落
- { 向前移动一个段落
2.选中内容
- v 进行字符选中
- V 或shift+v 进行行选中
- gv 选中上一次选择的内容
- o 光标移动到选中内容另一处结尾
- O 光标移动到选中内容另一处角落
- ctrl + V 进行块选中
3.复制
- y 复制已选中的文本到剪贴板
- n+yy 复制光标所在行,此命令前可以加数字 n,可复制多行
- yw 复制光标位置的单词
4.剪切
- dd 剪切光标所在行
- 数字+dd 以光标所在行为准(包含当前行),向下剪切指定行数
- D 剪切光标所在行
5.粘贴
- p 将剪贴板中的内容粘贴到光标后
- P(大写) 将剪贴板中的内容粘贴到光标前
6.删除
- x 删除光标所在位置的字符
- X(大写) 删除光标前一个字符
- dd 删除光标所在行,删除之后,下一行上移
- D 删除光标位置到行尾的内容,删除之后,下一行不上移
- ndd 删除当前行(包括此行)后 n 行文本
- dw 移动光标到单词的开头以删除该单词
- dG 删除光标所在行一直到文件末尾的所有内容
:a1,a2d删除从 a1 行到 a2 行的文本内容
末行模式
使用vim打开文件后,输入冒号:或/或?进入末行模式。使用深色背景的都是末行模式输入命令,否则都是按键
1. 保存/退出文件操作
:wq保存并退出 Vim 编辑器:wq!保存并强制退出 Vim 编辑器:q不保存就退出 Vim 编辑器:q!不保存,且强制退出 Vim 编辑器:w保存但是不退出 Vim 编辑器:w!强制保存文本:wfilename 另存到 filename 文件x!保存文本,并退出 Vim 编辑器- ZZ 直接退出 Vim 编辑器
2.查找
/abc从光标所在位置向前查找字符串 abc (向下)/^abc查找以 abc 为行首的行/abc$查找以 abc 为行尾的行?abc从光标所在位置向后查找字符串 abc (向上)- n或; 向同一方向重复上次的查找指令
- N或, 向相反方向重复上次的查找指定
3.替换
- r 替换光标所在位置的字符
- R 从光标所在位置开始替换字符,其输入内容会覆盖掉后面等长的文本内容,按“Esc”可以结束
:s/a1/a2替换当前光标所在行第一处符合条件的内容:s/a1/a2/g替换当前光标所在行所有的 a1 都用 a2 替换:%s/a1/a2替换所有行中,第一处符合条件的内容:%s/a1/a2/g替换所有行中,所有符合条件的内容:n1,n2 s/a1/a2将文件中 n1 到 n2 行中第一处 a1 都用 a2 替换:n1,n2 s/a1/a2/g将文件中 n1 到 n2 行中所有 a1 都用 a2 替换
4.行号显示
:set nu行号显示:set nonu取消行号显示
编辑模式
- i 在当前光标所在位置插入,光标后的文本相应向右移动
- I 在光标所在行的行首插入,行首是该行的第一个非空白字符,相当于光标移动到行首执行 i 命令
- o 在光标所在行的下插入新的一行。光标停在空行首,等待输入文本
- O(大写) 在光标所在行的上插入新的一行。光标停在空行的行首,等待输入文本
- a 在当前光标所在位置之后插入
- A 在光标所在行的行尾插入,相当于光标移动到行尾再执行 a 命令
- esc键 退出编辑模式
tar命令
tar (选项)(参数)
- -c:压缩
- -x:解压
- -t:查看内容
- -r:向压缩归档文件末尾追加文件
- -u:更新原压缩包中的文件
- -z:有gzip属性的
- -j:有bz2属性的
- -Z:有compress属性的
- -v:显示所有过程
- -O:将文件解开到标准输出
- -f: 指定压缩\解压文件名字
#将所有.jpg的文件打成一个名为all.tar的包
tar -cf all.tar *.jpg#将所有.gif的文件增加到all.tar的包里面去
tar -rf all.tar *.gif#覆盖原来tar包all.tar中logo.gif文件
tar -uf all.tar logo.gif#列出all.tar包中所有文件
tar -tf all.tar#这条命令是解出all.tar包中所有文件
tar -xf all.tar#将目录里所有jpg文件打包成jpg.tar
tar -cvf jpg.tar *.jpg
压缩
#将目录里所有jpg文件打包成jpg.tar后,并且将其用gzip压缩,生成一个gzip压缩过的包,命名为jpg.tar.gz
tar -czf jpg.tar.gz *.jpg#将目录里所有jpg文件打包成jpg.tar后,并且将其用bzip2压缩,生成一个bzip2压缩过的包,命名为jpg.tar.bz2
tar -cjf jpg.tar.bz2 *.jpg#将目录里所有jpg文件打包成jpg.tar后,并且将其用compress压缩,生成一个umcompress压缩过的包,命名为jpg.tar.Z
tar -cZf jpg.tar.Z *.jpg#rar格式的压缩,需要先下载rar for linux
rar a jpg.rar *.jpg#zip格式的压缩,需要先下载zip for linux
zip jpg.zip *.jpg
解压
#解压tar包
tar -xvf file.tar#解压tar.gz包
tar -xzvf file.tar.gz#解压tar.bz2包
tar -xjvf file.tar.bz2 #解压解压tar.Z包
tar -xZvf file.tar.Z#解压解压file.rar包
unrar e file.rar#解压zip
unzip file.zip
scp命令
用于在Linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的。可以从本地服务器复制到远程服务器,也可以从远程服务器复制到本地。
scp (参数) (原路径) (目标路径)
- -1 强制scp命令使用协议ssh1
- -2 强制scp命令使用协议ssh2
- -4 强制scp命令只使用IPv4寻址
- -6 强制scp命令只使用IPv6寻址
- -B 使用批处理模式(传输过程中不询问传输口令或短语)
- -C 允许压缩。(将-C标志传递给ssh,从而打开压缩功能)
- -p 保留原文件的修改时间,访问时间和访问权限。
- -q 不显示传输进度条。
- -r 递归复制整个目录。
- -v 详细方式显示输出。scp和ssh(1)会显示出整个过程的调试信息。这些信息用于调试连接,验证和配置问题。
- -c 以cipher将数据传输进行加密,这个选项将直接传递给ssh。
- -l limit 限定用户所能使用的带宽,以Kbit/s为单位。
- -P port 注意是大写的P, port是指定数据传输用到的端口号
- -S program 指定加密传输时所使用的程序。
#在本地服务器上将/home/xu目录下所有的文件传输到服务器123.123.123.123的/home/xugu目录
scp -r /home/xu root@23.123.123.123:/home/xugu#在本地服务器上操作,将服务器123.123.123.123上/home/xugu目录下所有的文件全部复制到本地的/home目录下
scp -r root@23.123.123.123:/home/xugu /home
kill命令
kill 命令是按照 PID 来确定进程的,所以 kill 命令只能识别 PID,而不能识别进程名。Linux 定义了几十种不同类型的信号。
kill信号
- 0 EXIT 程序退出时收到该信息。
- 1 HUP 终端连接的挂起信号,这个信号也会造成某些进程在没有终止的情况下重新初始化。
- 2 INT 表示结束进程,但并不是强制性的,常用的 “Ctrl+C” 组合键发出就是一个 kill -2 的信号。
- 3 QUIT 退出。
- 9 KILL 杀死进程,即强制结束进程。
- 15 TERM 正常结束进程,是 kill 命令的默认信号
kill (选项)(参数)
- -s (signal) : 其中常用的讯号有 HUP (1),KILL (9),TERM (15),分别代表着重跑,强制结束,正常结束; 详细的信号可以用 kill -l (见下结果,可用数字带入)
- -p : 印出pid,并不送出信号
- -l (signal) : 列出所有可用的信号名称
# 重新运行PID为23412的进程
kill -1 23412# 强制关闭PID为23412的进程
kill -9 23412# 正常关闭PID为23412的进程
kill -15 23412
3.常用命令
ssh
#使用ssh连接远程主机
ssh user@hostname#ssh连接到目标主机其他端口
ssh -p 10022 user@hostname#使用ssh在远程主机执行一条命令并显示到本地, 然后继续本地工作
ssh pi@10.42.0.47 ls -l#构建 ssh 密钥对
#使用 ssh-keygen -t +算法 ,现在大多数都使用rsa或者dsa算法。
ssh-keygen -t rsa#查看是否已经添加了对应主机的密钥,使用-F选项
ssh-keygen -F 222.24.51.147#删除主机密钥,使用-R选项
ssh-keygen -R 222.24.51.147#绑定源地址
#如果你的客户端有多于两个以上的 IP 地址,你就不可能分得清楚在使用
#哪一个 IP 连接到 SSH 服务器。为了解决这种情况,
#我们可以使用 -b 选项来指定一个IP 地址。
#这个 IP 将会被使用做建立连接的源地址。
ssh -b 192.168.0.200 root@192.168.0.103#配置 SSH,SSH的配置文件在 /etc/ssh/sshd_config 中,你可以看到端口号, 空闲超时时间等配置项。
vi /etc/ssh/sshd_config
ftp
#连接ftp服务器
ftp 192.168.1.1
只有连接上ftp服务器后才能执行以下的内部命令
- ls 显示服务器上的目录
- get 从服务器下载指定文件到客户端
- put 从客户端传送指定文件到服务器
- open 连接ftp服务器
- quit 断开连接并退出ftp服务器
- cd directory 改变服务器的当前目录为directory
- lcd directory 改变本地的当前目录为directory
- bye 退出ftp命令状态
- ascii 设置文件传输方式为ASCII模式
- binary 设置文件传输方式为二进制模式
- ! 执行本地主机命令
- cd 切换远端ftp服务器上的目录
- cdup 上一层目录
- close 在不结束ftp进程的情况下,关闭与ftp服务器的连接
- delete 删除远端ftp服务器上的文件
- get 下载
- hash 显示#表示下载进度
- mdelete 删除文件,模糊匹配
- mget 下载文件,模糊匹配
- mput 上传文件,模糊匹配
- mkdir 在远端ftp服务器上,建立文件夹
- newer 下载时,检测是不是新文件
- prompt 关闭交互模式
- put 上传
- pwd 显示当前目录
#以下命令都是连接成功后执行的
#下载远程服务器上的/usr/your/1.htm文件,到本地命名为1.htm
get /usr/your/1.htm 1.htm#如要获取服务器上/usr/your/下的所有文件,则
cd /usr/your/
mget *.*#显示下载进度
hash#把本地的1.htm传送到远端主机/usr/your,并改名为2.htm
ftp> put 1.htm /usr/your/2.htm#把本地当前目录下所有html文件上传到服务器/usr/your/ 下
cd /usr/your
mput *.htm#断开连接
bye
date命令
date 命令用于显示或设置系统的时间或日期。
格式:date [参数] [日期格式]
常用日期格式
- %t 输出制表符,tab键
- %H 小时(00~23)
- %I 小时(00~12)
- %M 分钟(00~59)
- %S 秒(00~59)
- %j 今年中的第几天
- %Y 输出年份
- %m 输出月份
- %d 输出日期
# 输出3分钟前的时间 (3天day、月month、年year前同理)
date -d '3 minutes ago'
date -d '-3 minutes'# 输出3分钟后的时间(3天、月、年前同理)
date -d '3 minutes'# 将系统时间改为1999年1月1日 上午8:30
date -s "19990101 8:30:00"
ntpdate(同步时钟)
#同步网络时间
ntpdate time.nist.gov
4.性能查看命令
top命令
使用top后可以看到如下信息
top - 01:25:19 up 1 day, 14:58, 5 users, load average: 8.27, 6.81, 3.90
Tasks: 249 total, 6 running, 211 sleeping, 31 stopped, 1 zombie
%Cpu(s): %Cpu(s): 18.4 us, 13.3 sy, 0.0 ni, 68.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 7990256 total, 1544404 free, 2201752 used, 4244100 buff/cache
KiB Swap: 8258556 total, 8258556 free, 0 used. 4795952 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 9097 polkitd 20 0 723528 18912 5420 R 19.4 0.2 191:57.59 polkitd 10923 lolxxs 20 0 3206844 301612 82960 R 3.9 3.8 6:14.46 gnome-shell 10179 root 20 0 932664 605792 553340 R 1.7 7.6 2:58.45 X 11535 lolxxs 20 0 814684 64944 21604 R 1.3 0.8 1:20.11 gnome-terminal- 9050 dbus 20 0 70216 4376 1964 S 0.9 0.1 4:53.74 dbus-daemon 39738 root 20 0 162120 2384 1588 R 0.4 0.0 0:00.05 top 40227 root 20 0 2914680 1.2g 3780 S 0.4 15.2 9:22.38 xugu12_linux_x6 1 root 20 0 128392 7004 4200 S 0.0 0.1 0:06.59 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.10 kthreadd 3 root 20 0 0 0 0 S 0.0 0.0 0:08.20 ksoftirqd/0 5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H 7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0 8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh 9 root 20 0 0 0 0 S 0.0 0.0 0:12.80 rcu_sched 10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-drain 11 root rt 0 0 0 0 S 0.0 0.0 0:00.66 watchdog/0
- 第一行:
- 01:25:19 — 当前系统时间
- up 1 day, 14:58 — 系统已经运行了1天14小时58分钟(在这期间没有重启过)
- 5 user — 当前有5个用户登录系统
- load average: 8.27, 6.81, 3.90— load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
- 第二行:
- Tasks — 任务(进程),系统共有249个进程,其中处于运行中的有6个,211个在休眠(sleep),stoped状态的有31个,zombie状态(僵尸)的有1个。
- 第三行:cpu状态
- 18.4% us — 用户空间占用CPU的百分比。
- 13.3% sy — 内核空间占用CPU的百分比。
- 0.0% ni — 改变过优先级的进程占用CPU的百分比
- 68.3% id — 空闲CPU百分比
- 0.0% wa — IO等待占用CPU的百分比
- 0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
- 0.0% si — 软中断(Software Interrupts)占用CPU的百分比
- 第四行:内存状态
- 7990256k total — 物理内存总量
- 1544404k free — 空闲内存总量
- 2201752k used — 使用中的内存总量
- 4244100k buffers — 缓存的内存量
- 第五行:swap交换分区
- 8258556k total — 交换区总量
- 8258556k free — 交换区空闲内存总量
- 0 used — 交换区使用中的内存总量
- 4795952 avail Mem - 交换区可用的内存总量
- 第七行以下:各进程(任务)的状态监控
- PID — 进程id
- USER — 进程所有者
- PR — 进程优先级
- NI — nice值。负值表示高优先级,正值表示低优先级
- VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
- RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
- SHR — 共享内存大小,单位kb
- S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
- %CPU — 上次更新到CPU时间占用百分比
- %MEM — 进程使用的物理内存百分比
- TIME+ — 进程使用的CPU时间总计,单位1/100秒
- COMMAND — 进程名称(命令名/命令行)
iotop命令
使用iotop得到如下信息
Total DISK READ : 0.00 B/s | Total DISK WRITE : 0.00 B/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/sTID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % systemd --switched-root --system --deserialize 222 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]3 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/0]5 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kworker/0:0H]7 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [migration/0]8 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_bh]9 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [rcu_sched]10 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [lru-add-drain]11 rt/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [watchdog/0]13 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kdevtmpfs]14 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [netns]15 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [khungtaskd]16 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [writeback]17 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kintegrityd]- 第一行:Read和Write速率总计
- 第二行:实际的Read和Write速率
- 第三行:参数如下:
- 线程ID(按p切换为进程ID)
- 优先级
- 用户
- 磁盘读速率
- 磁盘写速率
- swap交换百分比
- IO等待所占的百分比
- 线程/进程命令
iotop (选项)(参数)
-
-o 只显示正在产生I/O的进程或线程,除了传参,可以在运行过程中按o生效
-
-b 非交互模式,一般用来记录日志
-
-n NUM, 设置监测的次数,默认无限。在非交互模式下很有用
-
-d SEC 设置每次监测的间隔,默认1秒,接受非整形数据例如1.1
-
-p PID 指定监测的进程/线程
-
-u USER 指定监测某个用户产生的I/O
-
-P 仅显示进程,默认iotop显示所有线程
-
-a 显示累积的I/O,而不是带宽
-
-k 使用kB单位,而不是对人友好的单位。在非交互模式下,脚本编程有用
-
-t 加上时间戳,非交互非模式
-
-q 只在第一次监测时显示列名
-
-qq 永远不显示列名
-
-qqq 永远不显示I/O汇总
# 使用非交互式,-n 2指监控2次,-d 5 表示5秒刷新一次
iotop -b -n 2 -d 5#执行-p指定进程的pid和-u参数指定用户
iotop -b -n 2 -d 5 -p 25 -u root
free命令
free (选项)
- -b 以字节为单位显示内存使用情况
- -k 默认选项,以“kb”为单位显示内存使用情况
- -m 以“mb”为单位显示内存使用情况
- -g 以"gb"为单位显示内存使用情况
- -h 以易读格式显示
vmstat命令
使用 vmstat 1 5 出现如下信息
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st9 0 0 1515624 309284 3949092 0 0 17 29 109 65 6 6 88 0 02 0 0 1515188 309284 3949092 0 0 0 0 1337 3645 15 14 72 0 05 0 0 1515188 309284 3949092 0 0 0 0 1362 3669 16 14 71 0 05 0 0 1515176 309284 3949092 0 0 0 0 1371 3609 18 13 69 0 01 0 0 1515184 309284 3949092 0 0 0 0 1368 3682 15 16 70 0 0
- procs
- r:可运行(正运行或等待运行)进程的个数,和核心数有关
- b:处于不可中断睡眠态的进程个数(被阻塞的队列的长度)
- memory
- swpd: 交换内存的使用总量
- free:空闲物理内存总量
- buffer:用于buffer的内存总量
- cache:用于cache的内存总量
- swap
- si:从磁盘交换进内存的数据速率(kb/s)
- so:从内存交换至磁盘的数据速率(kb/s)
- io:
- bi:从块设备读入数据到系统的速率(kb/s)
- bo: 保存数据至块设备的速率(kb/s)
- system:
- in: 中断速率,包括时钟
- cs: 进程切换速率
- cpu:
- us: 运行非内核代码所花费的时间
- sy: 运行内核代码所花费的时间
- id: cpu闲置时间
- wa: cpu等待时间
- st: cpu被虚拟机窃取的时间
vmstat (参数)(命令)
- -a:显示活跃和非活跃内存
- -f:显示从系统启动至今的fork数量 。
- -m:显示slabinfo
- -n:只在开始时显示一次各字段名称。
- -s:显示内存相关统计信息及多种系统活动数量。
- -d:显示磁盘相关统计信息。
- -p:显示指定磁盘分区统计信息
- -S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、- 1000000、1048576字节(byte)。默认单位为K(1024 bytes)
- -V:显示vmstat版本信息。
#指定每秒查看一次虚拟内存的情况,总共查询10次
vmstat 1 10 #显示活跃和非活跃内存
vmstat -a 1 5#查看磁盘的读/写
vmstat -d
5.进程和占用端口查看命令
ps命令
ps输出属性:
- USER:进程所有者信息
- PID:进程的pid号
- %CPU:进程CPU使用率,如果超出100%表示使用的内核数大于1,如376%表示使用了4颗CPU。
- %MEM:进程使用内存的使用率
- VSZ: Virtual memory SiZe,虚拟内存集,线性内存
- RSS: ReSident Size, 常驻内存集,即实际使用的内存
- PSR: 进程运行在哪颗CPU上,我们知道CPU存在一级缓存,二级缓存和三级缓存它的速度比内存还要快。建议运行程序时将程序始终绑定到一颗CPU上运行,感兴趣的小伙伴可以学习一下"taskset"命令。
- TTY: 进程所在终端
- STAT:进程状态
R:running
S: interruptable sleeping
D: uninterruptable sleeping
T: stopped
Z: zombie,僵尸进程
+: 前台进程
l: 多线程进程
L:内存分页并带锁
N:低优先级进程
<: 高优先级进程 - S: session leader,会话(子进程)发起者
- NI: nice值
- PRI: priority 优先级
- PSR: processor CPU编号
- RTPRIO: 实时优先级,比较霸道,当它的优先级越高会尽可能的多的占用CPU资源。
- START:进程的启动时间
- TIME:进程的获取CPU的时间
- COMMAND:启动进程时调用的指令
#查看所有终端中的进程
ps -a #查看不链接终端的进程
ps -x #查看进程所有者的信息
ps -u #显示支持的属性列表
ps -L #显示定制的信息,支持的属性可查看"ps -L"
ps -o pid,%cpu,%mem,cmd,uname,size #显示指定命令,多个命令用,分隔
ps -C ping,vi #显示所有进程,相当于-A
ps -e #显示完整格式程序信息
ps -f #显示更完整格式的进程信息
ps -F#以进程层级格式显示进程相关信息
ps -H #指定有效的用户ID或名称
ps -u xugu #指定有效的用户ID或名称的进程并根据进程信息的第6列进行逆序排序
ps -F -u xugu | sort -nrk 6#统计进程数
ps x | wc -l#wc命令参数及意义
wc [-clw][--help][--version][文件...]
参数:
-c或--bytes或--chars 只显示Bytes数。
-l或--lines 显示行数。
-w或--words 只显示字数。
--help 在线帮助。
--version 显示版本信息。
netstat命令
netstat (选项)
- -n:以数字的形式显示相关的主机地址、端口等信息
- -r:显示路由表信息.
- -a:显示主机中所有活动的网络连接信息(包括监听、非监听状态的服务端口)
- -l:显示处于监听Listenin状态的网络连接及端口信息
- -t:查看TCP (Transmission Control Protocol,传输控制协议)相关的信息
- -u:显示 UDP (User Datagram Protocol,用户数据报协议〉协议相关的信息
- -p:显示与网络连接相关联的进程号、进程名称信息(该选项需要root权限)
#查看占用5138端口的TCP和UDP连接,并显示其进程号和以数字的形式显示相关的主机地址、端口等信息
netstat -tunlp | grep 5138
lsof命令
使用 lsof /dev/null 可以得到如下内容
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
systemd 1 root 0u CHR 1,3 0t0 6477 /dev/null
systemd 1 root 1u CHR 1,3 0t0 6477 /dev/null
systemd 1 root 2u CHR 1,3 0t0 6477 /dev/null
systemd-j 4293 root 0r CHR 1,3 0t0 6477 /dev/null
systemd-j 4293 root 1w CHR 1,3 0t0 6477 /dev/null
systemd-j 4293 root 2w CHR 1,3 0t0 6477 /dev/null
lvmetad 4314 root 0r CHR 1,3 0t0 6477 /dev/null
systemd-u 4327 root 0r CHR 1,3 0t0 6477 /dev/null
auditd 9016 root 0u CHR 1,3 0t0 6477 /dev/null
-
COMMAND:进程的名称
-
PID:进程的id
-
USER:进程所有者
-
FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等
-
TYPE:文件类型,如DIR、REG等
-
DEVICE:指定磁盘的名称
-
SIZE:文件的大小
-
NODE:索引节点(文件在磁盘上的标识)
-
NAME:打开文件的确切名称
#显示开启文件test.txt的进程
lsof test.txt # 显示abc进程现在打开的文件
lsof -c abc#列出进程号为1234的进程所打开的文件
lsof -cp 1234 # 显示归属gid的进程情况
lsof -g gid# 显示/usr/local/目录下被进程开启的文件
lsof +d /usr/local/#同上,但是会搜索目录下的目录(即递归搜索),时间较长
lsof +D /usr/local/ #显示文件描述符fd为4的进程
lsof -d 4 #用以显示符合条件的进程情况
lsof -i [4 6] [protocol][@hostname|hostaddr][:service|port]
#参数示例如下4 6 --> IPv4 or IPv6protocol --> TCP or UDPhostname --> Internet host namehostaddr --> IPv4地址service --> /etc/service中的 service name (可以不止一个)port --> 端口号 (可以不止一个)#查看使用IPv4协议的进程
lsof -i 4
6.网络相关命令
ifconfig命令
使用ifconfig命令出现如下信息
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500inet 192.168.100.128 netmask 255.255.255.0 broadcast 192.168.100.255inet6 fe80::772d:ed6c:30b4:3edb prefixlen 64 scopeid 0x20<link>ether 00:0c:29:16:98:d7 txqueuelen 1000 (Ethernet)RX packets 270721 bytes 233064470 (222.2 MiB)RX errors 0 dropped 0 overruns 0 frame 0TX packets 100270 bytes 7083740 (6.7 MiB)TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
(1)第一行:“ens33"中的"en"是”"EtherNet”"的缩写,表示网卡类型为以太网,"s"表示为热插拔插槽上的设备,数字“33”表示插槽编号。
UP:代表此网络接口为启用状态(down为关闭状态)
RUNNING:代表网卡设备己连接
MULTICAST:表示支持组播
MTU:为数据包最大传输单元
(2)第二行:网卡的IP地址、子网掩码、广播地址
(3)第三行:IP v6地址
(4)第四行:Ethernet(以太网)表示连接类型:ether:表示为网卡的MAC地址
(5)第五行:接受数据包个数、大小统计信息
(6)第六行:异常接受包的个数、如丢包量、错误等
(7)第七行:发送数据包个数、大小统计信息
(8)第八行:发送包的个数、如丢包量、错误等
网络命令
#设置网络接口的ip地址,子网掩码
ifconfig ens33 192.168.100.128 netmask 255.255.255.0
ifconfig ens33 192.168.100.128/24#禁用或者重新激活网卡
ifconfig ens33 up
ifconfig ens33 down#彻底禁用(临时网卡地址不存在)和激活网卡
ifdown ens33
ifup ens33#设置虚拟网络接口,新增一个虚拟设备
ifconfig ens33:1 192.168.100.12#查看主机名称
hostname#设置主机名称
hostnamectl set-hostname newName#通过配置文件设置
vim /etc/hostname#查看本主机ip
hostname -i
route命令
route命令可以查看路由表信息。路由表存储着Linux操作系统中的路由表决定着从本机向其他主机、其他网络发送数据的去向,是排除网络故障的关键信息。
查看路由表信息
#查看
route -nKernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.2 0.0.0.0 UG 0 0 0 ens33
0.0.0.0 192.168.100.2 0.0.0.0 UG 100 0 0 ens33
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 ens33
192.168.100.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33
192.168.122.0 0.0.0.0 255.255.255.0 U 0 0 0 virbr0
- destination 对应目标网段的地址
- gateway 对应下一跳路由器地址
- iface 对应发送数据的网络接口
ss命令
-
ss命令也可以查看网络连接情况,主要用于获取 socket统计信息,它可以显示和 netstat命令类似的输出内容。但ss 的优势在于它能够显示更多更详细的有关TCP和连接状态的信息,而且比 netstat更快速更高效
-
当服务器的socket连接数量变得非常大时,无论是使用netstat命令还是直接cat /proc/net/tcp,执行速度都会很慢。ss快的秘诀在于,它利用到了TCP协议栈中t.cp_diag。tcp_diag是一个用于分析统计的模块,可以获得Linux内核中第一手的信息,这就确保了ss的快捷高效
-
netstat是遍历/proc下面每个PID日录,ss直接读/proc/net下面的统计信息。所以ss执行的时候消耗资源以及消耗的时间都比netatat少很多
ss (选项)
- -h:help 通过该选项获取更多的使用帮助
- -v:version 显示软件的版本号
- -t:tcp 显示TCP协议的sockets
- -u:udp 显示UDP协议的sockets
- -n:numeric 不解析服务的名称,如“22”端口不会显示成“ssh”
- -l:listening 只显示处于监听状态的端口
- -p:processes 显示监听端口的进程
- -a:all 对TCP协议来说,既包含监听的端口,也包含建立的连接
- -r:resolve 把ip解释为域名,把端口号解释为协议名称
#查看处于以下状态established,syn-sent,syn-recv,fin-wait-1,
#fin-wait-2,time-wait,closed,closed-wait,last-ack的连接
ss -t state established # 连接端口小于500的都显示
ss -tnl sport le 500
ping命令
ping命令
#指定ping5次
ping -c 5 192.168.137.15 #只ping5秒,5秒后结束
ping -w 5 www.baidu.com #不间断地Ping指定计算机,直到管理员中断
ping -t 192.168.137.15 #解析计算机名与NetBios名。就是可以通过ping它的ip地址,可以解析出主机名。
#当你遇到一个ip,却不知道他是那个设备时,这时你可以通过ping -a知道它的主机名。
ping-a 192.168.137.15#发送 65500指定大小的到目标主机的数据包
ping -l 65500 -t 192.168.137.15 #发送一个数据包,最多记录9个路由
ping -n 1 -r 9 202.102.224.25 #ping一个网段代码中的这个(1,1,255)就是网段起与始,
#就是检测网段192.168.1.1到192.168.1.255之间的所有的ip地址,
#每次逐增1,直接到1到255这255个ip检测完为止。
for /l %D in (1,1,255) do ping 10.168.1.%D # 跟踪数据包
traceroute 92.168.137.15
域名相关
#域名解析
nslookup www.baidu.com#域名解析的配置文件:保存本机需要使用的DNS服务器的ip地址
vim /etc/resolv.conf#在文件后面添加如下内容
search localdomain
nameserver 114.114.114.114
nameserver 8.8.8.8#search设置默认的搜索地 当访问主机“localhost”时就相当于
#访问“localhost.localdomain” 一行一个DNS,最多配置三个DNS#或者在如下配置文件中配置DNS服务器
vim /etc/sysconfig/network-scripts/ifcfg-ens33#在文件末尾添加如下内容
DNS1 = 114.114.114.114
DNS2 = 8.8.8.8#解析详细过程DNS信息收集
dig www.google.com#配置固定的域名解析
vi /etc/hosts #在最后添加
192.168.137.15 www.guxin.com
本地主机映射文件/etc/hosts 文件中记录着一份主机名与 IP 地址的映射关系表,一般用来保存经常需要访问的主机的信息。当访问一个未知的域名时,先查找该文件中是否有相应的映射记录,如果找不到再去向DNS 服务器查询
若在/etc/hosts 文件中添加“192.168.137.15 www.guxin.com”的映射记录,则当访www.guxin.com 时,将会直接向 IP 地址 192.168.137.15 发送 Web 请求
hosts文件和DNS服务器的比较
- 默认情况下,系统首先从hosts文件查找解析记录
- hosts文件只对当前的主机有效
- hosts文件可减少DNS查询过程,从而加快访问速度
相关文章:
Linux操作系统基础知识命令参数详解
Linux操作系统 RAID分组 RAID JBOD RAID JBOD的意思是Just a Bunch Of Disks,是将多块硬盘串联起来组成一个大的存储设备,从某种意义上说这种类型不被算作RAID,在维基百科里JBOD同时也被归入非RAID架构。RAID JBOD将所有的磁盘串联成一个单…...

Rust中一些K/V存储引擎
K/V存储引擎的由来可以追溯到20世纪70年代的Berkley DB,而近年来,随着互联网应用的发展,KV存储引擎因其简单高效、可扩展性和适合缓存应用等特点,在分布式存储领域得到了广泛应用。而使用Rust编写KV存储具有内存安全、高性能、并发…...
202302-第四周资讯
山川软件愿为您提供最优质的服务。 您的每一个疑问都会被认真对待,您的每一个建议都将都会仔细思考。 我们希望人人都能分析大数据,人人都能搭建应用。 因此我们将不断完善我们的DEMO、文档、以及视频,期望能在最大程度上快速帮助用户快速…...

九方财富冲刺上市:付费用户开始减少,退款金额飙升至4.9亿元
日前,九方财富控股有限公司(下称“九方财富”)通过港交所上市聆讯,并披露了聆讯后招股书。据贝多财经了解,九方财富最早于2021年8月31日在港交所递表,后在2022年3月、9月分别进行了更新。 据每日经济新闻报…...
SSM+HTML搭建(小白教学)
最近做项目,觉得还是有意义记录以下前后端框架是怎么搭建的,今天给大家介绍介绍SSM:SpringBootSpringMVCMyBatis后端搭建:SpringBoot快速搭建的网站(Spring Initializr)选择创建之后,会下载到一个zip压缩包,对压缩包进行解压(包地址一般选择后端项目的放的文件夹中)用idea打开项…...
【知识蒸馏】知识蒸馏(Knowledge Distillation)技术详解
参考论文:Knowledge Distillation: A Survey 1.前言 近年来,深度学习在学术界和工业界取得了巨大的成功,根本原因在于其可拓展性和编码大规模数据的能力。但是,深度学习的主要挑战在于,受限制于资源容量࿰…...

公司新招了个腾讯5年经验的测试员,让我见识到什么才是真正的测试天花板····
5年测试,应该是能达到资深测试的水准,即不仅能熟练地开发业务,而且还能熟悉项目开发,测试,调试和发布的流程,而且还应该能全面掌握数据库等方面的技能,如果技能再高些的话,甚至熟悉分…...

(一维、二维)数组传参,(一级、二级)指针传参【含样例分析,新手易懂】
目录数组传参一维数组传参二维数组传参指针传参一级指针传参二级指针传参我们在写代码的时候难免要把数组或者指针传给函数,那函数的参数该如何设计呢? 数组传参 一维数组传参 我们首先来看下面代码的几个例子: #include <stdio.h>…...

for循环中的setTimeout以及var let作用域
看了很多解释,感觉都不好理解。这个文章是我自己的理解,可以做个参考,如果我理解的不对,欢迎在评论区指正: var:使用var声明的变量具有全局作用域 (循环中每次声明的是同一个变量) l…...
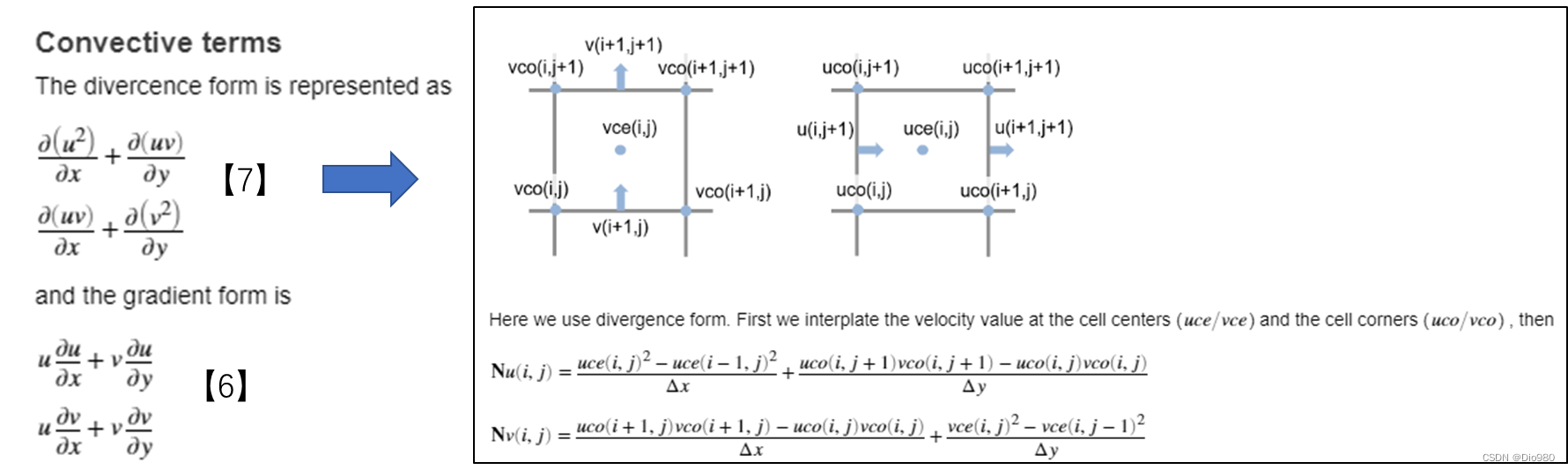
有限差分法求解不可压NS方程
网上关于有限差分法解NS方程的程序实现不尽完备,这里是一些补充注解 现有的优秀资料 理论向 【1】如何从物理意义上理解NS方程? - 知乎 【2】NS方程数值解法:投影法的简单应用 - 知乎 【3】[计算流体力学] NS 方程的速度压力法差分格式_…...
Android入门第66天-使用AOP
开篇这篇恐怕又是一篇补足网上超9成关于这个领域实际都是错的、用不起来的一个知识点了。网上太多太多教程和案例用的是一个叫hujiang的AOP组件-com.hujiang.aspectjx:gradle-android-plugin-aspectjx。首先这些错的文章我不知道是怎么来的,其次那些案例真的运行成功…...

pl/sql篇之触发器
简述本文將具体简述触发器的语法,触发条件及其适用场景,希望对读者理解,使用触发器能起到作用。触发器的定位触发器是数据库独立编译,存储的对象,是数据库重要的技术。和函数不同,触发器的执行是主动的&…...

黑马《数据结构与算法2023版》正式发布
有人的地方就有江湖。 在“程序开发”的江湖之中,各种技术流派风起云涌,变幻莫测,每一位IT侠客,对“技术秘籍”的追求和探索也从未停止过。 要论开发技术哪家强,可谓众说纷纭。但长久以来,确有一技&#…...
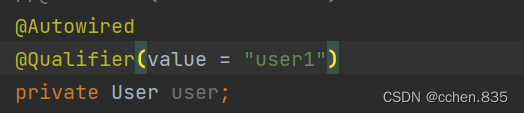
Spring的创建和使用
目录 创建Spring项目 步骤 1)使用Maven的方式创建Spring项目 2)添加Spring依赖 3)创建启动类 存Bean对象 1.创建Bean对象 2.将Bean注册到Spring中 取Bean对象并使用 步骤 1.先得到Spring上下文对象 2.从Spring中获取Bean对象 3.使用Bean ApplicationContext VS Bea…...
如何实现外网跨网远程控制内网计算机?快解析来解决
远程控制,是指管理人员在异地通过计算机网络异地拨号或双方都接入Internet等手段,连通需被控制的计算机,将被控计算机的桌面环境显示到自己的计算机上,通过本地计算机对远方计算机进行配置、软件安装程序、修改等工作。通俗来讲&a…...

【跟着ChatGPT学深度学习】ChatGPT教我文本分类
【跟着ChatGPT学深度学习】ChatGPT教我文本分类 ChatGPT既然无所不能,我为啥不干脆拜他为师,直接向他学习,岂不是妙哉。说干就干,我马上就让ChatGPT给我生成了一段文本分类的代码,不看不知道,一看吓一跳&am…...

IM即时通讯架构技术:可靠性、有序性、弱网优化等
消息的可靠性是IM系统的典型技术指标,对于用户来说,消息能不能被可靠送达(不丢消息),是使用这套IM的信任前提。 换句话说,如果这套IM系统不能保证不丢消息,那相当于发送的每一条消息都有被丢失的…...

【算法】三道算法题两道难度中等一道困难
算法目录只出现一次的数字(中等难度)java解答参考二叉树的层序遍历(难度中等)java 解答参考给表达式添加运算符(比较困难)java解答参考大家好,我是小冷。 上一篇是算法题目 接下来继续看下算法题…...
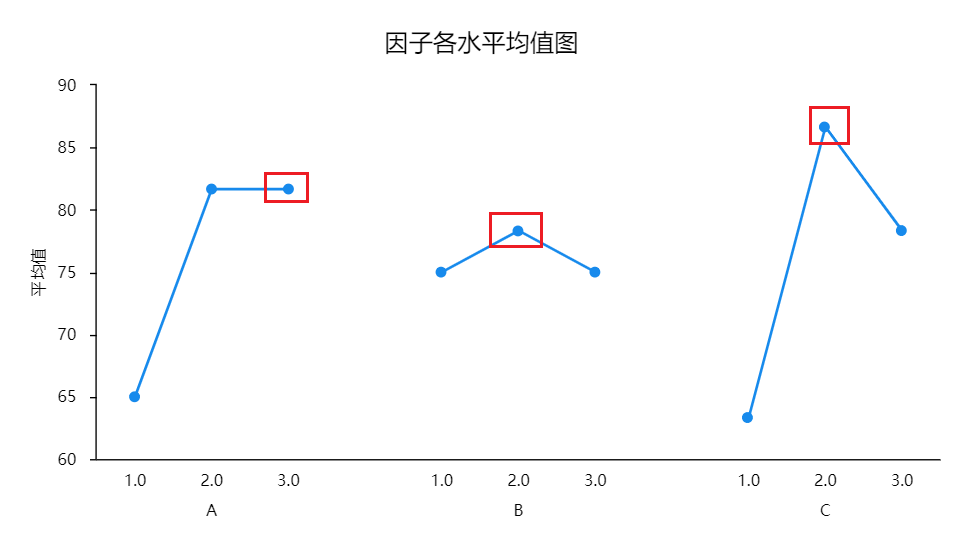
正交实验与极差分析
正交试验极差分析流程如下图: 正交试验说明 正交试验是研究多因素试验的设计方法。对于多因素、多水平的实验要求,如果每个因素的每个水平都要进行试验,这样就会耗费大量的人力和时间,正交试验可以选择出具有代表性的少数试验进行…...
DEXTUpload .NET增强的上传速度和可靠性
DEXTUpload .NET增强的上传速度和可靠性 DEXTUpload.NET Pro托管在Windows操作系统上的Internet Information Server(IIS)上,服务器端组件基于HTTP协议,支持从web浏览器到web服务器的文件上载。它也可以在ASP.NET服务器应用程序平台开发的任何网站上使用…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

如何在Windows本机安装Python并确保与Python.NET兼容
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

HTML中各种标签的作用
一、HTML文件主要标签结构及说明 1. <!DOCTYPE html> 作用:声明文档类型,告知浏览器这是 HTML5 文档。 必须:是。 2. <html lang“zh”>. </html> 作用:包裹整个网页内容,lang"z…...