Hadoop3教程(八):MapReduce中的序列化概述
文章目录
- (79)MR序列化概述
- (80)自定义序列化步骤
- (81)序列化案例需求分析
- (82)序列化案例代码
- 参考文献
(79)MR序列化概述
什么是序列化,什么是反序列化?
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。
为什么要序列化呢?
-
因为存活在内存里的对象,关机断电之后就没有了,要持久化保存的话,必须先序列化;
-
本地内存里的对象,只能供本地进程使用,如果想发送到另外一台计算机上使用,也必须先序列化。
那两台节点之间的内存数据传输,具体可以怎么做呢。
需要先序列化节点A中需要传输的内存数据,然后将序列化的结果传输到节点B中,然后节点B进行一个加载(反序列化)到内存,就实现了不同节点间,内存到内存的数据传输。
为什么不用java自带的序列化,而是Hadoop自己有一套序列化呢?
原因很简单,java的序列化中,待传输数据块后面都是跟了一大堆校验信息的。这对Hadoop来讲,有些过于繁重了,不便于在网络中高效传输,Hadoop里可能并不需要这么多的校验位,它只需要做简单校验就可以了。
基于这种需求,Hadoop就自己搞了一套序列化。主要是为了轻量
Hadoop的这套序列化,有什么好处呢?
- 结构紧凑;
- 存储空间占用相对少;
- 传输快;
- 互操作性;多种语言都可以反序列化(竟然有这个使用需求么还。。。)
(80)自定义序列化步骤
一般来讲,Hadoop里提供的那几种序列化类型,往往不能满足企业的要求,这时候企业就需要自定义一个bean对象,用于在Hadoop内部传递。
如果要自定义一个序列化对象的话,需要实现Writable接口,并重写以下方法:
void write(DataOutput out); # 序列化
void readFields(DataInput in); # 反序列化
注意,序列化时元素的顺序要跟反序列化的顺序完全一致。(这个很好理解,相当于位置参数嘛)
如:
@Override
public void write(DataOutput out) throws IOException {out.writeLong(upFlow);out.writeLong(downFlow);out.writeLong(sumFlow);
}@Override
public void readFields(DataInput in) throws IOException {upFlow = in.readLong();downFlow = in.readLong();sumFlow = in.readLong();
}
同时,如果想把结果显示在文件里(或者打印出来),都需要重写toString(),否则显示出来的是个内存地址值。
最后,如果想把自定义的bean放在key中传输,还需要实现Comparable接口,因为Map阶段需要对数据做shuffle,这意味着数据的key必须是能排序的。
@Override
public int compareTo(FlowBean o) {// 倒序排列,从大到小return this.sumFlow > o.getSumFlow() ? -1 : 1;
}
(81)序列化案例需求分析
需求案例:统计每个手机号耗费的总上行流量、总下行流量和总流量。
输入数据是每个手机号对每个网站的流量消耗情况。
输出数据是每个手机号的总上行流量、总下行流量和总流量。
需求设计的重点在于,明确map阶段输入输出的KV类型,reduce阶段输入输出的KV类型。
其中,map阶段输入的KV类型不需要操心,K相当于就是行号,V就是每行的内容;
而map阶段输出的KV跟reduce阶段输入的KV是一样的。
结合本次需求,考虑到要聚合的是手机号,所以map输出的K就应该设置成手机号,而value就只能设置成一个bean对象,包含了该条数据中的上行流量字段、下行流量字段,以及加和得到的总流量。
以以上形式,输入到reduce。
这里需要注意,bean对象如果想在不同节点(从map的节点传到reduce的节点)传输,就必须实现序列化接口。
(82)序列化案例代码
直接原样贴一下教程的代码,这块仅做了解,我也并没有实操,主要是考虑结合代码可能更好理解原理,所以还是在这里直接复制了。
1)编写自定义Bean对象:
package com.atguigu.mapreduce.writable;import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;//1 继承Writable接口
public class FlowBean implements Writable {private long upFlow; //上行流量private long downFlow; //下行流量private long sumFlow; //总流量//2 提供无参构造public FlowBean() {}//3 提供三个参数的getter和setter方法public long getUpFlow() {return upFlow;}public void setUpFlow(long upFlow) {this.upFlow = upFlow;}public long getDownFlow() {return downFlow;}public void setDownFlow(long downFlow) {this.downFlow = downFlow;}public long getSumFlow() {return sumFlow;}public void setSumFlow(long sumFlow) {this.sumFlow = sumFlow;}public void setSumFlow() {this.sumFlow = this.upFlow + this.downFlow;}//4 实现序列化和反序列化方法,注意顺序一定要保持一致@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeLong(upFlow);dataOutput.writeLong(downFlow);dataOutput.writeLong(sumFlow);}@Overridepublic void readFields(DataInput dataInput) throws IOException {this.upFlow = dataInput.readLong();this.downFlow = dataInput.readLong();this.sumFlow = dataInput.readLong();}//5 重写ToString@Overridepublic String toString() {return upFlow + "\t" + downFlow + "\t" + sumFlow;}
}
2)编写Mapper类:
package com.atguigu.mapreduce.writable;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {private Text outK = new Text();private FlowBean outV = new FlowBean();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1 获取一行数据,转成字符串String line = value.toString();//2 切割数据String[] split = line.split("\t");//3 抓取我们需要的数据:手机号,上行流量,下行流量String phone = split[1];String up = split[split.length - 3];String down = split[split.length - 2];//4 封装outK outVoutK.set(phone);outV.setUpFlow(Long.parseLong(up));outV.setDownFlow(Long.parseLong(down));outV.setSumFlow();//5 写出outK outVcontext.write(outK, outV);}
}
3)编写Reducer类:
package com.atguigu.mapreduce.writable;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;public class FlowReducer extends Reducer<Text, FlowBean, Text, FlowBean> {private FlowBean outV = new FlowBean();@Overrideprotected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {long totalUp = 0;long totalDown = 0;//1 遍历values,将其中的上行流量,下行流量分别累加for (FlowBean flowBean : values) {totalUp += flowBean.getUpFlow();totalDown += flowBean.getDownFlow();}//2 封装outKVoutV.setUpFlow(totalUp);outV.setDownFlow(totalDown);outV.setSumFlow();//3 写出outK outVcontext.write(key,outV);}
}
4)编写Driver驱动类:
package com.atguigu.mapreduce.writable;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;public class FlowDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {//1 获取job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);//2 关联本Driver类job.setJarByClass(FlowDriver.class);//3 关联Mapper和Reducerjob.setMapperClass(FlowMapper.class);job.setReducerClass(FlowReducer.class);//4 设置Map端输出KV类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);//5 设置程序最终输出的KV类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(FlowBean.class);//6 设置程序的输入输出路径FileInputFormat.setInputPaths(job, new Path("D:\\inputflow"));FileOutputFormat.setOutputPath(job, new Path("D:\\flowoutput"));//7 提交Jobboolean b = job.waitForCompletion(true);System.exit(b ? 0 : 1);}
}
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
:MapReduce中的序列化概述)
Hadoop3教程(八):MapReduce中的序列化概述
文章目录 (79)MR序列化概述(80)自定义序列化步骤(81)序列化案例需求分析(82)序列化案例代码参考文献 (79)MR序列化概述 什么是序列化,什么是反序…...
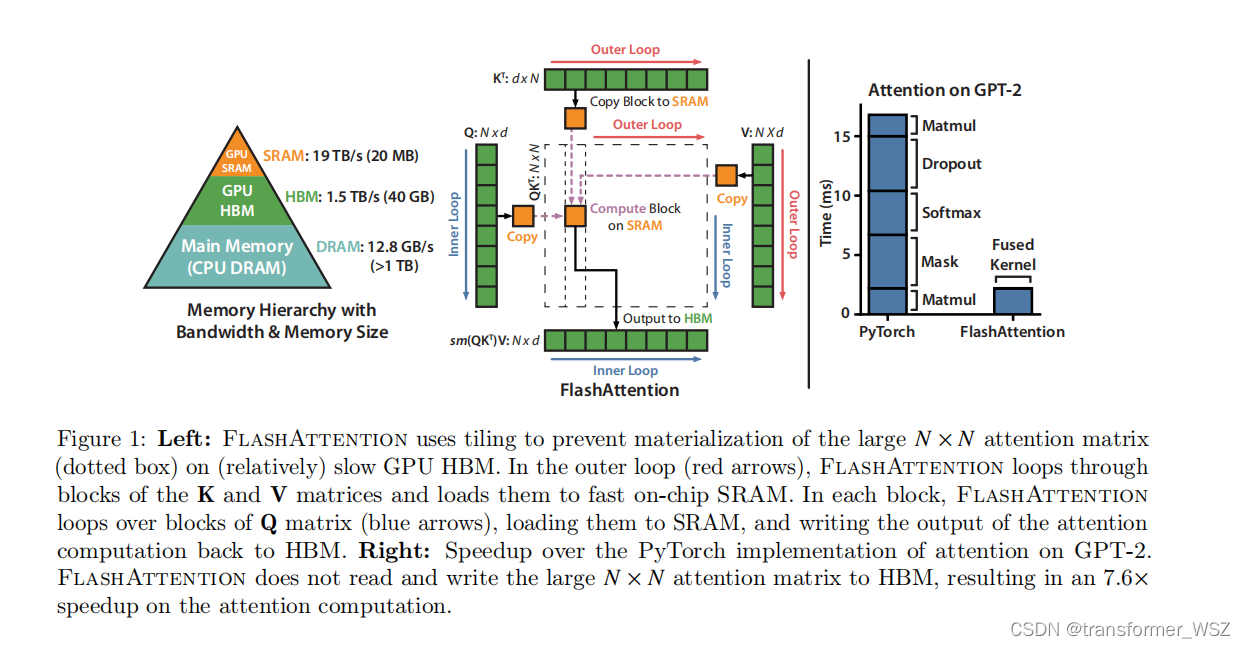
Flash-Attention
这是一篇硬核的优化Transformer的工作。众所周知,Transformer模型的计算量和储存复杂度是 O ( N 2 ) O(N^2) O(N2) 。尽管先前有了大量的优化工作,比如LongFormer、Sparse Transformer、Reformer等等,一定程度上减轻了Transformer的资源消耗…...
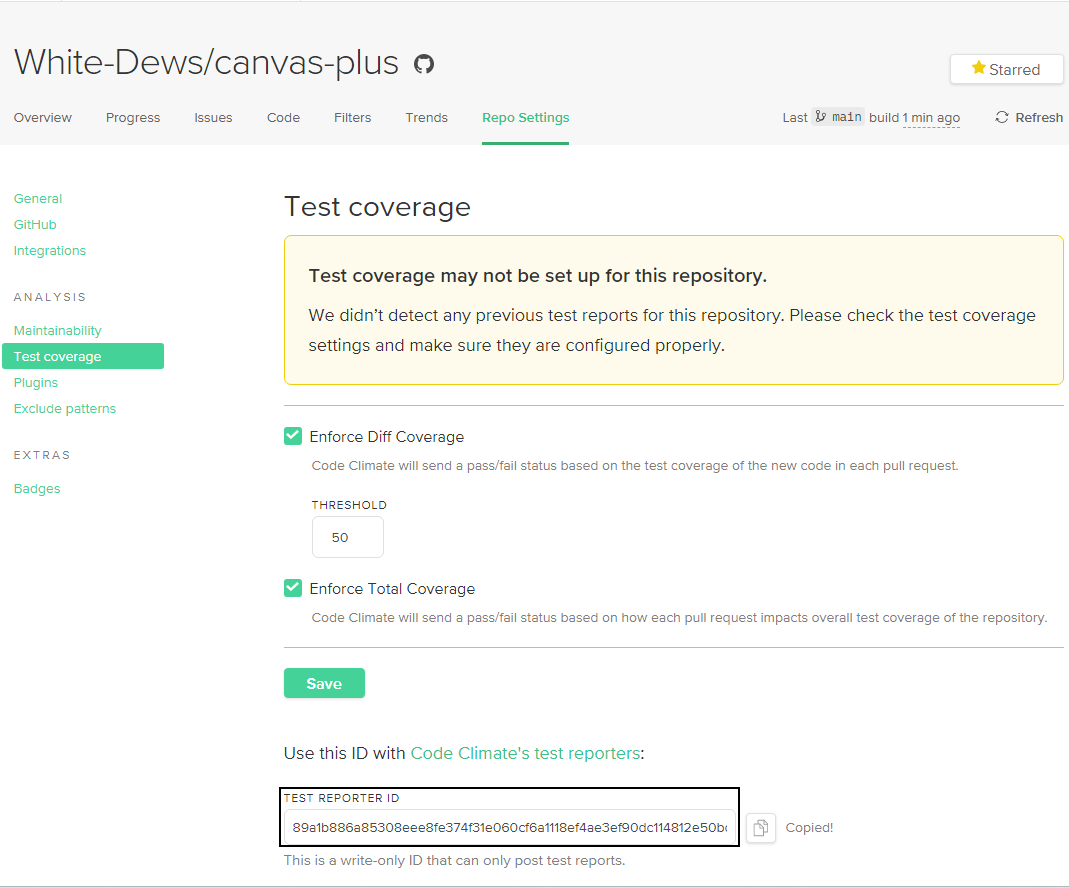
发布npm包质量分测试
查询质量分接口 https://registry.npmjs.org/-/v1/search?textcanvas-plus v0.0.1 quality 0.2987 新建文件夹 canvas-plus 执行命令 npm init 生成package.json {"name": "3r/canvas-plus","version": "0.0.1","descript…...

基于适应度相关优化的BP神经网络(分类应用) - 附代码
基于适应度相关优化的BP神经网络(分类应用) - 附代码 文章目录 基于适应度相关优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.适应度相关优化BP神经网络3.1 BP神经网络参数设置3.2 适应度相关算法应用 4…...

复杂网络 | 利用复杂网络预测城市空间流量
文章目录 效果一览文章概述导入必要的包读取时间序列数据,并使用日期做索引将时间序列进行可视化展示取一年的数据进行分析将数据分布进行可视化展示画移动平均图n 代表滑动窗口的大小向前差分法去趋势化线性回归方法去趋势化拟合模型的线性趋势将拟合得到趋势进行可视化detren…...
—>原始字面量)
【1】c++11新特性(稳定性和兼容性)—>原始字面量
在C11中添加了定义原始字符串的字面量,定义方式为:R “xxx(原始字符串)xxx”其中()两边的字符串可以省略。原始字面量R可以直接表示字符串的实际含义,而不需要额外对字符串做转义或连接等操作。 编程过程中,…...
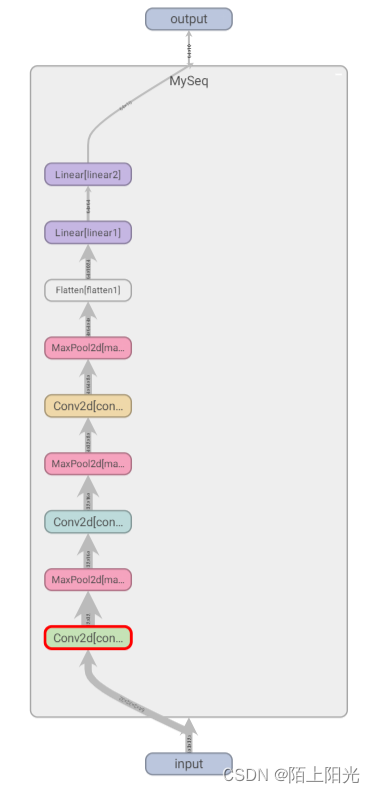
学习pytorch13 神经网络-搭建小实战Sequential的使用
神经网络-搭建小实战&Sequential的使用 官网模型结构根据模型结构和数据的输入shape,计算用在模型中的超参数coderunning log网络结构可视化 B站小土堆pytorch视频学习 官网 https://pytorch.org/docs/stable/generated/torch.nn.Sequential.html#torch.nn.Se…...

TCP发送接口(如send(),write()等)的返回值与成功发送到接收端的数据量无直接关系
1. TCP发送接口:send() TCP发送数据的接口有send,write,sendmsg。在系统内核中这些函数有一个统一的入口,即sock_sendmsg()。由于TCP是可靠传输,所以对TCP的发送接口很容易产生误解,比如sn send(...); 错误…...
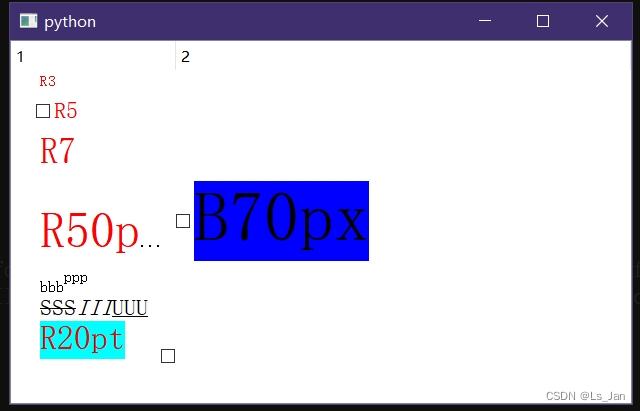
【Python、Qt】使用QItemDelegate实现单元格的富文本显示+复选框功能
主打一个 折磨 坑多 陪伴。代码为Python,C的就自己逐条语句慢慢改吧。 Python代码: import sys from types import MethodType from PyQt5.QtCore import Qt,QPoint,QSize,QRect,QEvent from PyQt5.QtGui import QStandardItemModel, QStandardItem,QTe…...

【JVM】JVM类加载机制
JVM类加载机制 加载双亲委派模型 验证准备解析初始化 JVM的类加载机制,就是把类,从硬盘加载到内存中 Java程序,最开始是一个Java文件,编译成.class文件,运行Java程序,JVM就会读取.class文件,把文件的内容,放到内存中,并且构造成.class类对象 加载 这里的加载是整个类加载的一…...

【面试经典150 | 区间】汇总区间
文章目录 Tag题目来源题目解读解题思路方法一:一次遍历复杂度分析 其他语言python3C 写在最后 Tag 【一次遍历】【数组】【字符串】 题目来源 228. 汇总区间 题目解读 给定一个无重复的升序数组 nums,需要将这个数组按照以下规则进行汇总࿱…...
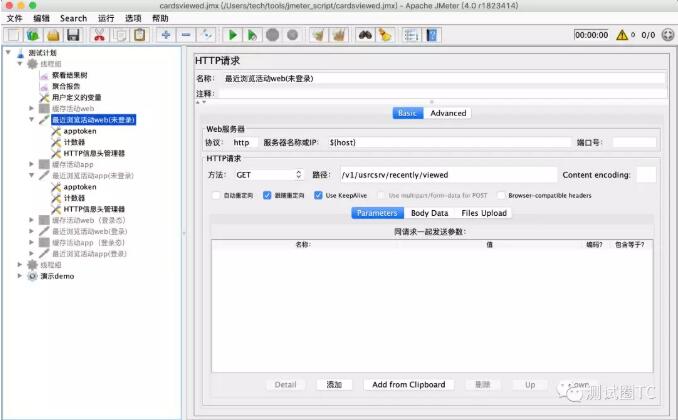
主流接口测试框架对比
公司计划系统的开展接口自动化测试,需要我这边调研一下主流的接口测试框架给后端测试(主要测试接口)的同事介绍一下每个框架的特定和使用方式。后端同事根据他们接口的特点提出一下需求,看哪个框架更适合我们。 需求 1、接口编写…...
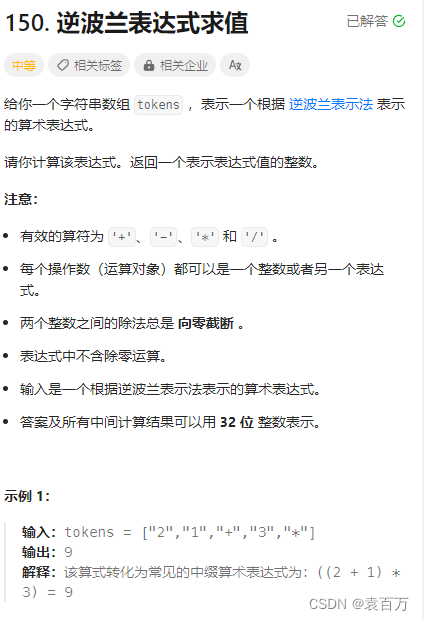
LeetCode 150.逆波兰表达式求值
题目链接 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 题目解析 首先我们需要知道什么是逆波兰表达式,像我们平常遇到的都是中缀表达式,然而逆波兰确实后缀表达式,因此这个题目隐含的意思就是将一个后缀表达式转…...
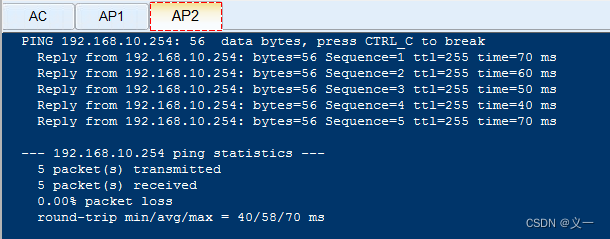
华为---企业WLAN组网基本配置示例---AC+AP组网
ACAP组网所需的物理条件 1、无线AP---收发无线信号; 2、无线控制器(AC)---用来控制管理多个AP; 3、PoE交换机---能给AP实现网络连接和供电的交换机; 4、授权:默认AC管理的AP数量有限,买授权才能管控更多AP。 WLAN创建…...
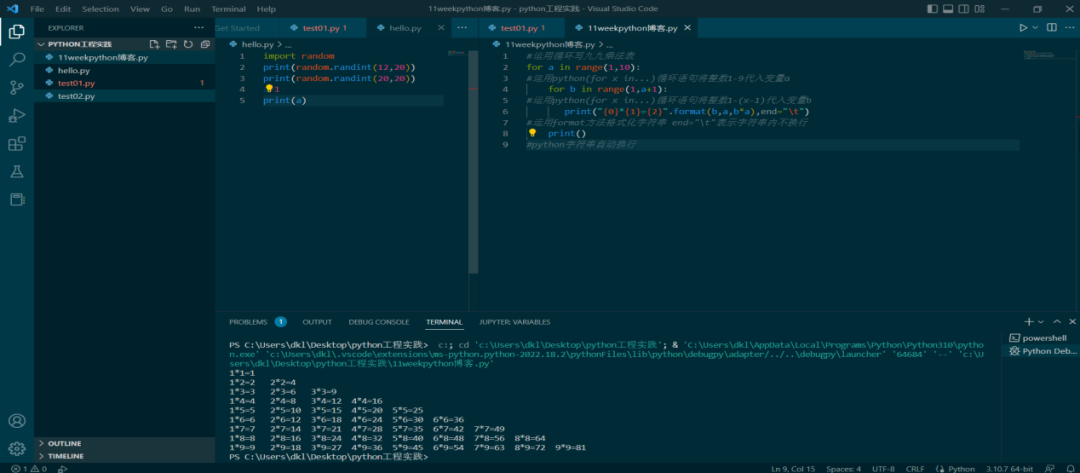
循环结构的运用
乘法口诀起源于中国,是古代人进行乘法、除法、开方等运算的基本法则,距今已经有两千多年的历史了,如何运用现代计算机技术快速写出九九乘法表呢? 循环结构可以用来重复执行一条或者多条语句,利用循环结构可以减少源程序…...

深度强化学习第 1 章 机器学习基础
1.1线性模型 线性模型(linear models)是一类最简单的有监督机器学习模型,常被用于简单的机 器学习任务。可以将线性模型视为单层的神经网络。本节讨论线性回归、逻辑斯蒂回归(logistic regression)、 softmax 分类器等…...
第一章 STM32 CubeMX (CAN通信发送)基础篇
第一章 STM32 CubeMX (CAN通信)基础篇 文章目录 第一章 STM32 CubeMX (CAN通信)基础篇STM32中文手册简介简介stm32f1系列CAN的特点CAN连接网络示意图硬件电路CAN波特率计数 一、 STM32 CubeMX设置设置波特率工程目录结构添加CAN驱…...

原子性操作
原子性操作是指一个操作在执行过程中不会被中断,要么全部执行成功,要么全部不执行,不会出现部分执行的情况。原子性操作对于多线程并发编程至关重要,因为它可以确保多个线程之间不会出现竞态条件或数据不一致性。 在计算机科学中…...
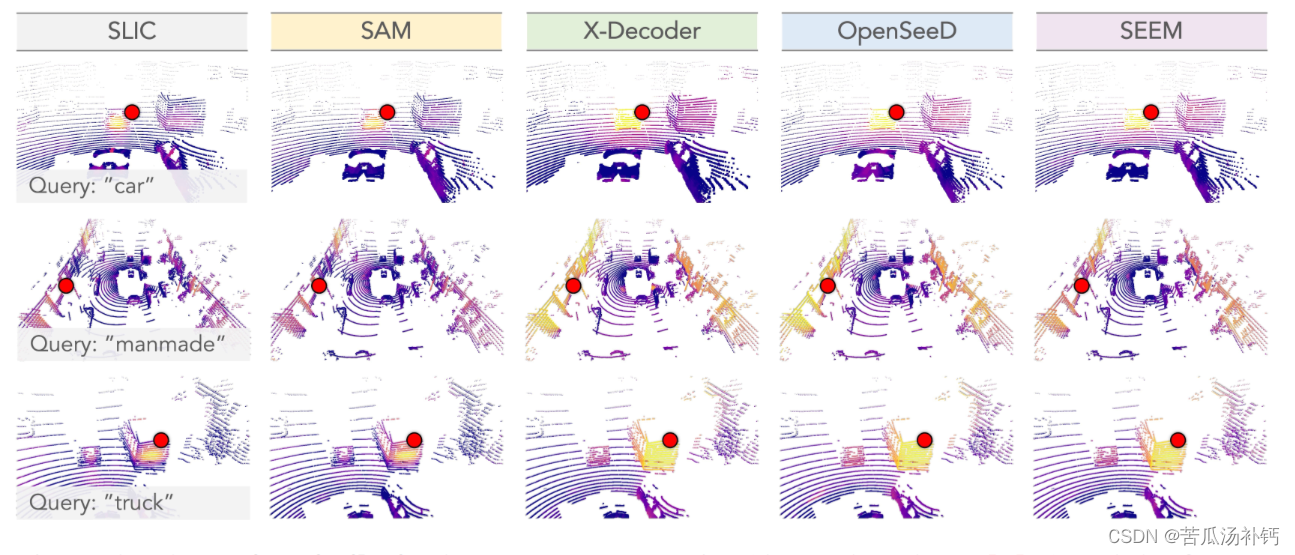
论文阅读:Segment Any Point Cloud Sequences by Distilling Vision Foundation Models
目录 概要 Motivation 整体架构流程 技术细节 小结 论文地址:[2306.09347] Segment Any Point Cloud Sequences by Distilling Vision Foundation Models (arxiv.org) 代码地址:GitHub - youquanl/Segment-Any-Point-Cloud: [NeurIPS23 Spotlight]…...
Netty 入门 — 亘古不变的Hello World
这篇文章我们正式开始学习 Netty,在入门之前我们还是需要了解什么是 Netty。 什么是 Netty 为什么很多人都推崇 Java boy 去研究 Netty?Netty 这么高大上,它到底是何方神圣? 用官方的话说:Netty 是一款异步的、基于事…...

CPU性能优化实战指南:从问题诊断到深度调优
CPU性能优化实战指南:从问题诊断到深度调优 【免费下载链接】CPUDoc 项目地址: https://gitcode.com/gh_mirrors/cp/CPUDoc 问题诊断:为什么相同硬件配置性能差异显著? 隐藏的性能损耗:现代CPU调度困境 现代处理器如同拥…...

SMUDebugTool专业级实战指南:Ryzen系统深度调试与优化
SMUDebugTool专业级实战指南:Ryzen系统深度调试与优化 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gi…...

FLUX.1-schnell终极指南:如何在4步内生成专业级AI图像
FLUX.1-schnell终极指南:如何在4步内生成专业级AI图像 【免费下载链接】FLUX.1-schnell 项目地址: https://ai.gitcode.com/hf_mirrors/black-forest-labs/FLUX.1-schnell 想象一下,你只需要输入简单的文字描述,就能在短短几秒钟内获…...

香港科技大学破解自动驾驶难题:让AI在虚拟暴风雨中学会驾驶
当你在雨夜开车时,雨滴敲打挡风玻璃,雾气遮挡视线,路面反射着车灯的光芒——这些恶劣天气条件对人类司机来说已经够困难了,对于正在学习驾驶的人工智能来说更是巨大的挑战。这项由香港科技大学、厦门大学和美团联合完成的突破性研…...

3个智能革新让黑苹果配置效率提升90%:OpCore-Simplify自动化EFI生成解决方案
3个智能革新让黑苹果配置效率提升90%:OpCore-Simplify自动化EFI生成解决方案 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 黑苹果&#…...

设计方案:核心框架搭建与落地实操全指南
当前很多团队在输出设计方案时容易陷入两个极端:要么过度追求创意忽略落地可行性,导致方案最终停留在概念阶段无法产生实际价值;要么完全照搬模板缺乏针对性,无法匹配业务的个性化需求。尤其是电商、新媒体、企业服务等领域的设计…...

为什么你的Spring Boot 4.0 Agent始终“不就绪”?7步诊断清单+ClassLoader隔离冲突终极解法
第一章:Spring Boot 4.0 Agent-Ready 架构演进与核心挑战Spring Boot 4.0 将 JVM Agent 集成能力提升为核心架构特性,标志着从“可监控”迈向“原生可观测”的范式跃迁。该版本深度重构了启动生命周期、类加载器隔离机制与 Bean 注册流程,使字…...

终极指南:通过cursor-free-vip开源工具实现Cursor Pro无限制访问
终极指南:通过cursor-free-vip开源工具实现Cursor Pro无限制访问 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reache…...

OpenClaw 真能提效?拆解 7 个场景背后的实际代价与边界
先说结论AI 助手在邮件分类、文档生成等结构化任务上确实能省时间,但需要前期投入配置和调试成本。代码审查、会议纪要等场景对模型能力和数据质量依赖很高,实际效果可能打折扣,更适合作为辅助工具。部署这类系统要考虑团队规模、数据安全和维…...

zookeeper 常用命令之zkCli
简介:介绍zkCli客户端非常常用的命令 zkCli.sh 不填后面的参数,默认连接的就是localhost:2181zk节点类似Linux的目录,比如/uar/local,-s表示持久的节点,-e是临时的节点。data是往这个节点里面放入哪些数据,…...