kafka安装和使用的入门教程
这篇文章简单介绍如何在ubuntu上安装kafka,并使用kafka完成消息的发送和接收。
一、安装kafka
访问kafka官网Apache Kafka,然后点击快速开始

紧接着,点击Download
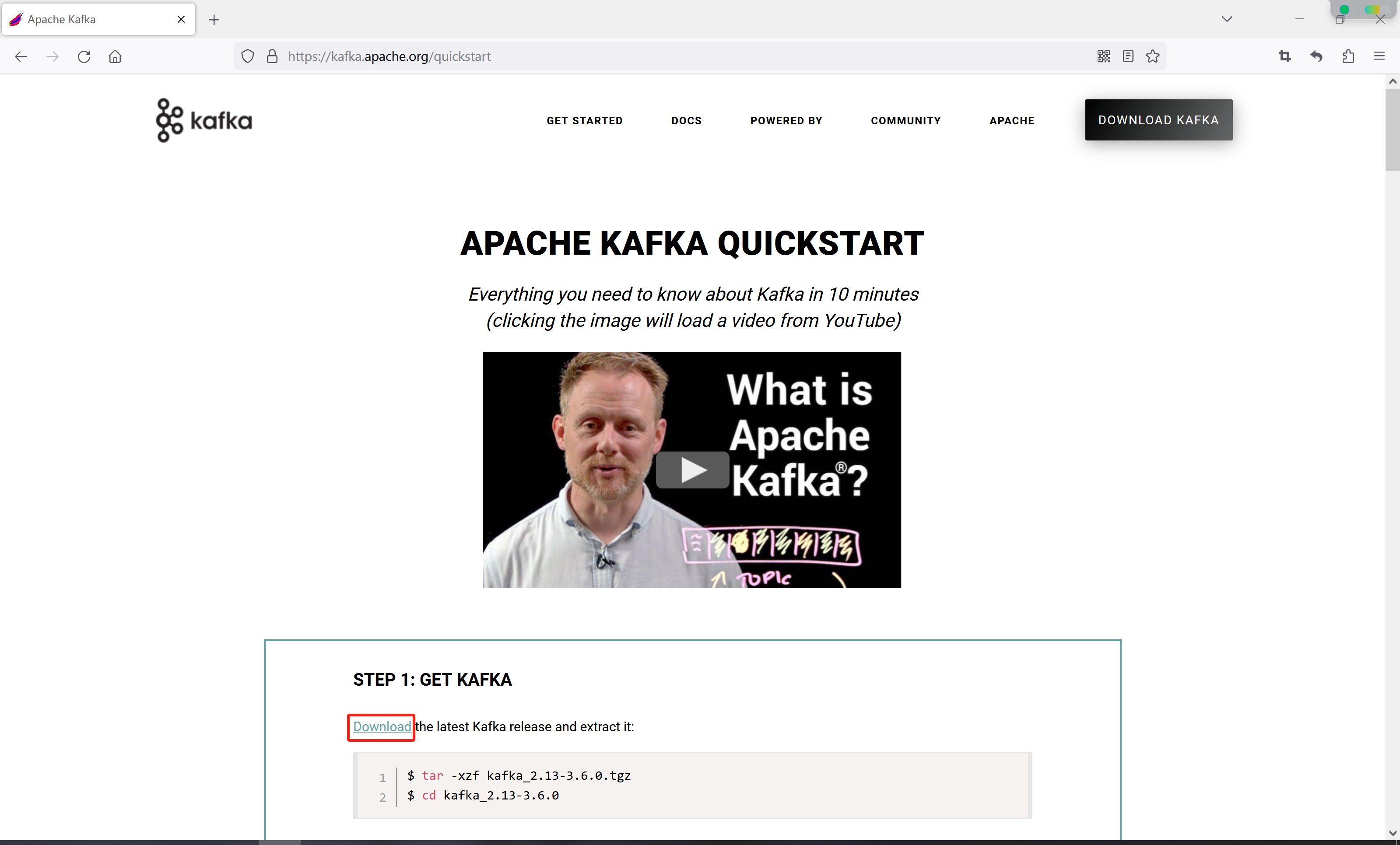
最后点击下载链接下载安装包

如果下载缓慢,博主已经把安装包上传到百度网盘:
链接:https://pan.baidu.com/s/1nZ1duIt64ZVUsimaQ1meZA?pwd=3aoh
提取码:3aoh
--来自百度网盘超级会员V3的分享
二、启动kafka
经过上一步下载完成后,按照页面的提示启动kafka
1、通过远程连接工具,如finalshell、xshell上传kafka_2.13-3.6.0.tgz到服务器上的usr目录
2、切换到usr目录,解压kafka_2.13-3.6.0.tgz
cd /usrtar -zxzf kafka_2.13-3.6.0.tgz3、启动zookeeper
修改配置文件confg/zookeeper.properties,修改一下数据目录
dataDir=/usr/local/zookeeper然后通过以下命令启动kafka自带的zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties4、启动kafka
修改配置文件confg/server.properties,修改一下kafka保存日志的目录
log.dirs=/usr/local/kafka/logs然后新开一个连接窗口,通过以下命令启动kafka
bin/kafka-server-start.sh config/server.properties三、kafka发送、接收消息
创建topic
bin/kafka-topics.sh --create --topic hello --bootstrap-server localhost:9092
生产消息
往刚刚创建的topic里发送消息,可以一次性发送多条消息,点击Ctrl+C完成发送
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic hello
消费消息
消费最新的消息
新开一个连接窗口,在命令行输入以下命令拉取topic为hello上的消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic hello
消费之前的消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic hello指定偏移量消费
指定从第几条消息开始消费,这里--offset参数设置的偏移量是从0开始的。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --partition 0 --offset 1 --topic hello消息的分组消费
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=helloGroup --topic hello四、Java中使用kafka
通过maven官网搜索kafka的maven依赖版本
https://central.sonatype.com/search?q=kafka![]() https://central.sonatype.com/search?q=kafka然后通过IntelliJ IDEA创建一个maven项目kafka,在pom.xml中添加kafka的依赖
https://central.sonatype.com/search?q=kafka然后通过IntelliJ IDEA创建一个maven项目kafka,在pom.xml中添加kafka的依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>kafka</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka_2.12</artifactId><version>3.6.0</version></dependency></dependencies>
</project>创建消息生产者
生产者工厂类
package producer;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;import java.util.Properties;/*** 消息生产者工厂类* @author heyunlin* @version 1.0*/
public class MessageProducerFactory {private static final String BOOTSTRAP_SERVERS = "192.168.254.128:9092";public static Producer<String, String> getProducer() {//PART1:设置发送者相关属性Properties props = new Properties();// 此处配置的是kafka的端口props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);// 配置key的序列化类props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 配置value的序列化类props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");return new KafkaProducer<>(props);}}测试发送消息
package producer;import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;/*** @author heyunlin* @version 1.0*/
public class MessageProducer {private static final String TOPIC = "hello";public static void main(String[] args) {ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC, "1", "Message From Producer.");Producer<String, String> producer = MessageProducerFactory.getProducer();// 同步发送消息producer.send(record);// 异步发送消息producer.send(record, new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {String topic = recordMetadata.topic();long offset = recordMetadata.offset();int partition = recordMetadata.partition();String message = recordMetadata.toString();System.out.println("topic = " + topic);System.out.println("offset = " + offset);System.out.println("message = " + message);System.out.println("partition = " + partition);}});// 加上这行代码才会发送消息producer.close();}}创建消息消费者
消费者工厂类
package consumer;import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.util.Properties;/*** 消息生产者工厂类* @author heyunlin* @version 1.0*/
public class MessageConsumerFactory {private static final String BOOTSTRAP_SERVERS = "192.168.254.128:9092";public static Consumer<String, String> getConsumer() {//PART1:设置发送者相关属性Properties props = new Properties();//kafka地址props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);//每个消费者要指定一个groupprops.put(ConsumerConfig.GROUP_ID_CONFIG, "helloGroup");//key序列化类props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");//value序列化类props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");return new KafkaConsumer<>(props);}}测试消费消息
package consumer;import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;import java.time.Duration;
import java.util.Collections;/*** @author heyunlin* @version 1.0*/
public class MessageConsumer {private static final String TOPIC = "hello";public static void main(String[] args) {Consumer<String, String> consumer = MessageConsumerFactory.getConsumer();consumer.subscribe(Collections.singletonList(TOPIC));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofNanos(100));for (ConsumerRecord<String, String> record : records) {System.out.println(record.key() + ": " + record.value());}// 提交偏移量,避免消息重复推送consumer.commitSync(); // 同步提交// consumer.commitAsync(); // 异步提交}}}五、springboot整合kafka
开始前的准备工作
然后通过IntelliJ IDEA创建一个springboot项目springboot-kafka,在pom.xml中添加kafka的依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId>
</dependency>然后修改application.yml,添加kafka相关配置
spring:kafka:bootstrap-servers: 192.168.254.128:9092producer:acks: 1retries: 3batch-size: 16384properties:linger:ms: 0buffer-memory: 33554432key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerconsumer:group-id: helloGroupenable-auto-commit: falseauto-commit-interval: 1000auto-offset-reset: latestproperties:request:timeout:ms: 18000session:timeout:ms: 12000key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer创建消息生产者
package com.example.springboot.kafka.producer;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;/*** @author heyunlin* @version 1.0*/
@RestController
@RequestMapping(path = "/producer", produces = "application/json;charset=utf-8")
public class KafkaProducer {private final KafkaTemplate<String, Object> kafkaTemplate;@Autowiredpublic KafkaProducer(KafkaTemplate<String, Object> kafkaTemplate) {this.kafkaTemplate = kafkaTemplate;}@RequestMapping(value = "/sendMessage", method = RequestMethod.GET)public String sendMessage(String message) {kafkaTemplate.send("hello", message);return "发送成功~";}}创建消息消费者
package com.example.springboot.kafka.consumer;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;/*** @author heyunlin* @version 1.0*/
@Component
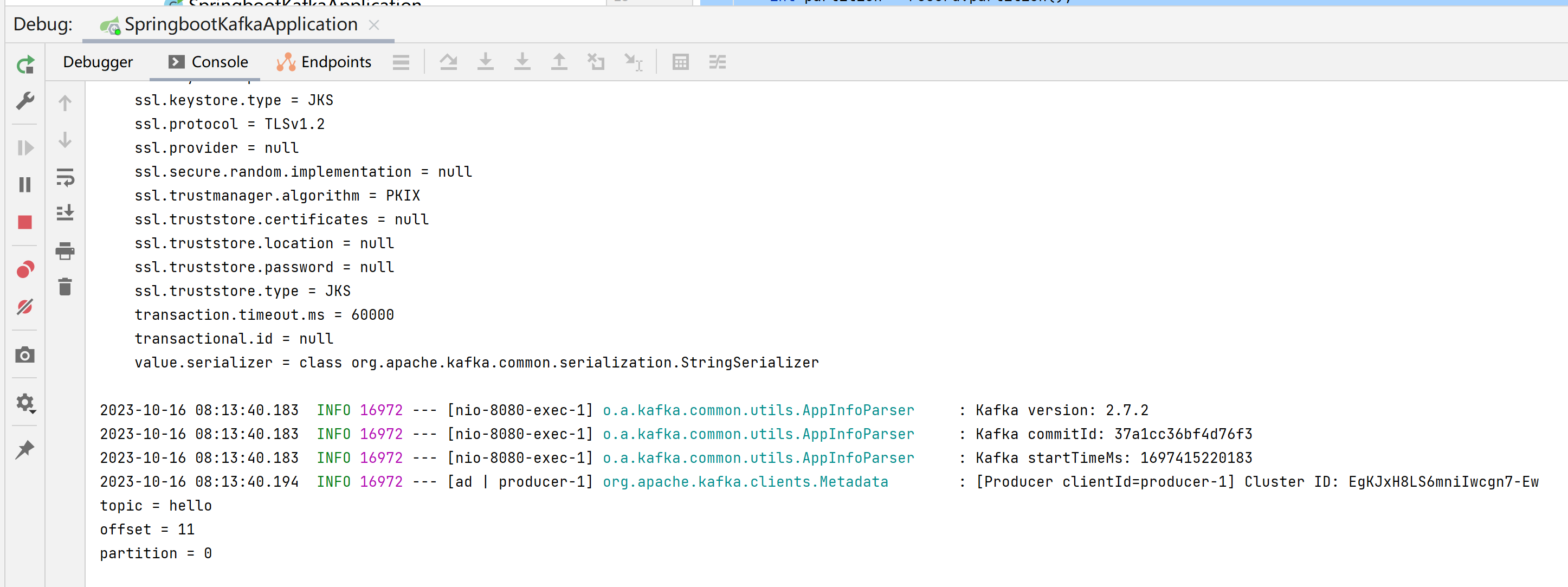
public class KafkaConsumer {@KafkaListener(topics = "hello")public void receiveMessage(ConsumerRecord<String, String> record) {String topic = record.topic();long offset = record.offset();int partition = record.partition();System.out.println("topic = " + topic);System.out.println("offset = " + offset);System.out.println("partition = " + partition);}}然后访问网址http://localhost:8080/producer/sendMessage?message=hello往topic为hello的消息队列发送消息。控制台打印了参数,成功监听到发送的消息。
文章涉及的项目已经上传到gitee,按需获取~
Java中操作kafka的基本项目![]() https://gitee.com/he-yunlin/kafka.git
https://gitee.com/he-yunlin/kafka.git
springboot整合kafka案例项目![]() https://gitee.com/he-yunlin/springboot-kafka.git
https://gitee.com/he-yunlin/springboot-kafka.git
相关文章:
kafka安装和使用的入门教程
这篇文章简单介绍如何在ubuntu上安装kafka,并使用kafka完成消息的发送和接收。 一、安装kafka 访问kafka官网Apache Kafka,然后点击快速开始 紧接着,点击Download 最后点击下载链接下载安装包 如果下载缓慢,博主已经把安装包上传…...

享搭低代码平台:加速企业应用开发,轻松搭建表单和报表
在当今快节奏的商业环境中,企业需要快速响应市场需求并提供高效的解决方案。然而,传统的应用开发过程繁琐、耗时,并且需要专业的编程技能。为了解决这些问题,享搭低代码平台应运而生。本文将详细介绍享搭低代码平台的特点和优势&a…...
华为云应用中间件DCS系列—Redis实现(社交APP)实时评论
云服务、API、SDK,调试,查看,我都行 阅读短文您可以学习到:应用中间件系列之Redis实现(社交APP)实时评论 1 什么是DEVKIT 华为云开发者插件(Huawei Cloud Toolkit)࿰…...
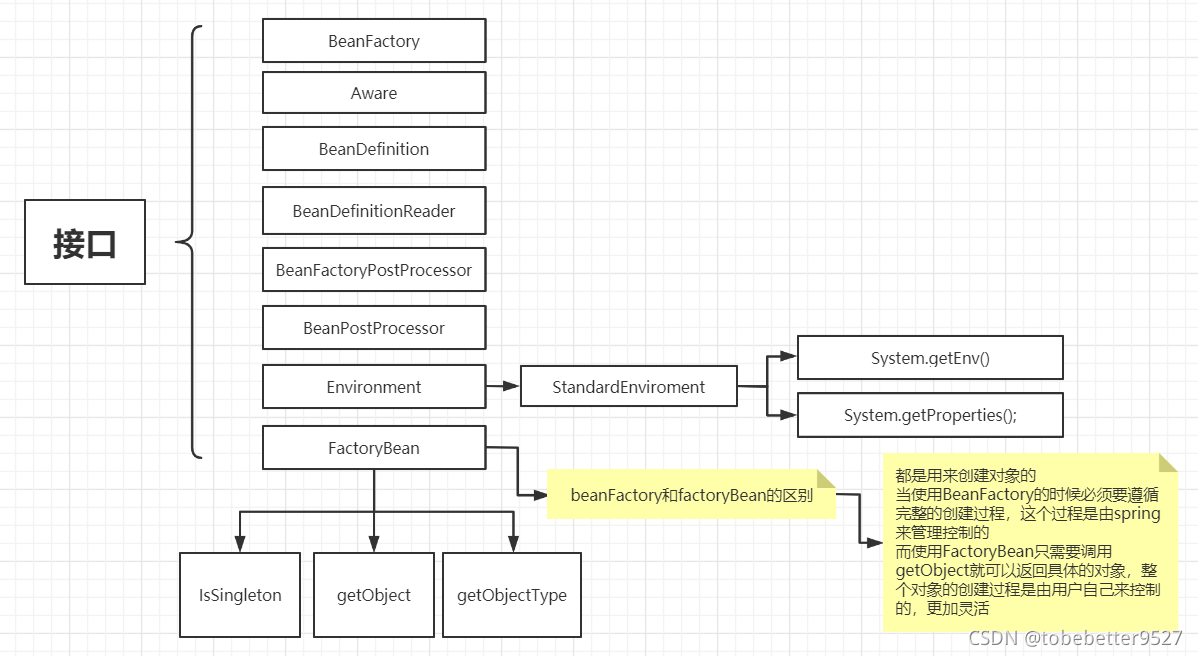
01-spring源码概述
文章目录 1. Spring两大主要功能2. Bean的生命周期(部分生命周期,不包括销毁)2.1 两个重要接口及Aware接口2.2 创建对象的过程2.3 Bean的scope作用域2.4 Bean的类型2.5 获得反射对象的三种方式 3. 涉及的接口汇总4. 涉及设计模式 1. Spring两…...

datax 同步本地csv到mysql
csv 文件 /root/tempdata/us_population.csv NY,New York,8143197 CA,Los Angeles,3844829 IL,Chicago,2842518 TX,Houston,2016582 PA,Philadelphia,1463281 AZ,Phoenix,1461575 TX,San Antonio,1256509 CA,San Diego,1255540 TX,Dallas,1213825 CA,San Jose,912332csv2mysq…...
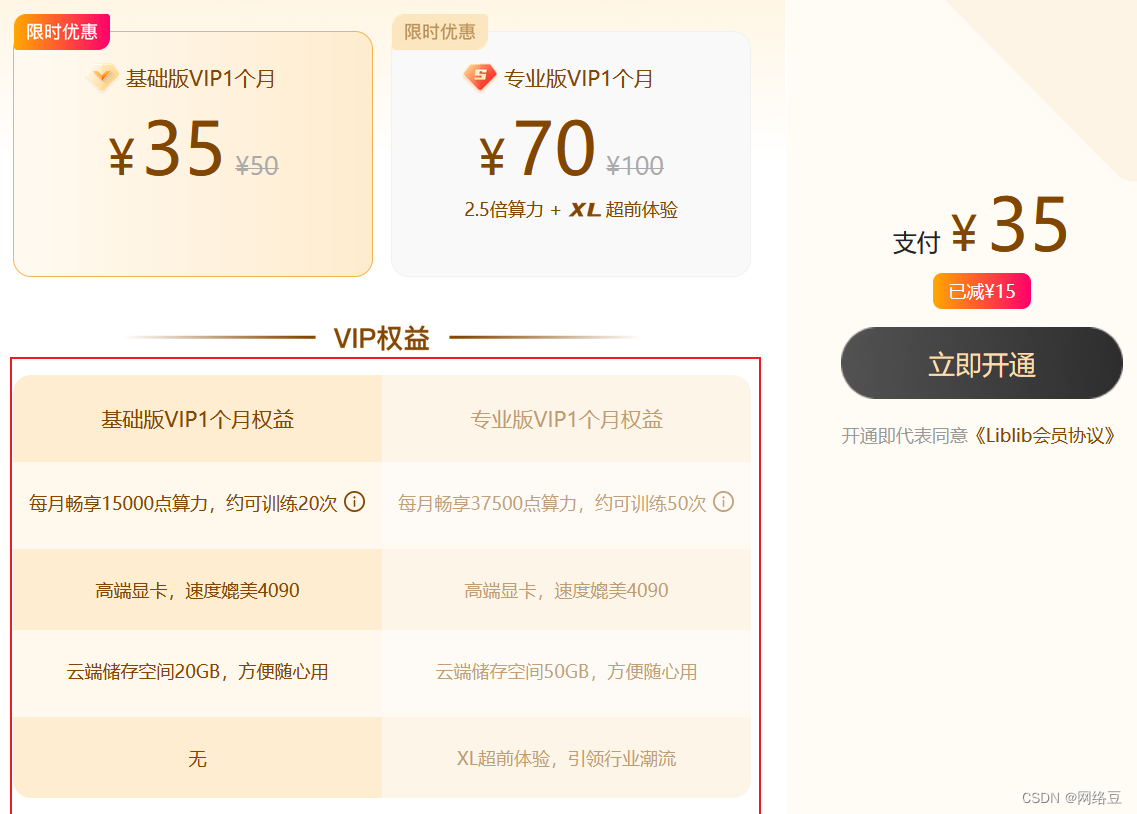
国内原汁原味的免费sd训练工具--哩布哩布AI
作者简介:一名云计算网络运维人员、每天分享网络与运维的技术与干货。 公众号:网络豆云计算学堂 座右铭:低头赶路,敬事如仪 个人主页: 网络豆的主页 目录 写在前面 一.体验与操作 1.注册 2.为何可…...
 用Vector实现获取所有组合数列表的QT实现)
组合数(1) 用Vector实现获取所有组合数列表的QT实现
1.工程文件 QT coreCONFIG c17 cmdline# You can make your code fail to compile if it uses deprecated APIs. # In order to do so, uncomment the following line. #DEFINES QT_DISABLE_DEPRECATED_BEFORE0x060000 # disables all the APIs deprecated before Qt 6.…...

Ultra-Fast-Lane-Detection-v2 裁剪数据增强
目录 标注拆分为独立文件加载并数据增强 Ultra-Fast-Lane-Detection-v2 裁剪数据增强 main方法是调用示例...
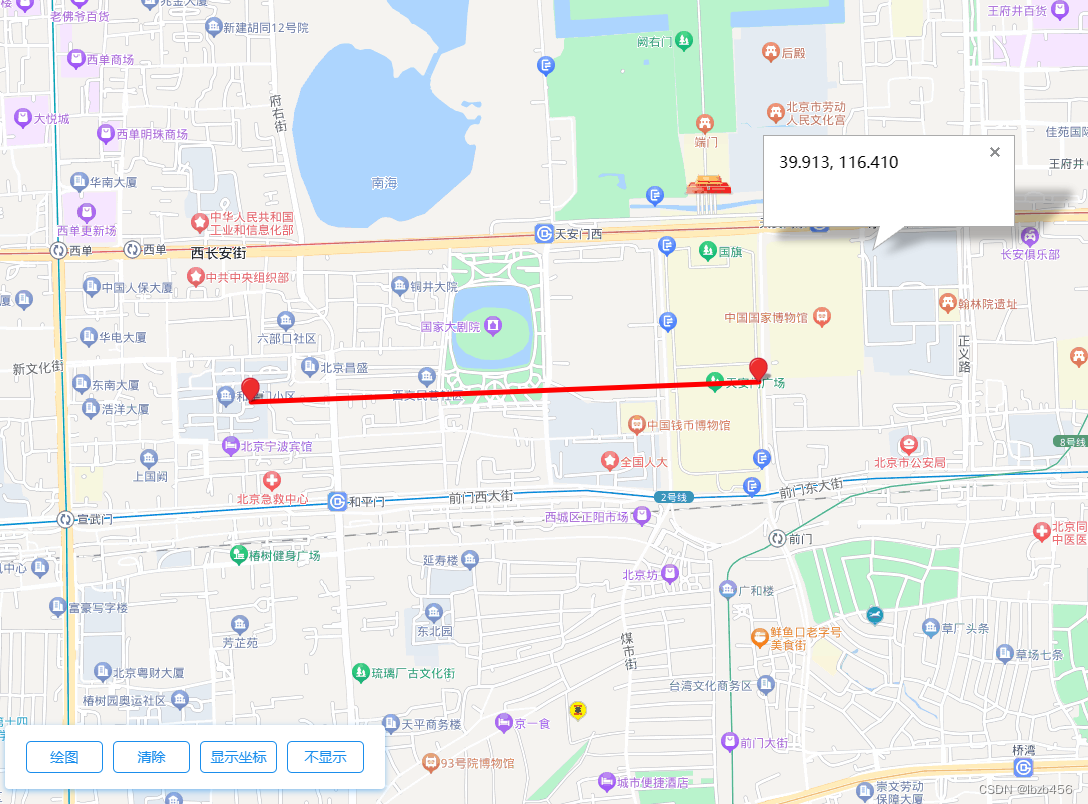
从零开始学习调用百度地图网页API:三、鼠标点击绘图功能
目录 代码功能问题注意addEventListenerplot_line 代码 <!DOCTYPE html> <html> <head><meta http-equiv"Content-Type" content"text/html; charsetutf-8" /><meta name"viewport" content"initial-scale1.0,…...
--- MountainCar基于Q-learning)
强化学习案例复现(1)--- MountainCar基于Q-learning
1 搭建环境 1.1 gym自带 import gym# Create environment env gym.make("MountainCar-v0")eposides 10 for eq in range(eposides):obs env.reset()done Falserewards 0while not done:action env.action_space.sample()obs, reward, done, action, info env.…...
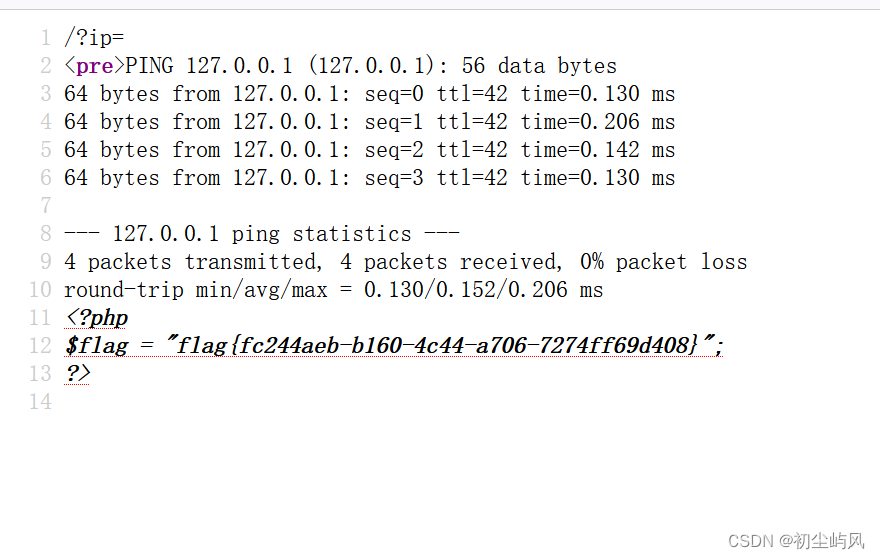
BUUCTF学习(6): 命令执行ip
1、介绍 2、hackbar安装 BUUCTF学习(四): 文件包含tips-CSDN博客 ?ip127.0.0.1;ag;cat$IFS$9fla$a.php 空格过滤 $IFS$9 检查源代码 结束...
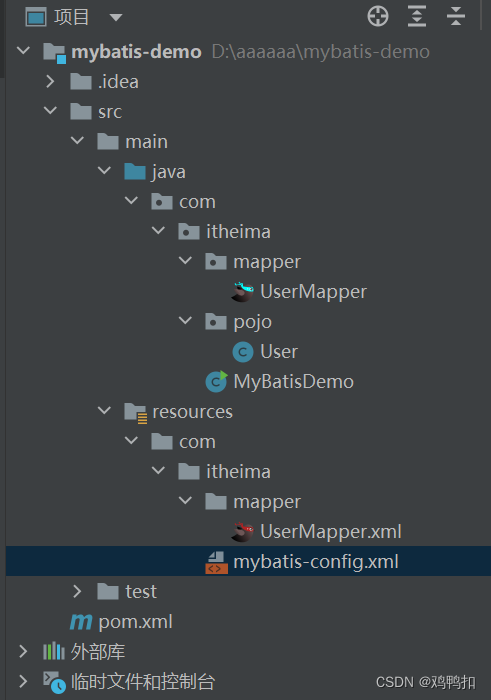
javaweb:mybatis:mapper(sql映射+代理开发+配置文件之设置别名、多环境配置、顺序+注解开发)
1.0版本 sql映射文件实现 流程 首先程序进入启动类MyBatisDemo.java中,读取配置文件mybatis-config.xml 再由mybatis-config的mappers属性 <mappers><mapper resource"UserMapper.xml"></mapper></mappers>找到sql映射文件Use…...
)
JavaScript基础知识——练习巩固(2)
写一个程序,要求如下 需求1:让用户输入五个有效年龄(0-100之间),放入数组中 必须输入五个有效年龄年龄,如果是无效年龄,则不能放入数组中 需求2:打印出所有成年人的年龄 (数组筛选)…...
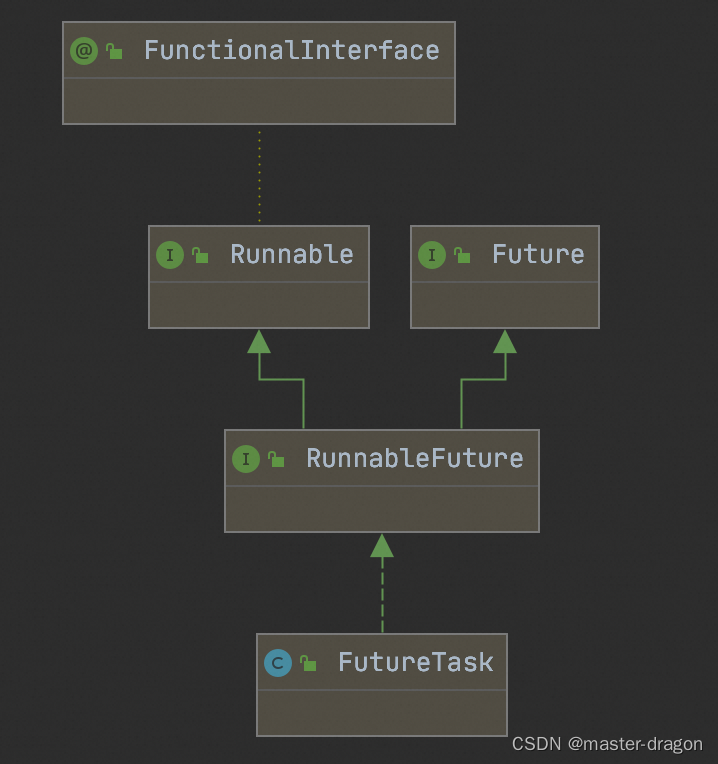
FutureTask的测试使用和方法执行分析
FutureTask类图如下 java.util.concurrent.FutureTask#run run方法执行逻辑如下 public void run() {if (state ! NEW ||!RUNNER.compareAndSet(this, null, Thread.currentThread()))return;try {Callable<V> c callable;if (c ! null && state NEW) {V res…...

SpringMVC的请求处理
目录 请求映射路径的配置 请求数据的接收 接收Restful风格的数据 什么是Restful风格? 接收上传文件 获取headers头信息和cookie信息 JavaWeb常用对象获取 请求静态资源 注解驱动标签 请求映射路径的配置 请求映射路径的配置主要是通过RequestMapping注解实现…...

260. 只出现一次的数字 III
给你一个整数数组 nums,其中恰好有两个元素只出现一次,其余所有元素均出现两次。 找出只出现一次的那两个元素。你可以按 任意顺序 返回答案。 你必须设计并实现线性时间复杂度的算法且仅使用常量额外空间来解决此问题。 示例 1: 输入&…...

家政预约接单系统,家政保洁小程序开发;
家政预约接单系统,家政保洁维修小程序开发,阿姨管理,家政保险,合同管理,资金管理,营销推广等功能,包括:推广、营销、管理、培训、周边服务等等 家政系统详细功能介绍: 家…...

网络安全工程师需要学什么?零基础怎么从入门到精通,看这一篇就够了
网络安全工程师需要学什么?零基础怎么从入门到精通,看这一篇就够了 我发现关于网络安全的学习路线网上有非常多看似高大上却无任何参考意义的回答。大多数的路线都是给了一个大概的框架,告诉你那些东西要考,以及建议了一个学习顺…...
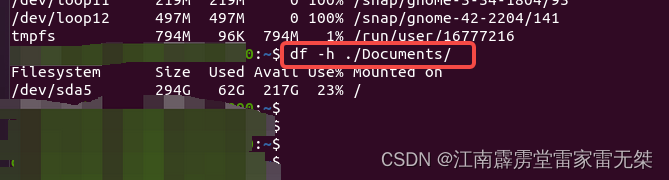
出差学知识No3:ubuntu查询文件大小|文件包大小|磁盘占用情况等
1、查询单个文件占用内存大小2、显示一个目录下所有文件和文件包的大小3、显示ubuntu所有磁盘的占用情况4、查看ubuntu单个包的占用情况 1、查询单个文件占用内存大小 使用指令:ls -lh 文件 2、显示一个目录下所有文件和文件包的大小 指令:du -sh* 3…...

详解cv2.copyMakeBorder函数【OpenCV图像边界填充Python版本】
文章目录 简介函数原型代码示例参考资料 简介 做深度学习图像数据集时,有时候需要调整一张图片的长和宽。如果直接使用cv2.resize函数会造成图像扭曲失真,因此我们可以采取填充图像短边的方法解决这个问题。cv2.copyMakeBorder函数提供了相关操作。本篇…...

AISMM模型适配中小团队的7大裁剪法则,92%的早期项目因忽略第5条导致AI投入归零
更多请点击: https://intelliparadigm.com 第一章:AISMM模型在创业公司中的应用 什么是AISMM模型 AISMM(Agile Intelligence Strategy Maturity Model)是一种融合敏捷开发、数据智能与战略演进的轻量级成熟度框架,专…...

互联网大厂 Java 求职面试:从 Spring Boot 到消息队列的挑战
互联网大厂 Java 求职面试:从 Spring Boot 到消息队列的挑战在这个充满竞争的互联网大厂中,Java 求职者往往面临着严苛的面试考验。今天,我们将通过燕双非与面试官的对话,深入探讨在音视频场景下的求职面试。第一轮面试面试官&…...

opencv 和opencv_contrib官网 不同版本的下载地址
opencv Releases opencv/opencv https://github.com/opencv/opencv_contrib/releases/tag/4.0.1 Release 3.4.13 opencv/opencv_contrib GitHubhttps://github.com/opencv/opencv_contrib/releases/tag/3.4.13 4.0.1 和3.4.13 都是版本号。下载就行。...

AI 热点资讯日报-2026-05-07
文章目录AI 热点资讯日报今日核心热点总结新华网科技 (tech.news.cn)36氪 (36kr.com)虎嗅网 (huxiu.com)网易科技 (tech.163.com)雷锋网 (leiphone.com)今日关键词云编辑点评📖 延伸阅读AI 热点资讯日报 日期:2026年5月7日(星期四࿰…...
)
AISMM不是概念!已落地5大场景的专利组合策略(含医疗影像实时推理、车规级边缘调度等8个真实授权案例)
更多请点击: https://intelliparadigm.com 第一章:2026奇点智能技术大会:AISMM与专利布局 2026奇点智能技术大会(Singularity Intelligence Summit 2026)正式发布全新智能模型架构——AISMM(Adaptive Int…...

AI写论文大合集!4款AI论文写作工具,让写论文不再是痛苦事!
AI论文写作工具介绍 还在为写期刊论文而烦恼吗?面对大量的文献、复杂的格式和无数次的修改,很多学术人员都觉得效率低下。别担心,接下来我将介绍4款实际测试过的AI论文写作工具,它们可以帮助你从文献检索、论文大纲生成到语言润色…...

别再死记硬背了!用Java代码和动画图解,5分钟搞懂基数排序的LSD和MSD
基数排序可视化:用动画和Java代码拆解LSD与MSD的奥秘 当你第一次听说基数排序时,脑海中是否浮现出一堆数字在某种神秘规则下自动排列的场景?作为非比较型排序算法中的佼佼者,基数排序通过巧妙的"分桶"策略,让…...

BayLing大模型:基于LLaMA的中文指令微调实战指南
1. 项目概述:当大语言模型学会“说”中文如果你最近在关注大语言模型(LLM)的进展,可能会发现一个有趣的现象:那些在国际上表现惊艳的模型,比如LLaMA、Falcon,甚至是GPT系列,它们在处…...

构建个人数字图书馆:novel-downloader 小说下载解决方案
构建个人数字图书馆:novel-downloader 小说下载解决方案 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader novel-downloader 是一个基于 TypeScript 构建的可扩展浏览器脚本…...
)
AISMM模型与技术生态建设(从理论幻想到规模化落地的12个月攻坚实录)
更多请点击: https://intelliparadigm.com 第一章:AISMM模型与技术生态建设 核心架构设计原则 AISMM(Adaptive Intelligent Service Mesh Model)是一种面向异构云原生环境的动态服务治理模型,强调感知—决策—执行闭…...