从零开始的stable diffusion

stable diffusion真的是横空出世,开启了AIGC的元年。不知你是否有和我一样的困惑,这AI工具好像并不是那么听话?

前言
我们该如何才能用好stable diffusion这个工具呢?AI究竟在stable diffusion中承担了什么样的角色?如何能尽可能快、成本低地得到我们期望的结果?
源于这一系列的疑问,我开始了漫长的论文解读。High-Resolution Image Synthesis with Latent Diffusion Models(地址:https://arxiv.org/abs/2112.10752?spm=ata.21736010.0.0.7d0b28addsl7xQ&file=2112.10752)
当然这论文看的云里雾里的,加篇读了How does Stable Diffusion work?(地址:https://stable-diffusion-art.com/how-stable-diffusion-work/?spm=ata.21736010.0.0.7d0b28addsl7xQ)
先简要概括下,stable diffusion的努力基本是为了2个目的:
低成本、高效验证。设计了Latent Space
Conditioning Mechanisms。条件控制,如果不能输出我们想要的图片,那这就像Monkey Coding。耗费无限的时间与资源。
这是整个内容里最重要最核心的两个部分。

图片生成的几种方式
随着深度神经网络的发展,生成模型已经有了巨大的发展,主流的有以下几种:
自回归模型(AutoRegressive model):按照像素点生成图像,导致计算成本高。实验效果还不错
变分自编码器(Variational Autoencoder):Image to Latent, Latent to Image,VAE存在生成图像模糊或者细节问题
基于流的方法(Glow)
生成对抗网络(Generative adversarial network):利用生成器(G)与判别器(D)进行博弈,不断让生成的图像与真实的图像在分布上越来越接近。
其中AR与GAN的生成都是在pixel space进行模型训练与推理。
▐ 模型是如何生成图片的?
以一只猫作为案例。当我们想画一只猫的时候,也都是从一个白板开始,框架、细节不断完善。
对于AI来说,一个纯是noise的image就是一个理想的白板,类似下图展示的这样。
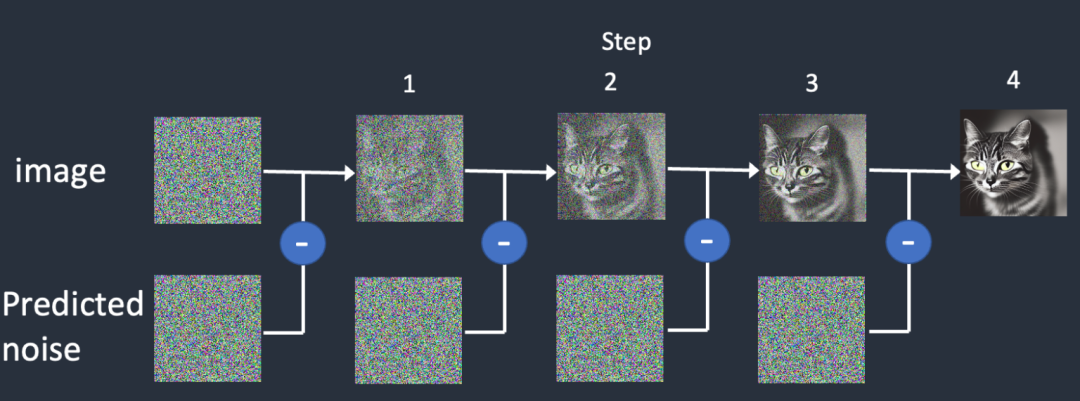
从图中的流程,我们可以看到推理的过程如下:
生成一个随机的noise image图片。这个noise取决于Random这个参数。相同的Random生成的noise image是相同的。
使用noise predictor预测这个图里加了多少noise,生成一个predicted noise。
使用原始的noise减去predicted noise。
不断循环2、3,直到我们的执行steps。
最终我们会得到一只猫。
在这个过程中,我们会以下疑问:
如何得到一个noise predictor?
怎么控制我们最终能得到一只猫?而不是一只狗或者其他的东西?
在回答这些疑问之前,我先贴一部分公式:
我们定义一个noise predictor: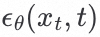 ,
,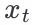 是第 t 个step过程中的noise image,t 表示第t个stop。
是第 t 个step过程中的noise image,t 表示第t个stop。
▐ 如何得到一个noise predictor?
这是一个训练的过程。过程如下图所示:
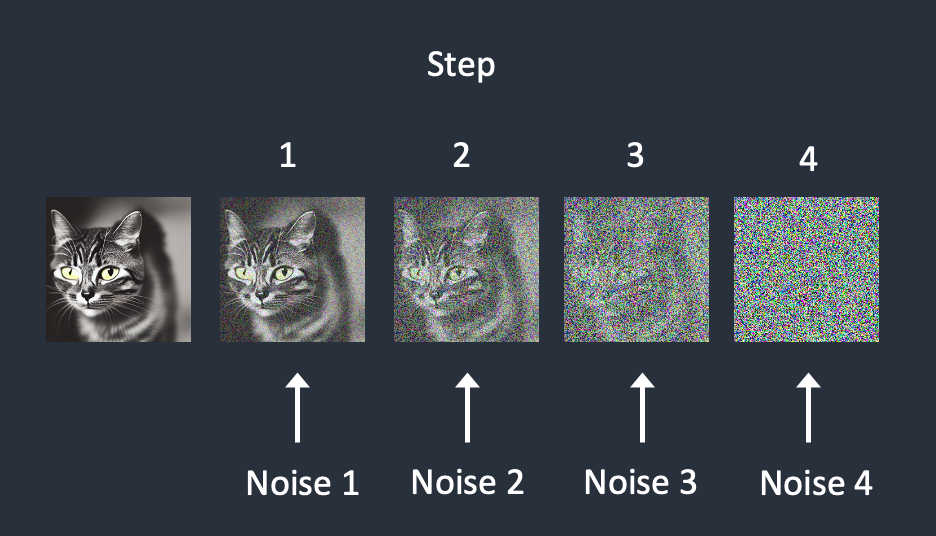
选择一张训练用的图片,比如说一张猫
生成一个随机的noise图片
将noise图叠加到训练用的图片上,得到一张有一些noise的图片。(这里可以叠加1~T步noise
训练noise predictor,告诉我们加了多少noise。通过正确的noise答案来调整模型权重。
最终我们能得到一个相对准确的noise-predictor。这是一个U-Net model。在stable-diffusion-model中。
通过这一步,我们最终能得到一个noise encoder与noise decoder。
PS: noise encoder在image2image中会应用到。
以上noise与noise-predictor的过程均在pixel space,那么就会存在巨大的性能问题。比如说一张1024x1024x3的RBG图片对应3,145,728个数字,需要极大的计算资源。在这里stable diffusion定义了一个Latent Space,来解决这个问题。
▐ Latent Space
Latent Space的提出基于一个理论:Manifold_hypothesis
它假设现实世界中,许多高维数据集实际上位于该高维空间内的低维Latent manifolds。像Pixel Space,就存在很多的难以感知的高频细节,而这些都是在Latent Space中需要压缩掉的信息。
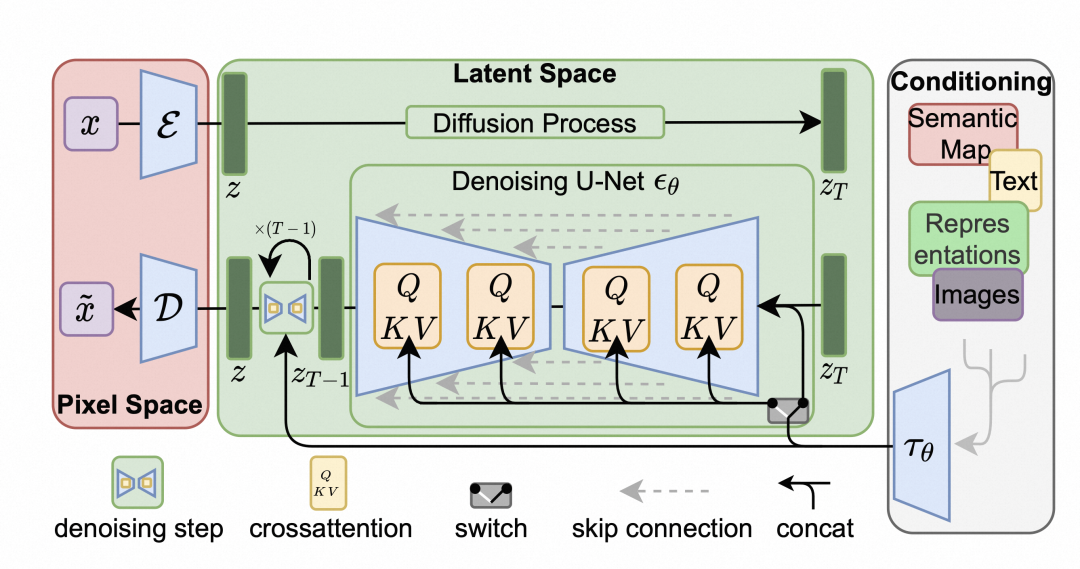
那么基于这个假设,我们先定义一个在RGB域的图片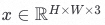
然后存在一个方法z=varepsilon(x),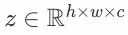 ,z是x在latent space的一种表达。
,z是x在latent space的一种表达。
这里有一个因子f=H/h=W/w,通常我们定义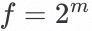 ,比如说stable-diffusion v1.5训练与推理图片在512x512x3,然后Latent Space的中间表达则是4x64x64,那么我们会有一个decoder D能将图片从Latent Space中解码出来。
,比如说stable-diffusion v1.5训练与推理图片在512x512x3,然后Latent Space的中间表达则是4x64x64,那么我们会有一个decoder D能将图片从Latent Space中解码出来。
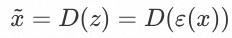 在这个过程中我们期望
在这个过程中我们期望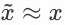 ,这俩图片无限接近。
,这俩图片无限接近。
整个过程如下图所示:
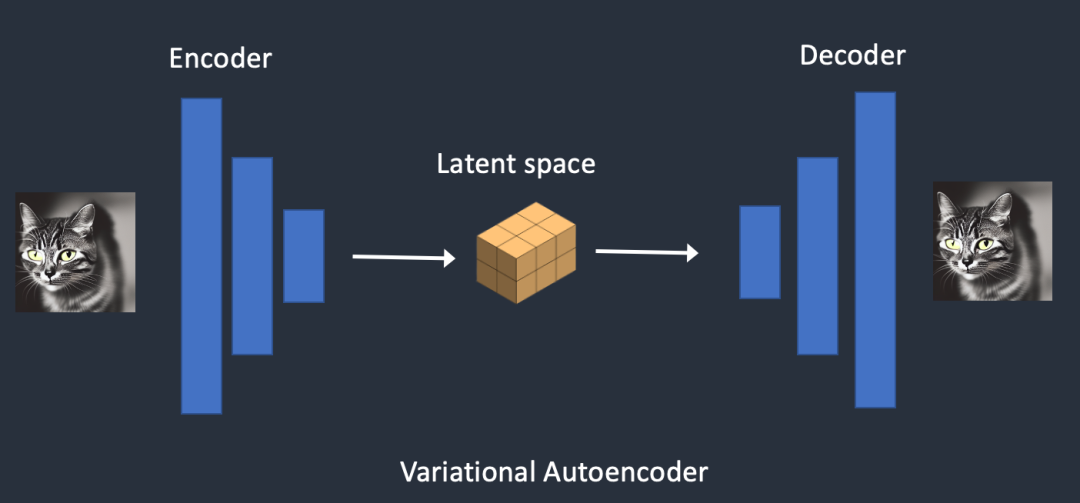
而执行这个过程的就是我们的Variational Autoencoder,也就是VAE。
那么VAE该怎么训练呢?我们需要一个衡量生成图像与训练图像之间的一个距离指标。
也就是 。
。
细节就不关心了,但这个指标可以用来衡量VAE模型的还原程度。训练过程与noise encoder和noise-predictor非常接近。
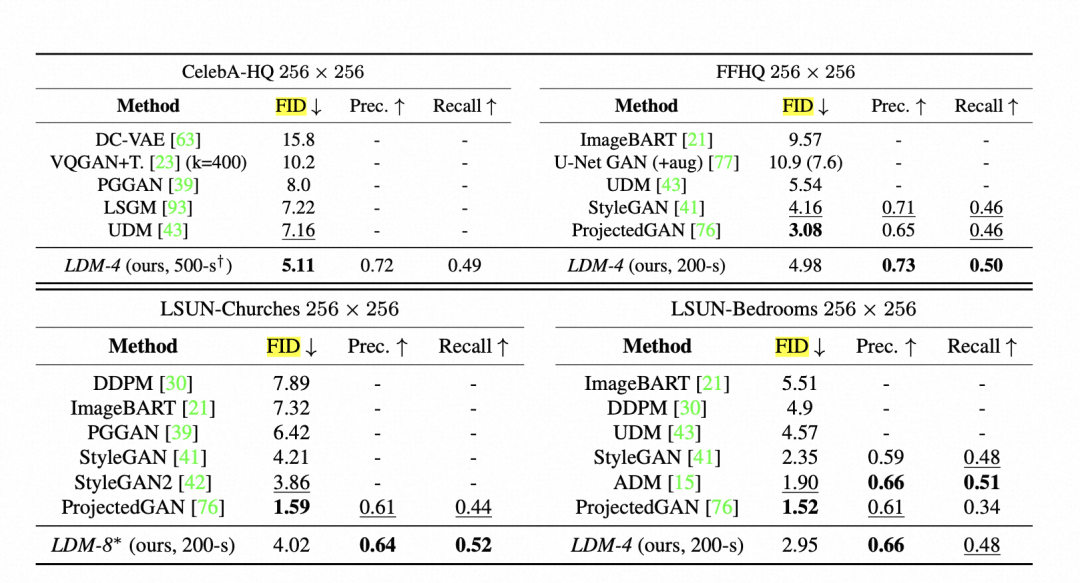
贴一个stable diffusion在FID指标上,与其他方法的对比。下面的表格来自于无条件图片生成。基本就是比较Latent Space是否有丢失重要信息。
为什么Latent Space是可行的?
你可能在想,为什么VAE可以把一张图片压缩到更小的latent space,并且可以不丢失信息。
其实和人对图片的理解是一样的,自然的、优秀的图片都不是随机的,他们有高度的规则,比如说脸上会有眼睛、鼻子。一只狗会有4条腿和一个规则的形状。
图像的高维性是人为的,而自然的图像可以很容易地压缩为更小的空间中而不丢失任何信息。
可能说我们修改了一张图片的很多难以感知的细节,比如说隐藏水印,微小的亮度、对比度的修改,但修改后还是同样的图像吗?我们只能说它表达的东西还是一样的。并没有丢失任何信息。
▐ 结合Latent Space与noise predictor的图像生成过程
生成一个随机的latent space matrix,也可以叫做latent representation。一种中间表达
noise-predictor预测这个latent representation的noise.并生成一个latent space noise
latent representation减去latent space noise
重复2~3,直到step结束
通过VAE的decoder将latent representation生成最终的图片
直到目前为止,都还没有条件控制的部分。按这个过程,我们最终只会得到一个随机的图片。

条件控制
非常关键,没有条件控制,我们最终只能不断地进行Monkey Coding,得到源源不断的随机图片。
相信你在上面的图片生成的过程中,已经感知到一个问题了,如果只是从一堆noise中去掉noise,那最后得到的为什么是有信息的图片,而不是一堆noise呢?
noise-predictor在训练的时候,其实就是基于已经成像的图片去预测noise,那么它预测的noise基本都来自于有图像信息的训练数据。
在这个denoise的过程中,noise会被附加上各种各样的图像信息。
怎么控制noise-predictor去选择哪些训练数据去预测noise,就是条件控制的核心要素。
这里我们以tex2img为案例讨论。
▐ Text Conditioning
下面的流程图,展示了一个prompt如何处理,并提供给noise predictor。
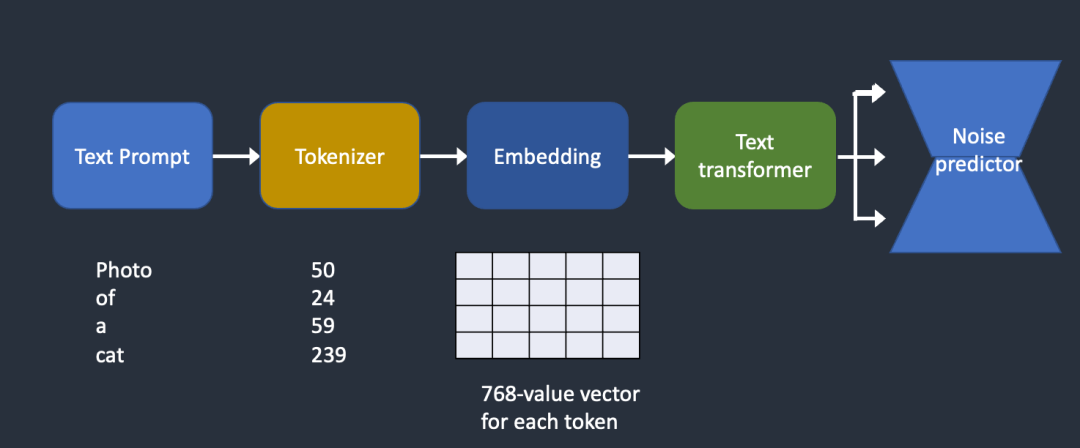
Tokenizer
从图中可以看到,我们的每一个word,都会被tokenized。stable diffusion v1.5使用的openai ViT-L/14 Clip模型来进行这个过程。
tokenized将自然语言转成计算机可理解的数字(NLP),它只能将words转成token。比如说dreambeach会被CLIP模型拆分成dream和beach。一个word,并不意味着一个token。同时dream与beach也不等同于dream和<space>beach,stable diffusion model目前被限制只能使用75个tokens来进行prompt,并不等同于75个word。
Embedding
同样,这也是使用的openai ViT-L/14 Clip model. Embedding是一个768长度的向量。每一个token都会被转成一个768长度的向量,如上案例,我们最后会得到一个4x768的矩阵。
为什么我们需要embedding呢?
比如说我们输入了man,但这是不是同时可以意味着gentleman、guy、sportsman、boy。他们可能说在向量空间中,与man的距离由近而远。而你不一定非要一个完全准确无误的man。通过embedding的向量,我们可以决定究竟取多近的信息来生成图片。对应stable diffusion的参数就是(Classifier-Free Guidance scale)CFG。相当于用一个scale去放大距离,因此scale越大,对应的能获取的信息越少,就会越遵循prompt。而scale越小,则越容易获取到关联小,甚至无关的信息。
如何去控制embedding?
我们经常会遇到stable diffusion无法准确绘制出我们想要的内容。那么这里我们发现了第一种条件控制的方式:textual inversion
将我们想要的token用一个全新的别名定义,这个别名对应一个准确的token。那么就能准确无误地使用对应的embedding生成图片。
这里的embedding可以是新的对象,也可以是其他已存在的对象。
比如说我们用一个玩具猫训练到CLIP模型中,并定义其Tokenizer对应的word,同时微调stable diffusion的模型。而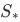 对应
对应toy cat就能产生如下的效果。

感觉有点像Lora的思路,具体还得调研下lora。
text transformer
在得到embedding之后,通过text transformer输入给noise-predictor
transformer可以控制多种条件,如class labels、image、depth map等。
Cross-attention
具体cross-attention是什么我也不是很清楚。但这里有一个案例可以说明:
比如说我们使用prompt "A man with blue eyes"。虽然这里是两个token,但stable diffusion会把这两个单词一起成对。
这样就能保证生成一个蓝色眼睛的男人。而不是一个蓝色袜子或者其他蓝色信息的男人。
(cross-attention between the prompt and the image)
LoRA models modify the cross-attention module to change styles。后面在研究Lora,这里把原话摘到这。
感觉更像是存在blue、eyes,然后有一个集合同时满足blue和eye。去取这个交叉的集合。问题:对应的embedding是不是不一样的?该如何区分blue planet in eye和blue eye in planet的区别?感觉这应该是NLP的领域了。
总结下tex2img的过程
stable diffusion生成一个随机的latent space matrix。这个由Random决定,如果Random不变,则这个latent space matrix不变。
通过noise-predictor,将noisy image与text prompt作为入参,预测predicted noise in latent space
latent noise减去predicted noise。将其作为新的latent noise
不断重复2~3执行step次。比如说step=20
最终,通过VAE的decoder将latent representation生成最终的图片
这个时候就可以贴Stable diffusion论文中的一张图了
手撕一下公式:
左上角的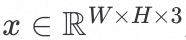 定义为一张RGB像素空间的图。经过
定义为一张RGB像素空间的图。经过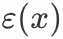 的变化,生成
的变化,生成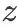 这个latent space representation。再经过一系列的noise encoder,得到
这个latent space representation。再经过一系列的noise encoder,得到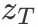 ,T表示step。
,T表示step。
而这个过程则是img2img的input。如果是img2img,那么初始的noise latent representation就是这个不断加noise之后的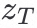 。
。
如果是tex2img,初始的noise latent representation则是直接random出来的。
再从右下角的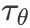 ,
,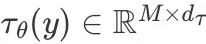 开始,y 表示多样的控制条件的入参,如text prompts。通过
开始,y 表示多样的控制条件的入参,如text prompts。通过 (domain specific encoder)将 y 转为intermediate representation(一种中间表达)。而
(domain specific encoder)将 y 转为intermediate representation(一种中间表达)。而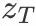 与
与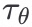 将经过cross-attention layer的实现:
将经过cross-attention layer的实现:
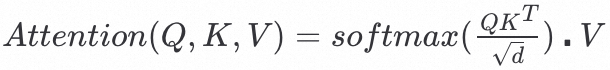
具体的细节说实话没看懂,而这一部分在controlnet中也有解释,打算从controlnet的部分进行理解。
图中cross-attention的部分可以很清晰的看到是一个由大到小,又由小到大的过程,在controlnet的图中有解释:
SD Encoder Block_1(64x64) -> SD Encoder Block_2(32x32) -> SD Encoder Block_3(16x16) -> SD Encoder(Block_4 8x8) -> SD Middle(Block 8x8) -> SD Decoder(Block_4 8x8) -> SD Decoder Block_3(16x16) -> SD Decoder Block_2(32x32) -> SD Decoder Blocker_1(64x64)
是一个从64x64 -> 8x8 -> 64x64的过程,具体为啥,得等我撕完controlnet的论文。回到过程图中,我们可以看到denoising step则是在Latent Space的左下角进行了一个循环,这里与上面的流程一直。
最终通过VAE的decoder D,输出图片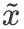
最终的公式如下:
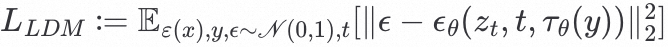
结合上面的图看,基本还是比较清晰的,不过这个:=和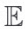 代表了啥就不是很清楚了。结合python代码看流程更清晰~删掉了部分代码,只留下了关键的调用。
代表了啥就不是很清楚了。结合python代码看流程更清晰~删掉了部分代码,只留下了关键的调用。
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16
)
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae")
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet"
)
scheduler = LMSDiscreteScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler"
)
prompt = ["a photograph of an astronaut riding a horse"]
generator = torch.manual_seed(32)
text_input = tokenizer(prompt,padding="max_length",max_length=tokenizer.model_max_length,truncation=True,return_tensors="pt",
)
with torch.no_grad():text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
max_length = text_input.input_ids.shape[-1]
uncond_input = tokenizer([""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
)
with torch.no_grad():uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
latents = torch.randn((batch_size, unet.in_channels, height // 8, width // 8), generator=generator
)
scheduler.set_timesteps(num_inference_steps)
latents = latents * scheduler.init_noise_sigmafor t in tqdm(scheduler.timesteps):latent_model_input = torch.cat([latents] * 2)latent_model_input = scheduler.scale_model_input(latent_model_input, t)with torch.no_grad():noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).samplenoise_pred_uncond, noise_pred_text = noise_pred.chunk(2)noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)latents = scheduler.step(noise_pred, t, latents).prev_samplelatents = 1 / 0.18215 * latentswith torch.no_grad():image = vae.decode(latents).sample还是很贴合图中流程的。
在代码中有一个Scheduler,其实就是noising的执行器,它主要控制每一步noising的强度。
由Scheduler不断加噪,然后noise predictor进行预测减噪。
具体可以看Stable Diffusion Samplers: A Comprehensive Guide(地址:https://stable-diffusion-art.com/samplers/)
▐ Img2Img
这个其实在上面的流程图中已经解释了。这里把步骤列一下:
输入的image,通过VAE的encoder变成latent space representation
往里面加noise,总共加T个noise,noise的强度由Denoising strength控制。noise其实没有循环加的过程,就是不断叠同一个noise T次,所以可以一次计算完成。
noisy image和text prompt作为输入,由noise predictor U-Net预测一个新的noise
noisy image减去预测的noise
重复3~4 step次
通过VAE的decoder将latent representation转变成image
▐ Inpainting
基于上面的原理,Inpainting就很简单了,noise只加到inpaint的部分。其他和Img2Img一样。相当于只生成inpaint的部分。所以我们也经常发现inpaint的边缘经常无法非常平滑~如果能接受图片的细微变化,可以调低Denoising strength,将inpaint的结果,再进行一次img2img

Stable Diffusion v1 vs v2
v2开始CLIP的部分用了OpenClip。导致生成的控制变得非常的难。OpenAI的CLIP虽然训练集更小,参数也更少。(OpenClip是ViT-L/14 CLIP的5倍大小)。但似乎ViT-L/14的训练集更好一些,有更多针对艺术和名人照片的部分,所以输出的结果通常会更好。导致v2基本没用起来。不过现在没事了,SDXL横空出世。

SDXL model
SDXL模型的参数达到了66亿,而v1.5只有9.8亿
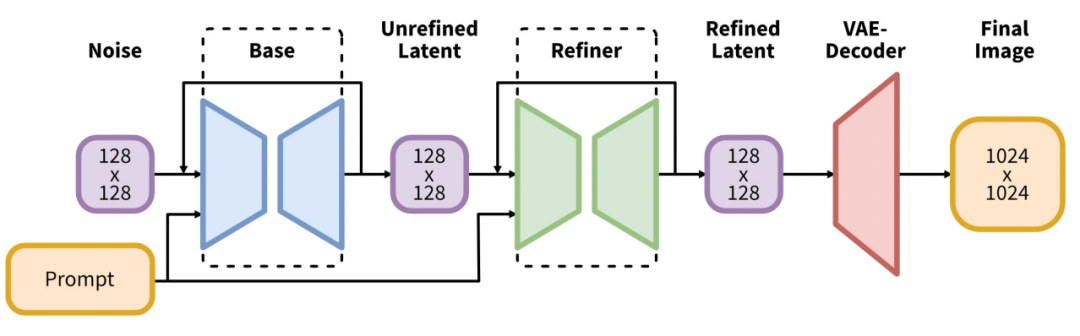
由一个Base model和Refiner model组成。Base model负责生成,而Refiner则负责加细节完善。可以只运行Base model。但类似人脸眼睛模糊之类的问题还是需要Refiner解决。
SDXL的主要变动:
text encoder组合了OpenClip和ViT-G/14。毕竟OpenClip是可训练的。
训练用的图片可以小于256x256,增加了39%的训练集
U-Net的部分比v1.5大了3倍
默认输出就是1024x1024
展示下对比效果:
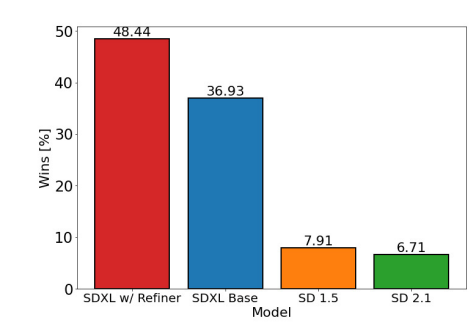
从目前来看,有朝一日SDXL迟早替代v1.5。从效果来说v2.1确实被时代淘汰了。

Stable Diffusion的一些常见问题
▐ 脸部细节不足,比如说眼部模糊
可以通过VAE files进行修复~有点像SDXL的Refiner
▐ 多指、少指
这个看起来是一个无解的问题。Andrew给出的建议是加prompt比如说beautiful hands和detailed fingers,期望其中有部分图片满足要求。或者用inpaint。反复重新生成手部。(这个时候可以用相同的prompt。)

团队介绍
我们是淘天集团-场景智能技术团队,作为一支专注于通过AI和3D技术驱动商业创新的技术团队, 依托大淘宝丰富的业务形态和海量的用户、数据, 致力于为消费者提供创新的场景化导购体验, 为商家提供高效的场景化内容创作工具, 为淘宝打造围绕家的场景的第一消费入口。我们不断探索并实践新的技术, 通过持续的技术创新和突破,创新用户导购体验, 提升商家内容生产力, 让用户享受更好的消费体验, 让商家更高效、低成本地经营。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法
相关文章:
从零开始的stable diffusion
stable diffusion真的是横空出世,开启了AIGC的元年。不知你是否有和我一样的困惑,这AI工具好像并不是那么听话? 前言 我们该如何才能用好stable diffusion这个工具呢?AI究竟在stable diffusion中承担了什么样的角色?如…...

【Qt之QString】数值与进制字符串间的转换详解
在Qt中,可以使用QString类提供的一些方法来进行数值和进制字符串之间的转换。 以下是示例: 1. 将整数转换为进制字符串: QString类的number静态方法用于将整数转换为字符串表示,并且可以指定转换的进制。方法的定义如下&#x…...

Pytest单元测试框架 —— Pytest+Allure+Jenkins的应用
一、简介 pytestallurejenkins进行接口测试、生成测试报告、结合jenkins进行集成。 pytest是python的一种单元测试框架,与python自带的unittest测试框架类似,但是比unittest框架使用起来更简洁,效率更高 allure-pytest是python的一个第三方…...

科普向丨语音芯片烧录工艺的要求
语音芯片烧录工艺要求烧录精度、速度、内存容量、电源稳定性、兼容性和数据安全性。这些要素需优化和控制以保证生产高效、稳定、安全并烧录出高质量的语音芯片。不同厂家生产的语音芯片在烧录工艺上存在差异,需相应设计和研发以实现兼容。 一、烧录精度 语音芯片烧…...
 但是它将不会被安装 或)
: 依赖: qtbase5-dev (= 5.12.8+dfsg-0ubuntu2.1) 但是它将不会被安装 或
有一些软件包无法被安装。如果您用的是 unstable 发行版,这也许是因为系统无法达到您要求的状态造成的。E: 无法修正错误,因为您要求某些软件包保持现状,就是它们破坏了软件包间的依赖关系。_unstable发行版-CSDN博客 E: 无法修正错误&#x…...

Unity中Camera类实现坐标系转换的示例
1. 用于将世界坐标系转换为屏幕坐标系 using System.Collections; using System.Collections.Generic; using UnityEngine;public class Camer_Class_WorldTo : MonoBehaviour {// 用于将世界坐标系转换为屏幕坐标系//本脚本将完成一个案例实现 小球从远处过来Transform Sta…...

vue-按键修饰符
按键修饰符:主要用于监听键盘上的按钮被按下时,可触发对应的事件函数 v-on:keyup.修饰符.修饰符】、 .enter .tab .delete(针对delete和backspace两个按键) .esc .space .esc .space .up .down .left .right 系统修饰符必须按下才触发 .ctrl .alt .shift…...
[初始java]——java为什么这么火,java如何实现跨平台、什么是JDK/JRE/JVM
java的名言: ”一次编译、到处运行“ 一、编译语言与解释语言 编译: 是将整份源代码转换成机器码再进行下面的操作,最终形成可执行文件 解释: 是将源代码逐行转换成机器码并直接执行的过程,不需要生成目标文件 jav…...

R语言手动绘制NHANSE数据基线表并聊聊NHANSE数据制作亚组交互效应表的问题(P for interaction)
美国国家健康与营养调查( NHANES, National Health and Nutrition Examination Survey)是一项基于人群的横断面调查,旨在收集有关美国家庭人口健康和营养的信息。 地址为:https://wwwn.cdc.gov/nchs/nhanes/Default.aspx 在既往的…...
)
C++引用(起别名)
0.引用的概念 引用不是新定义一个变量,而是给已存在变量取了一个别名,从语法的角度来说编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。比如说你的名字和外号指的都是你本人。 void Test() {int a 10;int& ra …...
Ubuntu:VS Code IDE安装ESP-IDF【保姆级】(草稿)
物联网开发学习笔记——目录索引 Visual Studio Code(简称“VS Code”)是Microsoft向开发者们提供的一款真正的跨平台编辑器。 参考: VS Code官网:Visual Studio Code - Code Editing. Redefined 乐鑫官网:ESP-IDF …...
rust解法)
子序列(All in All, UVa 10340)rust解法
输入两个字符串s和t,判断是否可以从t中删除0个或多个字符(其他字符顺序不变),得到字符串s。例如,abcde可以得到bce,但无法得到dc。 解法 use std::io;fn main(){let mut buf String::new();io::stdin().…...

AI时代,当项目经理遇到ChatGPT,插上腾飞的翅膀!
文章目录 一、 ChatGPT 在项目管理中的应用1. 任务分配和跟踪2. 风险管理3. 沟通和协作 二、 ChatGPT 在项目管理中的优势1. 高效性2. 可靠性3. 灵活性 三、 ChatGPT 在项目管理中的应用场景1. 智能会议2. 智能文档3. 智能报告 结语AI时代项目经理成长之道:ChatGPT让…...
Springboot项目中加载Groovy脚本并调用其内部方代码实现
前言 项目中部署到多个煤矿的上,每一种煤矿的情况都相同,涉及到支架的算法得写好几套,于是想到用脚本实现差异变化多的算法!一开始想到用java调用js脚本去实现,因为这个不需要引入格外的包,js对我来说也没…...

为什么要做数据可视化
在当今信息爆炸的时代,数据已成为个人和企业最宝贵的资产之一。然而,仅仅拥有大量的数据并不足以支持明智的决策。数据可视化,作为一种将数据转化为图形形式的技术和方法,可以帮助我们更好地理解和分析数据,从而更准确…...
0基础学习VR全景平台篇 第108篇:全景图细节处理(下,航拍)
上课!全体起立~ 大家好,欢迎观看蛙色官方系列全景摄影课程! (调色前图库) (原图-大图) 一、导入文件 单击右下角导入按钮,选择航拍图片所在文件夹,选择图片࿰…...
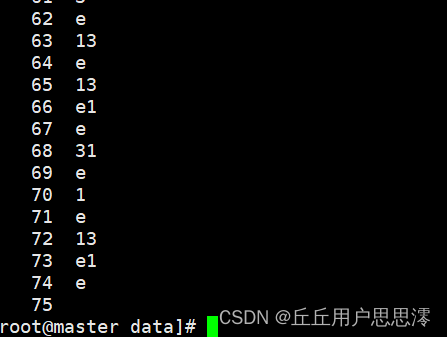
linux查看文件内容命令more/less/cat/head/tail/grep
1.浏览全部内容more/less 文件: more:可以查看文件第一屏的内容,同时左下角有一个显示内容占全部文件内容的百分比,空格键会显示下一屏的内容,直到文件末尾 [rootmaster data]# more file1less:相较于mor…...
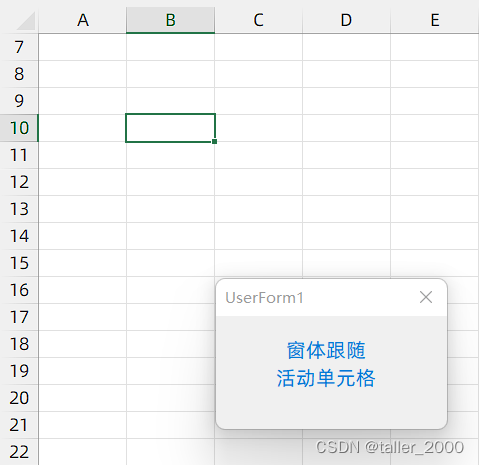
VBA窗体跟随活动单元格【简易版】
本篇博客与以往的风格不同,先上图再讲解。 这个效果是不是很酷,VBA窗体(即UserForm,下文中简称为窗体)可以实现很多功能,例如:用户输入数据,提供选项等等。如本博客标题标注&#…...
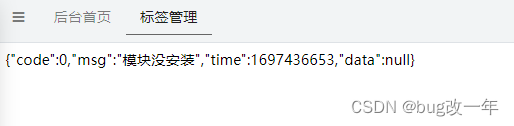
epiiAdmin框架注意事项
1,epiiAdmin文档地址: 简介/安装 EpiiAdmin中文文档 看云 2,项目性想新建模块 composer.json文件——autoload选项——psr-4下增加模块名称,然后执行composer update命令。 "autoload": {"psr-4": {"…...

数据仓库与ETL
什么是数据仓库 一种用于存储和管理数据的系统,提供一种统一方式,将不同来源、不同方式、不同时间的数据集成在一起。 数据仓库结构 主题域:一个特定领域的数据集,比如营销、销售、客户、库存等。 维度:定义数据的不…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

Webpack性能优化:构建速度与体积优化策略
一、构建速度优化 1、升级Webpack和Node.js 优化效果:Webpack 4比Webpack 3构建时间降低60%-98%。原因: V8引擎优化(for of替代forEach、Map/Set替代Object)。默认使用更快的md4哈希算法。AST直接从Loa…...