未来展望:大型语言模型与 SQL 数据库集成的前景与挑战
一、前言
随着 GPT-3、PaLM 和 Anthropic 的 Claude 等大型语言模型 (LLM) 的出现引发了自然语言在人工智能领域的一场革命。这些模型可以理解复杂的语言、推理概念并生成连贯的文本。这使得各种应用程序都能够使用对话界面。然而,绝大多数企业数据都存储在结构化 SQL 数据库中,例如 PostgreSQL、MySQL 和 TiDB。通过自然对话无缝访问和分析这些数据仍然具有挑战性。
最近新的研究提出了增强LLM与 SQL 数据库集成的技术,重点是跨领域和跨组合泛化。例如,Arora等人设计了一种算法[1],用于抽样涵盖所有 SQL 子句和运算符的多样化少量示例以有效提示LLM。他们的领域适应方法通过语义相似性将这些少量示例适应于目标数据库。此外,最少到最多提示技术将少量示例分解为具有中间表示的子问题,以提高组合泛化能力。
本文主要探讨了将大型语言模型与 SQL 数据库集成的前景和挑战。
二、将 LLM 与 SQL 数据库融合的初衷
其实原因很简单,前面我们在介绍 LangChain 框架的时候,有单独介绍过如何基于 LangChain 技术结合 LLM 实现自然语言操作数据库《LangChain:使用自然语言查询数据库》,包括业界这半年时间也陆续发布了一些关于DB和LLM结合的产品,都是希望能够将 LLM 模型的强大能力可以应用在数据库和大数据分析领域,试想一下以后业务分析师和业务用户只需要输入一段普通文本就可以直接与数据进行对话,快速或者到想要的结果,而不需要编写 SQL 查询。这样可以实现数据访问大众化、加速分析并释放数据驱动自动化的新可能性。
但是,想要有效地实现 LLM 与 SQL 之间类似人类语义交互的功能,需要克服有关查询正确性、安全性和性能等关键挑战。结合 LLM 的语义理解能力和 SQL 的丰富分析能力,可能会彻底改变我们与数据互动的方式。未来,我们与数据进行对话可能会像日常聊天一样自然流畅!
接下来我们将来讨论如仔细提示、验证循环和基于角色的访问控制等技术,这些技术可以为生产 LLM-SQL 集成铺平道路。
总的来说,融合 LLM 与 SQL 的原因有很多:
-
自然语言界面 —— 用户无需编写复杂的 SQL 查询语句,只需用平易近人的英语与数据库进行交谈。比如,他们只需要问 "上个月最热销的产品是什么?" 而无需编写 JOIN 和 GROUPBY 查询语句。这样一来,获取数据就变得更加直观,处理分析型数据的门槛也大大降低。
-
数据民主化 —— 启用自然语言界面后,即使是没有技术性 SQL 技能的用户也能访问到数据。商业用户、分析师甚至高管都可以通过自然对话直接获取有价值的洞见,从而实现整个组织的数据驱动决策。
-
增强型分析 —— LLM 已经展示出了其在理解信息和产生洞见方面的强大能力,它们能生成摘要、可视化和叙述。将它们与 SQL 集成后,可以自动用生成的文本、图表和图形来增强查询结果,突出显示关键趋势和发现。这样就能加快分析工作流程。
-
工作流自动化 —— 有了会话界面后,LLM 可以通过语音命令或聊天机器人集成到自动化工作流中。常见的分析工作流程可以通过对机器人说话来激活。例如,只需说 "运行我的周销售分析" 就可以生成周销售报告。具有 LLM SQL 访问权限的机器人可以成为数据分析师的智能助手。
-
增强协作 —— 通过结合 NLP 技术和 SQL 访问权限,LLM 可以实现数据分析的跨职能协作。各方利益相关者可以通过自然语言对话来讨论数据集,并交流他们的发现。在这个过程中,LLM 充当了 SQL 的接口,将对话转化为查询,并分享洞察。
-
多模态分析 —— LLM 接口允许我们无缝地将 SQL 数据与知识图、向量数据库以及其他数据源进行整合。这使我们能够进行多模态分析,从而获得更全面的洞察。
最终目标是让我们与数据的交互变得像人类之间的对话一样简单直观。通过 LLM 的自然语言处理能力和 SQL 数据库的丰富分析功能,我们可以进一步提升数据的民主化、自动化和协作。
三、使用外部数据增强 SQL
到目前为止,我们主要关注的是 LLM 和 SQL 数据库之间的接口。但实际上,存储在企业 SQL 系统中的数据只是整个数据难题的一部分。关键性的知识还存在于知识图谱、向量数据库、外部 API 等。
LLM 提供了一个独特的机会,能够无缝地整合和增强来自不同来源的数据。
LLM 可以查询 SQL 数据库,并通过调用知识图谱获取相关实体来增强查询结果。它还可以在企业向量数据库中进行相似性搜索,找到相关文档。此外,外部 API 可以提供补充数据以增强 SQL 的结果。
例如,在查询销售数据库时,LLM 可以通过使用地理空间 API 在地图上叠加结果来增强地理分析。在分析客户流失时,它可以引入向量化账户配置文件以揭示常见模式。当与其他来源的数据混合时,从 SQL 查询中得到的洞察力会变得更强大。
为了实现这一点,LLM 查询接口应该允许编排对各种内部和外部数据源的调用。然后,LLM 可以利用其强大的语言理解能力来分析汇总后的数据,并通过自动生成摘要、可视化和叙述来综合洞察力。
使用多模态数据增强 SQL 不仅可以提升单个查询的效果,还开启了构建虚拟知识图谱的可能性,将结构化数据库与非结构化知识连接起来。这使得组织能够从他们的企业数据中提取出更多价值。
四、SQL 结合向量数据库查询
4.1、方法 1 — SQLAutoVectorQueryEngine:
-
这种方法将单独的 SQL 和向量查询引擎融合成一个名为 SQLAutoVectorQueryEngine 的工具,该引擎可以同时从两种数据存储中提取信息。
-
这种方法已经在城市数据上进行了演示,其中使用了 SQLite 数据库和 Pinecone 向量索引。
-
它可以将查询路由到适当的引擎,并将结果进行整合。
具体示例可以参考[2]
4.2、方法 2 — SQLAlchemy 中的 PGVector:
-
这种方法通过将嵌入作为向量列存储在 PostgreSQL 中,实现了语义搜索。
-
它允许用户进行富有表现力的文本到 SQL 查询,包括过滤器和相似性搜索。
-
此外,它还提供了专门针对 PGVector 语法的自定义文本到 SQL 提示符。
具体示例可以参考[3]
4.3、方法 3 — OpenAI 函数 API:
-
这种方法使用 OpenAI 的函数 API 和代理进行跨 SQL 和向量的检索,而不是使用自定义检索器。
-
它定义了一个用于从向量自动检索信息的函数,并使用 SQL 和向量工具初始化代理。
-
尽管这种方法展示了联合查询的潜力,但仍需要进行更全面的稳健性分析。
具体示例可以参考[4]
4.4、关键挑战
目前面临着一些关键挑战,包括查询路由逻辑、跨数据库检索的限制、语义搜索能力的性能和质量以及随着复杂性增加而增加的稳健性扩展。
4.5、未来的研究
目前正在研究一些未来可能会探索的方向,包括简单且富有表现力的混合接口、增强提示的技术(如释义)、合并数据库元数据和统计信息,以及扩展到其他数据源(如知识图谱)。
五、LLM-SQL 集成的挑战
然而,想要有效地将 LLM 和 SQL 集成起来,目前可能还需要面对一些独特的挑战:
-
幻觉现象 —— 由于 LLM 是以概率方式生成文本,因此它们可能会产生一些不存在于实际数据库中的表或列等数据库元素的查询请求,我们称之为"幻觉"查询。这可能导致生成无效的 SQL 查询语句,从而得到错误的结果。
-
上下文长度限制 —— 大型语言模型在操作时有一定的上下文窗口长度限制。但是,包括模式定义和列详细信息在内的数据库元数据可能远超过这些令牌限制。这使得 LLM 很难在完整的数据库上下文中找到自己的定位。
-
查询错误 —— LLM 可能成功地理解了用户意图,但仍然可能生成逻辑错误的 SQL 查询语句,从而导致错误结果。次优的数据采样和提示可能导致此类错误发生。由于缺乏正式推理能力,LLM 很难生成无误差的 SQL 查询语句。
-
成本和性能问题 —— 随着查询复杂度增加,通过 LLM 生成和验证 SQL 查询语句所需的计算成本也会相应增加。大量使用 LLM 可能会导致高昂且不可预测的成本。同时,由于推理延迟问题,系统性能也可能受到影响。
-
安全性和治理问题 —— 在对话界面中,用户并没有明确指定查询语句,而只是表达了他们的意图。因此,保护数据访问和进行适当的治理变得非常具有挑战性。
-
可解释性问题 —— 解释为什么 LLM 会根据对话式自然语言意图生成特定的 SQL 查询语句可能会非常困难。缺乏可解释性使得调试失败更加困难。
-
监控和测试问题 —— 对于动态生成的 SQL 查询语句,进行持续的监控、测试和验证是非常困难的。要达到生产就绪状态,需要进行大量的测试。
六、潜在的解决方案
以下是一些可能解决这些挑战的策略:
6.1、信息提示
通过详细描述数据库模式、样本数据行、有效的 SQL 查询和业务逻辑,我们可以仔细地为 LLM 做好准备。这样可以使 LLM 在现实中找到自己的定位,避免出现"幻觉"错误。像通用提示这样的技术可以帮助我们创建覆盖 SQL 结构的代表性提示。
decompose_prompt(adapted_prompt):decomposed_prompt = []for query_pair in adapted_prompt:nl_questions = decompose_nl(query_pair.nl)sql_reps = generate_intermediate_sql(nl_questions)decomposed = [QueryRep(nl, sql) for nl, sql in zip(nl_questions, sql_reps)]decomposed_prompt.append(decomposed)return decomposed_prompt6.2、渐进式提示
将复杂的对话意图分解成逻辑子查询,有助于 LLM 逐步学习。中间步骤可以解释每个子查询的意图和数据需求。这样可以提高组合泛化能力,有助于处理查询错误。
6.3、语法验证
在执行前,我们可以验证生成的 SQL 查询语句在语法上是否正确。如果出现错误,我们可以通过解释错误来重新提示 LLM 进行更正。这样可以捕获任何不正确的 SQL 查询语句。
例如,LLM 从输入 "显示每个产品上个月的总销售额" 中生成了一个 SQL 查询语句。在执行前,我们使用 SQL 解析器验证查询语句,发现查询错误地引用了不存在的 "销售" 表。然后我们重新提示 LLM 来纠正查询。
6.4、用户反馈循环
通过收集用户对查询质量的持续反馈,并使用它来进一步微调提示,我们可以通过持续学习来提高 LLM 的性能。
例如,用户对像 "上个季度销售最好的产品是哪些?" 这样的查询检索到的结果进行相关性评级。这个反馈被用来进一步微调提示工程并训练 LLM 更好地定位其查询。
6.5、混合接口
允许在对话和更准确的查询接口之间无缝切换提供了一个备选方案,并在 LLM 接口成熟时弥补了差距。
例如,对话接口允许用简单的中文问 "我的顶级客户是谁?"。然而,对于更复杂的分析需求,用户可以无缝切换到 GUI 查询构建器接口来制作准确的 SQL 查询。
6.6、使用监控
通过跟踪计算使用统计信息,我们可以防止过度使用导致的过高成本,如果需要,我们可以通过限制请求来实现。此外,缓存也有所帮助。 例如,根据查询的数量和复杂性,我们跟踪 LLM 的计算使用情况。如果由于使用量激增预计会产生过高的成本,我们可以通过限流来限制非关键查询以控制费用。
6.7、访问控制
我们可以与现有访问控制框架集成以管理安全性,而不是直接暴露 LLM。我们可以根据用户凭证验证查询。
例如,用户通过中间件层与 LLM 进行交互,而不是直接交互。这样我们就可以验证用户在允许将 "显示客户地理位置的平均订单值" 的查询传递给 LLM 之前是否具有适当的数据访问权限。
6.8、领域适应
将通用提示适应目标数据库模式有助于使 LLM 适应新数据库。
adapt_to_target(generic_prompt, target_schema):adapted_prompt = []for query_pair in generic_prompt:sql = query_pair.sqladapted_sql = generate_similar_sql(sql, target_schema)nl = generate_nl(adapted_sql)adapted_prompt.append(QueryPair(nl, adapted_sql))return adapted_prompt6.9、最少到最多提示
渐进地分解查询有助于提高组合泛化能力。
decompose_prompt(adapted_prompt):decomposed_prompt = []for query_pair in adapted_prompt:nl_questions = decompose_nl(query_pair.nl)sql_reps = generate_intermediate_sql(nl_questions)decomposed = [QueryRep(nl, sql) for nl, sql in zip(nl_questions, sql_reps)]decomposed_prompt.append(decomposed)return decomposed_prompt我们最终目标应该是无缝、安全、高效能的 LLM 查询接口,与人类分析师相匹敌。如果要实现企业生产应用,需要进行仔细训练、验证和采用混合接口。
七、总结
如果能实现通过最直接的自然语言对话来分析企业数据,确实能带来不小的影响,然而,想要有效地将大型语言模型与生产 SQL 数据库集成,我们需要面对一些关于正确性、安全性、成本和治理等方面的关键挑战。
通过精心设计的提示策略、验证循环和混合接口,LLM 可以在不影响准确性、性能或控制的情况下,使数据访问更直观。领域适应、从最少到最多提示和渐进式分解等技术也显示出改善自然语言 SQL 接口的稳健性的前景。
随着 LLM 的能力以快速的速度不断趋于成熟,它们与数据访问堆栈的集成将变得更加可行。在未来,负责监督数据工作流的对话式分析机器人可能会成为企业现实。通过语言接口对数据进行民主化可以引领一个新层次的跨职能协作时代。
然而,负责任和受控的集成对于企业采用仍然至关重要。这项技术必须通过严格的测试和验证来赢得信任。通过审慎的方法,对话式 AI 和 SQL 分析之间的协同效应提供了巨大的机会来改变人类与数据互动的方式。前进的道路充满挑战,但可能性使它成为一个有益的旅程,可能会重塑企业分析和数据驱动决策的未来。
八、References
[1]. Adapt and Decompose: Efficient Generalization of Text-to-SQL via Domain Adapted Least-To-Most Prompting(https://arxiv.org/abs/2308.02582)
[2]. SQLAutoVectorQueryEngine examples:(https://docs.llamaindex.ai/en/stable/examples/query_engine/SQLAutoVectorQueryEngine.html#sql-auto-vector-query-engine)
[3]. SQLAlchemy 中的 PGVector examples:
https://docs.llamaindex.ai/en/latest/examples/query_engine/pgvector_sql_query_engine.html
[4]. OpenAI 函数 API examples:
https://docs.llamaindex.ai/en/stable/examples/agent/openai_agent_query_cookbook.html
相关文章:

未来展望:大型语言模型与 SQL 数据库集成的前景与挑战
一、前言 随着 GPT-3、PaLM 和 Anthropic 的 Claude 等大型语言模型 (LLM) 的出现引发了自然语言在人工智能领域的一场革命。这些模型可以理解复杂的语言、推理概念并生成连贯的文本。这使得各种应用程序都能够使用对话界面。然而,绝大多数企业数据都存储在结构化 …...
SpringCloud-Hystrix
一、介绍 (1)避免单个服务出现故障导致整个应用崩溃。 (2)服务降级:服务超时、服务异常、服务宕机时,执行定义好的方法。(做别的) (3)服务熔断:达…...
Ansible脚本进阶---playbook
目录 一、playbooks的组成 二、案例 2.1 在webservers主机组中执行一系列任务,包括禁用SELinux、停止防火墙服务、安装httpd软件包、复制配置文件和启动httpd服务。 2.2 在名为dbservers的主机组中创建一个用户组(mysql)和一个用户&#x…...

pytorch 模型部署之Libtorch
Python端生成pt模型文件 net.load(model_path) net.eval() net.to("cuda")example_input torch.rand(1, 3, 240, 320).to("cuda") traced_model torch.jit.trace(net, example_input) traced_model.save("model.pt")output traced_model(exa…...
Unity——数据存储的几种方式
一、PlayerPrefs PlayerPrefs适合用于存储简单的键值对数据 存储的数据会在游戏关闭后依然保持,并且可以在不同场景之间共享,适合用于需要在游戏不同场景之间传递和保持的数据。 它利用key-value的方式将数据保存到本地,跟字典类似。然后通…...

『heqingchun-ubuntu系统下安装cuda与cudnn』
ubuntu系统下安装cuda与cudnn 一、安装依赖 1.更新 sudo apt updatesudo apt upgrade -y2.基础工具 sudo apt install -y build-essential python二、安装CUDA 1.文件下载 网址 https://developer.nvidia.com/cuda-toolkit-archive依次点击 (1)“CUDA Toolkit 11.6.2”…...
Unity AI Muse 基础教程
Unity AI Muse 基础教程 Unity AI 内测资格申请Unity 项目Package ManagerMuse Sprite 安装Muse Texture 安装 Muse Sprite 基础教程什么是 Muse Sprite打开 Muse Sprite 窗口Muse Sprite 窗口 参数Muse Sprite Generations 窗口 参数Muse Sprite Generations 窗口 画笔Muse Sp…...
pgsl基于docker的安装
1. 有可用的docker环境 ,如果还没有安装docker,则请先安装docker 2. 创建pg数据库的挂载目录 mkdir postgres 3. 下载pg包 docker pull postgres 这个命令下载的是最新的pg包,如果要指定版本的话,则可以通过在后面拼接 :versio…...

idea设置某个文件修改后所在父文件夹变蓝色
idea设置某个文件修改后所在父文件夹变蓝色的方法: 老版idea设置方法: File---->Settings---->Version Control---->勾选 Show directories with changed descendants 新版idea设置方法: File---->Settings---->Version Co…...

代码随想录训练营二刷第五十八天 | 583. 两个字符串的删除操作 72. 编辑距离
代码随想录训练营二刷第五十八天 | 583. 两个字符串的删除操作 72. 编辑距离 一、583. 两个字符串的删除操作 题目链接:https://leetcode.cn/problems/delete-operation-for-two-strings/ 思路:定义dp[i][j]为要是得区间[0,i-1]和区间[0,j-1]所需要删除…...

秋日有感之秋诉-于光
诗:于光 秋风扫叶枝不舍, 叶落随风根欢唱。 秋日穿云不入眼, 云亦婆娑诉余年。...

ubuntu 22.04版本修改服务器名、ip,dns信息的操作方法
总结 1、ubuntu修改服务器名重启后生效的方法是直接修改/etc/hostname文件 2、ubuntu 22.04操作系统配置ip和dns信息,一般只需要使用netplan命令行工具来配置就行,在/etc/netplan/在目录下创建一个yaml文件就可以实现ip和dns的配置,当然如果…...
【微信小程序】6天精准入门(第2天:小程序的视图层、逻辑层、事件系统及页面生命周期)
一、视图层 View 1、什么是视图层 框架的视图层由 WXML 与 WXSS 编写,由组件来进行展示。将逻辑层的数据反映成视图,同时将视图层的事件发送给逻辑层。WXML(WeiXin Markup language) 用于描述页面的结构。WXS(WeiXin Script) 是小程序的一套脚本语言&am…...

速学Linux丨一文带你打开Linux学习之门
前言 如果你是刚开始学习Linux的小白同学,相信你已经体会到与学习一门编程语言相比,学习Linux系统的门槛相对较高,你会遇到一些困惑,比如: 为什么要学习Linux,学成之后我们可以在哪些领域大显身手…...
符尧:别卷大模型训练了,来卷数据吧!【干货十足】
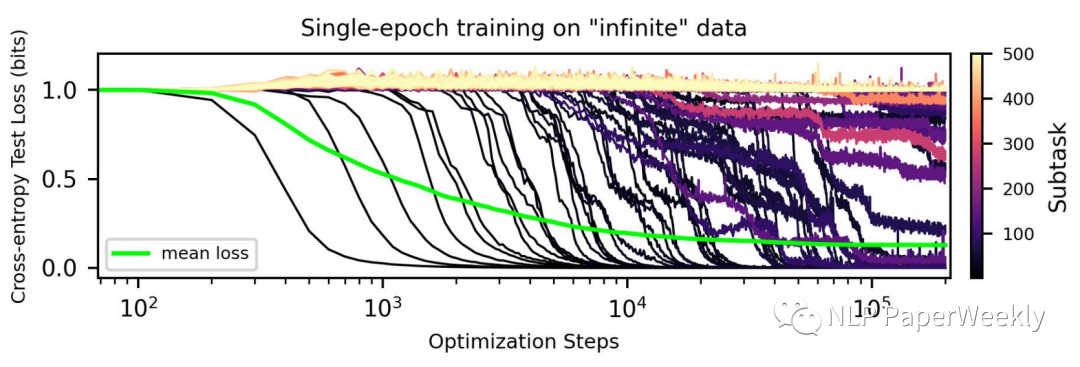
大家好,我是HxShine。 今天分享一篇符尧大佬的一篇数据工程(Data Engineering)的文章,解释了speed of grokking指标是什么,分析了数据工程(data engineering)包括mix ratio(数据混合…...

2023年中国半导体检测仪器设备销售收入、产值及市场规模分析[图]
半导体测试设备是一种用于电子与通信技术领域的电子测量仪器。随着技术发展,半导体芯片晶体管密度越来越高,相关产品复杂度及集成度呈现指数级增长,这对于芯片设计及开发而言是前所未有的挑战,随着芯片开发周期的缩短,…...

诊断DLL——Visual Studio安装与dll使用
文章目录 Visual Studio安装一、DLL简介二、使用步骤1.新建VS DLL工程2.生成dll文件3.自定义函数然后新建一个function.h文件,声明这个函数。4.新建VS C++ console工程,动态引用DLL编写代码,调用dll三、extern "C" __declspec(dllexport)总结Visual Studio安装 官…...

专业课138,总分390+,西工大,西北工业大学827信号与系统考研分享
数学一 考研数学其实严格意义上已经没有难度大小年之分了,说21年难的会说22年简单,说22年简单的做23年又会遭重,所以其实只是看出题人合不合你的口味罢了,建议同学不要因偶数年而畏惧,踏踏实实复习。资料方面跟谁就用…...

css3链接
你可以使用CSS3来自定义链接(超链接)的样式,以改变它们的外观。以下是一些用于自定义链接的常见CSS3样式规则: 链接的颜色: a { color: #0077b6; /* 设置链接的文字颜色 */ } 这个规则可以改变链接的文字颜色。你可以根据需要设置…...

第五章 运输层 | 计算机网络(谢希仁 第八版)
文章目录 第五章 运输层5.1 运输层协议概述5.1.1 进程之间的通信5.1.2 运输层的两个主要协议5.1.3 运输层的端口 5.2 用户数据报协议UDP5.2.1 UDP概述5.2.2 UDP的首部格式 5.3 传输控制协议TCP概述5.3.1 TCP最主要的特点5.3.2 TCP的连接 5.4 可靠传输的工作原理5.4.1 停止等待协…...

OpenAI 的 Harness Engineering介绍
OpenAI 的 Harness Engineering(驾驭工程)是其在 2026 年初提出的一种全新软件工程范式,旨在应对“智能体优先”(agent-first)的开发环境。这一概念的核心在于:人类工程师不再直接编写代码,而是设计环境、明确意图并构建反馈循环,让 AI 智能体(如 Codex)自主完成编码…...

BGE-Large-Zh实际作品:向量示例+热力图+最佳匹配三视图完整呈现
BGE-Large-Zh实际作品:向量示例热力图最佳匹配三视图完整呈现 1. 工具概览:中文语义理解的视觉化利器 BGE-Large-Zh语义向量化工具是一个专门为中文文本理解设计的本地化工具,它能够将中文文字转换为机器可以理解的数字向量,并通…...

C#与Sql Server 2008 R2图书信息管理系统源码解析:基于VS2015与.NET...
C#与Sql server 2008 R2图书信息管理系统,源码带注释,VS2015版本,.net4.5框架最近在整理硬盘翻出个古董项目——基于C#和SQL Server 2008 R2的图书管理系统。虽然技术栈有点年头,但架构设计现在看依然有参考价值。随手打开尘封的V…...

银行凌晨3点不该再有人:智能化运维,才是金融系统的“止痛药”
银行凌晨3点不该再有人:智能化运维,才是金融系统的“止痛药” 说个很真实的画面,你大概率见过: 凌晨 2 点,交易系统报警了。 电话一个接一个: 运维被叫醒 开发被拉群 DBA 在查慢 SQL 领导在群里问:“影响多大?” 最后一查: 👉 某个接口延迟飙高,原因是流量突增 …...

CICIDS2017数据集下多算法对比:基于机器学习的异常入侵检测系统性能评估
1. CICIDS2017数据集与入侵检测系统入门指南 第一次接触网络安全的朋友可能会好奇:异常入侵检测系统到底是怎么工作的?简单来说,它就像网络世界的"智能监控摄像头",通过分析流量数据来识别黑客攻击。而CICIDS2017就是目…...
双界面法(Transient Dual Interface Method,TDIM)热阻公式详解
双界面法(Transient Dual Interface Method,TDIM)热阻公式详解 双界面法是JEDEC JESD51-14标准规定的标准方法,用于精确测量半导体器件(如功率MOSFET、IGBT、LED等)的结到壳热阻(( R_{\theta JC} ) 或 (\theta_{JC}),单位 K/W 或 ℃/W)。它比传统热电偶测壳温的方法(…...

建筑制图规范GB/T 50104-2010要求双尺寸标注?Revit这个功能自动帮你搞定
Revit双尺寸标注实战:GB/T 50104-2010规范落地指南 在建筑制图领域,轴网标注的规范性直接影响施工图的专业性与可读性。GB/T 50104-2010《建筑制图标准》明确要求采用"双尺寸标注"体系——既要体现局部轴线间距,又要标注整体外包尺…...

Qwen All-in-One场景应用:在边缘设备上部署全能AI助手
Qwen All-in-One场景应用:在边缘设备上部署全能AI助手 1. 引言:当AI助手遇上资源受限的边缘世界 想象一下,你正在开发一款智能家居中控设备,或者一个工业现场的巡检机器人。你希望它能理解用户的情绪,并给出贴心的回…...

GitHub中文化插件:打破语言障碍,让全球最大开发者社区说你的母语
GitHub中文化插件:打破语言障碍,让全球最大开发者社区说你的母语 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese …...

在服务器刻符咒:运维不敢碰的机柜——软件测试视角下的技术黑洞与破局之道
当玄学入侵测试生态在软件测试领域,环境完整性是保障覆盖率和缺陷检测的基石。然而,现实中存在一种隐形威胁:运维人员在故障频发的服务器机柜刻下符咒,将其列为“禁区”,导致测试团队被迫绕行。这种现象不仅源于人类心…...