MongoDB中的嵌套List操作
前言
MongoDB区别Mysql的地方,就是MongoDB支持文档嵌套,比如最近业务中就有一个在音频转写结果中进行对话场景,一个音频中对应多轮对话,这些音频数据和对话信息就存储在MongoDB中文档中。集合结构大致如下
{"_id":23424234234324234,"audioId": 2689944,"contextId": "cht000d24ab@dx187d1168a449a4b540","dialogues": [{"ask": "今天是礼拜天?","answer": "是的","createTime": 1697356990966}, {"ask": "你也要加油哈","answer": "奥利给!","createTime": 1697378011483}, {"ask": "下周见","answer": "拜拜!","createTime": 1697378072063}]
}下面简单介绍几个业务中用到的简单操作。
查询嵌套List的长度大小
public Integer getDialoguesSize(Long audioId) {Integer datasSize = 0;List<Document> group = Arrays.asList(new Document("$match",new Document("audioId",new Document("$eq", audioId))), new Document("$match",new Document("dialogues",new Document("$exists", true))), new Document("$project",new Document("datasSize",new Document("$size", "$dialogues"))));AggregateIterable<Document> aggregate = generalCollection.aggregate(group);Document document = aggregate.first();if (document != null) {datasSize = (Integer) document.get("datasSize");}return datasSize;}根据嵌套List中属性查询
下面的代码主要查询指定audioId中的dialogues集合中小于createTime,并且根据limit分页查询,这里用到了MongoDB中的Aggregates和unwind来进行聚合查询,具体使用细节,可以参见MongoDB官方文档
public AIDialoguesResultDTO queryAiResult(Long audioId, Long createTime, Integer limit) {AIDialoguesResultDTO aiDialoguesResultDTO = new AIDialoguesResultDTO();List<Bson> pipeline = Arrays.asList(Aggregates.match(Filters.eq("audioId", audioId)),Aggregates.unwind("$dialogues"),Aggregates.match(Filters.lt("dialogues.createTime", createTime)),Aggregates.sort(Sorts.descending("dialogues.createTime")),Aggregates.limit(limit));AggregateIterable<Document> aggregate = generalCollection.aggregate(pipeline);List<AIDialoguesResult> aiDialoguesResultList = new ArrayList<>();String contextId = Constant.EMPTY_STR;for (Document document : aggregate) {AIDialoguesResult aiDialoguesResult = new AIDialoguesResult();List<String> key = Collections.singletonList("dialogues");aiDialoguesResult.setAnswer(document.getEmbedded(key, Document.class).getString("answer"));aiDialoguesResult.setAsk(document.getEmbedded(key, Document.class).getString("ask"));aiDialoguesResult.setCreateTime(document.getEmbedded(key, Document.class).getLong("createTime"));aiDialoguesResultList.add(aiDialoguesResult);contextId = document.getString("contextId");}if (!CollectionUtils.isEmpty(aiDialoguesResultList)) {aiDialoguesResultList = aiDialoguesResultList.stream().sorted(Comparator.comparingLong(AIDialoguesResult::getCreateTime)).collect(Collectors.toList());}aiDialoguesResultDTO.setCount(aiDialoguesResultList.size());aiDialoguesResultDTO.setContextId(contextId);aiDialoguesResultDTO.setResult(aiDialoguesResultList);return aiDialoguesResultDTO;}当然,我们还有一种比较简单的写法
public AIDialoguesResultDTO queryAiResultBackupVersion(Long audioId, Long createTime, Integer limit) {Bson query = and(eq("audioId", audioId));AITextResult aiTextResult = mongoDao.findSingle(query, AITextResult.class);AIDialoguesResultDTO aiDialoguesResultDTO = new AIDialoguesResultDTO();if (Objects.isNull(aiTextResult)) {aiDialoguesResultDTO.setResult(Collections.emptyList());aiDialoguesResultDTO.setCount(0);aiDialoguesResultDTO.setContextId("");}List<AIDialoguesResult> aiDialoguesResultList = aiTextResult.getDialogues();if (CollectionUtils.isEmpty(aiDialoguesResultList)) {return aiDialoguesResultDTO;}Long finalCreateTime = createTime;List<AIDialoguesResult> afterFilterAiDialoguesResultList =aiDialoguesResultList.stream().filter(t -> t.getCreateTime()< finalCreateTime).sorted(Comparator.comparingLong(AIDialoguesResult::getCreateTime).reversed()).limit(limit).collect(Collectors.toList());if (CollectionUtils.isEmpty(afterFilterAiDialoguesResultList)) {aiDialoguesResultDTO.setCount(0);} else {aiDialoguesResultDTO.setCount(afterFilterAiDialoguesResultList.size());}afterFilterAiDialoguesResultList = afterFilterAiDialoguesResultList.stream().sorted(Comparator.comparingLong(AIDialoguesResult::getCreateTime)).collect(Collectors.toList());aiDialoguesResultDTO.setResult(afterFilterAiDialoguesResultList);aiDialoguesResultDTO.setContextId(aiTextResult.getContextId());return aiDialoguesResultDTO;}上面这种写法比较直接,就是直接audioId进行匹配查询, 然后将当前文档中的dialogues全部加载到内存中,然后在内存中进行排序,分页返回,显然如果dialogues集合长度很大,对内存占用会比较高。
嵌套List的增量追加
对于dialogues数组,如果我们要向dialogues追加元素,我们可以把audioId对应的dialogues全部取出来,然后在List后面追加一个元素,大致代码如下
public void saveAiResult(SaveAIResultDTO saveAIResultDTO) {Long audioId = saveAIResultDTO.getAudioId();Bson filter = Filters.eq("audioId", audioId);AITextResult aiTextResult = mongoDao.findSingle(filter, AITextResult.class);if (Objects.isNull(aiTextResult)) {aiTextResult = AITextResult.buildAiTextResult(saveAIResultDTO);mongoDao.saveOrUpdate(aiTextResult);return;}List<AIDialoguesResult> aiDialoguesResults = aiTextResult.getDialogues();AIDialoguesResult aiDialoguesResult = new AIDialoguesResult();aiDialoguesResult.setCreateTime(new Date().getTime());aiDialoguesResult.setAsk(saveAIResultDTO.getAsk());aiDialoguesResult.setAnswer(saveAIResultDTO.getAnswer());aiDialoguesResults.add(aiDialoguesResult);aiTextResult.setDialogues(aiDialoguesResults);mongoDao.saveOrUpdate(aiTextResult);}上面这种写法本身没有什么问题,但是如果dialogues集合大小比较大,每次追加都将dialogues全部取出来进行追加操作,可能比较占用内存,我们可以利用MongoDB中的push操作,直接追加
public void saveAiResultIncremental(SaveAIResultDTO saveAIResultDTO) {Long audioId = saveAIResultDTO.getAudioId();Document query = new Document("audioId", audioId);Bson projection = Projections.fields(Projections.include("contextId"), Projections.excludeId());FindIterable<Document> result = generalCollection.find(query).projection(projection);AITextResult aiTextResult;if (!result.iterator().hasNext()) {aiTextResult = AITextResult.buildAiTextResult(saveAIResultDTO);mongoDao.saveOrUpdate(aiTextResult);return;}AIDialoguesResult aiDialoguesResult = new AIDialoguesResult();aiDialoguesResult.setCreateTime(new Date().getTime());aiDialoguesResult.setAsk(saveAIResultDTO.getAsk());aiDialoguesResult.setAnswer(saveAIResultDTO.getAnswer());Bson update = push("dialogues", aiDialoguesResult);Bson filter = Filters.eq("audioId", audioId);generalCollection.updateOne(filter, update);}总结
既然选择了MongoDB,就不能继续沿用Mysql的查询风格,要学会利用MongoDB的特性,否则往往达不到预期效果。
相关文章:

MongoDB中的嵌套List操作
前言 MongoDB区别Mysql的地方,就是MongoDB支持文档嵌套,比如最近业务中就有一个在音频转写结果中进行对话场景,一个音频中对应多轮对话,这些音频数据和对话信息就存储在MongoDB中文档中。集合结构大致如下 {"_id":234…...
【C#】什么是并发,C#常规解决高并发的基本方法
给自己一个目标,然后坚持一段时间,总会有收获和感悟! 在实际项目开发中,多少都会遇到高并发的情况,有可能是网络问题,连续点击鼠标无反应快速发起了N多次调用接口, 导致极短时间内重复调用了多次…...
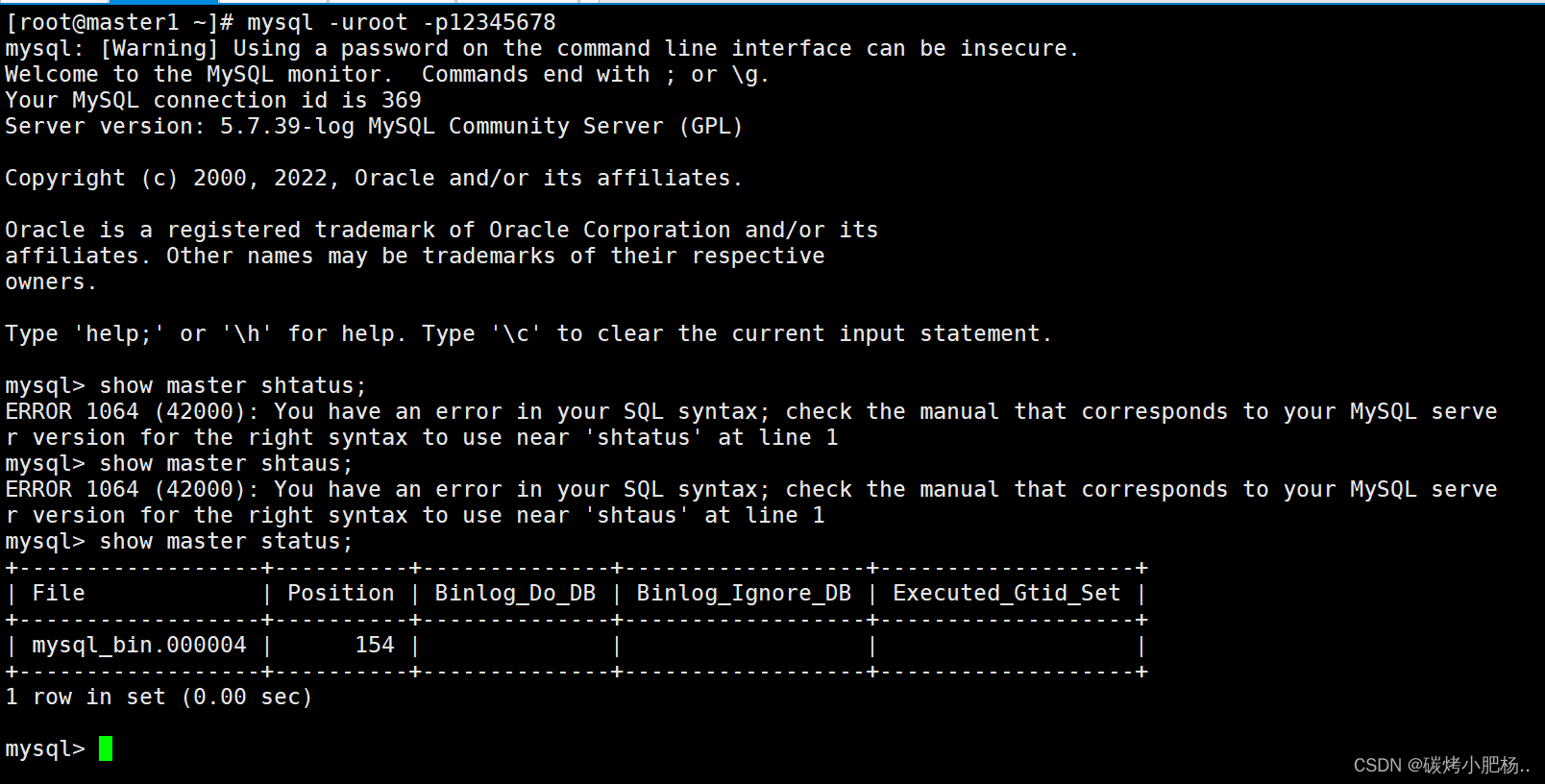
MySQL双主一从高可用
MySQL双主一从高可用 文章目录 MySQL双主一从高可用环境说明1.配置前的准备工作2.配置yum源 1.在部署NFS服务2.安装主数据库的数据库服务,并挂载nfs3.初始化数据库4.配置两台master主机数据库5.配置m1和m2成为主数据库6.安装、配置keepalived7.安装部署从数据库8.测…...

#力扣:2894. 分类求和并作差@FDDLC
2894. 分类求和并作差 - 力扣(LeetCode) 一、Java class Solution {public int differenceOfSums(int n, int m) {return (1n)*n/2-n/m*(mn/m*m)/2;} } 二、C class Solution { public:int differenceOfSums(int n, int m) {return (1n)*n/2-n/m*(mn…...
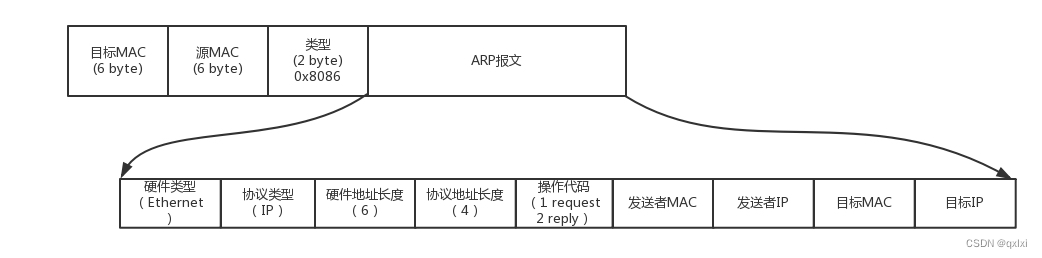
【网络协议】聊聊从物理层到MAC层 ARP 交换机
物理层 物理层其实就是电脑、交换器、路由器、光纤等。组成一个局域网的方式可以使用集线器。可以将多台电脑连接起来,然后进行将数据转发给别的端口。 数据链路层 Hub其实就是广播模式,如果A电脑发出一个包,B、C电脑也可以收到。那么数据…...
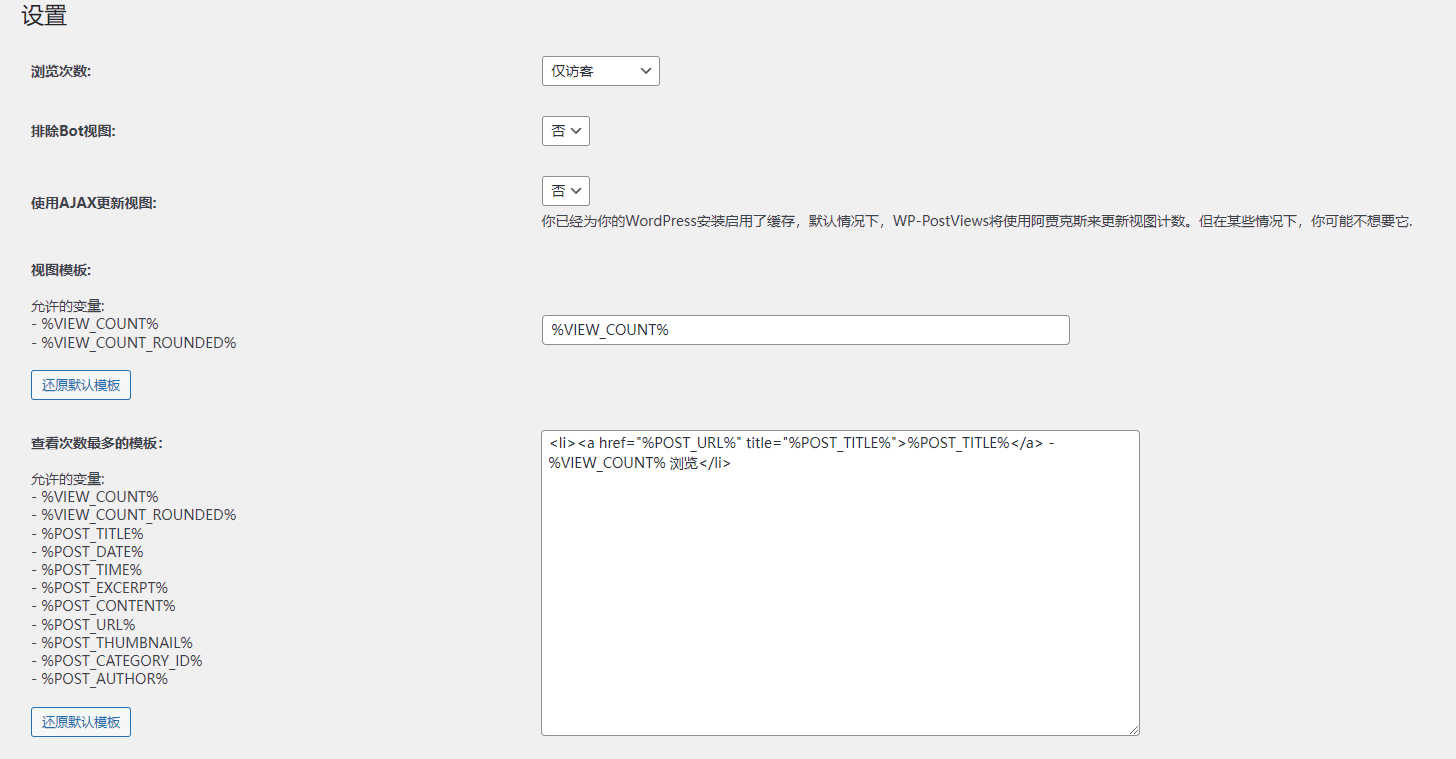
WordPress插件 WP-PostViews 汉化语言包
WP-PostViews汉化语言包 WP-PostViews是一款很受欢迎的文章浏览次数统计插件,记录每篇文章展示次数、根据展示次数显示历史最热或最衰的文章排行、展示范围可以是全部文章和页面,也可以是某些目录下的文章和页面。本文还介绍了一些隐藏的功能࿰…...
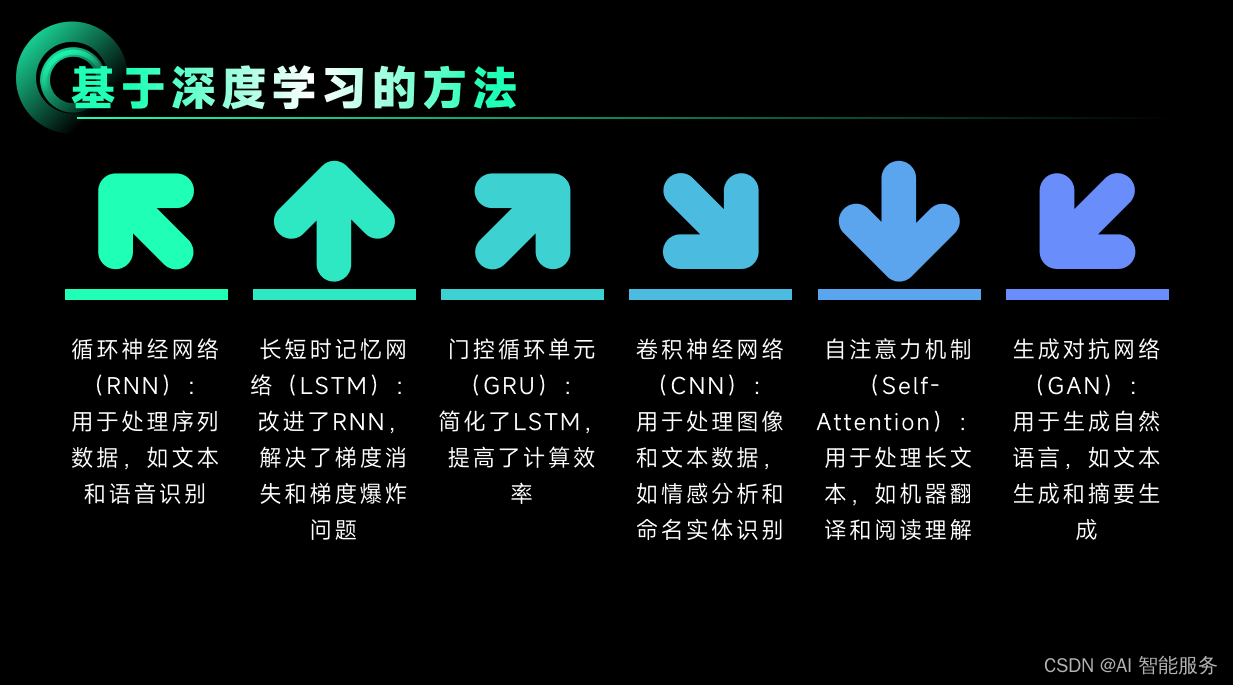
基础课2——自然语言处理
1.概念 自然语言处理(Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向,它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。 自然语言处理的主要研究方向包括: 语言学研究&…...

有趣的GPT指令
1 从现在开始,你的回答必须把所有字替换emoji,并保持原来的含义。你不能使用任何汉字或英文。如果有不适当的词语,将它们替换成对应的emoji。下面是一个例子: 原文:爷吐啦 翻译:👴ὃ…...

小样本学习--(1)概论
目录 一、概述 二、小样本学习的数据集 1、Omniglot 2、MiniimageNet 三、孪生网络 四、三元组损失函数 一、概述 小样本学习用于处理训练数据集中样本数量少的情况,一般来说,小样本学习流程是这样的,从一个多种类少量样本的巨大数据集…...
数据结构之手撕顺序表(讲解➕源代码)
0.引言 在本章之后,就要求大家对于指针、结构体、动态开辟等相关的知识要熟练的掌握,如果有小伙伴对上面相关的知识还不是很清晰,要先弄明白再过来接着学习哦! 那进入正题,在讲解顺序表之前,我们先来介绍…...

小微企业是怎样从客户管理系统中获益的?
大企业普遍拥有成熟的客户管理系统,而对小微企业而言,客户管理系统的重要性更为突出。这是因为小微企业管理相对薄弱,资源有限,人力资金需要更加精细化的管理。那么,小微企业如何从客户管理系统中获益? 一…...

mysql整库备份表结构和数据
命令 mysqldump -P 端口 -h 主机 -u 用户名 -p 数据库 > xxxxbak.sql 将导出数据库的表结构及数据(建表语句和insert语句) 举例 mysqldump -P 3306 -h 100.120.56.23 -u my_username-p sys > system-230510.sql...
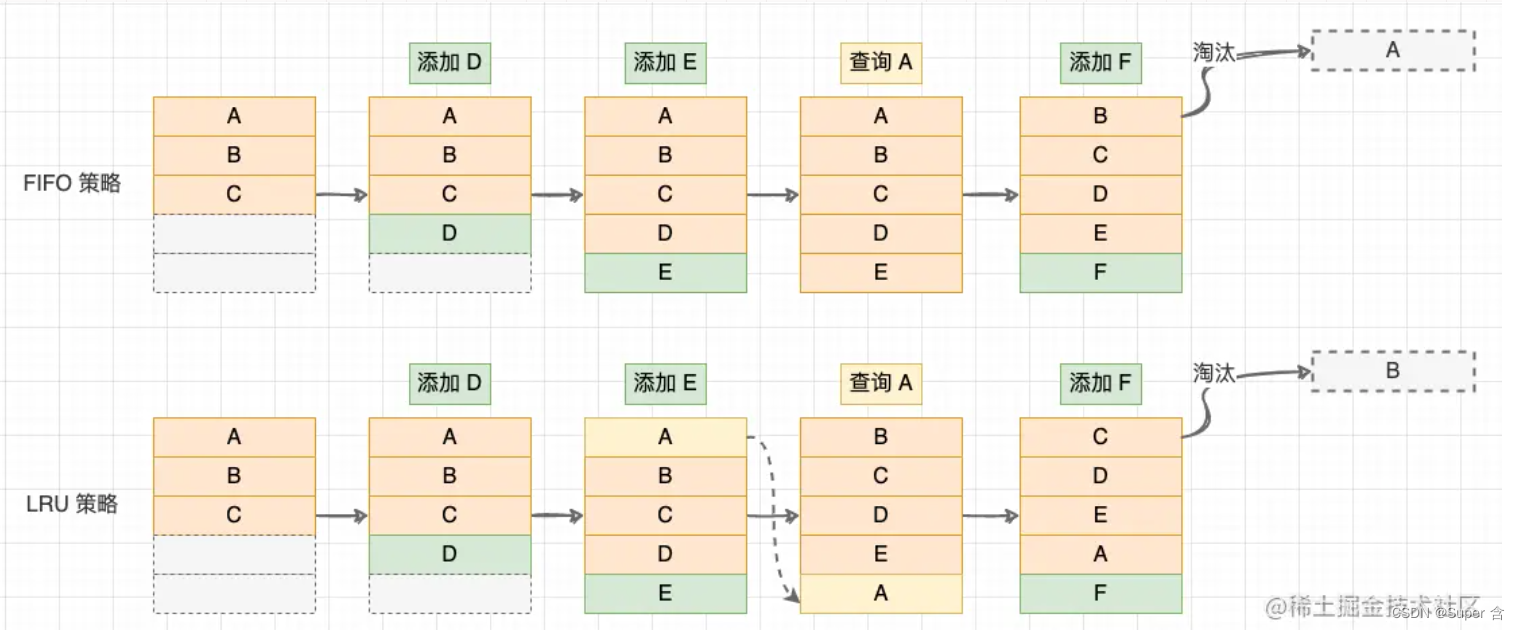
LinkedHashMap与LRU缓存
序、慢慢来才是最快的方法。 背景 LinkedHashMap 是继承于 HashMap 实现的哈希链表,它同时具备双向链表和散列表的特点。事实上,LinkedHashMap 继承了 HashMap 的主要功能,并通过 HashMap 预留的 Hook 点维护双向链表的逻辑。 1.缓存淘汰算法…...

2023大联盟6比赛总结
比赛链接 反思 A 为什么打表就我看不出规律!!! 定式思维太严重了T_T B 纯智障分块题,不知道为什么 B 100 B100 B100 比理论最优 B 300 B300 B300 更优(快了 3 倍),看来分块还是要学习一…...
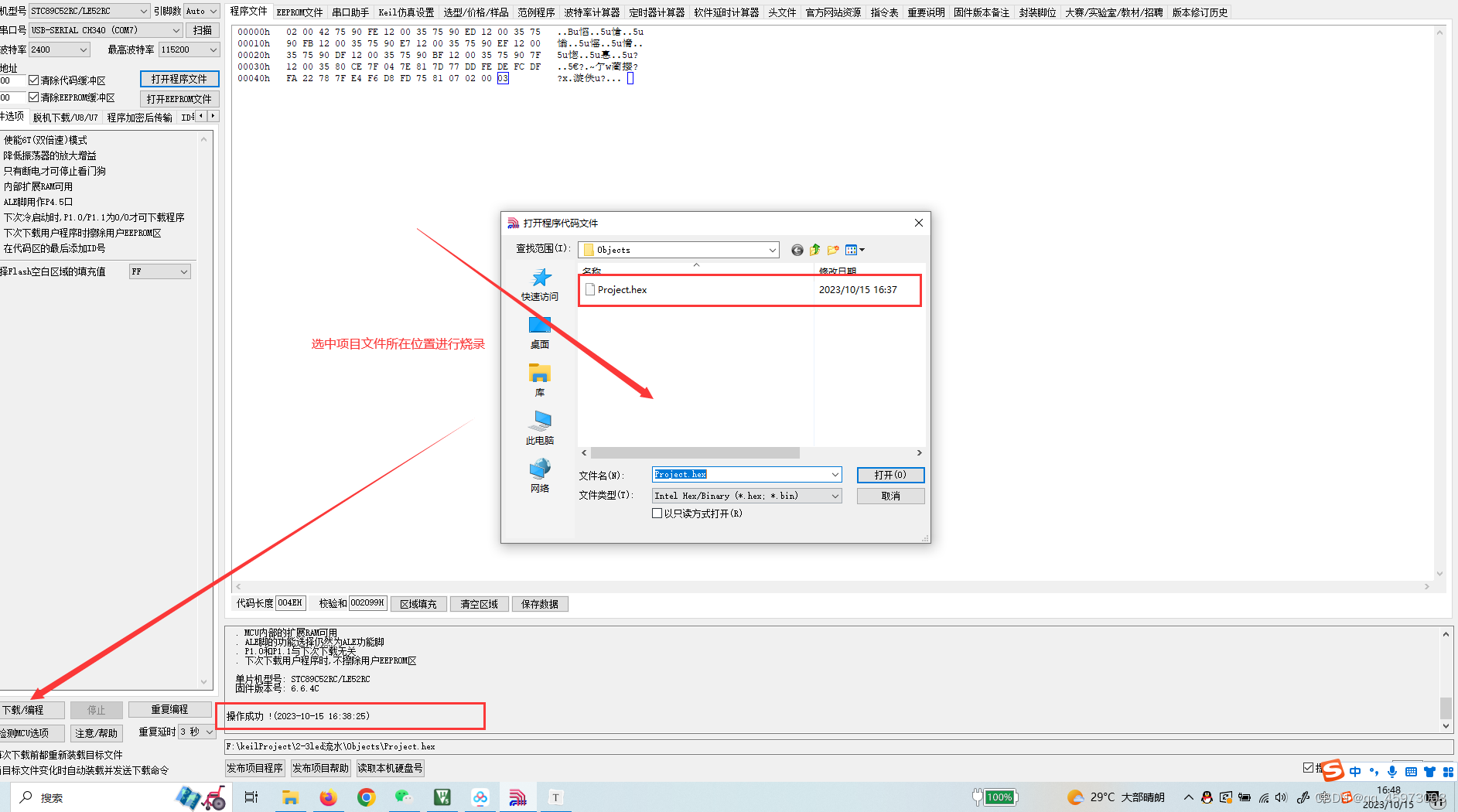
05_51单片机led流水线的实现
1:step创建一个新的项目并将程序烧录进入51单片机 以下是51单片机流水线代码的具体实现 #include <REGX52.H>void Delay500ms() //11.0592MHz {unsigned char i, j, k;i 4;j 129;k 119;do{do{while (--k);} while (--j);} while (--i); }void main(){while(1){P1 0…...
Java系列 | 如何讲自己的JAR包上传至阿里云maven私有仓库【云效制品仓库】
什么是云效 云效是云原生时代一站式 BizDevOps 平台,产研数字化同行者,支持公共云、专有云和混合云多种部署形态,通过云原生新技术和研发新模式,助力创新创业和数字化转型企业快速实现产研数字化,打造“双敏”组织&…...

小程序技术加速信创操作系统国产化替换
随着信息技术的不断发展,信息技术应用创新(简称“信创”)已经成为了当今企业数字化转型的重要趋势之一。信创是指在信息技术领域,以自主可控的国产软硬件产品和服务为核心,构建起一套完整的信息技术生态体系࿰…...
免费:实时 AI 编程助手 Amazon CodeWhisperer
点 ,一起程序员弯道超车之路 现已正式推出实时 AI 编程助手 Amazon CodeWhisperer,包括 CodeWhisperer 个人套餐,所有开发人员均可免费使用。最初于去年推出的预览版 CodeWhisperer 让开发人员能够保持专注、高效,帮助他们快速、安…...

面试准备-深入理解计算机系统-信息的表示与处理1
浮点运算是不可结合的(由于表示的精度有限)。比如(3.141e20)-1e20是0.0而3.14(1e20-1e20)是3.14。整数虽然只能编码一个较小的取值范围,但是是准确的;浮点数虽然能编码更大的范围,但是是近似的。 二进制转十六进制转换…...

搭建Atlas2.2.0 集成CDH6.3.2 生产环境+kerberos
首先确保环境的干净,如果之前有安装过清理掉相关残留 确保安装atlas的服务器有足够的内存(至少16G),有必要的hadoop角色 HDFS客户端 — 检索和更新Hadoop使用的用户组信息(UGI)中帐户成员资格的信息。对调…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...