NumPy基础及取值操作
目录
第1关:ndarray对象
相关知识
怎样安装NumPy
什么是ndarray对象
如何实例化ndarray对象
使用array函数实例化ndarray对象
使用zeros,ones,empty函数实例化ndarray对象
代码文件
第2关:形状操作
相关知识
怎样改变ndarray对象的形状
代码文件
第3关:基础操作
相关知识
算术运算
矩阵运算
简单统计
代码文件
第4关:随机数生成
相关知识
简单随机数生成
random_sample
choice
randint
概率分布随机数生成
随机种子
代码文件
第5关:索引与切片
相关知识
索引
遍历
切片
代码文件
第1关:ndarray对象
相关知识
怎样安装NumPy
本地想要安装
NumPy其实非常简单,进入命令行,输入pip install numpy即可。
什么是ndarray对象
NumPy为什么能够受到各个数据科学从业人员的青睐与追捧,其实很大程度上是因为NumPy在向量计算方面做了很多优化,接口也非常友好(总之就是用起来很爽)。而这些其实都是在围绕着NumPy的一个 核心数据结构 ndarray 。
ndarray的全称是N-Dimension Arrary,字面意义上其实已经表明了一个ndarray对象就是一个N维数组。但要注意的是,ndarray是同质的。同质的意思就是说N维数组里的所有元素必须是属于同一种数据类型的 。 (PS:python中的list是异质的) 。
ndarray对象实例化好了之后,包含了一些基本的属性。比如shape,ndim,size,dtype。其中:
shape:ndarray对象的形状,由一个tuple表示;
ndim:ndarray对象的维度;
size:ndarray对象中元素的数量;
dtype:ndarray对象中元素的数据类型,例如int64,float32等。
来看个例子,假设现在有一个3行5列的矩阵(ndarray)如下:
array([[ 0, 1, 2, 3, 4],[ 5, 6, 7, 8, 9],[10, 11, 12, 13, 14]])
那么该ndarray有
shape是(3, 5)(代表3行5列);ndim是2(因为矩阵有行和列两个维度);size是15(因为矩阵总共有15个元素);dtype是int32(因为矩阵中元素都是整数,并且用32位整型足够表示矩阵中的元素)。
示例代码如下:
# 导入numpy并取别名为npimport numpy as np# 构造ndarraya = np.arange(15).reshape(3, 5)# 打印a的shape,ndim,size,dtypeprint(a.shape)print(a.ndim)print(a.size)print(a.dtype)
如何实例化ndarray对象
实例化
ndarray对象的函数有很多种,但最为常用的函数是array,zeros,ones以及empty。
使用array函数实例化ndarray对象
如果你手头上有一个python的list,想要将这个list转成ndarray,此时可以使用NumPy中的array函数将list中的值作为初始值,来实例化一个ndarray对象。代码如下:
import numpy as np# 使用列表作为初始值,实例化ndarray对象aa = np.array([2,3,4])# 打印ndarray对象aprint(a)
使用zeros,ones,empty函数实例化ndarray对象
通常在写代码的时候,数组中元素的值一般都喜欢先初始化成0,如果使用array的方式实例化ndarray对象的话,虽然能实现功能,但显得很麻烦( 首先要有一个全是0的list )。那有没有简单粗暴的方式呢,有!那就是zeros函数,你只需要把ndarray的shape作为参数传进去即可。代码如下:
import numpy as np# 实例化ndarray对象a,a是一个3行4列的矩阵,矩阵中元素全为0a = np.zeros((3, 4))# 打印ndarray对象aprint(a)
如果想把数组中的元素全部初始化成1,聪明的你应该能想到就是用ones函数,ones的用法与zeros一致。代码如下:
import numpy as np# 实例化ndarray对象a,a是一个3行4列的矩阵,矩阵中元素全为1a = np.ones((3, 4))# 打印ndarray对象aprint(a)
如果01大法满足不了你,想要用随机值作为初始值来实例化ndarray对象,empty函数能够满足你。empty的使用方式与zeros和ones如出一辙,代码如下:
import numpy as np# 实例化ndarray对象a,a是一个2行3列的矩阵,矩阵中元素全为随机值a = np.empty((2, 3))# 打印ndarray对象aprint(a)
代码文件
import numpy as npdef print_ndarray(input_data):'''实例化ndarray对象并打印:param input_data: 测试用例,类型为字典类型:return: None'''#********* Begin *********#a = np.array(input_data['data'])print(a)#********* End *********#第2关:形状操作
相关知识
怎样改变ndarray对象的形状
上一关介绍了怎样实例化ndarray对象,比如想实例化一个3行4列的二维数组,并且数组中的值全为0。就可能会写如下代码:
import numpy as npa = np.zeros((3, 4))
那如果想把a变成4行3列的二维数组,怎么办呢?比较聪明的同学可能会想到这样的代码:
import numpy as npa = np.zeros((3, 4))# 直接修改shape属性a.shape = [4, 3]
最后你会发现,这样的代码可以完成功能,但是这种直接改属性的方式太粗暴了,不符合良好的编程规范。更加优雅的解决方式是使用NumPy为我们提供了一个用来改变ndarray对象的shape的函数,叫 reshape 。
NumPy为了照顾偏向于面向对象或者这偏向于面向过程这两种不同风格的程序员,提供了2种调用reshape函数的方式(其实很多函数都提供了两种风格的接口)。
如果你更偏向于面向对象,那么你可以想象成ndarray对象中提供好了一个叫reshape成员函数。代码如下:
import numpy as npa = np.zeros((3, 4))# 调用a的成员函数reshape将3行4列改成4行3列a = a.reshape((4, 3))
如果你更偏向于面向过程,NumPy在它的作用域内实现了reshape函数。代码如下:
import numpy as npa = np.zeros((3, 4))# 调用reshape函数将a变形成4行3列a = np.reshape(a, (4, 3))
PS:不管是哪种方式的reshape,都不会改变原ndarray的形状,而是将源ndarray进行深拷贝并进行变形操作,最后再将变形后的数组返回出去。也就是说如果代码是np.reshape(a, (4, 3))那么a的形状不会被修改!
如果想优雅的直接改变源ndarray的形状,可以使用resize函数。代码如下:
import numpy as npa = np.zeros((3, 4))# 将a从3行4列的二维数组变成一个有12个元素的一维数组a.resize(12)
有的时候懒得去算每个维度上的长度是多少,比如现在有一个6行8列的ndarray,然后想把它变形成有2列的ndarray(行的数量我懒得去想),此时我们可以在行的维度上传个-1即可,代码如下:
import numpy as npa = np.zeros((6, 8))# 行的维度上填-1,会让numpy自己去推算出行的数量,很明显,行的数量应该是24a = a.reshape((-1, 2))
也在变形操作时,如果某个维度上的值为-1,那么该维度上的值会根据其他维度上的值自动推算。
PS:-1虽好,可不能贪杯!如果代码改成a = a.reshape((-1, -1)),NumPy会认为你是在刁难他,并向你抛出异常ValueError: can only specify one unknown dimension。
代码文件
import numpy as npdef reshape_ndarray(input_data):'''将ipnut_data转换成ndarray后将其变形成一位数组并打印:param input_data: 测试用例,类型为list:return: None'''#********* Begin *********#a = np.array(input_data)a = a.reshape(-1)print(a)#********* End *********#第3关:基础操作
相关知识
算术运算
如果想要对ndarray对象中的元素做elementwise(逐个元素地)的算术运算非常简单,加减乘除即可。代码如下:
import numpy as npa = np.array([0, 1, 2, 3])# a中的所有元素都加2,结果为[2, 3, 4, 5]b = a + 2# a中的所有元素都减2,结果为[-2, -1, 0, 1]c = a - 2# a中的所有元素都乘以2,结果为[0, 2, 4, 6]d = a * 2# a中的所有元素都平方,结果为[0, 1, 4, 9]e = a ** 2# a中的所有元素都除以2,结果为[0, 0.5, 1, 1.5]f = a / 2# a中的所有元素都与2比,结果为[True, True, False, False]g = a < 2
矩阵运算
相同shape的矩阵A与矩阵B之间想要做elementwise运算也很简单,加减乘除即可。代码如下:
import numpy as npa = np.array([[0, 1], [2, 3]])b = np.array([[1, 1], [3, 2]])# a与b逐个元素相加,结果为[[1, 2], [5, 5]]c = a + b# a与b逐个元素相减,结果为[[-1, 0], [-1, 1]]d = a - b# a与b逐个元素相乘,结果为[[0, 1], [6, 6]]e = a * b# a的逐个元素除以b的逐个元素,结果为[[0., 1.], [0.66666667, 1.5]]f = a / b# a与b逐个元素做幂运算,结果为[[0, 1], [8, 9]]g = a ** b# a与b逐个元素相比较,结果为[[True, False], [True, False]]h = a < b
细心的同学应该发现了,*只能做elementwise运算,如果想做真正的矩阵乘法运算显然不能用*。NumPy提供了@和dot函数来实现矩阵乘法。代码如下:
import numpy as npA = np.array([[1, 1], [0, 1]])B = np.array([[2, 0], [3, 4]])# @表示矩阵乘法,矩阵A乘以矩阵B,结果为[[5, 4], [3, 4]]print(A @ B)# 面向对象风格,矩阵A乘以矩阵B,结果为[[5, 4], [3, 4]]print(A.dot(B))# 面向过程风格,矩阵A乘以矩阵B,结果为[[5, 4], [3, 4]]print(np.dot(A, B))
简单统计
有的时候想要知道ndarray对象中元素的和是多少,最小值是多少,最小值在什么位置,最大值是多少,最大值在什么位置等信息。这个时候可能会想着写一个循环去遍历ndarray对象中的所有元素来进行统计。NumPy为了解放我们的双手,提供了sum,min,max,argmin,argmax等函数来实现简单的统计功能,代码如下:
import numpy as npa = np.array([[-1, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 13]])# 计算a中所有元素的和,结果为67print(a.sum())# 找出a中最大的元素,结果为13print(a.max())# 找出a中最小的元素,结果为-1print(a.min())# 找出a中最大元素在a中的位置,由于a中有12个元素,位置从0开始计,故结果为11print(a.argmax())# 找出a中最小元素在a中位置,结果为0print(a.argmin())
有的时候,我们在统计时需要根据轴来统计。举个例子,公司员工的基本工资,绩效工资,年终奖的信息如下:
| 工号 | 基本工资 | 绩效工资 | 年终奖 |
|---|---|---|---|
| 1 | 3000 | 4000 | 20000 |
| 2 | 2700 | 5500 | 25000 |
| 3 | 2800 | 3000 | 15000 |
这样一个表格很明显,可以用ndarray来存储。代码如下:
import numpy as npinfo = np.array([[3000, 4000, 20000], [2700, 5500, 25000], [2800, 3000, 15000]])
info实例化之后就有了维度和轴的概念,很明显info是个二维数组,所以它的维度是2 。维度为2换句话来说就是info有两个轴:0号轴与1号轴(轴的编号从0开始算)。轴所指的方向如图所示:

如果想要统计下这3位员工中基本工资、绩效工资与年终奖的最小值与最大值(也就是说分别统计出每一列中的最小与最大值)。我们可以沿着0号轴来统计。想要实现沿着哪个轴来统计,只需要修改axis即可,代码如下:
import numpy as npinfo = np.array([[3000, 4000, 20000], [2700, 5500, 25000], [2800, 3000, 15000]])# 沿着0号轴统计,结果为[2700, 3000, 15000]print(info.min(axis=0))# 沿着0号轴统计,结果为[3000, 5500, 25000]print(info.max(axis=0))
PS:当没有修改axis时,axis的值默认为None。意思是在统计时会把ndarray对象中所有的元素都考虑在内。
代码文件
import numpy as npdef get_answer(input_data):'''将input_data转换成ndarray后统计每一行中最大值的位置并打印:param input_data: 测试用例,类型为list:return: None'''#********* Begin *********#a = np.array(input_data)b = a.argmax(axis=1)print(b)#********* End *********#第4关:随机数生成
相关知识
简单随机数生成
NumPy的random模块下提供了许多生成随机数的函数,如果对于随机数的概率分布没有什么要求,则通常可以使用random_sample、choice、randint等函数来实现生成随机数的功能。
random_sample
random_sample用于生成区间为[0, 1]的随机数,需要填写的参数size表示生成的随机数的形状,比如size=[2, 3]那么则会生成一个2行3列的ndarray,并用随机值填充。示例代码如下:
import numpy as np'''结果可能为[[0.32343809, 0.38736262, 0.42413616][0.86190206, 0.27183736, 0.12824812]]'''print(np.random.random_sample(size=[2, 3]))
choice
如果想模拟像掷骰子、扔硬币等这种随机值是离散值,而且知道范围的可以使用choice实现。choice的主要参数是a、size和replace。
a是个一维数组,代表你想从a中随机挑选;size是随机数生成后的形状。假如模拟5次掷骰子,replace用来设置是否可以取相同元素,True表示可以取相同数字;False表示不可以取相同数字,默认是True。
代码如下:
import numpy as np'''掷骰子时可能出现的点数为1, 2, 3, 4, 5, 6,所以a=[1,2,3,4,5,6]模拟5此掷骰子所以size=5结果可能为 [1 4 2 3 6]'''print(np.random.choice(a=[1, 2, 3, 4, 5, 6], size=5,replace=False))
randint
randint的功能和choice差不多,只不过randint只能生成整数,而choice生成的数与a有关,如果a中有浮点数,那么choice会有概率挑选到浮点数。
randint的参数有3个,分别为low,high和size。其中:
low表示随机数生成时能够生成的最小值;high表示随机数生成时能够生成的最大值减1;- 也就是说
randint生成的随机数的区间为[low, high)。
假如模拟5次掷骰子,代码如下:
import numpy as np'''掷骰子时可能出现的点数为1, 2, 3, 4, 5, 6,所以low=1,high=7模拟5此掷骰子所以size=5结果可能为 [6, 4, 3, 1, 3]'''print(np.random.randint(low=1, high=7, size=5)
概率分布随机数生成
如果对于产生的随机数的概率分布有特别要求,NumPy同样提供了从指定的概率分布中采样得到的随机值的接口。在这里主要介绍高斯分布。
高斯分布又称为正态分布,其分布图形如下:

上图中横轴为随机变量的值(在这里可以看成是产生的随机值),纵轴表示随机变量对应的概率(在这里可以看成是随机值被挑选到的概率)。
其实在日常生活中有很多现象或多或少都符合高斯分布。比如某个地方的高考分数,一般来说高考分数非常低和高考分数非常高的学生都比较少,而分数中规中矩的学生比较多,如果所统计的数据足够大,那么高考分数的概率分布也会和上图一样,中间高,两边低。
想要实现根据高斯分布来产生随机值,可以使用normal函数。示例代码如下:
import numpy as np'''根据高斯分布生成5个随机数结果可能为:[1.2315868, 0.45479902, 0.24923969, 0.42976352, -0.68786445]从结果可以看出0.4左右得值出现的次数比较高,1和-0.7左右的值出现的次数比较低。'''print(np.random.normal(size=5)
其中normal函数除了size参数外,还有两个比较重要的参数就是loc和scale,它们分别代表高斯分布的均值和方差。loc影响的分布中概率最高的点的位置,假设loc=2,那么分布中概率最高的点的位置就是2。下图体现了loc对分布的影响,其中蓝色f分布的loc=0,红色分布的loc=5。

scale影响的是分布图形的胖瘦,scale越小,分布就越又高又瘦,scale越大,分布就越又矮又胖。下图体现了scale对分布的影响,其中蓝色分布的scale=0.5,红色分布的scale=1.0。

所以,想要根据均值为1,方差为10的高斯分布来生成5个随机值,代码如下:
import numpy as npprint(np.random.normal(loc=1, scale=10, size=5)
随机种子
前面说了这么多随机数生成的方法,那么随机数是怎样生成的呢?其实计算机产生的随机数是由随机种子根据一定的计算方法计算出来的数值。所以只要计算方法固定,随机种子固定,那么产生的随机数就不会变!
如果想要让每次生成的随机数不变,那么就需要设置随机种子(随机种子其实就是一个0到2^32−1的整数)。设置随机种子很长简单,调用seed函数并设置随机种子即可,代码如下:
import numpy as np# 设置随机种子为233np.random.seed(seed=233)data = [1, 2, 3, 4]# 随机从data中挑选数字,结果为4print(np.random.choice(data))# 随机从data中挑选数字,结果为4print(np.random.choice(data))
代码文件
import numpy as npdef shuffle(input_data):'''打乱input_data并返回打乱结果:param input_data: 测试用例输入,类型为list:return: result,类型为list'''# 保存打乱的结果result = []#********* Begin *********#data = input_dataa = np.random.choice(data,len(data),replace=False)for i in a:result.append(i) #向列表末尾添加元素#********* End *********#return result第5关:索引与切片
相关知识
索引
ndarray的索引其实和python的list的索引极为相似。元素的索引从0开始。代码如下:
import numpy as np# a中有4个元素,那么这些元素的索引分别为0,1,2,3a = np.array([2, 15, 3, 7])# 打印第2个元素# 索引1表示的是a中的第2个元素# 结果为15print(a[1])# b是个2行3列的二维数组b = np.array([[1, 2, 3], [4, 5, 6]])# 打印b中的第1行# 总共就2行,所以行的索引分别为0,1# 结果为[1, 2, 3]print(b[0])# 打印b中的第2行第2列的元素# 结果为5print(b[1][1])
遍历
ndarray的遍历方式与python的list的遍历方式也极为相似,示例代码如下:
import numpy as npa = np.array([2, 15, 3, 7])# 使用for循环将a中的元素取出来后打印for element in a:print(element)# 根据索引遍历a中的元素并打印for idx in range(len(a)):print(a[idx])# b是个2行3列的二维数组b = np.array([[1, 2, 3], [4, 5, 6]])# 将b展成一维数组后遍历并打印for element in b.flat:print(element)# 根据索引遍历b中的元素并打印for i in range(len(b)):for j in range(len(b[0])):print(b[i][j])
切片
ndarray的切片方式与python的list的遍历方式也极为相似,对切片不熟的同学也不用慌,套路很简单,就是用索引。
假设想要将下图中紫色部分切片出来,就需要确定行的范围和列的范围。由于紫色部分行的范围是0到2,所以切片时行的索引范围是0:3(索引范围是左闭右开);又由于紫色部分列的范围也是0到2,所以切片时列的索引范围也是0:3(索引范围是左闭右开)。最后把行和列的索引范围整合起来就是[0:3, 0:3](,左边是行的索引范围)。当然有时为了方便,0可以省略,也就是[:3, :3]。

切片示例代码如下:
import numpy as np# a中有4个元素,那么这些元素的索引分别为0,1,2,3a = np.array([2, 15, 3, 7])'''将索引从1开始到最后的所有元素切片出来并打印结果为[15 3 7]'''print(a[1:])'''将从倒数第2个开始到最后的所有元素切片出来并打印结果为[3 7]'''print(a[-2:])'''将所有元素倒序切片并打印结果为[ 7 3 15 2]'''print(a[::-1])# b是个2行3列的二维数组b = np.array([[1, 2, 3], [4, 5, 6]])'''将第2行的第2列到第3列的所有元素切片并打印结果为[[5 6]]'''print(b[1:, 1:3])'''将第2列到第3列的所有元素切片并打印结果为[[2 3][5 6]]'''print(b[:, 1:3])
代码文件
import numpy as npdef get_roi(data, x, y, w, h):'''提取data中左上角顶点坐标为(x, y)宽为w高为h的ROI:param data: 二维数组,类型为ndarray:param x: ROI左上角顶点的行索引,类型为int:param y: ROI左上角顶点的列索引,类型为int:param w: ROI的宽,类型为int:param h: ROI的高,类型为int:return: ROI,类型为ndarray'''#********* Begin *********#x1 = xy1 = yx2 = x+h+1y2 = y+w+1ROI = data[x1:x2,y1:y2]return ROI#********* End *********#相关文章:
NumPy基础及取值操作
目录 第1关:ndarray对象 相关知识 怎样安装NumPy 什么是ndarray对象 如何实例化ndarray对象 使用array函数实例化ndarray对象 使用zeros,ones,empty函数实例化ndarray对象 代码文件 第2关:形状操作 相关知识 怎样改变n…...

vue webpack/vite的区别
Vue.js 可以与不同的构建工具一起使用,其中两个主要的工具是 Webpack 和 Vite。以下是 Vue.js 与 Webpack 和 Vite 之间的一些主要区别: Vue.js 与 Webpack: 成熟度: Webpack 是一个成熟的构建工具,已经存在多年&…...
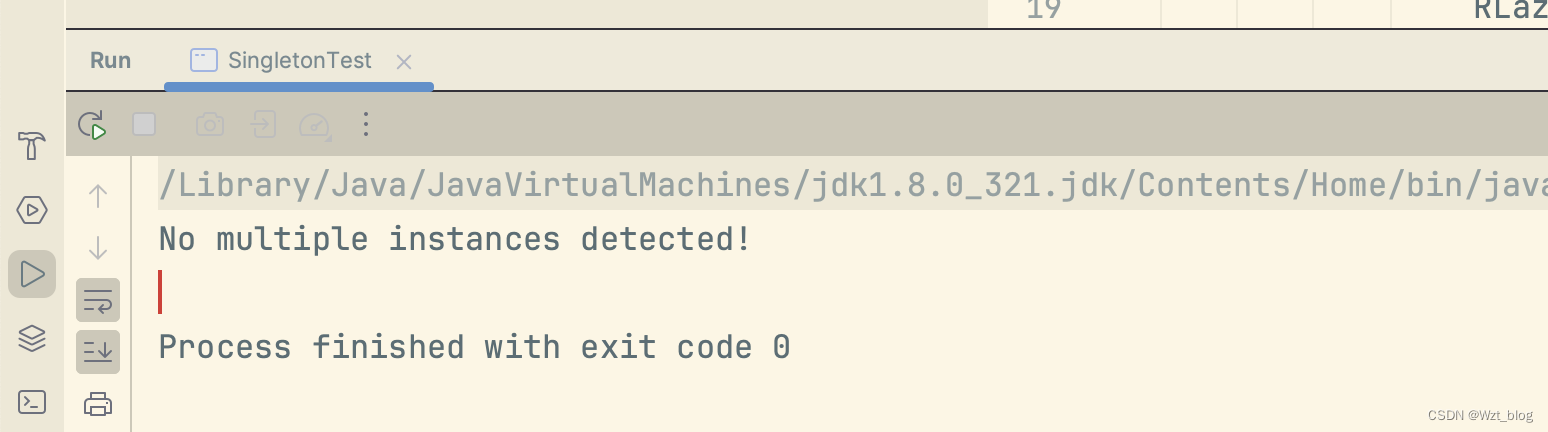
多线程下的单例设计模式(新手必看!!!)
在项目中为了避免创建大量的对象,频繁出现gc的问题,单例设计模式闪亮登场。 一、饿汉式 1.1饿汉式 顾名思义就是我们比较饿,每次想吃的时候,都提前为我们创建好。其实我记了好久也没分清楚饿汉式和懒汉式的区别。这里给出我的一…...

JDK 21的新特性总结和分析
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

【VR】【Unity】白马VR课堂系列-VR开发核心基础03-项目准备-VR项目设置
【内容】 详细说明 在设置Camera Rig前,我们需要针对VR游戏做一些特别的Project设置。 点击Edit菜单,Project Settings,选中最下方的XR Plugin Management,在右边面板点击Install。 安装完成后,我们需要选中相应安卓平台下的Pico VR套件,关于怎么安装PICO VR插件,请参…...
Windows服务器安装php+mysql环境的经验分享
php mysql环境 下载IIS Php Mysql环境集成包,集成包下载地址: 1、Windows Server 2008 一键安装Web环境包 x64 适用64位操作系统服务器:下载地址:链接: https://pan.baidu.com/s/1MMOOLGll4D7Eb5tBrdTQZw 提取码: btnx 2、Windows Server 2008 一键安装Web环境包 32 适…...

【LeetCode热题100】--287.寻找重复数
287.寻找重复数 方法:使用快慢指针 使用环形链表II的方法解题(142.环形链表II),使用 142 题的思想来解决此题的关键是要理解如何将输入的数组看作为链表。 首先明确前提,整数的数组 nums 中的数字范围是 [1,n]。考虑一…...
)
JUC并发编程——Stream流式计算(基于狂神说的学习笔记)
Stream流式计算 什么是Stream流式计算 Stream流式计算是一种基于数据流的计算模式,它可以对数据进行实时处理和分析,而不需要将所有数据存储在内存中。 Stream流式计算是将数据源中的数据分割成多个小的数据块,然后对每个小的数据块进行并…...
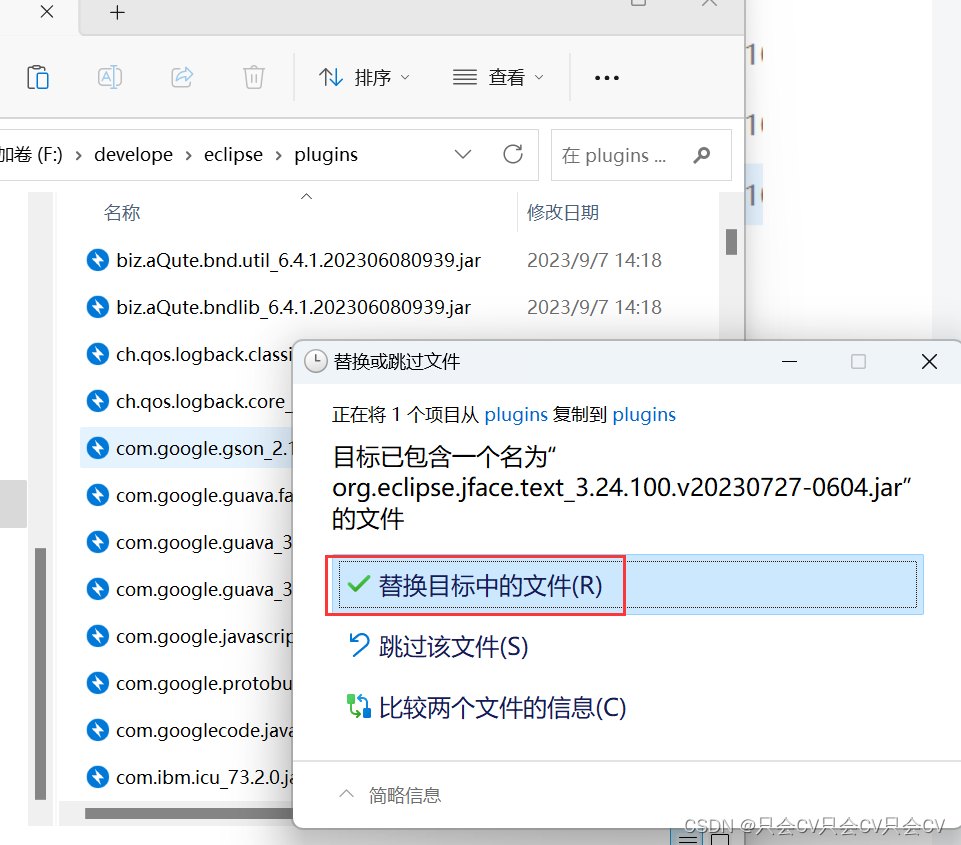
【Eclipse】取消按空格自动补全,以及出现没有src的解决办法
【Eclipse】设置自动提示 教程 根据上方链接,我们已经知道如何设置Eclipse的自动补全功能了,但是有时候敲变量名的时候按空格,本意是操作习惯,不需要自动补全,但是它却给我们自动补全了,这就造成了困扰&…...

ps制作透明公章 公章变透明 ps自动化批量抠图制作透明公章
ps制作透明公章 公章变透明 ps自动化批量抠图制作透明公章 1、抠图制作透明公章2、ps自动化批量抠图制作透明公章 1、抠图制作透明公章 抠图过程看视频 直接访问视频连接可以选高清画质 https://live.csdn.net/v/335752 ps抠图制作透明公章 2、ps自动化批量抠图制作透明公章 …...

Fetch与Axios数据请求
什么是Polyfill? Polyfill是一个js库,主要抚平不同浏览器之间对js实现的差异。比如,html5的storage(session,local), 不同浏览器,不同版本,有些支持,有些不支持。Polyfill(Polyfill有很多,在Gi…...
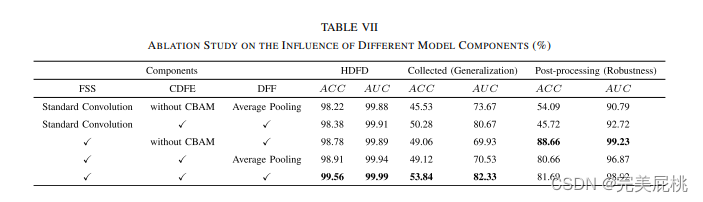
论文阅读-FCD-Net: 学习检测多类型同源深度伪造人脸图像
一、论文信息 论文题目:FCD-Net: Learning to Detect Multiple Types of Homologous Deepfake Face Images 作者团队:Ruidong Han , Xiaofeng Wang , Ningning Bai, Qin Wang, Zinian Liu, and Jianru Xue (西安理工大学,西安交…...
云服务器快速搭建网站
目录 安装Apache Docker 安装 Mysql 安装 Docker 依赖包 添加 Docker 官方仓库 安装 Docker 引擎 启动 Docker 服务并设置开机自启 验证 Docker 是否成功安装 拉取 MySQL 镜像 查看本地镜像 运行容器 停止和启动容器 列出正在运行的容器 安装PHP环境 搭建网站 安装…...

小程序首页搭建
小程序首页搭建 1. Flex布局是什么?2. 容器的属性2.1 flex-direction属性2.2 flex-wrap属性2.3 flex-flow属性2.4 justify-content属性2.5 align-items属性2.6 align-content属性 二.首页布局搭建二.1moke模拟数据实现轮播图4.信息搭建 Flex弹性布局 1. Flex布局是…...
5、使用 pgAdmin4 图形化创建和管理 PostgreSQL 数据库
通过上几篇文章我们讲解了如何安装 PostgreSQL 数据库软件和 pgAdmin4 图形化管理工具。 今天我们继续学习如何通过 pgAdmin4 管理工具图形化创建和管理 PostgreSQL 数据库。 一、PostgreSQL的基本工作方式 在学习如何使用PostgreSQL创建数据库之前,我们需要了解一…...

EtherCAT转Modbus-TCP协议网关与DCS连接的配置方法
远创智控YC-ECTM-TCP,自主研发的通讯网关,将为你解决以太网通讯难题。YC-ECTM-TCP是一款EtherCAT主站功能的通讯网关,能够将EtherCAT网络和Modbus-TCP网络连接起来。它可以作为EtherCAT网络中的主站使用,同时也可以作为Modbus-TCP…...

合伙企业的执行事务合伙人委派代表是什么样的存在
当合伙企业的执行事务合伙人为法人或非法人组织时,通常会委派自然人代表其执行合伙事务,特别是各类投资基金、信托、资产证券化等合伙企业类型的SPV中,由法人执行事务合伙人委派代表执行合伙企业事务比较常见,由此可能出现合伙企业…...
visual studio设置主题和背景颜色
visual studio2019默认的主题有4种,分别是浅白色、深黑色、蓝色、蓝(额外对比度),背景颜色默认是纯白色RGB(255,255,255)。字体纯白色看久了,眼睛会感到酸痛、疲劳,建议改成浅白RGB(250,250,250)、豆沙绿RGB(85,123,105)、透明蓝白…...

[JVM]问下,对象在堆上的内存分配是怎样的
Java 技术体系的自动内存管理,最根本的目标是自动化地解决两个问题:自动给对象分配内存以及自动回收分配给对象的内存 这里面最重要的就是,对象在堆上的内存分配 这篇文章来具体讲讲 堆整体上来说,主要分为 新生代 & 老年代 新生代又分为: Eden 区和 Survivor 区, Survivo…...
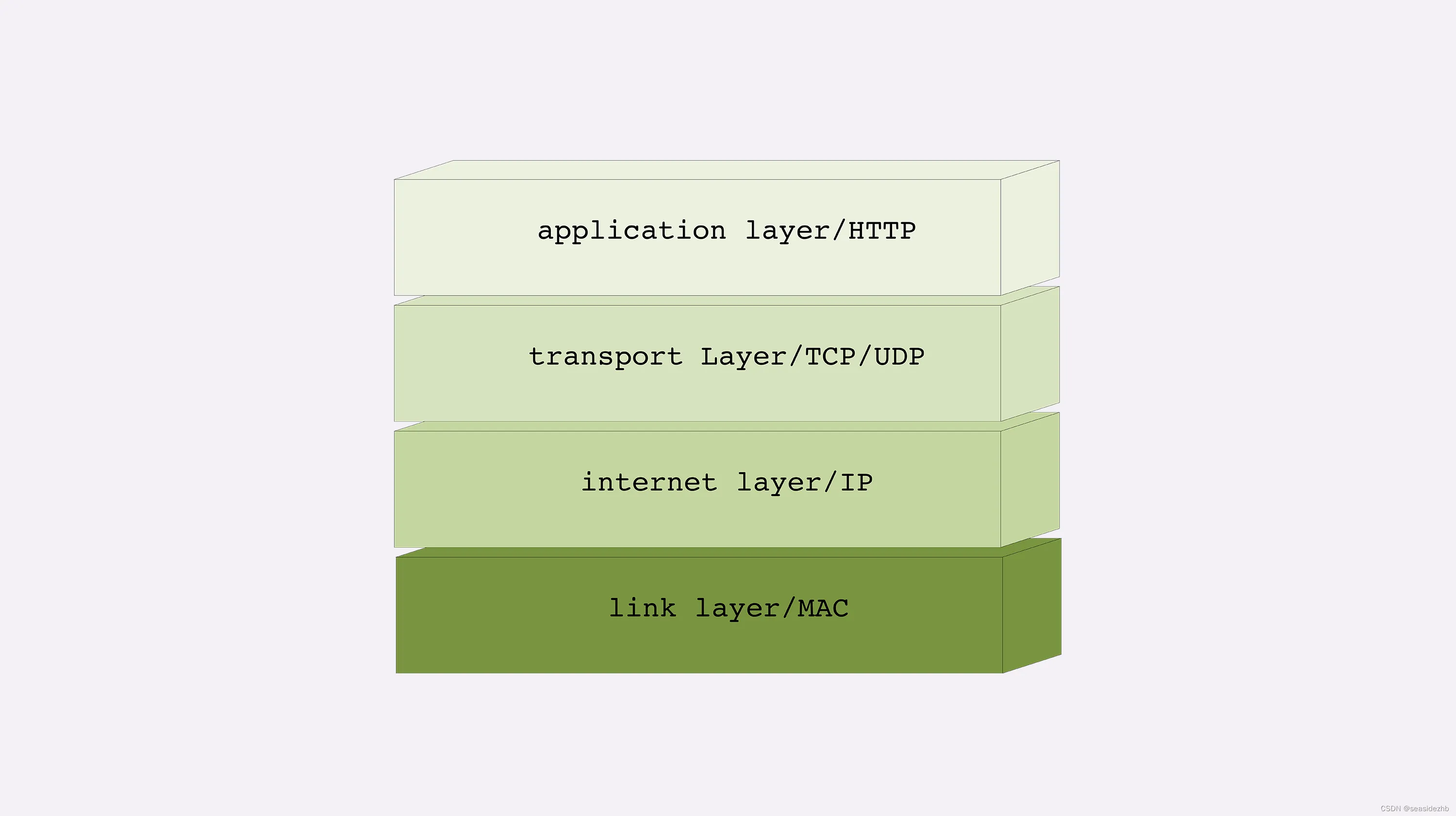
TCP/IP网络分层模型
TCP/IP当初的设计者真的是非常聪明,创造性地提出了“分层”的概念,把复杂的网络通信划分出多个层次,再给每一个层次分配不同的职责,层次内只专心做自己的事情就好,用“分而治之”的思想把一个“大麻烦”拆分成了数个“…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...

无人机侦测与反制技术的进展与应用
国家电网无人机侦测与反制技术的进展与应用 引言 随着无人机(无人驾驶飞行器,UAV)技术的快速发展,其在商业、娱乐和军事领域的广泛应用带来了新的安全挑战。特别是对于关键基础设施如电力系统,无人机的“黑飞”&…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...
在 Spring Boot 中使用 JSP
jsp? 好多年没用了。重新整一下 还费了点时间,记录一下。 项目结构: pom: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://ww…...