尚硅谷Flink(四)处理函数

目录
🦍处理函数
🐒基本处理函数
🐒按键分区处理函数(KeyedProcessFunction)
🐵定时器(Timer)和定时服务(TimerService)
// 1、事件时间的案例
// 2、处理时间的案例
// 3、获取 process的 当前watermark
🐒侧输出流
🦍状态管理
🐒什么是状态
🐒按键分区状态
🐵值状态(ValueState)
🐵列表状态(ListState)
🐵Map 状态(MapState)
🐵归约状态(ReducingState)
🐵聚合状态(AggregatingState)
🐵状态生存时间(TTL)
🐒*算子状态
🐒状态后端
🐵状态后端的分类(HashMapStateBackend/RocksDB)
🐵如何选择正确的状态后端
🐵状态后端的配置
🦍容错机制
🐒检查点(Checkpoint)
🐵检查点的保存
🐵恢复状态
🐵检查点算法
🐵配置
🐵保存点
🐒状态一致性
🐒端到端精确一次(End-To-End Exactly-Once)
🐵输入端保证
🐵输出端保证
🐵kafka
🦍处理函数
之前所介绍的流处理 API,无论是基本的转换、聚合,还是更为复杂的窗口操作,其实都是基于DataStream 进行转换的,所以可以统称为DataStream API。
在 Flink 更底层,我们可以不定义任何具体的算子(比如 map,filter,或者 window),而只是提炼出一个统一的“处理”(process)操作——它是所有转换算子的一个概括性的表达,可以自定义处理逻辑,所以这一层接口就被叫作“处理函数”(process function)。

🐒基本处理函数
我们之前学习的转换算子,一般只是针对某种具体操作来定义的,能够拿到的信息比较有限。如果我们想要访问事件的时间戳,或者当前的水位线信息,都是完全做不到的。跟时间相关的操,目前我们只会用窗口来处理。而在很多应用需求中,要求我们对时间有更精细的控制,需要能够获取水位线,甚至要“把控时间”、定义什么时候做什么事,这就不是基本的时间窗口能够实现的了。
处理函数的使用与基本的转换操作类似,只需要直接基于 DataStream 调用.process()方法就可以了。方法需要传入一个 ProcessFunction 作为参数,用来定义处理逻辑。
Flink 提供了8 个不同的ProcessFunction:
(1)ProcessFunction
最基本的处理函数,基于DataStream 直接调用.process()时作为参数传入。
- .processElement()
- 用于“处理元素”,定义了处理的核心逻辑。这个方法对于流中的每个元素都会调用一次,参数包括三个:输入数据值 value,上下文 ctx,以及“收集器”(Collector)out。方法没有返回值,处理之后的输出数据是通过收集器 out 来定义的。
- .onTimer()
- 这个方法只有在注册好的定时器触发的时候才会调用,而定时器是通过“定时服务”TimerService 来注册的。打个比方,注册定时器(timer)就是设了一个闹钟,到了设定时间就会响;而.onTimer()中定义的,就是闹钟响的时候要做的事。所以它本质上是一个基于时间的“回调”(callback)方法,通过时间的进展来触发;在事件时间语义下就是由水位线(watermark)来触发了。
- 注意:在 Flink 中,只有“按键分区流”KeyedStream 才支持设置定时器的操作。
(2)KeyedProcessFunction
对流按键分区后的处理函数,基于 KeyedStream 调用.process()时作为参数传入。要想使用定时器,比如基于 KeyedStream。
(3)ProcessWindowFunction
开窗之后的处理函数,也是全窗口函数的代表。基于WindowedStream 调用.process()时作为参数传入。
(4)ProcessAllWindowFunction
同样是开窗之后的处理函数,基于AllWindowedStream 调用.process()时作为参数传入。
(5)CoProcessFunction
合并(connect)两条流之后的处理函数,基于 ConnectedStreams 调用.process()时作为参数传入。关于流的连接合并操作,我们会在后续章节详细介绍。
(6)ProcessJoinFunction
间隔连接(interval join)两条流之后的处理函数,基于 IntervalJoined 调用.process()时作为参数传入。
(7)BroadcastProcessFunction
广播连接流处理函数,基于 BroadcastConnectedStream 调用.process()时作为参数传入。这里的“广播连接流”BroadcastConnectedStream,是一个未 keyBy 的普通 DataStream 与一个广播流(BroadcastStream)做连接(conncet)之后的产物。关于广播流的相关操作,我们会在后续章节详细介绍。
(8)KeyedBroadcastProcessFunction
按键分区的广播连接流处理函数,同样是基于 BroadcastConnectedStream 调用.process()时作为参数传入。与 BroadcastProcessFunction 不同的是,这时的广播连接流,是一个KeyedStream 与广播流(BroadcastStream)做连接之后的产物。

🐒按键分区处理函数(KeyedProcessFunction)
在上节中提到,只有在KeyedStream 中才支持使用TimerService 设置定时器的操作。所以一般情况下,我们都是先做了 keyBy 分区之后,再去定义处理操作;代码中更加常见的处理函数是KeyedProcessFunction。
🐵定时器(Timer)和定时服务(TimerService)
// 1、事件时间的案例
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> sensorDS = env.socketTextStream("localhost", 7777).map(new MapFunction<String, WaterSensor>() {@Overridepublic WaterSensor map(String value) throws Exception {String[] split = value.split(",");return new WaterSensor(split[0], Long.valueOf(split[1]), Integer.valueOf(split[2]));}}).assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner((element, ts) -> element.getTs() * 1000L));KeyedStream<WaterSensor, String> sensorKS = sensorDS.keyBy(sensor -> sensor.getId());// TODO Process:keyedSingleOutputStreamOperator<String> process = sensorKS.process(// key 输入类型 输出类型new KeyedProcessFunction<String, WaterSensor, String>() {/*** 来一条数据调用一次* @param value* @param ctx* @param out* @throws Exception*/@Overridepublic void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception {//获取当前数据的keyString currentKey = ctx.getCurrentKey();// TODO 1.定时器注册TimerService timerService = ctx.timerService();// 1、事件时间的案例Long currentEventTime = ctx.timestamp(); // 数据中提取出来的事件时间timerService.registerEventTimeTimer(5000L);System.out.println("当前key=" + currentKey + ",当前时间=" + currentEventTime + ",注册了一个5s的定时器");}/*** TODO 2.时间进展到定时器注册的时间,调用该方法* @param timestamp 当前时间进展,就是定时器被触发时的时间* @param ctx 上下文* @param out 采集器* @throws Exception*/@Overridepublic void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {super.onTimer(timestamp, ctx, out);String currentKey = ctx.getCurrentKey();System.out.println("key=" + currentKey + "现在时间是" + timestamp + "定时器触发");}});process.print();env.execute();}☢在以上代码的输出中,我定义的定时器是5s,为什么时间戳到了9秒才开始触发定时器
在 Flink 中,定时器的触发是基于水印(Watermark)和事件时间的进展的。在你的代码中,你设置了一个事件时间的定时器,其触发时间是5秒。但触发时间是相对于事件时间的进展而言的,而不是绝对的时间点。
定时器的触发受到水印的影响。水印用于表示事件时间的进展,以告知 Flink 什么时候认为事件已经到达了一定的事件时间。水印通常由数据源或处理算子生成,用于控制事件时间进展,以便定时器能够在合适的时间触发。
在你的代码中,你使用了以下的水印策略:
WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner((element, ts) -> element.getTs() * 1000L)
// 2、处理时间的案例
long currentTs = timerService.currentProcessingTime();
timerService.registerProcessingTimeTimer(currentTs + 5000L);
System.out.println("当前key=" + currentKey + ",当前时间=" + currentTs + ",注册了一个5s后后后后的定时器");
// 3、获取 process的 当前watermark
long currentWatermark = timerService.currentWatermark();
System.out.println("当前数据=" + value + ",当前watermark=" + currentWatermark);
🐒侧输出流
处理函数还有另外一个特有功能,就是将自定义的数据放入“侧输出流”(side output)输出。
我们之前讲到的绝大多数转换算子,输出的都是单一流,流里的数据类型只能有一种。而侧输出流可以认为是“主流”上分叉出的“支流”,所以可以由一条流产生出多条流,而且这些流中的数据类型还可以不一样。利用这个功能可以很容易地实现“分流”操作。
具体应用时,只要在处理函数的.processElement()或者.onTimer()方法中,调用上下文的.output()方法就可以了。
OutputTag<String> outputTag = new OutputTag<String>("side-output"){}; SingleOutputStreamOperator<Long> longStream = stream.process(new ProcessFunction<Integer, Long>() { @Override public void processElement( Integer value, Context ctx, Collector<Integer> out) throws Exception { // 转换成 Long,输出到主流中 out.collect(Long.valueOf(value)); // 转换成 String,输出到侧输出流中 ctx.output(outputTag, "side-output: " + String.valueOf(value)); }
}); 🦍状态管理
🐒什么是状态
在Flink中,算子任务可以分为无状态和有状态两种情况。
无状态的算子任务只需要观察每个独立事件,根据当前输入的数据直接转换输出结果。我们之前讲到的基本转换算子,如map、filter、flatMap,计算时不依赖其他数据,就都属于无状态的算子。

而有状态的算子任务,则除当前数据之外,还需要一些其他数据来得到计算结果。这里的“其他数据”,就是所谓的状态(state)。我们之前讲到的算子中,聚合算子、窗口算子都属于有状态的算子。

状态有两种:托管状态(Managed State)和原始状态(Raw State)。
通常我们采用 Flink 托管状态来实现需求。
- 托管状态就是由 Flink 统一管理的,状态的存储访问、故障恢复和重组等一系列问题都由 Flink 实现,我们只要调接口就可;
- 而原始状态则是自定义的,相当于就是开辟了一块内存,需要我们自己管理,实现状态的序列化和故障恢复。
又可以将托管状态分为两类:算子状态和按键分区状态。
算子状态作用范围限定为当前的算子任务实例,也就是只对当前并行子任务实例有效。这就意味着对于一个并行子任务,占据了一个“分区”,它所处理的所有数据都会访问到相同的状态,状态对于同一任务而言是共享的。
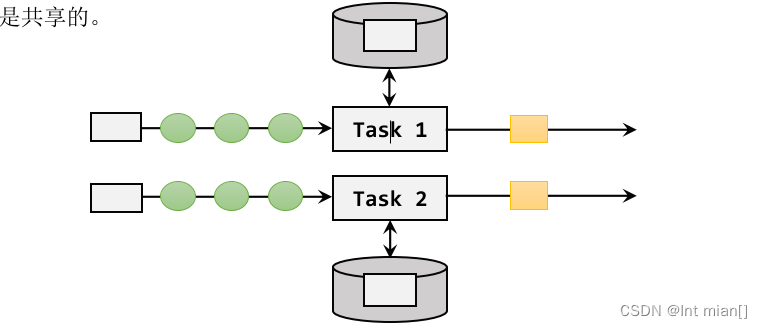
按键分区状态是根据输入流中定义的键(key )来维护和访问的,所以只能定义在按键分区流(KeyedStream)中,也就keyBy之后才可以使用。(每个并行度自己维护一个状态)

🐒按键分区状态
🐵值状态(ValueState)
顾名思义,状态中只保存一个“值”(value)。
在具体使用时,为了让运行时上下文清楚到底是哪个状态,我们还需要创建一个“状态描述器”(StateDescriptor)来提供状态的基本信息。例如源码中,ValueState 的状态描述器构造方法如下:
public ValueStateDescriptor(String name, Class<T> typeClass) {
super(name, typeClass, null);
}
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> sensorDS = env.socketTextStream("hadoop102", 7777).map(new WaterSensorMapFunction()).assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner((element, ts) -> element.getTs() * 1000L));sensorDS.keyBy(r -> r.getId()).process(new KeyedProcessFunction<String, WaterSensor, String>() {// TODO 1.定义状态ValueState<Integer> lastVcState;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);// TODO 2.在open 方法中,初始化状态// 状态描述器两个参数:第一个参数,起个名字,不重复;第二个参数,存储的类型lastVcState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("lastVcState", Types.INT));}@Overridepublic void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception {// lastVcState.value();// 取出 本组值状态 的数据
// lastVcState.update(); // 更新 本组值状态 的数据
// lastVcState.clear(); // 清除 本组值状态 的数据// 1. 取出上一条数据的水位值(Integer 默认值是null,判断)int lastVc = lastVcState.value() ==null ? 0 : lastVcState.value();// 2. 求差值的绝对值,判断是否超过 10Integer vc = value.getVc();if (Math.abs(vc - lastVc) > 10) {out.collect("传感器=" + value.getId() + "==>当前水位值=" + vc + ",与上一条水位值=" + lastVc + ",相差超过10!!!!");}// 3. 更新状态里的水位值lastVcState.update(vc);}}).print();env.execute();}🐵列表状态(ListState)
将需要保存的数据,以列表(List)的形式组织起来。在 ListState<T>接口中同样有一个类型参数T,表示列表中数据的类型。ListState 也提供了一系列的方法来操作状态,使用方式与一般的List 非常相似。
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> sensorDS = env.socketTextStream("hadoop102", 7777).map(new WaterSensorMapFunction()).assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner((element, ts) -> element.getTs() * 1000L));sensorDS.keyBy(r -> r.getId()).process(new KeyedProcessFunction<String, WaterSensor, String>() {ListState<Integer> vcListState;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);vcListState =getRuntimeContext().getListState(new ListStateDescriptor<Integer>("vcListState", Types.INT));}@Overridepublic void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception {// 1.来一条,存到list 状态里 vcListState.add(value.getVc());// 2.从list 状态拿出来(Iterable), 拷贝到一个List 中,排序, 只留 3 个最大的Iterable<Integer> vcListIt = vcListState.get();// 2.1 拷贝到List 中 List<Integer> vcList = new ArrayList<>();for (Integer vc : vcListIt) {vcList.add(vc);}// 2.2 对List 进行降序排序 vcList.sort((o1, o2) -> o2 - o1);// 2.3 只保留最大的 3 个(list 中的个数一定是连续变大,一超过 3 就立即清理即可)if (vcList.size() > 3) {// 将最后一个元素清除(第 4 个) vcList.remove(3);}out.collect("传感器id 为" + value.getId() + ",最大的3 个水位值=" + vcList.toString());// 3.更新list 状态 vcListState.update(vcList);// vcListState.get(); //取出 list 状态 本组的数据,是一个Iterable
// vcListState.add(); //向 list 状态 本组 添加一个元素
// vcListState.addAll(); //向 list 状态 本组 添加多个元素
// vcListState.update(); //更新 list 状态 本组数据(覆盖)
// vcListState.clear(); //清空List 状态 本组数据}}).print();env.execute();}🐵Map 状态(MapState)
package com.atguigu.state;import com.atguigu.bean.WaterSensor;
import com.atguigu.functions.WaterSensorMapFunction;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;/*** TODO 统计每种传感器每种水位值出现的次数** @author cjp* @version 1.0*/
public class KeyedMapStateDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> sensorDS = env.socketTextStream("hadoop102", 7777).map(new WaterSensorMapFunction()).assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner((element, ts) -> element.getTs() * 1000L));sensorDS.keyBy(r -> r.getId()).process(new KeyedProcessFunction<String, WaterSensor, String>() {MapState<Integer, Integer> vcCountMapState;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);vcCountMapState = getRuntimeContext().getMapState(new MapStateDescriptor<Integer, Integer>("vcCountMapState", Types.INT, Types.INT));}@Overridepublic void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception {// 1.判断是否存在vc对应的keyInteger vc = value.getVc();if (vcCountMapState.contains(vc)) {// 1.1 如果包含这个vc的key,直接对value+1Integer count = vcCountMapState.get(vc);vcCountMapState.put(vc, ++count);} else {// 1.2 如果不包含这个vc的key,初始化put进去vcCountMapState.put(vc, 1);}// 2.遍历Map状态,输出每个k-v的值StringBuilder outStr = new StringBuilder();outStr.append("======================================\n");outStr.append("传感器id为" + value.getId() + "\n");for (Map.Entry<Integer, Integer> vcCount : vcCountMapState.entries()) {outStr.append(vcCount.toString() + "\n");}outStr.append("======================================\n");out.collect(outStr.toString());// vcCountMapState.get(); // 对本组的Map状态,根据key,获取value
// vcCountMapState.contains(); // 对本组的Map状态,判断key是否存在
// vcCountMapState.put(, ); // 对本组的Map状态,添加一个 键值对
// vcCountMapState.putAll(); // 对本组的Map状态,添加多个 键值对
// vcCountMapState.entries(); // 对本组的Map状态,获取所有键值对
// vcCountMapState.keys(); // 对本组的Map状态,获取所有键
// vcCountMapState.values(); // 对本组的Map状态,获取所有值
// vcCountMapState.remove(); // 对本组的Map状态,根据指定key,移除键值对
// vcCountMapState.isEmpty(); // 对本组的Map状态,判断是否为空
// vcCountMapState.iterator(); // 对本组的Map状态,获取迭代器
// vcCountMapState.clear(); // 对本组的Map状态,清空}}).print();env.execute();}
}
🐵归约状态(ReducingState)
package com.atguigu.state;import com.atguigu.bean.WaterSensor;
import com.atguigu.functions.WaterSensorMapFunction;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReducingState;
import org.apache.flink.api.common.state.ReducingStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;import java.time.Duration;
import java.util.Map;/*** TODO 计算每种传感器的水位和** @author cjp* @version 1.0*/
public class KeyedReducingStateDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> sensorDS = env.socketTextStream("hadoop102", 7777).map(new WaterSensorMapFunction()).assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner((element, ts) -> element.getTs() * 1000L));sensorDS.keyBy(r -> r.getId()).process(new KeyedProcessFunction<String, WaterSensor, String>() {ReducingState<Integer> vcSumReducingState;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);vcSumReducingState = getRuntimeContext().getReducingState(new ReducingStateDescriptor<Integer>("vcSumReducingState",new ReduceFunction<Integer>() {@Overridepublic Integer reduce(Integer value1, Integer value2) throws Exception {return value1 + value2;}},Types.INT));}@Overridepublic void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception {// 来一条数据,添加到 reducing状态里vcSumReducingState.add(value.getVc());Integer vcSum = vcSumReducingState.get();out.collect("传感器id为" + value.getId() + ",水位值总和=" + vcSum);// vcSumReducingState.get(); // 对本组的Reducing状态,获取结果
// vcSumReducingState.add(); // 对本组的Reducing状态,添加数据
// vcSumReducingState.clear(); // 对本组的Reducing状态,清空数据}}).print();env.execute();}
}
🐵聚合状态(AggregatingState)
与归约状态非常类似,聚合状态也是一个值,用来保存添加进来的所有数据的聚合结果。与 ReducingState 不同的是,它的聚合逻辑是由在描述器中传入一个更加一般化的聚合函数(AggregateFunction)来定义的;这也就是之前我们讲过的 AggregateFunction,里面通过一个累加器(Accumulator)来表示状态,所以聚合的状态类型可以跟添加进来的数据类型完全不同,使用更加灵活。
package com.atguigu.state;import com.atguigu.bean.WaterSensor;
import com.atguigu.functions.WaterSensorMapFunction;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.state.AggregatingState;
import org.apache.flink.api.common.state.AggregatingStateDescriptor;
import org.apache.flink.api.common.state.ReducingState;
import org.apache.flink.api.common.state.ReducingStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;import java.time.Duration;/*** TODO 计算每种传感器的平均水位** @author cjp* @version 1.0*/
public class KeyedAggregatingStateDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> sensorDS = env.socketTextStream("hadoop102", 7777).map(new WaterSensorMapFunction()).assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner((element, ts) -> element.getTs() * 1000L));sensorDS.keyBy(r -> r.getId()).process(new KeyedProcessFunction<String, WaterSensor, String>() {AggregatingState<Integer, Double> vcAvgAggregatingState;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);vcAvgAggregatingState = getRuntimeContext().getAggregatingState(new AggregatingStateDescriptor<Integer, Tuple2<Integer, Integer>, Double>("vcAvgAggregatingState",new AggregateFunction<Integer, Tuple2<Integer, Integer>, Double>() {@Overridepublic Tuple2<Integer, Integer> createAccumulator() {return Tuple2.of(0, 0);}@Overridepublic Tuple2<Integer, Integer> add(Integer value, Tuple2<Integer, Integer> accumulator) {return Tuple2.of(accumulator.f0 + value, accumulator.f1 + 1);}@Overridepublic Double getResult(Tuple2<Integer, Integer> accumulator) {return accumulator.f0 * 1D / accumulator.f1;}@Overridepublic Tuple2<Integer, Integer> merge(Tuple2<Integer, Integer> a, Tuple2<Integer, Integer> b) {
// return Tuple2.of(a.f0 + b.f0, a.f1 + b.f1);return null;}},Types.TUPLE(Types.INT, Types.INT)));}@Overridepublic void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception {// 将 水位值 添加到 聚合状态中vcAvgAggregatingState.add(value.getVc());// 从 聚合状态中 获取结果Double vcAvg = vcAvgAggregatingState.get();out.collect("传感器id为" + value.getId() + ",平均水位值=" + vcAvg);// vcAvgAggregatingState.get(); // 对 本组的聚合状态 获取结果
// vcAvgAggregatingState.add(); // 对 本组的聚合状态 添加数据,会自动进行聚合
// vcAvgAggregatingState.clear(); // 对 本组的聚合状态 清空数据}}).print();env.execute();}
}
🐵状态生存时间(TTL)
在实际应用中,很多状态会随着时间的推移逐渐增长,如果不加以限制,最终就会导致存储空间的耗尽。一个优化的思路是直接在代码中调用.clear()方法去清除状态,但是有时候我们的逻辑要求不能直接清除。这时就需要配置一个状态的“生存时间”,当状态在内存中存在的时间超出这个值时,就将它清除。
状态的失效其实不需要立即删除,所以我们可以给状态附加一个属性,也就是状态的“失效时间”。状态创建的时候,设置 失效时间 = 当前时间 + TTL;之后如果有对状态的访和修改,我们可以再对失效时间进行更新;当设置的清除条件被触发时(比如,状态被访问的时候,或者每隔一段时间扫描一次失效状态),就可以判断状态是否失效、从而进行清除了。
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(10))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("my state",String.class);
stateDescriptor.enableTimeToLive(ttlConfig);⚫ .newBuilder()
状态TTL 配置的构造器方法,必须调用,返回一个Builder 之后再调用.build()方法就可以
得到 StateTtlConfig 了。方法需要传入一个 Time 作为参数,这就是设定的状态生存时间。
⚫ .setUpdateType()
设置更新类型。更新类型指定了什么时候更新状态失效时间,这里的 OnCreateAndWrite
表示只有创建状态和更改状态(写操作)时更新失效时间。另一种类型OnReadAndWrite则表示无论读写操作都会更新失效时间,也就是只要对状态进行了访问,就表明它是活跃的,从而延长生存时间。这个配置默认为OnCreateAndWrite。
⚫ .setStateVisibility()
设置状态的可见性。所谓的“状态可见性”,是指因为清除操作并不是实时的,所以当状态过期之后还有可能继续存在,这时如果对它进行访问,能否正常读取到就是一个问题了。这里设置的 NeverReturnExpired 是默认行为,表示从不返回过期值,也就是只要过期就认为它已经被清除了,应用不能继续读取;这在处理会话或者隐私数据时比较重要。对应的另一种配置是ReturnExpireDefNotCleanedUp,就是如果过期状态还存在,就返回它的值。
package com.atguigu.state;import com.atguigu.bean.WaterSensor;
import com.atguigu.functions.WaterSensorMapFunction;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;import java.time.Duration;/*** TODO** @author cjp* @version 1.0*/
public class StateTTLDemo {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);SingleOutputStreamOperator<WaterSensor> sensorDS = env.socketTextStream("hadoop102", 7777).map(new WaterSensorMapFunction()).assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner((element, ts) -> element.getTs() * 1000L));sensorDS.keyBy(r -> r.getId()).process(new KeyedProcessFunction<String, WaterSensor, String>() {ValueState<Integer> lastVcState;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);// TODO 1.创建 StateTtlConfigStateTtlConfig stateTtlConfig = StateTtlConfig.newBuilder(Time.seconds(5)) // 过期时间5s
// .setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) // 状态 创建和写入(更新) 更新 过期时间.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite) // 状态 读取、创建和写入(更新) 更新 过期时间.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) // 不返回过期的状态值.build();// TODO 2.状态描述器 启用 TTLValueStateDescriptor<Integer> stateDescriptor = new ValueStateDescriptor<>("lastVcState", Types.INT);stateDescriptor.enableTimeToLive(stateTtlConfig);this.lastVcState = getRuntimeContext().getState(stateDescriptor);}@Overridepublic void processElement(WaterSensor value, Context ctx, Collector<String> out) throws Exception {// 先获取状态值,打印 ==》 读取状态Integer lastVc = lastVcState.value();out.collect("key=" + value.getId() + ",状态值=" + lastVc);// 如果水位大于10,更新状态值 ===》 写入状态if (value.getVc() > 10) {lastVcState.update(value.getVc());}}}).print();env.execute();}
}
🐒*算子状态
算子状态(Operator State)就是一个算子并行实例上定义的状态,作用范围被限定为当前算子任务。算子状态跟数据的 key 无关,所以不同 key 的数据只要被分发到同一个并行子任务,就会访问到同一个Operator State。
当算子的并行度发生变化时,算子状态也支持在并行的算子任务实例之间做重组分配。根据状态的类型不同,重组分配的方案也会不同。
算 子状 态也 支持 不同的 结构 类型 ,主 要有三 种:ListState、UnionListState 和BroadcastState。
🐒状态后端
在Flink 中,状态的存储、访问以及维护,都是由一个可插拔的组件决定的,这个组件就叫作状态后端(state backend)。状态后端主要负责管理本地状态的存储方式和位置。
🐵状态后端的分类(HashMapStateBackend/RocksDB)
Flink 中提供了两类不同的状态后端,一种是“哈希表状态后端”(HashMapStateBackend),另一种是“内嵌 RocksDB 状态后端”(EmbeddedRocksDBStateBackend)。系统默认的状态后端是HashMapStateBackend。
(1)哈希表状态后端(HashMapStateBackend)
HashMapStateBackend是把状态存放在内存里。具体实现上,哈希表状态后端在内部会直接把状态当作对象(objects),保存在Taskmanager 的JVM 堆上。普通的状态,以及窗口中收集的数据和触发器,都会以键值对的形式存储起来,所以底层是一个哈希表(HashMap),这种状态后端也因此得名。2)内嵌RocksDB 状态后端(EmbeddedRocksDBStateBackend)
RocksDB 是一种内嵌的 key-value 存储介质,可以把数据持久化到本地硬盘。配置EmbeddedRocksDBStateBackend 后,会将处理中的数据全部放入 RocksDB 数据库中,RocksDB 默认存储在 TaskManager 的本地数据目录里。RocksDB 的状态数据被存储为序列化的字节数组,读写操作需要序列化/反序列化,因此状态的访问性能要差一些。另外,因为做了序列化,key 的比较也会按照字节进行,而不是直接调用.hashCode()和.equals()方法。
EmbeddedRocksDBStateBackend 始终执行的是异步快照,所以不会因为保存检查点而阻塞数据的处理;而且它还提供了增量式保存检查点的机制,这在很多情况下可以大大提升保存效率。
🐵如何选择正确的状态后端
HashMap 和RocksDB 两种状态后端最大的区别,就在于本地状态存放在哪里。
HashMapStateBackend是内存计算,读写速度非常快;但是,状态的大小会受到集群可用内存的限制,如果应用的状态随着时间不停地增长,就会耗尽内存资源。
而 RocksDB 是硬盘存储,所以可以根据可用的磁盘空间进行扩展,所以它非常适合于超级海量状态的存储。不过由于每个状态的读写都需要做序列化/反序列化,而且可能需要直接从磁盘读取数据,这就会导致性能的降低,平均读写性能要比 HashMapStateBackend 慢一个数量级。
🐵状态后端的配置
在不做配置的时候,应用程序使用的默认状态后端是由集群配置文件flink-conf.yaml中指定的,配置的键名称为 state.backend。这个默认配置对集群上运行的所有作业都有效,我们可以通过更改配置值来改变默认的状态后端。另外,我们还可以在代码中为当前作业单独配置状态后端,这个配置会覆盖掉集群配置文件的默认值。
(1)配置默认的状态后端
在 flink-conf.yaml 中,可以使用state.backend 来配置默认状态后端。
- 配置项的可能值为 hashmap,这样配置的就是 HashMapStateBackend;
- 如果配置项的值是rocksdb,这样配置的就是EmbeddedRocksDBStateBackend。
# 默认状态后端
state.backend: hashmap
# 存放检查点的文件路径
state.checkpoints.dir: hdfs://hadoop102:8020/flink/checkpoints
(2)为每个作业(Per-job/Application)单独配置状态后端
通过执行环境设置,HashMapStateBackend。
env.setStateBackend(new HashMapStateBackend());
env.setStateBackend(new EmbeddedRocksDBStateBackend());
需要注意,如果想在IDE 中使用EmbeddedRocksDBStateBackend,需要为Flink 项目添加
依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb</artifactId>
<version>${flink.version}</version>
</dependency>
🦍容错机制
在 Flink 中,有一套完整的容错机制来保证故障后的恢复,其中最重要的就是检查点。
🐒检查点(Checkpoint)
在流处理中,我们可以用存档读档的思路,就是将之前某个时间点所有的状态保存下来,这份“存档”就是所谓的“检查点”(checkpoint)。

所谓的“检查”,其实是针对故障恢复的结果而言的:故障恢复之后继续处理的结果,应该与发生故障前完全一致,我们需要“检查”结果的正确性。所以,有时又会把checkpoint叫做“一致性检查点
🐵检查点的保存
1)周期性的触发保存
“随时存档”确实恢复起来方便,可是需要我们不停地做存档操作。如果每处理一条数据就进行检查点的保存,当大量数据同时到来时,就会耗费很多资源来频繁做检查点,数据处理的速度就会受到影响。所以在Flink 中,检查点的保存是周期性触发的,间隔时间可以进行设置。
2)保存的时间点
我们应该在所有任务(算子)都恰好处理完一个相同的输入数据的时候,将它们的状态保存下来。
如果出现故障,我们恢复到之前保存的状态,故障时正在处理的所有数据都需要重新处理;我们只需要让源(source)任务向数据源重新提交偏移量、请求重放数据就可以了。当然这需要源任务可以把偏移量作为算子状态保存下来,而且外部数据源能够重置偏移量;kafka 就是满足这些要求的一个最好的例子。
3)保存的具体流程
检查点的保存,最关键的就是要等所有任务将“同一个数据”处理完毕。
🐵恢复状态
🐵检查点算法
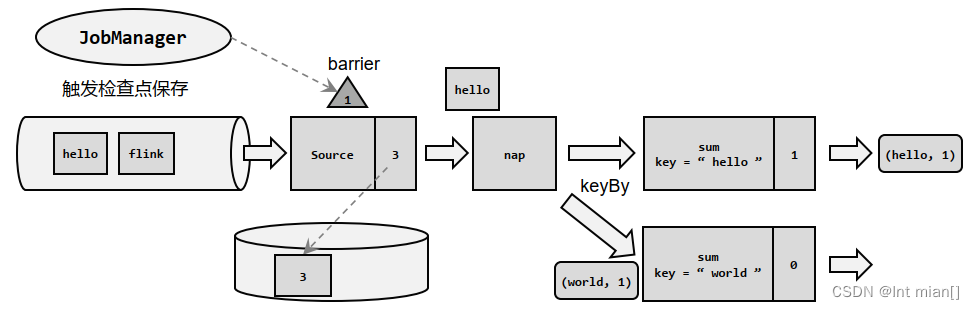
采用了基于 Chandy-Lamport 算法的分布式快照,可以在不暂停整体流处理的前提下,将状态备份保存到检查点
检查点分界线(Barrier)
借鉴水位线的设计,在数据流中插入一个特殊的数据结构,专门用来表示触发检查点保存的时间点。收到保存检查点的指令后,Source 任务可以在当前数据流中插入这个结构;之后的所有任务只要遇到它就开始对状态做持久化快照保存。由于数据流是保持顺序依次处理的,因此遇到这个标识就代表之前的数据都处理完了,可以保存一个检查点;而在它之后的数据,引起的状态改变就不会体现在这个检查点中,而需要保存到下一个检查点。 这种特殊的数据形式,把一条流上的数据按照不同的检查点分隔开,所以就叫做检查点的“分界线”(Checkpoint Barrier)。
在JobManager中有一个“检查点协调器”,专门用来协调处理检查点的相关工作。检查点协调器会定期向TaskManager发出指令,要求保存检查点(带着检查点ID);TaskManager会让所有的Source任务把自己的偏移量(算子状态)保存起来,并将带有检查点ID的分界线插入到当前的数据流中,然后像正常的数据一样像下游传递;之后Source任务就可以继续读入新的数据了。
分布式快照算法(Barrier 对齐的精准一次)
分布式快照算法(Barrier 对齐的至少一次)
分布式快照算法(非 Barrier 对齐的精准一次)
🐵配置
检查点的作用是为了故障恢复,我们不能因为保存检查点占据了大量时间、导致数据处理性能明显降低。为了兼顾容错性和处理性能,我们可以在代码中对检查点进行各种配置
默认情况下,Flink 程序是禁用检查点的。如果想要为 Flink 应用开启自动保存快照的功能,需要在代码中显式地调用执行环境的.enableCheckpointing()方法:
env.enableCheckpointing(1000); // 每隔1 秒启动一次检查点保存
默认情况下,检查点存储在JobManager 的堆内存中。而对于大状态的持久化保存,Flink 也提供了在其他存储位置进行保存的接口。
具体可以通过调用检查点配置的.setCheckpointStorage()来配置,需要传入一个CheckpointStorage 的实现类。Flink 主要提供了两种 CheckpointStorage:作业管理器的堆内存和文件系统。
// 配置存储检查点到 JobManager 堆内存
env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage());
// 配置存储检查点到文件系统
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("hdfs://namenode:40010/flink/checkpoint
s"));
不同于产生一个包含所有数据的全量备份,增量快照中只包含自上一次快照完成之后被修改的记录,因此可以显著减少快照完成的耗时。 (*目前标记为实验性功能)
EmbeddedRocksDBStateBackend backend = new EmbeddedRocksDBStateBackend(true);
如果数据源是有界的,就可能出现部分 Task 已经处理完所有数据,变成 finished 状态,不继续工作。从 Flink 1.14 开始,这些 finished 状态的Task,也可以继续执行检查点。自 1.15 起默认启用此功能,并且可以通过功能标志禁用它:
Configuration config = new Configuration();
config.set(ExecutionCheckpointingOptions.ENABLE_CHECKPOINTS_AFTER_TASKS_FINISH, false);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(config);
🐵保存点
除了检查点外,Flink 还提供了另一个非常独特的镜像保存功能——保存点(savepoint)。
从名称就可以看出,这也是一个存盘的备份,它的原理和算法与检查点完全相同,只是多了一些额外的元数据
而保存点不会自动创建,必须由用户明确地手动触发保存操作,所以就是“手动存盘”。
需要注意的是,保存点能够在程序更改的时候依然兼容,前提是状态的拓扑结构和数据类型不变。我们知道保存点中状态都是以算子 ID-状态名称这样的 key-value 组织起来的,算子 ID 可以在代码中直接调用 SingleOutputStreamOperator 的.uid()方法来进行指定:
DataStream<String> stream = env
.addSource(new StatefulSource()).uid("source-id")
.map(new StatefulMapper()).uid("mapper-id")
.print();对于没有设置 ID 的算子,Flink 默认会自动进行设置,所以在重新启动应用后可能会导致 ID 不同而无法兼容以前的状态。所以为了方便后续的维护,强烈建议在程序中为每一个算子手动指定ID。
要在命令行中为运行的作业创建一个保存点镜像,只需要执行:
bin/flink savepoint :jobId [:targetDirectory]
这里 jobId 需要填充要做镜像保存的作业 ID,目标路径 targetDirectory 可选,表示保存点存储的路径。
除了对运行的作业创建保存点,我们也可以在停掉一个作业时直接创建保存点:
bin/flink stop --savepointPath [:targetDirectory] :jobId
对于保存点的默认路径,可以通过配置文件 flink-conf.yaml 中的 state.savepoints.dir 项来设定:
state.savepoints.dir: hdfs:///flink/savepoints
现在要从保存点重启
bin/flink run -s :savepointPath [:runArgs]
🐒状态一致性
一致性其实就是结果的正确性,一般从数据丢失、数据重复来评估。
一般说来,状态一致性有三种级别:
⚫ 最多一次(At-Most-Once)
⚫ 至少一次(At-Least-Once)
⚫ 精确一次(Exactly-Once)
所以完整的流处理应用,应该包括了数据源、流处理器和外部存储系统三个部分。
这个完整应用的一致性,就叫做“端到端(end-to-end)的状态一致性”,它取决于三个组件中最弱的那一环。
🐒端到端精确一次(End-To-End Exactly-Once)
端到端一致性的关键点,就在于输入的数据源端和输出的外部存储端。
🐵输入端保证
输入端主要指的就是Flink 读取的外部数据源。对于一些数据源来说,并不提供数据的缓冲或是持久化保存,数据被消费之后就彻底不存在了,例如 socket 文本流。对于这样的数据源,故障后我们即使通过检查点恢复之前的状态,可保存检查点之后到发生故障期间的数据已不能重发了,这就会导致数据丢失。所以就只能保证at-most-once的一致性语义,相当于没有保证。
常见的做法就对数据进行持久化保存,并且可以重设数据的读取位置。一个最经典的应用就是 Kafka。
🐵输出端保证
有了 Flink 的检查点机制,以及可重放数据的外部数据源,我们已经能做到 at-least-once了。但是想要实现 exactly-once 却有更大的困难:数据有可能重复写入外部系统。
幂等(Idempotent)写入
所谓“幂等”操作,就是说一个操作可以重复执行很多次,但只导致一次结果更改。也就是说,后面再重复执行就不会对结果起作用了。
事务(Transactional)写入
如果说幂等写入对应用场景限制太多,那么事务写入可以说是更一般化的保证一致性的方式。
输出端最大的问题,就是写入到外部系统的数据难以撤回。而利用事务就可以实现对已写入数据的撤回。
(1)预写日志(write-ahead-log,WAL)
(2)两阶段提交(two-phase-commit,2PC)
🐵kafka
也就是说,我们写入 Kafka 的过程实际上是一个两段式的提交:处理完毕得到结果,写入 Kafka 时是基于事务的“预提交”;等到检查点保存完毕,才会提交事务进行“正式提交”。
相关文章:
尚硅谷Flink(四)处理函数
目录 🦍处理函数 🐒基本处理函数 🐒按键分区处理函数(KeyedProcessFunction) 🐵定时器(Timer)和定时服务(TimerService) // 1、事件时间的案例 // 2、处理…...
AXURE RP EXTENSION For Chrome 安装
在浏览器上输入地址:chrome://extensions/ 打开图片中这个选项,至此你就能通过index.html访问...
-3)
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...
【CNN-GRU预测】基于卷积神经网络-门控循环单元的单维时间序列预测研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
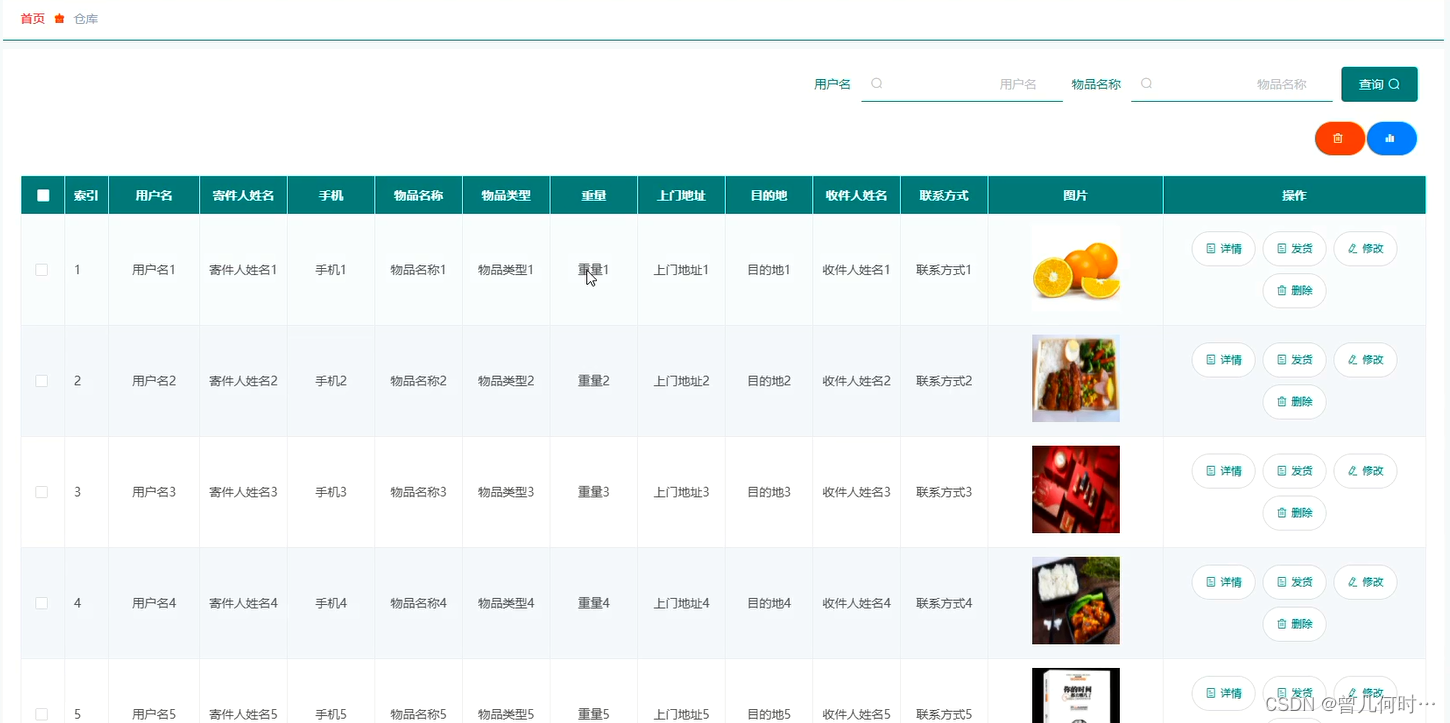
计算机毕业设计--基于SSM+Vue的物流管理系统的设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

GPT4 Plugins 插件 WebPilot 生成抖音文案
1. 生成抖音文案 1.1. 准备1篇优秀的抖音文案范例 1.2. Promept公式 你是一个有1000万粉丝的抖音主播, 请模仿下面的抖音脚本文案,重新改与一篇文章改写成2分钟的抖音视频脚本, 要求前一部分是十分有争议性的内容,并且能够引发…...
通过核密度分析工具建模,基于arcgis js api 4.27 加载gp服务
一、通过arcmap10.2建模,其中包含三个参数 注意input属性,选择数据类型为要素类: 二、建模之后,加载数据,执行模型,无错误的话,找到执行结果,进行发布gp服务 注意,发布g…...
【vue2高德地图api】02-npm引入插件,在页面中展示效果
系列文章目录 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、安装高德地图二、在main.js中配置需要配置2个key值以及1个密钥 三、在页面中使用3.1 新建路由3.2新建vue页面3.2-1 index.vue3.2…...

ai智能语音电销机器人怎么选?
智能语音电销机器人哪家好?如何选择一款智能语音电销机器人?这几年生活中人工智能的普及越来越广泛,就如智能语音机器人在生活当中的应用还是比较方便的,有许多行业都会选择这类的智能语音系统来把工作效率提高上去,随…...

NumPy基础及取值操作
目录 第1关:ndarray对象 相关知识 怎样安装NumPy 什么是ndarray对象 如何实例化ndarray对象 使用array函数实例化ndarray对象 使用zeros,ones,empty函数实例化ndarray对象 代码文件 第2关:形状操作 相关知识 怎样改变n…...

vue webpack/vite的区别
Vue.js 可以与不同的构建工具一起使用,其中两个主要的工具是 Webpack 和 Vite。以下是 Vue.js 与 Webpack 和 Vite 之间的一些主要区别: Vue.js 与 Webpack: 成熟度: Webpack 是一个成熟的构建工具,已经存在多年&…...
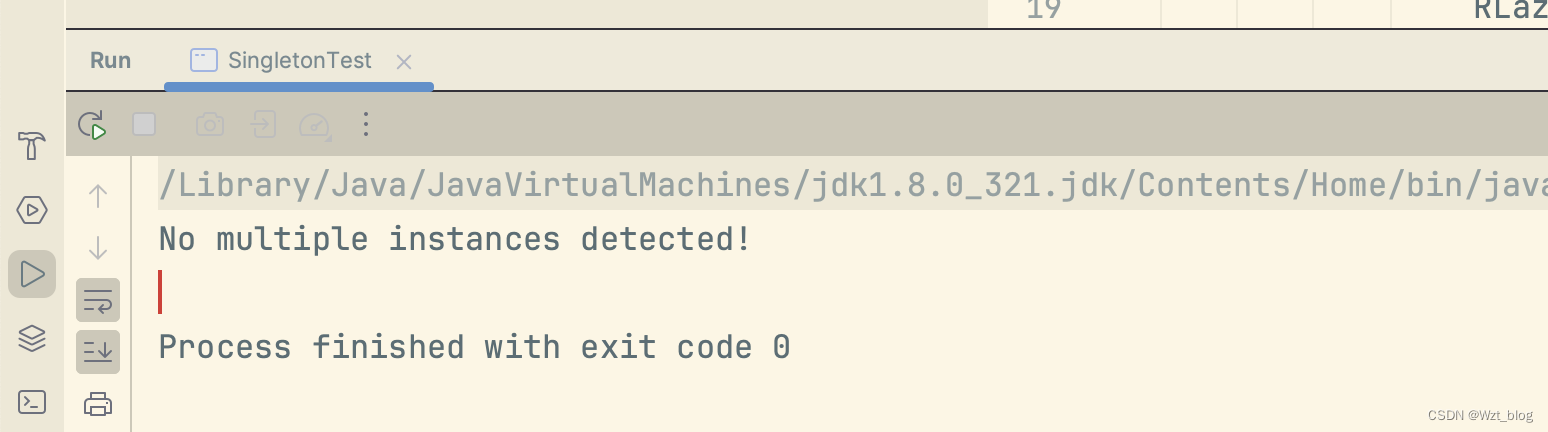
多线程下的单例设计模式(新手必看!!!)
在项目中为了避免创建大量的对象,频繁出现gc的问题,单例设计模式闪亮登场。 一、饿汉式 1.1饿汉式 顾名思义就是我们比较饿,每次想吃的时候,都提前为我们创建好。其实我记了好久也没分清楚饿汉式和懒汉式的区别。这里给出我的一…...

JDK 21的新特性总结和分析
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

【VR】【Unity】白马VR课堂系列-VR开发核心基础03-项目准备-VR项目设置
【内容】 详细说明 在设置Camera Rig前,我们需要针对VR游戏做一些特别的Project设置。 点击Edit菜单,Project Settings,选中最下方的XR Plugin Management,在右边面板点击Install。 安装完成后,我们需要选中相应安卓平台下的Pico VR套件,关于怎么安装PICO VR插件,请参…...
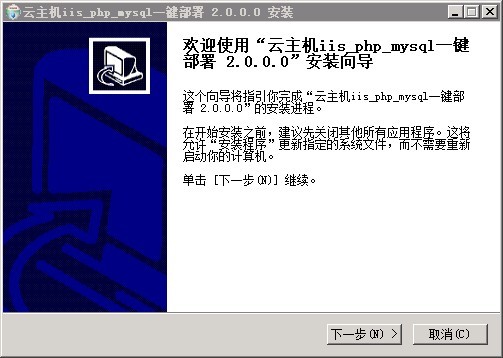
Windows服务器安装php+mysql环境的经验分享
php mysql环境 下载IIS Php Mysql环境集成包,集成包下载地址: 1、Windows Server 2008 一键安装Web环境包 x64 适用64位操作系统服务器:下载地址:链接: https://pan.baidu.com/s/1MMOOLGll4D7Eb5tBrdTQZw 提取码: btnx 2、Windows Server 2008 一键安装Web环境包 32 适…...

【LeetCode热题100】--287.寻找重复数
287.寻找重复数 方法:使用快慢指针 使用环形链表II的方法解题(142.环形链表II),使用 142 题的思想来解决此题的关键是要理解如何将输入的数组看作为链表。 首先明确前提,整数的数组 nums 中的数字范围是 [1,n]。考虑一…...
)
JUC并发编程——Stream流式计算(基于狂神说的学习笔记)
Stream流式计算 什么是Stream流式计算 Stream流式计算是一种基于数据流的计算模式,它可以对数据进行实时处理和分析,而不需要将所有数据存储在内存中。 Stream流式计算是将数据源中的数据分割成多个小的数据块,然后对每个小的数据块进行并…...
【Eclipse】取消按空格自动补全,以及出现没有src的解决办法
【Eclipse】设置自动提示 教程 根据上方链接,我们已经知道如何设置Eclipse的自动补全功能了,但是有时候敲变量名的时候按空格,本意是操作习惯,不需要自动补全,但是它却给我们自动补全了,这就造成了困扰&…...

ps制作透明公章 公章变透明 ps自动化批量抠图制作透明公章
ps制作透明公章 公章变透明 ps自动化批量抠图制作透明公章 1、抠图制作透明公章2、ps自动化批量抠图制作透明公章 1、抠图制作透明公章 抠图过程看视频 直接访问视频连接可以选高清画质 https://live.csdn.net/v/335752 ps抠图制作透明公章 2、ps自动化批量抠图制作透明公章 …...

Fetch与Axios数据请求
什么是Polyfill? Polyfill是一个js库,主要抚平不同浏览器之间对js实现的差异。比如,html5的storage(session,local), 不同浏览器,不同版本,有些支持,有些不支持。Polyfill(Polyfill有很多,在Gi…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...

Java 与 MySQL 性能优化:MySQL 慢 SQL 诊断与分析方法详解
文章目录 一、开启慢查询日志,定位耗时SQL1.1 查看慢查询日志是否开启1.2 临时开启慢查询日志1.3 永久开启慢查询日志1.4 分析慢查询日志 二、使用EXPLAIN分析SQL执行计划2.1 EXPLAIN的基本使用2.2 EXPLAIN分析案例2.3 根据EXPLAIN结果优化SQL 三、使用SHOW PROFILE…...