Hadoop3教程(二十一):MapReduce中的压缩
文章目录
- (123)压缩概述
- 在Map阶段启用
- 在Reduce阶段启用
- (124)压缩案例实操
- 如何在Map输出端启用压缩
- 如何在Reduce端启用压缩
- 参考文献
(123)压缩概述
压缩也是MR中比较重要的一环,其可以应用于Map阶段,比如说Map端输出的文件,也可以应用于Reduce阶段,如最终落地的文件。
压缩的好处,是减少磁盘的IO以及存储空间。缺点也很明显,就是极大增加了CPU的开销(频繁计算带来的频繁压缩与解压缩)。
压缩的基本原则:
- 对运算密集型job,少用压缩;(计算时需要解压缩,计算完需要压缩,受不了)
- 对IO密集型Job,多用压缩。
MR支持很多种压缩算法,常用的有以下几个:
| 压缩格式 | Hadoop自带? | 算法 | 文件扩展名 | 是否可切片 | 换成压缩格式后,原来的程序是否需要修改 |
|---|---|---|---|---|---|
| DEFLATE | 是,直接使用 | DEFLATE | .deflate | 否 | 和文本处理一样,不需要修改 |
| Gzip | 是,直接使用 | DEFLATE | .gz | 否 | 和文本处理一样,不需要修改 |
| bzip2 | 是,直接使用 | bzip2 | .bz2 | 是 | 和文本处理一样,不需要修改 |
| LZO | 否,需要安装 | LZO | .lzo | 是 | 需要建索引,还需要指定输入格式 |
| Snappy | 是,直接使用 | Snappy | .snappy | 否 | 和文本处理一样,不需要修改 |
支持切片的话,使用上会更方便很多。
压缩性能的比较如下:
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
据说最好的还是Google开发的snappy,其官网介绍它的压缩速度是250MB/s,解压缩速度是500MB/s。
那在生产环境下,该如何选择合适的压缩方式呢?
一般是重点考虑以下几点:
- 压缩/解压缩速度;
- 压缩率,即压缩后的文件大小;
- 压缩后是否还支持切片。
结合这几点,我们再回头看这几种压缩算法。
Gzip压缩:压缩率比较高,但是压缩/解压缩速度一般,且不支持切片;
Bzip2压缩,压缩率非常高,且支持切片,但是压缩/解压缩速度极慢;
Lzo压缩,压缩/解压缩速度非常快,且支持切片,但是压缩率一般;不过Lzo需要额外创建索引之后,才能支持切片。
Snappy压缩,压缩和解压缩速度极快,但不支持切片,压缩率一般。
压缩可以在MapReduce的任意阶段启用,一共三个阶段,即Map的输入端、Map到Reduce部分、Reduce的输出端。
在Map阶段启用
在Map的输入端启用压缩时:
不需要显式指定使用的编解码方式,Hadoop会自动通过文件扩展名,来选择合适的编解码方式。
同时,需要注意,如果数据量小于块大小的话,则可以考虑压缩、解压缩速度比较快的算法,如LZO、snappy;如果数据量大于块大小的话,则可以重点考虑支持切片的算法,如Bzip2和LZO。
在Mapper的输出端启用压缩时:
这里启用压缩,主要是为了减少MapTask和ReduceTask之间的网络IO,所以可以选择重点考虑压缩和解压缩快的LZO、snappy等。
在Reduce阶段启用
在Reducer的输出端启用压缩时:
如果输出的数据是需要永久保存,那么可以采用压缩率比较高的算法,以减少存储的空间;
如果是作为下一个MapReduce的输入,那么可以考虑数据量和是否支持切片。
(124)压缩案例实操
讲怎么写压缩代码的,此处只做了解,所以基本是直接复制教程文档。
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
要在Hadoop中启用压缩,可以配置如下参数
| 参数 | 默认值 | 阶段 | 建议 |
|---|---|---|---|
| io.compression.codecs (在core-site.xml中配置) | 无,这个需要在命令行输入hadoop checknative查看 | 输入压缩 | Hadoop使用文件扩展名判断是否支持某种编解码器 |
| mapreduce.map.output.compress(在mapred-site.xml中配置) | false | mapper输出 | 这个参数设为true启用压缩 |
| mapreduce.map.output.compress.codec(在mapred-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec | mapper输出 | 企业多使用LZO或Snappy编解码器在此阶段压缩数据 |
| mapreduce.output.fileoutputformat.compress(在mapred-site.xml中配置) | false | reducer输出 | 这个参数设为true启用压缩 |
| mapreduce.output.fileoutputformat.compress.codec(在mapred-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec | reducer输出 | 使用标准工具或者编解码器,如gzip和bzip2 |
抄一下案例。
如何在Map输出端启用压缩
假如想Mapper输出端启用压缩,只需要调整驱动类即可,Mapper和Reducer类不需要做特殊处理,跟正常一样就可以。
package com.atguigu.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();// 开启map端输出压缩conf.setBoolean("mapreduce.map.output.compress", true);// 设置map端输出压缩方式conf.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class,CompressionCodec.class);Job job = Job.getInstance(conf);job.setJarByClass(WordCountDriver.class);job.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));boolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
如何在Reduce端启用压缩
假如想Reducer输出端启用压缩:
package com.atguigu.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.DefaultCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.io.compress.Lz4Codec;
import org.apache.hadoop.io.compress.SnappyCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();Job job = Job.getInstance(conf);job.setJarByClass(WordCountDriver.class);job.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// 设置reduce端输出压缩开启FileOutputFormat.setCompressOutput(job, true);// 设置压缩的方式FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
// FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
// FileOutputFormat.setOutputCompressorClass(job, DefaultCodec.class); boolean result = job.waitForCompletion(true);System.exit(result?0:1);}
}
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
:MapReduce中的压缩)
Hadoop3教程(二十一):MapReduce中的压缩
文章目录 (123)压缩概述在Map阶段启用在Reduce阶段启用 (124)压缩案例实操如何在Map输出端启用压缩如何在Reduce端启用压缩 参考文献 (123)压缩概述 压缩也是MR中比较重要的一环,其可以应用于M…...
04、RocketMQ -- 核心基础使用
目录 核心基础使用1、入门案例生产者消费者 2、消息发送方式方式1:同步消息方式2:异步消息方式3:一次性消息管控台使用过程中可能出现的问题 3、消息消费方式集群模式(默认)广播模式 4、顺序消息分析图:代码…...

mysql中date/datetime类型自动转go的时间类型time.Time
在DSN中需要加入parseTimetrue&&locLocal,或 charsetutf8mb4&locAsia%2FShanghai&parseTimetrue。 package main_testimport ("database/sql""fmt""testing""time"_ "github.com/go-sql-driver/mysq…...
)
MATLAB算法实战应用案例精讲-【图像处理】机器视觉(基础篇)
目录 前言 几个高频面试题目 如何选择合适的面扫相机 如何选择光学滤波器 知识储备...

LDAP协议工作原理
LDAP,全称Lightweight Directory Access Protocol,译为轻量目录访问协议,是一个在互联网中广泛使用的协议,主要用于实现网络中的信息查找和检索。在身份认证方面,LDAP起着重要的作用。 LDAP的工作原理主要包括以下几个…...

【Jetpack Compose】BOM是什么?
前言 本篇旨在帮助小伙伴们了解和使用Compose中BOM相关的知识,在Compose的开发过程中更加便捷、统一的管理相关依赖信息。 BOM基础知识 Compose推出的BOM为物料清单的意思,BOM全称为Bill Of Materials,Compose推出BOM的意义旨在通过指定的…...
多域名SSL数字证书是什么呢
多域名SSL数字证书是众多SSL数字证书中最灵活的一款SSL证书产品。一般一张SSL证书只能保护一个域名,即使能保护多个域名站点,证书保护的域名类型也有限制(通配符SSL数字证书)。多域名SSL数字证书既能用一张SSL证书保护多个域名网站,又不限制域…...

杭电oj--求奇数的乘积
Problem Description 给你n个整数,求他们中所有奇数的乘积。 Input 输入数据包含多个测试实例,每个测试实例占一行,每行的第一个数为n,表示本组数据一共有n个,接着是n个整数,你可以假设每组数据必定至少存…...
E053-web安全应用-Brute force暴力破解初级
课程分类: web安全应用 实验等级: 中级 任务场景: 【任务场景】 小王接到磐石公司的邀请,对该公司旗下的网站进行安全检测,经过一番检查发现该论坛的后台登录页面上可能存在万能密码漏洞,导致不知道账号密码也能登录后台&am…...

外汇天眼;VT Markets 赞助玛莎拉蒂MSG Racing电动方程式世界锦标赛
随着国际汽联电动方程式世界锦标赛第十赛季的到来,外汇经纪商 VT Markets 和玛莎拉蒂 MSG Racing 宣布了一项为期多年的全球合作。 外汇天眼温馨提醒:在做外汇交易之前,一定要审核清楚外汇平台的资质以及官网信息,以防上当受骗&am…...
使用vscode + vite + vue3+ element3 搭建vue3脚手架
技术栈 开发工具:VSCode 代码管理:Git 前端框架:Vue3 构建工具:Vite 路由:vue-router 状态管理:vuex AJAX:axios UI库:element-ui 3 数据模拟:mockjs css预处理…...

竞赛 深度学习+opencv+python实现车道线检测 - 自动驾驶
文章目录 0 前言1 课题背景2 实现效果3 卷积神经网络3.1卷积层3.2 池化层3.3 激活函数:3.4 全连接层3.5 使用tensorflow中keras模块实现卷积神经网络 4 YOLOV56 数据集处理7 模型训练8 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 &am…...

spring boot 下载resources下的静态文件为流格式
废话不多说,直接上代码 一、下载逻辑 public void downAppApk(HttpServletResponse response){ClassPathResource classPathResource new ClassPathResource("app/xxxxxx.apk");if (!classPathResource.exists()) {throw new BusinessException("安…...

HTML渲染过程
整个渲染过程: 将 URL 对应的各种资源,通过浏览器渲染引擎的解析,输出可视化的图像。 基本概念: HTML 解释器:解析html语言、将html文本翻译成dom树; CSS 解释器:解析css语言,给…...
[已解决]llegal target for variable annotation
llegal target for variable annotation 问题 变量注释的非法目标 思路 复制时编码错误,自己敲一遍后正常运行 #** 将垂直知识加入prompt,以使其准确回答 **# prompt_templates { # "recommand":"用户说:__INPUT__ …...
nodejs基于vue小型企业银行账目管理系统
这就产生了以台式计算机为核心的管理信息系统在大规模的事务处理和对工作流的管理等方面的应用,在银行帐目管理之中的应用日益增加 且会出现信息的重复传递问题,因此该过程需要进行信息化,以利用计算机进行帐目管理。 3.1 银行帐目管理系统功能模块 …...
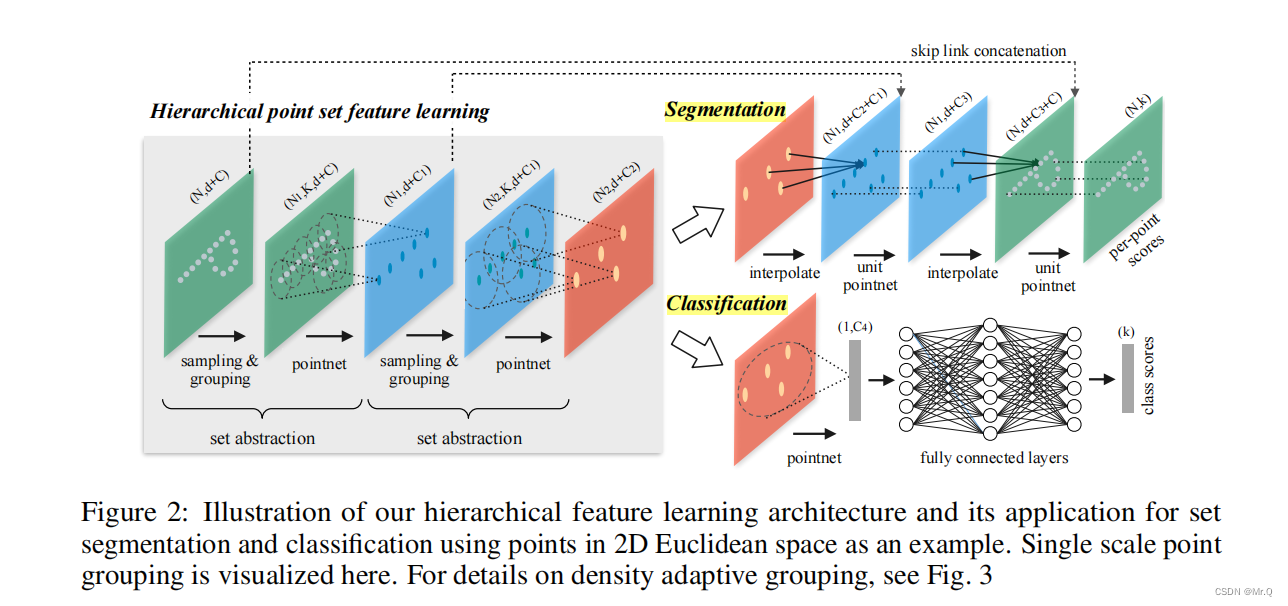
pointnet和pointnet++点云分割和分类
目录 1. pointnet 1.1 点云数据的特点 1.2 模型功能 1.3 网络结构 1.3.1 分类网络 1.3.2 分割网络 2. pointnet 2.1 模型 2.2 sampling layer组件 2.3 grouping layer 2.4 pointnet 1. pointnet 1.1 点云数据的特点 (1)无序性:…...

Docker-compose和Consul
目录 1、docker-compose 简介 1.1 Docker-compose 简介 2、compose 部署 2.1 Docker Compose 环境安装 2.2 YAML 文件格式及编写注意事项 * * * * 2.3 Docker Compose配置常用字段 2.4 Docker Compose 常用命令 2.5 Docker Compose 文件结构 3、Consul 3.1 什么是…...

AFL模糊测试+GCOV覆盖率分析
安全之安全(security)博客目录导读 覆盖率分析汇总 目录 一、代码示例 二、afl-cov工具下载 三、编译带覆盖率的版本并启动afl-cov 四、AFL编译插桩并运行afl-fuzz 五、结果查看 AFL相关详见AFL安全漏洞挖掘 GCOV相关详见GCOV覆盖率分析 现将两者结合,即进…...
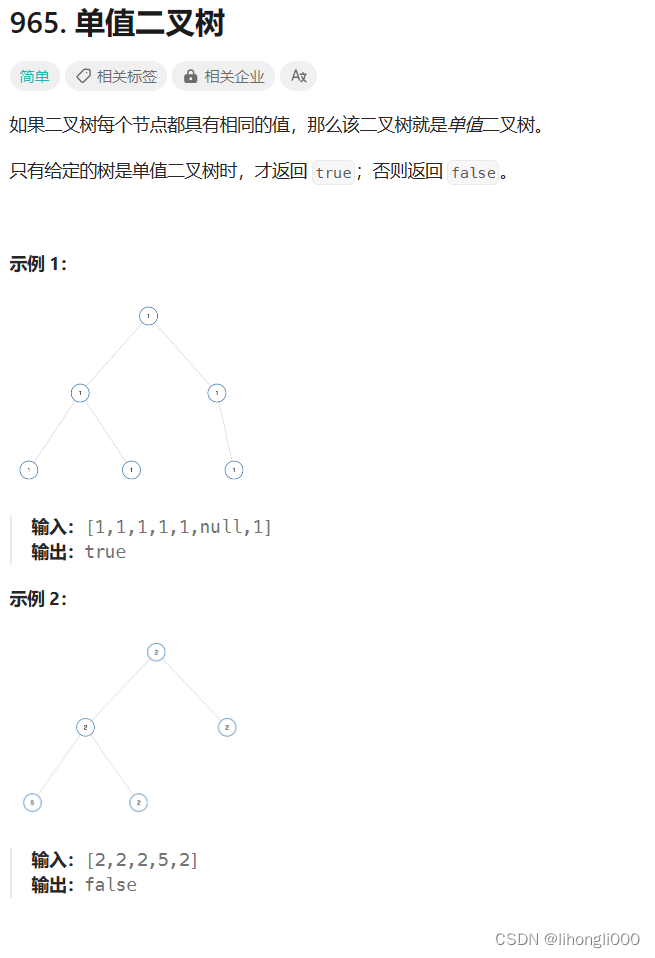
leetcode 965.单值二叉树
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/ //遍历判断函数 bool TreeCompare(struct TreeNode* root,int x) {if(root NULL)return true;if(root->val ! x)return false…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

Device Mapper 机制
Device Mapper 机制详解 Device Mapper(简称 DM)是 Linux 内核中的一套通用块设备映射框架,为 LVM、加密磁盘、RAID 等提供底层支持。本文将详细介绍 Device Mapper 的原理、实现、内核配置、常用工具、操作测试流程,并配以详细的…...
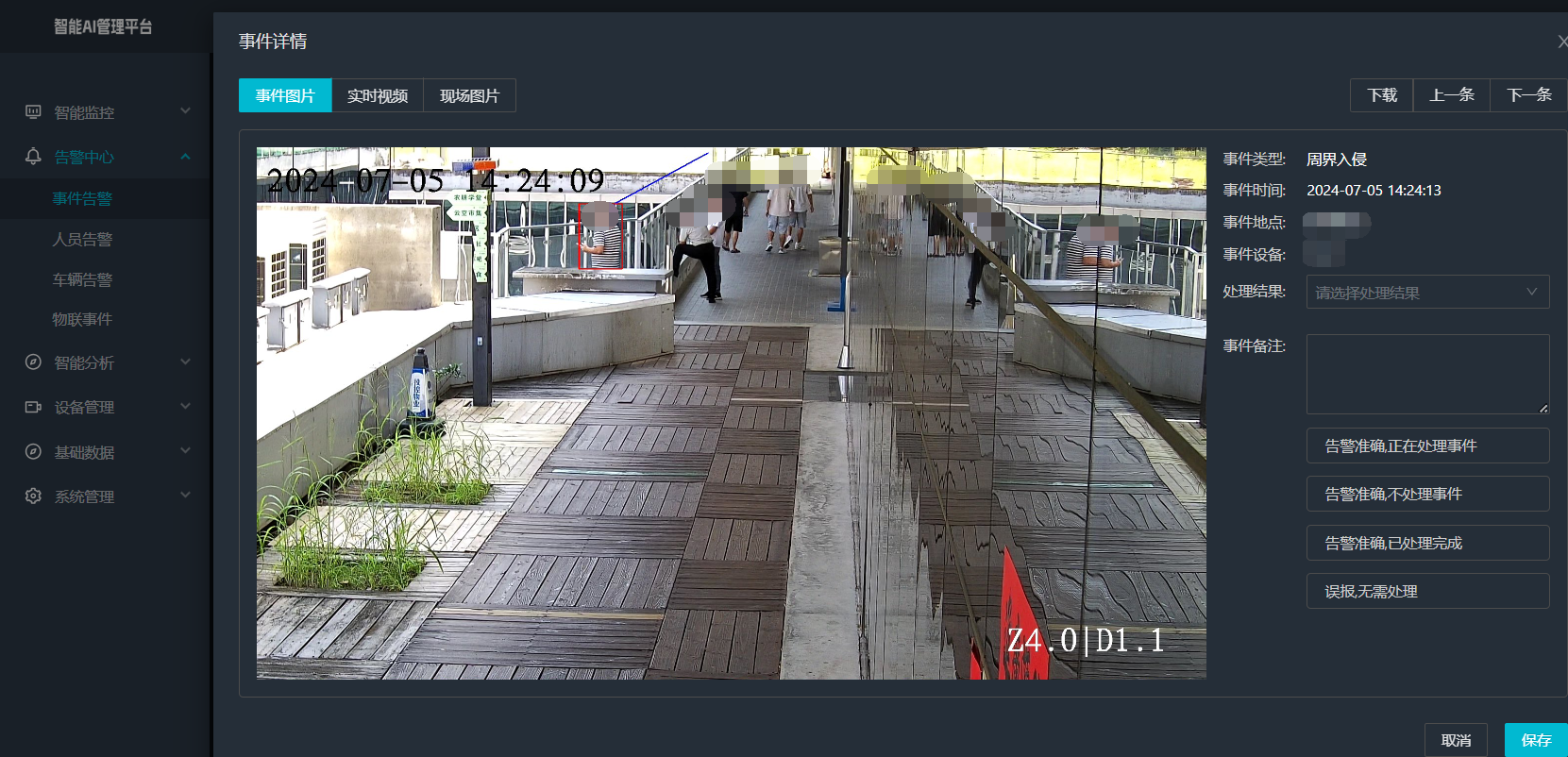
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...