[动手学深度学习]生成对抗网络GAN学习笔记
论文原文:Generative Adversarial Nets (neurips.cc)
李沐GAN论文逐段精读:GAN论文逐段精读【论文精读】_哔哩哔哩_bilibili
论文代码:http://www.github.com/goodfeli/adversarial
Ian, J. et al. (2014) 'Generative adversarial network', NIPS'14: Proceedings of the 27th International Conference on Neural Information Processing Systems, Vol. 2, pp 2672–2680. doi: https://doi.org/10.48550/arXiv.1406.2661
目录
1. GAN论文原文学习
1.1. Abstract
1.2. Introduction
1.3. Related work
1.4. Adversarial nets
1.5. Theoretical Results
1.5.1. Global Optimality of p_g = p_data
1.5.2. Convergence of Algorithm 1
1.6. Experiments
1.7. Advantages and disadvantages
1.8. Conclusions and future work
2. 知识补充
2.1. Divergence
2.2. 唠嗑一下
1. GAN论文原文学习
1.1. Abstract
①They combined generative model and discriminative model
together, which forms a new model.
is the "cheating" part which focus on imitating and
is the "distinguishing" part which focus on distinguishing where the data comes from.
②This model is rely on a "minmax" function
③GAN does not need Markov chains or unrolled approximate inference nets
④They designed qualitative and quantitative evaluation to analyse the feasibility of GAN
1.2. Introduction
①The authors praised deep learning and briefly mentioned its prospects
②Due to the difficulty of fitting or approximating the distribution of the ground truth, the designed a new generative model
③They compare the generated model to the person who makes counterfeit money, and the discriminative model to the police. Both parties will mutually promote and grow. The authors ultimately hope that the ability of the counterfeiter can be indistinguishable from the genuine product
④Both and
are MLP, and
passes random noise
⑤They just adopt backpropagation and dropout in training
corpora 全集;corpus 的复数
counterfeiter n.伪造者;制假者;仿造者
1.3. Related work
①Recent works are concentrated on approximating function, such as succesful deep Boltzmann machine. However, their likelihood functions are too complex to process.
②Therefore, here comes generative model, which only generates samples but does not approximates function. Generative stochastic networks are an classic generative model.
③Their backpropagation:
④Variational autoencoders (VAEs) in Kingma and Welling and Rezende et al. do the similar work. However, VAEs are modeled by differentiate hidden units, which is contrary to GANs.
⑤And some others aims to approximate but are hard to. Such as Noise-contrastive estimation (NCE), discriminating data under noise, but limited in its discriminator.
⑥The most relevant work is predictability minimization, it utilize other hiden units to predict given unit. However, PM is different from GAN in that (a) PM focus on objective function minimizing, (b) PM is just a regularizer, (c) the two networks in PM respectively make output similar or different
⑦Adversarial examples distinguish which data is misclassified with no generative function
1.4. Adversarial nets
①They designed a minimax function:
where denotes generator's distribution,
represents data,
denotes prior probability with noise,
denotes a differentiable function, namely a MLP layer, with parameters
,
also denotes a MLP layer with its output is a scalar, where the scalar is the probability that
is real data exceeds the probability that it is generated data
②They train and
together with maximizing
and minimizing
③They reckon is more likely to be overfitting. Hence, k-steps of optimizing
and 1-step optimizing of
is more suitable
④ is relatively weak in early stages, thus train
first might achieve better results
pedagogical adj.教育学的;教学论的
1.5. Theoretical Results
①Their fitting diagram:
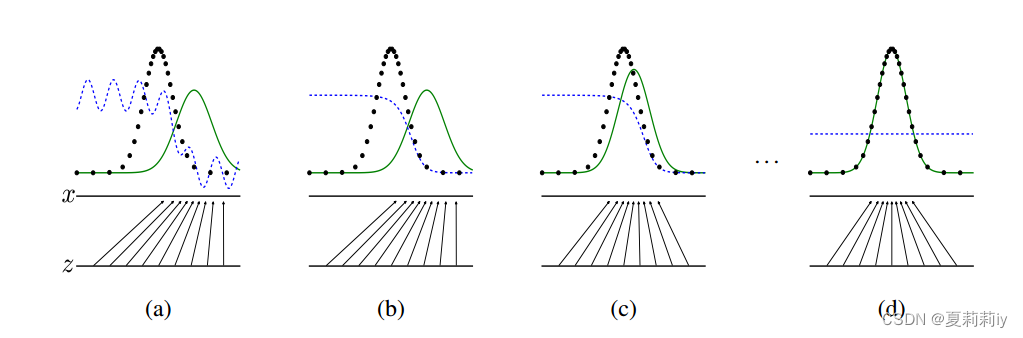
where is blue and dashed line,
is green and solid line, the real data distribution is black and dashed line,
converges to
. And when it equals to
with
that means
can not discriminate any data
②Pseudocode of GAN:

1.5.1. Global Optimality of p_g = p_data
①They need to maximize for
:
for any coefficient , the value of expression
achieves its maximum when
. Thus
②Then change the original function to:
③ is the minimum of
when
④KL divergence used for it:
⑤JS divergence used for it:
and the authors recognized the non negative nature of JS divergence more, therefore adopting JS divergence
1.5.2. Convergence of Algorithm 1
①The function is convex so that when gradient updating tends to stabilize, it may achieve the global optima
②Parzen window-based log-likelihood estimates:
where they adopt mean loglikelihood of samples on MNIST, standard error across folds of TFD
supremum n.上确界;最小上界;上限
1.6. Experiments
①Datasets: MNIST, Toronto Face Database (TFD), CIFAR-10
②Activation: combination of ReLU and Sigmoid for generator, Maxout for discriminator
③Adopting dropout in discriminator
④Noise is only allowed as the bottommost input
⑤Their Gaussian Parzen window method brings high variance and performs somewhat poor in high dimensional spaces
1.7. Advantages and disadvantages
(1)Disadvantages
①There is no clear representation of
②It is difficult to achieve synchronous updates between and
(2)Advantages
①No need for Markov chain
②Updating by gradients instead of data
③They can express any distribution
1.8. Conclusions and future work
①Samples (left) and generative data (right with yellow outlines) in (a) MNIST, (b) TFD, (c) CIFAR-10 (fully connected model), (d) CIFAR-10 (convolutional discriminator and “deconvolutional” generator):

②"Digits obtained by linearly interpolating between coordinates in space of the full model":

③Their summary of challenges in different parts:
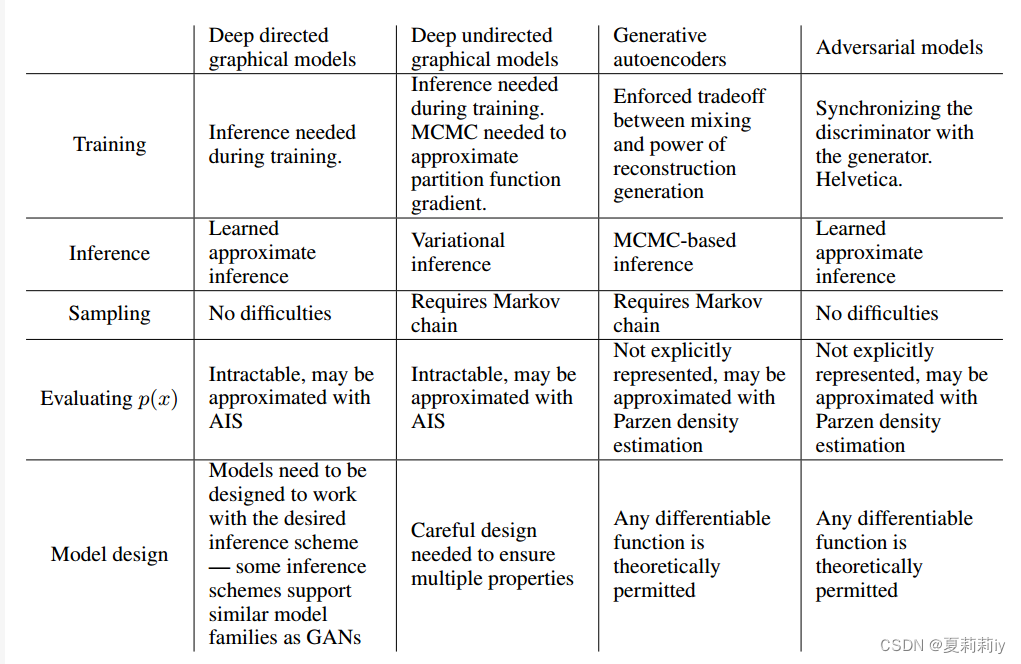
interpolate v.〈数〉插(值),内插,内推;计算(中间值);插入(字句等);添加(评论或字句);篡改;插话,插嘴
2. 知识补充
2.1. Divergence
(1)Kullback–Leibler divergence (KL divergence)
①相关链接:机器学习:Kullback-Leibler Divergence (KL 散度)_kullback-leibler散度-CSDN博客
②关于KL散度(Kullback-Leibler Divergence)的笔记 - 知乎 (zhihu.com)
(2)Jensen–Shannon divergence (JS divergence)
①理解JS散度(Jensen–Shannon divergence)-CSDN博客
2.2. 唠嗑一下
(1)论文倒是精简易懂,特别是配上李沐的讲解之后更没啥大问题了。但是作者提供的源码还是有点过于爆炸,且README没有多说。很难上手啊,新人完全不推荐
相关文章:
[动手学深度学习]生成对抗网络GAN学习笔记
论文原文:Generative Adversarial Nets (neurips.cc) 李沐GAN论文逐段精读:GAN论文逐段精读【论文精读】_哔哩哔哩_bilibili 论文代码:http://www.github.com/goodfeli/adversarial Ian, J. et al. (2014) Generative adversarial network…...
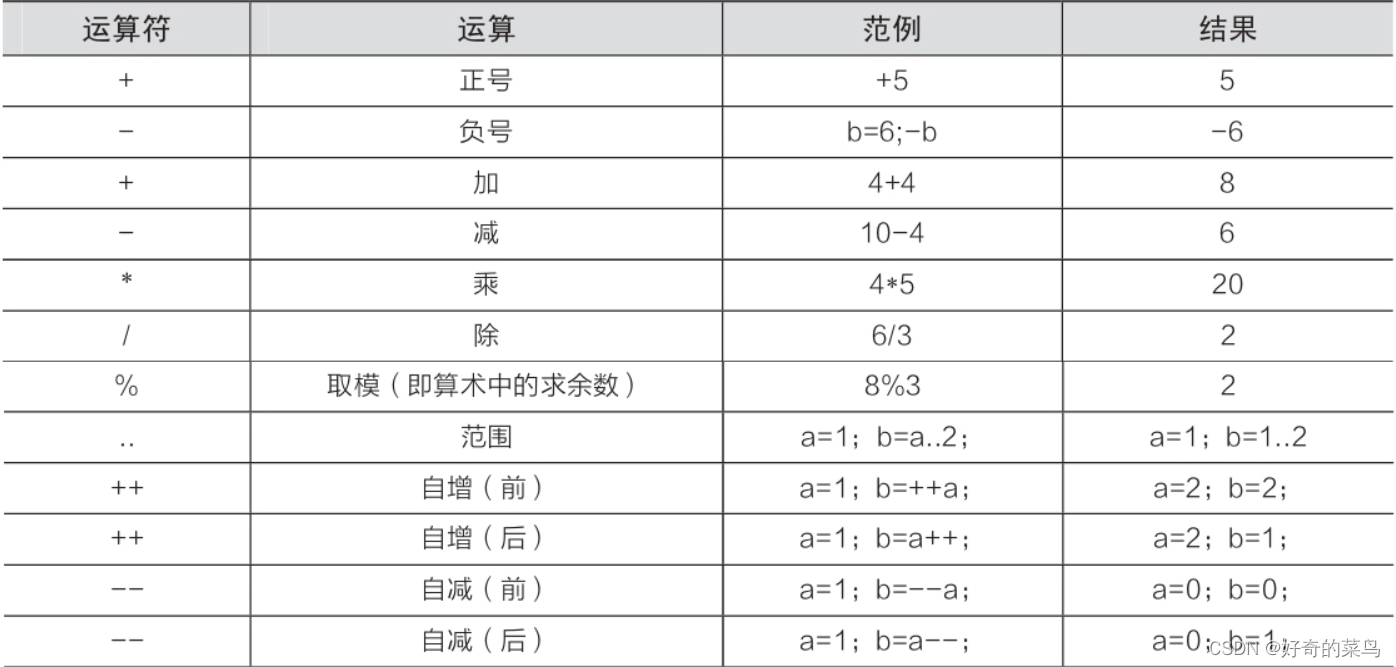
Kotlin中的算数运算符
在Kotlin中,我们可以使用各种算术运算符来进行数值计算和操作。下面对这些运算符进行详细描述,并提供示例代码。 正号(正数)和负号(负数): 正号用于表示一个正数,不对数值进行任何…...

Linux高性能服务器编程 学习笔记 第十六章 服务器调制、调试和测试
Linux平台的一个优秀特性是内核微调,即我们可以通过修改文件的方式来调整内核参数。 服务器开发过程中,可能会碰到意想不到的错误,一种调试方法是用tcpdump抓包,但这种方法主要用于分析程序的输入和输出,对于服务器的…...

第三期:云函数入门指南答案
1.云函数需要用户自行考虑租用/购买多少资源以达到最少成本最高效运行自己的函数。 答案:错误(False) 2.Cloud Functions可以为您准备好计算资源,弹性地、可地运行任务,并提供日志查询、性能监控和报警等功能。 答案:正确(True…...

企业怎么通过数字化工具来实现数字化转型?
数字化转型是使用数字技术和工具从根本上改变公司运营方式并向客户提供价值的过程。它涉及思维方式、流程和技术的全面转变,以跟上快节奏的数字时代。以下是有关公司如何通过数字工具实现数字化转型的分步指南: 1.定义您的愿景和目标: 首先确…...

React函数式写法和类式写法的区别(以一个计数器功能为例子)
函数式写法更加简洁和函数式编程思维导向,适用于无状态、UI纯粹的组件,且可以使用Hooks处理副作用。而类式写法适用于有内部状态、生命周期方法和复杂交互逻辑的组件,提供了更多的灵活性和控制力。 文章目录 一、计数器功能演示 1.函数式写法…...

【根据国防科大学报官网word模板修改的Latex模板】
根据国防科大学报官网word模板修改的Latex模板 学报Word模板链接Latex模板结构编译环境为Texlivevscode或Textstudio 学报Word模板链接 学报官网相关下载链接 点击链接即可前往官网下载相关word模板 Latex模板结构 latex模板 ass.cfg文件 %深层模板文件ass.cls文件 %浅层模板…...

系列十一、Redis中分布式缓存实现
一、缓存 1.1、什么是缓存 内存就是计算机内存中的一段数据。 1.2、内存中的数据特点 读写快断电数据丢失 1.3、缓存解决了什么问题 提高了网站的吞吐量和运行效率减轻了数据库的访问压力 1.4、哪些数据适合加缓存 使用缓存时,一定是数据库中的数据极少发生改…...
)
Spark大数据分析与实战笔记(第一章 Scala语言基础-4)
文章目录 每日一句正能量1.4 Scala面向对象的特性1.4.1 类与对象的特性1.4.2 继承1.4.3 单例对象和伴生对象1.4.4 特质 每日一句正能量 若要快乐,就要随和;若要幸福,就要随缘。快乐是心的愉悦,幸福是心的满足。别和他人争吵&#…...
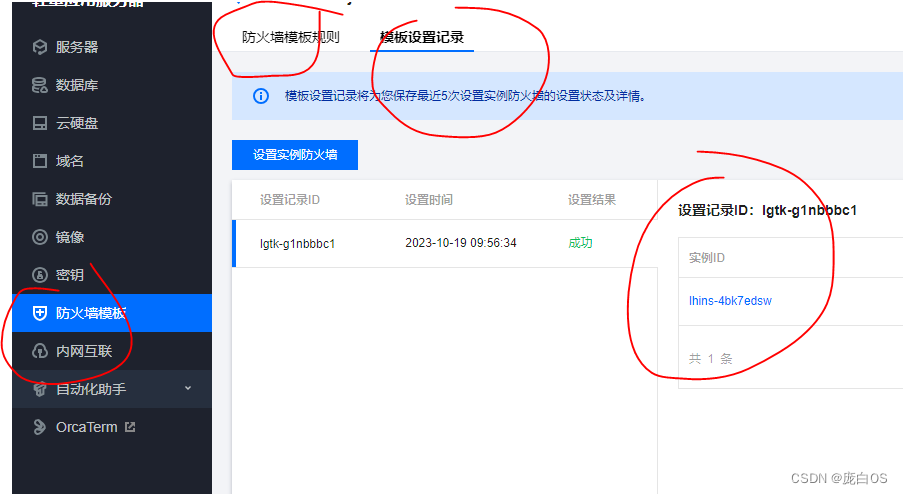
腾讯云服务器端口localhost可以访问,外部无法访问解决
搭建frp跳板,发现无法使用。ssh 连接不上。 主要检查2个东西: 1. ubuntu ufw系统防火墙。这个默认是关掉的 2. tencent这个防火墙规则设置后,还要设置到实例上。 以前不是这样的。就掉坑里了。 # systemctl rootVM-4-4-ubuntu:/lib/syst…...

【软考-中级】系统集成项目管理工程师 【16 变更管理】
持续更新。。。。。。。。。。。。。。。 【第十六章】变更管理 (选择2分 考点 1:变更的常见原因考点 2:变更管理的原则是项目基准化、变更管理过程规范化考点 3考点 4考点 5:变更的工作程序考点 6考点 7考点 8考点 9考点 10考点 11考点 12:变更分类系列文章经典语录 考点 1:变…...
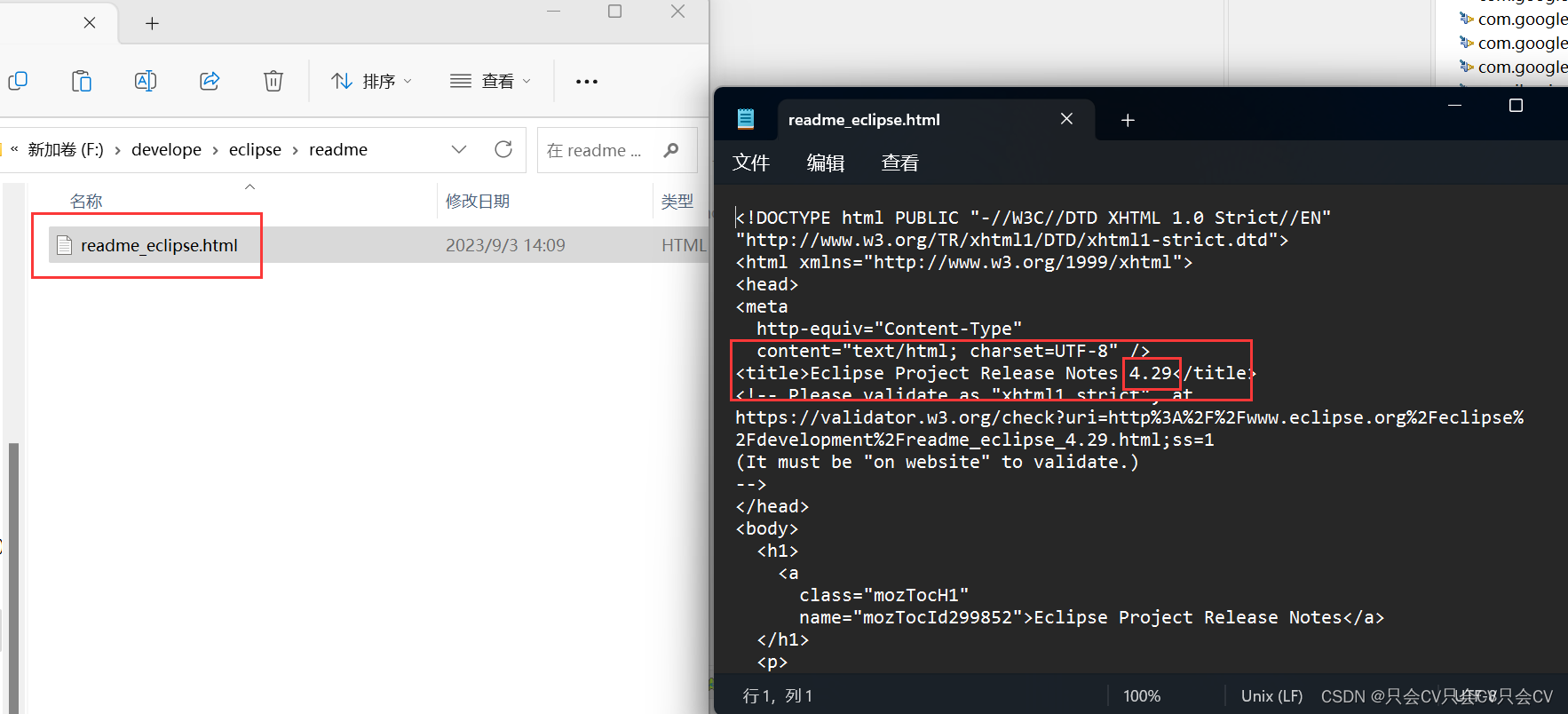
【Eclipse】查看版本号
1.在Eclipse的启动页面会出现版本号 2. Eclipse的关于里面 Help - About Eclipse IDE 如下图所示,就为其版本 3.通过查看readme_eclipse.html文件...

论文精讲目录
ViT论文逐段精读【论文精读】MoCo 论文逐段精读【论文精读】对比学习论文综述【论文精读】Swin Transformer论文精读【论文精读】CLIP 论文逐段精读【论文精读】双流网络论文逐段精读【论文精读】I3D 论文精读【论文精读】视频理解论文串讲(上)【论文精读…...

双飞翼布局和圣杯布局
双飞翼布局和圣杯布局都是一种三栏布局,其中主要内容区域位于中间,左侧栏和右侧栏位于两侧。它们的实现方式类似,但有一些细微的差别。 双飞翼布局的实现原理是通过使用flex布局,给主要内容区域设置flex:1;…...

Hive insert插入数据与with子查询
1. insert into 与 insert overwrite区别 insert into 与 insert overwrite 都可以向hive表中插入数据,但是insert into直接追加到表中数据的尾部,而insert overwrite会重写数据,既先进行删除,再写入 注意:如果存在分…...

如何在Django中集成JWT
文章目录 JWT简介在Django中使用JWT1. 安装2. 配置3. 添加认证接口 客户端使用JWT1. 获取新token2. 调用API3. 刷新token 同步发布在个人站点:https://panzhixiang.cn JWT简介 JWT(JSON Web Token)是一种流行的跨域认证解决方案。它可以在令牌中安全地传输用户身份…...

hive进行base64 加密解密函数
加密 select base64(cast(abcd as binary))YWJjZA 解密 -- 直接解密(结果字段格式为比binary格式) select unbase64(YWJjZA) -- 格式转换 select cast(unbase64(YWJjZA) as string) abcd...
Docker安装GitLab及使用图文教程
作者: 宋发元 GitLab安装及使用教程 官方教程 https://docs.gitlab.com/ee/install/docker.html Docker安装GitLab 宿主机创建容器持久化目录卷 mkdir -p /docker/gitlab/{config,data,logs}拉取GitLab镜像 docker pull gitlab/gitlab-ce:15.3.1-ce.0运行GitLa…...
asp.net酒店管理系统VS开发sqlserver数据库web结构c#编程Microsoft Visual Studio
一、源码特点 asp.net酒店管理系统是一套完善的web设计管理系统,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为vs2010,数据库为sqlserver2008,使用c#语言开发 asp.net 酒店管理系统1 二、功能介绍 …...

Yolov安全帽佩戴检测 危险区域进入检测 - 深度学习 opencv 计算机竞赛
1 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 Yolov安全帽佩戴检测 危险区域进入检测 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:3分创新点:4分 该项目较为新颖&am…...

大话软工笔记—需求分析概述
需求分析,就是要对需求调研收集到的资料信息逐个地进行拆分、研究,从大量的不确定“需求”中确定出哪些需求最终要转换为确定的“功能需求”。 需求分析的作用非常重要,后续设计的依据主要来自于需求分析的成果,包括: 项目的目的…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...

【网络安全】开源系统getshell漏洞挖掘
审计过程: 在入口文件admin/index.php中: 用户可以通过m,c,a等参数控制加载的文件和方法,在app/system/entrance.php中存在重点代码: 当M_TYPE system并且M_MODULE include时,会设置常量PATH_OWN_FILE为PATH_APP.M_T…...