JUC并发编程与源码分析笔记09-原子类操作之十八罗汉增强
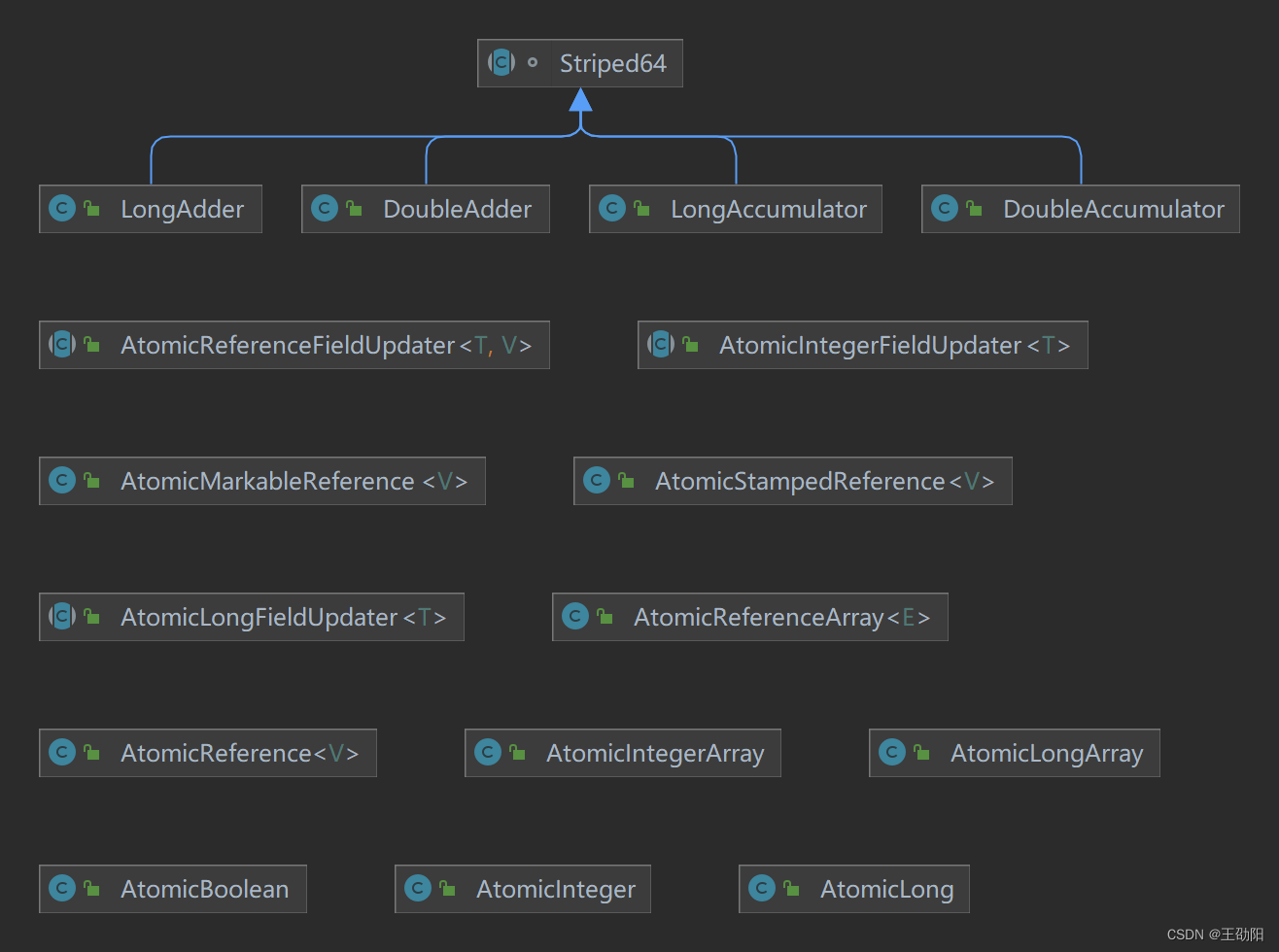
基本类型原子类
AtomicInteger、AtomicBoolean、AtomicLong。
常用API:
public final int get();// 获取当前的值
public final int getAndSet(int newValue);// 获取当前值,并设置新值
public final int getAndIncrement();// 获取当前的值,并自增
public final int getAndDecremennt();// 获取当前的值,并自减
public final int getAndAdd(int delta);// 获取当前的值,并加上预期的值
boolean compareAndSet(int expect, int update);// 如果输入的数值等于预期值(expect),则以原子方式将该值设置为输入值(update)
一个例子:
import java.util.concurrent.atomic.AtomicInteger;public class AtomicDemo {public static void main(String[] args) {MyNumber myNumber = new MyNumber();for (int i = 0; i < 50; i++) {new Thread(() -> {for (int j = 0; j < 1000; j++) {myNumber.add();}}).start();}System.out.println("最终结果:" + myNumber.atomicInteger.get());}
}class MyNumber {AtomicInteger atomicInteger = new AtomicInteger();public void add() {atomicInteger.getAndIncrement();}
}
多次执行,会发现每次的结果都不一样,这是因为main线程执行的太快了,子线程还没有运行完成,main线程就获取了原子对象的值。尝试在main线程获取结果之前,添加一个线程等待,可以看到main线程就可以获取到正确的结果了。
那么,就有一个问题了,这里线程等待多久呢?由此就引出countDownLatch。
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicInteger;public class AtomicDemo {public static void main(String[] args) throws InterruptedException {int size = 50;MyNumber myNumber = new MyNumber();CountDownLatch countDownLatch = new CountDownLatch(size);for (int i = 0; i < size; i++) {new Thread(() -> {try {for (int j = 0; j < 1000; j++) {myNumber.add();}} finally {countDownLatch.countDown();}}).start();}countDownLatch.await();System.out.println("最终结果:" + myNumber.atomicInteger.get());}
}class MyNumber {AtomicInteger atomicInteger = new AtomicInteger();public void add() {atomicInteger.getAndIncrement();}
}
数组类型原子类
了解了基本类型原子类,再理解数组类型原子类就很容易了:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray。
public class AtomicDemo {public static void main(String[] args) {AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(new int[5]);// AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(5);// AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(new int[]{1,2,3,4,5});for (int i = 0; i < atomicIntegerArray.length(); i++) {System.out.println(atomicIntegerArray.get(i));}System.out.println();int value = 0;value = atomicIntegerArray.getAndSet(0, 12345);System.out.println(value + "\t" + atomicIntegerArray.get(0));value = atomicIntegerArray.getAndIncrement(0);System.out.println(value + "\t" + atomicIntegerArray.get(0));}
}
引用类型原子类
AtomicReference、AtomicStampedReference、AtomicMarkableReference。
AtomicReference
在自旋锁SpinLock里介绍过。
AtomicStampedReference
携带版本号的引用类型原子类,可以解决ABA问题,解决修改过几次问题,修改过一次后,版本号加一。
AtomicMarkableReference
带有标记位的引用类型原子类,标记位的值有两个:true/false,如果修改过,标记位由false变为true,解决一次性问题。
import java.util.concurrent.atomic.AtomicMarkableReference;public class AtomicDemo {static AtomicMarkableReference atomicMarkableReference = new AtomicMarkableReference(100, false);public static void main(String[] args) {new Thread(() -> {boolean marked = atomicMarkableReference.isMarked();System.out.println(Thread.currentThread().getName() + "标识:" + marked);try {Thread.sleep(1000);// 为了线程2可以拿到和线程1同样的marked,都是false} catch (InterruptedException e) {e.printStackTrace();}boolean b = atomicMarkableReference.compareAndSet(100, 1000, marked, !marked);System.out.println(Thread.currentThread().getName() + "CAS结果:" + b);System.out.println("结果:" + atomicMarkableReference.getReference());}, "thread1").start();new Thread(() -> {boolean marked = atomicMarkableReference.isMarked();System.out.println(Thread.currentThread().getName() + "标识:" + marked);try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}boolean b = atomicMarkableReference.compareAndSet(100, 2000, marked, !marked);System.out.println(Thread.currentThread().getName() + "CAS结果:" + b);System.out.println("结果:" + atomicMarkableReference.getReference());}, "thread2").start();}
}
对象的属性修改原子类
AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater。
使用目的:以一种线程安全的方式,操作非线程安全对象内的某个字段。
使用要求:
- 更新对象属性必须使用public volatile修饰
- 因为对象属性修改类型原子类是抽象类,所以每次使用都必须使用静态方法newUpdater()创建一个更新器,并且需要设置想要更新的类和属性
AtomicIntegerFieldUpdater的例子
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicIntegerFieldUpdater;public class AtomicDemo {public static void main(String[] args) throws InterruptedException {int size = 10;Account account = new Account();CountDownLatch countDownLatch = new CountDownLatch(size);for (int i = 0; i < size; i++) {new Thread(() -> {try {for (int j = 0; j < 1000; j++) {// account.synchronizedAdd();// 使用synchronized方式保证程序正确性account.atomicAdd(account);// 不使用synchronized,保证程序的正确性}} finally {countDownLatch.countDown();}}).start();}countDownLatch.await();System.out.println("money=" + account.money);}
}class Account {String name = "王劭阳";public volatile int money = 0;/*** 使用synchronized方式保证程序正确性*/public synchronized void synchronizedAdd() {money++;}AtomicIntegerFieldUpdater<Account> accountAtomicIntegerFieldUpdater = AtomicIntegerFieldUpdater.newUpdater(Account.class, "money");/*** 不使用synchronized,保证程序的正确性*/public void atomicAdd(Account account) {accountAtomicIntegerFieldUpdater.getAndIncrement(account);}
}
AtomicReferenceFieldUpdater的例子
AtomicIntegerFieldUpdater也有局限性,它只能处理Integer类型的字段,对于其他类型的字段,可以使用AtomicReferenceFieldUpdater。
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicReferenceFieldUpdater;public class AtomicDemo {public static void main(String[] args) throws InterruptedException {int size = 10;CountDownLatch countDownLatch = new CountDownLatch(size);Account account = new Account();for (int i = 0; i < size; i++) {new Thread(() -> {try {account.init(account);} finally {countDownLatch.countDown();}}).start();}countDownLatch.await();}
}class Account {public volatile Boolean init = Boolean.FALSE;AtomicReferenceFieldUpdater<Account, Boolean> accountBooleanAtomicReferenceFieldUpdater = AtomicReferenceFieldUpdater.newUpdater(Account.class, Boolean.class, "init");public void init(Account account) {if (accountBooleanAtomicReferenceFieldUpdater.compareAndSet(account, Boolean.FALSE, Boolean.TRUE)) {System.out.println(Thread.currentThread().getName() + " start init");System.out.println(Thread.currentThread().getName() + " end init");} else {System.out.println(Thread.currentThread().getName() + " init fail,because there has been inited");}}
}
原子操作增强类原理深度解析
DoubleAccumulator、DoubleAdder、LongAccumulator、LongAdder:这几个类是从Java8出现的。
在阿里巴巴Java开发手册上,推荐使用LongAdder,因为它比AtomicLong性能更好(减少乐观锁的重试次数)。
这里以LongAccumulator和LongAdder为例进行比较。
区别:LongAdder只能用来计算加法,且从零开始计算,LongAccumulator提供了自定义函数操作。
import java.util.concurrent.atomic.LongAccumulator;
import java.util.concurrent.atomic.LongAdder;public class AtomicDemo {public static void main(String[] args) {LongAdder longAdder = new LongAdder();longAdder.increment();longAdder.increment();System.out.println(longAdder.sum());LongAccumulator longAccumulator = new LongAccumulator(Long::sum, 0);longAccumulator.accumulate(1);longAccumulator.accumulate(3);System.out.println(longAccumulator.get());}
}
设计计数器,比较synchronized、AtomicLong、LongAdder、LongAccumulator
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.atomic.LongAccumulator;
import java.util.concurrent.atomic.LongAdder;public class AtomicDemo {public static void main(String[] args) throws InterruptedException {long startTime, endTime;int size = 100;ClickNumber clickNumber = new ClickNumber();CountDownLatch countDownLatch1 = new CountDownLatch(size);CountDownLatch countDownLatch2 = new CountDownLatch(size);CountDownLatch countDownLatch3 = new CountDownLatch(size);CountDownLatch countDownLatch4 = new CountDownLatch(size);startTime = System.currentTimeMillis();for (int i = 0; i < size; i++) {new Thread(() -> {try {for (int j = 0; j < 100 * 10000; j++) {clickNumber.bySynchronized();}} finally {countDownLatch1.countDown();}}).start();}countDownLatch1.await();endTime = System.currentTimeMillis();System.out.println("bySynchronized:" + (endTime - startTime) + "\tsum=" + clickNumber.number);startTime = System.currentTimeMillis();for (int i = 0; i < size; i++) {new Thread(() -> {try {for (int j = 0; j < 100 * 10000; j++) {clickNumber.byAtomicLong();}} finally {countDownLatch2.countDown();}}).start();}countDownLatch2.await();endTime = System.currentTimeMillis();System.out.println("byAtomicLong:" + (endTime - startTime) + "\tsum=" + clickNumber.atomicLong.longValue());startTime = System.currentTimeMillis();for (int i = 0; i < size; i++) {new Thread(() -> {try {for (int j = 0; j < 100 * 10000; j++) {clickNumber.byLongAdder();}} finally {countDownLatch3.countDown();}}).start();}countDownLatch3.await();endTime = System.currentTimeMillis();System.out.println("byLongAdder:" + (endTime - startTime) + "\tsum=" + clickNumber.longAdder.sum());startTime = System.currentTimeMillis();for (int i = 0; i < size; i++) {new Thread(() -> {try {for (int j = 0; j < 100 * 10000; j++) {clickNumber.byLongAccumulator();}} finally {countDownLatch4.countDown();}}).start();}countDownLatch4.await();endTime = System.currentTimeMillis();System.out.println("byLongAccumulator:" + (endTime - startTime) + "\tsum=" + clickNumber.longAccumulator.longValue());}
}class ClickNumber {long number;public synchronized void bySynchronized() {number++;}AtomicLong atomicLong = new AtomicLong();public void byAtomicLong() {atomicLong.getAndDecrement();}LongAdder longAdder = new LongAdder();public void byLongAdder() {longAdder.increment();}LongAccumulator longAccumulator = new LongAccumulator(Long::sum, 0);public void byLongAccumulator() {longAccumulator.accumulate(1);}
}
通过运行结果,可以看出来:LongAdder和LongAccumulator的效率比AtomicLong要快。
源码、原理分析
架构
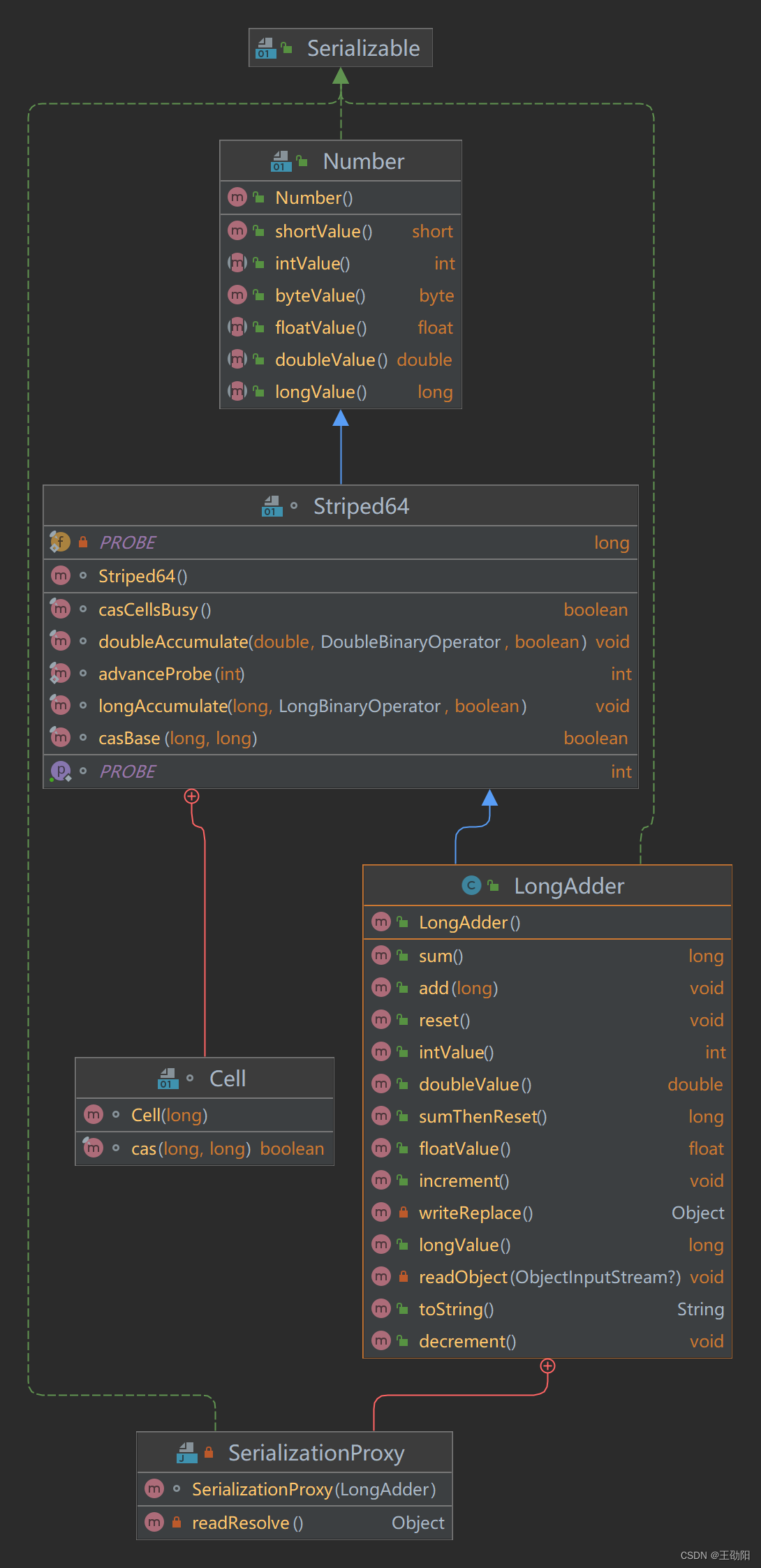
原理
当多个线程更新用于收集统计信息但不用于细粒度同步控制的目的的公共和时,LongAdder通常优于AtomicLong。在高争用的情况下,LongAdder的预期吞吐量明显更高,但代价是空间消耗更高。
为了分析其原理,需要先了解Striped64.java和Cell.java类。
Cell.java是java.util.concurrent.atomic下Striped64.java的一个内部类。
/** Number of CPUS, to place bound on table size:CPU数量,即cells数组的最大长度 */
static final int NCPU = Runtime.getRuntime().availableProcessors();/*** Table of cells. When non-null, size is a power of 2.* cells数组,为2的幂,方便位运算*/
transient volatile Cell[] cells;/*** Base value, used mainly when there is no contention, but also as* a fallback during table initialization races. Updated via CAS.* 基础value值,当并发较低时,只累加该值,主要用于没有竞争的情况,通过CAS更新*/
transient volatile long base;/*** Spinlock (locked via CAS) used when resizing and/or creating Cells.* 创建或扩容Cells数组时,使用自旋锁变量调整单元格大小(扩容),创建单元格时使用的锁*/
transient volatile int cellsBusy;
Striped64.java中一些变量或方法定义:
- base:类似于AtomicLong中全局value值。在没有竞争的情况下,数据直接累加到base上,或者cells扩容时,也需要将数据写入到base上
- collide:表示扩容意向,false:一定不会扩容,true:可能会扩容
- cellsBusy:初始化cells或者扩容cells需要获取锁,0:表示无锁状态,1:表示其他线程已经持有锁
- casCellsBusy():通过CAS操作修改cellsBusy的值,CAS成功代表获取锁,返回true
- NCPU:当前计算机CPU数量,Cell数组扩容时会使用到
- getProbe():获取当前线程hash值
- advanceProbe():重置当前线程hash值
LongAdder的基本思路就是分散热点,将value的值分散到一个Cell数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行CAS操作,这样热点就被分散了,冲突的概率就小很多。如果要获取真正的long值,只要将各个槽中的变量值累加返回。
sum()方法会将Cell数组中的value和base累加并作为返回值,核心思想就是将之前的AtomicLong的一个value的更新压力分散到多个value中去,从而降级更新热点。
低并发的时候,就是对base变量进行CAS操作。高并发的时候,就是对Cell数组进行CAS操作,最后调用sum()。
value=base+∑i=0nCell[i]value=base+\sum_{i=0}^{n}Cell[i]value=base+i=0∑nCell[i]
LongAdder在无竞争的情况下,跟AtomicLong一样,对同一个base进行操作,当出现竞争关系时,则采用化整为零分散热点的做法,用空间换时间,用一个数组Cell,将一个value拆分进这个数组Cell。多个线程需要同时对value进行操作时候,可以对线程id进行hash得到hash值,再根据hash映射到这个数组Cell的某个下标,再对该下标所对应的值进行自增操作。当所有线程操作完毕,将数组Cell的所有值和base加起来作为最终结果。
源码解读深度分析
LongAdder的increment()方法:
increment()方法首先调用add(1L)方法,add()方法里,真正起作用的方法是longAccumulate()方法。
public void add(long x) {// as:Cells对象的引用// b:获取的base值// v:期望值// m:cells数组的长度// a:当前线程命中的cell单元格Cell[] as; long b, v; int m; Cell a;if ((as = cells) != null || !casBase(b = base, b + x)) {boolean uncontended = true;if (as == null || (m = as.length - 1) < 0 ||(a = as[getProbe() & m]) == null ||!(uncontended = a.cas(v = a.value, v + x)))longAccumulate(x, null, uncontended);}
}
观察if判断条件,第一个条件(as = cells) != null的结果,第一次进来是false,我们继续看,会对base做一个cas操作,当线程少的时候,cas是足够的,因此casBase()的结果就是true,再取非,就是false了。这也是低并发时候,只需要操作base即可。
当线程增多,casBase()的返回值可能和想象中的不大一样了,因此,cas失败,!casBase()的值是false,所以会进第一层if。再继续往里看,第一个判断as == null即可判断出结果为true,再次进入if,接下来执行longAccumulate()方法。
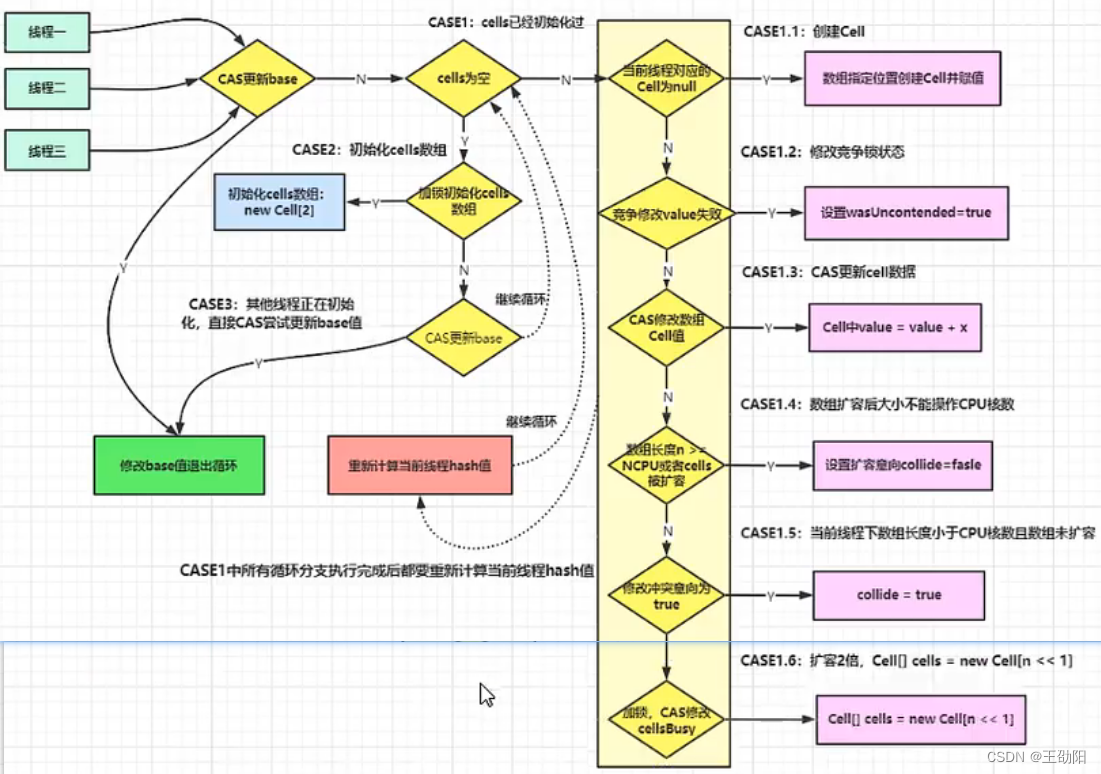
当第一次来到longAccumulate()方法的时候,会执行Initialize table这块代码,初始化cells。
再次回到add方法,此时(as = cells) != null的结果为true,继续判断里面的if条件。as == null为false,继续判断(m = as.length - 1) < 0的值为false,继续判断(a = as[getProbe() & m]) == null,其中getProbe() & m可以类比HashMap的put()方法,在找数组下标时候的思想,通过位运算快速定位数组下标,判断as[i]这个地方有没有填充值,如果没有填充,那么运算结果为true,进入下面的longAccumulate()方法,如果运算结果为false,继续判断!(uncontended = a.cas(v = a.value, v + x))的值,也就是对非空的a值进行cas操作,操作成功后,uncontended是一个非零值,那么!uncontended就是一个零值,代表false,下面的longAccumulate()方法不会执行。继续观察!(uncontended = a.cas(v = a.value, v + x)),当cas失败的时候,!uncontended就为true,此时,也会进入longAccumulate()方法,这时候代表线程竞争更加激烈,现有的base+cell已经计算不过来了,需要对cell数组进行扩容了,扩容方法也在longAccumulate()里实现。


接下来查看longAccumulate()方法。
这个方法有3个参数:
- long x:需要增加的值,一般是1
- LongBinaryOperator fn:默认为null
- boolean wasUncontentded:竞争标识,false表示存在竞争,只有cells初始化后,并且当前线程CAS修改失败,
wasUncontentded的值才为false
查看getProbe()方法,大致可以理解成当前线程的hash值,用于确定进入哪个cells里。
final void longAccumulate(long x, LongBinaryOperator fn,boolean wasUncontended) {int h;// 存储线程probe值if ((h = getProbe()) == 0) {// 说明probe未初始化// 使用ThreadLocalRandom为当前线程重新计算一个hash值,强制初始化ThreadLocalRandom.current(); // force initializationh = getProbe();// 重新获取probe值,probe值被重置好比一个全新的线程一样wasUncontended = true;// 标记wasUncontended为true}boolean collide = false; // True if last slot nonemptyfor (;;) {// 自旋,看代码的时候,先看case2,case3,再看case1Cell[] as; Cell a; int n; long v;// case1:cells已经被初始化了,可能存在扩容if ((as = cells) != null && (n = as.length) > 0) {if ((a = as[(n - 1) & h]) == null) {// 当前线程hash后映射的cells[i]为null,说明这个cells[i]可以使用// 数组没有在扩容if (cellsBusy == 0) { // Try to attach new Cell// 新建一个Cell,填充valueCell r = new Cell(x); // Optimistically create// 尝试加锁,成功后cellsBusy=1if (cellsBusy == 0 && casCellsBusy()) {boolean created = false;try { // Recheck under lockCell[] rs; int m, j;// 双端加锁,将刚才带值的cell放到cells数组中if ((rs = cells) != null &&(m = rs.length) > 0 &&rs[j = (m - 1) & h] == null) {rs[j] = r;created = true;}} finally {cellsBusy = 0;}if (created)break;continue; // Slot is now non-empty}}collide = false;}// wasUncontended表示初始化cells后,当前线程竞争失败,wasUncontended=false,重新设置wasUncontended为true,接着执行advanceProbe(h)重置当前hash值,重新循环else if (!wasUncontended) // CAS already known to failwasUncontended = true; // Continue after rehash// 说明当前线程对应数组有数据,也重置过hash值,通过CAS操作尝试对当前cells[i]累加x,如果cas成功了,直接跳出循环else if (a.cas(v = a.value, ((fn == null) ? v + x :fn.applyAsLong(v, x))))break;// 如果n≥CPU最大数量,就不能扩容,并通过下面的advanceProbe(h)再次计算hash值else if (n >= NCPU || cells != as)collide = false; // At max size or stale// 如果collide为false,则修改它为true(可以扩容),重新计算hash值,如果当前数组已经≥CPU最大数量,还会把collide置为false(不能扩容)else if (!collide)collide = true;else if (cellsBusy == 0 && casCellsBusy()) {try {// 当前数组和最先赋值的数组是同一个,代表没有被其他线程扩容过,当前线程对数组进行扩容if (cells == as) { // Expand table unless stale// 容量按位左移1位进行扩容Cell[] rs = new Cell[n << 1];// 扩容后的拷贝工作for (int i = 0; i < n; ++i)rs[i] = as[i];// 将扩容后的数组指向cellscells = rs;}} finally {// 释放锁cellsBusy = 0;}// 设置扩容状态=不能扩容,继续循环collide = false;continue; // Retry with expanded table}h = advanceProbe(h);}// case2:cells没有加锁且没有初始化,尝试对它加锁并初始化cells数组// cellsBusy=0表示无锁,并通过casCellsBusy()获取锁,也就是修改cellsBusy的值else if (cellsBusy == 0 && cells == as && casCellsBusy()) {boolean init = false;try { // Initialize table// double-check的目的:避免再次new一个cells数组,避免上一个线程中的数据被篡改if (cells == as) {// 新建一个容量为2的数组Cell[] rs = new Cell[2];rs[h & 1] = new Cell(x);// 填充数据cells = rs;init = true;}} finally {cellsBusy = 0;}if (init)break;}// case3:cells正在初始化,尝试直接在基数base上进行累加操作// 兜底方法,上面的所有cas操作都失败了,那么操作数据就会更新到base上else if (casBase(v = base, ((fn == null) ? v + x :fn.applyAsLong(v, x))))break; // Fall back on using base}
}
接下来是sum()方法求和,会将Cell数组中value和base累加作为返回值,核心思想就是将之前AtomicLong一个value的更新压力分散到多个value中去,从而降级更新热点。
public long sum() {Cell[] as = cells; Cell a;long sum = base;if (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}return sum;
}
sum()方法在执行的时候,并没有限制base和cells的更新,所以LongAdder不是强一致性的,它是最终一致性的。最终返回的sum是局部变量,初始化的时候sum=base,在累加cells[i]的时候,base可能被更新了,但是sum并不会重新读取base的值,所以会出现数据不准确的情况。
使用总结
AtomicLong:线程安全,可允许一些性能损耗,要求高精度时使用,保证精度,性能代价,AtomicLong是多个线程对单个热点值value进行原子操作。
LongAdder:需要在高并发下有较好的性能表现,对值精确度要求不高时候,可以使用,保证性能,精度代价,LongAdder是每个线程拥有自己的槽位,各个线程一般只对自己槽中的那个值进行CAS操作。
小总结
AtomicLong:
原理:CAS+自旋:incrementAndGet()
场景:低并发下全局计算,AtomicLong能保证并发下计数的准确性,内部通过CAS来解决并发安全性问题
缺陷:高并发后性能急剧下降,AtomicLong的自旋会成为瓶颈,N个线程进行CAS操作,每次只有一个线程成功,其他N-1个线程失败,失败后就不停的自旋直到成功,这样大量失败自旋的情况,CPU占用率就高了
LongAdder:
原理:CAS+Base+Cell数组,空间换时间分散热点数据
场景:高并发下全局计算
缺陷:如果在sum求和过程中,还有计算线程修改结果的话,会造成结果不准确
相关文章:
JUC并发编程与源码分析笔记09-原子类操作之十八罗汉增强
基本类型原子类 AtomicInteger、AtomicBoolean、AtomicLong。 常用API: public final int get();// 获取当前的值 public final int getAndSet(int newValue);// 获取当前值,并设置新值 public final int getAndIncrement();// 获取当前的值࿰…...

含分布式电源的配电网日前两阶段优化调度模型(Matlab代码实现)
👨🎓个人主页:研学社的博客💥💥💞💞欢迎来到本博客❤️❤️💥💥🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密…...
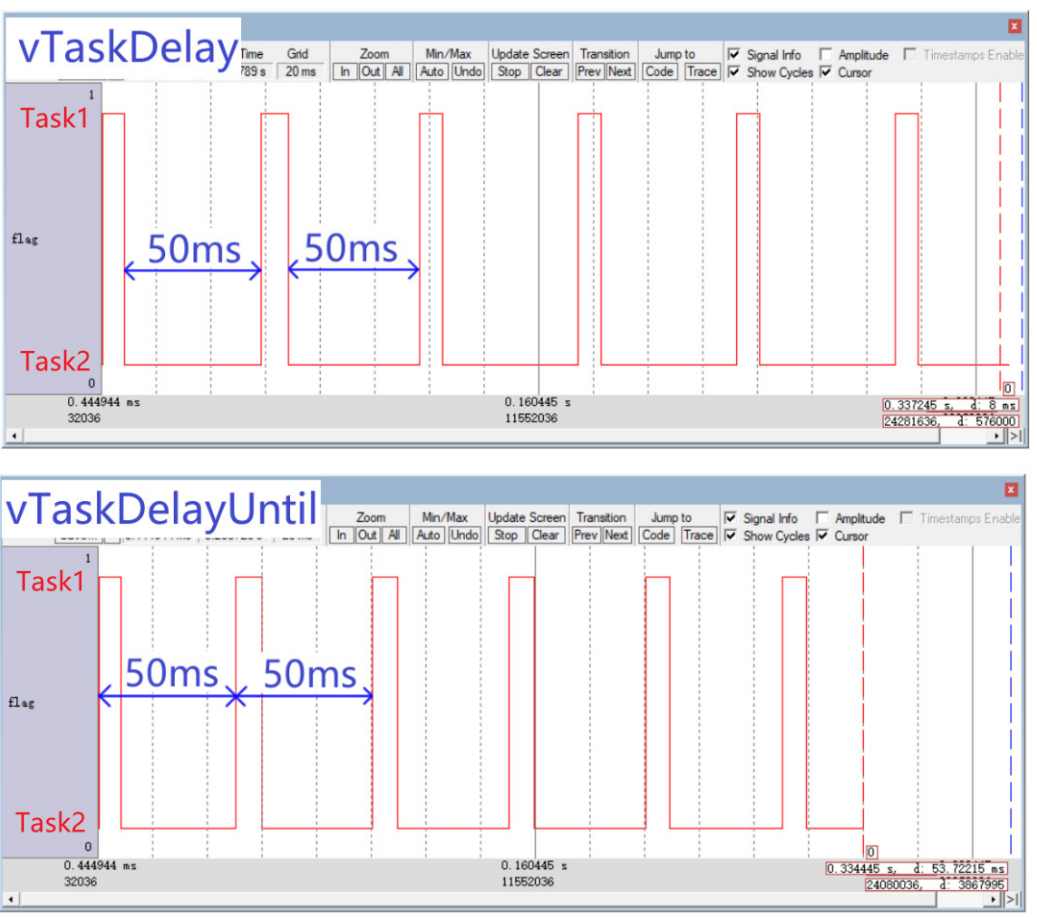
FreeRTOS的Delay函数
两个Delay函数有两个延时函数vTaskDelay:至少等待指定个数的Tick Interrupt才能变为就绪态xTaskDelayUtil:等待到指定的绝对时刻,才能变为就绪态个人感觉这两个延时函数就是,比如一个我等3个小时,一个是我等到下午3点的…...
HCIA-HarmonyOS Application Developer——题目集1
题目1 1、一位开发人员在设计应用程序时,添加了一个Text组件和Button组件,开发样图如下所示。该开发者不能选择哪种布局方式来放置组件? A、StackLayout B、DependentLayout C、DirectionalLayout D、TableLayout 解析:(A&#…...

高性能 Message ToJavaBean 工具 【easy.server.mapper】
easy.server.mapper 介绍 后端开发中,消息转换常见问题 Map 中的数据 转换成实体Bean数组 中的数据 转换成实体BeanServet 中的 param 转换成实体Bean 以上的三个问题是最常见的消息转换困扰。 以Map 举例 常见做法是 手动转换 Map<String,Object> da…...
Web前端学习:三 - 练习
三六:风筝效果 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title><style type"text/css">*{margin: 0;padding: 0;}.d1{width: 200px;height: 200px;background: yellow;position…...

面试题:Android 中 Intent 采用了什么设计模式?
答案是采用了原型模式。原型模式的好处在于方便地拷贝某个实例的属性进行使用、又不会对原实例造成影响,其逻辑在于对 Cloneable 接口的实现。 话不多说看下 Intent 的关键源码: // frameworks/base/core/java/android/content/Intent.java public cla…...

Java数据类型与变量
个人主页:平行线也会相交 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 平行线也会相交 原创 收录于专栏【JavaSE_primary】 文章目录字面常量数据类型变量整型变量字节型变量浮点数变量双精度浮点数单精度浮点数字符型变量布尔型变量空常量nu…...

Python为CANoe工程添加/删除DBC文件
前面文章我们对于通过COM来实现打开CANoe、导入CANoe配置工程、导入执行文件、启动CANoe软件和执行脚本;但是这只能完成最基本的功能调用,在实际得到使用过程中,特别是各家在推的CI/CD以及平台化,仅仅是实现这些功能是完全不够用的;比如dbc的添加和删除,这是我们非常必要…...

不同的产品经理特征和需要的能力
产品经理是一个管家,需要和各方沟通推动产品各个决策进展。 每天早上看看线上用户数据、看下今天要安排任务,接着就是和各方开会讨论推动产品实现。每天穿插于与 UI、用户以及完成自己的 todolist 中循环。如果公司体制完善,还要和运营、数据…...

webpack之处理样式资源
处理样式资源 本章节我们学习使用 Webpack 如何处理 Css、Less、Sass、Scss、Styl 样式资源 #介绍 Webpack 本身是不能识别样式资源的,所以我们需要借助 Loader 来帮助 Webpack 解析样式资源 我们找 Loader 都应该去官方文档中找到对应的 Loader,然后…...

Golang 接口笔记
基本介绍接口是一个数据类型,可以定义一组方法,但都不需要实现。并且interface中不能包含任何变量。到某个自定义类型要使用的时候,再根据具体情况把这些方法实现出来语法type 接口名 interface {method1(参数列表) 返回值列表method2(参数列…...
[计算机网络(第八版)]第二章 物理层(章节测试/章节作业)
章节作业 带答案版 选择题 (单选题)双绞线是用两根绝缘导线绞合而成的,绞合的目的是( )。 A. 减少干扰 B. 提高传输速度 C. 增大传输距离 D. 增大抗拉强度(单选题)在电缆中采用屏蔽技术可以带来的好处主要是( )。 A…...
 类)
[iOS 理解] Swift Runtime (1) 类
Warm up 先看一段代码: import ObjectiveCclass Obj {var x: Double 0 }let v: NSObjectProtocol Obj() as! NSObjectProtocol let result v.isKind(of: Obj.self) let size class_getInstanceSize(Obj.self)我们有一个没有继承 NSObject、没有遵循 NSObjectP…...
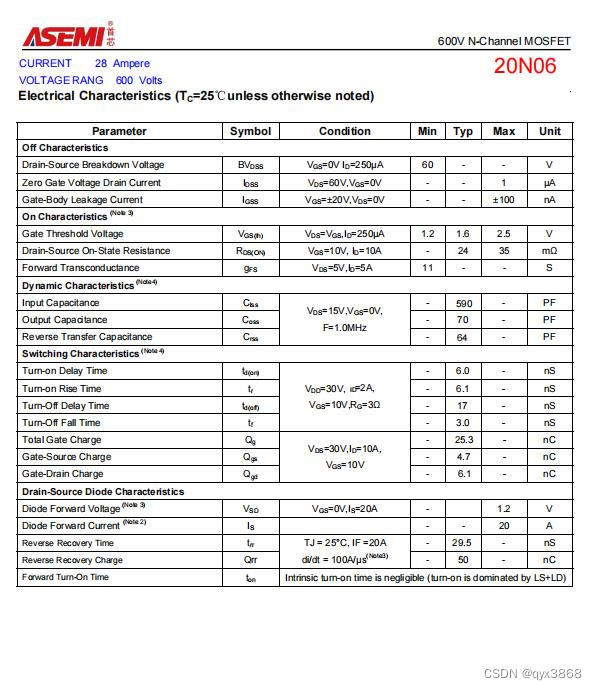
ASEMI低压MOS管20N06参数,20N06体积,20N06大小
编辑-Z ASEMI低压MOS管20N06参数: 型号:20N06 漏极-源极电压(VDS):60V 栅源电压(VGS):20V 漏极电流(ID):20A 功耗(PD࿰…...
(四))
常见前端基础面试题(HTML,CSS,JS)(四)
作用域和作用域链的理解 作用域 (1)全局作用域 最外层函数和最外层函数外面定义的变量拥有全局作用域所有未定义直接赋值的变量自动声明为全局作用域所有window对象的属性拥有全局作用域全局作用域有很大的弊端,过多的全局作用域变量会污染…...

RabbitMQ发布确认模式
目录 一、发布确认原理 二、发布确认的策略 (一)开启发布确认的方法 (二)单个确认模式 (三)批量确认模式 (四)异步确认模式 (五)如何处理异步未确认消…...

零基础的人如何入门 Python ?看完这篇文章你就懂了
第一部分:编程环境准备 零基础入门Python的话我不建议用IDE,IDE叫集成开发环境,这东西一般是专业程序员用来实战开发用的,好处很多,比如:调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测…...

Atcoder abc257 E
E - Addition and Multiplication 2 题意: 给你一个数字n表示你现在拥有的金额 然后给你1~9每个经营额所需要的成本, 设总经营额为x, 当前使用的经营额为y, 则每一次使用经营额时都有x10*xy 问, 如何在使用不大于成本数量的金额下, 使得经营额最高 例如: 5 5 4 3 8 1 6 7 …...

模拟退火算法改进
import numpy as np import matplotlib.pyplot as plt import math import random from scipy.stats import norm from mpl_toolkits.mplot3d import Axes3D # 目标函数 def Function(x, y): return -20 * np.exp(-0.2*np.sqrt(0.5*(x*xy*y)))\ -np.exp(0.5*(n…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...
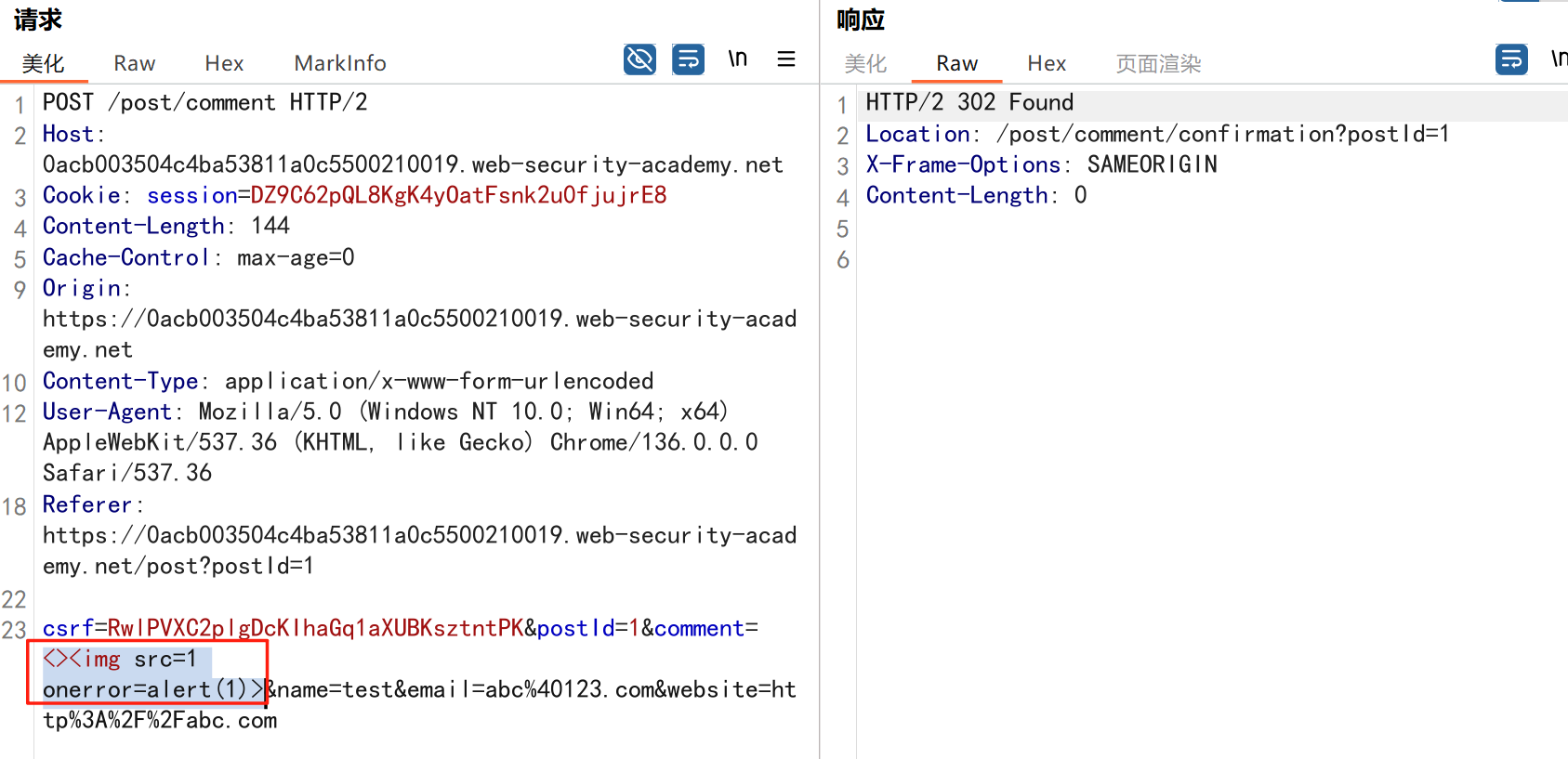
渗透实战PortSwigger靶场:lab13存储型DOM XSS详解
进来是需要留言的,先用做简单的 html 标签测试 发现面的</h1>不见了 数据包中找到了一个loadCommentsWithVulnerableEscapeHtml.js 他是把用户输入的<>进行 html 编码,输入的<>当成字符串处理回显到页面中,看来只是把用户输…...