学习(mianshi)必备-ClickHouse高性能查询/写入和常见注意事项(五)
目录
一、ClickHouse高性能查询原因-稀疏索引
二、ClickHouse高性能写入-LSM-Tree存储结构
什么是LSM-Tree
三、ClickHouse的常见注意事项和异常问题排查
一、ClickHouse高性能查询原因-稀疏索引
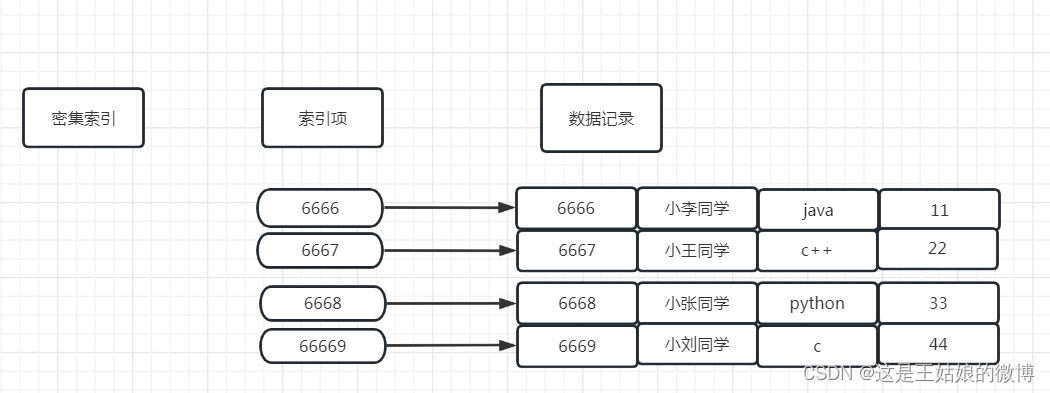
密集索引:
在密集索引中,数据库中的每个键值都有一个索引记录,可以加快搜索速度,但需要更多空间来存储索引记录本身,索引记录包含键值和指向磁盘上实际记录的指针。
mysql中Innodb引擎的主键就是密集索引
稀疏索引:
在稀疏索引中,不会为每个关键字创建索引记录,而是为数据记录文件的每个存储块设一个键-指针对,存储块意味着块内存储单元连续
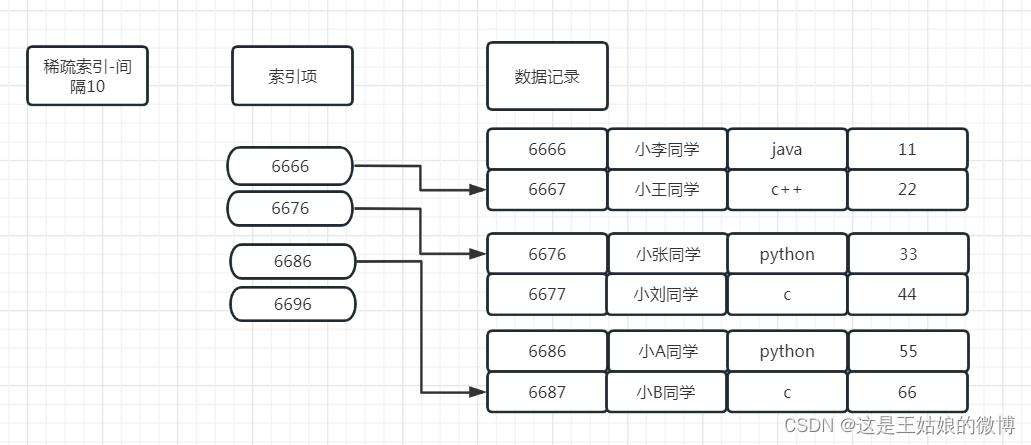
案例:
Mysql的MyISAM引擎里面, 使用均为稀疏索引;
Mysql的Innodb引擎里面,如果有主键,则主键为密集索引
Kafka里面的索引文件也是采用稀疏索引进行构造消息索引
ClickHouse的合并树MergeTree引擎是稀疏索引,默认index_granularity设置8192,新版本的提供了自适应粒度大小的特性
建表语句最后加这个,可以调整
SETTINGS index_granularity = 8192
结论:
ClickHouse一级索引就是【稀疏索引】,可以大幅减少索引占用的空间
默认的索引力度8192,假如1亿行数据只需要存储12208行索引,占用空间小,clickhouse中一级索引的数据是常驻内存的,取用速度极快
稀疏索引所占空间小,并且插入和删除时所需维护的开销也小,缺点是速度比密集索引慢一点
密集索引空间占用多,比稀疏索引更快的定位一条记录,缺点就是会占用较多的空间不变思想:时间换空间、空间换时间
二、ClickHouse高性能写入-LSM-Tree存储结构
先明白一个测试数据:
磁盘顺序读写和随机读写的性能差距大概是1千到5千倍之间
连续 I/O 顺序读写,磁头几乎不用换道,或者换道的时间很短,性能很高,比如0.03 * 2000 MB /s
随机 I/O 随机读写,会导致磁头不停地换道,造成效率的极大降低,0.03MB/s
ClickHouse中的MergeTree也是类LSM树的思想,所以我们也需要了解LSM树
充分利用了磁盘顺序写的特性,实现高吞吐写能力,数据写入后定期在后台Compaction
在数据导入时全部是顺序append写,在后台合并时也是多个段merge sort后顺序写回磁盘
官方公开benchmark测试显示能够达到50MB-200MB/s的写入吞吐能力,按照每行100Byte估算,大约相当于50W-200W条/s的写入速度
什么是LSM-Tree
全称 Log-Structured Merge-Tree 日志结构合并树,但不是树,而是利用磁盘顺序读写能力,实现一个多层读写的存储结构
是一种分层,有序,面向磁盘的数据结构,核心思想是利用了磁盘批量的顺序写要远比随机写性能高出很多
大大提升了数据的写入能力,但会牺牲部分读取性能为代价
HBase、LevelDB、ClickHouse这些NoSQL存储都是采用的类LSM树结构
在 NoSQL 系统里非常常见,基本已经成为必选方案, 为了解决快速读写的问题去设计的
可以分两个部分理解
Log-Structured日志结构的,打印日志是一行行往下写,不需要更改,只需要在后边追加就好了
Merge-tree ,合并就是把多个合成一个,自上而下
LSM-tree 是一个多层结构,就更一个喷泉树一样,上小下大
专门为 key-value 存储系统设计的,最主要的就两个个功能
写入put(k,v)
查找 get(k)得到v
首先是内存的 C0 层,保存了所有最近写入的 (k,v),这个内存结构是有序的,且可以随时原地更新,同时支持随时查询
接下去的 C1 到 Ck 层都在磁盘上,每一层都是一个有序的存储结构
降低一点读性能,通过牺牲小部分读性能,换来高性能写
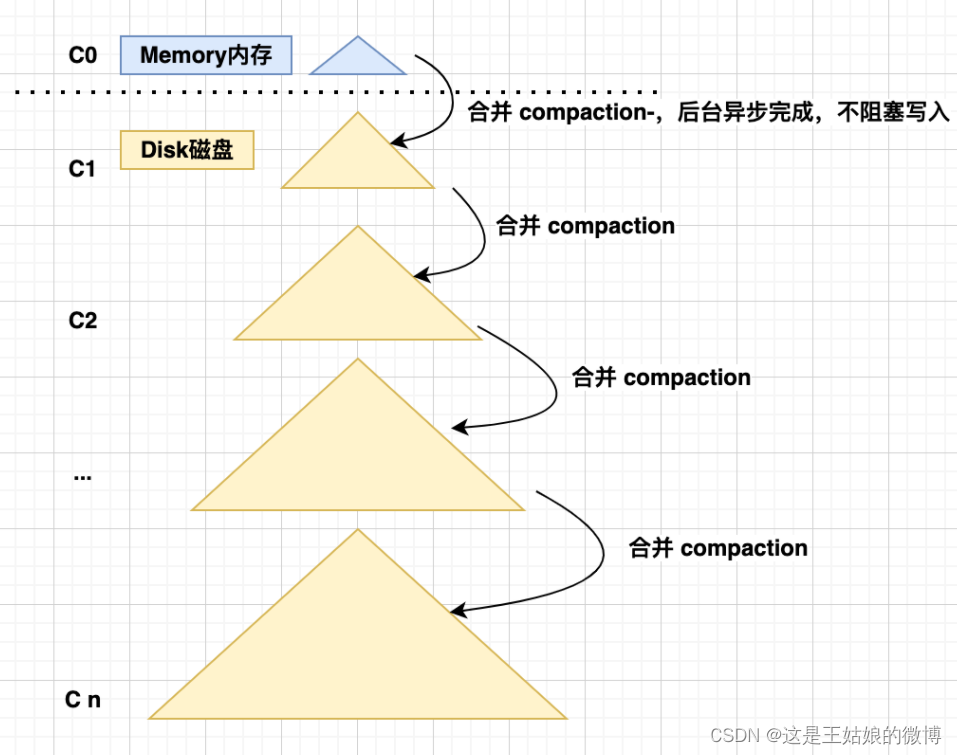
写入流程:
put 操作,首先追加到写前日志(Write Ahead Log),然后加到C0 层
当 C0 层的数据达到一定大小,就把 C0 层 和 C1 层合并,这个过程就是Compaction(合并)
合并出来的新的C1 会顺序写磁盘,替换掉原来的C1
当 C1 层达到一定大小,会和下层继续合并,合并后删除旧的,留下新的
查询流程:
最新的数据在 C0 层,最老的数据在 Cn 层
查询也是先查 C0 层,如果没有要查的数据,再查 C1,逐层查下去直到最后一层
缺点:
读放大:
读取数据时实际读取的数据量大于真正的数据量,在LSM树中需要先在C0查看当前key是否存在,不存在继续从Cn层中寻找写放大:
写入数据时实际写入的数据量大于真正的数据量,在LSM树中写入时可能触发Compact操作,导致实际写入的数据量远大于该key的数据量
三、ClickHouse的常见注意事项和异常问题排查
注意点一:
查询要使用的列,避免select * 全部字段,浪费IO资源
注意点二:
避免大量的小批量数据,插入更新操作,会导致分区过多
每次插入1条,产生了一个分区,大量写入产生大量临时分区和合并操作浪费资源
注意点三:
JOIN操作时一定要把数据量小的表放在右边,无论是Left Join 、Right Join还是Inner Join,右表中的每一条记录到左表中查找该记录是否存在,所以右表必须是小表
注意点四:
批量写入数据时,控制每个批次的数据中涉及到的分区的数量,无序的数据导致涉及的分区太多,建议写入之前最好对需要导入的数据进行排序
注意点五:
写入分布式表还是本地表? 建议:数据量不大,写入本地表和分布式表都行
分布式表不存储数据,本地表存储数据的表
大量数据,日新增500万行以上,分布式表在写入时会在本地节点生成临时数据,会产生写放大,所以会对CPU及内存造成一些额外消耗,服务器merge的工作量增加, 导致写入速度变慢;
数据写入默认是异步的(可以开启同步写但性能会影响),先在分布式表所在的机器进行落盘, 然后异步的发送到本地表所在机器进行存储,中间没有一致性的校验,短时间内可能造成不一致,且如果分布式表所在机器时如果机器出现down机, 会存在数据丢失风险。
建议大数据量尽量少使用分布式表进行写操作,可以根据业务规则均衡的写入本地表;
必须用的话尽量只用读,因为写分布式表对性能影响非常大
注意点六:
单sql查询可以压榨CPU ,但并发多条查询则不是很强
一个分区查询占据一个CPU,业务需要查询表的多个分区可以多个CPU并行处理
注意点七:
没有完整的事务支持,不支持Transaction
OLAP类业务由于数据量非常大,建议数据批量写入,尽量避免数据更新或少更新
注意点八:
在分布式模式下,ClickHouse会将数据分为多个分片,并且分布到不同节点上,有哪种分片策略
ClickHouse提供了丰富的sharding策略,让业务可以根据实际需求选用
random随机分片:写入数据会被随机分发到分布式集群中的某个节点上
constant固定分片:写入数据会被分发到固定一个节点上
hash column value分片:按照某一列的值进行hash分片
常见异常问题:
错误码 300,Too many parts
写入频率过快,使用了不合理的分区键导致总的 part 数目太多,直接拿精确到秒的 timestamp 来作为分区键来进行分区,GG了。
错误码252,Too many partitions for single INSERT block (more than 100),同一批次写入里包括大于100个分区值,clickhouse认为这样会存在性能问题
让数据是按照天/小时分区的,一批数据里的日期跨度为一年,单次插入可能产生365个分区,导致后台异步合并数据出现问题,也避免跨度过大
解决方案:单批次写入数据,要控制写入分区过多
参数:max_partitions_per_insert_block 限制单个插入块中的最大分区数,默认是100
相关文章:
学习(mianshi)必备-ClickHouse高性能查询/写入和常见注意事项(五)
目录 一、ClickHouse高性能查询原因-稀疏索引 二、ClickHouse高性能写入-LSM-Tree存储结构 什么是LSM-Tree 三、ClickHouse的常见注意事项和异常问题排查 一、ClickHouse高性能查询原因-稀疏索引 密集索引: 在密集索引中,数据库中的每个键值都有一个索引记录&…...
在Kotlin中探索 Activity Results API 极简的解决方案
Activity Results APIActivity Result API提供了用于注册结果、启动结果以及在系统分派结果后对其进行处理的组件。—Google官方文档https://developer.android.google.cn/training/basics/intents/result?hlzh-cn一句话解释:官方Jetpack组件用于代替startActivity…...

样式冲突太多,记一次前端CSS升级
目前平台前端使用的是原生CSSBEM命名,在多人协作的模式下,容易出现样式冲突。为了减少这一类的问题,提升研效,我调研了业界上主流的7种CSS解决方案,并将最终升级方案落地到了工程中。 样式冲突的原因 目前遇到的样式…...

如何解决报考PMP的那些问题?
关于PMP的报考条件,报考PMP都需要什么条件呢?【学历条件】:需要满足23周岁/高中毕业5年以上/大专以上学历,三个满足一个即可;【PDU条件】:报考PMP需要PDU证明(学习项目管理课程的学时证明&#…...
数据结构栈的经典OJ题【leetcode最小栈问题大剖析】【leetcode有效的括号问题大剖析】
目录 0.前言 1.最小栈 1.1 原题展示 1.2 思路分析 1.2.1 场景引入 1.2.2 思路 1.3 代码实现 1.3.1 最小栈的删除 1.3.2 最小栈的插入 1.3.3 获取栈顶元素 1.3.4 获取当前栈的最小值 2. 有效的括号 0.前言 本篇博客已经把两个关于栈的OJ题分块,可以根据目…...
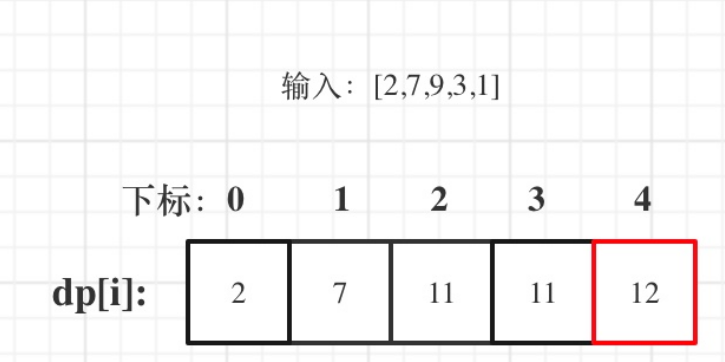
数据结构与算法之打家劫舍(一)动态规划思想
动态规划里面一部题目打家劫舍是一类经典的算法题目之一,他有各种各样的变式,这一篇文章和大家分享一下打家劫舍最基础的一道题目,掌握这一道题目,为下一道题目打下基础。我们直接进入正题。一.题目大家如果刚接触这样的题目&…...

无人驾驶路径规划论文简要
A Review of Motion Planning Techniques for Automated Vehicles综述和分类0Motion Planning for Autonomous Driving with a Conformal Spatiotemporal Lattice从unstructured环境向structured环境的拓展,同时还从state lattice拓展到了spatiotemporal lattice从而…...
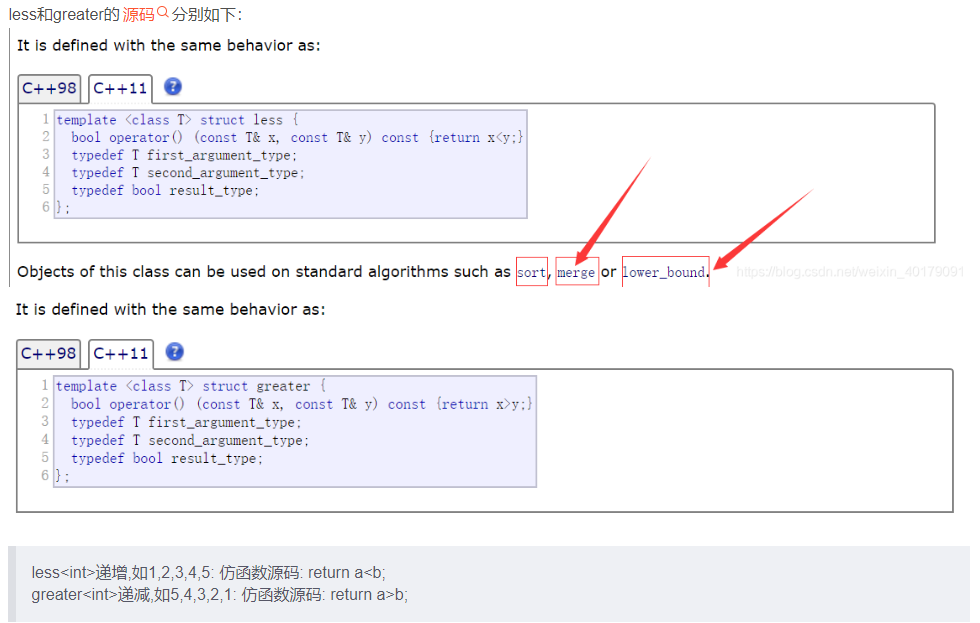
C++ sort()函数和priority_queue容器中比较函数的区别
普通的queue是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除。priority_queue中元素被赋予优先级。在创建的时候根据优先级进行了按照从大到小或者从小到大进行了自动排列(大顶堆or小顶堆)。可以以O(log n) 的效率查找…...
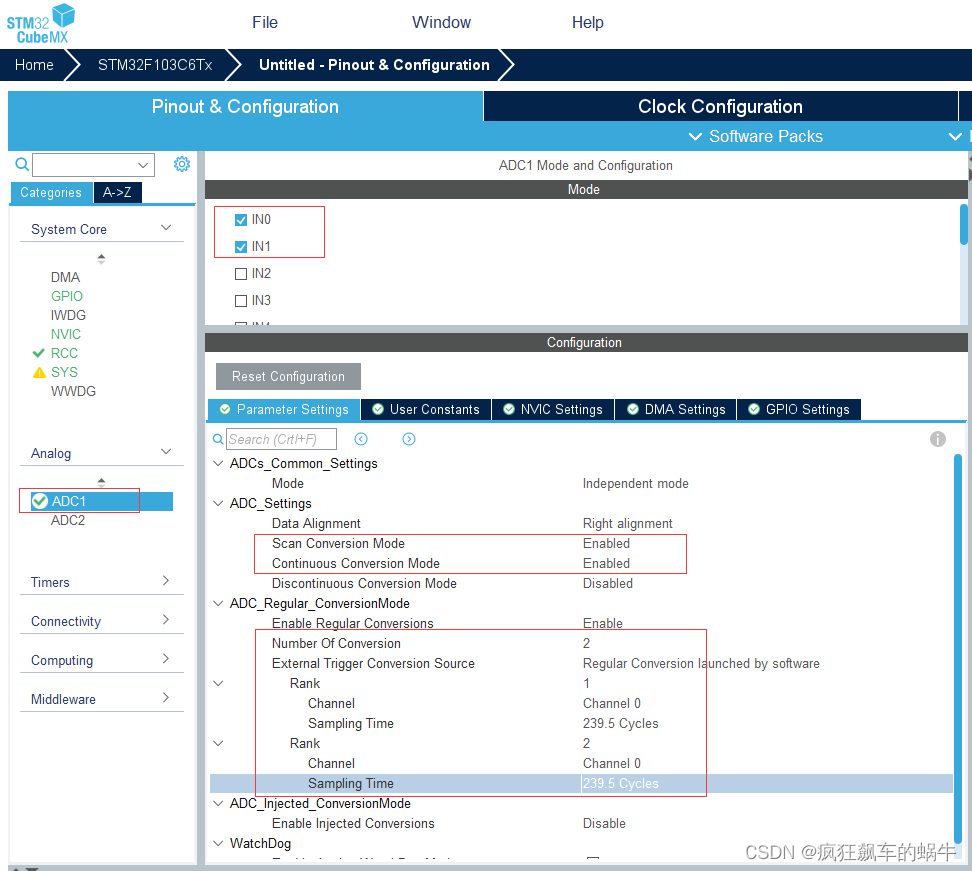
STM32开发(14)----CubeMX配置ADC
CubeMX配置ADC前言一、什么是ADC?二、实验过程1.单通道ADC采集STM32CubeMX配置代码实现2.多通道ADC采样(非DMA)STM32CubeMX配置代码实现3.多通道ADC采样(DMA)STM32CubeMX配置代码实现总结前言 本章介绍使用STM32CubeMX对ADC进行配置的方法&a…...
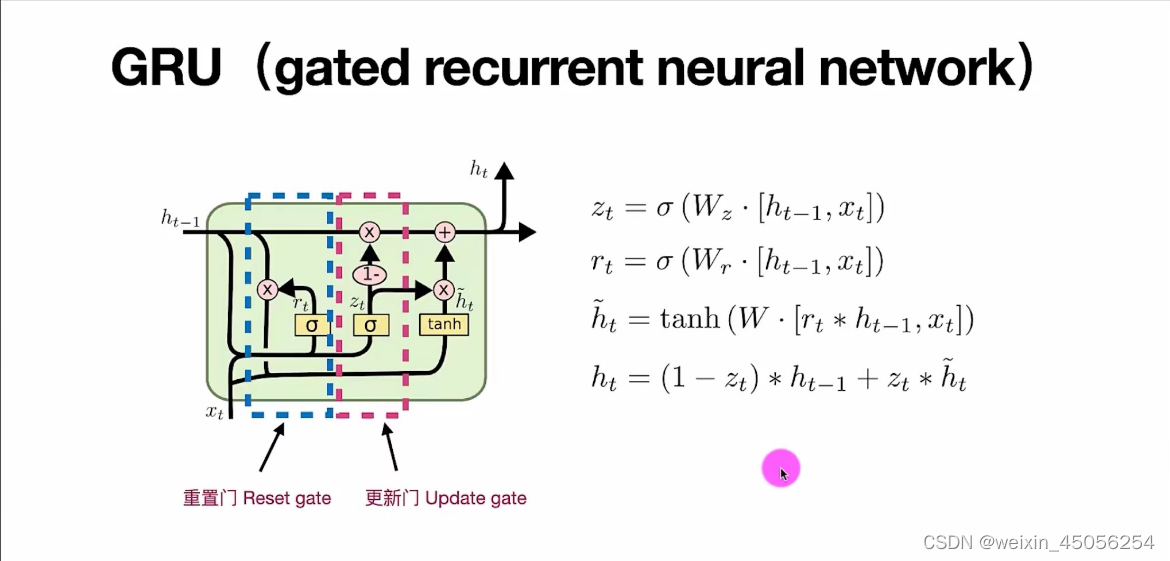
Simple RNN、LSTM、GRU序列模型原理
一。循环神经网络RNN 用于处理序列数据的神经网络就叫循环神经网络。序列数据说直白点就是随时间变化的数据,循环神经网络它能够根据这种数据推出下文结果。RNN是通过嵌含前一时刻的状态信息实行训练的。 RNN神经网络有3个变种,分别为Simple RNN、LSTM、…...
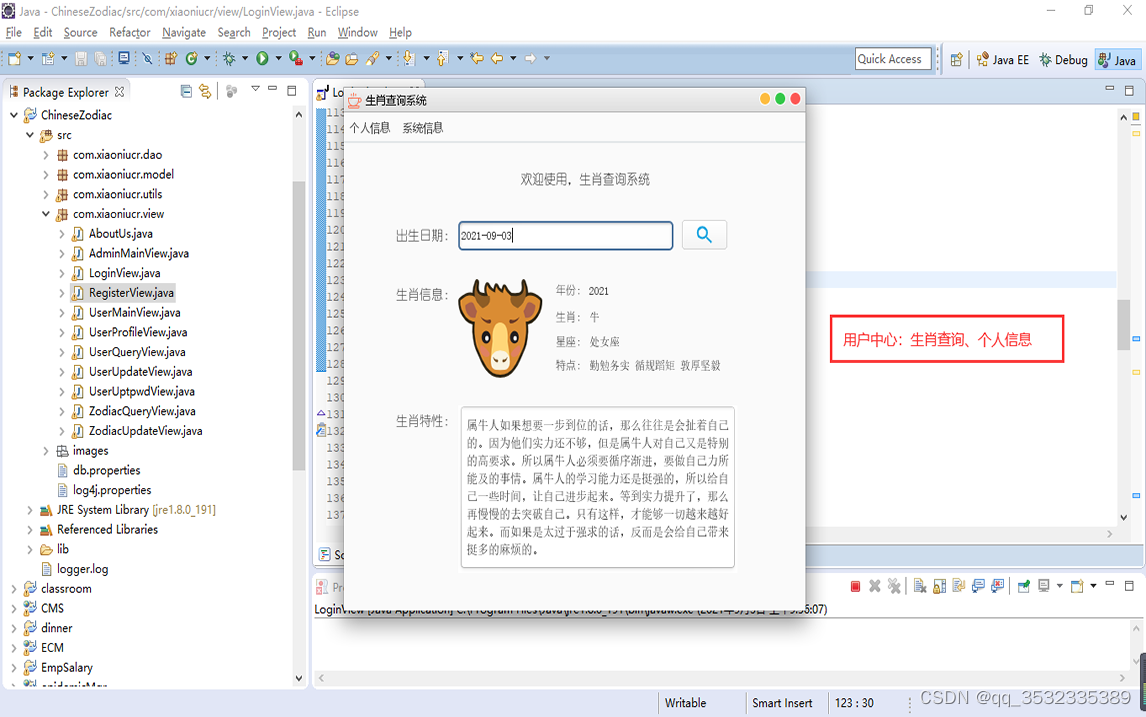
【原创】java+swing+mysql生肖星座查询系统设计与实现
今天我们来开发一个比较有趣的系统,根据生日查询生肖星座,输入生日,系统根据这个日期自动计算出生肖和星座信息反馈到界面。我们还是使用javaswingmysql去实现这样的一个系统。 功能分析: 生肖星座查询系统,顾名思义…...

CentOS 环境 OpneSIPS 3.1 版本安装及使用
文章目录1. OpenSIPS 源码下载2. 工具准备3. 编译安装4. opensips-cli 工具安装5. 启动 OpenSIPS 实例1. OpenSIPS 源码下载 使用以下命令即可下载 OpenSIPS 的源码,笔者下载的是比较稳定的 3.1 版本,读者有兴趣也可前往 官方传送门 sudo git clone htt…...

SQL95 从 Products 表中检索所有的产品名称以及对应的销售总数
描述 Products 表中检索所有的产品名称:prod_name、产品id:prod_idprod_idprod_namea0001egga0002socketsa0013coffeea0003colaOrderItems代表订单商品表,订单产品:prod_id、售出数量:quantityprod_idquantitya0001105…...

平时技术积累很少,面试时又会问很多这个难题怎么破?别慌,没事看看这份Java面试指南,解决你的小烦恼!
前言技术面试是每个程序员都需要去经历的事情,随着行业的发展,新技术的不断迭代,技术面试的难度也越来越高,但是对于大多数程序员来说,工作的主要内容只是去实现各种业务逻辑,涉及的技术难度并不高…...

SQL Server 数据库的备份
为何要备份数据库? 备份 SQL Server 数据库、在备份上运行测试还原过程以及在另一个安全位置存储备份副本可防止可能的灾难性数据丢失。 备份是保护数据的唯一方法 。 使用有效的数据库备份,可从多种故障中恢复数据,例如: 介质…...

NCNN Conv量化详解1
1. NCNN的Conv量化计算流程 正常的fp32计算中,一个Conv的计算流程如下: 在NCNN Conv进行Int8计算时,计算流程如下: NCNN首先将输入(bottom_blob)和权重(weight_blob)量化成INT8,在INT8下计算卷积,然后反量化到fp32,再和未量化的bias相加,得到输出(top_blob) 输入和…...
Redis大key多key拆分方案
业务场景中经常会有各种大key多key的情况, 比如:1:单个简单的key存储的value很大2:hash, set,zset,list 中存储过多的元素(以万为单位)3:一个集群存储了上亿的…...

python的类如何使用?兔c同学一篇关于python类的博文概述
本章内容如目录 所示: 文章目录1. 创建和使用类1.1 创建第一个python 类1.2 版本差异1.3 根据类创建实例1. 访问属性2. 调用方法3. 创建多个实例2. 使用类和实例2.1 给属性指定默认值2.2 修改属性的值3. 继承3.1 子类的 __init __()3.2 给子类定义属性和方法3.3 重写…...

Day60 动态规划总结
647. 回文子串 回文的做法注定我们得从里面入手,逐渐扩散到边界 初始化:准备一个ans,找到一个回文子串加一个 dp [[0] * n for _ in range(n)]ans 0 遍历公式: 当s[i]s[j]的时候,只要里面还是回文串,就能…...
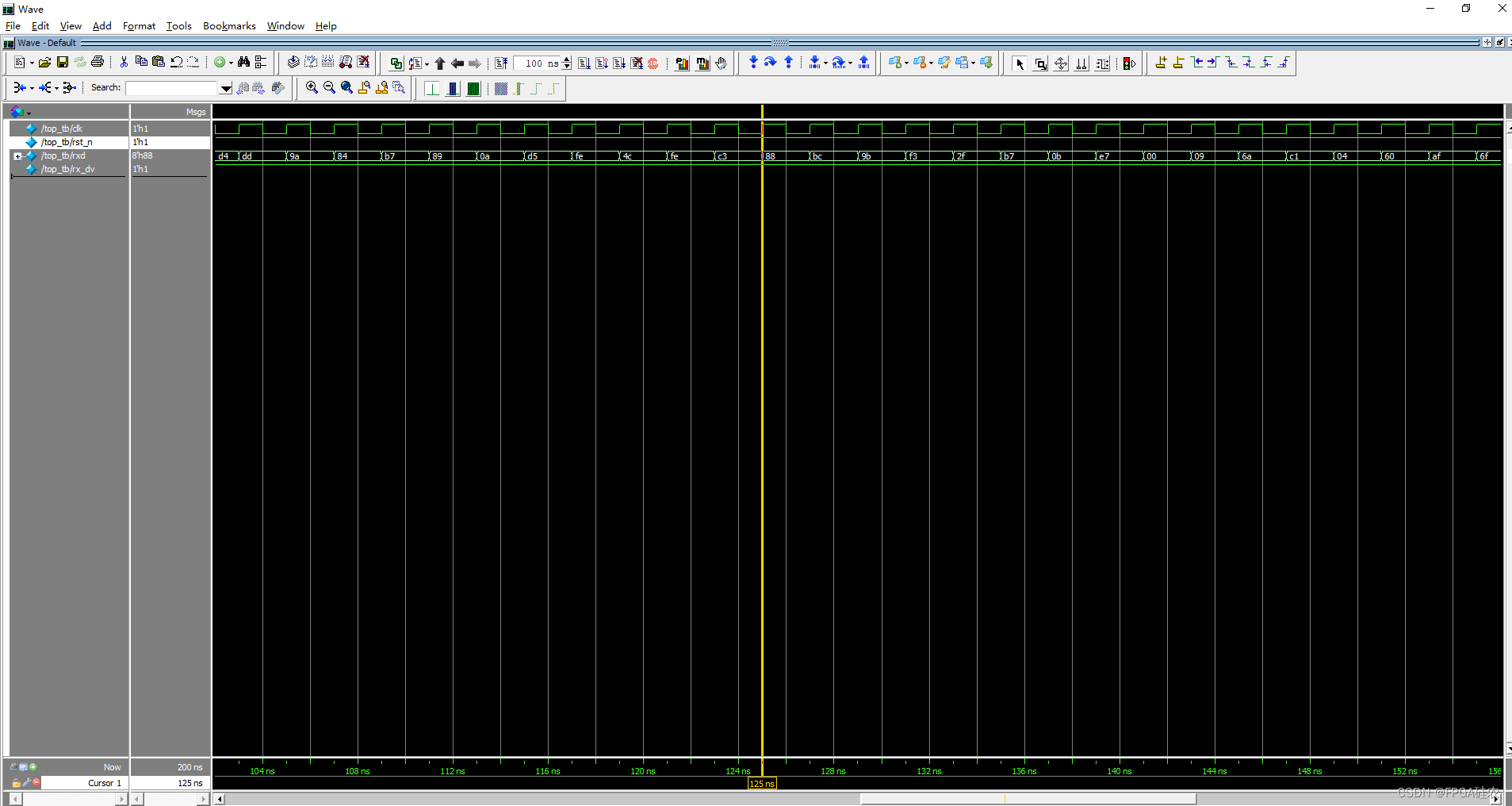
UVM仿真环境搭建
环境 本实验使用环境为: Win10平台下的Modelsim SE-64 2019.2 代码 dut代码: module dut(clk,rst_n, rxd,rx_dv,txd,tx_en); input clk; input rst_n; input[7:0] rxd; input rx_dv; output [7:0] txd; output tx_en;reg[7:0] txd; reg tx_en;always…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

NFT模式:数字资产确权与链游经济系统构建
NFT模式:数字资产确权与链游经济系统构建 ——从技术架构到可持续生态的范式革命 一、确权技术革新:构建可信数字资产基石 1. 区块链底层架构的进化 跨链互操作协议:基于LayerZero协议实现以太坊、Solana等公链资产互通,通过零知…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

如何在Windows本机安装Python并确保与Python.NET兼容
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南
在RK3588上搭建ROS1环境:创建节点与数据可视化实战指南 背景介绍完整操作步骤1. 创建Docker容器环境2. 验证GUI显示功能3. 安装ROS Noetic4. 配置环境变量5. 创建ROS节点(小球运动模拟)6. 配置RVIZ默认视图7. 创建启动脚本8. 运行可视化系统效果展示与交互技术解析ROS节点通…...

大数据治理的常见方式
大数据治理的常见方式 大数据治理是确保数据质量、安全性和可用性的系统性方法,以下是几种常见的治理方式: 1. 数据质量管理 核心方法: 数据校验:建立数据校验规则(格式、范围、一致性等)数据清洗&…...

对象回调初步研究
_OBJECT_TYPE结构分析 在介绍什么是对象回调前,首先要熟悉下结构 以我们上篇线程回调介绍过的导出的PsProcessType 结构为例,用_OBJECT_TYPE这个结构来解析它,0x80处就是今天要介绍的回调链表,但是先不着急,先把目光…...

CTF show 数学不及格
拿到题目先查一下壳,看一下信息 发现是一个ELF文件,64位的 用IDA Pro 64 打开这个文件 然后点击F5进行伪代码转换 可以看到有五个if判断,第一个argc ! 5这个判断并没有起太大作用,主要是下面四个if判断 根据题目…...

MeshGPT 笔记
[2311.15475] MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers https://library.scholarcy.com/try 真正意义上的AI生成三维模型MESHGPT来袭!_哔哩哔哩_bilibili GitHub - lucidrains/meshgpt-pytorch: Implementation of MeshGPT, SOTA Me…...