Elasticsearch基本概念和索引原理
一、Elasticsearch是什么?
Elasticsearch是一个基于文档的NoSQL数据库,是一个分布式、RESTful风格的搜索和数据分析引擎,同时也是Elastic Stack的核心,集中存储数据。Elasticsearch、Logstash、Kibana经常被用作日志分析系统,俗称ELK。
说白了,就是一个数据库,搜索贼快(但是插入更新较慢,要不然其他数据库别玩了)。速度快,还可以进行分词,非常适合做搜索,例如商城的商品搜索。为什么快,后面讲原理的时候会说,不单单是缓存的问题,原理非常精彩。而且它是nosql的,数据格式可以随便造。Elasticsearch还为我们提供了丰富的RESTful风格的API,写代码的成本极低。最后它支持分布式,高性能(搜索快),高可用(某些节点宕机可以接着用),可伸缩(可以方便的增加节点,解决物理内存上线问题),适合分布式系统开发。
优势:
-
分布式的实时文件存储,每个字段都被索引并可被搜索
-
实时分析的分布式搜索引擎
-
横向可扩展:支持上百台服务节点的扩展,集群增加机器简单,支持处理PB级数据
-
分片机制:
允许水平分割扩展数据,允许分片和并行操作从而提高性能和吞吐量
提供高性能:同一个索引可以分多个主分片(
primary shard),每个主分片拥有自己的副本分片(replica shard),每个副本分片都可以提供服务,提升系统搜索请求的吞吐量和性能提供高可用性:同一个索引可以分多个主分片,每个主分片拥有零个或者多个副本,如果主分片挂了,可以从副本分片中选择一个作为主分片继续提供服务
-
隐藏复杂实现:Elasticsearch 内部隐藏了分布式系统的复杂性,我们不用去关心它是如何做到高可用,可扩展,高性能的
-
易用开源:不需要额外配置,就可以运行一个Elasticsearch服务,开源
二、基本概念
为了快速了解Elasticsearch(后面可能会简称为ES),可以与mysql几个概念做个对比。
| Elasticsearch | Mysql |
|---|---|
| 字段(Filed) | 属性(列) |
| 文档(Document) | 记录(行) |
| 类型(Type) | 表 |
| 索引(Index) | 数据库 |
1、Cluster:集群
一个集群包含多个节点,对外提供服务,每个节点属于哪个集群通过配置文件中的集群名称决定
2、Node:节点
集群中的一个节点,每个节点也有一个名称,默认是随机分配,也可以自己指定,在es集群中通过节点名称进行管理和通信。
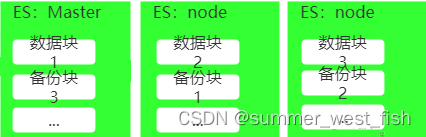
由于生产环境下ES基本都是集群部署的,所以一定少不了节点的概念,一个节点就是一个ES实例,就是一个Java进程,这些Java进程部署在不同的服务器上,增加ES可用性。
ES节点根据功能可以分为三种:
- 主节点:职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。每个节点都可访问集群的状态,但是只有主节点可以修改集群的状态。
- 数据节点:数据节点主要是储存数据的节点,对文档进行增删改查,聚合操作等等,数据节点对cpu,内存,io要求较高,当资源不够的时候,可以增加新的节点,很方便的进行数据拓展。
- 客户端节点:本节点主要处理路由请求,分发索引的操作。实际上主节点和数据节点也有路由转发的功能,但是为了提高效率,还是建议生产环境单独创建客户端节点。
分片类似于mysql中的分表,在一个索引拆分成几个小索引,分布在不同的节点(不同服务器)上,每个小索引都具有完备的功能,当客户端发来请求的时候,客户端节点找到合适的分片上的小索引,进行数据查询,这一过程对于用户来说都是透明的,用户表面上看只是在操作一个索引。利用分片,可以避免单个节点的物理限制,还可以增加吞吐量。建议最开始一个索引要用多少分片设计好,因为修改分片数量是个相当麻烦的过程。
作为分布式的数据库,ES必须为咱们提供数据冗余功能,这就是分片副本,就是将某个分片copy一份放到其他节点上。注意,这里分片和分片副本 **必须在不同的节点上!** 分片副本也可以提高吞吐量。分片副本不同于分片,可以很方便的进行修改。
说完了所有概念,再去看上面的图,有一个索引,分了3分片在三个节点上,并且每个分片在不同的节点上有分片副本。
3、Index:索引
索引是具有相同结构的文档集合,作用相当于mysql中的库。
ES中的索引类似于mysql中的数据库,我觉得未来索引有成为mysql中表概念的潜质。
我们把相同特征(Filed数量和类型基本相同)的文档放到同一个索引(index)里面。这样方便提前通过mapping来规定各个Filed的类型。另外,索引名称必须全部小写,所以不建议写成驼峰式。
4、Type:类型
一个索引可以对应一个或者多个类型,类型可以当做是索引的逻辑分区,作用相当于mysql中的表。
关于Type,类型概念,在6.x版本中,一个索引(Index)可以拥有多个Type。在7.x版本(目前最新版本),一个索引只能拥有一个Type,默认的type就是_doc,在7.x版本中,已经建议删除了。在未来的8.x版本会彻底删除。但是在7.x版本中,一个文档还必须归属于一个类型。
5、Document:文档
存储在es中的一个JSON格式的字符串,每一个文档有一个文档ID,如果没有自己指定ID,系统会自动生成一个ID,文档的index/type/id必须是唯一的,作用相当于mysql中的行。
ES中的一个对象将来会和Java代码中的一个对象对应。文档的每一个Filed可以是任意类型,但是一旦某索引(Index)(我们描述的时候,略过Type,但是Type依然存在)中插入了一个文档,某Filed被第一次使用,ES就会设置好此Filed的类型。
例如:你插入user的name是字符串类型,以后再插入文档,name字段必须是字符串类型。所以,建议在插入文档之前,先设置好每个Filed的类型。
如果插入文档的时候,不指定id,ES会帮助我们自动生成一个id,建议id是数字类型,这样搜索会快速很多。商城系统中的商品id建议使用雪花算法生成,这样既避免了自增id的安全性问题,又解决了字符串id检索慢的问题。
6、field:字段
一个文档会包含多个字段,每个字段都对应一个字段类型,类似于mysql中的列。
7、shard:分片
es中分为primary shard主分片和replica shard副本分片。
主分片:当存一个文档的时候会先存储在主分片中,然后复制到不同的副本分片中,默认一个索引会有5个主分片,当然可以自己指定分片数量,当分片一旦建立,分片数量不能改变副本分片:每一个主分片会有零个或者多个副本,副本主要是主分片的复制,通过副本分片可以提供高可用性,当一个主分片挂了,可以从副本分片中选择一个作为主分片,还可以提高性能,所以主分片不能和副本分片部署在相同的节点上。
8、replica:复制
复制是为了防止单点问题,可以做到对故障进行转移,保证系统的高可用。
9、映射
描述数据在每个字段内如何存储,是定义存储和索引的文档类型及字段的过程,索引中的每一个文档都有一个类型,每种类型都有它自己的映射,一个映射定义了文档结构内每个字段的数据类型。
使用GET /index/_mapping/type获取对应的/index/type的映射信息
三、Elasticsearch索引原理
首先,我们知道mysql底层数据结构使用的是B+Tree,这种BTree,将搜索时间复杂度变成了logN,已经很快了,我们Elasticsearch要比它还快。Elasticsearch是怎么做的呢?首先储存结构要优化,然后再提高下和磁盘的交互效率。
先说Elasticsearch索引结构,叫做倒排索引,啥是倒排索引呢?它的大概逻辑如下:

为了讲清楚这个概念,我们先看个例子,如下为我们user的数据:
| ID | Name | Age |
|---|---|---|
| 1 | Kate | 24 |
| 2 | John | 24 |
| 3 | Bill | 29 |
| 4 | Kate | 26 |
| 5 | Brand | 29 |
Elasticsearch会为以上数据建立两个索引树:
| Term | Posting List |
|---|---|
| Kate | 1,4 |
| Brand | 5 |
| John | 2 |
| Bill | 3 |
| Term | Posting List |
|---|---|
| 24 | 1,2 |
| 26 | 4 |
| 29 | 3,5 |
以上的索引树就叫做倒排索引,每个Filed字段对应着一组Term,每个Term后面跟着的id(这个主键用户不指定就会自动生成,所以一定存在)就是Posting List,它是一组id,有了id再去磁盘中对应的文档就so fast了。
你有没有发现,Term如果按序找会快点,将Term按序排,在进行二分查找,是不是速度就跟BTree一样了,时间复杂度为LogN。这个有序的Term组就是Term Dictionary。
那么问题又来了,比如:数据库中有name前缀为A的同学1000万个,前缀为Z的同学有3个,我要查前缀为Z的同学,那二分查找不也很多次吗,所以,Elasticsearch把每个开头的地方标记一下,拿出来,再放到一颗树里,速度不是就快了嘛,这棵树就是Term Index。Term Index前缀不一定是第一个字符,比如A、Ab、Abz,这种都可以在Term Index树里。并且Term Dictionary可能会太大,会被放到磁盘中,避免内存占用太多。
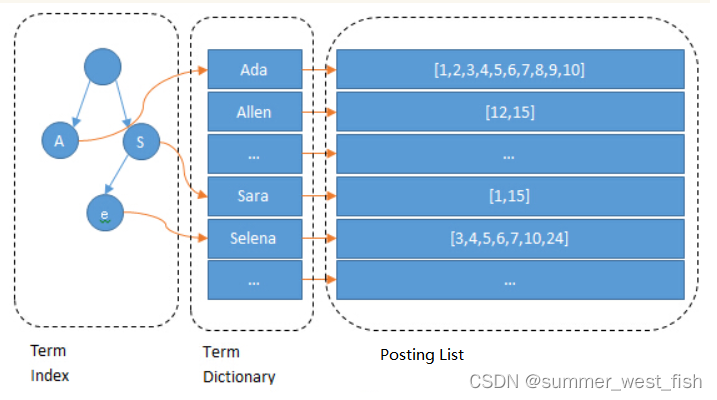
由于Term Index被放到内存中,所以最好压缩一下,减少内存使用,压缩使用的是FST,这个东西讲起来比较复杂,反正就是能压缩,内存变小就好了。
Term压缩完了,那么Posting List是不是也可以压缩一下,省省空间啊?既然都是id,使用过redis的同学瞬间会想到bitMap,就是有个巨大的数组,储存着0或1,有就是1,没有就是0。例如上面的3、5放在BitMap中就是 1,0,1,0,0,0。虽说空间已经明显小多了,但是如果一个Posting List只储存着1,10000001这两个id,最后产生的数字是不是过大呢。于是乎,Roaring bitmaps就出来了,进行了一次指数降级,简单点说就是取商和余数储存,被除数是65535。
例如:1000,62101,131385,196658, 这几个id,首先分组,分组规则就是商一样,例如上面id可分组为[(0,1000),(0,62101)],[],[(2,6915)],[(3,53)]。注意,没有商为1的值,我用空数组表示。此时,将某个组中的数字放到一个bitmap中。
相关文章:
Elasticsearch基本概念和索引原理
一、Elasticsearch是什么? Elasticsearch是一个基于文档的NoSQL数据库,是一个分布式、RESTful风格的搜索和数据分析引擎,同时也是Elastic Stack的核心,集中存储数据。Elasticsearch、Logstash、Kibana经常被用作日志分析系统&…...

《NFL橄榄球》:堪萨斯城酋长·橄榄1号位
堪萨斯城酋长队(Kansas City Chiefs)是位于密苏里州堪萨斯城的职业美式橄榄球队;目前在全国橄榄球联盟隶属于美国橄榄球联合会(AFC)西区;其夏季训练营在威斯康星大学河瀑校区举行。 酋长队的前身是达拉斯得州佬队,这支…...
python+django在线教学网上授课系统vue
随着科技的进步,互联网已经开始慢慢渗透到我们的生活和学习中,并且在各个领域占据着越来越重要的部分,很多传统的行业都将面临着巨大的挑战,包括学习也不例外。现在学习竞争越来越激烈,人才的需求量越来越大࿰…...
二叉搜索树之AVL树
AVL树的概念二叉搜索树虽可以缩短查找的效率,但如果数据有序或接近有序二叉搜索树将退化为单支树,查找元素相当于在顺序表中搜索元素,效率低下。因此,两位俄罗斯的数学家G.M.Adelson-Velskii和E.M.Landis在1962年 发明了一种解决上…...

全栈自动化测试技术笔记(二):准备工作的切入点
自动化测试技术笔记(二):准备工作的切入点 上篇整理的技术笔记,聊了自动化测试的前期调研工作如何开展,最后一部分也提到了工作的优先级区分。 这篇文章,接上篇文章的内容,来聊聊自动化测试前期的准备工作࿰…...
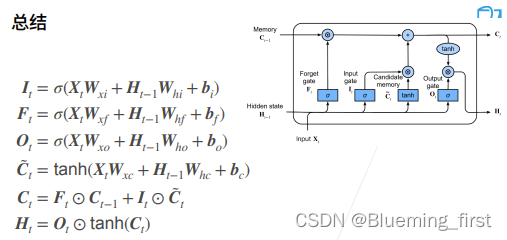
57 长短期记忆网络(LSTM)【动手学深度学习v2】
57 长短期记忆网络(LSTM)【动手学深度学习v2】 深度学习学习笔记 学习视频:https://www.bilibili.com/video/BV1JU4y1H7PC/?spm_id_fromautoNext&vd_source75dce036dc8244310435eaf03de4e330 长短期记忆网络(LSTM)…...
算法第十五期——动态规划(DP)之各种背包问题
目录 0、背包问题分类 1、 0/1背包简化版 【代码】 2、0/ 1背包的方案数 【思路】 【做法】 【代码】 空间优化1:交替滚动 空间优化2:自我滚动 3、完全背包 【思路】 【代码】 4、分组背包 核心代码 5、多重背包 多重背包解题思路1:转化…...
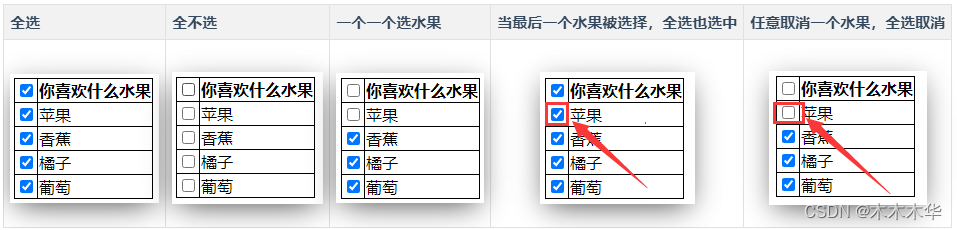
实现复选框全选和全不选的切换
今天,复看了一下JS的菜鸟教程,发现评论里面都是精华呀!! 看到函数这一节,发现就复选框的全选和全不选功能展开了讨论。我感觉挺有意思的,尝试实现了一下。 1. 全选、全不选,两个按钮ÿ…...
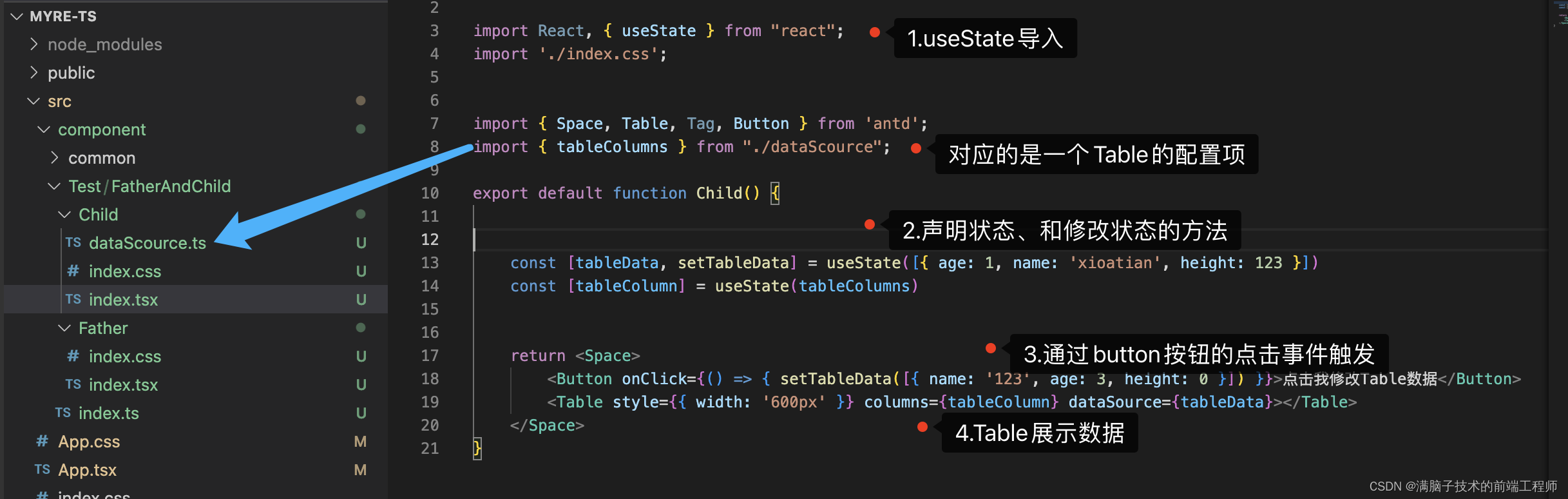
React hooks之useState用法(一)
系列文章目录 学习React已经有很长的一段时间了,今天决定重新回顾一下跟React相关的一些知识点 文章目录系列文章目录结构如下一、hooks是什么?useState可以能做什么二、如何使用useState()第一步:创建【函数组件&…...
spring的简单理解
目录 1 .ioc容器(控制反转) 2. Aop面向切面编程 3. 事务申明 4. 注解的方式启动 5. spring是什么与他的优势 6. 代理设计模式(比如aop) 7. springmvc中相应json数据 8. 使用lombok来进行对代码的简化 9. 使用logback记录…...
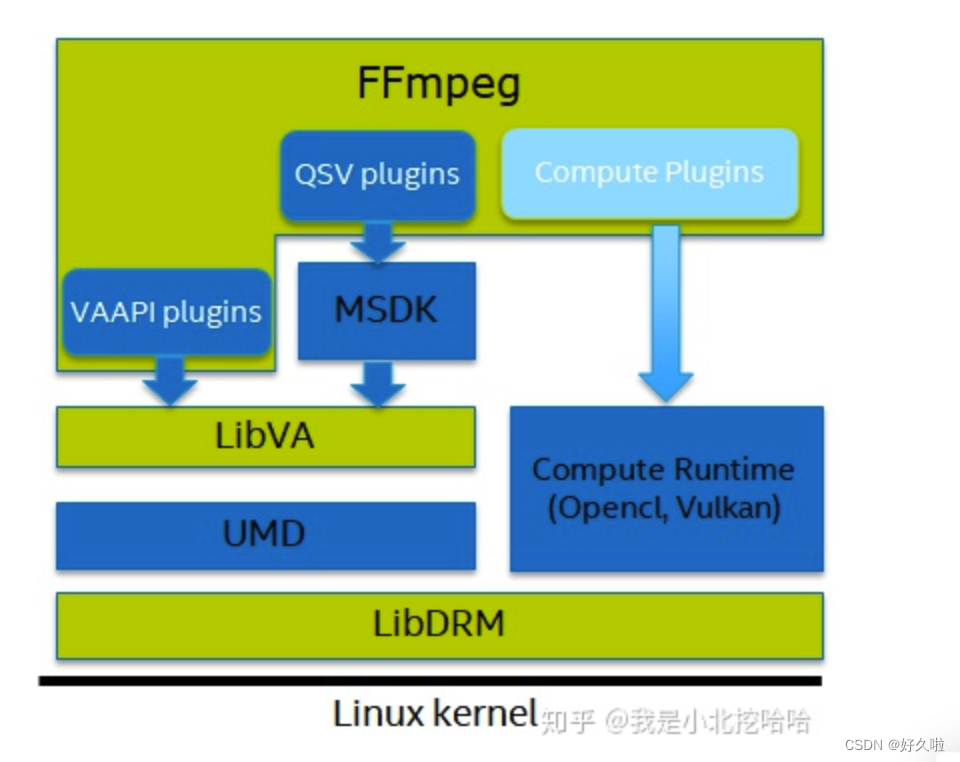
Docker调用Intel集显实现FFmpeg硬解码
文章目录Docker调用Intel集显实现FFmpeg硬解码参考FFmpeg 集成qsv方式一 容器完成所有步骤方式二 容器完成部分步骤方式三 dockerfile部署Docker调用Intel集显实现FFmpeg硬解码 参考 ffmpeg_qsv_docker拉取该镜像可以实现FFmpeg集成vaapi的硬加速,通过dockerfile文…...

端到端模型(end-to-end)与非端到端模型
一、端到端(end to end) 从输入端到输出端会得到一个预测结果,将预测结果和真实结果进行比较得到误差,将误差反向传播到网络的各个层之中,调整网络的权重和参数直到模型收敛或者达到预期的效果为止,中间所…...
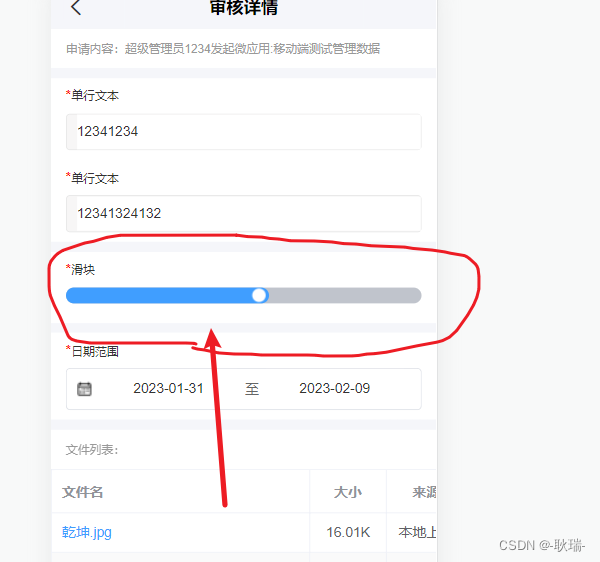
uniApp封装一个滑块组件
最近 项目中有一个需求 PC端动态设计的表单 移动端要能渲染出来 那么 就要去找到对应的组件 而其中 没有的 就包括滑块 没有又能怎么办 只能自己封装一个 我们直接上代码 <template><view class"u-slider" tap"onClick" :class"[disabled…...

运动基元(二):贝塞尔曲线
贝塞尔曲线是我第一个深入接触并使用于路径规划的运动基元。N阶贝塞尔曲线具有很多优良的特性,例如端点性、N阶可导性、对称性、曲率连续性、凸包性、几何不变性、仿射不变性以及变差缩减性。本章主要介绍贝塞尔曲线用于运动基元时几个特别有用的特性。 一、贝塞尔曲线的定义 …...

Android 11.0 关于Launcher3中调用截图功能总是返回null的解决方案
1.1概述 在11.0的系统产品开发中,在某些时候需要调用截图接口来进行截屏功能实现,而在Launcher3中发现调用系统截屏接口SurfaceControl.screenshot进行截图的时候始终为null, 获取不到系统当前页面的截屏功能,所以需要找到当前截屏失败的原因然后来实现截屏功能的实现,下面来…...

random随机数
random随机数 1.概述 random用来生成一些随机数,下面介绍random模块提供的方法根据需求生成不同的随机数。 2.random常用操作 2.1.random默认随机数 random()函数返回一个随机的浮点值,默认返回值范围在0 < n < 1.0区间 import randomfor i …...
【金三银四系列】Spring面试题-上(2023版)
Spring面试专题 1.Spring应该很熟悉吧?来介绍下你的Spring的理解 有些同学可能会抢答,不熟悉!!! 好了,不开玩笑,面对这个问题我们应该怎么来回答呢?我们给大家梳理这个几个维度来回答 1.1 Spring的发展历程 先介绍…...

linux基本功系列之tar命令实战
文章目录前言一. tar命令介绍二. 语法格式及常用选项三. 参考案例3.1 仅打包不压缩3.2 打包后使用调用压缩命令进行压缩3.3 列出文件的内容3.4 追加文件到tar命令中3.5 释放文件到指定的目录四 . 各种压缩方式的比较总结前言 大家好,又见面了,我是沐风晓…...
Prometheus服务发现
Prometheus服务发现介绍 Prometheus默认是采用pull的方式拉取监控数据的,每一个被抓取的目标都要暴露一个HTTP接口,prometheus通过这个接口来获取相应的指标数据,这种方式需要由prometheus-server决定采集的目标服务器有哪些,通过…...
【Spring6源码・MVC】请求处理流程源码解析
上一篇《【Spring6源码・MVC】初始化registry,完成url和controller的映射关系》我们知道,在IOC容器加载的同时,初始化了registry这个HashMap,这个HashMap中存放了请求路径和对应的方法。当我们请求进来,会通过这个regi…...
结构体的进阶应用)
基于算法竞赛的c++编程(28)结构体的进阶应用
结构体的嵌套与复杂数据组织 在C中,结构体可以嵌套使用,形成更复杂的数据结构。例如,可以通过嵌套结构体描述多层级数据关系: struct Address {string city;string street;int zipCode; };struct Employee {string name;int id;…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...