【C语言数据结构——————排序(1万字)】
文章目录
- 排序的概念
- 常见排序算法
- 分类
- 冒泡排序
- 时间复杂度
- 稳定性
- 原理
- 实现
- 插入排序
- 时间复杂度
- 稳定性
- 实现
- 选择排序
- 时间复杂度
- 稳定性
- 实现
- 希尔排序
- 时间复杂度
- 稳定性
- 希尔排序的算法思想
- 实现
- 优化
- 快速排序
- 时间复杂度
- 空间复杂度
- 稳定性
- 实现
- 三数取中优化
- 归并排序
- 时间复杂度
- 空间复杂度
- 稳定性
- 实现
- 递归实现归并排序
- 堆排序
- 时间复杂度
- 实现
- 大顶堆和小顶堆的介绍
- 向上调整算法
- 向下调整算法
- 计数排序
- 时间复杂度
- 空间复杂度
- 稳定性
- 实现
- 总结

欢迎阅读新一期的c语言数据结构模块————排序
✒️个人主页:-_Joker_-
🏷️专栏:C语言数据结构
📜代码仓库:c_code
🌹🌹欢迎大佬们的阅读和三连关注,顺着评论回访🌹🌹
排序的概念
排序是计算机内经常进行的一种操作,其目的是将一组“无序”的记录序列调整为“有序”的记录序列。将杂乱无章的数据元素,通过一定的方法按关键字顺序排列的过程叫做排序。
常见排序算法
快速排序、希尔排序、堆排序、直接选择排序、基数排序、计数排序、冒泡排序、插入排序、归并排序等。
分类
◆稳定排序:假设在待排序的文件中,存在两个或两个以上的记录具有相同的关键字,在
用某种排序法排序后,若这些相同关键字的元素的相对次序仍然不变,则这种排序方法
是稳定的。其中冒泡排序,插入排序,基数排序,归并排序、基数排序都属于稳定排序。
◆就地排序:若排序算法所需的辅助空间并不依赖于问题的规模n,即辅助空间为O(1)
◆不稳定排序:假设在待排序的文件中,存在两个或两个以上的记录具有相同的关键字,在
用某种排序法排序后,若这些相同关键字的元素的相对次序仍然不变,则这种排序方法
是不稳定的,其中选择排序,快速排序,希尔排序,堆排序都属于不稳定排序。
冒泡排序
冒泡排序是我们学习编程接触的第一个排序方式,它的优点是比较稳定,而且比较容易掌握。作为我们第一个接触到排序,它的缺点也非常明显,它的时间复杂度是O(n²),这就导致冒泡排序会非常慢,并不适用于排序,只适合用于教学,是一个具有教学意义的启蒙排序方式。
时间复杂度
冒泡排序的时间复杂度为O(n²)
稳定性
由于冒泡排序并没有改变元素的相对次序,所以冒泡排序是一个稳定的排序
原理
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较
冒泡排序的实现:
冒泡排序的算法思路主要就是两层嵌套的循环语句。外层循环控制第1到第 n-1 趟排序,而内层循环则控制每一趟排序中对前面未排好序的元素进行比较和交换。
#include<stdio.h>int main()
{int a[6]={20,40,10,5,50,30};int i = 0;for(j=0;j<5;j++)//外部总共要遍历n-1次(n为元素个数){for(i=0;i<5-j;i++)//每一次将最大值放在最后,前面的数比较次数-1,只需要和最大值前面的元素比较{if(a[i]>a[i+1])//比较相邻两者大小关系,如果前面元素大则需要改变位置{trmp = a[i];//通过中间量交换两者位置a[i]=a[i+1];a[i+1]=temp;}}}return 0;
}
插入排序
插入排序是指在待排序的元素中,假设前面n-1(其中n>=2)个数已经是排好顺序的,现将第n个数插到前面已经排好的序列中,然后找到合适自己的位置,使得插入第n个数的这个序列也是排好顺序的。按照此法对所有元素进行插入,直到整个序列排为有序的过程,称为插入排序 。
时间复杂度
在插入排序中,当待排序数组是有序时,是最优的情况,只需当前数跟前一个数比较一下就可以了,这时一共需要比较N- 1次,时间复杂度为O(N)。
最坏的情况是待排序数组是逆序的,此时需要比较次数最多,总次数记为:1+2+3+…+N-1,所以,插入排序最坏情况下的时间复杂度为O(N²)。
稳定性
如果待排序的序列中存在两个或两个以上具有相同关键词的数据,排序后这些数据的相对次序保持不变,即它们的位置保持不变,通俗地讲,就是两个相同的数的相对顺序不会发生改变,则该算法是稳定的;如果排序后,数据的相对次序发生了变化,则该算法是不稳定的。关键词相同的数据元素将保持原有位置不变,所以该算法是稳定的 。
实现
void InsertSort(int* a, int n)
{for (int i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];while (end >= 0){if ( tmp < a[end])//和前一个值比较大小{a[end + 1] = a[end];//把位置往后挪插入tmp}else{break;}--end;}a[end + 1] = tmp;}}选择排序
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理是:第一次从待排序数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零。选择排序是不稳定的排序方法。
时间复杂度
选择排序的交换操作介于 0 和 (n - 1)次之间。选择排序的比较操作为 n (n - 1) / 2 次之间。选择排序的赋值操作介于 0 和 3 (n - 1) 次之间。比较次数O(n^2),比较次数与关键字的初始状态无关,总的比较次数N=(n-1)+(n-2)+...+1=n*(n-1)/2。交换次数O(n),最好情况是,已经有序,交换0次;最坏情况交换n-1次,逆序交换n/2次。交换次数比冒泡排序少多了,由于交换所需CPU时间比比较所需的CPU时间多,n值较小时,选择排序比冒泡排序快。
稳定性
选择排序是给每个位置选择当前元素最小的,比如给第一个位置选择最小的,在剩余元素里面给第二个元素选择第二小的,依次类推,直到第n-1个元素,第n个元素不用选择了,因为只剩下它一个最大的元素了。那么,在一趟选择,如果一个元素比当前元素小,而该小的元素又出现在一个和当前元素相等的元素后面,那么交换后稳定性就被破坏了。所以选择排序是一个不稳定的排序算法。
实现
void SelectSort(int* a, int n)
{int begin = 0, end = n - 1;while (begin < end){int min = begin, max = begin;//定义max和min用于寻找最大值和最小值for (int i = begin + 1; i <= end; i++){if (a[i] > a[max])//比较最大值{max = i;}if (a[i] < a[min])//比较最小值{min = i;}}Swap(&a[begin], &a[max]);//交换if (max == begin)//如果首元素就是最大值,将最小值赋给最大值然后交换{max = min;}Swap(&a[begin], &a[min]);begin++;end--;}
}希尔排序
希尔排序(Shell's Sort)是插入排序的一种又称“缩小增量排序”(Diminishing Increment Sort),是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因 D.L.Shell 于 1959 年提出而得名。
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至 1 时,整个文件恰被分成一组,算法便终止。
时间复杂度
希尔排序的时间复杂度在最好和最坏情况下都是O(nlog²n),平均时间复杂度是O(nlogn),但是实际上希尔排序的时间复杂度是O(n^1.5),所以对于中小规模的排序希尔排序都是非常好用的,但是对于大型数据要稍微吃力。
稳定性
由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以希尔排序是不稳定的。
希尔排序的算法思想
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行插入排序;然后,取第二个增量d2 = …
该方法实质上是一种分组插入方法。
比较相隔较远距离(称为增量)的数,使得数移动时能跨过多个元素,则进行一次比较就可能消除多个元素交换。算法先将要排序的一组数按某个增量d分成若干组,每组中记录的下标相差d.对每组中全部元素进行排序,然后再用一个较小的增量对它进行分组,在每组中再进行排序。当增量减到1时,整个要排序的数被分成一组,排序完成。
一般的初次取序列的一半为增量,以后每次减半,直到增量为1。
实现
void ShelltSort(int* a, int n)
{int gap = 3;//给定跳过的步数for (int i = 0; i < gap; i++){for (int j = 0; j < n - gap; j += gap){int end = j;int tmp = a[end + gap];//按步数进行插入排序while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}}此方法还可以进一步优化
优化
void ShelltSort(int* a, int n)
{int gap = n;while (gap > 1){gap = gap / 2;//gap > 1时是预排序//gap == 1时就是插入排序for (int j = 0; j < n - gap; ++j){int end = j;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}快速排序
人如其名,快速排序简称快排,快速排序采用的是分治思想,即在一个无序的序列中选取一个任意的基准元素pivot,利用pivot将待排序的序列分成两部分,前面部分元素均小于或等于基准元素,后面部分均大于或等于基准元素,然后采用递归的方法分别对前后两部分重复上述操作,直到将无序序列排列成有序序列。
快速排序算法通过多次比较和交换来实现排序,其排序流程如下:
- 首先设定一个分界值,通过该分界值将数组分成左右两部分。
- 将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于分界值,而右边部分中各元素都大于或等于分界值。
- 然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
- 重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
时间复杂度
快排在理想的条件下的排序速度是非常快的,可以达到O(n log n)。但是在最坏情况下,快排的时间复杂度为O(n²),平均时间复杂度为O(n log n)。
空间复杂度
由于快排需要使用递归进行实现,递归需要消耗栈空间,所以空间复杂度为O(log n)
稳定性
由于快排在进行交换的过程中,会将元素的相对位置给打乱,所以快排属于不稳定排序
实现
void QuickSort(int* a, int begin, int end) {int i = begin; int j = end;if(i >= j) {return;}int tmp = a[begin];while(i != j) {while(a[j] >= tmp && i < j) {j--;}while(a[i] <= tmp && i < j) {i++;}if(i < j) {swap(a[i], a[j]);}}swap(a[begin], array[high]);//递归QuickSort(a, begin, i - 1);QuickSort(a, i + 1, end);
}
三数取中优化
快排同样也可以进行优化,我们可以添加一个三数取中来提高快排的效率。
int GetMiddle(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[left] < a[mid]){if (a[mid] < a[right])return mid;else if (a[left] > a[right])return left;elsereturn right;}else{if (a[mid] > a[right])return mid;else if (a[left] < a[left])return left;elsereturn right;}
}通过三个值寻找中间值的方法,可以极大程度减少快排的时间复杂度,可以使某些极端情况下的快排由O(n²)优化成O(nlongn),这对于快排无疑是非常重要的优化。
下面是优化后的代码
//三数取中
int GetMiddle(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[left] < a[mid]){if (a[mid] < a[right])return mid;else if (a[left] > a[right])return left;elsereturn right;}else{if (a[mid] > a[right])return mid;else if (a[left] < a[left])return left;elsereturn right;}
}//部分排序
int partsort1(int* a, int left, int right)
{int mid = GetMiddle(a, left, right);Swap(&a[left], &a[mid]);int key = left;while (left < right){while (left < right && a[right] >= a[key]){--right;}while (left < right && a[left] <= a[key]){++left;}Swap(&a[left], &a[right]);} Swap(&a[key], &a[left]);return left;
}//递归实现快排
void QuickSort(int* a, int begin, int end)
{if (begin >= end)return;int key = partsort3(a, begin, end);QuickSort(a, begin, key - 1);QuickSort(a, key + 1, end);
}归并排序
归并排序是建立在归并操作上的一种有效、稳定的排序算法,简称归排,该算法采用非常经典的分治法(分治法可以通俗的解释为:把一片领土分解,分解为若干块小部分,然后一块块地占领征服,被分解的可以是不同的政治派别或是其他什么,然后让他们彼此异化),归并排序的思路很简单,速度呢,也仅此于快速排序,归并排序由于它出色的稳定性和稳定的时间复杂度,使得它的效率比快排要更高。
时间复杂度
归并排序的时间复杂度为O(n log n),是速度仅次于快排的排序
空间复杂度
由于归并排序需要使用到一个临时空间用于存放合并后的结果,所以它的空间复杂度为O(n)
稳定性
由于归并排序的算法是通过将序列中待排序数字分为若干组,每个数字分为一组,然后将若干组两两合并,保证合并的组都是有序的,之后再重复第二步的操作,直到剩下最后一组即为有序数列,所以这就保证了相对顺序不会改变,所以是稳定的。
实现
void MergeSortNonR(int* a, int n)
{int gap = 1;int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}while (gap < n){for (int i = 0; i < n; i += 2 * gap){int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;//[begin1,end1] [begin2,end2]两组归并int index = i;if (begin2 >= n){break;}//修正越界情况if (end2 >= n){end2 = n - 1;}while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[index++] = a[begin1++];}else{tmp[index++] = a[begin2++];}}while (begin1 <= end1){tmp[index++] = a[begin1++];}while (begin2 <= end2){tmp[index++] = a[begin2++];}//归并一组后,将数据拷贝回原数组memcpy(a + i, tmp + i, (end2 - i + 1) * sizeof(int));}gap *= 2;}
}归并排序同样也可以通过递归来实现,下面是通过递归方法所实现的归并排序
递归实现归并排序
void _MergeSort(int* a, int* tmp, int begin, int end)
{if (end >= begin){return;}int mid = (end + begin) / 2;_MergeSort(a, tmp, begin, mid);_MergeSort(a, tmp, mid + 1, end);//归并到tmp数组中,再拷贝回去//a->[begin, mid-1] [mid, end]->tmpint begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;int index = begin;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[index++] = a[begin1++];}else{tmp[index++] = a[begin2++];}}while (begin1 <= end1){tmp[index++] = a[begin1++];}while (begin2 <= end2){tmp[index++] = a[begin2++];}memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin));
}void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}_MergeSort(a, tmp, 0, n - 1);free(tmp);
}堆排序
堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它也是不稳定排序。
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆, 注意 : 没有要求结点的左孩子的值和右孩子的值的大小关系。
每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆
时间复杂度
堆排序的最坏,最好还有平均时间复杂度均为O(nlogn)
实现
堆排序的基本思想是:
- 将待排序序列构造成一个大顶堆
- 此时,整个序列的最大值就是堆顶的根节点。
- 将其与末尾元素进行交换,此时末尾就为最大值。
- 然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了
大顶堆和小顶堆的介绍:
- 大顶堆:每个节点的值都大于或者等于它的左右子节点的值: arr[i] >= arr[2i + 1] && arr[i] >= arr[2i + 2]
- 小顶堆:每个节点的值都小于或者等于它的左右子节点的值: arr[i] <= arr[2i + 1] && arr[i] <= arr[2i + 2]
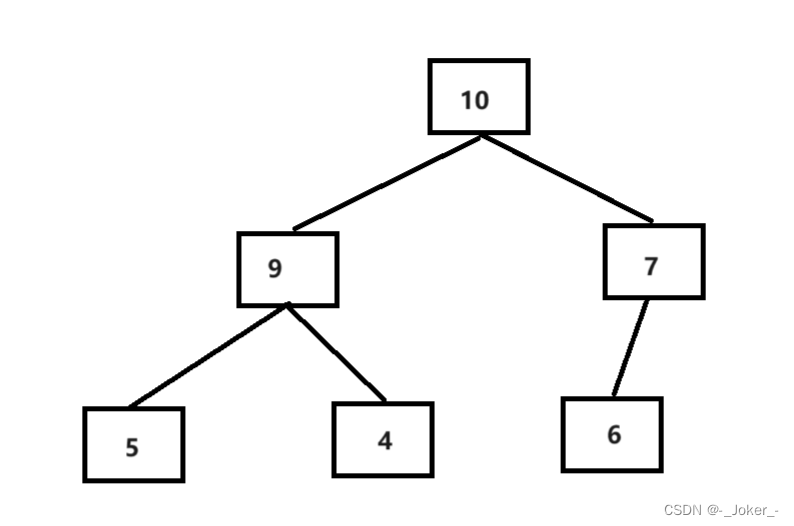
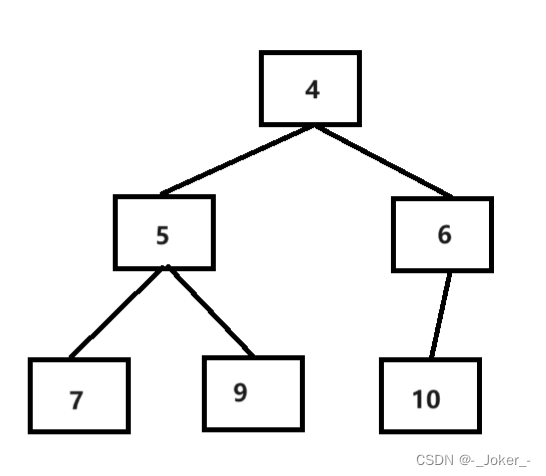
我们在实现归排的时候,如果需要排成升序,我们需要建大堆,若是要排成降序则需要建小堆
简称升序建大堆,降序建小堆
实现
//向上调整
void AdjustUp(HPDataType* a, int child)
{int parent = (child - 1) / 2;while (child > 0){if (a[child] < a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (parent - 1) / 2;}else{break;}}
}//向下调整
void AdjustDown(HPDataType* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n){// 找出小的那个孩子if (child + 1 < n && a[child + 1] < a[child]){++child;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);// 继续往下调整parent = child;child = parent * 2 + 1;}else{break;}}
}
void HeapSort(int* a, int n)
{//建堆(升序建大堆)for (int i = 1; i < n; i++){AdjustUp(a, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end ,0);--end;}
}这里再介绍一下向上调整和向下调整
向上调整算法
所谓向上调整,字面意思就是把数不断的和上面的数做调整。
如果已经存在堆,再插入一个结点,从插入的结点开始,向上依次调整。
调整:如果插入的结点不需要调整,即插入该结点,依旧是堆。
如果插入的结点不满足堆结构,就要对该结点的父亲结点调整,调整完因为改变了父亲结点,就要迭代调整新的孩子结点。
类似下图
那我们在看图片下面的情况可以看到我们在我们在堆的末尾空白位置插入了一个数9,那么此时为了保证堆维持一个大根堆,我们必须要把我们这个新插入的数和它的父亲节点作比较,如果这个新插入的数大于父亲,那么就和父亲交换位置。
那么我们怎么找到它的父亲节点呢?用孩子节点下标求父亲节点下标:Parent = (Child - 1) / 2;
此时9是大于8的,所以我们交换两数的位置,交换完毕后继续用9和他的父亲进行比较,10>9所以不需要调整了

向下调整算法
同样的,向下调整算法字面意思就是把数据和它的孩子节点作比较,然后做出相应的调整。我们这里一样的用大根堆做示例。
注意:向下调整算法有一个前提(左右子树必须是一个堆,才能调整)
也就是说要执行向下调整必须要保证根节点的左右子树都是小根堆或大根堆我们才能执行向下调整。
此时根节点是2,2小于它的的孩子,那么我们就要和它的孩子交换位置,但是具体和哪个孩子交换位置呢?我们需要和两个孩子中大的那个孩子交换,那么我们就需要找到孩子节点的下标,还记得我们上面提到的通过父亲节点找孩子节点的公式吗。
LeftChild = Parent * 2 + 1; //左孩子的节点下标
RightChild = Parent * 2 + 2; //右孩子的节点下标
然后依次向下交换调整
计数排序
计数排序是一个非基于比较的排序算法,该算法于1954年由 Harold H. Seward 提出。它的优势在于在对一定范围内的整数排序时,快于任何比较排序算法。
时间复杂度
时间复杂度是O(n+k):通过上面的代码可知最终的计数算法花费的时间是3n+k,则时间复杂度是O(n+k)。 当然这是一种牺牲空间换取时间的做法,而且当O(k)>O(n*log(n))的时候其效率反而不如基于比较的排序(基于比较的排序的时间复杂度在理论上的下限是O(n*log(n)), 如归并排序,堆排序。
空间复杂度
空间复杂度是O(k):如果出去最后的返回数组,则空间复杂度是2k,则空间复杂度是O(k)
稳定性
由于统计数组可以知道该索引在原数组中排第几位,相同的元素其在原数组中排列在后面,其从原数组的后面遍历,其在最终数组中的索引也在后面,所以相同的元素其相对位置不会改变。计数排序是稳定排序
实现
void CountSort(int* a, int n)
{//寻找最大值和最小值int min = a[0], max = a[0];for (int i = 0; i < n; i++){if (a[i] < min){min = a[i];}if (a[i] > max){max = a[i];}}int range = max - min + 1;int* count = (int*)malloc(sizeof(int) * range);if (count == NULL){perror("malloc fail");return;}//映射数据 统计个数memset(count, 0, sizeof(int) * range);for (int i = 0; i < n; i++){count[a[i] - min]++;}//排序int j = 0;for (int i = 0; i < range; i++){while (count[i]--){a[j++] = i + min;}}
}计数排序最大的好处就是它的稳定性,在某些情况下时间复杂度可以做到惊人的O(1),比快速排序还要更快,能想出这种算法的人可谓是真正的佬。
最后放一张图供各位参考,可以保存起来方便以后快速查找
总结
创作不易,花了几个小时才写出来,感谢各位的三连关注,顺着评论回访🌹🌹
相关文章:
【C语言数据结构——————排序(1万字)】
文章目录 排序的概念 常见排序算法分类冒泡排序 时间复杂度稳定性 原理实现插入排序 时间复杂度稳定性实现选择排序 时间复杂度稳定性实现希尔排序 时间复杂度稳定性希尔排序的算法思想实现 优化快速排序 时间复杂度空间复杂度稳定性实现 三数取中优化归并排序 时间复杂度空间复…...
PyTorch基础(18)-- torch.stack()方法
一、方法详解 首先,看一下stack的直观解释,动词可以简单理解为:把……放成一堆、把……放成一摞。 有了对stack方法的直观感受,接下来,我们正式解析torch.stack方法。 PyTorch torch.stack() method joins (concaten…...

从lc560“和为 K 的子数组“带你认识“前缀和+哈希表“的解题思路
1 前缀和哈希表解题的几道题目:建议集中练习 560. 和为 K 的子数组:https://leetcode.cn/problems/subarray-sum-equals-k/ 1248. 统计「优美子数组」: https://leetcode.cn/problems/count-number-of-nice-subarrays/ 1249. 和可被 K 整除的子数组(利用…...

c:变参函数:汇编解析;va_list;marco 宏:__VA_ARGS__
文章目录 参考gcc 内部的宏定义代码汇编调用在 SEI CERT C Coding Standard 这个标准里示例实例宏里的使用 参考 https://git.sr.ht/~gregkh/presentation-security/blob/3547183843399d693c35b502cf4a313e256d0dd8/security-stuff.pdf gcc 内部的宏定义 宏定义:…...
eclipse安装教程(2021版)
第一步:下载JDK (下载地址) Java SE - Downloads 第二步 根据自己电脑的系统,选择相应的版本x64代表64位,x86代表32位。点击相应的JDK进行下载 点击之后会出现一个对话框 同意之后下载。(记住下载到哪,打…...
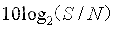
计算机网络重点概念整理-第二章 物理层【期末复习|考研复习】
第二章 物理层 【期末复习|考研复习】 计算机网络系列文章传送门: 第一章 计算机网络概述 第二章 物理层 第三章 数据链路层 第四章 网络层 第五章 传输层 第六章 应用层 第七章 网络安全 计算机网络整理-简称&缩写 文章目录 第二章 物理层 【期末复习|考研复习…...
【计算机网络】从输入URL到页面都显示经历了什么??
文字总结 ① DNS 解析:当用户输入一个网址并按下回车键的时候,浏览器获得一个域名,而在实际通信过程中,我们需要的是一个 IP 地址,因此我们需要先把域名转换成相应 IP 地址。浏览器会首先从缓存中找是否存在域名&…...

[C++]——带你学习类和对象
类和对象——上 目录:一、面向过程和面向对象二、类的概念三、类的访问限定符和封装3.1 访问限定符3.2 封装 四、类的作用域五、类的实例化六、类的对象大小的计算七、类成员函数this指针7.1 this指针的引用7.2 this 指针的特性 目录: 类和对象是很重要…...

Docker多平台、跨平台编译打包
大多数带有Docker官方标识的镜像都提供了多架构支持。如:busybox镜像支持amd64, arm32v5, arm32v6, arm32v7, arm64v8, i386, ppc64le, and s390x。当你在amd64设备上运行容器时,会拉取amd64镜像。 当你需要构建多平台镜像时,可以用 --platf…...

LLM系列 | 22 : Code Llama实战(下篇):本地部署、量化及GPT-4对比
引言 模型简介 依赖安装 模型inference 代码补全 4-bit版模型 代码填充 指令编码 Code Llama vs ChatGPT vs GPT4 小结 引言 青山隐隐水迢迢,秋尽江南草未凋。 小伙伴们好,我是《小窗幽记机器学习》的小编:卖热干面的小女孩。紧接…...

Nginx的进程结构实例演示
可以参考《Ubuntu 20.04使用源码安装nginx 1.14.0》安装nginx 1.14.0。 nginx.conf文件中worker_processes 2;这条语句表明启动两个worker进程。 sudo /nginx/sbin/nginx -c /nginx/conf/nginx.conf开启nginx。 ps -ef | grep nginx看一下进程情况。 sudo /nginx/sbin/ng…...

【Nginx36】Nginx学习:SSI静态文件服务器端包含模块
Nginx学习:SSI静态文件服务器端包含模块 这个模块让我想到了 2009 年刚刚工作的时候。最早我是做 .NET 的,而第一家公司其实是从 ASP 向 ASP.NET 转型中,因此,还是有不少的 ASP 做的页面。在那个时候,就用到了 SSI 。 …...
StripedFly恶意软件框架感染了100万台Windows和Linux主机
导语 近日,一款名为StripedFly的恶意软件框架在网络安全研究人员的监视之外悄然感染了超过100万台Windows和Linux系统。这款跨平台的恶意软件平台在过去的五年中一直未被察觉。在去年,卡巴斯基实验室发现了这个恶意框架的真实本质,并发现其活…...
蓝桥杯每日一题2023.10.25
乘积尾零 - 蓝桥云课 (lanqiao.cn) 题目描述 题目分析 由于需要相乘的数很多,所以我们不能直接进行暴力模拟,我们知道10 2 * 5, 所以我们只需要找出这个数2和5的个数,其中2和5个数小的那个则为末尾0出现的个数 #include<bi…...

【C++】详解map和set基本接口及使用
文章目录 一、关联式容器与键值对1.1关联式容器(之前学的都是序列容器)1.2键值对pairmake_pair函数(map在插入的时候会很方便) 1.3树形结构的关联式容器 二、set2.1set的基本介绍2.1默认构造、迭代器区间构造、拷贝构造࿰…...

如何学习 Linux 内核内存管理
Linux内核内存管理部分是Linux内核中第二复杂的部分,但也非常有趣。学习它的最佳方法就是阅读代码。但在不了解术语和当前 mm 部分到底发生了什么的情况下,显然不能随意开始阅读代码。因此,我想这样开始学习比较好: 了解当前的 LS…...

【计算机网络】(谢希仁第八版)第一章课后习题答案
1.计算机网络可以向用户提供哪些服务? 答:例如音频,视频,游戏等,但本质是提供连通性和共享这两个功能。 连通性:计算机网络使上网用户之间可以交换信息,好像这些用户的计算机都可以彼此直接连…...

Operator开发之operator-sdk入门
1 operator-sdk 除了kubebuilder,operator-sdk是另一个常用的用于开发Operator的框架,不过operator-sdk还是基于kubebuilder,因此,通常还是建议使用kubebuilder开发Operator。 2 环境准备 跟kubebuilder类似,需要安…...
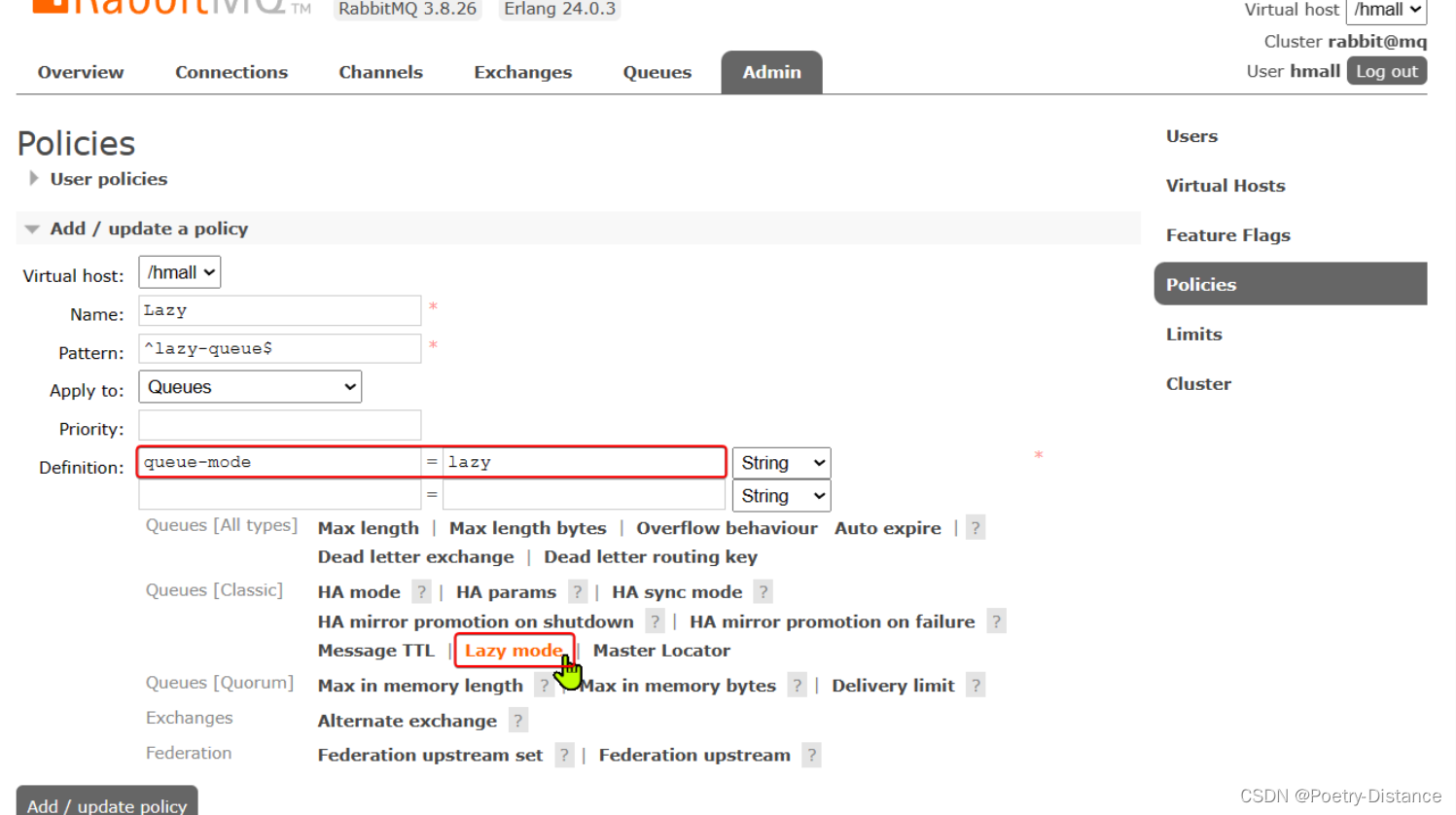
RabbitMQ生产者的可靠性
目录 MQ使用时会出现的问题 生产者的可靠性 1、生产者重连 2、生产者确认 3、数据持久化 交换机持久化 队列持久化 消息持久化 LazyQueue懒加载 MQ使用时会出现的问题 发送消息时丢失: 生产者发送消息时连接MQ失败生产者发送消息到达MQ后未找到Exchange生…...

集群节点批量执行 shell 命令
1、SSH 工具本身支持多窗口 比如 MobaXterm: 2、编写脚本通过 ssh 在多台机器批量执行shell命令 创建 ssh_hosts 配置文件,定义需要批量执行的节点(必须能够通过 ssh 免密登录,且存在同名用户) vim ssh_hostsbig…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...

Python第七周作业
Python第七周作业 文章目录 Python第七周作业 1.使用open以只读模式打开文件data.txt,并逐行打印内容 2.使用pathlib模块获取当前脚本的绝对路径,并创建logs目录(若不存在) 3.递归遍历目录data,输出所有.csv文件的路径…...
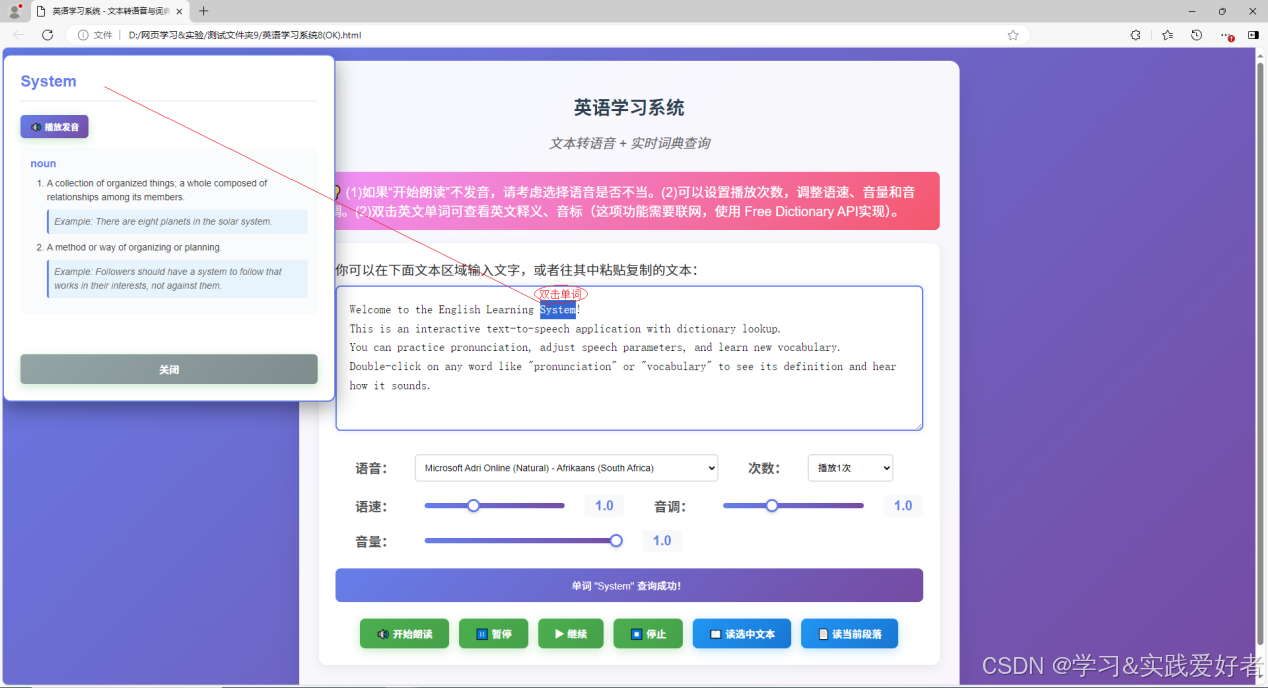
HTML版英语学习系统
HTML版英语学习系统 这是一个完全免费、无需安装、功能完整的英语学习工具,使用HTML CSS JavaScript实现。 功能 文本朗读练习 - 输入英文文章,系统朗读帮助练习听力和发音,适合跟读练习,模仿学习;实时词典查询 - 双…...

linux设备重启后时间与网络时间不同步怎么解决?
linux设备重启后时间与网络时间不同步怎么解决? 设备只要一重启,时间又错了/偏了,明明刚刚对时还是对的! 这在物联网、嵌入式开发环境特别常见,尤其是开发板、树莓派、rk3588 这类设备。 解决方法: 加硬件…...