Azure - 机器学习实战:快速训练、部署模型
本文将指导你探索 Azure 机器学习服务的主要功能。在这里,你将学习如何创建、注册并发布模型。此教程旨在让你深入了解 Azure 机器学习的基础知识和常用操作。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

一、开始之前的准备
要深入 Azure 机器学习,首先确保你有一个工作区。如果你还未设置工作区,那么请按照指引,完成必要的资源配置来搭建你的工作区,并了解其基本操作。
请登录到Azure工作室,并选择你的工作区(如果它还未被激活)。
接下来,在工作区内,你可以选择启动或新建一个笔记本:
- 如果你打算把代码复制到某个单元,那么请新建一个笔记本。
- 作为另一种选择,你可以在工作室的“示例”区域找到
tutorials/get-started-notebooks/quickstart.ipynb。打开后点击“克隆”,这样这个笔记本就会被保存到你的“文件”里。
二、配置内核
当你打开笔记本时,可以在顶部的工具栏中找到并设定一个计算实例(前提是你之前还没有设立过)。
如果发现计算实例处于暂停状态,请点击“启动计算”并耐心等待其启动完成。
当出现提示横幅,要求你完成身份验证时,请点击“身份验证”进行操作。

三、建立工作区连接
在开始编写代码之前,我们要确保有办法正确引用工作区。工作区是 Azure 机器学习的核心资源,它为你在 Azure 机器学习上创建的所有项目提供了统一的管理点。
你会为这个工作区连接创建名为 ml_client 的句柄。之后,你可以利用 ml_client 来统筹各种资源和任务。
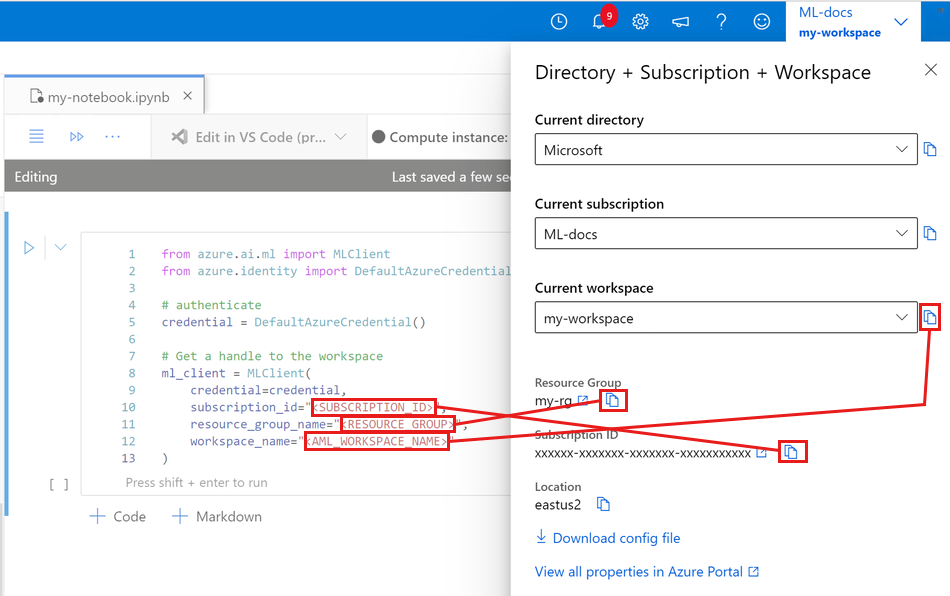
请在下方的代码单元格里输入你的订阅ID、资源组名以及工作区名。要找到这些信息的方法如下:
- 在 Azure 机器学习工作室界面的右上角,点击你的工作区名称。
- 从显示的信息中复制工作区、资源组和订阅ID。
- 一次复制一个信息,粘贴到代码中后再返回继续复制下一个。
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential# authenticate
credential = DefaultAzureCredential()# Get a handle to the workspace
ml_client = MLClient(credential=credential,subscription_id="<SUBSCRIPTION_ID>",resource_group_name="<RESOURCE_GROUP>",workspace_name="<AML_WORKSPACE_NAME>",
)四、编写训练代码
首先,我们需要制定训练代码并保存为 Python 文件,命名为 main.py。
开始时,为这个脚本设置一个专门的源代码目录。
import ostrain_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
这段代码负责数据预处理,对数据进行训练和测试的划分。接着,脚本将利用这些数据来培训一个基于树的机器学习模型,并输出该模型。
在整个管道运行过程中,我们会利用 MLFlow 来记录相关参数和性能指标。
接下来的代码单元将使用 IPython magic 命令,把训练脚本保存到你刚刚设定的目录中。
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_splitdef main():"""Main function of the script."""# input and output argumentsparser = argparse.ArgumentParser()parser.add_argument("--data", type=str, help="path to input data")parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)parser.add_argument("--n_estimators", required=False, default=100, type=int)parser.add_argument("--learning_rate", required=False, default=0.1, type=float)parser.add_argument("--registered_model_name", type=str, help="model name")args = parser.parse_args()# Start Loggingmlflow.start_run()# enable autologgingmlflow.sklearn.autolog()####################<prepare the data>###################print(" ".join(f"{k}={v}" for k, v in vars(args).items()))print("input data:", args.data)credit_df = pd.read_csv(args.data, header=1, index_col=0)mlflow.log_metric("num_samples", credit_df.shape[0])mlflow.log_metric("num_features", credit_df.shape[1] - 1)train_df, test_df = train_test_split(credit_df,test_size=args.test_train_ratio,)#####################</prepare the data>#######################################<train the model>################### Extracting the label columny_train = train_df.pop("default payment next month")# convert the dataframe values to arrayX_train = train_df.values# Extracting the label columny_test = test_df.pop("default payment next month")# convert the dataframe values to arrayX_test = test_df.valuesprint(f"Training with data of shape {X_train.shape}")clf = GradientBoostingClassifier(n_estimators=args.n_estimators, learning_rate=args.learning_rate)clf.fit(X_train, y_train)y_pred = clf.predict(X_test)print(classification_report(y_test, y_pred))####################</train the model>##############################################<save and register model>########################### Registering the model to the workspaceprint("Registering the model via MLFlow")mlflow.sklearn.log_model(sk_model=clf,registered_model_name=args.registered_model_name,artifact_path=args.registered_model_name,)# Saving the model to a filemlflow.sklearn.save_model(sk_model=clf,path=os.path.join(args.registered_model_name, "trained_model"),)############################</save and register model>############################ Stop Loggingmlflow.end_run()if __name__ == "__main__":main()
正如你将在脚本中看到的,一旦模型训练完毕,它会被保存并在工作区中进行注册。这样,这个已注册的模型就可以被用于推理节点了。
为了在“文件”区域看到新创建的文件夹和脚本,你可能需要点击“刷新”按钮。
五、配置计算集群
为训练任务提供弹性处理能力
虽然你已有一个计算实例来执行笔记本操作,但下一步你需要设置一个计算集群,专门用于处理训练任务。不同于计算实例的单节点,计算集群能够支持单节点或多节点的 Linux 或 Windows 操作系统,甚至是特定的计算配置,如 Spark。
此处,你应当预先设置一个 Linux 计算集群。关于虚拟机的规格和价格,你可以查阅相关资料。
对于本例子,你只需简单的集群配置,选择 Standard_DS3_v2,拥有 2 个 vCPU 核心和 7 GB 的 RAM。
from azure.ai.ml.entities import AmlCompute# Name assigned to the compute cluster
cpu_compute_target = "cpu-cluster"try:# let's see if the compute target already existscpu_cluster = ml_client.compute.get(cpu_compute_target)print(f"You already have a cluster named {cpu_compute_target}, we'll reuse it as is.")except Exception:print("Creating a new cpu compute target...")# Let's create the Azure Machine Learning compute object with the intended parameters# if you run into an out of quota error, change the size to a comparable VM that is available.\# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.cpu_cluster = AmlCompute(name=cpu_compute_target,# Azure Machine Learning Compute is the on-demand VM servicetype="amlcompute",# VM Familysize="STANDARD_DS3_V2",# Minimum running nodes when there is no job runningmin_instances=0,# Nodes in clustermax_instances=4,# How many seconds will the node running after the job terminationidle_time_before_scale_down=180,# Dedicated or LowPriority. The latter is cheaper but there is a chance of job terminationtier="Dedicated",)print(f"AMLCompute with name {cpu_cluster.name} will be created, with compute size {cpu_cluster.size}")# Now, we pass the object to MLClient's create_or_update methodcpu_cluster = ml_client.compute.begin_create_or_update(cpu_cluster)
六、命令设置
既然我们已有了执行任务的脚本和对应的计算集群,接下来你将设置一系列的命令行操作,这些操作或直接调用系统命令,或执行特定脚本。
在这一部分,你需要定义输入变量,比如输入数据、数据拆分比例、学习率以及模型的注册名。你的命令脚本将做以下事情:
利用计算集群执行命令。
使用 Azure 机器学习提供的预设环境来运行训练脚本,这些环境内包含了训练脚本所需的软件和运行时库。后续,在其他教程中,你将了解如何自定义这些环境。
设定命令行操作,例如 python main.py。你可以使用 ${{ … }} 这样的语法在命令中传递输入/输出参数。
在这一示例中,我们将直接从互联网获取数据。
from azure.ai.ml import command
from azure.ai.ml import Inputregistered_model_name = "credit_defaults_model"job = command(inputs=dict(data=Input(type="uri_file",path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",),test_train_ratio=0.2,learning_rate=0.25,registered_model_name=registered_model_name,),code="./src/", # location of source codecommand="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",compute="cpu-cluster", #delete this line to use serverless computedisplay_name="credit_default_prediction",
)
七、任务提交
现在,你可以在 Azure 机器学习平台上提交一个作业了。这次,你需要对 ml_client 使用 create_or_update 功能。
ml_client.create_or_update(job)
八、查看任务结果并等待完成
你可以通过点击前一个代码单元的输出链接,在 Azure 机器学习工作室里查看任务的进展。
任务的各类输出,比如指标、结果等,都可以在 Azure 机器学习工作室里查看。当任务完成后,其训练出的模型会被注册到你的工作区。
九、部署模型为在线服务
是时候将你的机器学习模型作为一个 Web 服务,部署到 Azure 云上了。
为了部署这个服务,你应当使用已经注册过的机器学习模型。持有一个已经注册过的模型,接下来,你可以着手搭建一个在线端点。需要确保你为端点选择的名称在整个Azure地区是独一无二的。为了确保名字的唯一性,在这个教程里,我们建议采用UUID作为端点名称。
import uuid# Creating a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
```python```python
# Expect the endpoint creation to take a few minutes
from azure.ai.ml.entities import (ManagedOnlineEndpoint,ManagedOnlineDeployment,Model,Environment,
)# create an online endpoint
endpoint = ManagedOnlineEndpoint(name=online_endpoint_name,description="this is an online endpoint",auth_mode="key",tags={"training_dataset": "credit_defaults","model_type": "sklearn.GradientBoostingClassifier",},
)endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()print(f"Endpoint {endpoint.name} provisioning state: {endpoint.provisioning_state}")
十、模型部署到终结点
端点构建完毕后,你可以采用入口脚本将模型部署到此端点。值得注意的是,一个端点可以支持多个部署版本,并能够设定特定规则来分流到不同的部署版本。在此,我们会为你创建一个部署版本,它将处理所有的流入流量。对于部署的命名,我们提供了一些建议,如“蓝色”、“绿色”和“红色”,你可以根据自己的喜好选择。
你还可以浏览Azure机器学习工作室的“模型”页面,这有助于你识别已注册模型的最新版本。另外,你也可以利用下面的代码来获取最新的版本信息。
# Let's pick the latest version of the model
latest_model_version = max([int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(f'Latest model is version "{latest_model_version}" ')
# picking the model to deploy. Here we use the latest version of our registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)# Expect this deployment to take approximately 6 to 8 minutes.
# create an online deployment.
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.blue_deployment = ManagedOnlineDeployment(name="blue",endpoint_name=online_endpoint_name,model=model,instance_type="Standard_DS3_v2",instance_count=1,
)blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()
十一、实例推理测试
完成模型的部署之后,你现在可以对它进行推理测试了。
按照评分脚本中run函数的要求,制定一个示例请求文件。
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)%%writefile {deploy_dir}/sample-request.json
{"input_data": {"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],"index": [0, 1],"data": [[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]]}
}# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(endpoint_name=online_endpoint_name,request_file="./deploy/sample-request.json",deployment_name="blue",
)
十二、节点删除
如果你暂时不需要使用该端点,请记得删除,以避免不必要的费用。在进行删除之前,请确保没有其他部署正在使用这个端点。
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
十三、停止计算实例
如果你暂时不使用计算实例,建议暂停:
在工作室左侧导航栏,点击“计算”。
选择“计算实例”选项卡。
从列表中选择对应的计算实例。
点击顶部工具栏的“停止”按钮。
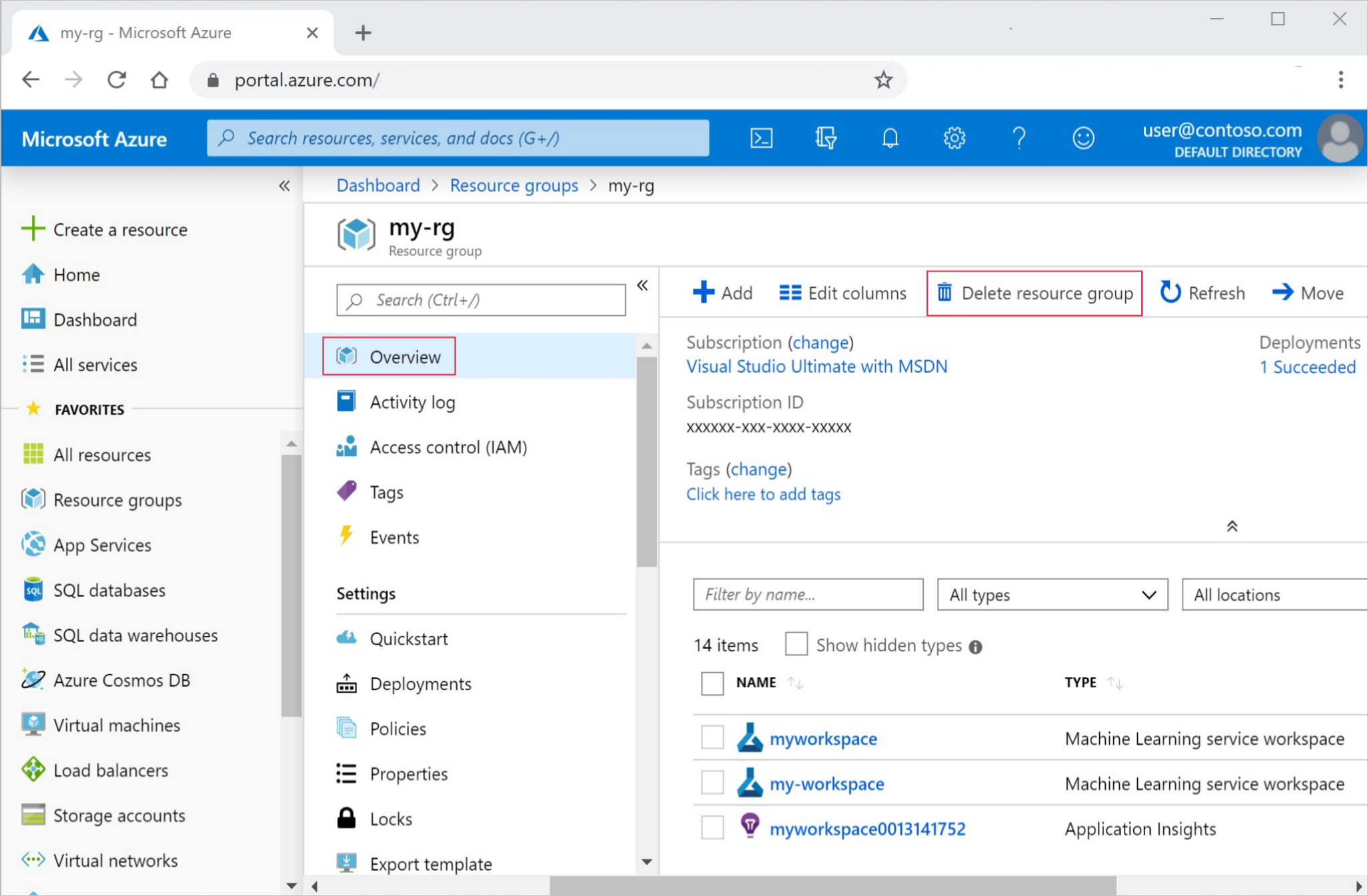
十四、资源清理
若你决定不再使用已创建的资源,为避免费用,请进行清理:
在Azure门户里,点击左侧的“资源组”。
从列表中找到并选择你所创建的资源组。
点击“删除资源组”,在弹出的确认框里输入资源组名称,并点击“删除”。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
相关文章:
Azure - 机器学习实战:快速训练、部署模型
本文将指导你探索 Azure 机器学习服务的主要功能。在这里,你将学习如何创建、注册并发布模型。此教程旨在让你深入了解 Azure 机器学习的基础知识和常用操作。 关注TechLead,分享AI全维度知识。作者拥有10年互联网服务架构、AI产品研发经验、团队管理经验…...
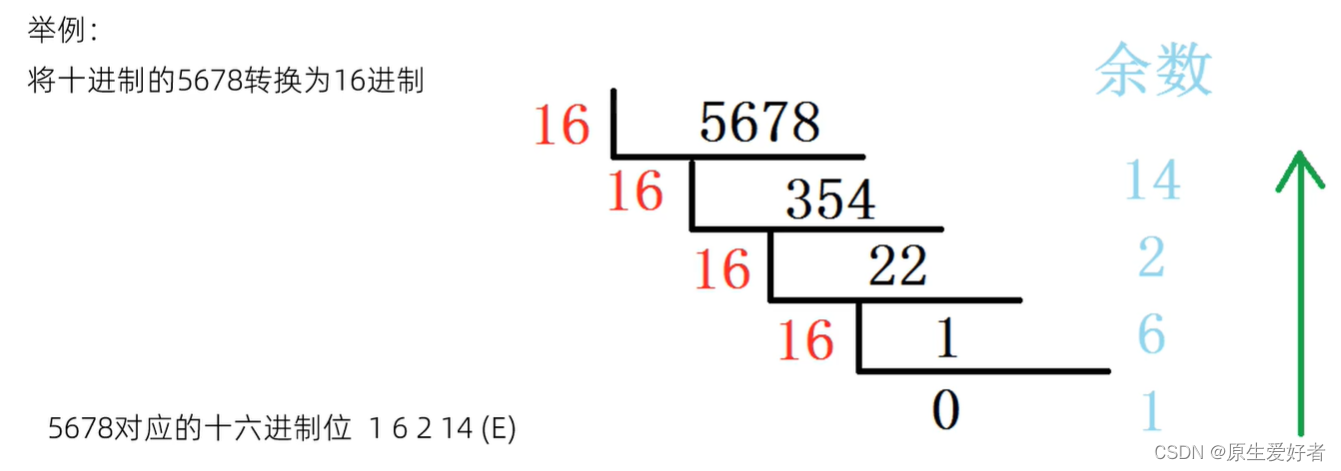
C语言十进制转其它进制
短除法介绍 短除法: 主要功能为将十进制数据转为其它进制的数据,假设我们要转换为 X 进制,那么具体的流程如下: 十进制数字不断除以 X,直到商为 0 记录每次计算得到的余数 将余数倒序输出,即为对应的 X 进…...

网络建设 之 React数据管理
React作为一个用于构建用户界面的JavaScript库,很多人认为React仅仅只是一个UI 库,而不是一个前端框架,因为它在数据管理上是缺失的。在做一个小项目的时候,维护的数据量不多,管理/维护数据用useState/useRef就足够了&…...

如何隐藏woocommerce 后台header,woocommerce-layout__header
如何隐藏woocommerce 后台header,woocommerce-layout__header WooCommerce |Products Store Activity| Inbox| Orders| Stock| Reviews| Notices| breadcrumbs 在 functions.php 里添加如下代码即可: // Disable WooCommerce Header in WordPress Admi…...
通俗易懂的理解 解耦 概念
解耦(Decoupling)是计算机科学和软件工程中的一个概念,指的是降低系统中不同部分之间的依赖性,使系统的各个组件能够相对独立地进行开发、维护和演化。解耦的主要目标是减少组件之间的紧密耦合,以提高系统的灵活性、可…...

全志A40i android7.1 增加Vlan功能
一,VLAN基础知识 1.VLAN的定义: VLAN(Virtual Local Area Network)即虚拟局域网,是将一个物理的LAN在逻辑上划分成多个广播域的通信技术。VLAN内的主机间可以直接通信,而VLAN间不能直接通信,从…...

NAT技术与代理服务器
目录 一、NAT与NAPT技术 1.NAT技术 2.NAPT技术 (1)四元组的唯一性 (2)数据的传输过程 (3)NAPT的缺陷 二、代理服务器 1.正向代理和反向代理 2.代理服务器的应用 (1)游戏加…...
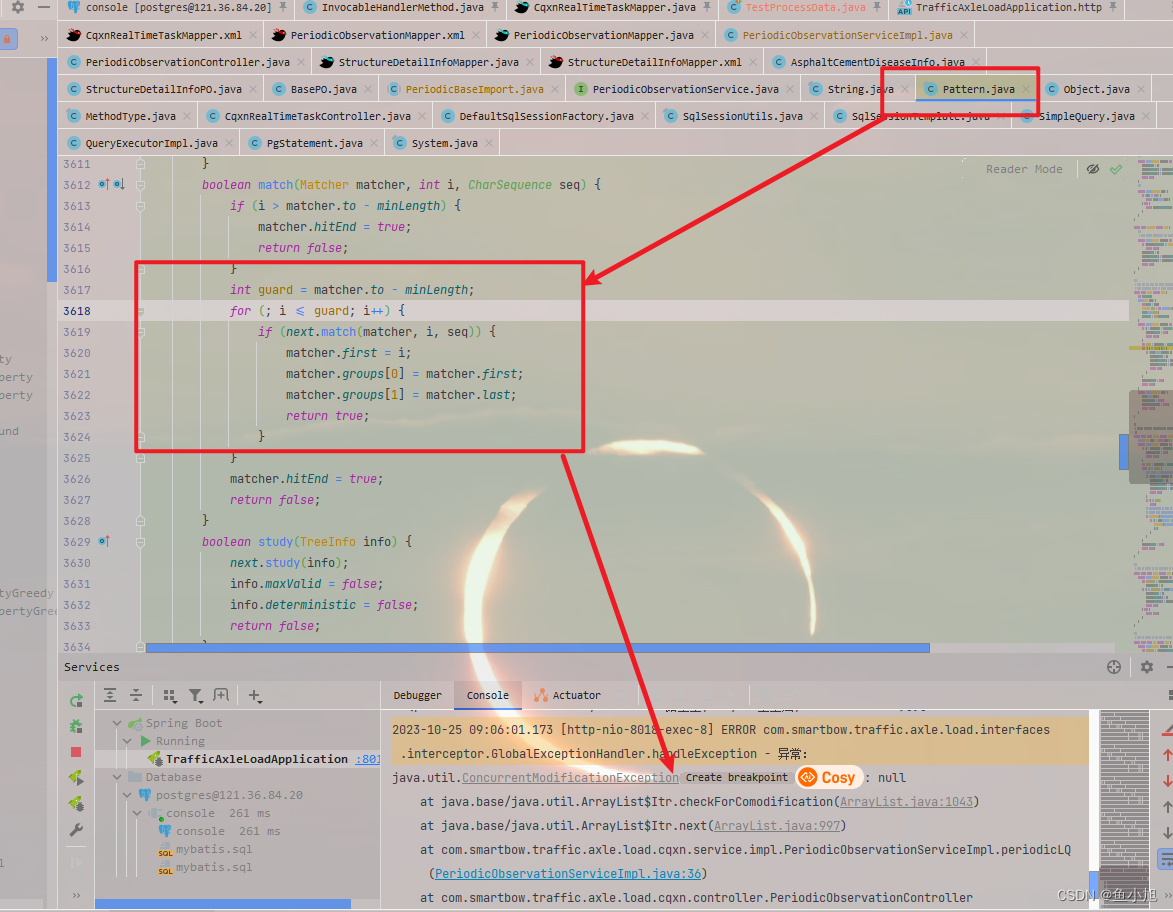
关于报错java.util.ConcurrentModificationException: null的源码分析和解决
一般有这种问题,方法中至少会有List或者Map下的至少两个子类,有可能参数类型相同,也有可能不同都有可能触发这个问题!其主要原因是使用了ArrayList进行删除操作或者使用iterator遍历集合的同时对集合进行修改都有可能会出现这个问题 ArrayList属于List下的子类 需要区分的是Li…...
)
使用koa搭建服务器(一)
最近有个需求需要使用到koa搭建服务器并编写接口对数据库进行增删改查,因此写一篇博客记录这段时间的收获。 一、新建koa项目 (一)安装koa及其相关依赖 npm i koa npm i koa-router// 中间件,用于匹配路由 npm i koa-bodyparse…...
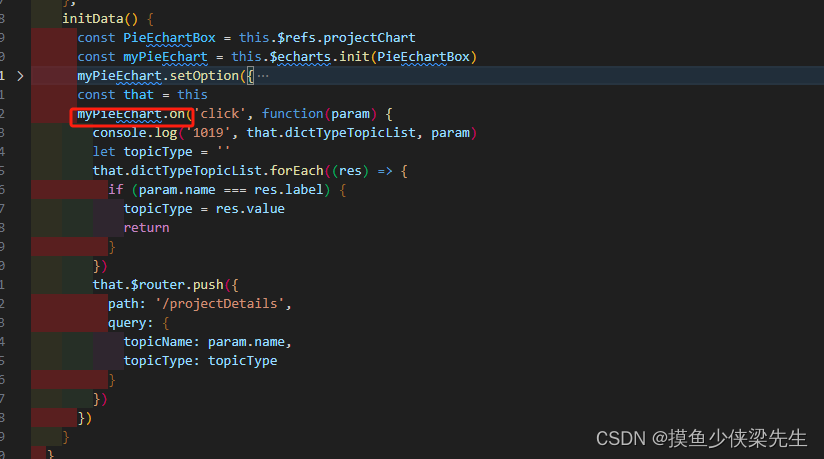
echarts的柱状图的重叠和堆叠实现两个柱体的显示和之前的差值显示
效果图 主要思路 准备三个柱体(原计划,实际进度,差值) 原计划和实际进度设置成重叠 {barWidth: 20,// yAxisIndex: 1,z: 1,name: 原计划,type: bar,stack: ab,emphasis: { // 点击柱体其他柱体颜色会变浅disabled: true},label…...
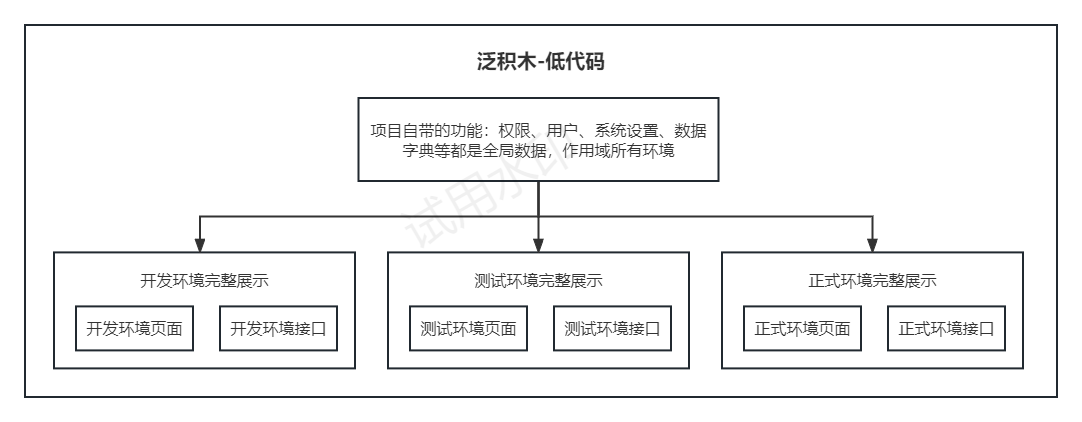
泛积木-低代码 使用攻略
文档首发于 泛积木-低代码 使用攻略 我们以大纲的方式(总体把握)讲述如何高效、便捷使用 泛积木-低代码。 权限 首先说下权限,在 系统设置 / 权限设置 菜单内,我们可以新增调整项目内的权限,默认拥有管理员和成员两…...
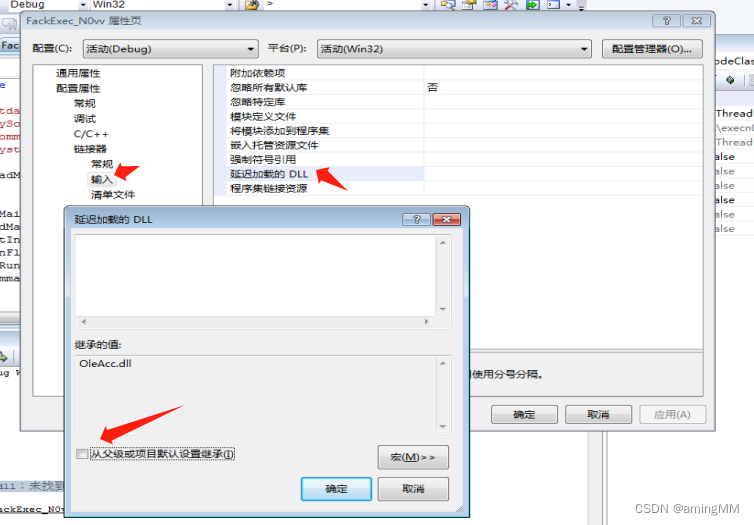
红队专题-从零开始VC++C/S远程控制软件RAT-MFC-远控介绍及界面编写
红队专题 招募六边形战士队员[1]远控介绍及界面编写1.远程控制软件演示及教程简要说明主程序可执行程序 服务端生成器主机上线服务端程序 和 服务文件管理CMD进程服务自启动主程序主对话框操作菜单列表框配置信息 多线程操作非模式对话框 2.环境:3.界面编程新建项目…...

机器学习(五)如何理解机器学习三要素
1.8如何理解机器学习三要素 统计学习模型策略算法 模型:规律yaxb 策略:什么样的模型是好的模型?损失函数 算法:如何高效找到最优参数,模型中的参数a和b 1.8.1模型 机器学习中,首先要考虑学习什么样的…...

【计算机视觉】3D视觉
文章目录 一、基本问题二、三个坐标系 X w \boldsymbol{X}_w Xw到 X c \boldsymbol{X}_c Xc的转换 X c \boldsymbol{X}_c Xc到 x i \boldsymbol{x}_i xi的转换投影矩阵尺度模糊问题 三、相机标定四、立体视觉 我的《计算机视觉》系列参考UC Berkeley的CS180课程&#x…...

策略路由和路由策略
目录 策略路由 路由策略 策略路由和路由策略 策略路由 Step1:配置ACL,匹配流量 acl number 2010 rule 10 permit source 192.168.10.0 0.0.0.255 acl number 2020 rule 10 permit source 192.168.20.0 0.0.0.255 Step2:流分类traffic classifier jiaoxue //匹配…...
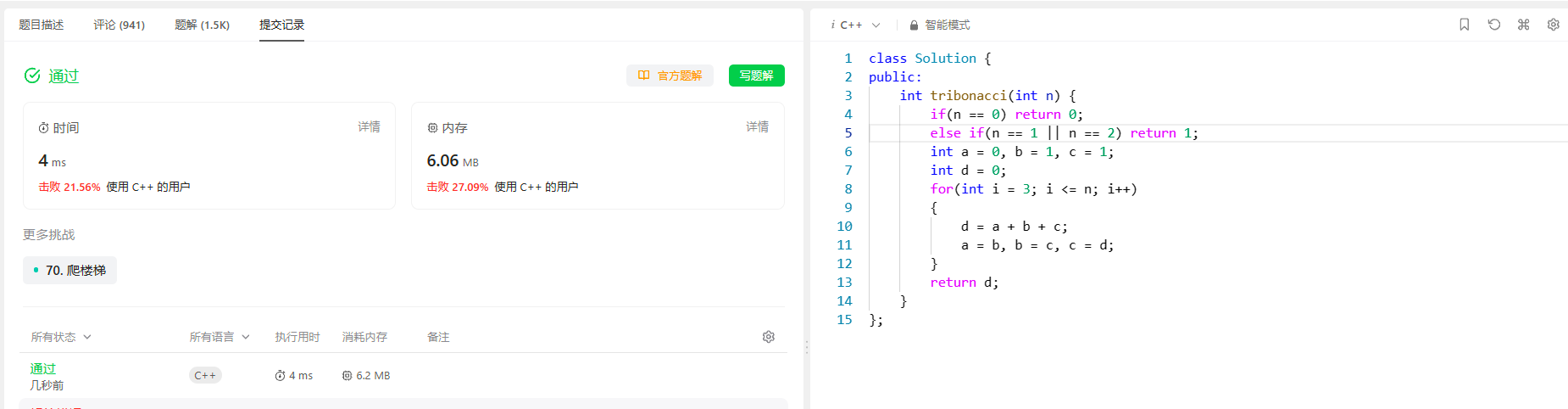
[动态规划] (一) LeetCode 1137.第N个泰波那契数
[动态规划] (一) LeetCode 1137.第N个泰波那契数 文章目录 [动态规划] (一) LeetCode 1137.第N个泰波那契数题目解析解题思路状态表示状态转移方程初始化和填表顺序返回值 代码实现总结空间优化代码实现 总结 1137. 第 N 个泰波那契数 题目解析 解题思路 状态表示 (1) 题目要…...

SystemVerilog语法中,在Class中引用层次化信号
在class中可以像在verilog中一样,直接在class中引用层次化信号。示例如下: 1.DUT模块,文件名为top.v。 module top (input clk ,input rst_n ,//总线信号 input wr_n ,input rd_n ,input cs0_n ,input cs7_n …...
磁盘的结构(磁道,扇区,盘面,柱面,物理地址)
目录 1.磁盘、磁道、扇区的概念1.磁盘2.磁道3.扇区 2.如何在磁盘中读/写数据3.盘面、柱面的概念4.磁盘的物理地址1.根据地址读取一个“块” 5.磁盘的分类1.活动头磁道2.固定头磁盘3.根据盘片是否可更换 1.磁盘、磁道、扇区的概念 1.磁盘 磁盘的表面由一些磁性物质组成…...

uni-app集成uni-simple-router,报错:Uncaught ReferenceError: ROUTES is not defined
参考连接:GitHub - SilurianYang/uni-read-pages: read pages.json file to generate the routes table 作用:配置 vue.config.js 通过 webpack注入全局变量 问题:缺少Webpack 配置环境 方法: 项目根目录下打开终端,…...
几个常用的nosql数据库的操作方式
dynamoDB 键 partition key:分区键 定义:分区键是用于分布数据存储的主键,每个项(Item)在表中都必须有一个唯一的分区键值。 特点: 唯一性:每个分区键值在表中必须是唯一的,这是因为…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...