0基础学习PyFlink——使用Table API实现SQL功能
大纲
- Souce
- schema
- descriptor
- Sink
- schema
- descriptor
- Execute
- 完整代码
- 参考资料
《0基础学习PyFlink——使用PyFlink的Sink将结果输出到Mysql》一文中,我们讲到如何通过定义Souce、Sink和Execute三个SQL,来实现数据读取、清洗、计算和入库。
如下图所示SQL是最高层级的抽象,在它之下是Table API。本文我们会将例子中的SQL翻译成Table API来实现等价的功能。
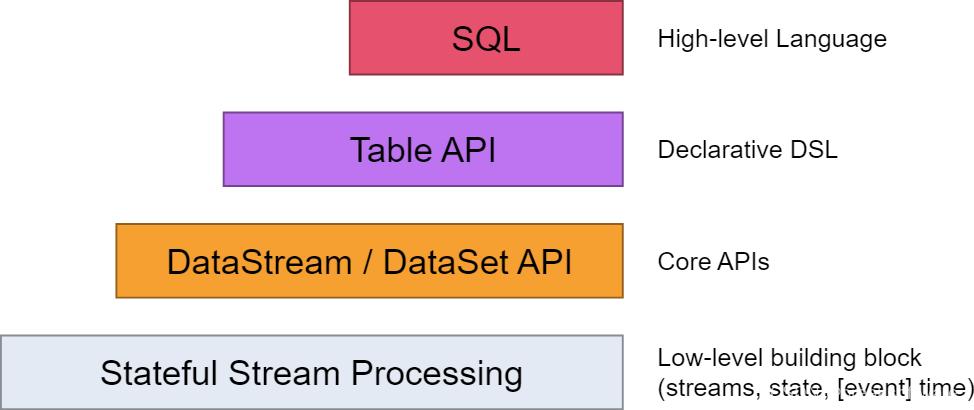
Souce
# """create table source (# word STRING# ) with (# 'connector' = 'filesystem',# 'format' = 'csv',# 'path' = '{}'# )# """.format(input_path)
下面的SQL分为两部分:
- Table结构:该表只有一个名字为word,类型为string的字段。
- 连接器:是“文件系统”(filesystem)类型,格式是csv的文件。这样输入就会按csv格式进行解析。
SQL中的Table对应于Table API中的schema。它用于定义表的结构,比如有哪些类型的字段和主键等。
上述整个SQL整体对应于descriptor。即我们可以认为descriptor是表结构+连接器。
我们可以让不同的表和不同的连接器结合,形成不同的descriptor。这是一个组合关系,我们将在下面看到它们的组合方式。
schema
# define the source schemasource_schema = Schema.new_builder() \.column("word", DataTypes.STRING()) \.build()
new_builder()会返回一个Schema.Builder对象;
column(self, column_name: str, data_type: Union[str, DataType])方法用于声明该表存在哪些类型、哪些名字的字段,同时返回之前的Builder对象;
最后的build(self)方法返回Schema.Builder对象构造的Schema对象。
descriptor
# Create a source descriptorsource_descriptor= TableDescriptor.for_connector("filesystem") \.schema(source_schema) \.option('path', input_path) \.format("csv") \.build()
for_connector(connector: str)方法返回一个TableDescriptor.Builder对象;
schema(self, schema: Schema)将上面生成的source_schema 对象和descriptor关联;
option(self, key: Union[str, ConfigOption], value)用于指定一些参数,比如本例用于指定输入文件的路径;
format(self, format: Union[str, ‘FormatDescriptor’], format_option: ConfigOption[str] = None)用于指定内容的格式,这将指导怎么解析和入库;
build(self)方法返回TableDescriptor.Builder对象构造的TableDescriptor对象。
Sink
# """CREATE TABLE WordsCountTableSink (# `word` STRING,# `count` BIGINT,# PRIMARY KEY (`word`) NOT ENFORCED# ) WITH (# 'connector' = 'jdbc',# 'url' = 'jdbc:mysql://127.0.0.1:3306/words_count_db?useSSL=false',# 'table-name' = 'WordsCountTable',# 'driver'='com.mysql.jdbc.Driver',# 'username'='admin',# 'password'='pwd123'# );# """
schema
sink_schema = Schema.new_builder() \.column("word", DataTypes.STRING().not_null()) \.column("count", DataTypes.BIGINT()) \.primary_key("word") \.build()
大部分代码在之前已经解释过了。我们主要关注于区别点:
- primary_key(self, *column_names: str) 用于指定表的主键。
- 主键的类型需要使用调用not_null(),以表明其非空。
descriptor
# Create a sink descriptorsink_descriptor = TableDescriptor.for_connector("jdbc") \.schema(sink_schema) \.option("url", "jdbc:mysql://127.0.0.1:3306/words_count_db?useSSL=false") \.option("table-name", "WordsCountTable") \.option("driver", "com.mysql.jdbc.Driver") \.option("username", "admin") \.option("password", "pwd123") \.build()
这块代码主要是通过option来设置一些连接器相关的设置。可以看到这是用KV形式设计的,这样就可以让option方法有很大的灵活性以应对不同连接器千奇百怪的设置。
Execute
使用下面的代码将表创建出来,以供后续使用。
t_env.create_table("source", source_descriptor)
tab = t_env.from_path('source')
t_env.create_temporary_table("WordsCountTableSink", sink_descriptor)
# execute insert# """insert into WordsCountTableSink# select word, count(1) as `count`# from source# group by word# """
tab.group_by(col('word')) \.select(col('word'), lit(1).count) \.execute_insert("WordsCountTableSink") \.wait()
这儿需要介绍的就是lit。它用于生成一个表达式,诸如sum、max、avg和count等。
execute_insert(self, table_path_or_descriptor: Union[str, TableDescriptor], overwrite: bool = False)用于将之前的计算结果插入到Sink表中
完整代码
import argparse
import logging
import sysfrom pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment, Schema)
from pyflink.table.types import DataTypes
from pyflink.table.table_descriptor import TableDescriptor
from pyflink.table.expressions import lit, coldef word_count(input_path):config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_batch_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)# """create table source (# word STRING# ) with (# 'connector' = 'filesystem',# 'format' = 'csv',# 'path' = '{}'# )# """# define the source schemasource_schema = Schema.new_builder() \.column("word", DataTypes.STRING()) \.build()# Create a source descriptorsource_descriptor = TableDescriptor.for_connector("filesystem") \.schema(source_schema) \.option('path', input_path) \.format("csv") \.build()t_env.create_table("source", source_descriptor)# """CREATE TABLE WordsCountTableSink (# `word` STRING,# `count` BIGINT,# PRIMARY KEY (`word`) NOT ENFORCED# ) WITH (# 'connector' = 'jdbc',# 'url' = 'jdbc:mysql://127.0.0.1:3306/words_count_db?useSSL=false',# 'table-name' = 'WordsCountTable',# 'driver'='com.mysql.jdbc.Driver',# 'username'='admin',# 'password'='pwd123'# );# """# define the sink schemasink_schema = Schema.new_builder() \.column("word", DataTypes.STRING().not_null()) \.column("count", DataTypes.BIGINT()) \.primary_key("word") \.build()# Create a sink descriptorsink_descriptor = TableDescriptor.for_connector("jdbc") \.schema(sink_schema) \.option("url", "jdbc:mysql://127.0.0.1:3306/words_count_db?useSSL=false") \.option("table-name", "WordsCountTable") \.option("driver", "com.mysql.jdbc.Driver") \.option("username", "admin") \.option("password", "pwd123") \.build()t_env.create_temporary_table("WordsCountTableSink", sink_descriptor)# execute insert# """insert into WordsCountTableSink# select word, count(1) as `count`# from source# group by word# """tab = t_env.from_path('source')tab.group_by(col('word')) \.select(col('word'), lit(1).count) \.execute_insert("WordsCountTableSink") \.wait()if __name__ == '__main__':logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")parser = argparse.ArgumentParser()parser.add_argument('--input',dest='input',required=False,help='Input file to process.')argv = sys.argv[1:]known_args, _ = parser.parse_known_args(argv)word_count(known_args.input)
参考资料
- https://nightlies.apache.org/flink/flink-docs-master/zh/docs/concepts/overview/
- https://nightlies.apache.org/flink/flink-docs-release-1.17/api/python//reference/pyflink.table/descriptors.html
相关文章:
0基础学习PyFlink——使用Table API实现SQL功能
大纲 Souceschemadescriptor Sinkschemadescriptor Execute完整代码参考资料 《0基础学习PyFlink——使用PyFlink的Sink将结果输出到Mysql》一文中,我们讲到如何通过定义Souce、Sink和Execute三个SQL,来实现数据读取、清洗、计算和入库。 如下图所示SQL是最高层级的…...
文心一言 VS 讯飞星火 VS chatgpt (123)-- 算法导论10.4 4题
四、用go语言,对于一个含 n个结点的任意有根树,写出一个 O(n)时间的过程,输出其所有关键字该树以左孩子右兄弟表示法存储。 文心一言: 在计算机科学中,左孩子右兄弟表示法是一种用于表示树状结构的方法,其…...
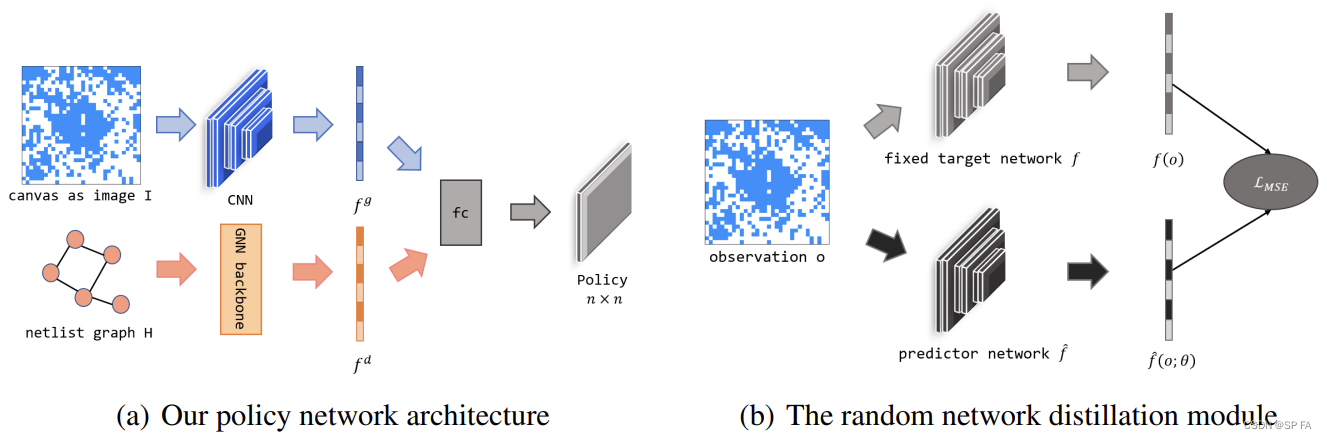
[读论文] On Joint Learning for Solving Placement and Routing in Chip Design
0. Abstract 由于 GPU 在加速计算方面的优势和对人类专家的依赖较少,机器学习已成为解决布局和布线问题的新兴工具,这是现代芯片设计流程中的两个关键步骤。它仍处于早期阶段,存在一些基本问题:可扩展性、奖励设计和端到端学习范…...

L2-1 插松枝
L2-1 插松枝 分数 25 全屏浏览题目 切换布局 作者 陈越 单位 浙江大学 人造松枝加工场的工人需要将各种尺寸的塑料松针插到松枝干上,做成大大小小的松枝。他们的工作流程(并不)是这样的: 每人手边有一只小盒子,初始…...

Android 使用ContentObserver监听SettingsProvider值的变化
1、Settings原理 Settings 设置、保存的一些值,最终是存储到 SettingsProvider 的数据库 例如: Settings.Global.putInt(getContentResolver(), "SwitchLaunch", 0); Settings.System.putInt(getContentResolver(), "SwitchLaunch&quo…...
二进制安装部署k8s
概要 常见的K8S按照部署方式 minikube 是一个工具,可以在本地快速运行一个单节点微型K8S,仅用于学习,预习K8S的一些特性使用。 Kubeadmin kubeadmin也是一个工具,特工kubeadm init 和kubedm join,用于快速部署k8s…...
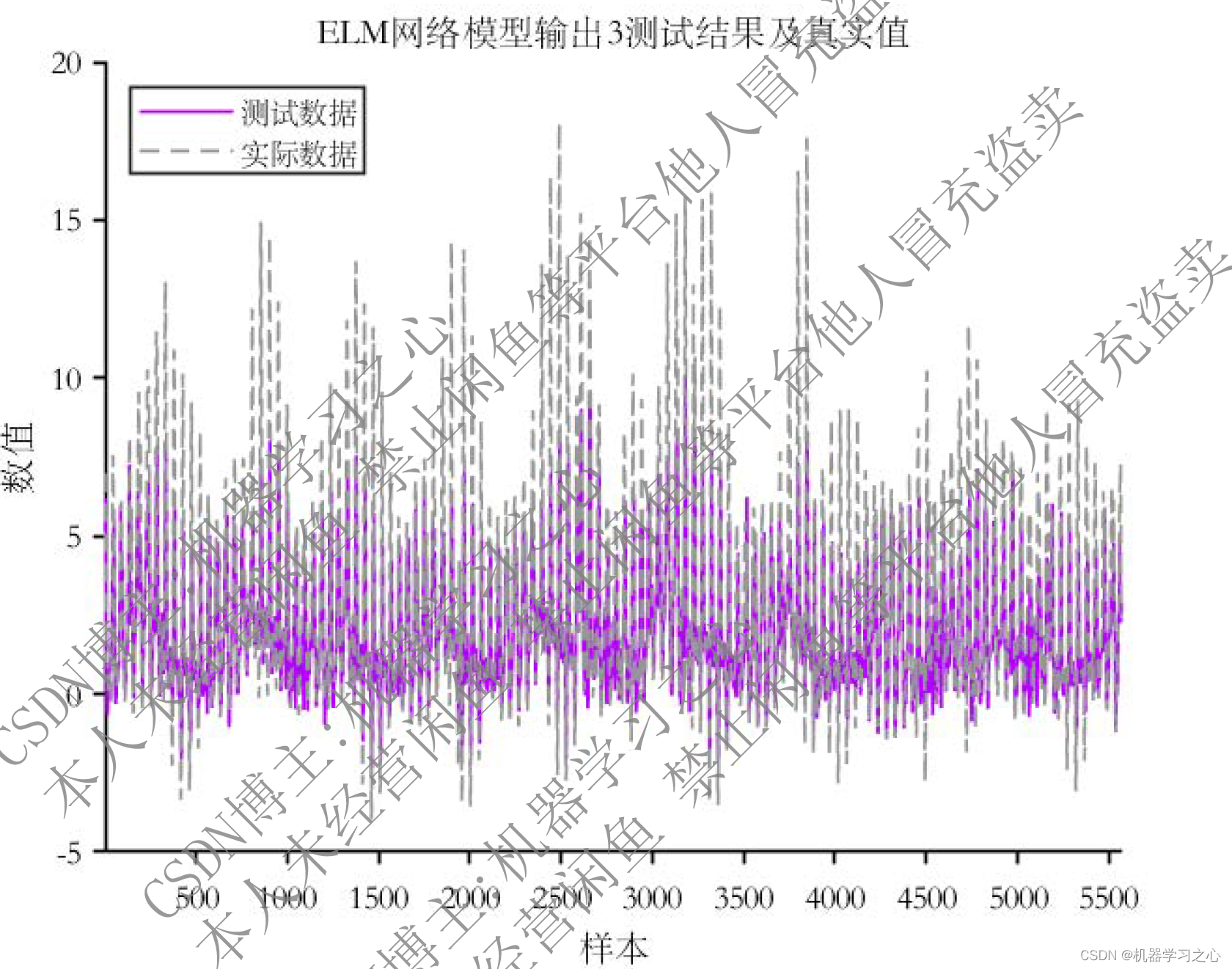
多输入多输出 | Matlab实现k-means-ELM(k均值聚类结合极限学习机)多输入多输出组合预测
多输入多输出 | Matlab实现k-means-ELM(k均值聚类结合极限学习机)多输入多输出组合预测 目录 多输入多输出 | Matlab实现k-means-ELM(k均值聚类结合极限学习机)多输入多输出组合预测预测效果基本描述程序设计参考资料 预测效果 基…...

ITSource 分享 第5期【校园信息墙系统】
项目介绍 本期给大家介绍一个 校园信息墙 系统,可以发布信息,表白墙,分享墙,校园二手买卖,咨询分享等墙信息。整个项目还是比较系统的,分为服务端,管理后台,用户Web端,小…...
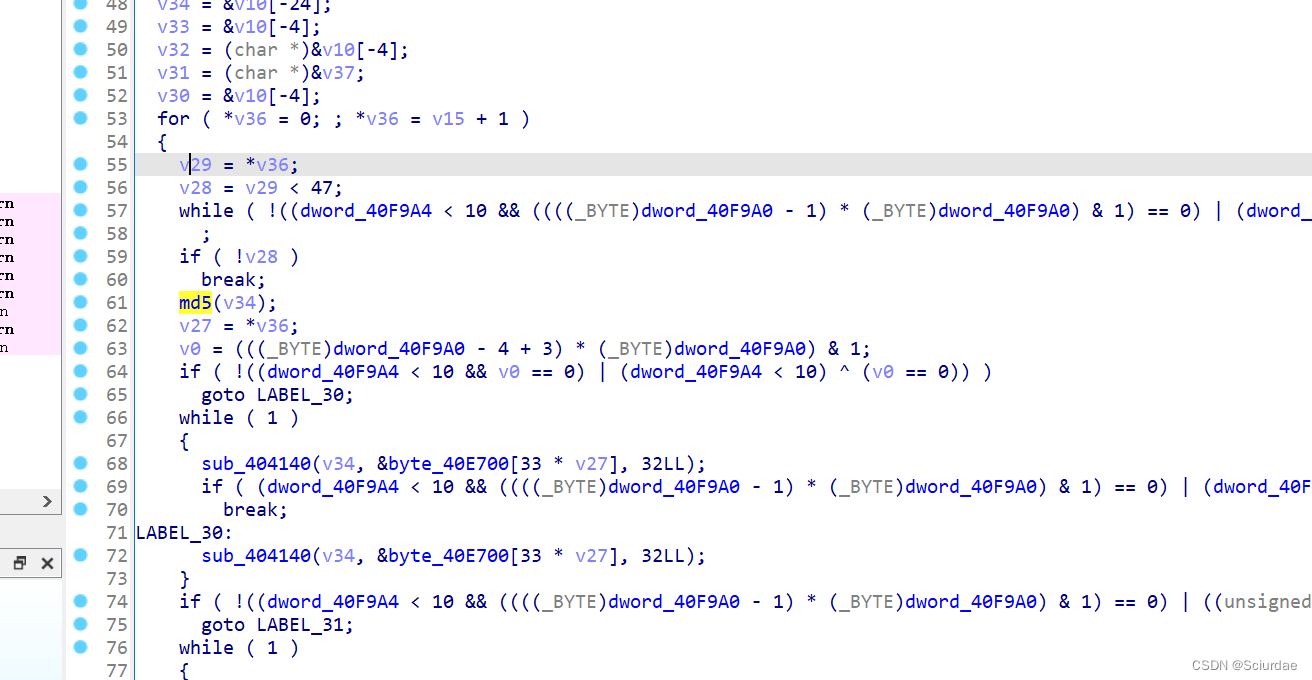
记 : CTF2023羊城杯 - Reverse 方向 Blast 题目复现and学习记录
文章目录 前言题目分析and复习过程exp 前言 羊城杯题目复现: 第一题 知识点 :DES算法 : 链接:Ez加密器 第二题 知识点 :动态调试 : 链接:CSGO 这一题的查缺补漏: 虚假控制流的去除…...

【数据结构练习题】删除有序数组中的重复项
✨博客主页:小钱编程成长记 🎈博客专栏:数据结构练习题 🎈相关博文:消失的数字 — 三种解法超详解 删除有序数组中的重复项 1.🎈题目2. 🎈解题思路3. 🎈具体代码🎇总结 1…...
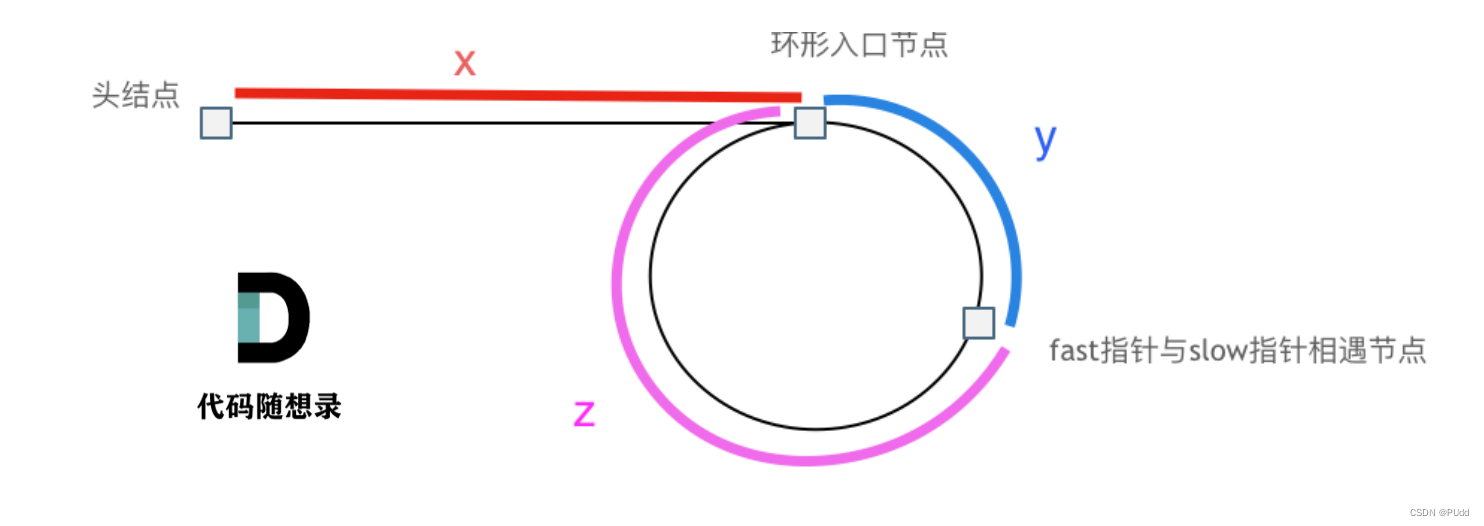
leetcode-链表
链表是一个用指针串联起来的线性结构,每个结点由数据域和指针域构成,指针域存放的是指向下一个节点的指针,最后一个节点指向NULL,第一个结点称为头节点head。 常见的链表有单链表、双向链表、循环链表。双向链表就是多了一个pre指…...
CV计算机视觉每日开源代码Paper with code速览-2023.10.27
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货 论文已打包,点击进入—>下载界面 点击加入—>CV计算机视觉交流群 1.【基础网络架构:Transformer】(Ne…...
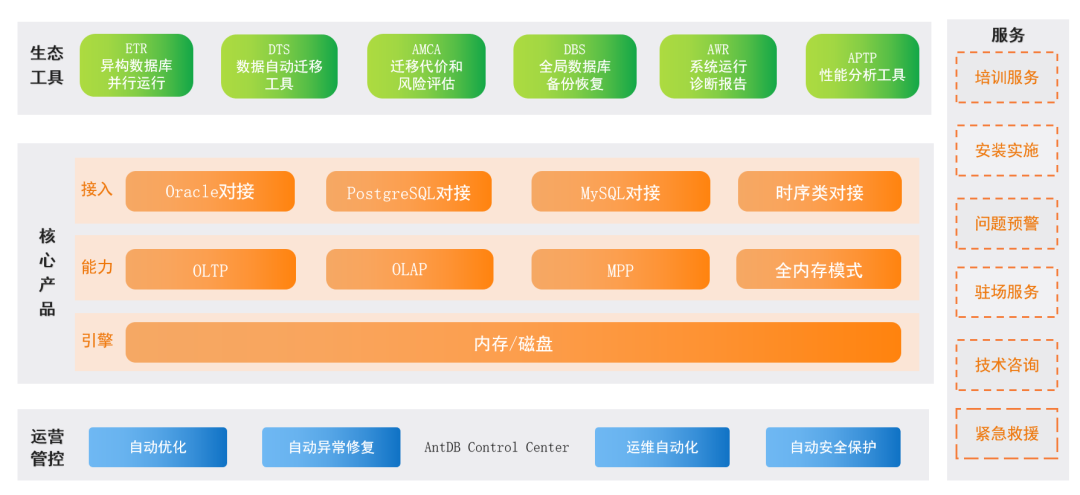
“赋能信创,物联未来” AntDB数据库携高可用解决方案亮相2023世界数字经济大会
10月14日,在2023世界数字经济大会暨京甬信创物联网产融对接会上,AntDB数据库技术总监北陌应邀发表《AntDB国产分布式数据库创新演进与高可用解决方案》主题演讲,就AntDB数据库助力客户数智化升级的高可用信创解决方案进行了详实、真挚地分享&…...
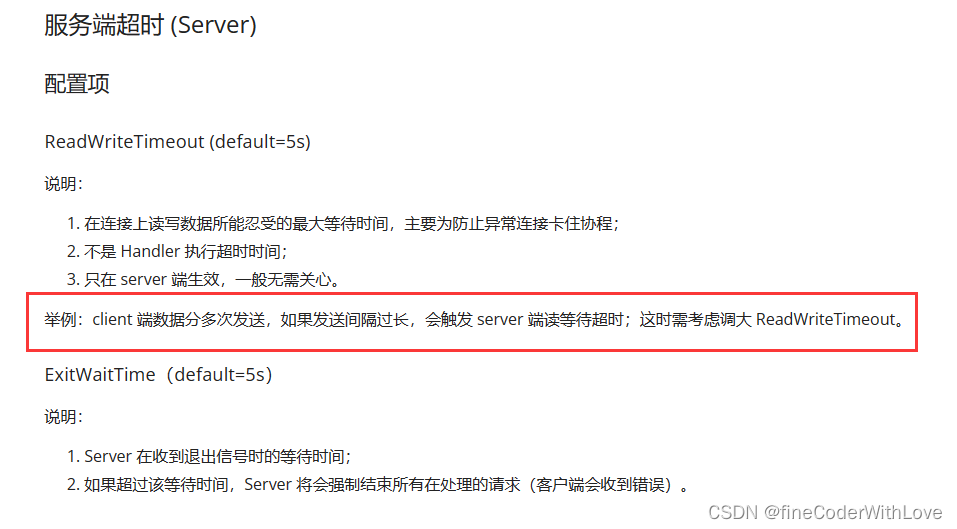
Kitex踩坑 [Error] KITEX: processing request error,i/o timeout
报错问题 2023/010/28 17:20:10.250768 default_server_handler.go:234: [Error] KITEX: processing request error, remoteService, remoteAddr127.0.0.1:65425, errordefault codec read failed: read tcp 127.0.0.1:8888->127.0.0.1:65425: i/o timeout 分析原因 Hert…...

前端移动web高级详细解析二
移动 Web 第二天 01-空间转换 空间转换简介 空间:是从坐标轴角度定义的 X 、Y 和 Z 三条坐标轴构成了一个立体空间,Z 轴位置与视线方向相同。 空间转换也叫 3D转换 属性:transform 平移 transform: translate3d(x, y, z); transform…...

Cesium 展示——对每段线、点、label做分组实体管理
文章目录 需求分析需求 对多组实体的管理,每组实体中包含多个点和一条线,并可对该组进行删除操作 分析 删除操作中用到了 viewer.entities.remove(radarEntity); 根据ID获取实体var radar = viewer.entities.getById(radar); viewer.entities.remove(radar );...

前端学习之Babel转码器
前言 Babel转码器可以将ES6转为ES5代码,从而在老版本的浏览器运行。这说明你可以用ES6的方式编码,又不用担心现有环境是否支持。 浏览器支持性查看:https://caniuse.com/ Babel官网:https://babeljs.io/ Babel安装流程 安装Babe…...

智能井盖监测系统功能,万宾科技传感器效果
智能井盖传感器的出现是高科技产品的更新换代,同时也是智慧城市建设中的需求。在智慧城市建设过程之中,高科技产品的应用数不胜数,智能井盖传感器的出现,解决了城市道路安全保护着城市地下生命线,改善着传统井盖带来的…...

LangChain+LLM实战---BERT主要的创新之处和注意力机制中的QKV
BERT主要的创新之处 BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的预训练语言模型,由Google在2018年提出。它的创新之处主要包括以下几个方面: 双向性(Bidirectional&…...
)
使用 @antfu/eslint-config 配置 eslint (包含兼容uniapp方法)
安装 pnpm i -D eslint antfu/eslint-config创建 eslint.config.js 文件 // 如果没有在 page.json 配置 "type": "module" const antfu require(antfu/eslint-config).default module.exports antfu()// 配置了 "type": "module" …...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

力扣-35.搜索插入位置
题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 class Solution {public int searchInsert(int[] nums, …...

[免费]微信小程序问卷调查系统(SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的微信小程序问卷调查系统(SpringBoot后端Vue管理端)【论文源码SQL脚本】,分享下哈。 项目视频演示 【免费】微信小程序问卷调查系统(SpringBoot后端Vue管理端) Java毕业设计_哔哩哔哩_bilibili 项…...

区块链技术概述
区块链技术是一种去中心化、分布式账本技术,通过密码学、共识机制和智能合约等核心组件,实现数据不可篡改、透明可追溯的系统。 一、核心技术 1. 去中心化 特点:数据存储在网络中的多个节点(计算机),而非…...

【HarmonyOS 5】鸿蒙中Stage模型与FA模型详解
一、前言 在HarmonyOS 5的应用开发模型中,featureAbility是旧版FA模型(Feature Ability)的用法,Stage模型已采用全新的应用架构,推荐使用组件化的上下文获取方式,而非依赖featureAbility。 FA大概是API7之…...
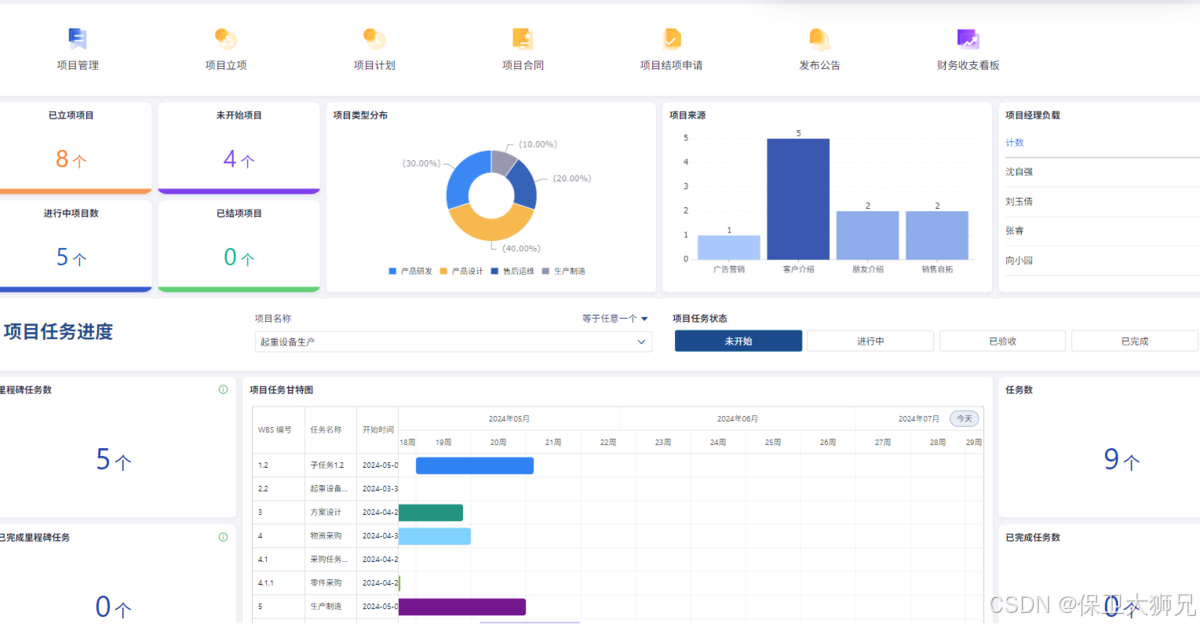
项目进度管理软件是什么?项目进度管理软件有哪些核心功能?
无论是建筑施工、软件开发,还是市场营销活动,项目往往涉及多个团队、大量资源和严格的时间表。如果没有一个系统化的工具来跟踪和管理这些元素,项目很容易陷入混乱,导致进度延误、成本超支,甚至失败。 项目进度管理软…...
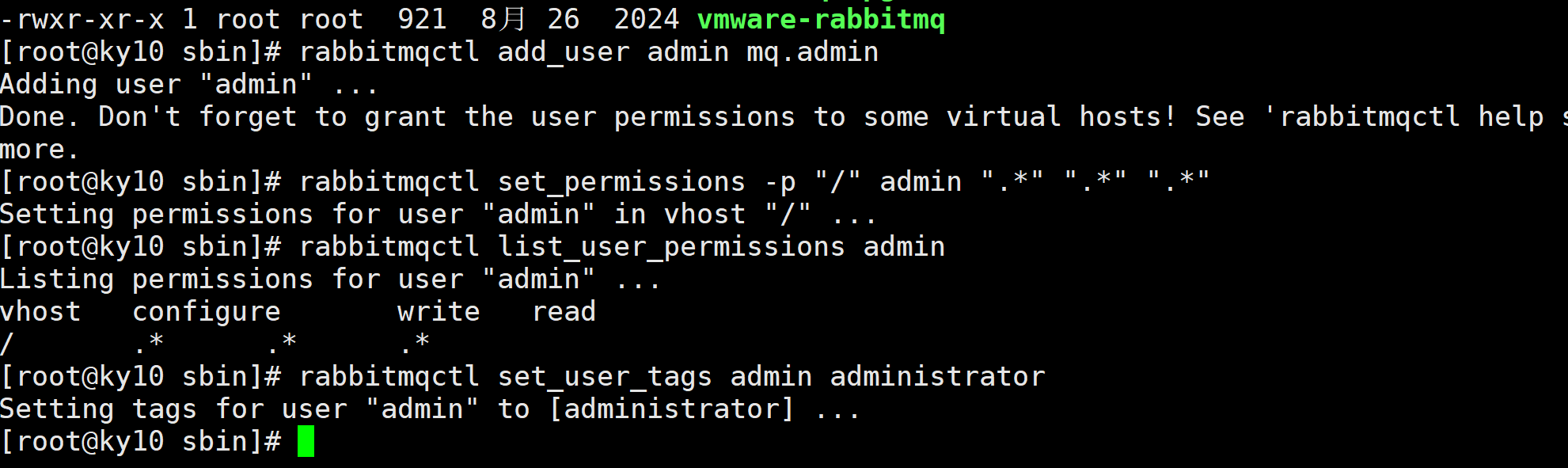
mq安装新版-3.13.7的安装
一、下载包,上传到服务器 https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.13.7/rabbitmq-server-generic-unix-3.13.7.tar.xz 二、 erlang直接安装 rpm -ivh erlang-26.2.4-1.el8.x86_64.rpm不需要配置环境变量,直接就安装了。 erl…...
实现p2p的webrtc-srs版本
1. 基本知识 1.1 webrtc 一、WebRTC的本质:实时通信的“网络协议栈”类比 将WebRTC类比为Linux网络协议栈极具洞察力,二者在架构设计和功能定位上高度相似: 分层协议栈架构 Linux网络协议栈:从底层物理层到应用层(如…...

全面解析网络端口:概念、分类与安全应用
在计算机网络的世界里,数据的传输与交互如同一场繁忙的物流运输,而网络端口就是其中不可或缺的 “货运码头”。无论是日常浏览网页、收发邮件,还是运行各类网络服务,都离不开网络端口的参与。本文将深入介绍网络端口的相关知识&am…...