TensorRT量化实战课YOLOv7量化:pytorch_quantization介绍
目录
- 前言
- 1. 课程介绍
- 2. pytorch_quantization
- 2.1 initialize函数
- 2.2 tensor_quant模块
- 2.3 TensorQuantizer类
- 2.4 QuantDescriptor类
- 2.5 calib模块
- 总结
前言
手写 AI 推出的全新 TensorRT 模型量化实战课程,链接。记录下个人学习笔记,仅供自己参考。
该实战课程主要基于手写 AI 的 Latte 老师所出的 TensorRT下的模型量化,在其课程的基础上,所整理出的一些实战应用。
本次课程为 YOLOv7 量化实战第一课,主要介绍 TensorRT 量化工具箱 pytorch_quantization。
课程大纲可看下面的思维导图

1. 课程介绍
什么是模型量化呢?那我们都知道模型训练的时候是使用的 float32 或 float16 的浮点数进行运算,这样模型能保持一个比较好的效果,但浮点数在提升计算精度的同时也导致了更多的计算量以及存储空间的占用。
由于在模型推理阶段我们并不需要进行梯度反向传播,因此我们不需要那么高的计算精度,这时可以将高精度的模型参数映射到低精度上,可以降低运算量提高推理速度。
将模型从高精度运算转换到低精度运算的过程就叫做模型量化
量化的过程与数据的分布有关,当数据分布比较均匀的时候,高精度 float 向低精度 int 进行映射时就会将空间利用得比较充分,如果数据分布不均匀就会浪费很大的表示空间。
量化又分为饱和量化和非饱和量化,如果直接将量化阈值设置为 ∣ x max ∣ |x_{\text{max}}| ∣xmax∣,此时 INT8 的表示空间没有被充分的利用,这是非饱和量化
如果选择了一个比较合适的阈值,舍弃那些超出范围的数值,再进行量化,那这种量化因为充分利用 INT8 的表示空间因此也被称为饱和量化。
模型量化及其意义可以总结为:
- 模型量化是指将神经网络的浮点转换为定点
- 模型量化主要意义就是加快模型端侧的推理速度,并降低设备功耗和减少存储空间,工业界一般只使用 INT8 量化模型。
本系列实战课程需要大家具备一些基本的量化知识,如果对模型量化知识模糊的看官的可以先观看 TensorRT下的模型量化 课程。
2. pytorch_quantization
我们先对 TensorRT 的量化工具箱 pytorch_quantization 做一个简单的介绍
它的安装指令如下:
pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com
要求:torch >= 1.9.1,Python >= 3.7, GCC >= 5.4
在博主之前学习的过程中,发现 pytorch 的版本和 pytorch_quantization 的版本如果不适配可能会导致一些问题。
目前博主的软件版本是:pytorch==2.0.1,pytorch_quantization==2.1.3
我们下面介绍下 pytorch_quantization 工具库中的一些函数、类和模块
2.1 initialize函数
首先是 quant_modules 模块中的 initialize() 函数,它的使用如下:
import torchvision
from pytorch_quantization import quant_modulesquant_modules.initialize() # quant_modules 初始化,自动为模型插入量化节点
model = torchvision.models.resnet50() # 加载 resnet50 模型
# model 是带有量化节点的模型
它的作用是初始化量化相关的设置和一些参数,因此我们需要在量化之前调用它。因为不同类型的神经网络层如 Conv、Linear、Pool 等等,它们所需要的量化方法是不同的,例如某个网络层当中的校准方法可能用的是 Max,也有可能用的是直方图,那这都可以在我们量化之前通过 initialize 来进行一个设置。
initialize 还有一个作用,那就是将模型中的 torch 网络层替换为相应的 quant 量化层,如下所示:
torch.nn.Conv2d -> quant_modules.quant_nn.Conv2d
torch.nn.Linear -> quant_modules.quant_nn.Linear
torch.nn.MaxPool2d -> quant_modules.quant_nn.MaxPool2d
也就是会把 torch 中对应的算子转换为相应的量化版本。
总的来说,initialize 用于在量化模型之前,对量化过程进行必要的配置和准备工作以确保量化操作时按照我们所需要的方式进行,这样的话有助于提高量化模型的性能。
在我们调用 initialize 之后,我们的模型结构会插入 FQ 节点,也就是 fake 算子,如下图所示:

那在之后的代码讲解部分我们会清晰的观察到在调用 initialize 前后模型结构的一些变化。
2.2 tensor_quant模块
然后是 tensor_quant 模块,它的使用如下:
from pytorch_quantization import tensor_quanttensor_quant.fake_tensor_quant()
tensor_quant.tensor_quant()
tensor_quant 模块负责进行张量数据的量化操作。那在模型量化过程中我们有两种量化方式:
- 模型 weights 的量化:对于权重的量化我们是对权重的每个通道进行量化,比如一个 Conv 层的通道数是 32,这意味着 32 个通道数的每个通道都有一个对应的 scale 值去进行量化。
- 模型 inputs/activate 的量化:而对于输入或者激活函数数值而言,它们的量化是对每个张量进行量化,也就是说整个 Tensor 数据都是用同一个 scale 值进行量化
具体见下图:

在上面的图中我们可以清楚的看到右边是我们的输入量化,inputs 的量化 scale 只有一个,而左边是我们的权重量化,weights 的量化 scale 有 32 个,这是因为 Conv 的通道数是 32,它有 32 个 channel,每个 channel 对应一个 scale。
下面的代码使用了 tensor_quant 模块中的函数对张量进行量化:
fake_quant_x = tensor_quant.fake_tensor_quant(x, x.abs().max) # Q 和 DQ 节点组成了 Fake 算子
quant_x, scale = tensor_quant.tensor_quant(x, x.abs().max()) # Q 节点的输出和 scale 值
我们先来看看 tensor_quant 中的两个函数
- tensor_quant.fake_tensor_quant
- 这个函数通常用于模拟量化的过程,而不是实际上执行量化,也就是我们通常说的伪量化
- 伪量化(Fake Quantization)是一种在训练过程中模拟量化效果的技术,但在内部仍然保持使用浮点数。
- 这样做的目的是使模型适应量化带来的精度损失,从而在实际进行量化时能够保持较好的性能。
- tensor_quant.tensor_quant
- 这个函数用于实际对张量进行量化,它将输入的浮点数张量转换为定点数的表示(比如从 floa32 转换为 int8)
- 这个过程涉及确定量化的比例因子 scale 和零点 zero-point,然后应用这些参数将浮点数映射到量化的整数范围内。
在上面的代码中,x 是我们的输入数据,x.abs().Max 代表我们使用基于 Max 的对称量化方法进行量化,函数的输出 fake_quant_x 是经过伪量化处理的张量,它看起来像是被量化了,但实际上仍然是浮点数。
tensor_quant 函数的输出 quant_x 是我们经过实际 int 量化处理后得到的 int 类型的张量,scale 则是我们用于量化过程中的比例因子。
2.3 TensorQuantizer类
下面我们来看看将量化后的模型导出要做哪些操作,实际上我们需要使用到 nn 模块中的 TensorQuantizer,它的使用如下:
from pytorch_quantization import nn as quant_nnquant_nn.TensorQuantizer.use_fb_fake_quant = True # 模型导出时将一个 QDQ 算子导出两个 op
其中 pytorch_quantizaiton 的 nn 模块提供了量化相关的神经网络层和工具,大家可以类比于 pytorch 中的 nn 模块。而 TensorQuantizer 是一个用于张量量化的工具类,use_fb_fake_quant 是它的一个类属性,用于控制量化过程中伪量化的行为。
我们将 use_fb_fake_quant 设置为 True 表明我们在导出量化模型时,希望将量化和反量化操作过程作为两个单独的 op 算子来导出,如下图所示:

可以看到上图中的红色框部分,导出的量化模型中包含 QuantizeLinear 和 DequantizeLinear 两个模块,对应我们的量化和反量化两个 op。
在我们将 use_fb_fake_quant 设置为 True 的时候,它会调用的是 pytorch 模块中的两个函数,如下:
torch.fake_quantize_per_tensor_affine
torch.fake_quantize_per_channel_affine
这两个函数会导出我们之前量化的操作,值得注意的是,在模型导出和模型前向阶段的量化操作并不是使用 tensor_quant 模块中的函数来实现的,而是使用 torch 中上述两个函数来实现,这样做是因为更容易转化成相应 的 tensorRT 的一个操作符,以便我们后续的部署。在模型训练阶段,我们则是调用 tensor_quant 函数插入 fake 算子来进行量化的,大家需要了解到在模型训练和前向阶段调用的函数的不同。
在 Torch-TesorRT 内部,fake_quantize_per_*_affine 会被转换为 QuantizeLayer 和 DequantizerLayer,也就是我们上面导出 ONNX 模型的两个 op 算子。


从上图中我们能清晰的看出在模型训练的时候和模型导出的时候 Q/DQ 节点所发生的一个变化,在模型训练的时候,我们是通过 tensor_quant 来插入 fake 算子来实现量化的,而在模型训练完成后导出 ONNX 时,我们是需要将 use_fb_fake_quant 置为 True,它会调用 torch 中的函数将 fake 算子的节点导出成 Q 和 DQ 两个模块。
2.4 QuantDescriptor类
接下来我们再来看下 QuantDescriptor 类,它的使用如下:
import torch
import pytorch_quantization.nn as quant_nn
from pytorch_quantization.tensor_quant import QuantDescriptor# 自定义层的量化
class QuantMultiAdd(torch.nn.Module):def __init__(self):super().__init__()self._input_quantizer = quant_nn.TensorQuantizer(QuantDescriptor(num_bits=8, calib_method="histogram"))self._weight_quantizer = quant_nn.TensorQuantizer(QuantDescriptor(num_bits=8, axis=(1), calib_method="histogram"))def forward(self, w, x, y):return self._weight_quantizer(w) * self._input_quantizer(x) + self._input_quantizer(y)
QuantDescriptor 类主要是用于配置量化的描述符,包括量化的位数,量化的方法等等。在上面的代码中,我们创建了一个自定义的量化层,该层对权重和输入进行量化,并执行加权乘法和加法操作
- 我们先创建了两个 TensorQuantizer 实例,一个是 _input_quantizer 用于输入量化,另一个是 _weight_quantizer 用于权重量化
- 我们使用 QuantDescriptor 来描述量化的参数,对于这两个量化器,都使用了 8bit 量化,量化的校准方法都设置为直方图校准
也就是说,我们使用 QuantDescriptor 可以实现自定义层的量化操作,在后续代码介绍的时候会使用到这个类。
2.5 calib模块
我们再来看下 pytorch_quantization 中的校准模块 calib,它的使用如下:
from pytorch_quantization import calibif isinstance(module._calibrator, calib.MaxCalibrator):module.load_calib_amax()
calib 校准模块包含 MaxCalibrator 和 HistogramCalibrator 两个校准类,其中 MaxCalibrator 用于执行最大值校准,在我们的量化训练中,我们通常会确定每个张量的一个动态范围,也就是它们的最大值和最小值,Max 方法通过跟踪张量的最大值来执行标定工作,以便在量化推理时能将其映射到 int 整数范围之内。
而对于 Histogram 直方图校准方法则是通过收集和分析张量值的直方图来确定我们的动态范围,这种方法可以更准确地估计张量值的一个分布,并且更好地适应不同数据分布的情况。
这两种校准方法在模型量化中都有它们各自的优势,具体选择哪种校准方法主要取决于我们具体的应用场景和数据分布的情况,我们通常是根据数据分布和量化的需求来选择合适的校准方法,以确保量化后的模型在推理时能保持一个比较好的准确性。
以上就是关于 pytorch_quantization 中的函数、类和模块的简单介绍。
总结
本次课程介绍了 pytorch_quantization 量化工具以及其中的一些函数、类和模块。在我们量化之前需要调用 initialize 函数来初始化量化相关的一些设置和参数。接着我们会使用 tensor_quant 模块来对张量数据进行实际的量化,而在量化完成后导出时我们需要将 TensorQuantizer 类中的属性 usb_fb_fake_quant 设置为 True,使得导出的量化模型包含 Q、DQ 两个模块。这是因为在模型训练阶段和前向、导出阶段的量化操作调用的函数是不同的,训练阶段是通过 tensor_quant 函数插入 fake 算子来量化的,而导出阶段是 torch 中的两个函数来实现的。
在量化过程中我们还会使用 QuantDescriptor 来配置量化的一些参数,包括量化位数、量化方法等等,最后我们简单介绍了 Calib 校准模块,它包含 Max 和 Histogram 两种校准方法。
下节我们正式进入 YOLOv7-PTQ 量化的学习😄
相关文章:
TensorRT量化实战课YOLOv7量化:pytorch_quantization介绍
目录 前言1. 课程介绍2. pytorch_quantization2.1 initialize函数2.2 tensor_quant模块2.3 TensorQuantizer类2.4 QuantDescriptor类2.5 calib模块 总结 前言 手写 AI 推出的全新 TensorRT 模型量化实战课程,链接。记录下个人学习笔记,仅供自己参考。 该…...

【23真题】知识点覆盖全!有罕见判断题!
今天分享的是23年烟台大学833的信号与系统试题及解析。 本套试卷难度分析:本套试题内容难度中等偏下,题目难度不大,但是题量较多,考察的知识点全面,比较多的考察了对信号波形以及频谱图的画法,值得注意的是…...

K8s外部网络访问之Ingress
K8s外部网络访问之Ingress 1 简介2 安装ingress-nginx-controller2.1 下载ingress部署文件2.2 修改deploy.yaml文件参数2.2.1 修改镜像源2.2.2 修改部分参数2.2.3 部署ingress-nginx2.2.4 查看部署结果3.ingress-nginx应用3.1 制作镜像3.2 配置TLS secret3.2.1 创建HTTPS证书3.…...

中文编程工具免费版下载,中文开发语言工具免费版下载
中文编程工具免费版下载,中文开发语言工具免费版下载 中文编程工具开发的实际部分案例如下图 编程系统化课程总目录及明细,点击进入了解详情。 https://blog.csdn.net/qq_29129627/article/details/134073098?spm1001.2014.3001.5502...

昂首资本严肃且专业地探讨波浪理论第一波
很多投资者已经了解了波浪理论第一波,今天昂首资本和各位投资者再加深一下理解,让我们严肃且专业地探讨一下第一波。 以小时价格图表举例,第一波的起始点存在一个看涨反转棒。请注意,这个棒形结构对应了比尔威廉姆斯交易策略三智…...

《论文写作》课程总结
《论文写作》课程总结 前言 本文是我对《论文写作》课程的一个学习总结. 在上这门课程前我已经开始了论文写作, 我觉得这门课对我的最大作用就是将我以前从视频、博客、写作和经验贴等地方学习到的经验串起来了. 接下来, 我会根据我的收获对这门课做一个总结. 文章目录 《论文…...
基于SSM的作业提交与查收系统设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:采用JSP技术开发 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目&#x…...

Hololens2 报错Microsoft.Windows.System缺少
文章目录 前言Hololens2 报错Microsoft.Windows.System缺少错误提示如下解决方法小结 前言 在Unity开发Hololens2 时候,需要导入很多工具和库,有些问题,也就第一次导入的时候会遇到。好记性不如烂笔头嘛,记录一下。 Hololens2 报…...
nginx: [emerg] bind() to 0.0.0.0:18888 failed (98: Unknown error)问题解决办法
周末断网,今天来了之后,nginx出现这个问题,本站基本搜索的都是端口被占用问题,我试着杀掉所有占用端口的进程,解决办法 1.killall -9 nginx 2.然后启动(./nginx)nginx(PS:不要./nginx -s relo…...
基于 Redis + Lua 脚本实现分布式锁,确保操作的原子性
1.加锁的Lua脚本: lock.lua --- -1 failed --- 1 success--- getLock key local result redis.call(setnx , KEYS[1] , ARGV[1]) if result 1 then--PEXPIRE:以毫秒的形式指定过期时间redis.call(pexpire , KEYS[1] , 3600000) elseresult -1;-- 如果value相同&…...
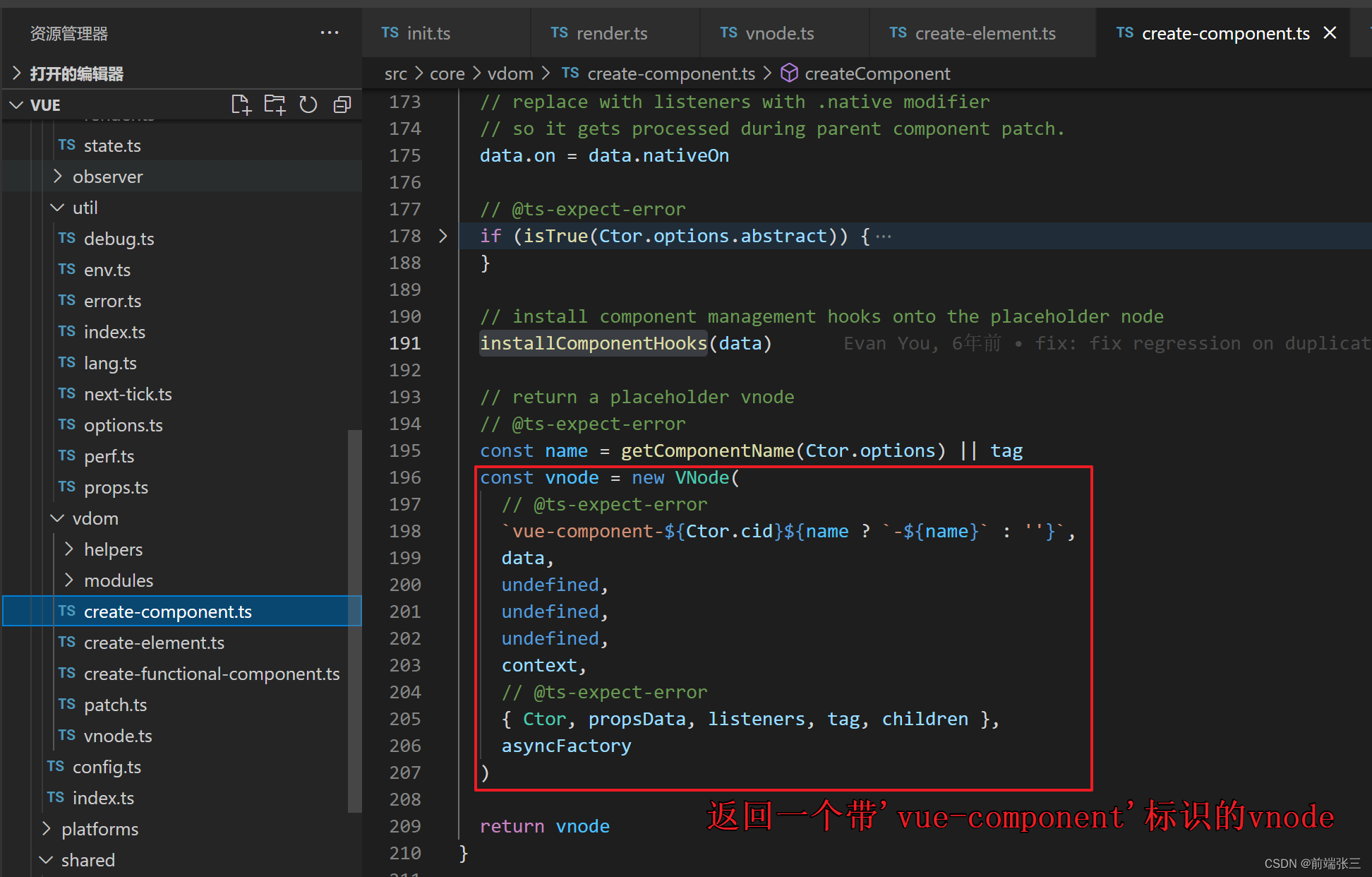
vue源码分析(七)—— createComponent
文章目录 前言一、createComponent 参数说明二、createComponent 源码详解1.baseCtor的实际指向2.extend 方法3.判断Ctor是否是函数的判断4.installComponentHooks方法5.返回一个带标识的组件 vnode 前言 createComponent文件的路径: src\core\vdom\create-componen…...

vue实现图片分页
本小节学会使用v-show和click 、v-bind,v-bind可以简写为: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"…...

Baklib专注:企业数字内容体验与知识管理
随着科技的发展,消费者对数字体验的依赖程度攀升,品牌正面临着越来越大的压力。数字化体验作为当下最热门的话题之一,无论是传统企业还是互联网企业,都在积极探索创新方案和具体措施,从而提高用户的数字化体验…...

C++ 标准库随机数:std::default_random_engine
库头文件 #include <random> // 通过种子值设置随机数生成器 std::default_random_engine rng(seed);// 不设置种子值,使用默认值 std::default_random_engine rng; // 生成一个0到9之间的随机整数 int random_int rng() % 10;// 生成一个0到1之间的随机浮…...

Python requests之Cookie
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium 在某些需要登录的网站或者或者应用,假如我们需要抓取登录后的内容,技术上本质通过session会话实现。服务器端存会话信息,浏览器通过Cookie携带…...

【嵌入式项目应用】__嵌入式中,映射表的应用例子!
目录 一、嵌入式中的映射表是什么? 二、映射表在串口数据解析中的应用 1. 数据结构 2. 指令、函数映射表 3. 串口解析函数实现 三、映射表在UI设计中的应用 1. 数据结构 2. 函数映射表 3. 定义两个变量保存当前场景和上一个场景 4. 按下Up按键 跳转到指定场…...
react中的useState和useImmer的用法
文章目录 一、useState1. 更新基本类型数据2. 更新对象3. 更新嵌套对象4. 更新数组5.更新数组对象 二、Immer1. 什么是Immer2. 使用use-immer更新嵌套对象3. 使用useImmer更新数组内部的对象 一、useState react中文官网教程 1. 更新基本类型数据 在函数式组件中,…...

Can‘t compile code “launch: program <program_path> does not exist “
StackOverflow上有一个类似的提问 我的情况很特殊,上面的回答没有解决我的问题,最后我发现是我的cpp文件名称为数字开头(类似于1_floy.cpp),把名字里的数字挪到后面就好了。。。。。...

Mac电脑上升级nodejs
第一步,先查看本机node.js版本: node -v 第二步,清除node.js的cache: sudo npm cache clean -f 第三步,安装 n 工具,这个工具是专门用来管理node.js版本的,别怀疑这个工具的名字,…...
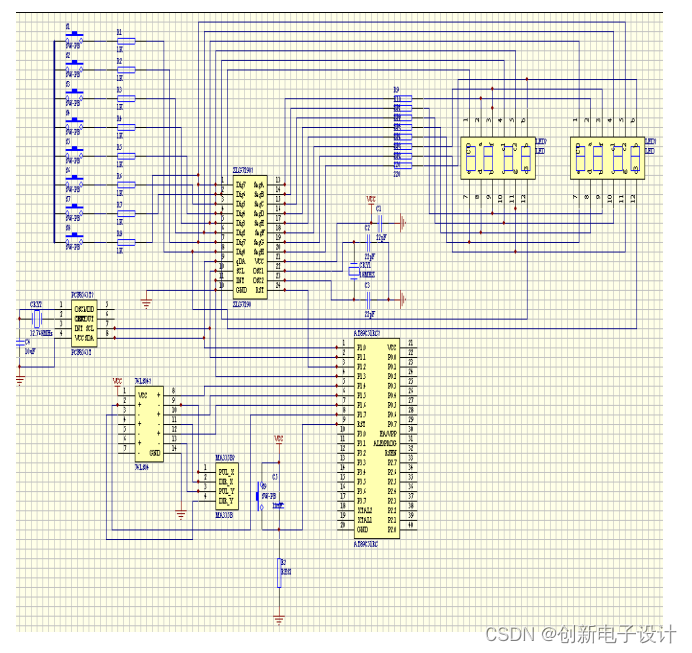
基于单片机的太阳跟踪系统的设计
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 技术交流认准下方 CSDN 官方提供的联系方式 文章目录 概要 一、设计的主要内容二、硬件电路设计2.1跟踪控制方案的选择2.1.1跟踪系统坐标系的选择2.2系统总体设计及相关硬件介绍…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

区块链技术概述
区块链技术是一种去中心化、分布式账本技术,通过密码学、共识机制和智能合约等核心组件,实现数据不可篡改、透明可追溯的系统。 一、核心技术 1. 去中心化 特点:数据存储在网络中的多个节点(计算机),而非…...