CPython解释器性能分析与优化
原文来自微信公众号“编程语言Lab”:CPython 解释器性能分析与优化
搜索关注 “编程语言Lab”公众号(HW-PLLab)获取更多技术内容!
欢迎加入 编程语言社区 SIG-元编程 参与交流讨论(加入方式:添加文末小助手微信,备注“加入 SIG-元编程”)。
作者 | 张强
整理 | Hana、IceY
作者简介
南京大学计算机科学与技术系四年级直博生,研究方向为“解释器性能分析与优化”,研究兴趣是偏底层、偏工程的项目编写与性能调优。
论文
https://doi.org/10.1016/j.scico.2021.102759
视频回顾
编程语言技术沙龙 | 第12期:CPython 解释器性能分析与优化
1 背景介绍
首先需要明确,Python 作为一门语言,其实只是一个存在于概念中的规范,它本身并没有限制开发者去怎样实现它。因此就有 IronPython、Jython、PyPy 和 Pyston 等具有不同特性的实现。不过在实践中,大部分情况下大家用的都还是 CPython。这是因为,首先它作为一个参考实现,能够支持全部语言特性。还有 PyPI 这个仓库可以 pip install 第三方包,其他的实现可能因为兼容性等问题用不了仓库里的包。最后还一个原因,某些行为到底是语言标准的要求,还是实现定义的,或者甚至是未定义的,Python 并没有一个非常明确且详细的描述,所以这时候开发者会以 CPython 作为事实上的标准。
接下来的报告也只关注 CPython。
CPython 解释器
CPython 可以看成由一个编译器和一个虚拟机构成。前者把将要执行的 Python 代码编译成一个中间表示,也就是字节码。后者执行的时候就不用再去理会复杂的语法结构。
不过 CPython 的这个编译器非常的简单甚至简陋。它把每个函数视为独立的编译单元,不会实施任何函数间优化。函数内优化也几乎没有,比如公共表达式提取这种,不存在的。甚至它还会舍弃掉类型信息,所以对象一律视为 object,哪怕使用了 type annotation 语法显式标注了类型也不例外。

CPython 字节码
这有一个阶乘函数和它的字节码。字节码中每个指令都固定为两字节,一字节的 opcode 和一字节的 oparg。

下图展示了 CPython 内部负责指令解释的函数,可以看到是基于栈式架构。

2 性能分析
接下来是性能分析部分。
采样法的应用
插桩法的问题
测量程序中某个部分的时间开销,最容易想得到的办法自然是插桩,开头结尾时间一测再一个减法就好。但是它有一些问题:
首先插入的测量代码本身有时间代价,然后插桩后的代码会在寄存器分配等各个方面和原来的代码有所不同。而且,现代 CPU 基本会采取乱序执行,插桩的位置在实际执行中可能就不会对应它那一段代码的开头结尾了。
当然,使用更加先进的插桩方法和工具可以缓解缓解前面的问题,但依然有两个难点。首先被干扰的部分就是被插桩的部分,程序中有插桩和没插桩的各个部分受到的干扰程度不一样,可能让结果产生畸变。另外,插桩需要提前设置位置,无法在没有假设的前提下进行探索性的实验。
插桩法不适用于对解释器进行整体上的性能分析。
采样法
因此我们使用采样法来对解释器进行性能分析。它的原理是,程序每执行一段给定时间就会被中断,然后采样器记录下当前的状态,比如寄存器值,或者某一段内存里的数据。在分析的时候,就用这些样本的比例,或者说分布,去近似程序实际的开销分布。实际上就是用一系列离散点代替一段连续的时间。

因此采样法不需要修改被测程序,直接用正常编译的版本就行。而且,周期性中断对被测程序而言是随机的,程序里每个部分都可能受到影响,结果不会被带偏。最后,除了时间(也就是 CPU 周期),还可以用其他事件执行采样,比如分支跳转、缓存失效等等,这样还可以得到其他性能事件在程序中的分布。
采样法(误差控制)
当然,采样就意味着误差是必然的,只能设法减小。最简单粗暴的是增加运行时间或次数,样本够,精度就够。但如果时间有限的话,就只能增大采样频率了,在同样的时间内更频繁地中断程序获取样本,不过这样对程序的干扰也就大了,要掌握火候。

最后还有一个值得注意的,也不是光样本数越多越好,要足够随机,样本才能有代表性。如果采样的节奏和程序运行的节奏刚好对上,产生 lockstep sampling 现象,结果就会很离谱了。

采样法(误差估计)
如果采样是随机的话,样本就服从超几何分布。用切比雪夫不等式推一下可以发现,误差与样本量根号的倒数成正比。

我们用的采样工具是 Linux perf,它采集一个样本的开销大致在 10000 个 CPU 周期。所以我们把采样周期 rrr 设置为 5000011,大两个多的数量级,保证在采样的影响相对较小的情况下可以收集更多样本。值得注意的是,这里用 5000011,而非整 5000000,因为这是一个质数,可以防止前面提到的 lockstep sampling 问题。单个 benchmark 运行 400 秒,大概获得 n=3.8×105n=3.8\times10^5n=3.8×105 个样本。
数据代入上述公式可以确认,误差已经控制在合理的范围内,样本量足够了。

字节码开销
拆解
接下来是从字节码的角度分析 CPython 的性能。
首先是开销的拆解,后面还会有一些具体问题的分析。
从 C 栈帧到 opcode 开销
采样工具加上 addr2line 工具,可以帮我们还原中断发生时解释器本身的 C 语言调用链,那怎么知道当前正在处理的 Python 指令是哪种 opcode 呢?我们的方法是逆着调用链回溯,直到找到 _PyEval_EvalFrameDefault 函数,这个负责字节码指令解释的函数。

它有一个大的 switch-case 负责处理各种 opcode,看它当前正在执行哪个 case 的代码就行。因为只看最顶端的一个 Python 指令,所以像图 c 中带 Python 函数调用的,它的开销就被判定给 BINARY_ADD 而非 CALL_FUNCTION。然后有部分库函数是用 C 语言写的,我们也把它标记出来了,像图 d 这里,它的开销就不属于任何一个 Python 指令。
使用频率与时间开销
Python 3.9 定义了 119 种 opcode,如下左右两幅图分别列出了使用频率最高和运行时间开销最高的 20 个。所有数据都是在 48 个 benchmark 上独立收集的。Q1、Q2、Q3 是不同 benchmark 结果的四分位数,Q2 是中位数,图中按中位数排序。

- 最突出的结果是各种 LOAD 还有 STORE,特别是其中的 LOAD_FAST,占了 27.5% 的使用量,排名垫底的 99 个指令使用频率加起来都没它一半多。
- 然后是右边的时间开销,两个 CALL 排名第一第二。
- 再来找找加减乘除,左移右移,取与取或等等这些运算符对应的 opcode,结果除了一个 BINARY_ADD(对应加法运算符),无一上榜。也就是说,从多数 benchmark 整体看来,运算符的使用量还真没有我们直觉中预期的那么多。
opcode 分类
直接列出来可能不好发现多少信息,接下来就把 opcode 分成六个类:
- 首先是那一堆 LOAD 和 STORE,其实还有用的比较少的 DELETE,他们都是用来读、写、删某些目标位置,根据目标的种类的不同,他们占据了三个类:

- name access,名字访问,访问常量或者变量。
- attribute access,属性访问,用 a.b 的形式访问对象的属性。
- element access,元素访问,用 a[b] 的形式访问容器内的元素。
- 函数调用有 4 种不同的 opcode,对应不同的调用语法,把它们也归为名为 function call 的一类。

- 各种运算符号,也归为 math operator 一类。

- 剩下 63 中 opcode,不分了,丢在一起,就叫它杂类 miscellany 好了。
频率与开销(分类占比)
不同类别的使用频率和运行开销总结就是这个箱线图了。

- name access 的频率最为突出,占了一半了,说明常量和变量的访问非常频繁,开销也不小。
- Python 因为是动态类型,attribute access 就意味着要查字典,所以比较耗时。
- 然后是 function call,占了 16.0% 开销,说明 Python 上下文切换代价挺大的。好消息是,现在还是 beta 版本的 Python 3.11 加了一堆优化来缓解这个问题,所以未来这部分的开销会低一点。
- math operator 这边,中位数都不大,但是有少数几个 benchmark 专门测试科学计算的,数值拉得很高。
- element access 和 miscellany 数据都不怎么突出,就不讨论了。
名字访问问题
讨论了整体上的情况,再来看一些具体问题,首先是关于名字访问。
名字访问,这里的名字其实有两种不同的访问机制。
图里左边的是 array-style,包括常量、局部变量、还有闭包变量,这些名字是保存在数组中的,访问的时候直接数组加下标就行了。
图里右边的是 dict-style,包括全局变量和内置变量,由于 Python 的语法限制,他们不能用数组保存,所以 CPython 用了哈希字体,访问时候得查字典。

后者的复杂度比前者高多了,但是除了访问数据这个核心操作外,每个指令都有一堆共同的附加工作。所以,最终表现就是左边 array-style 的访问不管是从频率还是开销都占了上风,尤其是加载常量和读写局部比变量三种 opcode。那么有没有办法消除这几个指令?有!使用寄存器式解释器架构就是一种方法。这会在后面关于性能优化的部分展开讲解,所以就不继续展开。
动态类型的问题
第二个问题与动态类型有关。
动态类型之负担
这里可以总结出两个方面的负担:
- 其一是关于属性访问的。在 C++ 和 Java 等静态语言里,属性访问就是首地址加上一个偏移(当然如果有多态的话要利用虚函数表间接索引)。而在 Python 中,它需要依次查找对象本身、对象类型、对象父类乃至祖父类各自的哈希字典。如果类型里还定义了 __getattr__等魔法函数的话,整个过程还会更加复杂。
- 其二是关于数学运算的。因为类型不确定,即使是两个 int 或者两个 float 相加,也要和其他对象一样过一遍完整的流程,依次检查左右类型是否定义了处理例程,然后执行间接调用。无法转化为直接调用对应的底层过程。

静态推断之困难
很自然的一个想法是,能不能在编译时候,用静态分析的方法尽可能地推断出一些对象的类型,然后利用类型信息生成优化过的字节码,减小那两部分的开销。理论上是可以,但是第一步类型推断就会很棘手。
首先是对全局变量的静态推断是无法做到安全可靠的,他们可能在模块外或者通过反射的形式被意想不到地修改。然后普通的 Python 类型及其对象,允许用户在它定义之后再添加或者删除属性,这其中包括对运算符的重载,所以就算推断出来了类型也没有用。
唯一能够安全地进行静态推断的,就是从 123 和 “hello world” 这些 int 和 str 类型的字面值常量出发,推断出的一些局部变量的类型。并且这些内置类型还都有一个优点,就是不允许用户修改它们的属性。所以理论上来说,推断出来了类型也就能够优化它们的属性访问和数学运算。
但是话也不能说得这么绝对,比如看下面这个例子,这两个局部变量,不管怎么赋值,在下一行打印出来的类型都表明它们是字符串。其实是因为我们在前面(当然也可能是模块外)配置了 settrace,它还是可以反射地修改局部变量值。不过这个特性官方文档也没有说清楚到底是语言规范还是 CPython 自己的行为,所以也不好说。
from sys import settracedef my_tracer(frame, event, arg = None):if frame.f_code is foo.__code__:frame.f_locals['v'] = 'surprise'return my_tracersettrace(my_tracer)def foo():v = 42print(type(v))v = 3.14159print(type(v))foo()
输出:
<class 'str'>
<class 'str'>
失败的尝试
那先不考虑 settrace 这种近乎于魔法的东西,我们能不能进行静态优化呢?很久之前有过这方面的尝试。
从字面值常量出发,在函数内尽可能地推断出局部变量的类型,然后为它们的生成一些类型特化之后的指令。比如上面表格第四行这里,如果一个加号左右两边都是 str 类型,那么就用 STR_CONCAT 指令替代 BINARY_ADD,运行时就不必检查类型,直接调用字符串连接过程。但是效果呢?如下面的这个表格所示,在添加了类型推断和字节码特化之后,程序的运行时间消耗和 baseline 不相上下。还有另外几个 benchmark 的结果没有列出来,总之最后的结果是,比 baseline 还差一点点。所以这个尝试算是给了一个历史教训吧,光靠静态推断是没用的。

属性访问
下面先来看用于属性访问的 4 种 opcode 的开销。

它们在 48 个 benchmark 的中位开销是 8.9%,在两个 benchmark 上甚至占了超过一半的开销。其中,又以 LOAD 的开销为主,STORE 开销占比相对少些,DELETE 是几乎不用的。
优化的余地还是很大的,所以 CPython 3.10 加入了 per-opcode cache 机制来加速 LOAD_ATTR 的过程,然后 3.11 又进一步再优化了一点。
可优化的余地那么大,为什么前面那个尝试失败了?请看下图。

我们把所有 benchmark 的 LOAD_ATTR 和 LOAD_METHOD 开销画了出来,分别在横轴上方和下方。然后,又统计了下访问 int 和 str 等这种内建类型属性在其中的次数占比,对应为图中有颜色的区域。这意味着什么?意味着:
- 就算假设内建类型的单次属性访问耗时和自定义类型一样
- 然后我们可以推断出所有属于内建类型的 Python 变量类型
- 并且把它们的属性访问开销降低到 0
- 整个过程还不带一点副作用
加上这一堆理想化的假设,最后也就是能砍掉图中有颜色这部分的开销。所以,想要降低属性访问开销,还得关注用户自定义的类型。
再来看数学运算符部分的开销。其实它们只在多数 benchmark 上开销并不大,中位数只有 4.6%,不过在少数 benchmark 上还是举足轻重的。

比如 pidigits 上,开销占比 96.5%。不过,这么多开销,并不完全是因为动态类型造成的,我们把其中开销按照性质分为三种组成部分:
- 第一个是 opcode handling,也就是在前面那个 _PyEval_EvalFrameDefault 函数里面,解释字节码所对应的开销
- 第三个是 calculation,是以及执行确定类型的底层计算的耗时
- 夹在中间的第二个 overloading,它的开销就是和动态类型有关的,比如查找类型方法重载,然后执行间接调用这种
可以看到开销主要来自于底层计算,对特定类型的运算符操作添加一些 “捷径”,收效会有,但不会太多。而且,也不要用静态推断的方法来添加这些捷径,因为能推断成功的数量非常有限。CPython 3.11 用动态特化的方法尝试了下优化,官网的数据只说了最好可以加速 10%,没有提到平均效果。
小结
总的来说,从字节码角度分析性能,有以下一些小结论。
- 寄存器架构是我们后面性能优化部分会讲到的一个尝试。
- 基于静态类型推断的优化可以认为是一条死胡同。
- 然后优化一般类型的属性访问以及函数调用开销这方面,CPython 确实在最近几个版本里正在改进它们。
解释器开销
拆解
接下类,从另外一个角度来分析 CPython 的性能,也就是把解释器本身看作一个普通的程序,看看它的哪些模块开销占比最大。
CPython 解释器的构成
先来看 CPython 编译之后的组件构成。

它包括了一个解释器本体,一堆动态链接库,还有一些 Python 写的标准库代码。
然后从解释器虚拟机的视角,标准库 Python 代码和用户 Python 代码其实没多大区别。
而那些二进制的动态链接库,其实一般都是实现一些的特定事务,比如 json 和 pickle 的处理,当然 tensorflow 和 PyTorch 等机器学习库的二进制模块也属于此类。
二进制文件粒度
然后来看前面提到的那几个组件在运行时的开销占比,如图所示:

- 红色的解释器本体,占比是最大的
- 绿色的内置动态链接库,只有在与测试 json、pickle、xml 性能有关的 benchmark 上才有所表现
- 青色的外部动态链接库,因为我们把 C 语言标准库等系统库也算在里面,所以或多或少各个 benchmark 上都占一点
- 黄色的是系统内核态的开销,只有在一些需要频繁进行系统调用的 benchmark 上比较明显
- 图里红色网格线部分是 _PyEval_EvalFrameDefault 函数的开销,一个函数占比大概四分之一左右。
源文件粒度
把前面解释器本体的开销进一步分解,从 CPython 的 C 语言源文件粒度来看。这个图是一个小提琴图,表明不同 benchmark 上开销数值的分布,左半部分是局部图,用比较精细的比例尺展开 10% 以内的开销分布。

- 最突出的是 Python/ceval.c,这是负责解释执行的。
- 下面几乎全部是 Objects / 目录下的源文件,也就是对各种对象的操作。
- 这其中另类的一个是一个名为 Modules/gcmodule.c 的源文件,它和 GC 有关。
- 所有没有列出的源文件汇总在最下面一行,它们单个文件开销中位数没超过 0.1%,加起来也没超过 7.7%。所有如果是优化 CPython 的化,关注列出来的源文件就好了。
函数粒度
然后是函数粒度。这部分其实倒也没什么新发现,也就是印证了前面提到的自定义类型属性访问开销和函数调用上下文开销挺大的。

函数粒度(列出内联函数)
但是如果把内联函数独立出来,那就有意思多了。这里可以看到有两个函数排名第二第三,分别是 _Py_INCREF 和 _PY_DECREF。因为 CPython 使用了引用计数,它们分别负责把引用计数 + 1 或者 - 1。非常简单的两个函数,而且也内联起来了,但是开销占比却不小,我们后面会讨论它们。

语句粒度
最后是语句粒度,也就是 _PyEval_EvalFrameDefault 函数内部的开销分解。这一部分比较琐碎,如果不是专门从事 CPython 优化的开发人员可以不必在意其中细节。不过有一点值得留意,就是这个 dispatch 的开销。什么是 dispatch 呢?CPython 不是需要解释执行各个字节码指令么,然后解释完一个指令,需要取下一个指令,然后解码,再跳转,这就是 dispatch。如下图所示,CPython 就用一个名为 DISPATCH(当然还要 FAST_DISPATH)的宏来实现这一系列操作。它占了整个解释执行过程开销的三分之一。我们后面也会讨论和它有关的问题。

GC 问题
不过,还是先从到前面提到的 GC 问题开始讨论。
各种各样的 GC 算法,不说成千上万也得有成百上千。但是变来变去,归其根本,就两个思路:
- 一个是基于追踪,它从若干个根对象开始,进行可达性分析,不可达的对象就是垃圾,执行回收。缺点呢,就是不能逐个回收,程序运行一段时间后就要停下来等垃圾回收器运行一遍。
- 另一个是基于引用计数,每个对象一个计数器,计数器一旦变成 0 就回收。它很简单、也可以逐个回收对象,但是有一点空间成本,而且最为致命的是存在循环引用问题。
CPython 中的 GC
那 CPython 是怎么做的呢?
最古老的版本,Python 1.x,只有引用计数,如果有循环引用,不好意思,Python 程序员需要手动解决问题。到了 Python 2,它终于加上了一个基于追踪的 GC 模块了,所以不用再去操心循环引用了。因此,CPython 用的是一种混合的 GC 实现,引用计数有,追踪也有。

那哪个部分对性能的影响最大呢?我们对比了不同 benchmark 上二者的开销的大小,以散点图的形式画了出来。这里的横座标 LOPC,是我们自定义的一个度量,就不展开,只需要知道它代表了 benchmark 自身的某种特性即可。总的来说,可以看到,tracing 的开销处于较低水平,而且不同 benchmark 之间变化不太明显。而引用计数的开销,就大了一个数量级了,而且基本上和这个 LOPC 度量正相关。

引用计数的IPC性能
引用计数,明明就是把一个整型变量 + 1/-1 的事,这么简单的操作为什么会有这么大的开销?很自然地,大家会想到内存访问的速度问题,因为引用计数器在对象结构体里,对象在堆内存中。很可能对象所在的内存并未出现在 CPU 缓存中,然后内存这么一读一写,速度自然就拉下来了。
但事实是么?我们测量了修改引用计数这个两个操作的的 IPC 性能,如果是因为缓存失效的话,CPU 会失速,IPC 应该明显降低。可是拿这两个操作的 IPC 和解释器整个运行周期全局平均的 IPC 对比,发现差异好像没那么明显。

- _Py_INCREF 的 IPC 相对整体确实还是偏低了些,所以推测是,还是有一些缓存问题的,虽然不多。
- _Py_DECREF 这边,它的 IPC 和整体 IPC 没有统计学差异,说明几乎不存在缓存问题。我们的推测是,一般来说增加引用计数要早于减少引用计数,所以等它减少计数时候,对象已经被 CPU cache 给缓存住了,速度正常。另外,它还要判断引用计数是否为 0,进行有个条件跳转,为 0 的话要发起回收对象的函数调用,一般来说条件跳转和函数调用都是很费时的,但是它们也没有降低 IPC。
总的来说,引用计数费时,主要就是因为使用过于频繁,就这么简单直接的原因。
取消引用计数
在 GC 领域,有一条经验法则是,GC 开销占比超过 10%,就说明用错了方法。引用计数中位数开销是 12.0% 了,最高逼近 20%。因此,我们认为,至少对 CPython 而言,它不是一个好方案,更像是一个历史包袱。而且,因为有引用计数,CPython 里面还存在一个 GIL 的问题,一个全局锁,导致 CPython 的多线程目前只能并发,不能并行。
所以,也许可以考虑直接取消掉引用计数,干脆用纯粹基于追踪的 GC 方案得了。JVM 和 JS 引擎是这么做的,其他 Python 解释器实现比如 PyPy 也是如此。原理上并没有什么问题,问题还是在于历史包袱太多,特别是很多 C 语言写的第三方库,依赖了目前引用计数的方案。不过有个名为 HPy 的项目试图解决这个过渡的问题,也许未来 CPython 真的可以取消引用计数。
调整GC tracing阈值
那么 tracing 这边,有没有问题呢?有的!我们发现有两个 benchmark 的 tracing 开销特别高,具体一看,发现是测试 Python 启动性能的两个 benchmark。所以我们猜测是不是 GC 阈值太低了?调用得过于频繁,明明没有垃圾还反复去收集,浪费时间。所以我们做了个小实验,把 GC 阈值设置成 2 倍、4 倍、8 倍等等,还有 2 的 20 次方倍,这就基本等同于关闭了追踪垃圾回收了。结果发现,整个进程的内存占用基本不变,但是时间消耗都降低了 3% 左右。也就是说,至少对于 CPython 的启动过程来说,tracing-based GC 是徒劳无功地调用得过于频繁了。那么其他 benchmark 呢?不排除也有这种现象。

因为现在 CPython 的 GC 阈值是固定的,所以一个优化建议是:也许可以设计一套方案,让 GC 的阈值变得动态可调节,几次回收发现没有垃圾,那接下来阈值就高一点,别再反反复复调用了。
dispatch问题
GC 问题就分析到这,接下来还是关于 dispatch 问题的。
dispatch
再介绍一遍 dispatch,解释器解释完一个指令后,“取指令、解码、跳转” 等这一流程称为 dispatch。不过可能在有些研究中,dispatch 是指狭义的 dispatch,只包括其中的跳转操作,也就是图中这个 goto 语句。因为在传统的观点中,这个跳转目的地址多变,分支预测很难,是整个过程中最耗时的环节,是解释执行的性能瓶颈,所以关注点都在它这。

threaded code
如果不是专门研究解释器性能的,可能会有人问:为什么要用 goto,用这个 while 循环加一个 switch 不好么,一个指令执行后,break 出去,进入下一次循环然后再次 switch 一下?这是一种最直观的设计,但是过去认为有一些问题。

因为每个指令都从 switch 这里跳转,CPU 根本猜不出来你要 switch 到哪里去,于是,速度就不行了。
反之,如果在每个指令的结束位置分别 goto,就相当于从从原来 switch-case 1-N 的跳转变成了每个指令到下一个指令的 N-N 跳转。CPU 根据跳转发起的位置不同,更有可能猜出来跳转的目的地在哪,速度会高些。

这种方案叫 threaded code,CPython 很早就用上了,并且当时发现可以让解释器速度快个 15-20%。
真的改进很多么?
但是,这一切都发生在很早之前,现在呢?分支预测还是那么容易失误么?threaded code 还是带来了很大收益么?
我们定义了一个度量,MPKC,也就是程序运行 1000 个周期,CPU 分支预测失误了几次。
左下角这个散点图里,红色的散点对比了不同 benchmark 启用和禁用 threaded code 的 MPKC,横座标是启用,纵座标是禁用。回归线斜率 1.227,也就是禁用之后,分支预测错误多了 22.7%,还是有效果的,不过效果有限。然后,从另外一个方面看,我们说,threaded code 的好处是把跳转分散了开来。可是前面我们发现 LOAD_FAST 这个 opcode 的使用频率高达 27.5%,也就是说 27.5% 的 dispatch 跳转还集中在它这。那它的 MPKC 是多少呢?看图中绿色的散点,做一条回归线,斜率是 0.267,也就是它的 MPKC 占比 26.7%,和使用频率 27.5% 基本一致,还小了一点。也就是说,很多 dispatch 跳转都集中在它这,却也没引发什么灾难。反过来其实也印证了,把 dispatch 跳转分散开来,效果也很小。

dispatch——并非瓶颈
除了相对对比,再来看绝对值。
1 个 misprediction 浪费约 CPU 流水线长度个的 CPU 周期,1MPKC 在我们的设备上大致等价于 1.6% 的运行开销。

图中绿色的部分,是由 dispatch 导致的 MPKC 值(黄色部分是由于解释器其他部分引起的,这里不做讨论)。从中位 benchmark 看,dispatch 导致的 mispredition 对应的开销只有 1.1%;最大的 benchmark 上,为 6.2%。整体处于很低水平,因此 threaded code 减少 misprediction 带来的收益更是有限。
再来做一次验证,还是用 IPC 来度量,发现 dispatch 部分的 IPC 性能与整体相比并无统计差异。并不是像很久前的研究中说的那样,dispatch 的跳转部分很难预测,导致 CPU 失速。主要也是因为现在 CPU 越来越先进了,预测得越来越准,哪怕是使用普通的 switch-case 方案也能预测得很准确。所以,现在 dispatch 还是耗时了不少时间,是因为取指、解码、跳转这一系列操作非常冗长,并不单单是因为跳转操作的特殊性。

小结
解释视角的性能分析,大概有这么些结论:
- 首先是 CPython 的 GC 中,引用计数开销占了上风,高了一个数量级
- 一个可能的优化是干脆取消引用计数,纯粹使用基于 tracing 的 GC
- 然后 tracing 这边可以设置自适应阈值来进一步提高性能
- 最后关于 dispatch,古早的研究都认为它是解释器性能的重中之重,但是现在发现它的意义并没有那么突出。
3 性能优化
RegCPython:寄存器架构的 CPython
前面的都是实证分析,接下来谈谈优化。我们目前实现了一个优化尝试,也就是改造 CPython 为基于寄存器架构,就叫它 RegCPython。
架构之争:栈与寄存器
所谓栈架构,就是运算指令需要从一个栈上取出输入,然后把运算输出放回栈顶。至于变量的读写,则使用专门的 LOAD 和 STORE 指令。寄存器架构呢,每个指令的输入和输出都显式地编码在指令参数中,就不需要经过栈来中转。

两者架构,优缺点正好相反。栈式,设计简单,IR 体积小且生成快,解码速度有更胜一筹。寄存器式,指令数量会少很多,所以速度会快些。
| 栈式 | 寄存器式 | |
|---|---|---|
| 设计编写 | 易 | 难 |
| IR生成速度 | 快 | 慢 |
| IR体积 | 小 | 大 |
| 解码速度 | 快 | 慢 |
| 指令数量 | 多 | 少 |
| 运行速度 | 慢 | 快 |
CPython 用的是栈式,我们想,改成寄存器式的话,这些优点和缺点,会有多大的程度呢?
RegCPython
我们对 CPython 的修改集中在两个部分:
- 首先是前端,也就是编译器部分,需要修改字节码生成器,AST 还是原来那个 AST,但是现在需要生成寄存器式字节码。
- 然后式后端,也就是运行时部分,需要修改负责字节码解释的执行器,它需要接受寄存器式字节码。

其他的,诸如词法、语法、语义分析部分,或者 GC 系统和类型系统,都不改变,这样可以在最大程度上保证兼容性。
下面的图 c 展示了 RegCPython 编译出来的字节码,它是一种三地址码结构,并且把原来的 16 条指令缩减到 8 条。

benchmark 特质与分类
最值得关心的,肯定是修改前后的运行速度。不过在这之前我们需要先把所有的 benchmark 分个类。
我们定义了一个度量,叫做 P/VP/VP/V 比,它意思是执行一个字节码指令,平均消耗多少个 CPU 指令。
P/V=NphysicalinstructionsNvirtualinstructionsP/V=\frac{N_{physical\ instructions}}{N_{virtual\ instructions}}P/V=Nvirtual instructionsNphysical instructions
P/VP/VP/V 值越低,同样多时间内执行的字节码指令越多,也就是说,字节码指令被密集地执行。这 benchmark 就接近于所谓的 “纯 Python 程序”。比如用纯 Python 进行各自逻辑问题的求解。反之,P/VP/VP/V 值很高的话,一个 Python 指令背后是一大堆机器指令,这基本说明程序主要在调用各种库函数,Python 更多地充当为一种 “胶水语言”。因此,按照 P/VP/VP/V 值,我们把全部 benchmark 平均分为三类,依次是:python-intensive,neutral,以及 binary-intensive。
研究解释执行的性能,自然是 python-intensive 的 benchmark 更为重要。
实验结果
速度对比(相对运行耗时)
下图中横座标是不同的 benchmark,以 CPython 的时间开销为 1,纵座标是相对时间开销。其中有颜色的是 RegCPython 的,没有颜色的是 CPython 的。之所以是一个小提琴图而不是一个点,是因为我们把每个基准都重复运行了很多遍,然后把这么多次重复运行的时间开销分布都画出来了。

- 在最好的一个 benchmark 上,时间消耗大概减少了 25%。
- 从所有 Python-intensive 的 benchmark 看,时间消耗平均减少 12.0%。
- 即使是从包括 binary-intensive 的所有 benchmark 平均看,寄存器架构也是快了 6.2%。
- 并且,除了在少数几个 benchmark 上会略微慢一点点,绝大多数情况使用寄存器架构都可以让程序运行得更快。
空间代价(相对内存占用)
时间代价之外,是空间代价。我们继续把 CPython 的内存占用视为 1,修改之后的相对内存占用的分布,就是如下直方图。

内存消耗确实大了一点,但是多数的 benchmark 而言,增加的幅度都在 0.2% 到 2.6% 之间。不过有两个例外 mako 和 regex_dna 这两个 benchmark。因为对栈式架构来说,一个临时变量从栈上被弹出,它的引用计数立马会 - 1,然后可以立即被回收。而寄存器架构把变量放在寄存器中,临时变量只有在下一次写入时候才会被覆盖,所以引用计数不会立马减少。这就导致,可能有些对象,在栈式解释器中被回收得很及时,在寄存器式架构中被回收就有延迟。然后这两个 benchmark 刚好就是处理超长字符串的,一个字符串就有 1MB 大小,只要有两三字符串回收的慢点,内存占用就这么多了 10% 左右。
不过值得注意的是,引用计数,并不是 Python 语言的标准,所以前面我们才提出可以尝试使用纯粹基于 tracing-based GC。那如果未来真的没有引用计数的话,这里空间上的相对劣势会小很多。
开发代价(代码复杂度)
然后,是代码复杂度的对比。代码复杂度越低,开发起来越快,维护起来越容易。这里我们使用 C 语言语句数量和 McCabe’s cyclomatic complexity 两个度量,分别对比 CPython 和 RegCPython 的字节码生成器和字节码执行器源文件的复杂度。

结果发现,使用寄存器式架构,RegCPython 字节码生成器的代码复杂度要比原来低很多,也就是说,从同样的 AST 出发,编写一个生成寄存器式字节码的程序要比写一个栈式字节码的生成程序容易一点。这和一般的观点是完全相反的,一般的观点是说栈式更容易设计一些。然后执行器方面,二者复杂度差不多。不过 RegCPython 定义了好几个比较复杂的宏,所以预处理宏展开之后复杂度高一点。但是作为程序员,大家写的都是宏展开之前的代码,所以不必也没有多大问题。
总而言之,就是如果你是一门新语言的解释器开发人员,一开始就不要为了实现方便而选择栈式架构,因为它也没简单多少,寄存器架构也没麻烦到哪里去。
编译速度与 IR 体积
最后一个对比,关于编译的速度和生成的 IR 体积。我们取了 PyPI 仓库里下载量最高的 500 个包做实验。然后对比生成 pyc 文件的速度和 pyc 文件的相对体积。总的来看编译时间消耗小了一点点,文件体积大了一点点,简单概括就是半斤八两。所以一般观点认为的栈式代码体积小生成快,对 Python 解释器这边并不成立。

小结
从 CPython 到 RegCPython,我们定下了四个设计目标,可以说都满足了:
- 首先是速度要更快
- 然后内存占用和编译代价等其他方面,没有拖后腿的
- 再后式兼容性,从 API 到 ABI 都是兼容的
- 最后是复杂度,它也足够简单,易于维护
其他优化讨论
最后一部分是稍微介绍一下其他 Python 性能优化工作。
JIT
解释器是有极限的,对纯解释器性能做优化,要说精益求精还可以,但要说改头换面基本不可能。最根本的解决方案还得看 JIT。围绕 Python 的 JIT 尝试其实一直都不少,但也一直都不温不火。
- 最早的尝试应该是 Psyco,04 年的,但是后来维护不下去了,开发者让大家转投 PyPy。
- PyPy 可以说是目前实践应用的最多的带 JIT 的 Python 解释器,但是它不兼容 C-API,导致二进制库不能直接移植,所以还差点火候。
- Unladen Swallow 曾经可以说是众望所归,它是谷歌赞助的,而且还一度有 PEP 计划把它纳入 CPython 主线,但是最后还是维护不下去了,项目终止。
- Pyston 和 Pyjion,这两个命运比较类似,都是开发着开发着就没人继续维护了,然后到了最近的 2020 和 2021 年,又双双复活了,github 上的提交也变得活跃起来。
- Numba 的话,专用于科学计算,不能算是普适的 JIT。
总的来说就是,Python 的动态性太强了,导致 JIT 的开发比较困难。然后又要兼顾语言的兼容性和底层二进制接口的兼容性,历史包袱又很重,开发 JIT 属实有些 “劝退”,所以好几个项目做着做着就做不下去了。
Faster CPython与Python 3.11
然后如果是 Python 性能的研究者,个人觉得一定要关注的就是这个 Faster CPython 项目。
它是一个由 CPython 核心开发人员发起和参与的一个旨在改善 CPython 运行速度的项目,计划是四年之内把 CPython 速度提高到 5 倍,而且还不会破坏 Python 兼容性,也不会再极端情况让性能变得更差,甚至准备在 Python 3.13 的时候支持 JIT。
前几天 CPython 3.11 已经发布了第一个 beta 版,应用了来自 Faster CPython 的几个优化方案,速度达到了 CPython 3.10 的 1.25 倍,性能提升幅度比之前的 CPython 版本更新强了不少。不过正式版的话,按照以往的开发节奏,大概是要等到年底。
4 结语
以上就是我关于 CPython 性能分析和优化的全部报告内容,感谢大家的关注和倾听,欢迎进行探讨。
相关文章:
CPython解释器性能分析与优化
原文来自微信公众号“编程语言Lab”:CPython 解释器性能分析与优化 搜索关注 “编程语言Lab”公众号(HW-PLLab)获取更多技术内容! 欢迎加入 编程语言社区 SIG-元编程 参与交流讨论(加入方式:添加文末小助手…...
Linux 进程:理解进程和pcb
目录一、进程的概念二、CPU分时机制三、并发与并行1.并发2.并行四、pcb的概念一、进程的概念 什么是进程? 进程就是进行中的程序,即运行中的应用程序。比如:电脑上打开的LOL、QQ…… 这些都是一个个的进程。 什么是应用程序? 应用…...
银行数字化转型导师坚鹏:招商银行数字化转型战略研究
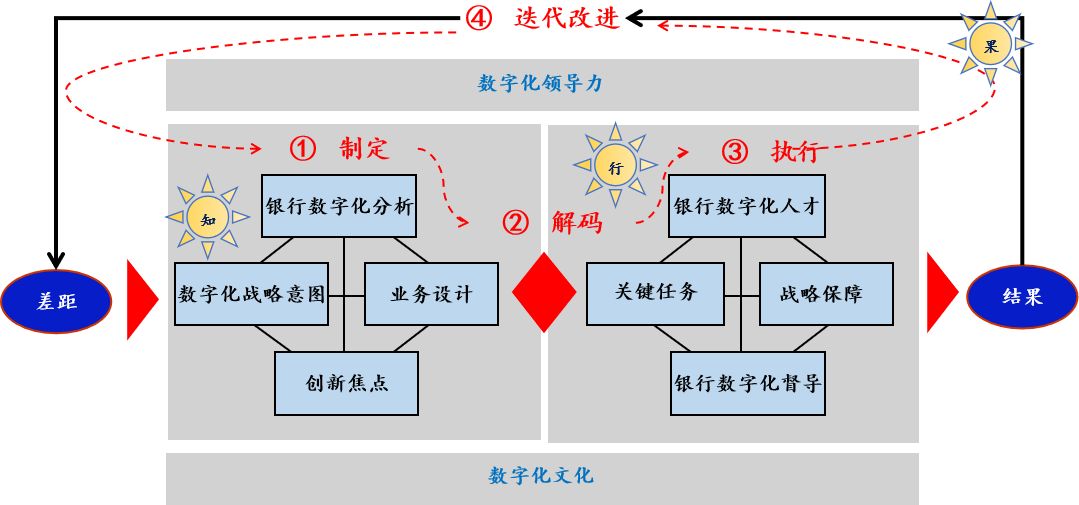
招商银行数字化转型战略研究课程背景: 很多银行存在以下问题:不清楚如何制定银行数字化转型战略?不知道其它银行的数字化转型战略是如何演变的? 课程特色:用实战案例解读招商银行数字化转型战略。用独特视角解…...
java 一文讲透面向对象 (20万字博文)
目录 一、前言 二、面向对象程序设计介绍 1.oop三大特性 : 2.面向对象和面向过程的区别 : 3.面向对象思想特点 : 4.面向对象的程序开发 : 三、Java——类与对象 1.java中如何描述一个事物? 2.什么是类? 3.类的五大成员: 4.封装的前提——抽象 : 5.什么是对…...
使用file-selector-button美化原生文件上传
前言 你平时见到的上传文件是下面这样的? 还是下面这种美化过的button样式 还是下面这种复杂的上传组件。 <input type="file" >:只要指定的是type类型的input,打开浏览器就是上面第一种原生的浏览器默认的很丑的样式。 下面的两种是我从ElementUI截的图,…...

0402换元积分法-不定积分
文章目录1 第一类换元法1.1 定理11.2 例题1.2 常见凑微分形式1.2.1常见基本的导数公式的逆运算1.2.2被积函数含有三角函数2 第二类换元法2.1 定理22.2 常见第二换元代换方法2.2.1 三角代换-弦代换2.2.2 三角代换-切代换2.2.3 三角代换-割代换2.2.4 三角代换汇总2.2.5 倒代换2.2…...
信号类型(雷达)——脉冲雷达(三)
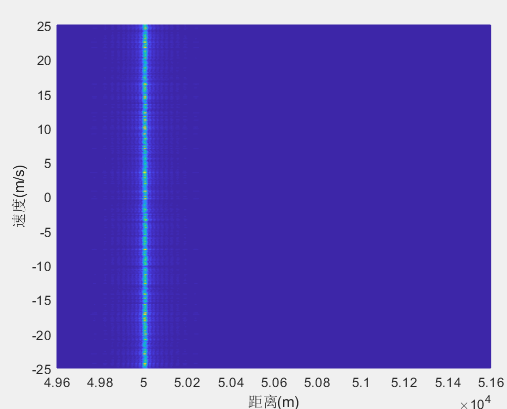
系列文章目录 《信号类型(雷达通信)》 《信号类型(雷达)——雷达波形认识(一)》 《信号类型(雷达)——连续波雷达(二)》 文章目录 前言 一、相参雷达 1…...
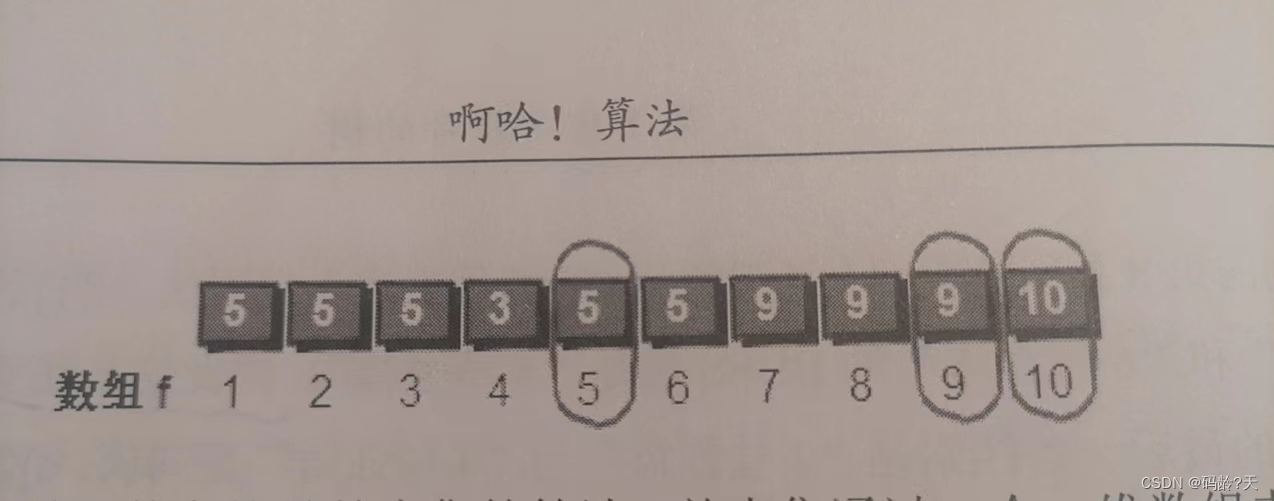
并查集(13张图解)--擒贼先擒王
目录 前言 故事 🌼思路 🌼总结 🌼代码 👊观察过程代码 👊正确代码 👊细节代码 来自《啊哈算法》 前言 刚学了树在优先队列中的应用--堆的实现 那么树还有哪些神奇的用法呢?我们从一…...
Flutter3引用原生播放器-IOS(Swift)篇
前言由于Flutter项目中需要使用到播放器功能,因此对flutter中各种播放器解决方案进行了一番研究和比对,最后决定还是自己通过Plugin的方法去引用原生播放器符合自己的需求,本篇文章会对各种解决方案做一个简单的比较,以及讲解一下…...
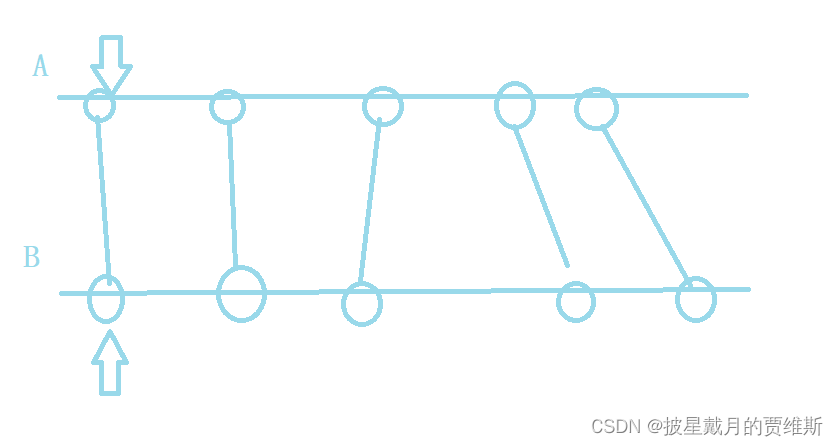
【蓝桥杯每日一题】双指针算法
🍎 博客主页:🌙披星戴月的贾维斯 🍎 欢迎关注:👍点赞🍃收藏🔥留言 🍇系列专栏:🌙 蓝桥杯 🌙我与杀戮之中绽放,亦如黎明的花…...
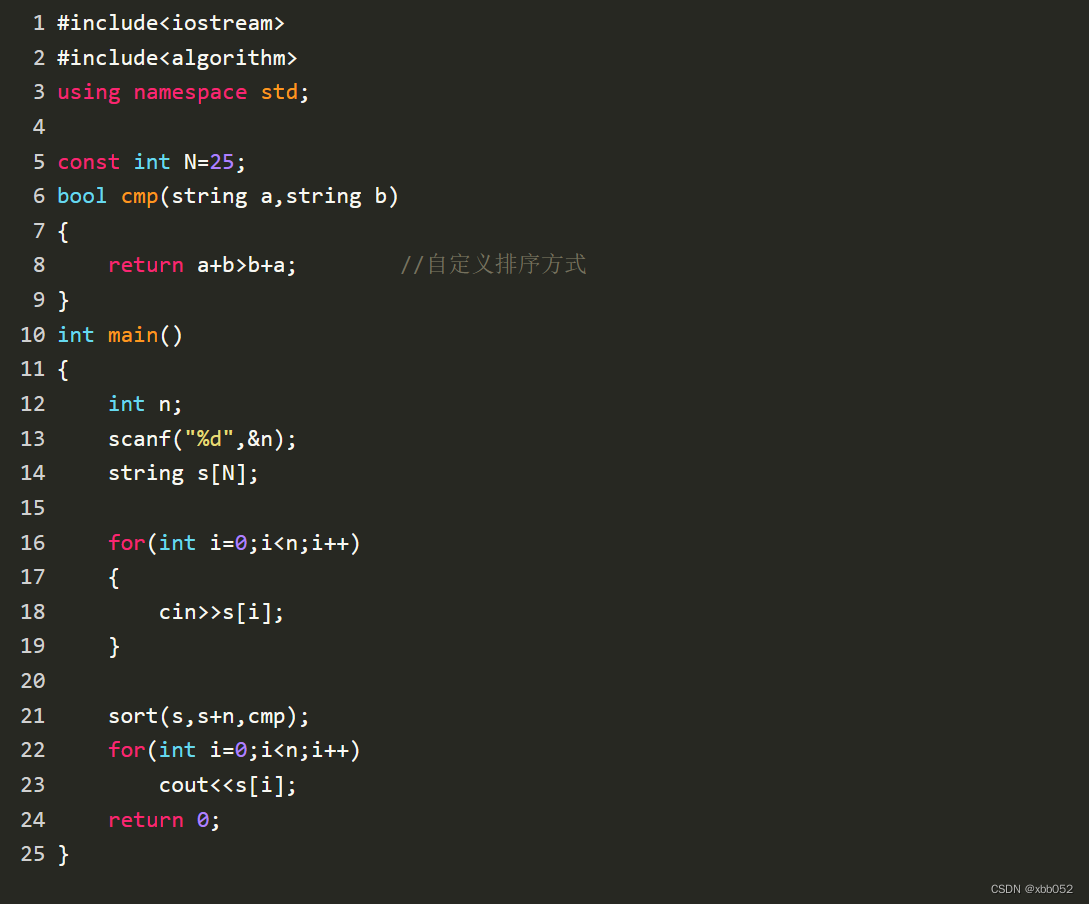
拼数(一般贪心)
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 题号:NC16783 时间限制:C/C 1秒,其他语言2秒 空间限制:C/C 262144K,其他语言524288K 64bit IO Format: %lld 题目描述 设有n个正整…...

LeetCode 热题 C++ 169. 多数元素 10. 正则表达式匹配 155. 最小栈
力扣169 给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。 你可以假设数组是非空的,并且给定的数组总是存在多数元素。 示例 1: 输入:nums [3,2,3] 输出࿱…...
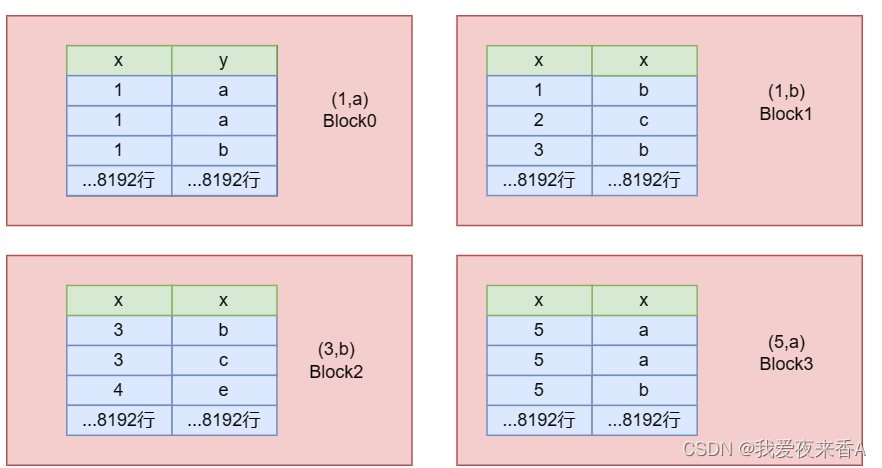
Clickhouse学习:MergeTree
MergeTree一、MergeTree逻辑存储结构二、MergeTree物理存储结构三、总结一、MergeTree逻辑存储结构 如上图所示,在排序键(CountrID、Date)上做索引,数据会按照这两个字段先后排序ClickHouse是稀疏索引,每隔8192行做一个索引,如(a,1),(a,2),比如想查a,要读取[0,3)之间的内容,稀疏…...
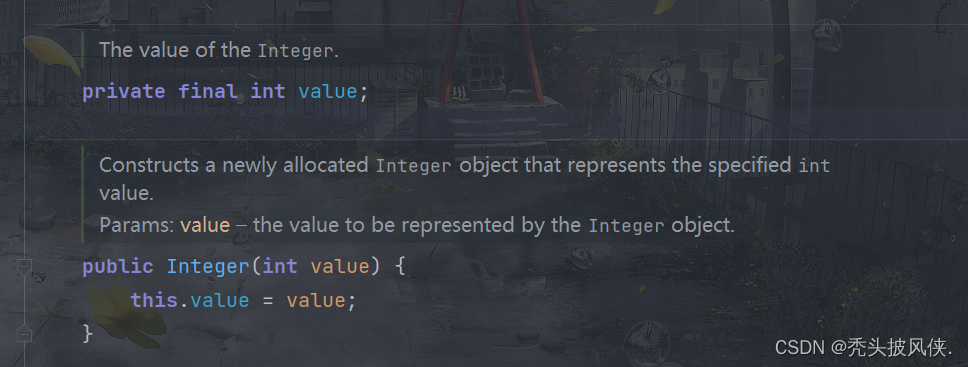
【java基础】包装类,自动装箱和自动拆箱
文章目录基本介绍包装类自动装箱自动拆箱包装类注意事项包装类比较包装器内容不可变基本介绍 有时,需要将int这样的基本类型转换为对象。所有的基本类型都有一个与之对应的类。 例如,Integer类对应基本类型int。通常,这些类称为包装器&#…...
Android笔记(二十五):两种sdk热更插件资源加载方案
背景 在研究sdk插件化热更新方式的过程中总结出了两套插件资源加载方案,在此记录下 资源热更方式 方式一:合并所有插件资源 需要解决资源id冲突问题 资源ID值一共4个字段,由三部分组成:PackageIdTypeIdEntryId PackageId&…...

spring框架--全面详解(学习笔记)
目录 1.Spring是什么 2.Spring 框架特点 3.Spring体系结构 4.Spring开发环境搭建 5.spring中IOC和DI 6.Spring中bean的生命周期 7.Spring Bean作用域 8.spring注解开发 9.Spring框架中AOP(Aspect Oriented Programming) 10.AOP 实现分类 11.A…...
)
2023年CDGA考试模拟题库(401-500)
2023年CDGA考试模拟题库(401-500) 401.数据管理战略的SMART原则指的是哪项? [1分] A.具体 、高质量、可操作 、现实、有时间限制 B.具体、可衡量、可检验、现实、有时间限制 C.具体、可衡量、可操作、现实、有时间限制 D.具体、高质量、可检验、现实12-24个月的目标 答…...

软件设计师备考文档
cpu 计算机的基本硬件系统:运算器、控制器、存储器、输入设备、输出设备 cpu负责获取程序指令,对指令进行译码并加以执行 * cpu的功能控制器(保证程序正常执行,处理异常事件) 程序控制操作控制运算器(只能…...
)
Javascript的API基本内容(一)
一、获取DOM对象 querySelector 满足条件的第一个元素 querySelectorAll 满足条件的元素集合 返回伪数组 document.getElementById 专门获取元素类型节点,根据标签的 id 属性查找 二、操作元素内容 通过修改 DOM 的文本内容,动态改变网页的内容。 inn…...

10、最小公倍数
法一: #include <stdio.h>int main(){int a,b;scanf("%d%d",&a,&b);int m a>b?a:b;//m表示a,b之间的较大值while(1){if(m%a0&&m%b0){break;}m;}printf("%d",m);return 0; }法二:a*i%b0成立 #include &…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...