Spark UI中Shuffle dataSize 和shuffle bytes written 指标区别
背景
本文基于Spark 3.1.1
目前在做一些知识回顾的时候,发现了一些很有意思的事情,就是Spark UI中ShuffleExchangeExec 的dataSize和shuffle bytes written指标是不一样的,
那么在AQE阶段的时候,是以哪个指标来作为每个Task分区大小的参考呢
结论
先说结论 dataSzie指标是 是存在内存中的UnsafeRow 的大小的总和,AQE阶段(规则OptimizeSkewedJoin/CoalesceShufflePartitions)用到判断分区是否倾斜或者合并分区的依据是来自于这个值,
而shuffle bytes written指的是写入文件的字节数,会区分压缩和非压缩,如果在开启了压缩(也就是spark.shuffle.compress true)和未开启压缩的情况下,该值的大小是不一样的。
开启压缩如下:

未开启压缩如下:

先说杂谈
这两个指标的值都在 ShuffleExchangeExec中:
case class ShuffleExchangeExec(override val outputPartitioning: Partitioning,child: SparkPlan,shuffleOrigin: ShuffleOrigin = ENSURE_REQUIREMENTS)extends ShuffleExchangeLike {private lazy val writeMetrics =SQLShuffleWriteMetricsReporter.createShuffleWriteMetrics(sparkContext)private[sql] lazy val readMetrics =SQLShuffleReadMetricsReporter.createShuffleReadMetrics(sparkContext)override lazy val metrics = Map("dataSize" -> SQLMetrics.createSizeMetric(sparkContext, "data size")) ++ readMetrics ++ writeMetrics
dataSize指标来自于哪里
涉及到datasize的数据流是怎么样的如下,一切还是得从ShuffleMapTask这个shuffle的起始操作讲起:
ShuffleMapTask||\/
runTask||\/
dep.shuffleWriterProcessor.write //这里的shuffleWriterProcessor是来自于 ShuffleExchangeExec中的createShuffleWriteProcessor||\/
writer.write() //这里是writer 是 UnsafeShuffleWriter类型的实例||\/
insertRecordIntoSorter||\/
UnsafeRowSerializerInstance.writeValue||\/
dataSize.add(row.getSizeInBytes)这里的 row 是UnsafeRow的实例,这样就获取到了实际内存中的每个分区的大小,
而ShuffleMapTask runTask 方法最终返回的是MapStatus,而该MapStatus最终是在UnsafeShuffleWriter的closeAndWriteOutput方法中被赋值的:
void closeAndWriteOutput() throws IOException {assert(sorter != null);updatePeakMemoryUsed();serBuffer = null;serOutputStream = null;final SpillInfo[] spills = sorter.closeAndGetSpills();sorter = null;final long[] partitionLengths;try {partitionLengths = mergeSpills(spills);} finally {for (SpillInfo spill : spills) {if (spill.file.exists() && !spill.file.delete()) {logger.error("Error while deleting spill file {}", spill.file.getPath());}}}mapStatus = MapStatus$.MODULE$.apply(blockManager.shuffleServerId(), partitionLengths, mapId);}
shuffle bytes written指标来自哪里
基本流程和dataSize 一样,还是来自于ShuffleMapTask:
ShuffleMapTask||\/
runTask||\/
dep.shuffleWriterProcessor.write //这里的shuffleWriterProcessor是来自于 ShuffleExchangeExec中的createShuffleWriteProcessor||\/
writer.write() //这里是writer 是 UnsafeShuffleWriter类型的实例||\/
closeAndWriteOutput||\/
sorter.closeAndGetSpills() -> writeSortedFile -> writer.commitAndGet -> writeMetrics.incBytesWritten(committedPosition - reportedPosition) -> serializerManager.wrapStream(blockId, mcs) // 这里进行了压缩||\/
mergeSpills||\/
mergeSpillsUsingStandardWriter||\/
mergeSpillsWithFileStream -> writeMetrics.incBytesWritten(numBytesWritten)||\/
writeMetrics.decBytesWritten(spills[spills.length - 1].file.length())相关文章:
Spark UI中Shuffle dataSize 和shuffle bytes written 指标区别
背景 本文基于Spark 3.1.1 目前在做一些知识回顾的时候,发现了一些很有意思的事情,就是Spark UI中ShuffleExchangeExec 的dataSize和shuffle bytes written指标是不一样的, 那么在AQE阶段的时候,是以哪个指标来作为每个Task分区大…...

Java——Map.getOrDefault方法详解
Java——Map.getOrDefault方法详解 Map.getOrDefault(Object key, V defaultValue)是Java中Map接口的一个方法,用于获取指定键对应的值,如果键不存在,则返回一个默认值。 该方法的签名如下: V getOrDefault(Object key, V defau…...

银河集团香港优才计划95分获批案例展示!看看是如何申请的?
银河集团香港优才计划95分获批案例展示!看看是如何申请的? 今天来分享一则银河集团香港优才计划获批案例!客户本科学历非名校、从事业务支援及人力资源行业,优才打分95分,这个条件可能在很多人的印象里,会觉…...

Python class中以`_`开头的类特殊方法
在学基础的时候没学到过(可能见过但是又忘了),在学习深度学习项目的时候遇见了很多; 以论文Multi-label learning from single positive label为例; 这些方法都是程序自行调用的,不需要(也不可以…...

2023云栖大会开幕:全球数万开发者参会,展现AI时代的云计算创新
10月31日,2023云栖大会在杭州开幕,大会吸引全球数万开发者参会。阿里巴巴集团董事会主席蔡崇信在致辞中表示,今年云栖大会主题回归“计算,为了无法计算的价值”,这也是2015年云栖大会的主题,当时云计算支撑…...

[量化投资-学习笔记004]Python+TDengine从零开始搭建量化分析平台-EMA均线
在之前的文章中用 Python 直接计算的 MA 均线,但面对 EMA 我认怂了。 PythonTDengine从零开始搭建量化分析平台-MA均线的多种实现方式 高数是我们在大学唯一挂过的科。这次直接使用 Pandas 库的 DataFrame.ewm 函数,便捷又省事。 并且用 Pandas 直接对之…...

KaiwuDB 获山东省工信厅“信息化应用创新优秀解决方案”奖
10月23日,山东省工信厅正式公示《2023年山东省信息化应用创新典型应用案例及优秀解决方案名单》,面向全省、全国重点推荐山东省技术水平先进、应用示范效果突出、产业带动性强的信息化解决方案及应用实践,对于进一步激发山东省信息技术产业创…...

Python-常用的量化交易代码片段
算法交易正在彻底改变金融世界。通过基于预定义标准的自动化交易,交易者可以以闪电般的速度和比以往更精确的方式执行订单。如果您热衷于深入了解算法交易的世界,本指南提供了帮助您入门的基本代码片段。从获取股票数据到回溯测试策略,我们都能满足您的需求! 1. 使用 YFina…...

Netty优化-rpc
Netty优化-rpc 1.3 RPC 框架1)准备工作 1.3 RPC 框架 1)准备工作 这些代码可以认为是现成的,无需从头编写练习 为了简化起见,在原来聊天项目的基础上新增 Rpc 请求和响应消息 Data public abstract class Message implements …...
:概念、作用、术语)
【Docker 内核详解】cgroups 资源限制(一):概念、作用、术语
cgroups 资源限制(一):概念、作用、术语 1.cgroups 是什么2.cgroups 的作用3.cgroups 术语表 当谈论 Docker 时,常常会聊到 Docker 的实现方式。很多开发者都知道,Docker 容器本质上是宿主机上的进程(容器所…...
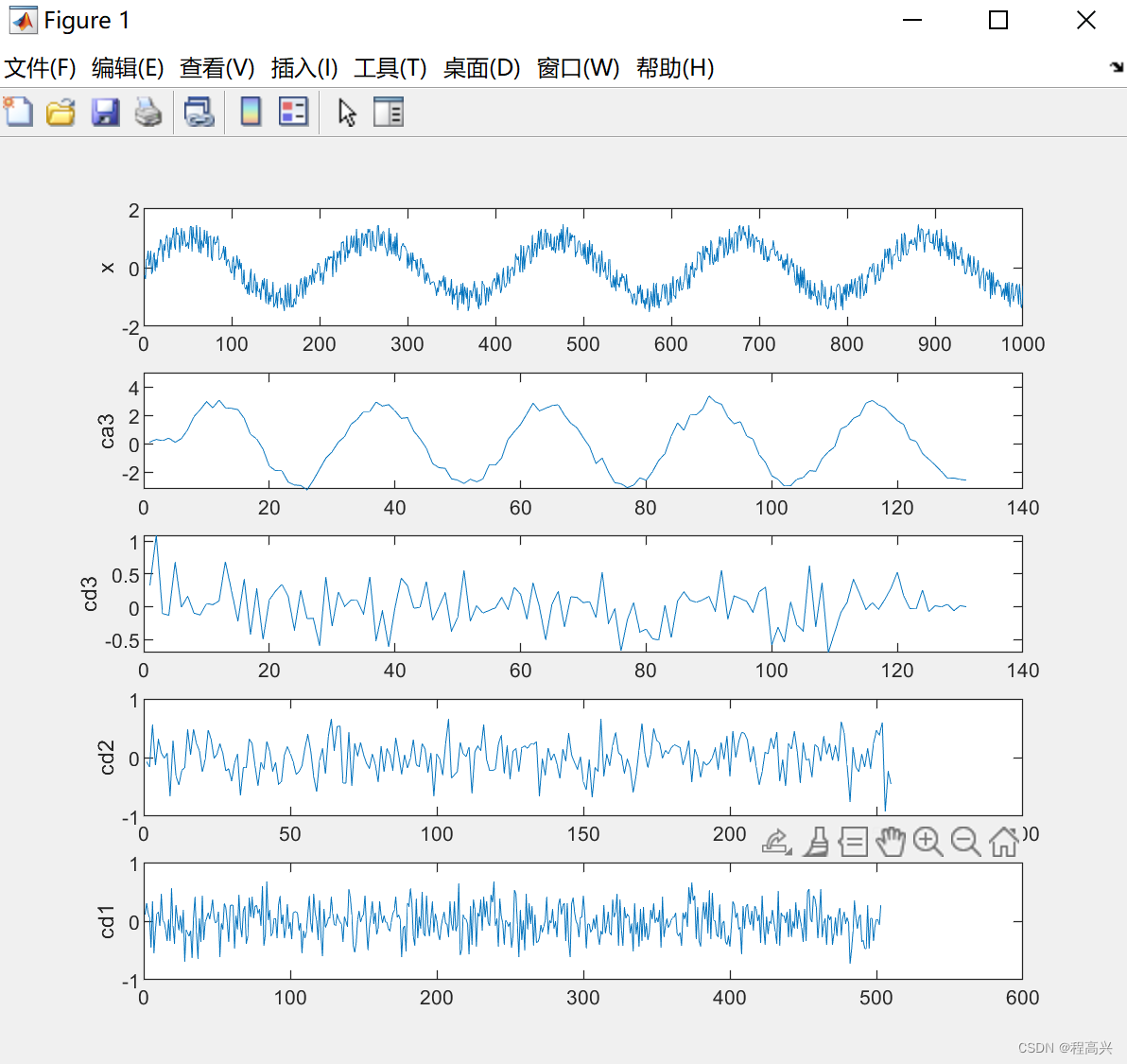
MATLAB——一维小波的多层分解
%% 学习目标:一维小波的多层分解 clear all; close all; load noissin.mat; xnoissin; [C,L]wavedec(x,3,db4); % 3层分解,使用db4小波 [cd1,cd2,cd3]detcoef(C,L,[1,2,3]); % 使用detcoef函数获取细节系数 ca3appcoef(C,L,db4,3); …...
C++的拷贝构造函数
目录 拷贝构造函数一、为什么用拷贝构造二、拷贝构造函数1、概念2、特征1. 拷贝构造函数是构造函数的一个重载形式。2. 拷贝构造函数的参数3. 若未显式定义,编译器会生成默认的拷贝构造函数。4. 拷贝构造函数典型调用场景 拷贝构造函数 一、为什么用拷贝构造 日期…...
【手机端远程连接服务器】安装和配置cpolar+JuiceSSH:实现手机端远程连接服务器
文章目录 1. Linux安装cpolar2. 创建公网SSH连接地址3. JuiceSSH公网远程连接4. 固定连接SSH公网地址5. SSH固定地址连接测试 处于内网的虚拟机如何被外网访问呢?如何手机就能访问虚拟机呢? cpolarJuiceSSH 实现手机端远程连接Linux虚拟机(内网穿透,手机端连接Linux虚拟机) …...

Jupyter Notebook的使用
文章目录 Jupyter Notebook一、Jupyter Notebook是什么?二、使用步骤1.安装Miniconda2.安装启动**Jupyter Notebook**3.一些问题 三、Jupyter Notebook的操作1.更换解释器2.在指定的文件夹中打开3 运行的快捷键 四.报错解决1.画图的时候出现报错2.画图的时候空白3.p…...

vue 使用vue-office预览word、excel,pdf同理
在此,我只使用了docx和excel, pdf我直接使用的iframe进行的展示就不作赘述了 //docx文档预览组件 npm install vue-office/docx//excel文档预览组件 npm install vue-office/excel//pdf文档预览组件 npm install vue-office/pdf如果是vue2.6版本或以下还…...
【Spring Boot 源码学习】RedisAutoConfiguration 详解
Spring Boot 源码学习系列 RedisAutoConfiguration 详解 引言往期内容主要内容1. Spring Data Redis2. RedisAutoConfiguration2.1 加载自动配置组件2.2 过滤自动配置组件2.2.1 涉及注解2.2.2 redisTemplate 方法2.2.3 stringRedisTemplate 方法 总结 引言 上篇博文࿰…...

Linux中如何进行粘贴复制
因为CTRLC在Linux中具有特定的含义:终止当前操作 xshell提供了CTRLinsert(复制)/shiftinsert(粘贴) 上述快捷键在Windows中依旧支持,...
多输入多输出 | Matlab实现k-means-LSTM(k均值聚类结合长短期记忆神经网络)多输入多输出组合预测
多输入多输出 | Matlab实现k-means-LSTM(k均值聚类结合长短期记忆神经网络)多输入多输出组合预测 目录 多输入多输出 | Matlab实现k-means-LSTM(k均值聚类结合长短期记忆神经网络)多输入多输出组合预测预测效果基本描述程序设计参…...
学习笔记3——JVM基础知识
学习笔记系列开头惯例发布一些寻亲消息 链接:https://baobeihuijia.com/bbhj/contents/3/196593.html JVM(Write Once,Run Anywhere) 以下是一些学习时有用到的资料,只学习了JVM的基础知识,对JVM整体进…...

图像处理:图片二值化学习,以及代码中如何实现
目录 1、了解下图片二值化的含义 2、进行图像二值化处理的方法 3、如何选择合适的阈值进行二值化 4、实现图片二值化(代码) (1)是使用C和OpenCV库实现: (2)纯C代码实现,不要借…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

五年级数学知识边界总结思考-下册
目录 一、背景二、过程1.观察物体小学五年级下册“观察物体”知识点详解:由来、作用与意义**一、知识点核心内容****二、知识点的由来:从生活实践到数学抽象****三、知识的作用:解决实际问题的工具****四、学习的意义:培养核心素养…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...