【大数据Hive】Hive ddl语法使用详解
一、前言
使用过关系型数据库mysql的同学对mysql的ddl语法应该不陌生,使用ddl语言来创建数据库中的表、索引、视图、存储过程、触发器等,hive中也提供了类似ddl的语法。本篇将详细讲述hive中ddl的使用。
二、hive - ddl 整体概述
在Hive中,DATABASE的概念和RDBMS中类似,我们称之为数据库,DATABASE和SCHEMA是可互换的,都可以使用,默认的数据库叫做default,存储数据位置位于/user/hive/warehouse下,用户自己创建的数据库存储位置是/user/hive/warehouse/database_name.db下。
如下是我们操作演示时候创建的一个名叫test的数据库,在hdfs上的目录展示如下
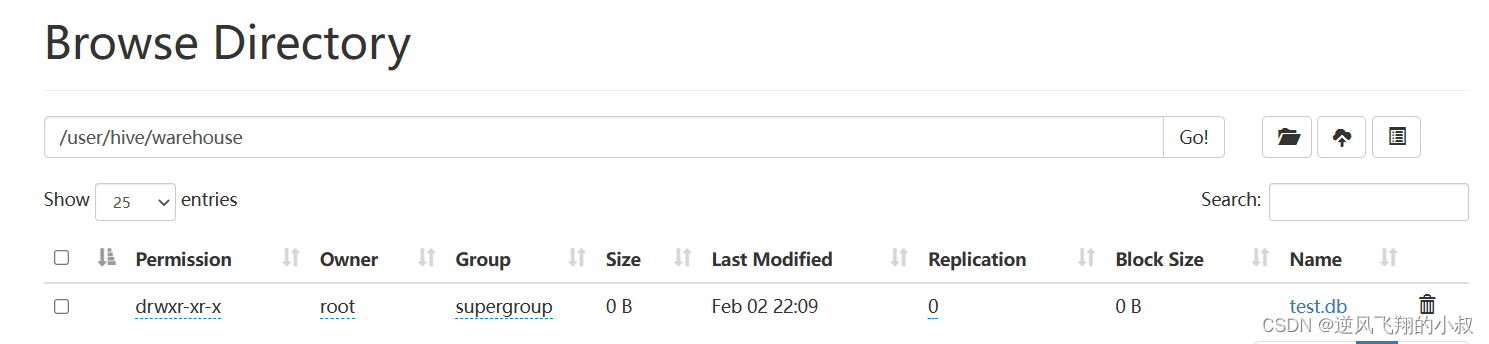
ddl主要包括数据库数据表相关的操作,接下来分别通过操作进行演示说明
三、数据库操作
3.1 创建数据库完整语法
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];参数说明:
- COMMENT:数据库的注释说明语句;
- LOCATION:指定数据库在HDFS存储位置,默认/user/hive/warehouse/dbname.db;
- WITH DBPROPERTIES:用于指定一些数据库的属性配置;
3.2 数据库操作 DDL
创建一个数据库
create database if not exists mydb
comment "this is my first db"
with dbproperties ('createdBy'='congge');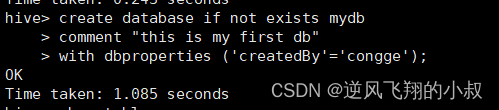
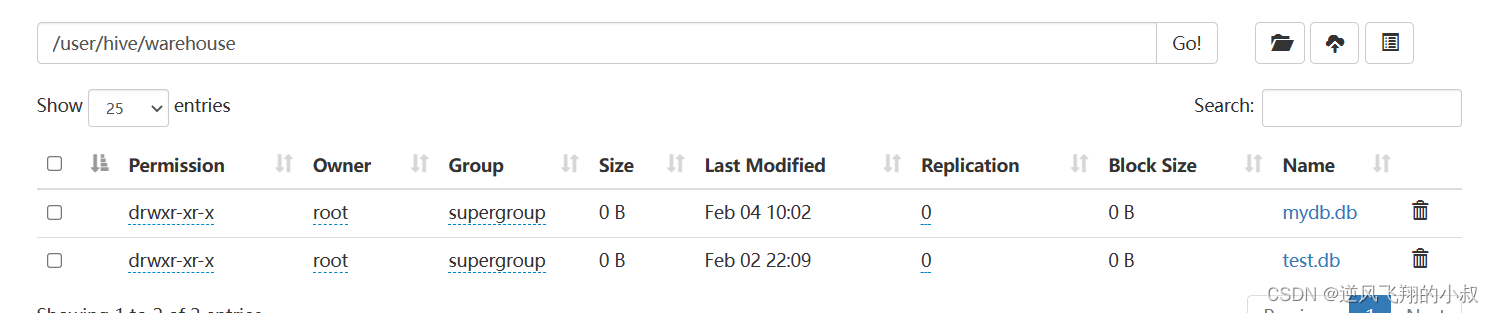
创建成功后hdfs上就创建了与库对应的目录
查看数据库信息
可以通过下面的命令查看数据库的信息
describe database mydb;
describe database extended mydb;
desc database extended mydb;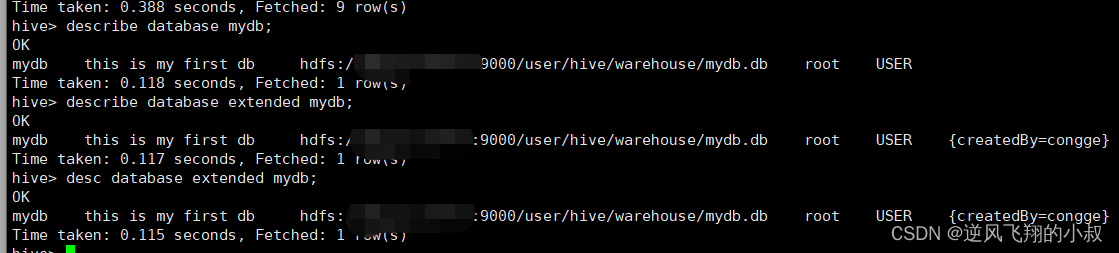
切换数据库
use 数据库名称;
删除数据库
语法
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
默认情况下,如果待删除的数据库下面有表的情况下,直接执行drop命令时会失败,其实是hive对数据库的一种保护操作,如下,假如my_db下面创建一张表,此时直接执行删除,会报错;
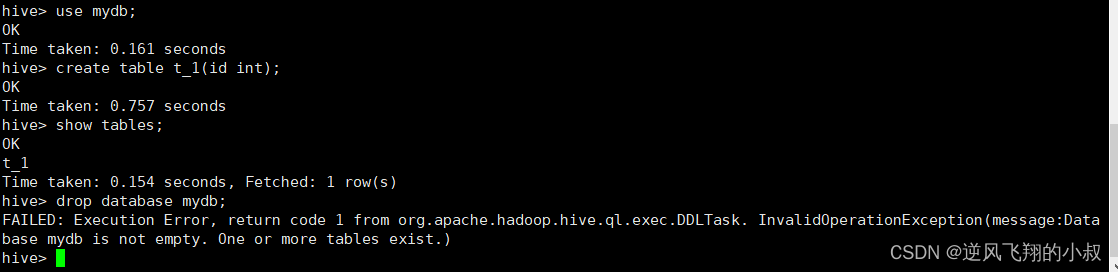
当然如果没有表的话就可以直接删除成功了,但是在存在表的情况下仍然要删除,就可以在语句后加上CASCADE关键字;
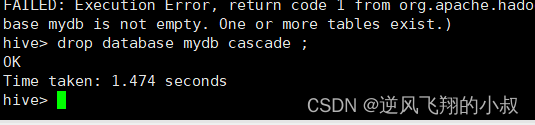
drop database mydb cascade ;
执行效果
修改数据库
数据库的修改主要是更改与Hive中的数据库关联的元数据;
更改数据库属性
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...);
更改数据库所有者
ALTER (DATABASE|SCHEMA) database_name SET OWNER USER user;
更改数据库位置
ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path;
四、数据表table操作
4.1 整体概述
1、Hive中针对表的DDL操作可以说是DDL中的核心操作,包括建表、修改表、删除表、描述表元数据信息;
2、其中以建表语句为核心中的核心,详见Hive DDL建表语句;
3、可以说表的定义是否成功直接影响着数据能够成功映射,进而影响是否可以顺利的使用Hive开展数据分析;
4、由于Hive建表之后加载映射数据很快,实际中如果建表有问题,可以不用修改,直接删除重建;
4.2 操作演示
创建表
见之前的DDL的一篇:hive ddl操作
删除表
DROP TABLE [IF EXISTS] table_name [PURGE]; -- (Note: PURGE available in Hive 0.14.0 and later)
执行drop table 删除该表的元数据和数据
- 如果已配置垃圾桶且未指定PURGE,则该表对应的数据实际上将移动到HDFS垃圾桶,而元数据完全丢失。 删除EXTERNAL表时,该表中的数据不会从文件系统中删除,只删除元数据;
- 如果指定了PURGE,则表数据跳过HDFS垃圾桶直接被删除。因此如果DROP失败,则无法挽回该表数据;
从表中删除所有行
TRUNCATE [TABLE] table_name;
可以简单理解为清空表的所有数据但是保留表的元数据结构,如果HDFS启用了垃圾桶,数据将被丢进垃圾桶,否则将被删除。
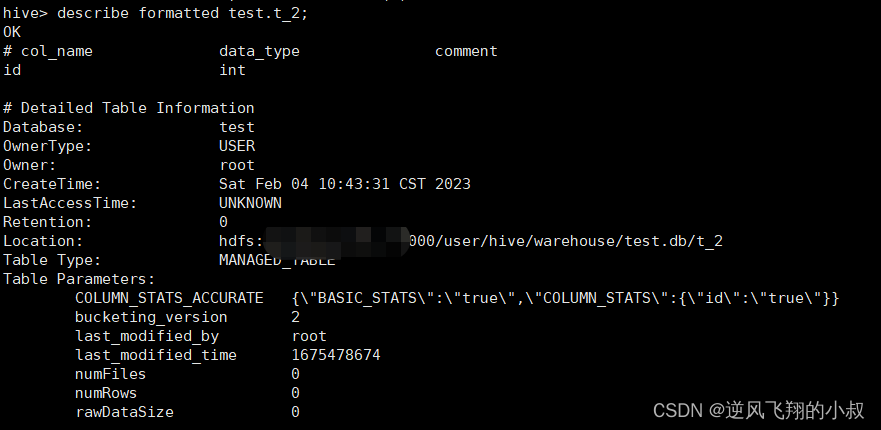
查询指定表的元数据信息
describe formatted test.t_2;
修改表操作
--1、更改表名
ALTER TABLE table_name RENAME TO new_table_name;--2、更改表属性
ALTER TABLE table_name SET TBLPROPERTIES (property_name = property_value, ... );--更改表注释
ALTER TABLE student SET TBLPROPERTIES ('comment' = "new comment for student table");--3、更改SerDe属性
ALTER TABLE table_name SET SERDE serde_class_name [WITH SERDEPROPERTIES (property_name = property_value, ... )];ALTER TABLE table_name [PARTITION partition_spec] SET SERDEPROPERTIES serde_properties;ALTER TABLE table_name SET SERDEPROPERTIES ('field.delim' = ',');--移除SerDe属性
ALTER TABLE table_name [PARTITION partition_spec] UNSET SERDEPROPERTIES (property_name, ... );--4、更改表的文件存储格式 该操作仅更改表元数据。现有数据的任何转换都必须在Hive之外进行
ALTER TABLE table_name SET FILEFORMAT file_format;--5、更改表的存储位置路径
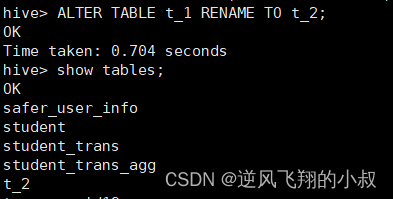
ALTER TABLE table_name SET LOCATION "new location";比如将t_1表改为t_2;
ALTER TABLE table_name RENAME TO new_table_name;
修改表字段操作
修改数据表中的字段相关的操作也是日常DDL中的重要操作,下面以一个表为例进行操作演示
创建一个表
CREATE TABLE test_change (a int, b int, c int);

修改字段名称
ALTER TABLE test_change CHANGE a a1 INT;
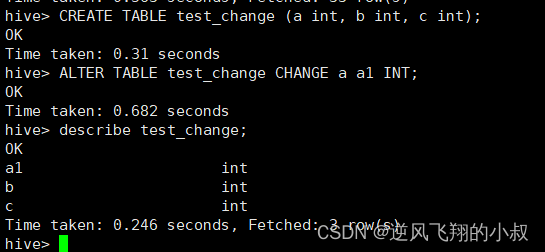
修改字段名称和类型
ALTER TABLE test_change CHANGE a1 a2 STRING AFTER b;
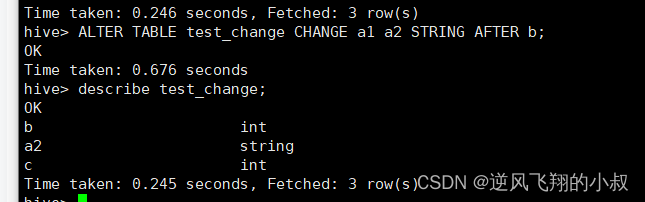
修改字段名称并将字段位置提前
ALTER TABLE test_change CHANGE c c1 INT FIRST;
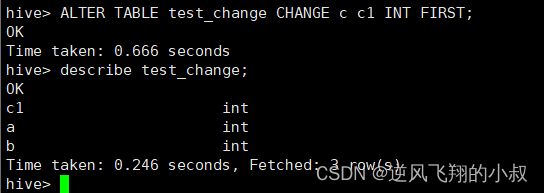
给字段补充注释
ALTER TABLE test_change CHANGE a1 a1 INT COMMENT 'this is column a1';
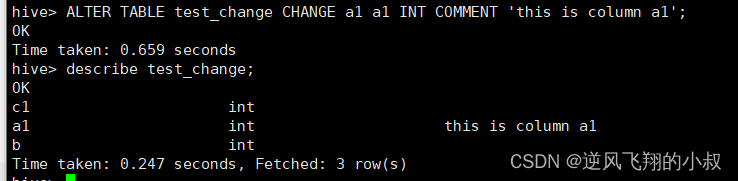
添加/替换列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type,...);
- 使用ADD COLUMNS,您可以将新列添加到现有列的末尾但在分区列之前;
- REPLACE COLUMNS 将删除所有现有列,并添加新的列集;
4.3 分区表DDL相关操作
在之前的学习中了解到,hive中还有一种分区表,有必要对分区表相关的DDL做一下补充说明
Hive中针对分区Partition的操作主要包括:增加分区、删除分区、重命名分区、修复分区、修改分区
1)增加分区概述
- ADD PARTITION会更改表元数据,但不会加载数据。如果分区位置中不存在数据,查询时将不会返回结果;
- 因此需要保证增加的分区位置路径下,数据已经存在,或者增加完分区之后导入分区数据;
接下来通过实际的操作演示一下
2)添加分区操作演示
创建表手动加载分区数据
drop table if exists t_user_province;
create table t_user_province (num int,name string,sex string,age int,dept string) partitioned by (province string);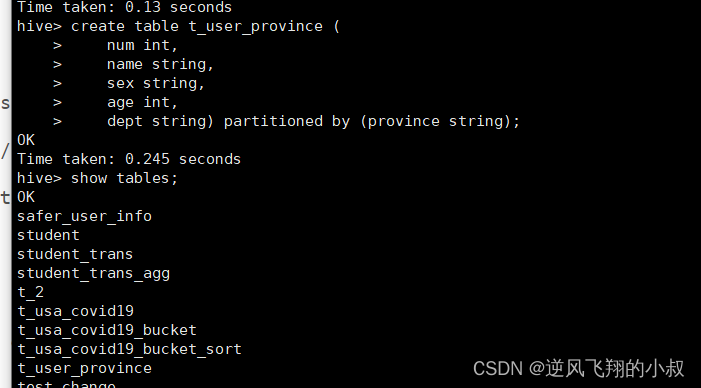
给t_user_province表加载数据
load data local inpath '/usr/local/soft/hivedata/students.txt' into table t_user_province partition(province ="SH");

执行完成后可以在hdfs文件目录下看到一个分区的目录
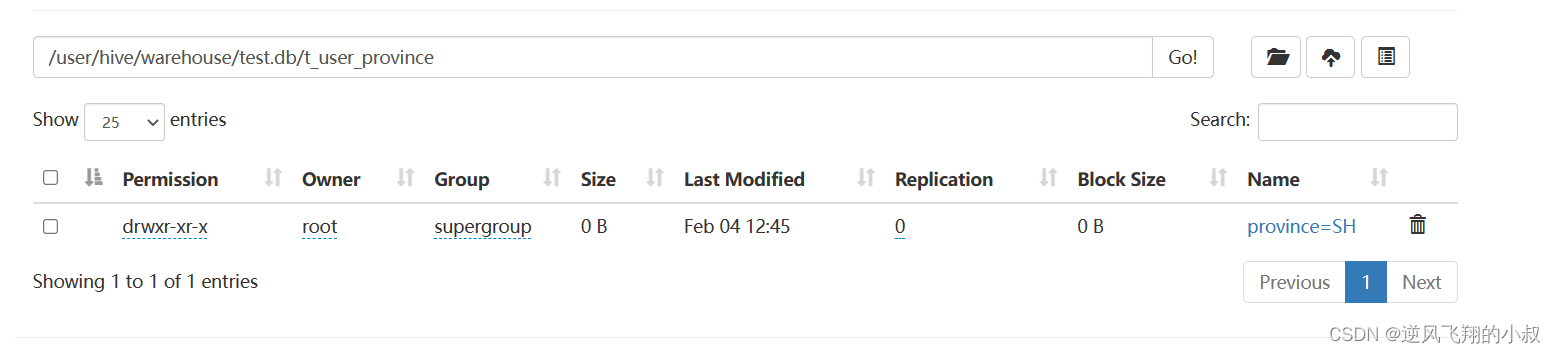
添加一个分区
ALTER TABLE t_user_province ADD PARTITION (province='BJ') location '/user/hive/warehouse/test.db/t_user_province/province=BJ';

执行完成后可以在hdfs文件目录下看到一个新的分区目录

最后,还必须自己把数据加载到增加的分区中 hive不会帮你添加;
此外还支持一次添加多个分区,具体语法
ALTER TABLE table_name ADD PARTITION (dt='2022-08-08', country='us') location '/path/to/us/part220808'
PARTITION (dt='2022-08-09', country='us') location '/path/to/us/part220809';
3)重命名分区
语法
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;
ALTER TABLE table_name PARTITION (dt='2022-08-09') RENAME TO PARTITION (dt='20220909');
4)删除分区
删除表的分区,将删除该分区的数据和元数据
删除分区
ALTER TABLE table_name DROP [IF EXISTS] PARTITION (dt='2022-08-08', country='us');
直接删除数据 不进垃圾桶
ALTER TABLE table_name DROP [IF EXISTS] PARTITION (dt='2022-08-08', country='us') PURGE;
5)修改分区
更改分区文件存储格式
ALTER TABLE table_name PARTITION (dt='2008-08-09') SET FILEFORMAT file_format;
更改分区位置
ALTER TABLE table_name PARTITION (dt='2008-08-09') SET LOCATION "new location";
6)分区修复
背景:
Hive将每个表的分区列表信息存储在其metastore中。但是,如果将新分区直接添加到HDFS(例如通过使用hadoop fs -put命令)或从HDFS中直接删除分区文件夹,则除非用户ALTER TABLE table_name ADD/DROP PARTITION在每个新添加的分区上运行命令,否则metastore(也就是Hive)将不会意识到分区信息的这些更改。
MSCK是metastore check的缩写,表示元数据检查操作,可用于元数据的修复,语法如下:
MSCK [REPAIR] TABLE table_name [ADD/DROP/SYNC PARTITIONS];
关于MSCK的几点说明
- MSCK默认行为ADD PARTITIONS,使用此选项,它将把HDFS上存在但元存储中不存在的所有分区添加到metastore;
- DROP PARTITIONS选项将从已经从HDFS中删除的metastore中删除分区信息;
- SYNC PARTITIONS选项等效于调用ADD和DROP PARTITIONS;
- 如果存在大量未跟踪的分区,则可以批量运行MSCK REPAIR TABLE,以避免OOME(内存不足错误);
下面看一个案例的具体的操作演示
- 创建一张分区表,直接使用HDFS命令在表文件夹下创建分区文件夹并上传数据,此时在Hive中查询是无法显示表数据的,因为metastore中没有记录,使用MSCK ADD PARTITIONS进行修复;
- 针对分区表,直接使用HDFS命令删除分区文件夹,此时在Hive中查询显示分区还在,因为metastore中还没有被删除,使用MSCK DROP PARTITIONS进行修复;
4.4 案例一:直接通过HDFS创建分区并加载数据
创建分区表
create table t_all_hero_part_msck(id int,name string,hp_max int,mp_max int,attack_max int,defense_max int,attack_range string,role_main string,role_assist string
) partitioned by (role string)row format delimitedfields terminated by "\t";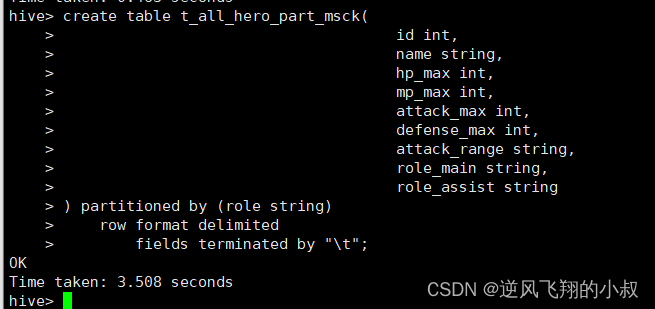
在linux上,使用HDFS命令创建分区文件夹
hdfs dfs -mkdir -p /user/hive/warehouse/test.db/t_all_hero_part_msck/role=sheshou
hdfs dfs -mkdir -p /user/hive/warehouse/test.db/t_all_hero_part_msck/role=tanke
执行完成后效果如下,这个操作就是说,直接通过hdfs命令创建分区,对于hive的底层来说是感知不到的;
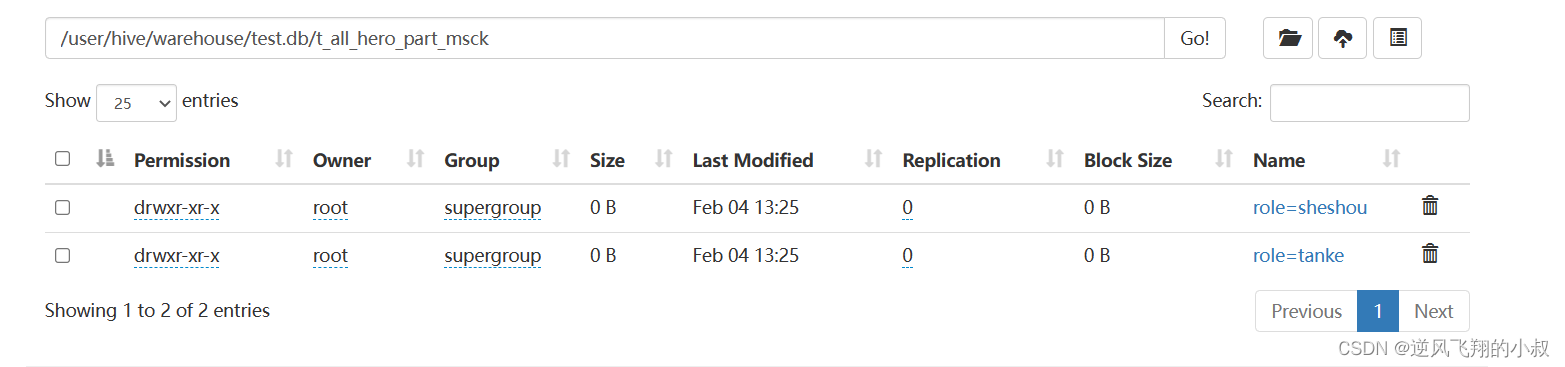
把数据文件上传到对应的分区文件夹下
hdfs dfs -put ./archer.txt /user/hive/warehouse/test.db/t_all_hero_part_msck/role=sheshou
hdfs dfs -put ./tank.txt /user/hive/warehouse/test.db/t_all_hero_part_msck/role=tanke执行上传

上传完毕后,hdfs的分区表下也加载了对应的数据文件

查询分区表数据
select * from t_all_hero_part_msck;
查询发现表中并没有数据,这就进一步说明,直接通过hdfs命令操作,对于hive来说是无法感知到数据变化的;

使用MSCK命令进行修复
add partitions可以不写 因为默认就是增加分区
MSCK repair table t_all_hero_part_msck add partitions;
执行完上述的命令后再次查询数据表,发现就有数据了;
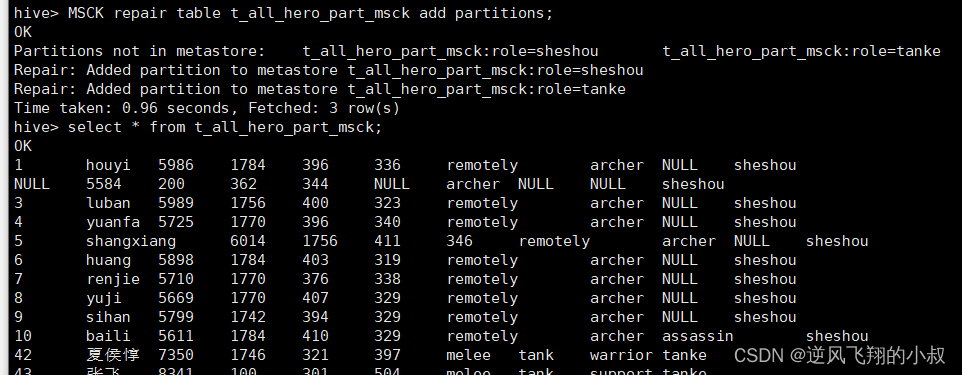
4.5 案例二:直接通过HDFS删除分区表某个分区文件夹
删除分区表的某个分区文件夹
hdfs dfs -rm -r /user/hive/warehouse/test.db/t_all_hero_part_msck/role=sheshou

执行完成检查hdfs分区目录已经被删除
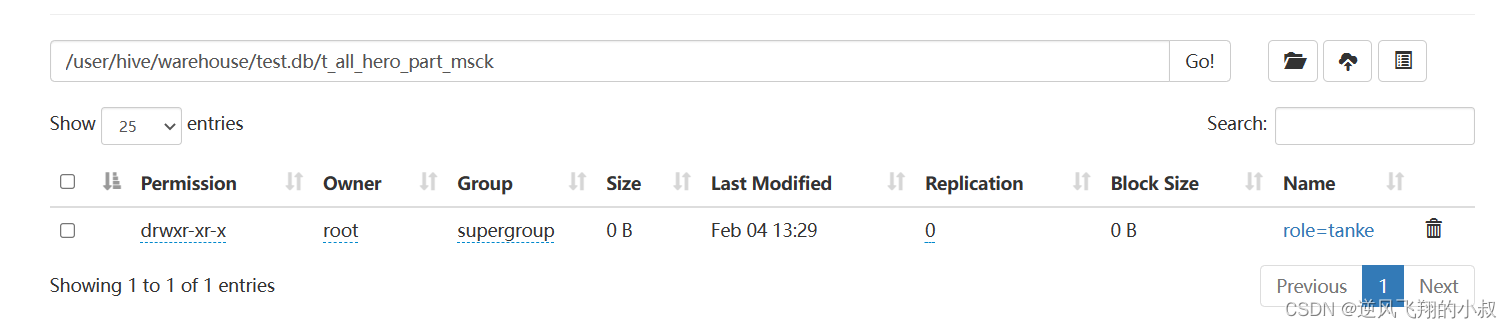
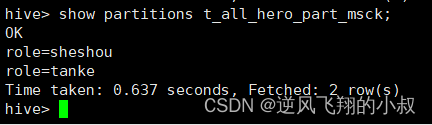
查询数据表数据
show partitions t_all_hero_part_msck;
查询结果发现分区的信息仍然还在,这是因为hive的元数据信息还没有删除 ,也就是说hive并没有感知到变化;
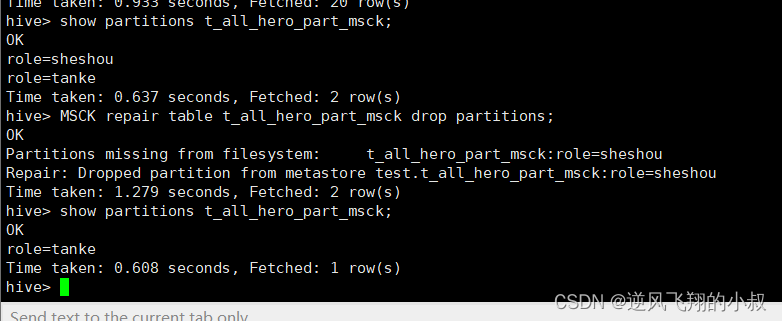
使用MSCK命令进行修复
MSCK repair table t_all_hero_part_msck drop partitions;
执行修复命令之后,再次检查分区信息,此时分区就只剩下一个了;
相关文章:
【大数据Hive】Hive ddl语法使用详解
一、前言 使用过关系型数据库mysql的同学对mysql的ddl语法应该不陌生,使用ddl语言来创建数据库中的表、索引、视图、存储过程、触发器等,hive中也提供了类似ddl的语法。本篇将详细讲述hive中ddl的使用。 二、hive - ddl 整体概述 在Hive中,DA…...
)
Connext DDS录制服务 Recording Service(2)
2.4 远程管理 控制客户端(如RTI管理控制台)可以使用此接口远程控制录制服务。 注:记录服务远程管理基于第10.3节中描述的RTI远程管理平台。有关录制服务中远程管理工作的详细讨论,请参阅该手册 下面是所有支持操作的API引用。 2.4.1 启用远程管理 默认情况下,在录制服务中…...

mysql数据类型选择
数据类型选择 完整性约束 是完整性约束是为保证数据库中数据的正确性和相容性,对关系模型提出的某种约束条件或规则。 通常包括:实体完整性约束、参照完整性约束、域完整性约束、用户自定义完整性约束。 实体完整性(Entity integrity)是指主键必须非空…...

【Java】Spring Boot 配置文件
文章目录SpringBoot 配置文件1. 配置文件的作用2. 配置文件的格式3. properties配置文件说明3.1 properties基本语法3.2 读取配置文件3.3 properties缺点分析4. yml配置文件说明4.1 yml基本语法4.2 yml使用进阶4.2.1 yml配置不同的数据类型及null4.2.1 yml配置的读取4.2.2 配置…...
AtCoder Beginner Contest 290 G. Edge Elimination(思维题 枚举+贪心)
题目 T(T<100)组样例,每次给出一棵深度为d的k叉树, 其中,第i层深的节点个数为 保证k叉树的所有节点个数tot不超过1e18, 求在k叉树上构建一棵大小恰为x的连通块,所需要断开的最少的树边的条数(x<tot<1e18)…...
数据挖掘概述
目录1、数据挖掘概述2、数据挖掘常用库3、模型介绍3.1 分类3.2 聚类3.3 回归3.4 关联3.5 模型集成4、模型评估ROC 曲线5、模型应用1、数据挖掘概述 数据挖掘:寻找数据中隐含的知识并用于产生商业价值 数据挖掘产生原因:海量数据、维度众多、问题复杂 数…...

linux kernel iio 架构
linux kernel iio 架构讲解Linux IIO(Industrial I/O)架构是Linux内核提供的一种用于支持各种类型传感器和数据采集设备的子系统,包括温度、压力、湿度、加速度、光度等多种传感器。IIO架构的核心是一个通用的IIO子系统,它提供了一…...

Socket通信详解
Socket通信详解 文章目录Socket通信详解Socket流程介绍函数介绍编程实例Socket流程介绍 socket通信类似于电话通信,其服务器基本流程就是 Created with Raphal 2.3.0安装电话socket()分配电话号码bind()连接电话线listen()拿起话筒accept()函数介绍 socket() 其中…...
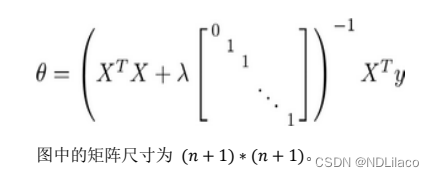
多分类、正则化问题
多分类问题 利用逻辑回归解决多分类问题,假如有一个训练集,有 3 个类别,分别为三角形 𝑦 1,方框𝑦 2,圆圈 𝑦 3。我们下面要做的就是使用一个训练集,将其分成 3 个二…...

史上最全面的软件测试面试题总结(接口、自动化、性能全都有)
目录 思维发散 Linux 测试概念和模型 测试计划与工具 测试用例设计 Web项目 Python基础 算法 逻辑 接口测试 性能测试 总结感谢每一个认真阅读我文章的人!!! 重点:配套学习资料和视频教学 思维发散 一个球ÿ…...

速来~与 Werner Vogels 博士一起探索敏捷性与创新速度一起提升的秘方
Amazon Web Services 的现代应用程序创新一直是 Amazon 公司坚持追求的核心目标。约20年前,我们经历了一次彻底的转型,旨在建立起“发明、发布、再发明、再发布、重新开始、洗牌、再重复”的快速迭代流程。正是此番探索,彻底改变了我们构建应…...

Apache Hadoop、HDFS介绍
目录Hadoop介绍Hadoop集群HDFS分布式文件系统基础文件系统与分布式文件系统HDFS简介HDFS shell命令行HDFS工作流程与机制HDFS集群角色与职责HDFS写数据流程(上传文件)HDFS读数据流程(下载文件)Hadoop介绍 用Java语言实现开源 允许…...
python“r e 模块“常见函数详解
正则表达式:英文Regular Expression,是计算机科学的一个重要概念,她使用一种数学算法来解决计算机程序中的文本检索,匹配等问题,正则表达式语言是一种专门用于字符串处理的语言。在很多语言中都提供了对它的支持,re模块…...

【数据结构】二叉树的四种遍历方式——必做题
写在前面学完上一篇文章的二叉树的遍历之后,来尝试下面的习题吧开始做题144. 二叉树的前序遍历 - 力扣(LeetCode)94. 二叉树的中序遍历 - 力扣(LeetCode)145. 二叉树的后序遍历 - 力扣(LeetCode)…...

Nginx使用“逻辑与”配置origin限制,修复CORS跨域漏洞
目录1.漏洞报告2.漏洞复现3.Nginx 修复3.1 添加请求头3.2 配置origin限制2.3 调整origin限制1.漏洞报告 漏洞名称: CORS 跨域漏洞等级: 中危漏洞证明: Origin从任何域名都可成功访问,未做任何限制。漏洞危害: 因为同源…...
Laravel框架02:路由与控制器
Laravel框架02:路由与控制器一、路由配置文件二、路由参数三、路由别名四、路由群组五、控制器概述六、控制器路由七、接收用户输入一、路由配置文件 以web网页路由文件为例: 默认根路由 路由定义格式Route::请求方式(请求的URL, 匿名函数或控制响应的方…...
)
【POJ 2418】Hardwood Species 题解(映射)
描述 阔叶树是一种植物群,具有宽阔的叶子,结出果实或坚果,通常在冬天休眠。 美国的温带气候造就了数百种阔叶树种的森林,这些树种具有某些生物特征。例如,虽然橡树、枫树和樱桃都是硬木树,但它们是不同的物…...
)
React组件之间的通信方式总结(下)
一、写一个时钟 用 react 写一个每秒都可以更新一次的时钟 import React from react import ReactDOM from react-domfunction tick() {let ele <h1>{ new Date().toLocaleTimeString() }</h1>// Objects are not valid as a React child (found: Sun Aug 04 20…...
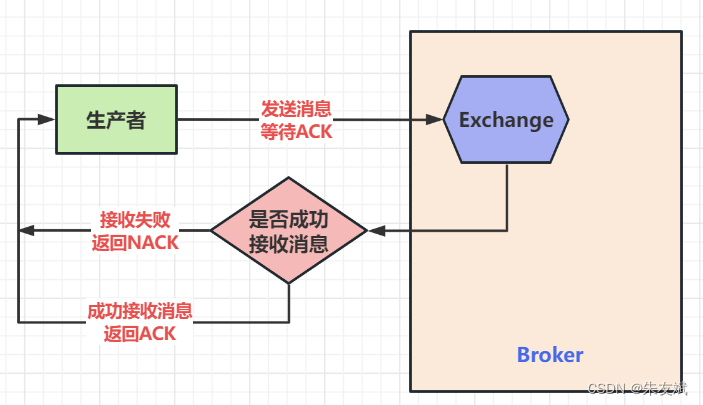
【RabbitMQ笔记07】消息队列RabbitMQ七种模式之Publisher Confirms发布确认模式
这篇文章,主要接收消息队列RabbitMQ七种模式之Publisher Confirms发布确认模式。 目录 一、消息队列 1.1、发布确认模式 1.2、案例代码 (1)引入依赖 (2)编写生产者【消息确认--单条确认】 (3…...

【华为OD机试模拟题】用 C++ 实现 - IPv4 地址转换成整数(2023.Q1)
最近更新的博客 【华为OD机试模拟题】用 C++ 实现 - 去重求和(2023.Q1) 文章目录 最近更新的博客使用说明IPv4 地址转换成整数题目输入输出示例一输入输出说明示例一输入输出说明Code使用说明 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...